一种基于关联数据的科技项目查重系统*
2022-06-16李善青安淑荻邢晓昭
李善青 安淑荻 邢晓昭
(中国科学技术信息研究所 北京 100038)
1 引言
科技项目的重复申报是指同一个团队向不同的科技计划申报了多个研究内容相似而又处于同一研发阶段的项目。这是一种典型的科研不端行为,不仅会造成国家科研经费的浪费,而且会破坏公平竞争的科研氛围,已经成为我国科技事业健康发展的阻碍因素。国家高度重视科技项目的重复立项问题,于2014 年12 月正式启动了中央财政科技计划(专项、基金等)管理改革,将中央各部门管理的科技计划(专项、基金等)整合形成新五类科技计划(专项、基金等),并全部纳入统一的国家科技管理平台管理,加强项目查重,解决分散重复和封闭低效等问题。随着国家科技管理信息系统公共服务平台的开通运行,我国实现了新五类科技计划项目的集中统一管理,初步解决了科技资源配置的“碎片化”问题,为解决科技项目的重复立项问题奠定了基础。
在大数据的时代背景下,利用文本挖掘算法从项目申请书中抽取特征向量构建相似度判别模型的科技项目查重方法逐步成为领域内学者们的共识,涉及的相关技术包括文本分词[1]、关键词抽取[2]、向量空间模型[3]和文档检索[4]等。刘如等[5]较为系统地对我国科技项目查重研究现状以及国内外查重相关技术的发展态势进行了梳理和总结。张新民等[6]通过梳理科技项目查重的研究现状,分析了国家科技信息管理平台的典型特征、功能需求、体系结构和工作流程。
国内的学者利用文本挖掘方法开展了一系列的科技项目查重的应用研究[7~16]。赵晓平等[7]将文本的结构特征和TF-IDF 方法进行融合,提出了一种面向科技项目文本的相似度度量方法。左川[8]通过CHARM 算法挖掘后缀树节点的频繁闭项集作为科技项目申请书的特征点,构建向量空间模型计算科技项目申请书的相似度。鞠丽娟[9]采用最长回溯分词算法进行中文句子的分词,并基于N-gram 的向量空间模型构建了项目申报书正文的相似度算法。方延风[10]利用词的长度和位置等信息对TF-IDF 算法进行改进,提升了特征词抽取的准确性,并构建向量空间模型描述科技项目的内容。刘红娜[11]提出一种改进的基于词序列频率有向网的未登录词识别方法,并基于向量空间和图模型构建了申请书的相似度判别模型。吴燕[12]提出一种基于层次聚类的科技项目分类模型,通过计算关键词词频向量的相似度作为聚类依据,采用层次聚类算法在不同的粒度下逐层聚类,从而实现项目分类。赵士杰[13]提出一种结合物元知识表示模型和向量空间模型的科技项目知识表示模型,利用编辑距离计算项目标题的相似度,融合向量空间模型的语义相似度计算科技项目的综合相似度。黄思颖等[14]提出了一种基于SolrCloud 的分布式科技项目查重系统,采用标题段落语句模型计算项目申报书文本的相似度。杨晓瑜[15]提出了一种基于多暹罗网络的文本匹配模型,根据词语的上下文信息、位置信息与实体关系信息对其进行词嵌入处理,并通过权值共享的BiLSTM 模型挖掘文本的深层语义特征,从而评估文本的语义匹配性。这些研究工作都是以项目申报书为研究对象,提取词频特征建立申报书文本的向量空间模型,并将特征向量的相似度定义为项目申报书的内容相似度。这些方法的局限性主要体现在两个方面:1)完全依赖于项目申报书的文本内容,未考虑与项目密切相关的其他文献信息。2)从申报书文本建立向量空间模型是一个空间降维的过程,损失的信息会降低科技项目查重的准确性。
针对上述存在的问题,通过整合与项目密切关联的公开信息,建立科技项目的综合描述模型,利用大数据挖掘等方法实现科技项目查重是一种可行的解决方案。国家科技报告服务系统和国家科技成果转化项目库等平台相继开通运行,对公众开放共享科技报告和科技成果等信息,使得利用关联数据和大数据技术解决科技项目查重的方法成为可能。本文将重点介绍一种基于关联数据的科技项目查重系统,整合与科技项目密切相关的科技论文、科技报告和科技成果等信息,建立科技项目的描述模型。采用改进的TextRank 算法从摘要和标题等短文本中抽取关键词构建特征向量,并给出了项目相似度的判别方法。利用Hadoop 和Spark 的分布式计算框架,实现项目查重系统并进行相关的实验。该系统为解决项目查重问题提供了一种新的方案,是对现有项目查重方法的拓展,具有急迫的现实需求和广阔的应用前景。
2 系统架构
基于关联数据的科技项目查重系统的架构如图1 所示。系统大致可按模块划分如下:输入输出模块、特征词抽取模块、领域词系统模块、数据管理模块和相似度判别模块等。其中,输入输出模块负责将用户的输入信息提交到服务器端,提交的信息包括项目标题、关键词、摘要、承担人和承担单位等;并将项目查重的结果在浏览器端以直观的方式展示给用户。特征词抽取模块负责从输入的标题和摘要文本中抽取出特征词,在抽取的过程中会用到关键词词典和词频统计文件。领域词系统模块负责将一义多词的特征词标准化为统一的特征词。数据管理模块负责科技项目大数据的存储、管理和调度,负责为特征词抽取模块提供关键词词典和词频统计表,为相似度判别模块提供海量项目的特征词向量。相似度判别模块负责计算待查项目与海量存档项目的相似度,并利用Hadoop 和Spark框架对相似度判别算法进行的分布式处理,以提升项目查重的速度。相似度判别首先计算项目内容方面的相似度,然后综合考虑承担人和承担单位的因素,对项目的相似度进行综合判别,得到最终的判别结果。需要指出的是,重复项目的判定是一个复杂的过程,需要综合的背景知识和较高的判断力,因此系统计算得到的判别结果仅提供疑似重复项目的清单和客观的证据材料,最终将由专家小组做出是否为重复项目的判定结果。
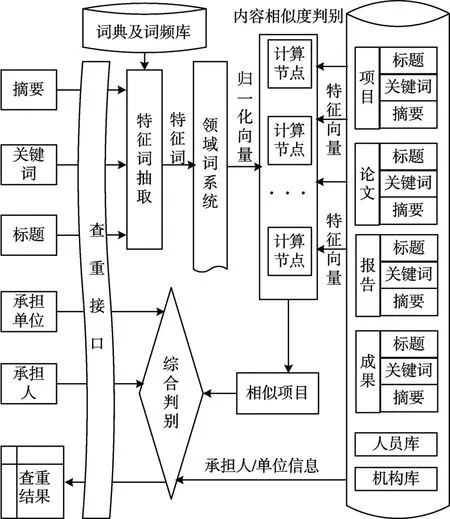
图1 科技项目查重系统的架构示意图
3 描述模型
本文采用整合多来源信息描述项目研究内容的数据模型[16],利用科技项目、科技论文、科技报告和科技成果的文本信息中抽取关键词并构建特征向量,从不同维度描述项目的研究内容。以项目信息为例,采集的数据中包含项目的标题、关键词和摘要等字段信息,利用改进的TextRank算法获取能表征项目研究内容的特征词,通过大量语料信息计算成词概率以反映短语结合的紧密程度,排除短语中不相关的成分,从而保证所抽取特征词的准确性和语义表达能力。此外,利用构建的领域词系统,解决一义多词的问题,将抽取的关键词进行标准化处理。统计关键词在语料库中的TFIDF 值作为其权重,最终得到特征词向量V1={(Ki,Wi)|i=1,2,…,N},其中,Ki表示第i个特征词,Wi表示第i个特征词的权重,N表示所采用特征词的个数。按照相同的方法,可以得到论文信息、报告信息和成果信息的特征词向量,分别表示为V2、V3、V4。因此,项目研究内容的描述模型可表示为式(1):
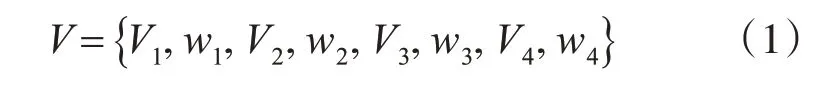
其中,{wi|i∈[1 ,4] }表示不同来源信息的权重,用于反映来源信息对描述项目内容的重要程度。考虑到不同形式的产出物与项目关联的紧密程度存在差异性,科技项目和科技报告是对项目研究内容的规划和总结,将其设置为较高的权重;科技论文和科技成果只是科技项目的部分产出,将其设置为较低的权重。
4 相似度判别算法
由于特征词抽取算法的准确性、特征词长度标准不一致和抽取的关键词数量限制等因素,从文本转化为特征词的过程中不可避免的存在信息丢失问题,从而导致项目查重的准确性降低。本项目不对语料库中的文本进行特征词抽取的预处理,而是在去掉非中文字符和停用词后将其拆分成长度为2~8字的短语,短语之间用符号“/”分隔。在实际计算项目相似度时,根据输入的待查询的特征词向量,从预处理的文件中构建与查询向量维度匹配的特征词向量,并计算两者之间的相似度。该方法在提升科技项目查重准确性的同时也导致了较高的计算复杂度。为应对上述的大量计算,我们构建由5 台计算机组成的集群计算环境,借助Spark 框架管理和优化计算资源的配置,快速完成项目相似度的计算过程。
考虑到重复性项目通常具有相同的负责人或者承担单位,我们引入两个校正因子用于体现上述因素的影响,并定义项目的相似度为式(2):
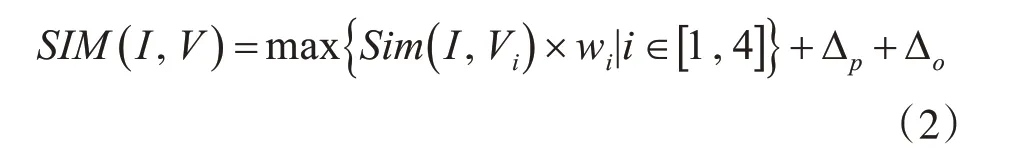
其中,Sim(·)表示相似度函数,I为从输入的检索信息中抽取的描述项目内容的特征向量,V为待判定项目的描述向量,max(·)为最大值函数,表示从四个信息来源中选取相似度的最大值,Δp表示因相同负责人而引入的校正因子,Δo表示因相同承担单位而引入的校正因子。由于科技项目、科技报告、科技论文和科技成果等信息可能存在缺失的情况,因此分别按照四类资源分别计算相似度,并取相似度最高的结果作为项目研究内容相似度的判别结果。通过引入校正因子,可以保证在项目内容相似度一致的情况下,优先筛选出具有相同负责人或者相同承担单位的项目。经上述计算后,可得到待查重的项目与全部已有项目的相似度,选取超出阈值的项目作为疑似重复项目的候选集,由专家做出最终的判定结果。
5 实验结果
本文基于Spark分布式计算框架实现了科技项目查重系统,如图2 所示。该系统包括主控节点、计算节点和交换机等三部分。主控节点主要负责计算任务的协调和调度,收集计算节点的状态信息,为计算节点分配任务,汇总计算结果并将其反馈给用户。计算节点负责完成具体的计算任务,为任务分配必需的硬件资源,与主控节点或其他节点通信获取必要的数据。主控节点和计算节点之间通过千兆交换机连接,可进行任务指令和中间数据的交换及传递。我们针对电动汽车领域对上述系统进行个性化配置。首先对大数据文件中的科技资源进行检索,筛选出与电动汽车相关的资源信息。其次,利用上述资源信息分别构建了电动汽车领域的关键词词典、词频统计文件和领域词系统。前两个文件主要用于增强特征词抽取的准确性,而领域词系统用于处理电动汽车领域内异名同义词语之间的关系,将其标准化为领域内的统一词语。

图2 项目查重原型系统的示意图
为验证关键词抽取算法的有效性,我们使用4272 份国家自然科学基金管理学部的项目信息构建测试样本集,采用准确率、召回率和F 值作为算法的评价指标。其中,随机选取200 份摘要作为测试用例,已标注的关键词作为正例样本;剩余的作为语料,用于计算候选特征词的成词概率。本文选定词语共现窗口大小为5 和成词概率阈值为1.00%,与TFIDF 算法和TextRank 算法的抽取结果进行对比实验。结果如表1 所示,本文算法在准确率、召回率和F 值均优于传统的TextRank 算法和TFIDF 算法,验证了关键词抽取算法在从科技摘要短文本抽取特征词的有效性。

表1 关键词抽取算法的对比结果
为验证个性化配置后的项目查重系统的性能,我们从电动汽车项目的信息中抽取150 份结题摘要作为测试集,与项目的立项摘要、论文摘要和成果摘要等约2 万条数据进行重复性检测,测试了不同阈值下算法的准确率、召回率和F 值等性能指标,结果如表2 所示。结果表明,随着阈值的增加,算法的准确率呈现不断提升的趋势,同时召回率则呈现不断下降的趋势。当选取阈值为0.4 时,F 值取得最大值,准确率和召回率分别为93.75%和90.00%。该结果基本可以满足科技项目查重的实际需求。
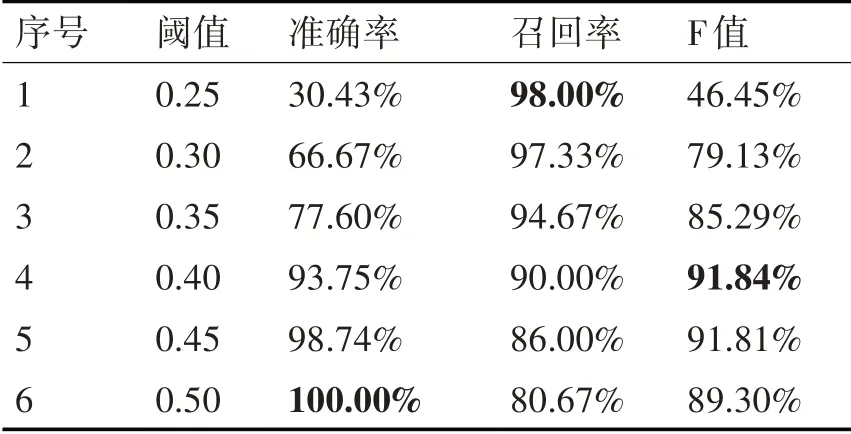
表2 不同阈值下算法的查重结果
为验证分布式计算对科技项目查重的加速作用,本文以1 个计算节点所需的时间作为基准,不断增加计算节点的数量,测定完成相同任务所需的时间,进而计算其加速效果。实验结果如图3 中的实线所示(虚线为理想条件下可取得的线性加速效果),2 个计算节点的加速比为1.19,3 个节点的加速比为1.43,4 个计算节点的加速比为2.34。可以看出,随着计算节点数量的增加,加速效果得到不断提升,但距离理想的加速效果还存在一定的差距。原因之一是计算节点之间的通信和数据交换需消耗一定的时间和资源。此外,多个并行任务的计算复杂度存在差异,会导致任务之间的等待,也会增加运行时间。后续可进一步优化程序设计,以取得更好的加速效果。
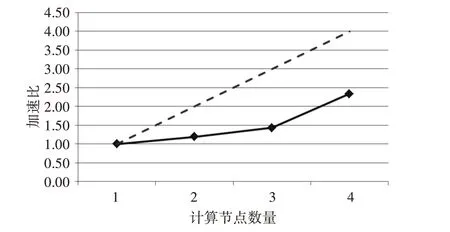
图3 分布式加速的实验结果
6 结语
本文提出了一种基于关联数据的科技项目查重系统。整合与科技项目密切相关的科技论文、科技报告和科技成果等信息,建立科技项目的综合描述模型,在一定程度上解决了项目查重的数据来源单一的问题。采用改进的TextRank 算法从摘要和标题等短文本中抽取关键词构建特征向量,并给出了项目相似度的判别方法。利用Hadoop 和Spark的分布式计算框架,实现了项目查重系统并进行了相关的实验。结果证明了该方法的有效性和可行性,在给定的实验条件下取得了较高的准确率和召回率。本文为解决项目查重问题提供了一种全新的思路和方法,是对现有项目查重方法的拓展和补充,为科技主管部门开发和部署科技项目查重系统提供了经验和借鉴。
