融合上下文信息特征的小目标检测方法*
2022-06-16姚广华吴训成张雪翔
姚广华 吴训成 张雪翔 侍 俊
(1.上海工程技术大学机械与汽车工程学院 上海 201620)(2.32128部队 济南 250000)
1 引言
在目标检测领域,图片中小目标的分辨率和图像表观信息有限,检测小目标是一项具有挑战性的任务。小目标是指,目标尺寸的长宽是原图像尺寸的0.1。现有方法[1~4]已证明,通过利用上下文信息可以提高对小目标检测的精度。用于小目标检测的另一种常用方法是扩大小区域[5],扩大小区域也能够提高检测小目标的精度,但扩大小区域方法会显著增加计算量。
目前大多数研究都是基于区域的目标检测方法,包括SPP-Net[6],RCNN[7],Fast RCNN[8],Faster RCNN[9],这些目标检测方法由于存在大量的提议框,无法快速地检测到小目标。单点检测器SSD(Single Shot Multi-box Detector)[10]由于没有区域提取以及区域提取后的像素重采样阶段,检测速度很快,能够进行实时检测,但对于小目标的检测效果较差。反卷积单点检测器DSSD(the fast detector Single Shot Multi-box Detector)[4]使用SSD 作为基础网络,由于其通过使用基础残差网络Res-Net 101[11]来提高检测精度,而牺牲了速度。对于小目标检测,如何在精度与速度之间进行取舍,这仍然是有待解决的问题。
引入上下文信息的常用方法是利用卷积网络中的组合特征图进行预测。例如,ION[1]使用池化层从每个区域提议的多个层中提取VGG16[12]特征,并将提取的特征连接为固定大小的特征图谱以进 行 最 终 预 测。Hyper-Net[4]、GBD-Net[13]和AC-CNN[14]采用了类似的方法,即使用每个区域提议的组合特征图进行目标检测。这样每个区域提议的特征图都包含细粒度的局部特征和上下文信息。但是,这些方法都是基于区域提议的方法,基于区域提议的方法会产生大量的提议框,从而增加内存占用量并降低检测速度。
在本文中,为了实现对小目标快速而精确的检测这一目标,本文在检测精度与检测速度之间进行权衡取舍,提出了一种引入上下文特征融合的方法:在卷积网络中添加上下文信息,以提高小目标检测的准确性。具体来讲就是,使用一个特征融合模块来融合浅层特征,而深层特征并没有进行融合,这样能够保证检测器的实时性。并提出了一个融合模块,该融合模块使用1×1 卷积层来学习目标信息和上下文信息的融合权重,这样可以减少无用的背景噪声的干扰。
2 CF-Net模型
本节将详细阐述本文提出的融合上下文信息特征的小目标检测方法CF-Net,以及在CF-Net 模型中提出的用于特征融合的融合模块。
2.1 CF-Net模型整体架构
本文提出的CF-Net 模型如图1 所示。CF-Net使用了VGG16 作为底层网络,并将VGG16 中的两个全连接层(FC6、FC7)改成了一个卷积层用于预测通用目标。在VGG16 之后增加了4 个卷积层用于预测一般大小的目标。其中卷积块Conv1_x 和Conv2_x 包含2 个3×3 的卷积核;卷积块Conv4_x 和Conv5_x 包含3 个3×3 的卷积核;卷积块FC_x、Conv6_x、Conv7_x、Conv8_x、Conv9_x 分别包含一个1×1的卷积核和一个3×3的卷积核。
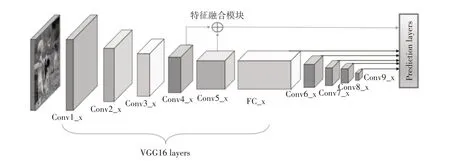
图1 CF-Net网络结构
CF-Net 采用了特征金之塔结构进行检测。即利用了由VGG16 的全连接层构成的卷积块(FC_x)和另外增加的4 个卷积块,一共5 个卷积块的输出FC_2、Conv6_2、Conv7_2、Conv8_2、Conv9_2,进行分类和回归用于检测通用目标。由于浅层特征包含了丰富的小目标信息,故利用VGG16 中的浅层卷积块Conv4_x 和Conv5_x 的输出层Conv4_3 和Conv5_3,并对其进行特征融合,将融合后的特征图进行小目标检测。对于检测用的特征图,CF-Net分别用两个3×3 的卷积核进行卷积,一个用于输出分类用的置信度(confidence);另一个用于输出回归用的定位坐标(localization)。
在检测问题中,由于输入图像包含多个目标,需要对多个目标进行特征提取。因此,CF-Net 对每个输出特征图加入了候选框,然后对候选框进行分类和回归。候选框的设计与SSD 的候选框类似。对于用于预测的特征图上的每个单元格,设计了不同尺寸候选框。候选框尺寸大小计算见式(1)。其中对用于通用目标检测的输出特征图FC_2、Conv6_2、Conv7_2、Conv8_2、Conv9_2,smin和smax分别取0.2 和0.9;对用于小目标检测的融合特征图,由于小目标尺度较小,因此将最底层尺度设置为0.1,最高层尺度设置为0.85,故对用于小目标检测的融合特征层,smin和smax分别取0.1 和0.85;m为特征层数。考虑到计算量,本文中将每个单元格中候选框的数量设置为6 个。每个候选框的长度和宽度计算方法分别见式(2)和式(3),其中用ar={1 ,2,3,12,13} 表 示 候 选 框 的 长 宽 比,当ar=1时增加了一种候选框尺寸:。
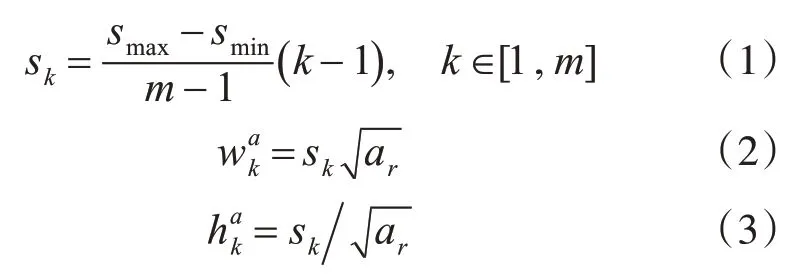
CF-Net 不使用卷积网络的最后一个特征图,而是使用卷积网络内的金字塔特征层次结构来预测具有不同尺寸的目标。即使用较浅的特征层来预测较小的目标,而使用较深的特征层来预测较大的目标,因此可以减轻整个模型的预测负担。但是,较浅的特征层通常缺少语义信息,而语义信息有利于小目标检测。因此,本文通过将高层特征与浅层特征融合,使在卷积正向计算中捕获的语义信息传递回较浅的特征层。通过特征融合,浅层特征既包含小目标信息又包含语义信息,使得浅层检测小目标的性能得到了提高。
2.2 CF-Net中的融合模块
本文利用浅层特征预测小目标,因此将特征融合模块应用于浅层网络,而不用于深层网络,这种策略保证了CF-Net 检测速度。为了选择合适的特征层进行特征融合,本文使用反卷积方法探索了不同层中的有效感受野。最终选择了Conv4_3 和Conv5_3 进行融合。为了将上下文信息注入缺少语义信息的浅层特征层(Conv4_3)中,本文设计了一个特征融合模块。
特征融合模块如图2 所示。为了使特征层Conv5_3 的尺寸大小与特征层Conv4_3 相同,在特征层Conv5_3 之后设计了一个反卷积层,该层利用双线性上采样进行初始化,即将Conv5_3 上采样扩大为原特征图的2 倍,得到了与Conv4_3 尺寸大小相同的特征图。为了得到更好的特征,在Conv4_3层和Conv5_3层反卷积之后分别使用一个3×3卷积层进行特征提取,然后加入归一化层,并沿其通道进行轴向连接组合,得到了Fusion_conv43_conv53,最后经过1×1 卷积降维以及Relu 运算得到最终的融合特征图Fusion。
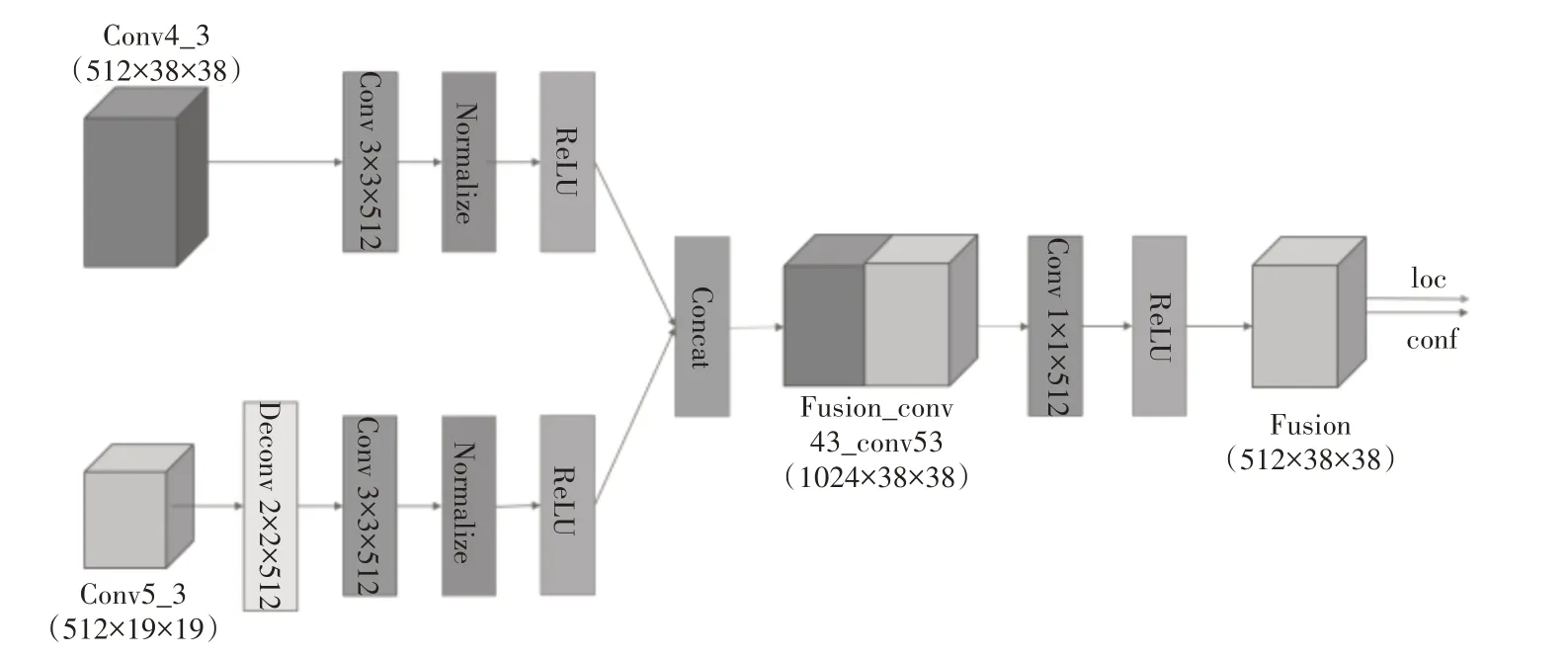
图2 融合模块
特征图Fusion 是Conv4_3 和Conv5_3 的产物,其分辨率与Conv4_3 完全一样,但是具有更丰富的语义信息,所以用特征图Fusion 进行分类和回归,能得到更好的检测效果。
2.3 损失函数
CF-Net 模型在训练过程中总损失函数L(x,c,l,g)由分类损失函数Lconf(x,c)和定位损失函数Lloc(x,l,g)二部分组成[16],如式(4)所示。分类损失函数使用了soft-max 损失函数,如式(5)和式(6)所示。定位损失函数的计算方式与Fast-RCNN 中的smooth L1 loss 类似,如式(7)和式(8)所示。
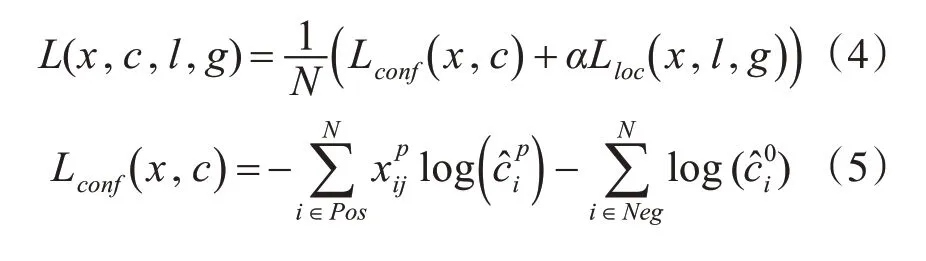
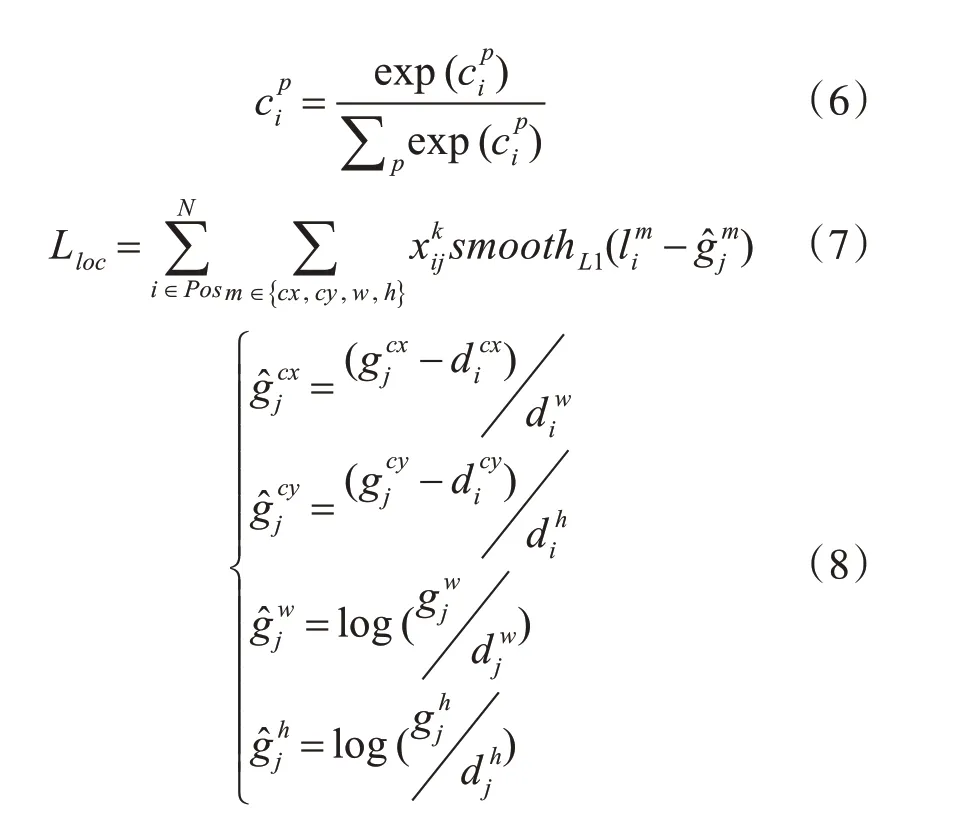
3 实验结果
在PASCAL VOC 2007 上对CF-Net 模型进行了评估,并将检测结果与SSD 和DSSD 进行对比。此外,本文给出了CF-Net 模型对小目标检测的性能评估,并进行了比较分析。最后给出了CF-Net模型的测试速度。
3.1 实验步骤
CF-Net模型是基于构建在深度学习框架Caffe[17]上的VGG16 实现的。首先在ImageNet 数据集上对本文模型进行预训练以完成图像分类任务。图片输入大小为300×300。训练过程中前8×103次迭代的学习率设置为10-3,迭代次数在8×103到1.2×103之间时学习率设置为10-4,迭代次数在1.2×103到1.4×103时学习率设置为10-5。然后将CF-Net模型用PASCAL VOC2007数据集进行训练。CF-Net在预训练好的模型上进行微调,并进行了一万次迭代。
3.2 检测结果
在设计最有效的特征融合模块时,本文做了一些必要的尝试。如表1 所示,本文尝试了不同特征层之间的融合,在PASCAL VOC 2007 数据集上都获得了不错的检测精度。本文选择了检测精度最好的组合方式Conv4_3+Conv5_3 进行融合。此外,在设计模块时,尝试了不同数量的内核。从表2 中可以看出,本文提出的CF-Net 模型在不同内核数量的情况下均表现良好,即使内核数量减少到128个,检测精度也令人满意。

表2 不同内核检测精度
在表3 中,展现了CF-Net 模型的检测性能。对于小目标检测,CF-Net 在固态硬盘上测试时的mAP 达到了78.9,比SSD 高1.7%。此外,从表中还可以看出在精度方面CF-Net 模型略胜于DSSD 321,高出0.3%。小目标检测结果如图3 所示。对比分析发现具有特定背景的小目标的检测精度得到有效提高,例如公路上的小型汽车,坐在帆船上的人的检出率相对较高。
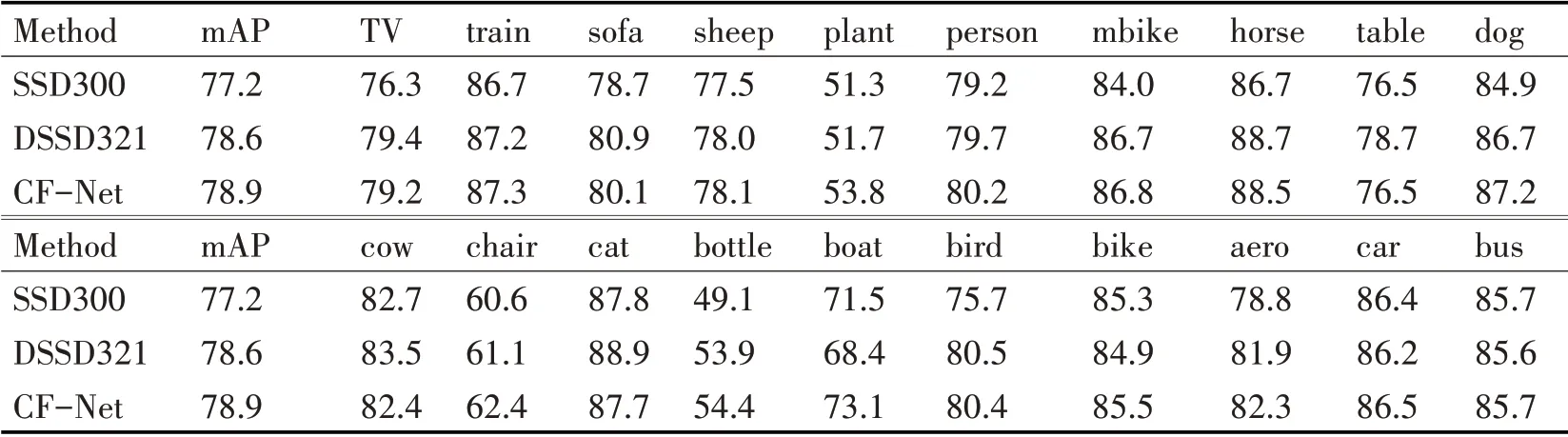
表3 PASCAL VOC2007数据集上测试结果

图3 检测结果
3.3 检测时间分析
本文在PASCAL VOC 2007 测试数据集上对CF-Net模型进行运行时间评估,如表4所示。本文提出的模型的检测速度为40 fps,比SSD模型要慢,因为模型增加了特征融合模块。但是,本文提出的模型仍然可以实现实时检测。与具有13.6 fps 的DSSD321 相比,CF-Net 模型可获得更快的检测速度,而且检测精度与DSSD321 模型相当。由于DSSD321 使用Residual-101 网络作为基础网络,而CF-Net方法是使用VGG16,故CF-Net模型检测速度要远远快于DSSD321。
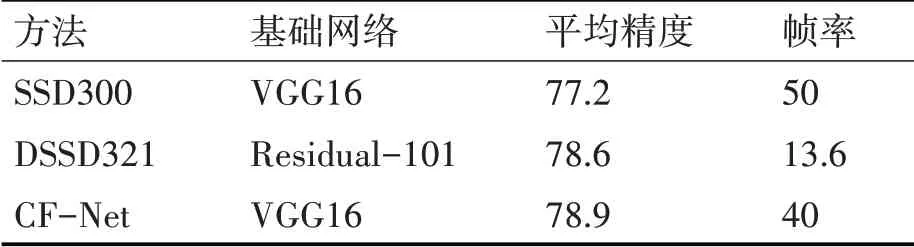
表4 不同方法的检测性能分析
4 结语
本文提出了一种引入上下文信息特征融合的CF-Net 模型,可快速准确地检测出小目标。CF-Net 将包含小目标信息的浅层特征层进行融合,用于检测小目标。而深层特征直接用于通用目标检测,不进行特征融合。与用于小目标检测的DSSD321等现有的小目标检测方法相比,具有检测速度快、检测精度高等优点。由于上下文信息有时可能会引入无用的背景噪声,因此控制信息传输是接下来需要进一步研究的工作。
