程序能耗测量分析工具FPowerTool及其能耗优化实践
2022-06-17钱德沛杨海龙栾钟治
魏 光,钱德沛,2,杨海龙,2,栾钟治,2+
1.北京航空航天大学 计算机学院 中德联合软件研究所,北京 100191
2.北京航空航天大学 软件开发环境国家重点实验室,北京 100191
在“新基建”的推动下,数据中心等基础设施发展迅猛,对电力能源的需求快速增长。数据中心中存在大量的服务器等IT 设备,每天都要处理海量数据,完成大量计算,随着能源价格的不断上升,电费已经成为数据中心最主要的运营成本。另一方面,随着移动互联网应用的普及,电源受限的移动或嵌入式设备的能耗问题也引起越来越多的关注。在电源受限的设备例如手机中,软件能耗优化的重要性日益凸显,优化这类软件的能耗不仅可以节能,更重要的是可以延长设备的待机或操作时间。因此,IT设备的节能降耗已经成为学术界和工业界共同关注的热点问题。
在降低IT 设备能耗方面已有大量研究工作,例如,缩小集成电路特征尺寸降低供电电压,改进器件结构降低静态电流,以分区供电应对工艺的离散性,动态调整电压频率以降低运行功耗,沉浸式相变高效冷却,以及能耗感知的任务调度等。但是,从软件开发和程序编写模式角度研究如何降低能耗的工作还比较少。数据中心存在大量每天都要反复运行的日常应用软件,如果能从改进这些软件的编写模式和数据访问模式入手,使这些软件在相同硬件条件下的运行能耗得到降低,那么数据中心的整体能效就会得到进一步改善。优化程序能耗的关键在于定位程序中能耗热点,发现产生过高能耗的原因,通过改变代码的编写方式和数据的访问方式,达到降低程序执行能耗的目的,称这种编程模式为能耗感知的编程(energy-aware programming,EAP)。如何在程序开发过程中准确测量程序代码的能耗,建立起能耗、性能事件和程序代码三者之间的关联关系,是实现能耗感知编程的关键。
本文针对能耗感知编程的需求,提出一种程序能耗和性能事件协同测量与分析的方法,通过统一的时间基准,建立程序能耗热点、性能事件和程序代码段之间的关联关系,确定影响程序能耗的主要因素,定位与高能耗对应的程序操作,从而为面向能耗的代码优化奠定基础。在论述方法的基本原理之后,本文简要介绍了基于该方法的程序能耗测量分析工具FPowerTool的实现以及能耗和性能事件关联分析的方法。然后,以若干典型程序的能耗优化为例,分析程序能耗与代码编写模式、数据存放和访问模式等因素之间的关系,通过改变程序中与过高能耗相关的变量定义、赋值和访问模式,降低程序执行的能耗。实验结果表明,本文提出的能耗与性能事件协同测量与分析方法能够准确地获取程序的能耗行为,建立能耗与性能事件之间的关系,帮助程序员分析影响程序能耗的主要因素,从而有针对性地改进代码,优化程序的能耗,并可以利用FPowerTool工具评估对比代码修改前后能效的优劣。
1 相关工作
大部分现代处理器都集成了RAPL(running average power limit)模块。RAPL 使用了软件的能耗模型,提供了读取事件编码及掩码配置MSR(model specific register)接口。Intel 的技术文档中说明RAPL 相关计数器的更新频率为1 kHz,这对于能耗的精准测量是一个限制。MSR 中包含了系统中PKG(package)、PP0(power plane 0)、PP1(power plane 1)和DRAM 能量消耗的计数值。其中PKG 表示整个芯片,PP0 表示处理器的所有核,PP1 表示其他非处理器的设备(一般是GPU),DRAM 表示主存。通过MSR 还可以获得性能计数器的值,目前已经有多种成熟的采样性能计数器的工具被广泛使用,例如PAPI(performance application programming interface)、Perfsuit、Perfmon和libpfm4 函数库等。Perf是Linux 内核中的一个功能强大的性能调优工具,可以通过RAPL 提供的接口进行能耗的测量。Likwid是Linux 操作系统对Intel 和AMD 处理器进行性能监控的工具集,其中的likwid-powermeter 工具可以读取RAPL 中的能耗信息,计算出程序运行过程中系统消耗的能量。
一些能耗研究工作结合使用性能分析工具和RAPL 来分析应用的能耗信息。Khan 等人基于IgProf的能耗工具和RAPL,得到了应用执行时间和特定函数所消耗的能量的强相关性信息。TProf是一个并行程序能耗的评价工具,其中能耗部分的测量使用PAPI 来读取RAPL 的值。Mukhanov 等人设计的ALEA 是一个细粒度的能耗评价工具,通过建立能耗的统计模型并利用RAPL 计算得到代码基本块的能耗值,并在Intel Sandy Bridge 和ARM big.LITTLE硬件平台上进行了验证。E-Team是一个Linux上基于RAPL 测量能耗信息的调度器。
面向代码的能耗优化按优化的对象可分为指令级、语句级和模块级。面向语句级的能耗优化更适合于程序的开发或调试过程,例如通过代码结构或数据结构的变换、提高缓存利用率等方法来降低能耗。Kandemir 等人在多体存储系统(multi-bank memory systems)上研究了循环优化对能耗的影响,例如循环分裂融合(loop fission and fusion)、循环分块(loop tiling)和线性循环变换(linear loop transformation),这些方法尝试提高缓存利用率,但仅使用建模的方法来得到能耗信息,并未测得代码在硬件上的实际能耗信息。Bunse 等人在嵌入式环境下评测了各种排序算法的能效,发现不同的算法消耗的能量不同,但一个算法的时间复杂度和能量消耗之间并无必然的联系,实验中采用外接数字示波器的方法来估算能耗。还有一些研究工作使用系统硬件计数器来进行能耗建模,文献[22-23]归纳总结了在数据中心和高性能计算系统能耗及应用能耗建模和预测方面的工作。
高速缓存(cache memory)是介于处理器与内存之间的存储层次,对于程序员并不显式可见,但对于提高处理器性能至关重要。显然,访问处理器片外的内存要比访问片内的高速缓存慢得多。cache 对提高处理器性能非常重要,但由于是用高速静态存储器技术实现的,其本身能耗也很高。研究工作表明,ARM 920T 的cache 子系统的能耗约占处理器整体能耗的44%。另一研究工作对不同规模的处理器进行了模拟,发现因泄漏电流导致的静态能耗比例约为37%~72%,其中L2 cache 产生了大部分静态能耗。因此,改进cache 的组织结构、一致性协议和替换策略不仅能提高处理器性能,也会降低处理器能耗。在改进cache 优化程序执行性能方面已有大量研究,本文将从cache 中数据的放置以及访问模式角度分析cache对程序能耗的影响。
2 能耗和性能事件协同测量方法EPC
2.1 能耗感知编程
图1 显示了能耗感知编程的过程。能耗和性能事件测量模块采集原始代码执行过程中消耗的能量和发生的性能事件,产生与被测代码执行过程相对应的能耗数据和性能事件数据;采集到的数据经过能耗分析模块处理,得到能耗与性能事件的相关关系。再由能耗优化模块根据相关性,改写程序代码编写或数据访问模式,减少能耗高的性能事件,得到能耗优化的代码。这个过程可以多次迭代,直到达到预期的效果为止。

图1 能耗感知编程的过程Fig.1 Workflow of energy-aware programming
能耗感知编程需要解决以下问题:
(1)如何以较细粒度测量代码段执行产生的能耗,精确定位程序中的能耗热点。
(2)如何确定程序能耗和程序执行中性能事件之间的因果关系,找出影响能耗的主要因素。
(3)如何确定能耗热点程序段中的性能事件与代码编写模式和数据放置与访问模式之间的关系,为面向能耗的代码优化提供依据和指导。
2.2 EPC 方法的基本原理
针对上述能耗感知编程急需解决的问题,提出了一种程序能耗和性能事件协同测量与分析的新方法EPC(energy-performance correlation)。EPC 的基本原理是,在程序执行过程中同时采集消耗的能量和产生的性能事件数据,通过基于统一时间基准的时间戳把代码段产生的能耗和性能事件关联起来,建立它们之间的对应关系。能耗的测量通过采集处理器内置的能量消耗计数器完成,不需额外的测量硬件,也无需对硬件做任何改动。在测量过程中,始终有一个能耗采集模块在后台运行,周期性地采集系统的能耗值,附加上采集时刻的时间戳后形成系统能耗文件并存储。这个模块的作用相当于一块虚拟电表,记录系统消耗的电能,供测量时查询。被测程序被划分基本代码段。一个基本代码段可以是函数或任意大小的代码段,通过插桩的方法在基本代码段的开始点和结束点插入简短的代码。插入的代码从系统能耗采集模块获得该基本代码段消耗的能量值,并从处理器内置的硬件性能计数器获取该代码段执行过程中产生的性能事件值。采集到的数据附加时间戳后存储,供后续分析时使用。通过比对时间戳,把一个基本代码段的能耗、性能事件和基本代码段在源代码中的位置关联起来,从而为分析产生高能耗的主要因素,优化程序代码提供依据。
2.3 EPC 的实现
基于EPC 的基本原理,设计实现了一个支持能耗感知与分析的评测工具FPowerTool。FPowerTool以插桩和采样相结合的方法,动态获取处理器内置的能量计数器和性能事件计数器的值,从而准确地测量各个基本代码段在执行过程中所消耗的能量和产生的性能事件,分析基本代码段的能耗行为与其产生的性能事件的关系,掌握程序的能耗行为特征。FPowerTool的实现有以下特点:
评测粒度可控:基本代码段的大小对于能耗热点定位的准确性有直接影响。代码段划分得越小,越有利于能耗热点的定位。但如果基本代码段过小,测量开销过大,反而会造成被测程序能耗行为的失真。在FPowerTool 的实现中,基本代码段可以是一个函数,也可以是指定的代码片段。通过指定特定被测函数或调节基本代码段的大小,FPowerTool可以控制测量的粒度。实际使用中,可以先划分较大的基本代码段,粗略定位热点,然后进一步细分基本代码段,获得更为精细的热点能耗行为。
非入侵性:能耗的测量对非侵入要求更苛刻,不能改变程序原有的时序关系和能耗行为,造成测量的失真。FPowerTool 通过对编译后的二进制可执行文件添加动态插桩,实现对基本代码段能耗及性能事件数据的采集,动态插桩的位置位于函数的调用和返回处,或基本代码段的起始行和结束行。FPower-Tool不需要对被测程序源代码做任何修改,只需在被测程序编译时使用“-g”编译选项,以获得基本代码段的行号信息。非入侵性意味着FPowerTool 能耗测量过程中引入的失真较小,不会影响被测程序执行的正确性。
低开销:由于不需要对被测程序做预处理和静态检测,FPowerTool 引入的额外开销很小。通过控制动态插桩的探针数量以及合理选择基本代码段的大小,可以在开销可控的前提下完成对指定代码范围内所需粒度的测量,在测量过程中对被测程序执行时间的影响很小。
FPowerTool 的动态插桩主要基于SystemTap 实现。SystemTap 是一个基于Linux 内核的调试和监控工具。使用SystemTap 脚本可以对二进制可执行程序添加动态插入的探针。SystemTap 脚本会被翻译成C 代码,然后转换成一个系统内核模块。通过在内核层面的uprobes 接口,对代码进行动态插桩。当可执行文件执行到探针的探测点时,模块会被触发并执行相应的操作。动态插桩的流程图如图2 所示。

图2 动态插桩流程图Fig.2 Workflow of dynamic instrument
在动态插桩过程中,在基本代码段首尾成对地插入探针,对非函数的任意代码段的动态插桩而言,额外需要DWARF(debugging with attributed record formats)调试信息中的行号。简言之,DWARF 信息在动态插桩的探测点和对应的源代码行号之间建立起关联,使得可执行文件执行到指定行数时会触发相应的探针。
当插桩的探针被触发时,SystemTap 工具就会记录下触发的时刻和perf 事件的统计信息。图3 展示了被测程序插桩的探针被触发的示意图。

图3 程序插桩触发示意图Fig.3 Schematic diagram of probe triggering

图4 一个基本代码段的能耗计算Fig.4 Computing energy consumption by a basic code block
虚拟电表程序即能耗采集后台程序通过调用PAPI 周期性地读取RPAL 能耗数据。在被测程序执行过程中,FPowerTool 会不停地记录程序执行过程中各个基本代码段的时间信息和RAPL 相关的能耗数据。程序执行结束后,FPowerTool 会根据时间戳把基本代码段的插桩信息和能耗数据相互关联起来。图4 是计算一个基本代码段能耗信息的示意图。图中左侧是插桩产生的基本代码段时间戳信息,右侧是能耗采集模块产生的采样时刻信息和能耗数值。因为能耗采样模块和基本代码段的动态插桩都是利用SystemTap 工具在探针触发时记录的时间戳信息,也就是说,基本代码段的时间戳信息和能耗采样的时间戳信息是基于同一时间基准,因此可以使用基本代码段开始与结束处的两个时间戳作为索引,精确计算并累加这两个时间点之间的能耗采样数据值,不足一个RAPL 能耗采样时间间隔的部分按时间比例计算。计算方法如式(1)所示,其中表示插桩过程中的能耗,和表示插桩在开始处和结束处的时间戳,E表示时间戳t和t间的能耗。

更为详尽的FPowerTool设计与实现可参阅文献[1]和Github(https://github.com/fpowertool/FPowerTool)。
2.4 能耗和性能事件的关联分析
EPC 方法不仅实现对基本代码段的能耗的测量,还同时记录了基本代码段执行过程中产生的性能事件数值,例如缓存命中和扑空、内存访问以及I/O 操作的次数等。这些性能事件信息为识别能耗与各种性能事件之间的关系,分析过高能耗的原因,进而优化相应的代码提供了依据。为了分析性能事件与程序能耗之间的关系,使用机器学习中的判别分析方法建立了以性能事件为输入变量、以能耗水平为输出的能耗模型。模型由一组判别函数和一组能耗分类的重心(坐标)组成。判别函数是性能事件测量值的一个线性组合,其一般形式如式(2)所示,其中a为系数,x为第个性能事件的值。在本文的模型中,选取了20种性能事件作为输入变量,如表1所示。


表1 模型用到的性能事件Table 1 Performance events used in model
使用PARSEC和NPB 3.3 基准测试集中的22个程序,在不同数据规模和不同线程数的组合下运行,得到900 多个样本,每个样本含一个能耗值和20个性能事件值。利用这些样本,训练出14 个判别函数。程序能耗由低至高分为15 级。预测一个新的程序的能耗时,使用该程序的性能事件值作为输入,计算出14 个判别函数的输出分数,然后以这14 个分数得到该程序在判别空间中的坐标,与各能耗分类的重心相比较,判断该程序落在哪个分类。判别分析的原理在此不再赘述,可参见文献[30]。
根据标准化后的判别函数公式中性能事件变量系数的大小,就可以初步判定各种性能事件对于能耗的相对重要性。判别函数的特征值表明其判别能力,特征值越大,判别能力越强。其中建立的第一个判别函数就具有89.945%的判别能力,前两个判别函数就可以解释96%的变量。因此,分析第一个判别函数中变量的系数,就可以大致了解各种性能事件对能耗的影响。表2 显示了第一个判别函数中各变量(性能事件)的系数。可以看出,在同一个架构下影响程序能耗水平的主要因素是与CPU 相关的性能事件,如cpucycles,降低指令执行次数就可以降低能耗。其次,缓存相关的性能事件,如iTLBloads 和L1icacheloadmisses 等也有较大影响。了解各个性能事件对于能耗的重要性有助于找出影响能耗的主要因素,对代码的改写和优化有指导意义。

表2 第一个判别函数中各性能事件的相对重要性Table 2 Relative importance of performance events in the first discriminant function
3 FPowerTool的应用验证
为了验证FPowerTool 在支持能耗感知编程方面的能力,利用它测量了几个案例程序,分析编程模式对于能耗的影响,并对代码进行了优化。在现代计算机中,数据的访问和移动都会消耗一定的能量,因此实验中选择了几个与数据存放和访问模式相关的案例。实验对象程序选自Rodinia和Rogue Wave公司的白皮书。
实验平台采用Intel Haswell-EP 架构服务器,配置如表3 所示,服务器上有两个Intel Xeon E5-2680 v3 处理器(2.50 GHz,12-core),安装了Centos 操作系统(Linux 内核版本是3.10.0)。Haswell-EP 架构支持读取PACKAGE 和DRAM 的RAPL 能耗信息。

表3 实验平台配置Table 3 Experiment platform configuration
所有实验的案例程序均使用gcc 及-O3 选项进行编译,链接成可执行文件,并使用likwid-pin 工具将程序指定在PACKAGE1 的同一个核上运行。在运行过程中,本文使用FPowerTool 工具收集程序在运行过程中的性能事件和能耗信息。
由于程序的能耗和性能之间可能相互牵制,为了综合评价优化对二者的影响,本文选用能耗时延积(energy delay product,EDP)作为评价能耗与性能优化技术好坏的综合指标。
EDP 的计算公式如式(3)所示,其中表示消耗的能量,表示运行时间,的值为1、2 或3,在实际运用时会对数据进行规则化处理。

在能耗感知编程过程中,EDP 的值越小表示能耗效率越高,性能也越好。
3.1 优化案例1:消除变量赋值冗余
第一个实验有关变量赋值冗余。变量赋值冗余是指在短时间内对内存的同一地址重复写入相同的值,也称为重复写,重复写会造成程序能耗增加、性能下降。实验中选取了异构计算的基准测试程序集Rodinia中的LavaMD程序。LavaMD是一个OpenMP的程序,用来计算3D 空间中由于粒子之间的相互作用而导致的粒子电势和粒子位置的重定位。
首先对程序进行能耗测量,测量结果如图5 所示。从能耗信息中,可以发现kernel_cpu 函数是程序的能耗热点。

图5 LavaMD 原生程序的能耗信息Fig.5 Energy consumption of original LavaMD program
利用动态插桩对LavaMD 程序进行重复写的检测。对源代码内层for 循环的分析发现,在对变量2的赋值计算中,不变,为for 循环的自变量,也就是说2 的值依赖于变量[].的值,但是变量[].的相邻元素存在大量的重复值。优化方案是在对2赋值计算之前,添加一个对变量[].的值的判断语句,如果变量[].值不变,就不再进行后续计算和赋值。下面是相关的原生代码和优化后的代码。
优化前后的LavaMD 相关代码:


优化前后的kernel_cpu 函数的能耗和性能事件如表4 和表5 所示。可以看出,优化后的函数在处理器和DRAM 上的能耗都有所下降,而且几乎所有性能事件的数量都有所下降,这正是其能耗下降的主要原因。在能耗下降的同时,程序执行时间也缩短了12%。
3.2 优化案例2:消除多余变量定义
多余的变量定义在程序模块复用中是常见的现象。有些模块为了兼顾多种用途,变量定义覆盖较广,但是在某个特定应用中,却只需使用其中的一部分。这个实验给出多余变量定义影响能耗的一个例子。程序1 和程序2 分别是优化前后的代码片段。对比这两个代码片段,不同之处在于程序1 中的data结构体的定义中存在没有用到的成员c 和成员d,如下所示。

表4 kernel_cpu 函数优化前后能耗变化Table 4 Energy consumed by kernel_cpu before and after optimization

表5 kernel_cpu 函数优化前后性能事件对比Table 5 Performance events of kernel_cpu before and after optimization
程序1 和程序2:


FPowerTool 测得的能耗和程序运行中发生的性能事件分别如表6 和表7 所示。

表6 程序1 和程序2 的能耗结果Table 6 Energy consumed by program 1 and program 2

表7 程序1 和程序2 的性能事件统计Table 7 Performance events statistics of program 1 and program 2
从测得的能耗和性能硬件事件结果可以看出,程序2 的执行时间较短,能耗较低,所产生的cache 扑空相关的性能事件(如cache misses、L1dreadmiss 等)的数量都少得多,其能效及性能都优于程序1。其原因是,现代处理器中的cache 以缓存行(cache line)形式缓存用户的数据,一个典型的缓存行通常为32 Byte或64 Byte,对应内存的一块地址。在处理数据的过程中,CPU 会按缓存行来写入或读取内存的数据。程序1 中定义的数据会在内存中连续存放,缓存行中存放了多个结构体成员。但程序1 从内存中读取数据的过程中只用到了成员a 和成员b,缓存中的缓存行中只有一半的数据被访问,成员c 和成员d 并不使用,这是多余变量定义的典型例子。
程序2 中数据在内存缓存行中只有成员a 和成员b,从内存读取到缓存行的所有数据都被用到,没有多余变量占据cache 空间。cache 空间利用更有效,缓存行的替换会减少。
图6 显示了程序1 和程序2 的执行时间、PACKAGE1 能量和EDP 的对比,图中的数据均经过规则化处理。以程序1 的数据规则化为1 作为基准。其中,EDP1=×,EDP2=×,EDP3=×。可见,通过简单消除多余变量,就可以显著改善程序的能效和性能。

图6 程序1 和程序2 的执行时间、能量和EDPFig.6 Normalized execution time,energy and EDP of program 1 and program 2
3.3 优化案例3:按字对齐的数据放置
与案例2 类似,程序3 和程序4 分别是优化前和优化后的代码片段。两段程序中的struct结构体定义中都存在没有用到的成员b 和成员c,但它们在结构体中所处的位置不同,如下所示。
程序3 和程序4:


FPowerTool 测得的能耗和程序运行中发生的性能事件分别如表8 和表9 所示。可以看到程序4 仅仅通过调整struct 变量定义中成员的位置,就能得到较好的能耗及性能,这是一个理解数据按字对齐存储的典型例子。通常编译器会根据数据字段的大小和类型来决定它们在内存中的存放方式。程序3 定义的结构体成员a 在缓存行存放时,因为内存需要按字节对齐而浪费掉3 个字节空间。同样,程序3 中结构体成员c 也浪费掉3 个字节空间。而程序4 定义的结构体成员a 和成员c 在缓存行中按字节对齐时,可以连续排列,只浪费掉2 个字节空间。很明显程序3 的cache 空间利用率要比程序4 的低很多,因此导致cache扑空的性能事件数量更多。

表8 程序3 和程序4 的能耗结果Table 8 Energy consumed by program 3 and program 4
图7 显示了程序3 和程序4 规则化后的执行时间、PACKAGE1 能量和EDP 的对比,可以看出程序4 实现了更优的能效和性能。这个案例说明,与按字对齐存储方式相匹配的数据放置可以改善程序能效和性能。
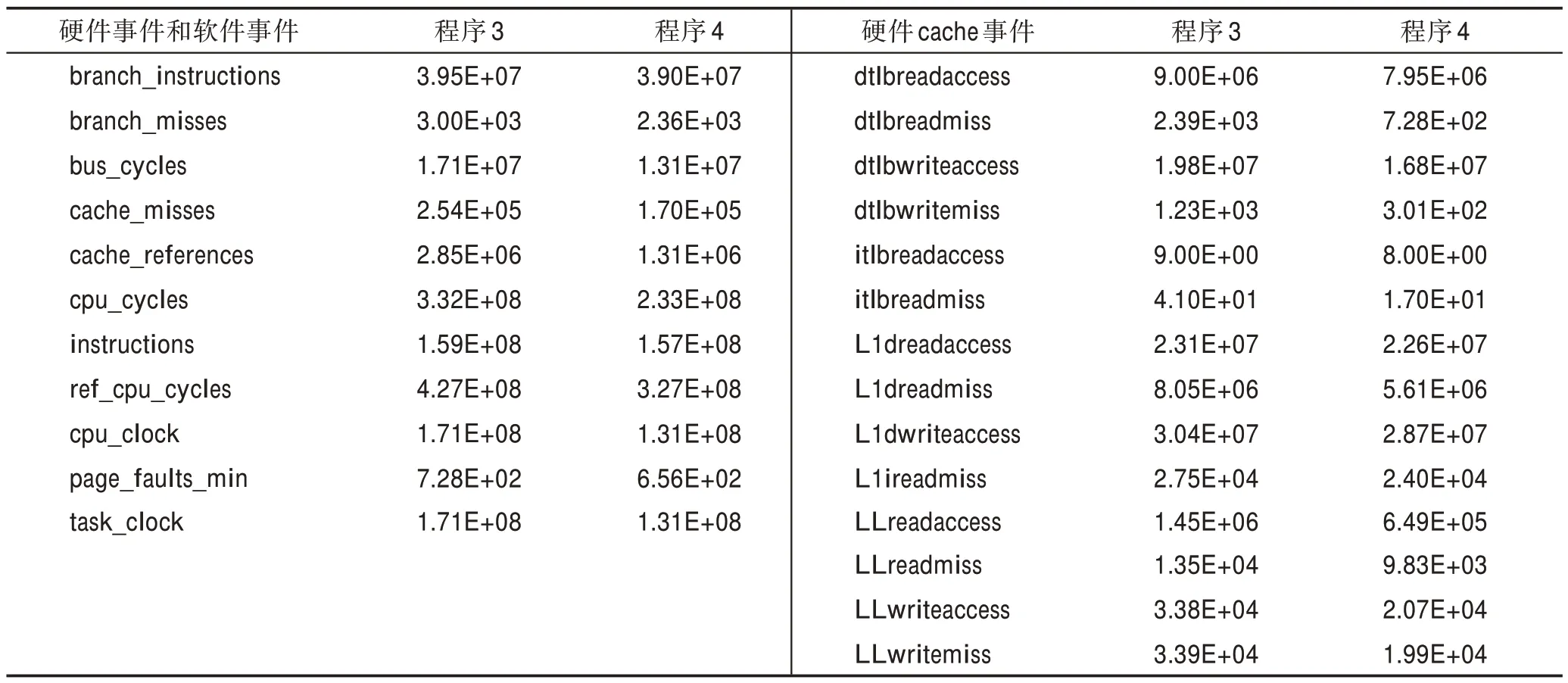
表9 程序3 和程序4 的性能事件统计情况Table 9 Performance events statistics of program 3 and program 4

图7 程序3 和程序4 的执行时间、能量和EDPFig.7 Normalized execution time,energy and EDP of program 3 and program 4
3.4 优化案例4:数组存储与访问模式的匹配
优化前后的代码片段程序5 和程序6 的不同之处在于这两个代码段对数组访问的模式不一样。这是一个典型的数组按行还是按列访问对性能的影响问题。所处理的数据构成一个1 024 行(row)10 240列(col)的数组。数组在内存中按行序存储,也就是说同一行中的单元连续存放,存完一行再存下一行。Cache 从内存每次加载一个缓存行。程序5 和程序6 都用和分别作为行和列的索引对数组进行访问,如下所示。
程序5 和程序6:


图8 显示了两个程序的访问逻辑,虚线线头显示出缓存中数据的访问次序。程序5 是按列访问,如图8(a)所示,每加载一个缓存行,只访问对应列中的一个单元,然后加载下一缓存行。而程序6 是按行访问,每次加载一个新的缓存行,会连续访问该行的所有单元,其访问效果如图8(b)所示。

图8 按列访问与按行访问对比Fig.8 Comparison of per-column access and per-row access
FPowerTool 测得的能耗和程序运行中发生的性能事件分别如表10 和表11 所示。

表10 程序5 和程序6 的能耗结果Table 10 Energy consumed by program 5 and program 6
从以上访存模式的分析中可知,对特定存储方式的数组的不同访问模式会导致不同的能耗及性能。程序6 的按行访问模式与按行连续存储模式相匹配,使每次加载的cache 行中的数据得到充分利用,因此cache 空间利用率高,避免了从内存的频繁加载,执行中与cache 扑空相关的事件数量明显减少,不仅程序性能得到提高,其能效也得到改善,表10 和表11 中的能耗和性能事件数据印证了这一点。图9 显示了程序5 和程序6 规则化后的执行时间、PACKAGE1 能量和EDP 的对比,程序6 明显占优。这个案例说明,数组数据的访问模式一定要和数据的放置相匹配,按行连续存放与行序访问相匹配;反之,按列连续存放要求列序的访问。

表11 程序5 和程序6 的性能事件统计情况Table 11 Performance events statistics of program 5 and program 6

图9 程序5 和程序6 的执行时间、能量和EDPFig.9 Normalized execution time,energy and EDP of program 5 and program 6
从案例2~案例4 可知,数据放置和访问模式对程序的性能和能耗有很大影响,通过简单地消除多余变量,变换struct结构体成员的位置,改变数组元素的访问次序,就可以显著提高程序的执行性能,降低程序的能耗。可以预见,诸如循环展开、数据预取、流水处理、通信计算重叠以及数据放置等方面的性能优化手段也可能改善程序的能耗,但是需要用工具去测量,用实验去验证。
以上实验也显示了FPowerTool 在能耗感知编程过程中的角色和使用方式。通过测量程序基本代码段的能耗和性能事件,定位程序能耗热点,了解热点代码段中的性能事件水平,分析其对能耗的影响,然后有针对性地改进程序中的数据分布、数据访问模式,使其尽可能与特定的硬件相匹配。这个优化过程可以多次迭代,逐步逼近优化的目标。在这个过程中,FPowerTool 可起到获取真实数据、定量评估优化效果的作用。
4 结束语
本文提出了能耗感知编程的概念,针对能耗感知编程对能耗测量和分析的需求,提出了一种程序能耗与性能事件协同测量与分析的方法EPC。该方法通过采集处理器内部的硬件计数器,获得程序能耗以及执行过程中的性能事件数值,定位能耗高的程序代码段,并通过时间戳对能耗和性能事件进行关联分析,找出影响程序能耗的主要性能事件。由于该方法无需修改被测代码,额外开销低,对被测程序的打扰少,测量结果失真较低。基于该方法实现了面向能耗感知编程的测量分析工具FPowerTool,使用FPowerTool 对几个程序优化案例进行了评测和优化,揭示了变量定义、赋值、放置和访问模式对程序能耗的影响。实验结果表明,改进变量定义、赋值、放置与访问方式可以提高cache 利用率,提升程序性能,改善程序能效。这几个实验案例初步验证了FPowerTool在支持能耗感知编程中的有效性。
FPowerTool 在一定程度上解决了能耗感知编程面临的基本问题,但是其使用仍具有一定的局限性。首先,能耗采样的分辨率受限于处理器内部硬件计数器的采样频率,它不能区分指令级别的能耗,只能做到代码段级。在多数情况下,这对定位程序能耗热点是足够的。要追求更细粒度的指令级别的能耗测量则依赖于处理器内部计数器采样分辨率的提高。其次,能耗和性能事件关联关系的分析目前自动化水平还不高,更多依赖程序员的经验,需要发展更为智能的辅助分析工具。这些将是下一步的研究工作。
