基于模板匹配的身份证号码识别方法研究
2022-06-15梁丽华孙玉冰房家琦
梁丽华 赵 凯 唐 琳 王 冰 孙玉冰 房家琦
(1.山东建筑大学信息与电气工程学院,山东 济南 250101;2.山东建筑大学材料科学与工程学院,山东 济南 250101)
1 引言
随着计算机技术的发展,数字识别技术更加成熟,逐渐应用于车牌识别、印刷体数字识别和手写数字识别等领域[1]。日常生活中,经常遇到绑定身份证或需提供身份证号码的情况,而手动输入身份证号码易错且耗时长,更需要仔细二次核对。因此,提出一种身份证号码识别方法十分必要。李美玲[2]提出了基于计算机视觉的身份证号码识别算法,该算法基于LeNet-5模型[3]自动训练样本图像,优点是达到了自动识别身份证号码的效果,不足之处在于该模型所需要的训练样本数量大,训练速度慢且模型的稳定性较差。成利敏[4]构建一套基于BP神经网络和GUI的身份证号码识别系统,该系统虽然在训练完成后识别准确率高,识别速度快,但是传统的BP神经网络存在收敛速度慢和阈值稳定性低等问题,若要得到更好的身份证号码识别效果,仍需对算法进行进一步优化。因此,本文中提出了一种基于模板匹配的身份证号码识别方法,该方法逻辑清晰、结构简单且可跨平台应用,实现身份证号码自动识别。
2 身份证图像预处理
身份证号码识别前需对图像预处理,预处理过程包含图像灰度化、图像二值化和ROI提取,剔除由出生日期或者家庭住址中的数字导致的身份证号码识别干扰。
2.1 图像灰度化
采集的原图像通常为一幅彩色图像,直接对彩色图像进行处理计算复杂且难度较大,所以要对彩色图像进行灰度化处理[5]。本文使用加权法对原图像进行加权平均处理,算法如式(1)所示,其中g(i,j)是转换后的灰度图像,fR(i,j) 、fG(i,j) 、fB(i,j)分别为彩色图像的三个分量。处理后的图像数据类型为8位,像素灰度值的取值范围为[0,255],处理结果如图1所示。由于身份证图像带有背景图案,所以需要对图像进行裁剪处理。经前期实验发现,裁切后的图像,宽度和高度分别为原尺寸的90%时效果最佳,裁剪结果如图2所示。
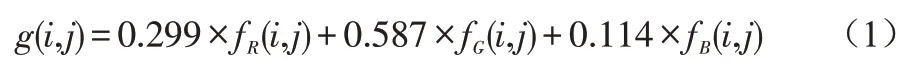

图1 灰度图像

图2 裁剪后的灰度图像
2.2 图像二值化
为使背景与数字的区分度更大,利于身份证号码识别,所以对灰度图像进行二值化[6]操作,使灰度图像转化为二值化图像。本文使用大津法[7],根据输入图像计算出最佳阈值进行全局阈值分割,避免在固定阈值条件下,由于图像灰度差异而造成的图像分割错误等问题,阈值计算方法如式(2)~(8)所示。设输入图像尺寸为Mr×Nr,灰度值取值范围为[0,L-1],ni代表了图像灰度值为i的像素数量,pi代表了这一灰度值i出现的概率,计算公式为pi=ni(Mr×Nr) ,本文使用的是单域值分割所以,将所有像素点一共分为两类分别为C0类、C1类,阈值分割点为T,C0类出现的概率为P0(T) ,C1类出现的概率为P1(T)。u0(T) 、u1(T)分别表示C0、C1这两类和图像的平均灰度级。为类间方差,T*即最佳阈值。处理结果如图3所示。

图3 二值化图像
2.3 感兴趣区域(ROI)提取
本文的目的是为了识别身份证图像中的数字,所以需提取感兴趣区域(ROI),即身份证二值化图像中的号码区域。本文采用特征定位方法提取身份证号码的ROI[8]。先确定提取身份证号码的最佳区域范围即特征区域,然后生成了一幅掩膜图像,如图4所示,再使用掩膜图像对二值化图像进行ROI提取操作,即可得到只含有身份证号码的二值化图像,如图5所示。

图4 掩膜图像

图5 ROI操作取反图像
3 身份证号码识别
身份证号码识别过程包含字符提取[9]、归一化处理和模板匹配,非常适合只有简单数字和字母的身份证号码提取,具有算法简单和计算量小的优点。
3.1 字符提取
经过前期身份证图像预处理,得到一幅只含有身份证号码的二值化图像,该图像分为黑色背景和白色数字和汉字,所以需要提取图像中的数字和文字,并把每个数字和文字分离,即字符提取,再进行后续的操作。
图像中的数字和文字并不是紧密相连的,数字或字符间存在着一定的间隔。本文使用8邻域连通域标记法[10]实现身份证号码字符分割,连通域标记原理如图6和图7所示。
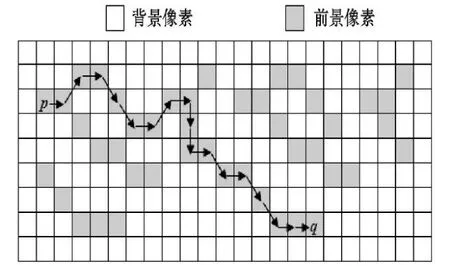
图6 连通域标记路径

图7 连通域标记结果
先粗定位身份证号码区域,通过剪切后图像中的非零灰度值像素点的返回坐标,定位数字和汉字的初步裁剪区域,如图8所示。再对裁剪区域进行连通域标记,得到一幅带有标记点的图像和连通域标记的数量。

图8 粗定位结果
连通域进行比对、拼接、裁剪。定义一个常数n= 1即从第一个连通域标记开始比较。令Lh为粗定位结果的高度,Lw为剪切后图像的宽度。
第一步:找出第一个连通域的所有非零像素点坐标,然后计算该连通域的高度H1、宽度W1、宽高比R1、面积S1,判断是否为最后一个连通域,若不是则寻找下一个连通域。
第二步:计算第二个连通域的高度H2、宽度W2、宽高比R2、面积S2。
第三步:对这两个连通域进行拼接,计算拼接连通域的拼接高度Uh、宽度Uw、宽高比Ur。再计算出两连通域的重叠高度Oh、宽度Ow、面积Os。
第四步:若两个连通域重叠,则根据式(9)和式(10)判断两个连通域是否属于同一字符。若两式同时满足,则判定为同一字符,若Ow<-(Lw/7)则表示两连通域相距较远,判定不属于同一字符,若0<Ow则表示两连通域重叠,且满足式(11)或式(12),则判定两连通域属于同一字符。
第五步:经过第四步的判断,若两个连通域为同一字符,则进行拼接,再根据返回的坐标裁剪字符,若不是同一字符,则裁剪第一个连通域,再对常数n加1后返回第一步。
经过多次循环,可得到分割后的独立字符,如图9所示,再对其进行后续操作。


图9 数字和汉字的字符分割结果
3.2 归一化处理
裁剪后的图像尺寸可能不一致,与模板图像的尺寸也有差别,所以将裁剪后的图像和模板图像归一化[11],变换成相同的尺寸图像以便模板匹配操作。对于二值化图像本文采用最近邻插值法,设图像像素点坐标为(i,j) ,所求灰度值为,公式如(13)~(15)所示。


3.3 模板匹配
模板匹配法[12]是数字图像处理中的经典算法,本文使用了自主建立的字库T(i,j) ,字库文件中包含了所需的数字模板和汉字的字符模板。下面根据公式(16)来计算相似度Ck,公式中的f(i,j)为所需识别的身份证号码图像,为所需识别身份证号码的平均灰度,若输入为二值化图像则代表了图像所有像素点的平均值。模板的表达函数由fk(i,j)和表示,分割后独立字符和模板的宽度和高度分别表示为M和N,令M=36,N=23。使用循环对比的方式对比每一幅身份证图像与字库文件每一幅图像之间的相似度Ck,Ck的数值越大,代表匹配程度越高,则最大值所对应的模板就认定为最后的识别结果。

定义的一串字符串包括了数字、字母和汉字,通过对识别出的模板图像结果添加返回值的方式,定位到字符串编号,再进行字符拼接,得到身份证号码的识别内容。
4 实验结果
本文提出的基于模板匹配的身份证号码识别方法,在MATLAB 2020b软件,Core i7-7700处理器,16G内存和500G硬盘的计算机硬件环境下,设计一个逻辑清晰、结构简单的数字识别仿真平台,实现身份证号码自动识别功能。在均匀光照、强光照和弱光照下采集30张身份证图像,使这些图像的明暗差异较大。分别采用BP神经网络、Keras框架下的卷积神经网络与本文方法作对比实验,测试结果如表1所示。
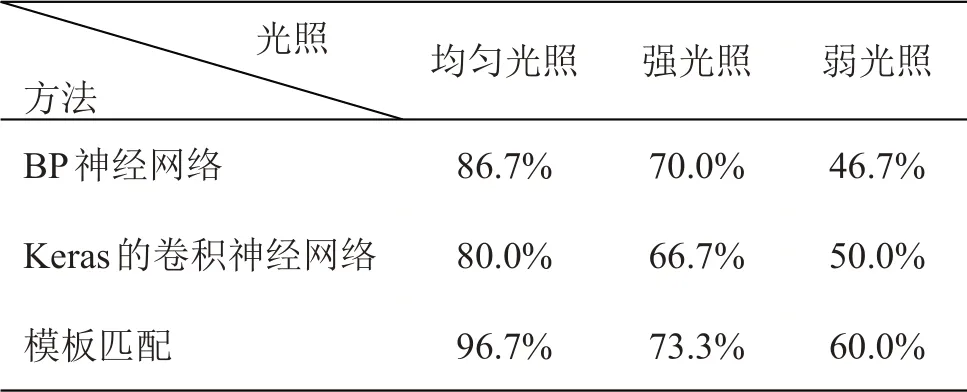
表1 身份证号码识别正确率
在均匀光照条件下,本文提出的基于模板匹配的身份证号码识别方法正确率最高为96.7%,而采用BP神经网络和Keras框架下的卷积神经网络方法,身份证号码识别正确率分别为86.7%和80.0%。在光照不均匀的强光照和弱光照下的身份证号码识别,三种方法识别结果的正确率都比较低,均在75%以下。由实验结果可知,身份证号码识别对光照条件有一定要求,只有在均匀光照条件下正确率较高,强光照和弱光照都不利于身份证号码识别。
5 结语
本文提出了一种基于模板匹配的身份证号码识别方法,该方法通过对身份证图像的灰度化、二值化和感兴趣区域(ROI)提取等操作,完成对身份证图像的预处理,实现18个数字和字符分割,通过对分割后的字符图像进行归一化处理,得到与模板相同尺寸的图像,最后进行模板匹配,计算号码识别结果。实验结果表明该方法在均匀光照条件下,身份证号码的识别准确率较高,验证了方法的可行性和有效性。
