基于知识点的个性化试题推荐方法*
2022-06-16王启亮
王启亮 刘 镇
(江苏科技大学计算机学院 镇江 212003)
1 引言
2020 年,伴随着教育信息化由1.0 到2.0 升级步伐的加快,以虚拟现实、增强现实、人工智能、5G、区块链为代表的新一代信息技术及其教育应用无疑会引发更多关注[1]。
通常情况下,用户的学习成效一般都是通过对知识点的掌握情况来衡量的,知识点直接决定了用户是否掌握了当前知识点所表示的知识。怎样以高效合适的方式来评估一个用户的知识是一项艰巨的任务,鱼龙混杂的试题会不但浪费资源,而且对用户的学习时间造成不必要的浪费。然而,试题的关键在挑战在于如何使用合适的题目以及问题,来检测用户的相关能力。因此,在进行试题的设计时,应该在知识点的基本要求和延伸之间取得平衡。
2 模型框架
2.1 知识点实体抽取
给定输入句子X,即试题发布中的知识点要求,将三个元素信息(即字符、单词和字符的bi-gram)全部考虑在内。用{c1,c2,…,cn}表示X的字符序 列,{b1,b2,…,bn} 表示字符 的bi-gram 序列,其中bi=cici+1。使用中文分词器将X拆 分 为m 个 单 词,即{w1,w2,…,wm}[2]。计算三类元素信息表征为
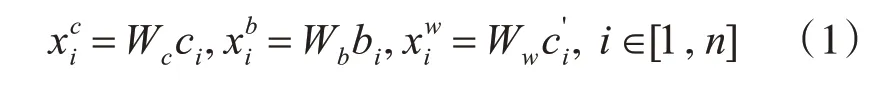
其中Wc、Wb、Ww是基于百度百科数据的预训练字符、字符bi-gram 和字向量矩阵初始化的。将字符和字符bi-gram 的表示连接起来,并使用完全连接的层来减少与相同的维度。然后使用一个门机制来动态地组合语义字符层和单词层的表示[3],如式(2)所示:
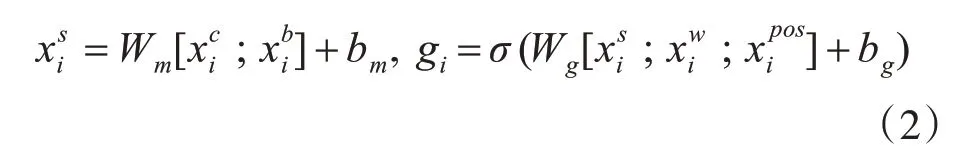
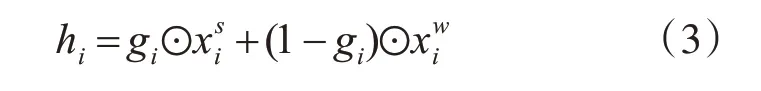
式中⊙表示按元素划分的结果,使用隐藏向量hi和POS 标记作为双向LSTM 层的输入,可以表示为
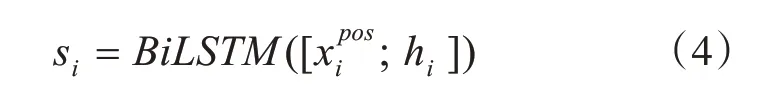
最后,将隐藏状态s={s1,s2,…,sn}作为标准CRF 层的输入,输出y={y1,y2,…,yn},其中yi∈{I,O,B,E,S}表示字符在技能实体的内部、外部、开始、结束或单个[4]。所以序列y的条件概率:
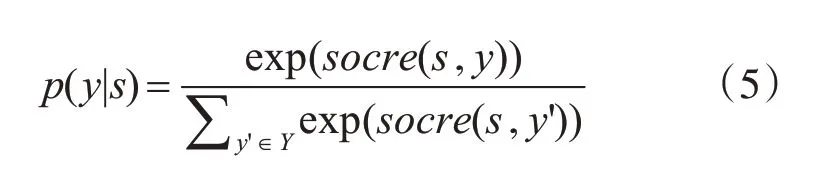
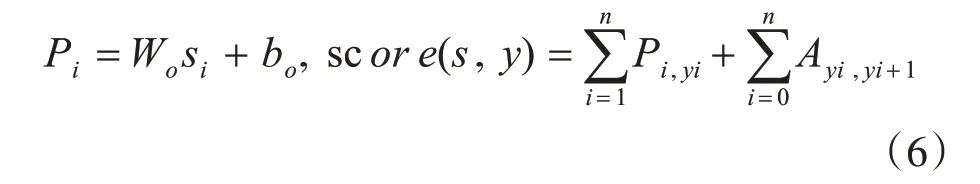
其中Y表示s的所有可能的标签序列,Pi,yi是用标签yi指定第i 个单词的分数,Ayi,yi+1表示从标签yi到yi+1的转换分数,Wo、bo是可训练参数。
2.2 知识点实体降噪
创建一个实体-URL 图G=(V,E)。节点集V包含两种节点,实体Ve和包含在这些实体的查询日志中的URLs 集合。边E的集合同样包括两个部分,即Eeu和Eee。Eeu⊂Ve×Vu是Ve中的点与它们在Ve,Vu中的相应URL集合之间的链接集。删除了在标记数据中同时连接了知识点实体和非知识点实体的URL 的边。用Weu∈Rpe×pu表示权重矩阵,对应的边集是Eee。
通过基于LP 的方法计算一个实体为知识点的概率。将y∈Rpe×2表示为实体标签。当实体被标记为知识点词时,设置对应的,非知识点词,则设置。计算如下两个归一化权重矩阵。
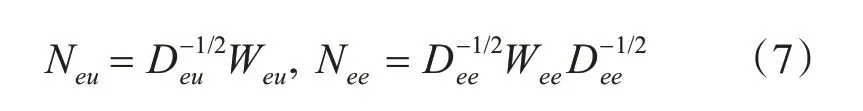
其中Deu和Dee是两个对角矩阵,其中每个元素为。然后,迭代地使用LP 来更新yeu,yee∈Rpe×2,分别表示Weu和Wee所获实体标签的得分。
2.3 试题推荐
给定试题J,将当前参加这套试题用户的个人信息表示为R={R1,R2,…,Rp},并且还利用用户的历史成绩表示为P={P1,P2,…,Pp},通过该试题的用户为S。将VJ,VRi和VS分别表示为J,Ri和S的知识点集合。将Ri和S中出现的知识点vk的数量分别计算为CRik和CSk,将 子 节 点(descendant(vk))表示为Gr 中知识点vk的所有后代节点集,而父节点(ancestor(vk))表示为其所有父节点集[6]。之后,可以根据历史成绩信息和应聘者的简历来衡量Gr 中每个知识点vk的权重。
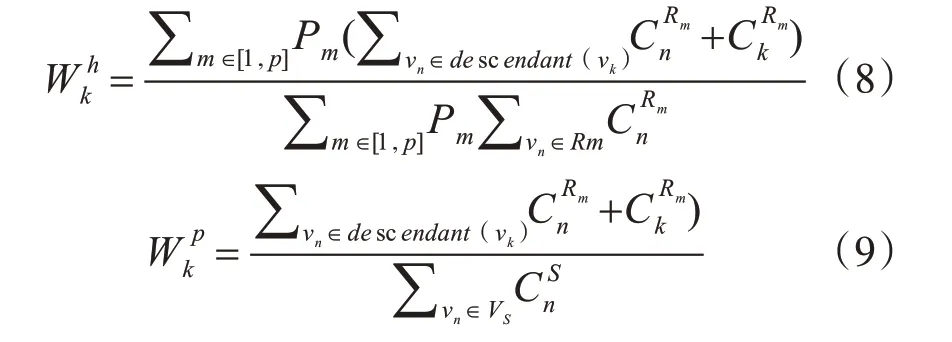
同时,将主要知识点集V'J定义为VJ中所有基本知识点的集合,即ancestor(vn)=∅}。还分别定义了VRi、VR和VS知识点集和VS'。
然后将VJ,VR和VS中的所有知识点分为匹配知识点、个性化知识点和非匹配知识点三部分,分别计算它们的权重[7]。此外,为了处理冷启动问题,还考虑了试题信息,但不出现在历史成绩数据或用户的个人信息中。知识点权重数学定义如下。
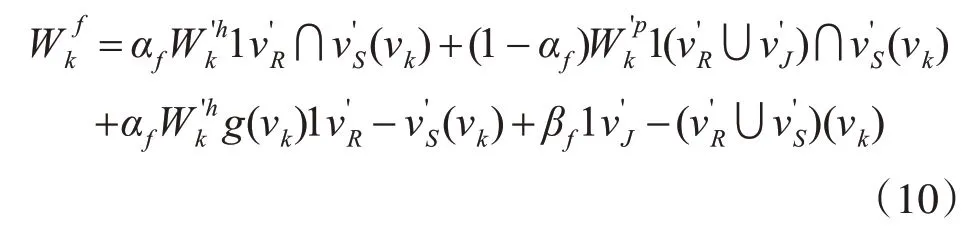
其中,通过函数g(vk)来移除用户没有的当前知识点。例如,假设历史试题数据表明,C++和PHP 的。如果用户喜欢C++,并且对C++感兴趣,将忽略PHP在历史试题数据中的权重。
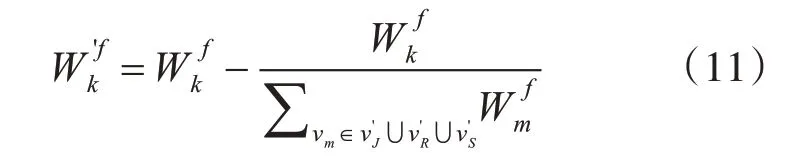


3 实验结果与分析
3.1 知识点实体抽取测试
通过一个历史试题数据集用于知识点实体提取,包括3605份试题和17931份用户历史试题。在2000 个的需求中手动标记了知识点实体句子和3700个试题。如表1所示,为试题申请数据集的统计信息。

表1 试题申请数据集的统计信息
使用Skipgram 模型对来自百度百科文本数据的字符,字符、单词和字符的bi-gram 进行了预训练。在知识点实体提取模型中,维度在BiLSTM 中的隐藏状态设置为300。同时也遵循了文献[8]中的思想初始化所有矩阵和向量参数。所有模型均采用Adam 算法进行优化。最后,为了验证模型的性能,选择几种模型作为基线方法,包括字符基线,即基于字符的BiLSTM CRF,它直接使用字符作为BiLSTM;字符基线中引入的信息包含单词和字符的bi-gram信息[9]。
试题发布和个人信息的整体表现数据集如表2 所示。可以看出使用的三类信息(字符、单词、字符bi-gram)对建模知识点实体抽取的有效性,以及门结构的有效性。
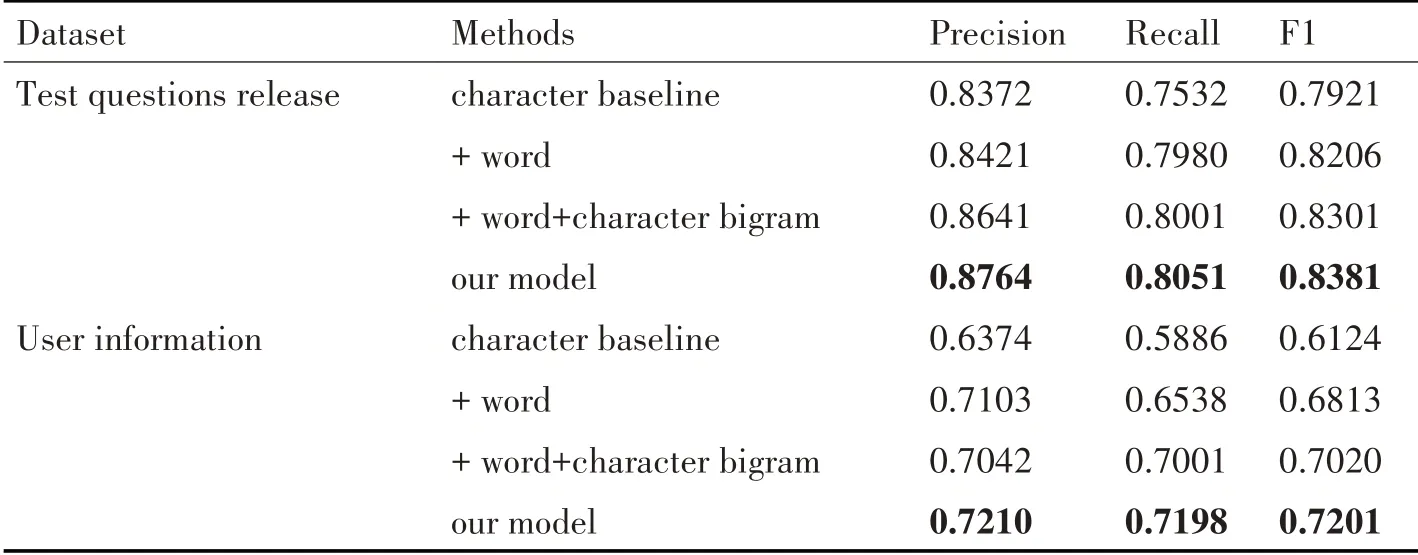
表2 知识点实体抽取结果
3.2 知识点实体降噪测试
通过收集2019年1月至6月之间的点击数据[10],将kt设置为20,以便为每个实体选择点击最多的URL 标题。将主题数nt设为100 训练LDA 模型Mt,将α设为0.5 计算高斯核矩阵S。然后,将ke设置为20,将kg设置为0.7,以在每两个实体节点之间的Eee中构造边。
模型和基准的性能如表3 所示。发现的模型没有Eee中的信息达到了0.97 的最高准确率,表明使用LP算法过滤知识点实体的有效性。实际在模型的变体中,缺少Eee导致20%测试集中的实体节点不连接任何URL,并且不能被它预测。因此,尽管它具有很高的精度,但是召回率仅为0.75。而且利用Eee在LP 算法可以预测所有实体标签并取得最佳性能与所有基准模型进行比较。虽然随机森林可以达到最佳召回率,其精度值没有竞争力。最后通过的LP 算法,总共获得了4,836 个知识点实体。
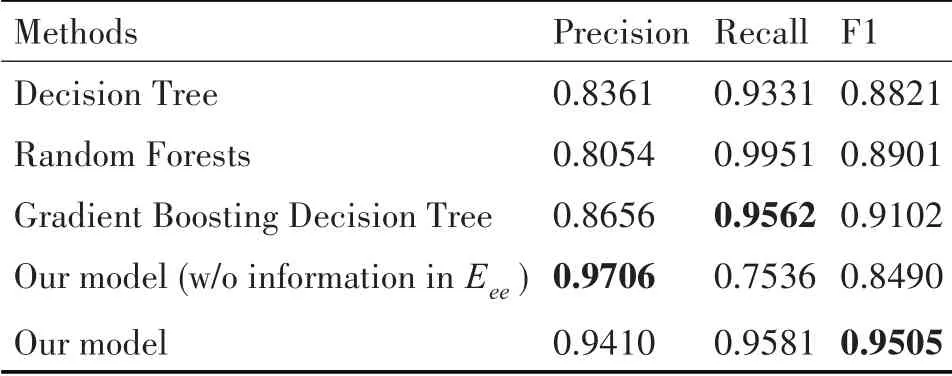
表3 知识点实体降噪效果
3.3 试题推荐测试
首先对上述数据集依照时间分为训练集和测试集对数据特征进行抽取,结果用onehot 热编码。通过GBDT 模型进行特征提取,用对梯度提升树中的树的最大深度参数进行设置。实验采取了ROC曲线[11]来作为很亮性能的主要指标,其中ROC 曲线横纵坐标分别代表了假正率FPR和真正率TPR,由在一系列阈值下FPR 和TPR 中的数值连接成的曲线。如图1 所示,为GBDT 的F1 分值与maxdepth参数之间的关系图。
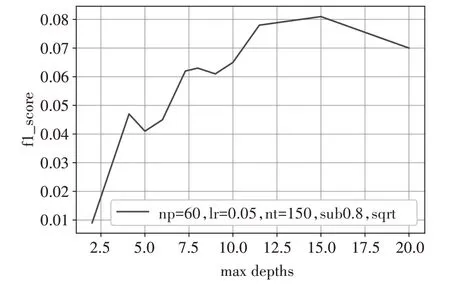
图1 F1与maxdepth参数的关系图
然后将GBDT 模型的输出作为LR 的特征进行处理,逻辑回归算法受到正负样本比例影响很大因此选取合适的最佳的正负样本比例对推荐的结果有较大的影响,如图2所示,为LR的F1分值与阈值参数NP ratio关系图。

图2 LR 的F1分值与NP ratio 关系
此外,逻辑回归算法由于使用的sigmoid 函数[12]进行分类,在不同的正负样本比例的情况下,其阈值参数cut_off 的最优值也不尽相同。阈值参数与F1 的关系如图4所示。

图3 LR 的F1与cut_off 关系
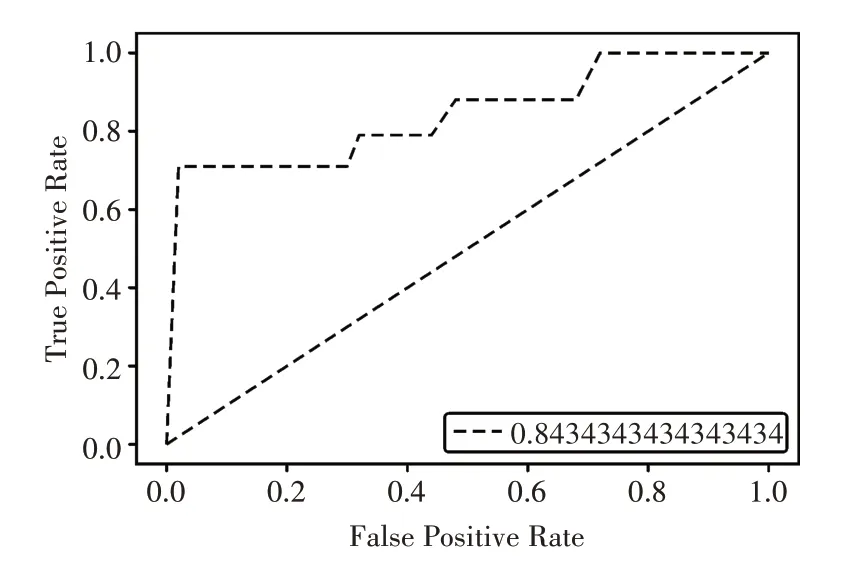
图4 GBDT 与LR 混合下的ROC 曲线图
最后经过通过混合模型可以进一步的提高推荐的性能,其ROC 曲线如图5所示。
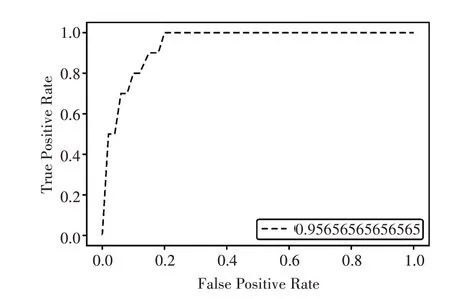
图5 混合模型框架下的ROC 曲线图
本文同时将算法与各类算法进行对比,如表4所示,通过实验结果可以看出,由于进行模拟测试时数据量较少,导致本算法与其他算法在准确性、召回率和F1 综合评价指标上差距较小,但在一定程度上还是体现了本文算法的优越性,加之之后互联网的海量数据,该算法的精度将愈发精确。

表4 各类算法对比
4 结语
本文介绍了一个种基于知识点个性化试题推荐系统,用于在线学习中的用户在线对当前知识点掌握情况的测试。该系统的关键思想是通过挖掘历史试题数据和从网络中获得的工作技能数据来构建知识点的知识图谱。具体来说,首先基于双向LSTM-CRF 神经网络设计了一种知识点实体提取方法。然后基于点击日志数据设计了标签传播方法,以提高提取的知识点实体的可靠性。此外,提出基于知识点实体之间的上位词-下位词关系,构建知识点图谱,并提出了一种启发式的个性化的试题推荐算法,以改善用户在线学习时的对知识点更加熟悉。最后,通过对比SETB 算法和TBTFIDF 算法体现了本问算法在一定程度上的优越性。
