深度半监督学习中伪标签方法综述
2022-06-17刘雅芬郑艺峰江铃燚李国和张文杰
刘雅芬,郑艺峰+,江铃燚,李国和,张文杰
1.闽南师范大学 计算机学院,福建 漳州 363000
2.数据科学与智能应用福建省高校重点实验室,福建 漳州 363000
3.中国石油大学(北京)信息科学与工程学院,北京 102249
随着智能技术的发展,深度学习已得到学术界和工业界的广泛关注,尤其在计算机视觉、图像处理、自然语言处理和语音识别等领域。例如百度的无人驾驶、阿里的用户行为分析等。
深度学习以数据为驱动,其优异的性能离不开大量标签数据。然而,在现实生活中,标签数据获取代价高昂。例如:在医疗任务中,标签均由领域专家分析得出。相比于标签数据,无标签数据获取相对容易,半监督学习则将二者相结合用以训练模型。研究表明将少量有标签数据和大量无标签数据相结合有助于提高学习任务的准确率。基于上述思想,研究人员将半监督学习引入到深度学习,提出深度半监督学习。根据所采用半监督损失函数和模型设计方式,深度半监督学习方法可分为:生成式方法、一致性正则化方法、基于图的方法、混合方法和伪标签方法。
(1)生成式方法:生成式方法学习数据的隐式特征,假设所有数据均来自同一潜在模型,以更好地将无标签数据与学习目标关联建模,并采用最大期望进行求解。在标签数据极少时,相比其他方法,能获得较好的性能。其关键在于与真实分布吻合程度。
(2)一致性正则化方法:将无标签数据用以模型强化,即将一个实际的扰动应用于一个无标签的数据,亦不会使预测结果出现明显变化。对于具有不同标签的数据,在聚类假设中属于低密度区域分离,因此,数据在扰动后标签发生变化的可能性微乎其微。由此可见,可将一致性正则化项作用于损失函数,以指定假设的先验约束。
(3)基于图的方法:在数据集上构建图,图中每个节点表示一个训练数据,每个边缘表示节点对相似性。可分为图正则化和图嵌入两种。图正则化使用Laplacian 正则化,假设具有强连接边缘的节点可能共享相同的标签,例如标签传播(label propagation)、高斯随机场(Gaussian random fields)和局部全局一致性(local and global consistency)。图嵌入则是将节点编码为向量,用于度量节点之间的相似性。
(4)混合方法:融合伪标签、伪一致性正则化和熵最小化的思想用以提高模型性能。此外还引入一种混合物学习原理,即一种简单的、数据不可知的数据增强方法,一个配对的数据及其各自标签的凸组合。
大部分深度半监督学习方法不足之处在于过分依赖特定区域的数据增强,然而在大多数应用场景下,数据增强并不容易生成,而其中伪标签方法却不受数据增强的约束。现阶段为无标签数据标注伪标签的方法则大多先利用标签数据训练模型,而后将伪标签数据与标签数据相结合扩大数据集,共同训练模型。可见,伪标签方法的性能主要依赖于所选择的模型。伪标签方法可分成自训练和多视角训练两大部分,自训练通过获得无标签数据的伪标签从而得到更多训练数据。多视角训练是通过训练多个模型,利用模型间的“分歧”给无标签数据打上伪标签。而Zhu 于2002 年提出的标签传播算法,无需依赖于任何的分类模型,将图和伪标签相结合,利用样本间的关系建立图模型,通过相似度给无标签节点标记标签。其具备易于实现且复杂度较低的特点,已被广泛应用于虚拟社区挖掘等领域。
在本文中,首先,对深度半监督学习进行分析;其次,从自训练和多视角训练两方面对伪标签方法进行详细的剖析;然后,着重阐述利用相似性且无需预训练的基于图和伪标签的标签传播方法,并讨论其优势所在;接着,对已有的伪标签方法进行实验分析的比对;最后,从无标签数据在实际应用中是否适用于所有模型、真实数据集带有噪声数据、数据采样的合理性以及伪标签方法和其他方法结合的情况总结伪标签方法所面临的问题和未来研究方向。
1 深度半监督学习
深度学习以数据为驱动,而获取大量的标签数据代价昂贵。深度半监督学习可通过少量标签数据和大量无标签数据构建模型,其无标签信息能提供更多关于数据分布的信息,从而更好地估计不同类别的决策边,有助于提高模型的性能。
近年来,随着智能信息技术的推广,机器学习方法得到广泛的研究,其主要分为:监督学习(supervised learning)、无监督学习(unsupervised learning)和半监督学习(semi-supervised learning)。
半监督学习介于监督学习和无监督学习二者之间,其基本思想是利用无标签数据提高模型的泛化能力,以减少对外界交互的过分依赖,从而训练更好的模型。三者之间对比如图1 所示。从图中可以看出,在半监督学习中,同时提供标签数据集D={(,),(,),…,(x,y)} 和无标签数据集D={x,x,…,x},且无标签数据数量远远多于标签数据,即≪。更具体地说,半监督学习的目标是利用无标签数据集D辅助生成预测函数f,比仅使用标签数据集D所获得的函数更准确。

图1 监督学习、半监督学习、无监督学习结构对比Fig.1 Structure comparison of supervised learning,semi-supervised learning and unsupervised learning
随着智能应用的普及,数据量急剧增加,数据标注标签信息代价昂贵。例如:在进行医学影像分析时,虽可获得大量的医院影像,但对影像中的病灶进行标注则需要由医学专家才能进行标注。同样,在进行商品推荐时,仅有少部分的用户愿意协助对商品进行标注。由此可见,半监督学习具有较高的应用价值。
如何有效利用无标签数据成为亟需解决的问题。无标签数据因其与标签数据从相同的数据源独立分布采样而来,虽未包含标签信息,但其分布的信息有助于模型的构建。本文给出一个直观的示例,如图2所示,图中包含一个正方形类和一个三角形类,待判别样本恰好位于两者之间,则在进行样本类别判断时仅能依靠随机猜测。倘若能观察到图中的无标签数据分布状况,则可将此待判别样本归为正方形类。由此可见,无标签数据可提供关于数据分布结构的额外信息,有助于更好地估计不同类别之间的决策边界。

图2 无标签数据效用示例(黑点为无标签数据)Fig.2 Unlabeled data utility example(black dots indicate unlabeled data)
最早将无标签数据应用到半监督学习中的方法是Self-training 方法,该方法使用有标签数据构建模型,进而对无标签数据进行预测,从中筛选出预测置信度高的样本加入标签数据集中,不断更新模型,直至收敛。然而要有效利用无标签数据,则必须对无标签样本所揭示的数据分布信息与类别标签之间的关系进行假设。目前,可分为聚类假设(cluster assumption)、平滑假设(smoothing assumption)和流行假设(manifold assumption)。
(1)聚类假设:当两个数据属于同一簇时,则拥有相同的类标签,即当数据和位于同一簇时,和的预测结果应一致。聚类假设亦称为低密度分离假设,即决策边界应位于低密度区域。
(2)平滑假设:指位于稠密数据区域的两个距离相近的数据具有相同的标签,即对于稠密区域中的两个数据,如果其存在边连接,则具有相同的标签信息,反之亦然。这个假设在分类任务中很有帮助,但对回归任务没有多大的帮助。
(3)流行假设:将高维数据嵌入到低维流形中,如两个数据在低维流形中同属于一个局部邻域,则其应具有相似的类信息,其着重于模型的局部特性。在该假设下,无标签数据就能使数据空间更加密集,有助于分析局部区域特征信息,从而使决策函数较好地拟合数据。
综上所述,上述三类假设虽然实现的方式不同,但其本质都是考虑样本的相似性。
近年来,深度学习在实际应用中取得优异的表现,但其以数据为驱动,需要大量标签样本用以训练模型。然而,在现实生活中,对样本进行标注代价高昂。为此,研究人员将半监督学习引入到深度学习中,提出深度半监督学习。
在早期的方法中标签数据和无标签数据分开使用,先利用无标签数据进行初始化,再利用标签数据对模型进行调整,其本质上仍是监督学习的模式。在半监督模式下,神经网络则应同时训练有标签和无标签样本,其损失函数的范式定义如下:

其中,表示为监督损失,表示为无监督损失,()为权重。不同的深度半监督方法区别在于所采用的的不同。
2 伪标签
现阶段,以一致性正规化方法为主的深度半监督学习由于过分依赖特定区域的数据增强,不易实现。为此Lee 提出伪标签方法,标签数据和无标签数据同时参与模型的训练。对于无标签数据,在每次权重更新时,为每个无标签数据赋予具有最大预测概率的标签,再将标注后的无标签数据放入标签数据集用以模型训练。本章将从自训练和多视角训练两方面对伪标签方法进行详细的剖析。
2.1 自训练
自训练是基于最可信预测以此标记无标签数据,根据模型自身生成伪标签,可分为熵最小化方法、代理标签方法、噪声学生模型方法、自半监督方法和元伪标签方法。首先,使用少量的标签数据D来训练预测模型f,再使用f为无标签数据x∈D分配伪标签。如果模型预测概率高于预定的阈值,则将数据(,argmax f())添加到标签数据集中,继续训练模型,为D-{x}中的数据标记伪标签,重复上述过程,直至模型无法产生最可信预测或所有的无标签数据都标注伪标签。在实际训练过程中,可采用相对置信度决定为哪些无标签数据标记伪标签,即在每次训练后对前个高置信度预测的无标签样本进行标记,并添加至标签数据集D中。Yalniz 等人将自训练方法用以训练ResNet-50 模型,先在带有伪标签的无标签图像上进行训练,再对标签图像进行微调,实验结果表明自训练方法进一步提高训练模型的鲁棒性。
熵最小化方法(entropy minimization)是一种熵正则化的方法,其通过鼓励模型对无标签数据进行低熵预测,再将其应用到监督学习中以实现半监督学习。理论分析表明熵最小化有助于阻止决策边界通过高密度的数据点区域,如无法阻止则将对无标签的数据产生低置信度的预测。
给定图像数据∈,令()表示特定神经输出函数,将所有概率分布P的熵(P)最小化,上述方法仅精确神经网络的预测,无法单独使用。如果将其作为损失,则会导致预测退化。Grandvalet 和Bengio 考虑从标签和无标签的数据中学习决策规则,并使熵最小化方法规范化。熵最小化方法可作用于任何特定的或限制最低熵规范的模型。当生成模型被错误指定时,熵最小化方法更有助于实现最低熵规范化。最新研究表明,熵最小化方法本身并不能产生有竞争力的结果,但当与不同的方法结合时,可以产生最先进的结果。
代理标签是一种估计无标签数据为伪标签的最简单方法,目标是生成代理标签用以增强学习。代理标签同时将标签数据和无标签数据以监督方式进行训练,如图3 所示。

图3 代理标签模型Fig.3 Proxy-label model
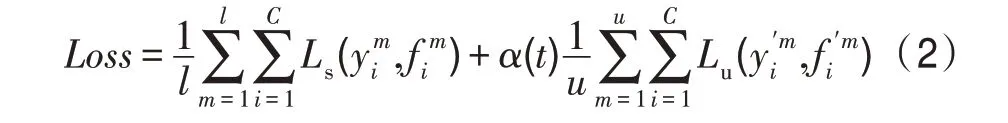

Shi 等试图确定其最优标签和最优模型参数,并通过迭代训练最小化损失函数。Iscen 等人将代理标签方法用于标签传播,在标签数据和伪标签数据上交替训练网络模型,同时引入两个不确定性参数,即每一个样本基于输出概率的熵(用以克服对预测的不平等置信度问题)和基于每个类得分的类种群(用以处理类的不平衡问题)。Arazo 等人则认为由于存在确认偏差,从而导致单纯的伪标签会过度拟合于不正确的伪标签。同时证明采用混合方式并设置每批的最少标签样本数量有助于减少上述偏差。
噪声学生模型(noisy student)方法受知识蒸馏思想启发,基于“教师-学生”框架,如图4 所示。其具体过程:首先采用教师EfficientNet模型对标签数据进行训练,为无标签数据生成伪标签,加入标签数据集;再采用规模更大的EfficientNet 模型作为学生模型,在新数据集上进行训练。同时,可在学生模型训练阶段加入Dropout 和Stochastic Depth 等模型噪声。经多次迭代,获更具有鲁棒性的学生模型,此时学生模型可作为教师模型,重新标注无标签数据。

图4 噪声学生模型Fig.4 Noisy student model
Liu 等人将噪声学生模型法用于探索药物代谢作用,可进一步加速药物发现过程,从而降低成本。Kumar 等人也采用噪声学生模型方法进行面部表情的识别,模型隔离面部的不同区域,并使用多级注意机制独立进行处理。其结果表明,与其他单一模型相比,该方法更加有助于提升模型的性能。
自半监督学习(self-supervised semi-supervised learning)将自监督学习技术用以解决半监督图像分类的问题。在自半监督学习方法中,有四个旋转度{0°,90°,180°,270°},用以旋转输入图像,其旋转损失为旋转图像预测输出的交叉熵损失。对于无标签数据,预测其不同的旋转角度打上伪标签,后与标签数据共同训练模型,如图5 所示。
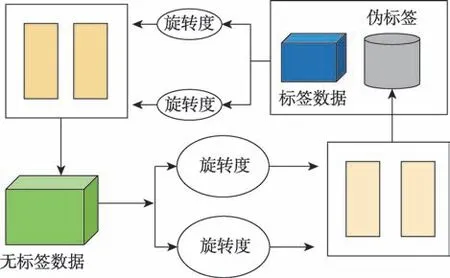
图5 自半监督学习模型Fig.5 Self-supervised semi-supervised learning model
Beyer 等人将损失分成有监督损失和无监督损失两部分,其中监督损失为交叉熵损失,而无监督损失是基于自监督技术的旋转和样本预测的损失。同时,提出两种半监督图像分类方法,有助于解决图像分类的半监督问题。
在半监督学习过程中,伪标签通常是由教师模型生成,不能有效适应网络训练的学习状态。为此,Pham 等人提出元伪标签(meta pseudo labels)方法,采用“学生-教师”框架,如图6 所示。在该框架中,教师模型使用元学习方法生成代理标签,并鼓励教师模型以改进学生模型学习的方式从而调整训练的目标分布,再通过评估学生模型用以更新教师模型。虽然允许教师模型调整和适应学生的学习状态,但不足以训练教师模型。为了克服上述问题,在教师模型中,还需使用验证集对标签数据进行训练。

图6 元伪标签模型Fig.6 Meta pseudo labels model
Pham 等在CIFAR-10、SVHN 和ImageNet 实验更进一步证明MPL方法的有效性。此外,在CIFAR10和ImageNet上附加额外的无标签数据,并使用Efficient-Net 进行训练。实验结果表明,采用元伪标签方法在CIFAR-10 上获得88.6%的准确率,在ImageNet 上获得86.9%的top-1 准确率。
自训练具备简单性和通用性,可广泛应用于各个领域。例如,图像分类、语义分割和目标对象检测等任务。但其不足之处在于,无法纠正其自身错误(即任何错误的分类都会被迅速放大)。而多视角训练在理想情况下,不同的视角可相互补充、相互协作,进而提高彼此的性能。
2.2 多视角训练
多视角训练亦称为基于分歧的模型训练,根据不同数据视角训练的模型生成伪标签,可分为协同训练方法和三体训练方法。与自训练不同之处在于,其数据存在多个视角,例如图像的颜色信息和纹理信息。多视角训练的基本思想是同时训练多个学习模型,分别用以标记无标签的样本。
协同训练方法(co-training)是指在两个视角上训练不同的分类模型,即在标签数据上分别训练两个预测函数f和f,如图7所示。在每次迭代过程中,将f标记的无标签数据添加到f中,彼此交换,重复此过程,直至无标签数据耗尽或满足最大迭代次数。

图7 协同训练模型Fig.7 Co-training model
具体过程描述如下:令()和()表示两个不同的数据视图,使得=(,)。假设为在上训练的分类模型,表示在上训练的分类模型,在目标函数中,协同训练方法假设定义如下:

其中,(·)表示熵。
在标签数据集上,标准的交叉熵损失可定义为:

其中,(,)表示和之间的交叉熵。
对于协同训练模型,关键在于其两种视角是不同且互补的,但损失函数和L仅确保模型对于数据集上的预测趋于一致。为了解决此问题,可在协同训练模型强制引入视角差异约束。
Tran 等人提出协同训练半监督回归和自适应算法,利用不同的视角增加输入数据量,并结合互相关等技术用于基于可见光的指纹技术定位。实验结果表明,随着输入数据量的增加,模型的定位精度随着增高。Díaz 等人提出一种使用深度神经网络的视觉对象识别的联合训练模型,通过添加多层自我监督神经网络作为视图的中间输入,视图会因其输出的交叉熵正则化而呈现多样化。该模型综合考虑输出的差异性,将协同训练和自我监督学习相结合,可称为差分自我监督共同训练(different self-supervised co-training)。结果表明,该方法虽然简单,但有助于提高模型的精度。
三体训练(tri-training)试图克服多个视角存在的数据缺乏问题,从三个不同的训练集(均通过自助抽样法得到)中训练三个分类模型,有助于减少自我训练中产生的预测偏差,如图8 所示。其基本思想:首先利用标签数据集训练三个预测函数f、f和f。令表示无标签数据,若其在f和f上预测结果一致,则认为伪标签自信且稳定。此时,将标记好的添加到f的标签数据集中,再对其进行微调。如果无数据点再被添加到任何模型的训练集中,则训练停止。在整个增强过程中,三个模型会变得越来越相似。因此,需分别在训练集上进行微调,以确保模型多样性。根据所采用的框架不同,三体训练可分为多任务三体训练(multi-task tri-training)和交叉视图训练(cross-view training)。

图8 三体训练模型Fig.8 Tri-training model
(1)多任务三体训练:使用神经网络的三体训练代价昂贵,需要对三个模型中的所有无标签进行预测。为了缓解上述问题,Ruder 和Plank将迁移学习思想引入半监督学习中,提出多任务三体训练方法,三个模型与特定于模型的分类层共享相同的特征提取器,将模型与一个额外的正交约束联合训练,从而进一步减少时间和空间复杂度。多任务三体训练不再单独训练模型,而是采用共享参数,并用多任务学习机制进行联合训练。需要注意的是,由于模型作用相同,其属于伪多任务学习。
(2)交叉视图训练:Clark 等人结合多视角学习和一致性训练,提出交叉视图训练,对于不同的输入视图能获得一致的预测输出。其基本思想是采用共享编码器,再添加辅助预测模块,将编码器表示转换为预测输出。可将上述模块分为辅助学生模块和初级教师模块,二者具有一致的预测。学生预测模块可以从教师模块的预测中学习,既提高编码器产生表示的质量,也有助于改进使用相同共享表示的完整模型。
在车辆识别中,不同视点下车辆的视觉外观会发生显著变化。为此,Yang 等人提出弱监督交叉视图学习模块,用于车辆的重识别,仅通过基于车辆入侵检测系统最小化交叉视角特征距离,而不使用任何视角标注来学习一致的特征表示。该模型在VeRi-776、VehicleID、VRIC 和VRAI 数据集上均获得显著的性能改进。
3 标签传播
基于伪标签的深度半监督学习方法均需使用标签数据训练模型,继而标注无标签数据,其算法复杂度较高。而将伪标签方法与基于图的方法相结合可解决训练模型复杂度高和数据分布形状局限的问题。本章主要介绍标签传播方法,即为二者相结合的深度半监督学习方法,其满足聚类假设和流行假设,即同一簇和同一流行中的数据可能共享相同的标签,利用簇的结构和节点间的相似性,将标签数据标签传播给无标签数据,具有运算简单和复杂度小的特点。
3.1 基于图的半监督学习

周志华认为基于图形的半监督学习概念清晰,且易通过对所涉矩阵运算的分析来阐述其性质。其不足之处在于存储开销成本较大。此外,在图构建过程仅依赖于训练样本集,对于新数据样本,难以判断其在图中的位置。Yi 等人建立了一种自适应的基于图的标签传播模型,解决了非负矩阵分解不能充分利用标签信息的弱点,采用局部约束来反映数据的局部结构,迭代优化算法求解目标函数。实验结果表明,该框架具有优异的性能。
3.2 基于图和伪标签的标签传播
标签传播主要假设是流行假设,即属于同一流形中的数据样本很可能共享相同的语义标签。为此,标签传播根据数据流形结构和中间节点相似性,将标签数据的标签传播给无标签数据。
首先,根据给定数据构建图,若假设图为完全图,则节点x和x边的权重可表示为:

其中,是超参数。
标签传播算法通过相邻节点之间传播标签,若节点间的权重越大,则表示其相似程度越高,标签越容易传播。为此,概率转移矩阵可定义为:

其中,p表示从节点x转移到节点x的概率。
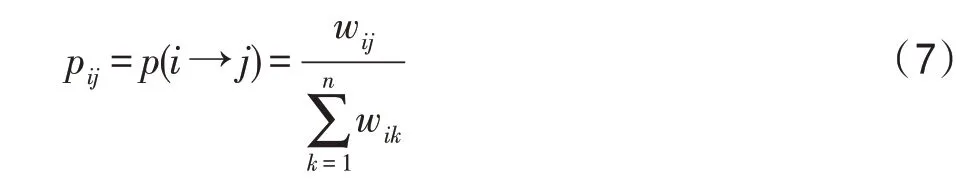
假设数据集中有个类和个标签样本,则定义一个×的标签数据矩阵F:

其第行表示第个样本的标签指示向量,即若第个样本的类别为Y,则第个元素为1,其他为0。
为了便于说明,将上述标签数据矩阵表示为F=[,,…,f]。
同样对于个无标签样本定义一个×无标签数据矩阵F:

值得注意,其数值初始可进行[0,1]之间随机初始化。为了便于说明,将上述无标签数据矩阵表示为F=[f,f,…,f]。
将F和F合并得到标签向量矩阵=[F:F]。
标签传播算法的具体过程如下:
(1)执行传播=;
(2)重置中前行标签样本的标签F=F;
(3)重复步骤(1)、(2)直至收敛。
上述过程中,步骤(1)表示将矩阵和矩阵相乘,即对于每个节点按传播概率将其周围节点传播的标注值按权重相加,并更新自身的概率分布。两个节点越相似(在欧式空间中距离越近),则对方的伪标签会越容易受影响。对于步骤(2),由于标签数据的标签是事先确定的,在每次传播后,需要回归其初始标签。随着标签数据不断将其标签传播出去,最后的类边界会穿越高密度区域,而停留在低密度的间隔中。
在每次迭代过程中,需对=[F:F]进行计算,由于F已知,且需要重新恢复初始值,F是最终结果,于是可将矩阵表示如下:

F计算方式可表示为:

重复此步骤直至收敛。
近年来,社交媒体已广泛应用于各个领域,影响最大化(influence maximization,IM)已成为社会网络分析研究的热点问题之一。Kumar 等人提出一种基于节点播种、标签传播和社团检测的影响最大化算法,其使用扩展h 指数中心性检测种子节点,再使用标签传播技术检测群落。经典的标签传播方法不足之处在于无法有效地联合节点属性和标签,且在大规模图上收敛速度较慢。为解决上述问题,Xie 等提出一种基于图结构数据的可伸缩半监督节点分类方法(简称为GraphHop),其使用适当的初始标签嵌入向量。模型主要包括:标签聚合和标签更新。在标签聚合过程中,每个节点将前一次迭代得到的相邻节点的标签向量进行聚合;在标签更新过程中,利用邻域信息,根据节点本身的标签和其所得到的聚合标签信息,为每个节点预测新的标签向量。实验结果表明,GraphHop 在各种规模的图表中均能取得较好的结果。王俊斌对标签传播算法进行扩展,提出基于成对约束的标签传播算法,将先验信息保存到成对关系矩阵中,并采用成对关系与聚类结果之间的差异来代替划分矩阵之间的差异。同时,通过构建一种新的最优化模型,将标签传播算法的最优化问题转化为谱聚类问题,并通过特征值分解方法进行求解。
4 实验分析
本章将介绍各类半监督伪标签方法所采用的数据集,同时对各种伪标签方法进行实验分析对比。
4.1 实验数据集介绍
在实验分析过程中,本文主要采用UCI(University of California,Irvine)数据集和图像数据集进行实验比对。UCI 数据集主要包括Iris、Cmc(contraceptive method choice)和Iono(Ionosphere),数据集信息如表1 所示。在实验过程中,为了保证实验结果的有效性,需对每个数据集进行归一化处理,并划分训练集和验证集。在进行半监督训练时,标签数据占训练集的10%,采取分层抽样的方式对每个类别进行采样。
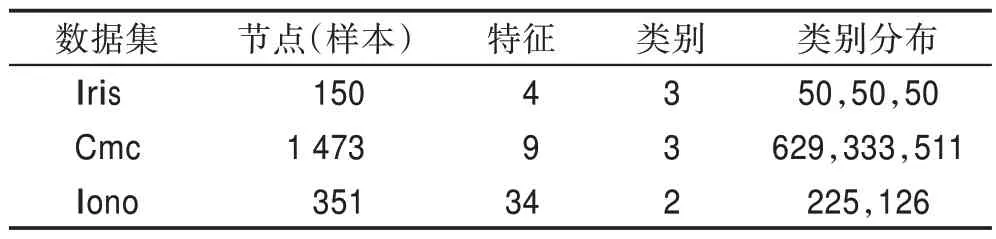
表1 实验中使用的UCI数据集Table 1 UCI datasets used in experiment
图像数据集主要包括ILSVRC-2012(多用于自训练)、CIFAR-10(多用于多视角训练)和CIFAR-100(多用于多视角训练)。
ILSVRC-2012 是ImageNet 的子集,包含1 000 个图像类别,其中训练集包含120 万张图像,验证集和测试集共包含15 万张图像。由于类别的数量较多,通常会将精确度设置为Top-1 和Top-5。Top-1 准确度是指一个预测与一个真实标签相比较的经典准确度,而Top-5 准确性则是检查一个基本真实标签是否在一组最多5 个预测中。本文实验过程中所给出的结果为仅使用10%的标签进行训练的Top-1 准确度。
CIFAR-10 和CIFAR-100 是大小为32×32 的彩色自然图像大型数据集,其中CIFAR-10 包含10 个类别,CIFAR-100 包含100 个类别。均使用5 万张图像用于训练,1 万张图像用于测试。本文实验过程中,对于CIFAR-10,使用从训练集中随机选择的4 000 张图像作为标签数据,其余的图像作为无标签数据;对于CIFAR-100,则是随机挑选10 000 张图像作为标签数据,其余的图像作为无标签数据。
4.2 实验结果分析
为了对已有的伪标签方法进行分析,本文分别在图像数据集和UCI数据集上进行实验,具体结果分别如表2 和表3 所示。其中图像数据集CIARF-10 和CIFAR-100 还未在自训练模型实验中大规模投入使用。因此,为保证实验的公平性,自训练模型仍然以ILSVRC-2012 为主。
表2 主要描述图像数据集中不同方法的实验结果,其中自半监督模型在不同数据集上均取得最高的准确率。自半监督模型为混合模型,将自监督旋转预测、VAT(virtual adversarial training)、交叉熵损失和fine-tuning 结合到一个具有多个训练步骤的单一模型中。此外,其将损失函数分为有监督和无监督的部分,其监督损失为交叉熵损失,而无监督损失则采用旋转和范例的自监督技术。由此可见,基于伪标签半监督学习方法仍然有着很大的进步空间。此外,从实验结果不难发现,随着数据样本的类别增多,模型的不确定程度逐渐增大,精确率随之下降。在相同的数据集上,三体训练方法效果也都优于协同训练方法,因三体训练方法同时使用半监督学习和集成学习机制,进一步提升学习性能。综上所述,随着基于伪标签半监督学习方法的发展,模型的识别准确率逐渐提高。而随着所使用的架构复杂程度增加,可以预测模型精度亦会随着时间的推移而提高。

表2 伪标签方法在不同图像数据集上实验结果Table 2 Experimental results of pseudo-labeling method on different image datasets %
表3 主要描述在3 个不同的UCI 数据集中,协同训练、三体训练和标签传播方法在kNN(nearest neighborhood)上的实验效果(=10)。为了更好地挑拣出结果的差异,采用十折交叉验证方式。从结果可以看出,标签传播方法优于前两者。模型的训练与数据的分布情况直接有关,标签传播主要假设是流行假设(即属于同一流形中的数据样本很可能共享相同的语义标签),可获得更好的实验结果。协同训练要求数据能够从不同的角度提取出两份不同的数据,即使用同一份数据构造出两个分类器,然而现实的数据大多缺乏多个视角。而三体训练能有效解决协同训练缺乏视角的问题,相比协同训练,其在UCI 数据集和图像数据集上均表现出更好的性能。但需要注意的是,基于图的标签传播无法有效地联合节点属性并且具有很强的随机性从而导致结果不稳定。在后续的工作中,可对此进行研究。

表3 伪标签方法在不同UCI数据集上实验结果Table 3 Experimental results of pseudo-labeling method on different UCI datasets %
5 问题与挑战
尽管基于伪标签的深度半监督学习已取得有效的进展,但仍存在有待研究的开放研究问题。
(1)无标签数据效用性:在半监督学习中,人们普遍认为无标签数据可以提高学习性能,特别是在标签数据稀缺的情况下。值得注意的是,无标签数据可以提高学习性能是在适当的假设或条件下,一些研究表明,使用无标签的数据可能导致性能退化。现有的基于伪标签的深度半监督方法主要使用无标签数据来生成约束,然后与标签数据共同更新模型。一般情况下,使用权衡因子用于平衡监督和无监督的损失,即所有无标签数据等权。然而,并非所有的无标签数据在实际应用中都同样适用于该模型。此时,需考虑无标签数据的权重问题。
(2)噪声数据:本文所提到的标签数据均认为是准确的,从而可以学习标准的交叉熵损失函数。然而现实生活中得到的标签数据可能带有噪声,在训练时只能训练带有噪声的数据集。在基于图的半监督学习中,为增强数据预测的一致性,引入一种由稀疏编码实现的L范数形式的Laplacian 正则化。从记忆效应的角度提出了一种协同训练和平均教师相结合的学习范式。还可对数据进行预处理,降低噪声数据带来的损失。
(3)合理性:在标签传播方法中,目前大多采用有放回的取样方式,使得样本在下次采样时仍然有可能被抽取到,这面临的问题是有时取到的样本集不能代表整体,从而降低其合理性,通过计算可得约有36.8%的样本未出现在采集数据集中。在之后的工作中,可对群优化进行研究,群优化的核心价值在于研究和探索“个体与总体之间的冲突和求得一致结果的条件”,进而提升数据采样的合理性。
(4)方法的结合:在调查过程中发现,一些平常的方法与伪标签方法结合在一起会显示出超乎预期的效果,第3 章有相应的介绍。然而,目前只有少数方法与伪标签方法相结合,而合理的组合策略有助于进一步提高模型的性能,因此,不同思想的相结合的融合策略是一个值得探索的未来研究领域。
6 结束语
本文首先介绍深度半监督学习,可根据半监督损失函数和模型中最显著的特征,将其分为生成式方法、一致性正则化方法、基于图的方法、伪标签方法和混合方法。本文以伪标签方法作为切入点展开详细的叙述,该方法旨在标签数据上训练模型,用以预测无标签数据的类别(即伪标签),再将新生成的伪标签数据扩充训练数据。针对伪标签方法需预训练模型这一问题展开讨论,引入基于图的标签传播方法,即无需经过预训练模型就可得到伪标签。此外,本文进一步阐述标签传播方法的基本思想,其利用数据的分布及其内在关系(即样本间的相似关系),用以标记无标签数据。最后,本文对伪标签学习研究过程中所存在的问题进行总结,并提出未来的研究方向。
