基于改进XGBoost 的电商客户流失预测*
2022-06-16廖开际邹珂欣庄雅云
廖开际 邹珂欣 庄雅云
(华南理工大学工商管理学院 广州 510641)
1 引言
目前我国电商行业发展迅速,电子商务数据作为国家大数据战略的重要组成要素,不仅有很高的应用价值,还有很高的经济价值[1]。目前,电子商务竞争愈发激烈,各大电子商务企业在推进业务增长的同时均在发展以客户为中心的企业战略,而如今企业发展新客户的成本越来越高甚至大幅超过用以维系老客户的成本,所以,如何有效精准识别潜在的客户流失对电商企业的长期战略发展有着举足轻重的意义。
目前国内外通常采用的客户流失预测研究主要有基于传统统计学方法的客户流失预测,如朱志勇等[2]利用贝叶斯分析客户流失特征,创建贝叶斯网络模型;张宇等[3]利用决策树算法,创建了所需的流失预测模型,并用中国邮政的业务数据对模型进行了验证;Arno De Caigny[4]将决策树与逻辑回归结合,为两阶段客户创建了相应的流失预测模型,但这两种方法较为简单,对于数据维度较高的问题不太适用。
近几年由于人工智能等技术的发展,利用机器学习、神经网络构建的客户流失预测模型,也取得了很大的进展。如Ruiyun 等[5]提出了一种优化的BP神经网络来预测电信公司流失客户。Yaya Xie[6]提出改进平衡随机森林算法的预测模型并将其应用于银行客户流失数据集,结果表示该方法效果更优。朱帮助等[7]提出了基于最小二乘SVM 的三阶段客户流失预测模型并验证了模型的有效性。王重仁[8]等通过把社交网络分析、XGBoost 两者结合起来,最终发现具有更好的效果。
以上基于人工智能和机器学习的算法虽然都能有效地提高客户流失的预测精准度,但是其研究所涉及领域与电商大数据领域的特点仍有一定差异。如今,在研究客户流失预测状况时,主要把契约型客户当作研究对象,其流失有着较为明确的标志。然而以电子商务客户为典型代表的非契约型客户与企业之间并不存在契约关系,企业无法准确观察到客户的流失时间点,因此该类客户的流失预测是现阶段研究的难点和重点。
本文基于多种模型和算法,开发了相应的客户流失预测方法,在最终的预测模型中还对预测过程中对电商领域对真阳性错误更敏感的情况进行了针对性的算法改进,使得方法和模型更加符合电商领域的使劲应用情境。
2 客户流失预测模型
图1 展示了模型的基本流程,该方法含有三个不同的模块,包括流失预测模型模块,客户细分模块、客户特征筛选模块。
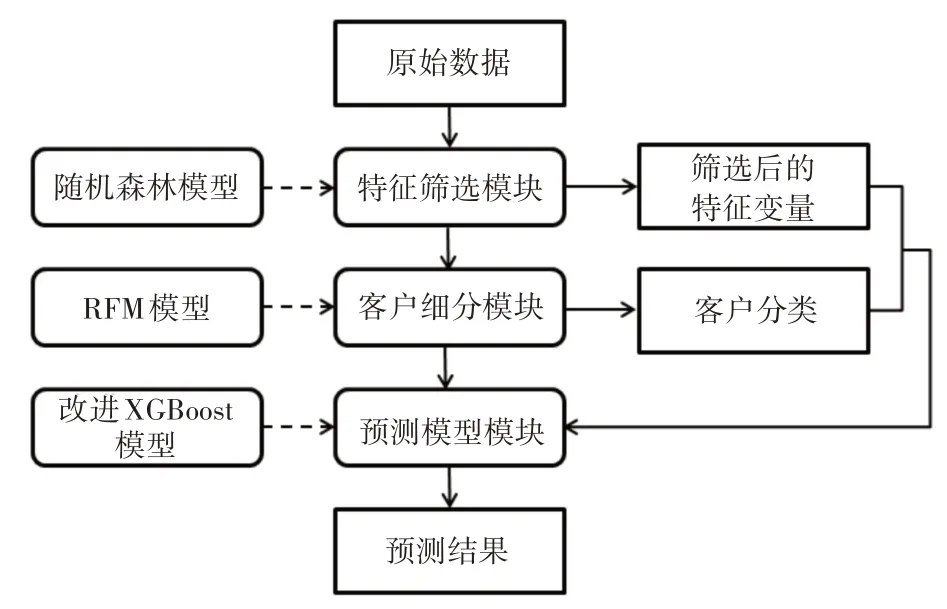
图1 预测方法流程图示
2.1 客户特征筛选模块
由于电子商务客户的特征数量较多且维度较高,在进行客户流失预测之前首先采用随机森林算法进行降维和特征筛选操作。随机森林算法通过计算数据误差来衡量特征的好坏程度,其中的数据误差来源自训练决策树时随机抽取的样本数据所带来的随机误差[9]。特征X 的重要性由式(1)计算得出。
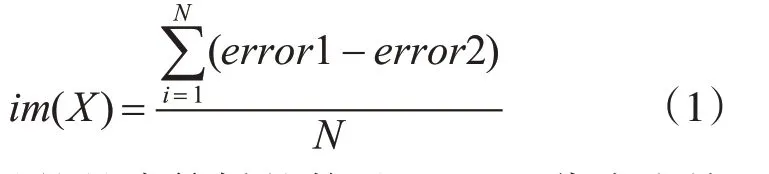
其中,N 表示的是决策树的数量。error1 代表去掉被抽取样本数据外的数据误差,error2 代表加入随机干扰后去掉被抽取样本数据外的数据误差。
对于原始数据集合首先使用Boot-Strapping随机采样方法来获取n 个数据样本集合。再对数据子集进行单独训练,变为树分类器,对于每一个树分类器,在实施分裂操作时,会需要按照信息增益情况,选择最佳的分裂特征[10]。随后每棵树继续分裂,直到所有的训练样本分为同一类结束,然后组合不同的决策树,形成随机森林,此时每个特征的影响程度也会被计算出来。最终选取影响程度高且其累计营销程度超过90%的特征进行流失客户预测。
2.2 客户细分模块
客户细分是指根据客户的某些特征来识别客户群体的方法,其中基于客户价值的细分是近年来较为常见且应用广泛的方法,其中,对于RFM 模型而言,是从众多交易数据中筛选出来的,可以有效地判断用户的价值,常被用于研究顾客忠诚度和活跃度[11]。
本文提出的客户细分模块是以RFM 客户价值模型为重要依据与分类基础,确定RFM 模型的三大指标,组成相应的数据集,然后通过K-means 方法,实施聚类操作,详细地划分电子商务客户的类型。主要指标如下所示,分别为Recency、Frequency、Monetary[12]。其中,R 代表的是最近购买与现在相距的时间,反映了用户活跃程度;F 代表的是某一阶段的购买频次,反映的是用户的忠诚度;M 代表的是某一阶段购买的总金额,反映了用户消费能力[13]。

图2 客户细分模块流程图
将通过RFM 模型确定的指标数据放入K-means聚类算法中得到一个收敛的聚类结果,对于K-means 算法,它是最常用的聚类算法,是一种划分为主的聚类算法[14]。最后对聚类结果进行分析并根据每一个客户类别显示出来的特点对聚类结果中的客户类别进行命名,最终对客户进行细分。
2.3 流失预测模型模块
根据电子商务领域的情境,将客户流失错分为非客户流失视为第一类错误。在此种情况下,企业不会挽留这部分客户,企业将会错失此类客户。而对于非客户流失,错误的看作是客户流失,这属于第二类错误,此时企业会对被错分为客户流失的客户采取相挽留措施,从而增加了企业的运营成本。然而,通过研究发现,与维持老客户相比,发展新客户所需的成本更高,所以在预测电子商务客户流失时,第一类错误能够导致更大的损失,远远超过了第二类错误。因此,通过分析电子商务客户流失预测发现,对真阳性错误更敏感。
XGBoost 算法在处理大数据集时能够保持较高的精度,其原理通过不断对误差进行进一步分类,来改善系统的训练准确率[15]。因此本文选择XGBoost 来构建流失客户预测模型。在处理分类问题时,XGBoost 一般把对数函数当作损失函数,见式(2)。本文基于电子商务的特殊情境,在XGBoost 算法的损失函数中,需要添加上惩罚系数α(0.5<α≤1),对上述两类错误的损失比例进行了调整,见式(3)。
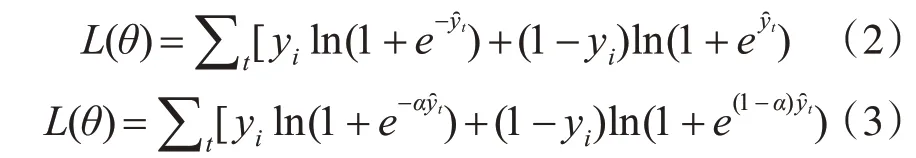
当样本yi=1 时,相应的损失函数为ln(1+e-αy^t) ,如果样本yi=0 时,那么损失函数为ln(1+e(1-α)y^t)。可见经过对损失函数的改进,发生一类错误的损失会高于二类错误损失,更加符合电子商务领域场景特征。经过多次实验,当惩罚系数α取0.6 时,AUC 值达到最优,因此预测模型中惩罚系数α取值为0.6。
3 预测模型验证与结果对比
本文采用国内某电子商务平台中4439 名客户在2018 年1 月至8 月产生的数据作为原始数据对提出的方法进行验证。通过准确率、召回率、ROC曲线、AUC值等指标,对其进行评价。
3.1 特征筛选结果
采用随进森林算法对上述数中21 个特征进行筛选,得到表1 中重要性程度较高的7 个特征,且这7 个变量对结果的解释贡献率达到了90%,因此选取这7 个特征变量作为最终输入预测模型的特征。
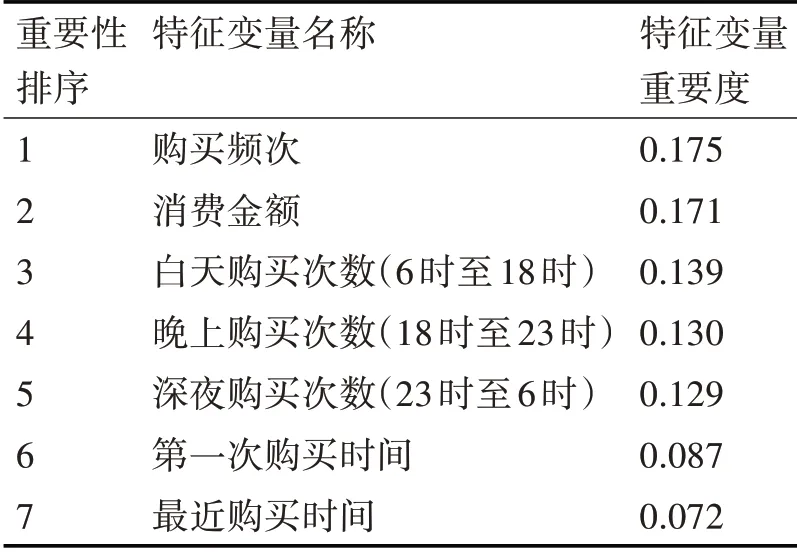
表1 特征变量重要性结果
3.2 客户细分结果
通过标准化等预处理操作之后,再通过K-means聚类算法,实施相应的聚类操作。经过反复试验,发现当类数K=3 时结果达到收敛,故最终结果将客户分为三类,最终聚类结果见表2。

表2 客户细分结果
对结果中的三类客户的三项指标分别进行描述统计后发现,第二类客户的R 指标均值最小为7.52,同时这类客户的F 指标与M 指标均值在三类客户中均为最大且远大于其他两类客户,即这类客户最后一次在该电子商务平台的购买时间距现在普遍较近而且他们的累计订单数与累计销售额远高于其他两类客户。可以认为这类客户经常在该平台消费且消费金额较大,可见此类客户对电子商务企业具有重要的价值,因此将聚类结果中的第二类客户定义为重要价值客户。
聚类结果中的第三类客户的R 指标均值最大为159.17,并且该类客户的F 指标与M 指标的均值远小于其他两类指标,即第三类客户最后一次在该电子商务平台的购买时间较现在较远且这类客户的累计订单数与累计消费金额较小,这就表示该类客户在该平台购买的频率较低且消费力度较小,该类用户更容易变成潜在的客户流失,因此需要企业针对他们开展相应的挽留措施,所以,在得出聚类结果之后,往往把第三类客户当作价值最低的客户。
聚类结果中的第一类客户的三项指标的均值均处于中等水平,这表示该类客户在活跃度、忠诚度以及消费能力上均处于三类客户的中间水平,因此,把这部分客户当作一般价值的客户。
3.3 XGBoost算法改进前后对比
算法改进前后预测结果的各项评价指标见表3,可知改进后的算法在各个指标上的表现均优于改进前的算法。
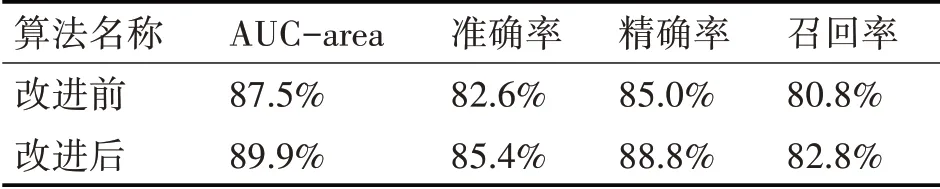
表3 XGBoost改进前后预测结果对比表
3.4 不同算法对比
这里选取了逻辑回归、支持向量机、BP 神经网络这三种常用的算法模型来与改进后的XGBoost算法进行对比分析,结果见表4。可以看出,除了召回率与其他算法存在较小差距之外,改进后的XGBoost 算法的预测结果在其余各项指标的表现均明显优于其他算法,即说明改进后的XGBoost 算法较其他算法来说在预测客户流失的效果上表现更好。

表4 各类算法预测结果对比表
3.5 客户细分前后对比
经过客户细分后再进行预测与用总体客户即不进行客户细分进行预测的结果对比见表5(均采用改进后的XGBoost 算法进行预测),可以看出经过客户细分后再进行预测时各个评价指标的结果均有明显上升,说明在预测前对客户进行细分能够有效提升价值客户的流失预测精度。
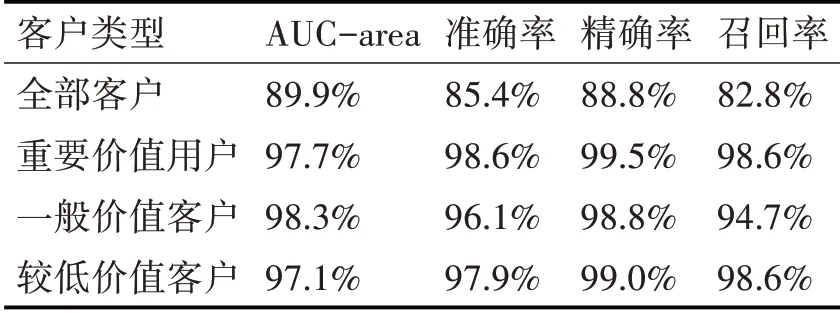
表5 客户细分前后预测结果对比
4 结语
研究结果表明经过预先进行客户细分能更有效地进行客户流失的预测,预测结果的各评级指标均有明显提升。同时,结合电子商务客户流失的特征,对损失函数作出一定的修正,改进后的XGBoost 算法的预测效果相比改进前也有更好的表现,预测结果AUC 值提高了2.4%,准确率提升了2.8%,精确率提升了3.8%,召回率提升了2%。由此可以说明,所提出的预测方法是行之有效的。
根据客户价值对电子商务客户进行了细分并预测了不同群体中的客户流失情况,但是现有研究主要基于结构化的客户数据,图片、音视频等其他类型的复杂数据并没有涉及,后续有待进一步深入研究。
