基于Python爬虫技术抓取台风报文的研究与实现
2022-06-15陈琼莺施蔚然郑玉兰冯招程
陈琼莺 施蔚然 郑玉兰 冯招程
(福建省气象信息中心,福建 福州 350001)
1 引言
由于台风过境时一般会出现狂风暴雨天气[1],造成庄稼摧毁、山体滑坡、各种房屋摧毁及倒塌等[2-3],因此,提高预报台风精确度迫在眉睫。
根据台风产生的时间、风速、移向、强度、中心位置、最大风速、移动速度等观测数据形成台风报文。台风报文中的数据,能预测台风的路径及台风眼位置,因此台风报文是提高台风预报准确性的不可或缺的数据。中央气象台根据台风起始的发展变化,在中央气象台网页中实时发布台风报文。目前福建气象局无法实时抓取中央气象台网页中的台风报文数据,同时也缺乏丰富的台风报文库,造成许多台风报文无法很好地在业务科研上使用。台风报文资料的不齐全是影响台风预报能力的主要因素。提高台风报文的首要工作是收集台风报文资料。
在中央气象台发布的台风报文网页中,如何对网页数据进行抓取,并快速分析获取的资料中哪些是台风资料是我们要解决的问题。现代网页中都使用了搜索引擎功能,用户根据自己所需获取信息的关键字、关键词在网页中搜索,就能获其取所要的信息。由于爬虫技术是搜索引擎的核心技术,其在网页检索中发挥了重要作用,因此对爬虫技术进行研究并利用其实现台风报文抓取具有重要意义。
2 Python概述
2.1 Python特点
Python是一种具有解释性和交互性的跨平台的高级编程语言[4]。Python简单易学易用,拥有许多标准库,在UNIX、Macintosh和Windows平台上具有很好的兼容性。
2.2 Python技术特点分析
网络爬虫技术已经广泛应用在互联网领域中,搜索引擎运用网络爬虫抓取网页信息、视频、图片、文档等资源,利用索引技术组织这些信息,供用户进行搜索。Python网络功能非常强大,常用来实现网络爬虫,常用框架有grab网络爬虫框架(基于pycurl/multicur)、scrapy网络爬虫框架(基于twisted)、pyspider爬虫系统、cola分布式爬虫框架、portia可视化爬虫。由于Python的爬虫技术拥有强大的功能,可以在短时间内实现各类程序的编写任务。此外,现代科学技术的飞快发展,为Python提供了技术支撑,利用Python的网络能力,让爬虫在互联网各种数据信息中进行搜索,可使有效的信息得到充分利用。
3 Python爬虫概述
3.1 爬虫的基本结构
爬虫是一种自动抓取万维网信息的脚本,从万维网上获取用户需要的信息。网络爬虫可以自主遍历采集网页上的信息。网络爬虫最重要的作用就是在互联网的大数据中爬取到有效的信息,并将有效的信息数据存储到本地数据库中。
Python爬虫[5]框架主要是由爬虫调度器、URL管理器、网页下载器、网页解析器、信息采集器组成。其中调度器是实现协调网页下载器、网页解析器、URL管理器之间的运行。URL管理器主要包含已获取的URL地址和待获取的URL地址,避免重复抓取URL和循环抓取URL,URL管理器主要是通过内存、数据库、缓存数据库三种方式来实现的。网页下载器是根据传入的URL地址来下载网页内容,将网页内容转变为文本,常用的网页下载器有urllib。调度器将种子提供的URL进行下载,然后下载器从网上获取页面信息并发送至信息采集器,提取器根据信息提取指令获取信息,然后将下一级URL发送到一个等待队列,等待队列提交重载的URL,过滤和排序操作后进入列表,等待调度器调用。
3.2 爬虫过程的顺序图
网络爬虫的时序图如图1所示。具体的爬虫过程描述如下:首先调度端启动爬虫,询问URL管理器是否有要爬取的URL。URL管理器将要爬取的URL发给调度端,调度端根据获取的URL,利用网页下载器下载URL对应的页面内容。网页下载器将下载好的内容发给网页解析器来解析,返回解析好的内容和更新URL列表,获取有效的数据。
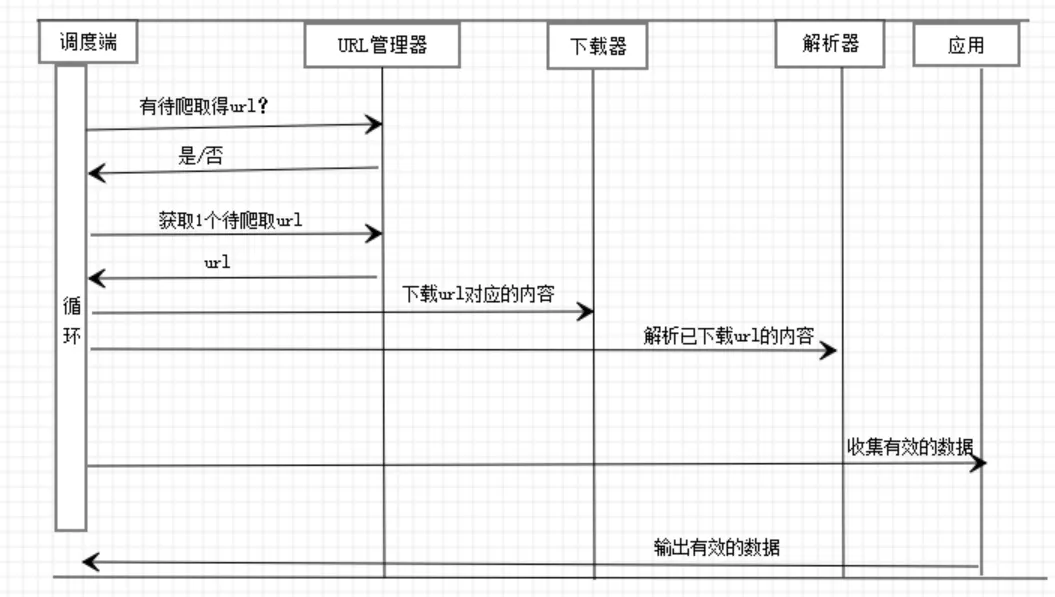
图1 爬虫过程的时序图
3.3 网络爬虫的分类
网络爬虫[6]根据不同的实现技术手段,可以大致分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫。通用网络爬虫也称为全网爬虫。通用网络爬虫是从网络各个领域的网页中抓取与主题相关的所有文档和链接。通用网络爬虫需要消耗大量的时间和磁盘空间。
聚焦网络爬虫也称为主题网络爬虫。聚焦爬虫只爬取特定的网页,与通用网络爬虫相比聚焦爬虫节省大量的时间、磁盘空间和网络资源,聚焦爬虫与通用爬虫的区别在于增加了过滤网页链接的两个模块:网页决策模块和URL链接优先级排序模块。
网页决策模块:当爬虫抓取到特定内容时,网页相关性评估器开始比较网页中的内容与预先给定的主题的相关性。如果网页的相关性没有达到之前设定的阈值,则会放弃该网页,以保持获取网页的高精度。
URL链接优先级排序模块:该模块主要用于比较解析的URL与给定主题的相关程度。该模块根据链接对内容的权限和链接的引用次数对链接进行优先级排序。按优先级排序并删除优先级过低的链接。
增量爬虫与一般爬虫的区别主要在于搜索策略不同。对于一般爬虫来说,一次遍历完成后,需要更新数据,按照之前的遍历形式对全网进行新的遍历,然后替换之前的结果。增量爬虫采用了一种新的机制来更新数据。增量式爬虫只会在需要的时候爬取新产生或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,可以提高爬取效率,减少对物理内存的占用,提高数据更新率。
3.4 网页获取与分析
爬虫的工作原理是模拟浏览器发出HTTP请求,发送至Web服务器。爬虫获取Web服务器响应后,对网页内容进行分析和存储,执行爬取任务。
网页解析主要是网页去噪的过程。在Internet中,网页的各种信息都存储在HTML的框架中。网页去噪主要是网页内容文本的提取。主题爬虫需要分析解析页面的HTML结构来提取搜索用户所需的信息。常用的方法包括通过Beautiful Soup解析HTML结构和使用正则表达式提取文本数据。
3.5 数据存储
爬虫获取数据的数据,一般采用两种存储方式:保存至本地文件或存储至数据库,通常量少的数据一般保存至本地文件,数据量大的数据一般存储到数据库中。
4 基于Python抓取台风报文的实现
4.1 网站页面分析
通过中央气象台网站,找到台风报文如图2所示。

图2 中央气象台网站
由图2可知台风报文的关键词中头部设置为ZCZC,尾部设置为NNNN。
在网页调试器中,任意选择一个时间(例2021/12/21 06:21),network中会增加一条为json存储的地址的调用记录,详细如图3所示。
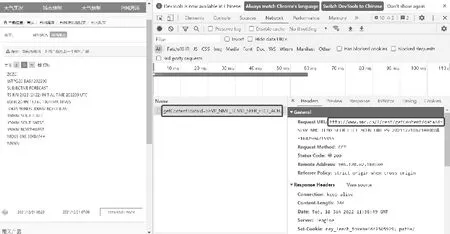
图3 获取报文信息存储的Web地址
通过图3可以得到模拟点击的链接参数为http://www.nmc.cn/f/rest/GetContent?dataId =。提取关键字为SEVP_NMC_TCMO_SFER_ETCT_ACHN_L88_P9。选择不同时间network的调用记录如图4所示。

图4 台风报文地址
从图4中可知台风报文的Web地址并没有呈现某种规律的变化,因此本系统采用固定的时间间隔去抓取数据(默认时间是每分钟,可以根据工作需要在页面上设置抓取的时间间隔),并判断地址中的信息是否有效,从而完成数据爬取任务。
4.2 系统实现
在基于Python抓取台风报文的软件中,本系统设计了定时提取和手工提取两种功能,定时提取可以根据需要设置定时周期,默认的定时周期是每分钟,本系统利用Python提供的一种常用的数据结构字典来实现重置字典功能。本系统中设有两个字典:报文地址字典和报文数据字典,用于防止重复解析和防止重复入库,重置字典即清空以上两个字典。当点击重置字典按钮就会重新获取报文,设置配置功能可以根据需要对存盘的路径、定时提取时间、报文关键词进行设置。本系统的导航存盘是用打开存储文件夹技术实现的,点击导航存盘按钮就会进入台风报文存放的目录中,方便用户查找文件。下面是实现爬虫程序设计的关键代码:
import requests#导入requests库
#获取网页内容
def get_html(url, params):
html = ' '
#设置请求头
http_headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'}
try:
r= requests.get(url=url,params=params,headers=http_headers, timeout=5)
r.encoding = 'utf-8'
html = r.text
except Exception as e:
print(e)
return html
代码解析:requests库的get()方法中的第二个参数params是台风报文,第一个参数url是中央气象台发布的网址:http://www.nmc.cn/publish/typhoon/message.html,第三个参数headers是用来向浏览器发出请求,它的参数是字典类型,表示的是用户代理信息。用户代理(user-agent)是浏览器客户端与服务器交互时的重要信息之一,用于帮助网站识别请求用户的浏览器类别,以便于网站发送相应的网页数据,第四个参数timeout是请求网面数据,如果5秒内没返回抓取的报文信息就会报出错信息。在基于Python抓取台风报文抓取软件中显示获取到的台风报文如图5所示,原始网页如图6所示,执行日志如图7所示。
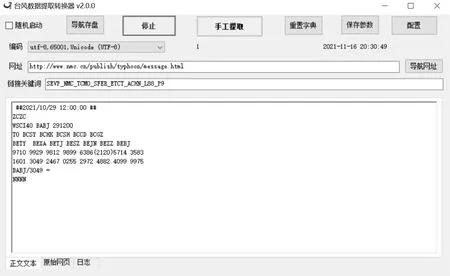
图5 台风报文

图6 原始网页
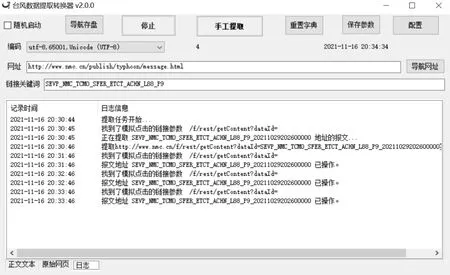
图7 日志信息
5 结语
基于Python台风报文抓取系统能够定时提取中央气象台网页中的台风报文,为福建气象局提供台风的当前位置、气压、风速、台风目前移速、预测未来的位置与强度、中心位置等信息,有利于福建气象台日常预报及业务的顺利开展,以及对台风报文进行更深入的研究。在大数据时代基于Python爬虫技术的气象信息挖掘具有重要应用价值。
