大湾区多语种政府新闻标注语料库建设研究
2022-06-15姜嬴杨静朱哲宇林佳莹
姜嬴,杨静,朱哲宇,林佳莹
(北京师范大学珠海分校,广东珠海 519000)
1 大湾区多语种语料库研究必要性
目前,粤港澳大湾区已经存在一些语料库,如“香港儿童粤语语料库”系统地记录了8 个幼儿在一年内学习和使用粤语情况,最终整理出177 个档案,存储记录14 兆字节[1];“香港粤语语料库”通过收集日常谈话,针对性地提供给研究者和语言学习者一个反应真实演讲和对话内容的粤语语料库[2];“LIVAC 共时语料库”语料来源于上海、港、澳、台,以及新加坡5 地的报纸资料,已处理逾5.7 亿字,累积并持续提炼出二百多万词条。
大湾区现存语料库多建立于20世纪90年代,部分语料库在取材上、时间维度上,存在滞后现象且语种选取较为单一,无法胜任多语种研究的任务。粤港澳大湾区及其辐射区域存在多种语言文字,构成了语言种类复杂多样性、语言分布分层交织性、对外关系复杂性等问题,是中国从古代到现代语言文字多样性最发达,使用量最多,同时共存时间最长的地区[3],这些问题都需要多语种语料库的支持。
普通话、粤语、英语为大湾区语言使用层次第一的3 个语种,覆盖了大湾区绝大多数的地区和人口。葡萄牙语使用层次位于第3,被认定为澳门地区的官方语言,具有一定代表性[4]。因此,该文选取这4 个语种作为主要研究对象,采集高度规范化的政府新闻语料,并结合标注语料库数据,尝试为语言研究者提供多语种语料库研究的思路。
2 研究内容及方法
该文根据研究过往的标注经验,分析多语种分词标注任务中存在的差异,提出符合多语种语料库的通用分词标注策略,基于项目研究过程中已经搭建好的在线众包标注平台收集人工检验的标注结果,对标注结果进行交叉检验,提炼出粤港澳地区新闻多语种语料库,基于编程技术训练分词模型并进行交叉验证,评测标注策略是否符合实际生产要求,根据实验结果整理出多语种标注规范,提出在研究多语种问题上的建议,为湾区的自然语言研究者提供基础条件和便利,促进大湾区文化、教育事业发展。
3 数据来源
该研究的普通话文本来自香港律政司、行政长官2018年施政报告、香港政府一站通、政府账目及报告、香港特别行政区政府新闻公报、中国文化报、大公报,粤语文本来自明报OL,英语文本来自South China Morning Post,葡萄牙语文本来自Revista Macau。以上均为粤港澳地区权威且文本数量较多的新闻网站,总共包含12 个新闻网站,其中有“国际”“两岸”“中国”等50 多个板块。自2019年3月开始持续开展标注工作,已收集大量数据,具体规模在6.1 节可见。
4 多语种分词标注异同
粤港澳大湾区的语言文字生态样貌较为独特,语言文字资源也较为丰富,汉语普通话、英语、葡萄牙语在不同区域都具有法定语言的地位,粤语、客家方言、闽方言等多种汉语方言在日常生活中也拥有广泛的民众基础[5]。不同的语言文字在分词上的规则和难度是不同的,下文举例说明多语种分词标注时需要注意的地方。
4.1 是否有分隔符
现代英语、葡语的基本语素表达形式是词,文本中的词天然由空格分开,分词时主要运用的是正则表达式和专家提供的词库分词。普通话、粤语文本的基本组成单位并不是词而是字,计算机可以轻而易举地对字进行切分,但词与词之间的切割则极为困难,主要是因为中文词语在句中存在互相重叠的情况,这很容易产生歧义字段,以“不过度开发生物资源”一句为例,进行完全切分的结果如下。
[不,不过,过,过度,度,开,开发,发,发生,生,生物,物,物资,资,资源,源]
完全切分并不是严格意义上的分词,它输出句中所有出现在词表中的字和词。因为中文词语存在类似“不过”和“过度”交集现象,9 个字被切分成了长度为16 的序列。粤语属于汉藏语系汉语族汉语方言,文本结构与普通话类似,同样没有分隔符做切分,这无疑增加了中文分词的难度。
4.2 是否有词语形态变换
对英文和葡语预处理时需要做词干提取和词性还原,而中文或者粤语则不需要。英文存在词形变换,例如,动词do 需要根据时态的不同变换为does、doing、did、done,do homework 和doing homework 本质上是一样的,但对于计算机来说是完全不同的两个字符串。
葡语的名词和形容词存在“阳性”和“阴性”的区别,tempo、sol 为阳性,canção、lua 为阴性。普通话中的“好”在葡语中既可以是bom 也可以是boa,但这实际上这种区别无法被消除,因为词的“阴阳性”是互相独立的,并不会有“原型”或者“词根”一说,也就没有办法降维。对分词来说需要注意的是葡语动词需要根据人称变化发生对应的变形,即“变位”,例如,estudar 根据主语的不同需要转换为estudas、estudo、estuda、estudamos 或estudam,而它们的原型是相同的。
4.3 是否需要考虑颗粒度
在通常情况下对于普通话和粤语分词来说切分颗粒度越大,结果也就越精确,但与此同时召回率低和歧义切分问题也必然会随之出现。在实际环境,例如搜索引擎中,当用户希望获取有关“自然语言处理”的内容时,若将其拆分为“自然”“语言”“处理”,那么颗粒度如此之大的分词结果必然会造成搜索引擎返回结果数过多,导致不能满足用户预期。
英语中Natural Language Processing 可以被拆分为Natural、Language、Processing,但是按照完整语义的角度出发,同样可以不将其分词而是作为一个复合词来看待,整体入库。同样,葡语中Processamento de linguagem natural 可以被拆分为Processamento、de、linguagem、natural。所以在分词时需要根据具体环境划分合理的颗粒度。
综上,普通话、粤语、英语、葡萄牙语之间分词既有相同之处也有不同之处,主要可以归纳为3 个问题:是否有分隔符、是否有形态转换、是否需要考虑分词颗粒度。
5 多语种分词标注流程策略
5.1 系统设计概述
在标注不同语种的语料时需要做分库处理,同时对标注人员进行分组,同组人员完成对同一语种的标注工作,方便对语种和语料进行管理。同时,系统内应设置3 种基本模块:“标注”模块和“个人”模块为系统内所有种类的用户服务,“工作组管理”模块则只为专家用户和系统管理员服务,普通用户只需专注于标注任务本身即可(见图1)。

图1 标注用户流程图
5.2 标注人员选择
语料库是研究人员、学者进行深度研究的基础,必须保证分词标注结果由专业领域内的人员产生。比如,普通话文本标注者最好来源于大湾区内部的普通话母语者,粤语文本标注者最好来源于大湾区内部的粤语母语者,若要让普通话母语者去分词标注粤语文本中的“点解”(粤语含义:为什么),标注者虽然可以看懂文本中的每一个字,但无法理解文本本身的含义,甚至可能觉得文本出现了错误,此时也就无法准确、客观地对文本进行处理。
每个语种都是十分具有特色的,且部分规则只有在当地长期生活或者母语是该语种者才能知晓,为了得到准确的分词标注结果,需要由专业人员去处理其擅长的语种领域。
5.3 系统角色分配
知识领域的众包分配任务需要引入“角色”的概念,多语种众包标注系统应包含3 种角色:普通用户、专家用户和系统管理员。普通用户为语言、历史、教育或相关专业的本科生、硕士生或专业标注人员,负责对系统标注结果进行修改。专家用户为拥有领域内专业知识的且从事自然语言研究的学者、研究人员或高校教授,主要负责对普通用户产生的结果进行评估和修改。
若标注系统中只包含标注类用户,则无法很好地对数据、标注过程及一些事务做管理,需要引入系统管理员维护后台,对语料、用户、系统的各种状态进行实时监控与管制,与分词标注工作的总负责人还有系统内的专家用户保持一定沟通,保证系统正常、高效运作。
5.4 三级标注
人工标注时总是会存在一些难以避免的错误,针对大湾区的多语种标注应采取三级标注模式,使错误率接近0%,以保障入库数据是准确的。第一阶段为算法预标注阶段,指的是标注系统依据现有的开源分词工具对导入数据库中的生语料做预标注,预标注的准确率普遍可以达到85% ~95%。在进入第二阶段众包标注阶段时,标注用户所需要做的只是处理5% ~15% 的系统标注错误,大大减少了时间成本。一条语料往往需要至少被两位不同的标注用户所标注以确保其正确性,若标注结果不相同,则还会被更多的标注用户所标注,这是为了保证语料库的质量,若语料库的质量无法保证,那么再多的数据量也是无效的。到了第三阶段,也就是专家标注阶段,专家角色的知识水平和对于同一条语料的理解程度通常是超过普通标注人员的,专家所需要重点处理的是第二阶段所遗留下来的“疑难语料”,之后专家用户也可以对普通用户的结果做检查和修改。经过严格的三级标注之后我们认为所产出的语料是可信的,可以作为语料库搭建的基础。
5.5 多语种标注细节
针对第4 节结尾提出的多语种标注存在的3 种不同之处,在该节提供解决方案。
(1)分割符:对于不存在天然分割的语种,例如,普通话和粤语,在系统预标注阶段推荐采用Hanlp、NLTK 等高质量开源工具进行分词标注预处理。对于存在天然分割的语种,例如,英语和葡语,若仅需提供给标注用户预分词结果,推荐使用正则表达式对文本进行预处理。正则表达式分词的优点在于灵活、门槛较低且标注效果好,以下为该研究提供的一种正则匹配规则。
[ ,,.。??!! \f\n\t\r\v]+
分词测试中有3 个常见的指标:P 指精确率,代表预测结果中正类数量占全部结果的比率;R 指召回率,代表正类样本被找出来的比率;F1 代表P 值和R 值的调和平均。在布朗语料库(Brown Corpus)和麦克莫弗语料库(MacMorpho Corpus)上进行测试后发现该研究F1 值达到98.97% 和99.73%,这说明在语料没有基本格式错误的情况下,通过正则匹配来初步分词效果十分不错。
(2)形态转换:当需要标注的语种存在时态变换或根据人称变换词语形态之类的问题时,需要对语料进行词干提取或是词性还原。词干提取和词性还原两者并不相同,词干提取由基于规则的方法实现,主要用于信息检索领域,而词形还原基于词典方法,在处理单词准确率较高的领域效果更好,例如,文本分类、情感分析等[6]。其的目的是减少回复的词语数量,从而达到降低语言模型维度的作用,具体使用何种方式进行预处理需要视使用场景而定。
同时,引入上述处理的具体位置也同样关键。若在系统标注阶段引入,则会导致系统标注结果不准确。而且该结果是需要向标注用户展示的,去掉句中原本存在的一些信息后必然会影响标注者的判断,造成标注的错误。所以,持久化保存语料结果之前应保留语料文本的全貌,在进行模型训练之前做词干提取或词性还原的操作,这保证了词语的序列不会改变且保留了原文本除了词语形态之外的所有信息。
(3)分词颗粒度:通过限定标注格式可以实现同时记录不同颗粒度分词标注结果的效果。复合构词的现象几乎存在于所有语种中,在对“中央督导委员会”这一复合词进行人工标注时,推荐采用如下的格式。
[中央/n 督导/vn 委员会/ni]/nto
中括号里的为复合词的各个组成部分,标注时需要为每个部分进行分词和词性标注,而中括号外的词性为整个复合词的词性,这样可以同时得到不同颗粒度的结果,方便对模型进行调整,但是需要标注人员付出更多的精力和耐心。
5.6 结果存储策略
同一条语料会被分配到不同的普通标注用户手中,且在三级标注阶段中的第二阶段我们规定一条语料应至少分配给两人以上进行标注,所以在数据入库时必然会存在多种结果。为了保证结果的全面性和准确性,需要将语料的id 与标注用户的id 联系起来同时存储,而不是进行覆盖式存储或者整合式存储。
同时,考虑到标注用户的专业性问题,若一条语料被专家用户修改或者标注后,直接将其作为该语料的分词标注结果,在提取分词标注和进行训练时应优先考虑该类结果,而非普通标注用户的结果。
5.7 质量保障
聘用标注用户时应首先进行考核,判断其是否能够胜任标注任务,考核的结果将作为初步任务分配的依据,将不同难度的标注任务分配给不同水平的标注者。标注期间应隐式地对标注者再次进行评估,并根据结果重新为其分配适合的标注任务。当标注者完成任务数量达到阈值时应及时给予不同程度的奖励,对于完成质量差的用户则及时解聘。
6 实验
6.1 词典
在生成词典和词性标注时,中文和粤语标注集采用《ICTPOS 3.0 汉语词性标记集》和《现代汉语语料库加工规范——词语切分与词性标注》 的兼容版本,英文标注采用的标注集为Penn Treebank Tagset,葡萄牙语标注采用的标注集为Universal Tagset。
词语种数指语料库中有多少个不重复的词语,总频次指的是所有词语的词频之和,分别可以用来衡量语料库应用的丰富程度和规模大小[7],词典统计信息如表1所示。
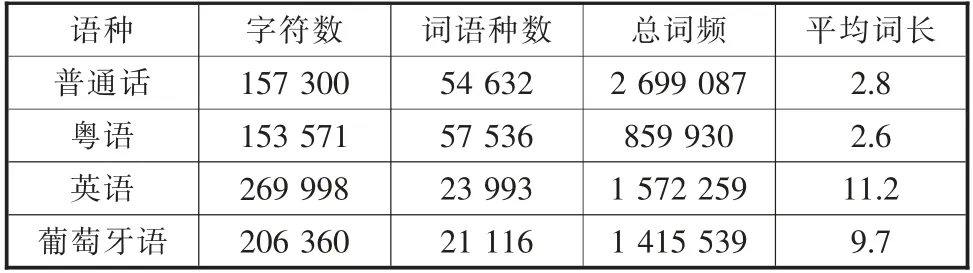
表1 词典统计
6.2 分词标注评测
使用Hanlp 提供的NatureDictionaryMaker 接口将已标注语料生成二元语法模型,接着对不同语种语料库做K 折交叉验证。
在K 值取10 的情况下,普通话和粤语的F1 均值达到了91%以上,英语和葡萄牙语,F1 均值达到了99% 以上。观察图2可知该文给出的多语种标注策略是切实可行的。

图2 交叉验证结果
7 结语
该文给出多语种语料库研究的流程和策略,通过实验结果和统计信息,展现研究总体进度和策略可信度。同时,该研究经过了长时间的语料标注收集和多种多样的分词实验,为粤港澳地区新闻媒体文本处理提供了较为丰富的数据。后续会继续采集粤港澳地区各种类型、各种语种的语料,届时数据量和分词标注的效果将会大大提升,我们会将语料库本体和分词器代码打包发送到开源平台,以供感兴趣的学者深入研究,为粤港澳地区语言研究事业以及教育事业献力。
