基于TSSA-SVR模型的焦炭质量预测模型研究
2022-06-14暴子旗卢才武宋思远
暴子旗,卢才武,章 赛,宋思远
(1.西安建筑科技大学资源工程学院,陕西 西安 710055;2.西安市智慧工业感知计算与决策重点实验室,陕西 西安 710055)
焦炭在高炉内的作用主要有供热剂、还原剂、骨架、渗碳剂等,除骨架作用不可替代外,其他作用均可被喷吹燃料所代替。随着高炉炼铁技术的进步,焦比不断降低,焦炭作为料柱骨架的作用更加突出,反映焦炭作为骨架能力的抗碎强度(M40)、耐磨强度(M10)、反应性(CRI)、反应后强度(CSR)等四项焦炭质量指标的好坏对高炉冶炼过程有着极大的影响[1-2],在焦炭生产中如何稳定、优化焦炭质量,是企业面临的重要课题[3-4]。
焦炭生产是一个具有多变量、非线性等复杂问题的大工业生产过程,在目前的焦炭生产中,焦炉的自动化程度仍然无法实现焦炭质量的稳定,生产现场也无法实现焦炭质量指标的在线测量,对于焦炭质量的人工分析则存在很大的滞后性与延迟性,因此,建立一个稳定、可靠的焦炭质量预测模型对炼焦生产进行指导具有十分重要的意义。
诸多学者针对焦炭质量预测问题进行了研究,周洪等[5]基于BP神经网络对特大型焦炉焦炭质量进行预测,并对影响模型预测精度的因素进行了详细分析,取得了较好的结果;崔庆安等[6]较早采用支持向量机预测焦炭质量,并将其与ANN模型进行对比,结果表明SVM模型具有更高的泛化性与预测精度;张伟峰等[7]建立了通过遗传算法(GA)优化BP神经网络的焦炭质量预测模型,实例证明该模型具有较好的准确度;都吉东等[8]构建了自适应差分进化算法优化的BP神经网络预测模型并进行仿真,将该模型与BP神经网络的预测结果进行对比分析,证明了ADE-BP神经网络预测模型具有更好的适应性与精确度;张代林等[9]对配煤中焦炭质量指标进行了分析,基于GA-SVR模型对焦炭强度进行了预测,具有较好的准确性与可靠性。但在预测模型中,BP神经网络存在难以选择合适的网络结构、易出现局部极值等问题,而在对预测模型进行优化的算法方面,GA算法收敛速度较慢,且参数交叉率和变异率等的选择凭借于经验,具有主观性,影响参数寻优的结果。
综上所述,本文采用具有较强泛化能力和学习能力的支持向量回归机作为模型建立的基础,引入Tent混沌映射改进的麻雀搜索算法(TSSA)对支持向量回归机的参数进行优化,建立了基于TSSA-SVR模型的焦炭质量预测模型,提高了模型参数的搜索能力以及预测模型的精确度,并对实际生产中的焦炭质量进行预测,以验证该模型的可行性与有效性。
1 模型理论研究
1.1 支持向量回归机

f(x)=ωT×φ(x)+b
(1)
式中:φ(x)为原始特征数据的非线性映射函数;ω为权向量;b∈R为阈值。
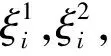

(2)
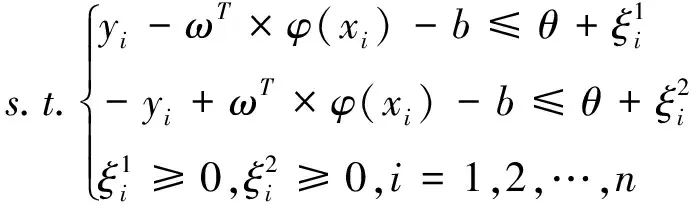
(3)
引入拉格朗日函数和核函数K(xi,xj)=φ(xi)φ(xj),可转化为对偶形式,见式(4)和式(5)。

(4)

(5)
式中,α为拉格朗日乘子。通过求解对偶优化问题,可以得到相应的决策函数,见式(6)。

(6)
1.2 Tent混沌映射
仿生类算法在解决函数优化问题中,通常利用随机产生的数据作为初始种群信息,而初始种群的分布会对算法的寻优精度与收敛速度产生很大的影响。
混沌序列具有随机性、遍历性和规律性等特点,通过其产生的初始种群可以具有较好的多样性,并提高算法的全局搜索能力。现有的混沌映射有Tent映射、Logistic映射等。但是,不同的混沌映射对于提高函数优化能力不同。其中,单梁等[11]的研究表明,Tent映射相比Logistic映射具有更佳的遍历性,可以生成更好的均匀序列。因此,本文引入Tent映射初始化种群,提高算法的全局搜索能力。
TENT混沌映射的表达式为式(7),即xi+1=(2xi)mod1。
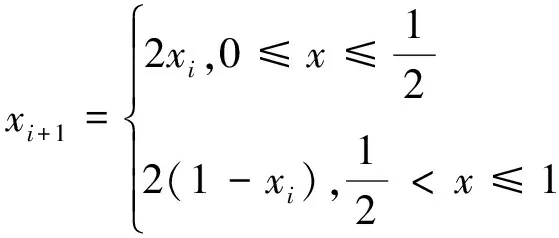
(7)

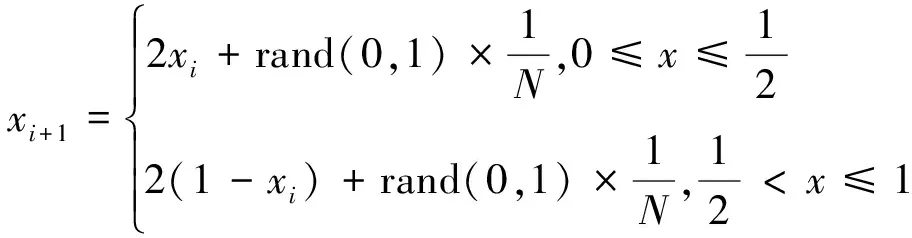
(8)
变换后表达式见式(9)。

(9)
式中:N为混沌序列内粒子个数;rand(0,1)为在[0,1]之间取值的随机数。
1.3 麻雀搜索算法
麻雀搜索算法(sparrow search algorithm,SSA)是受到生物界麻雀捕食和反捕食行为的启发,由XUE等[13]于2020年提出的新型仿生类算法。其仿生学原理及抽象数学表达如下所述。
麻雀觅食过程可将群体抽象为三类:发现者、加入者以及侦察者。具有较高适应度的麻雀作为发现者,在广泛范围进行搜索,并引导种群搜索和觅食,加入者则会跟随发现者进行觅食。而当作为预警者的麻雀意识危险时,会对整个种群发出信号,促使整个种群立即进行反捕食行为。
在SSA算法中,麻雀群体可表示为Xi=[xi1,…,xid,…xiD],i=1,2,…,N,N为麻雀的总数,其中,Xid为第i只麻雀在第d维的位置。
在种群的发现者位置更新公式见式(10)。

(10)
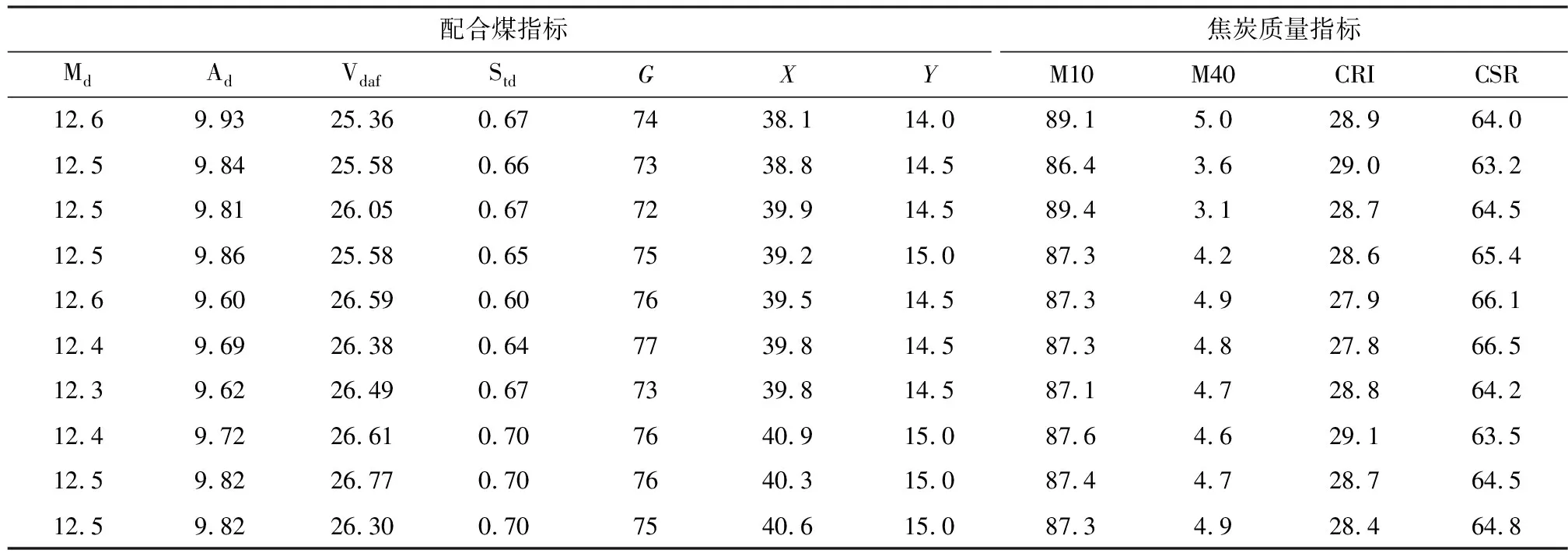
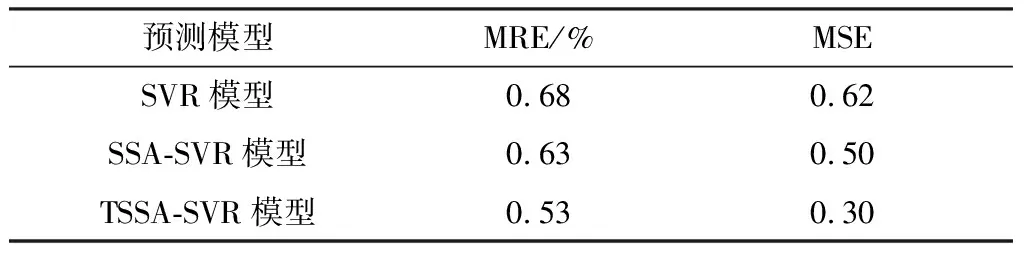
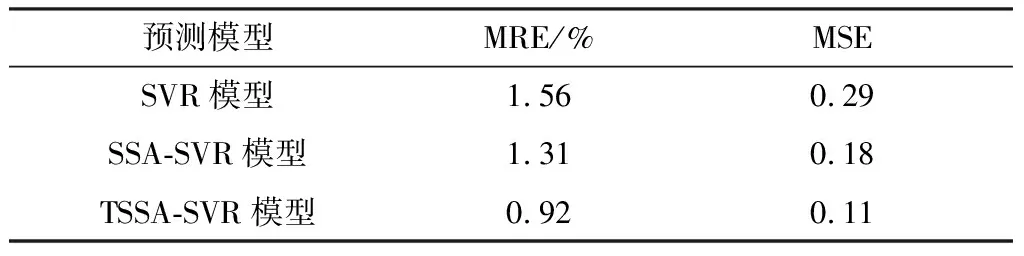
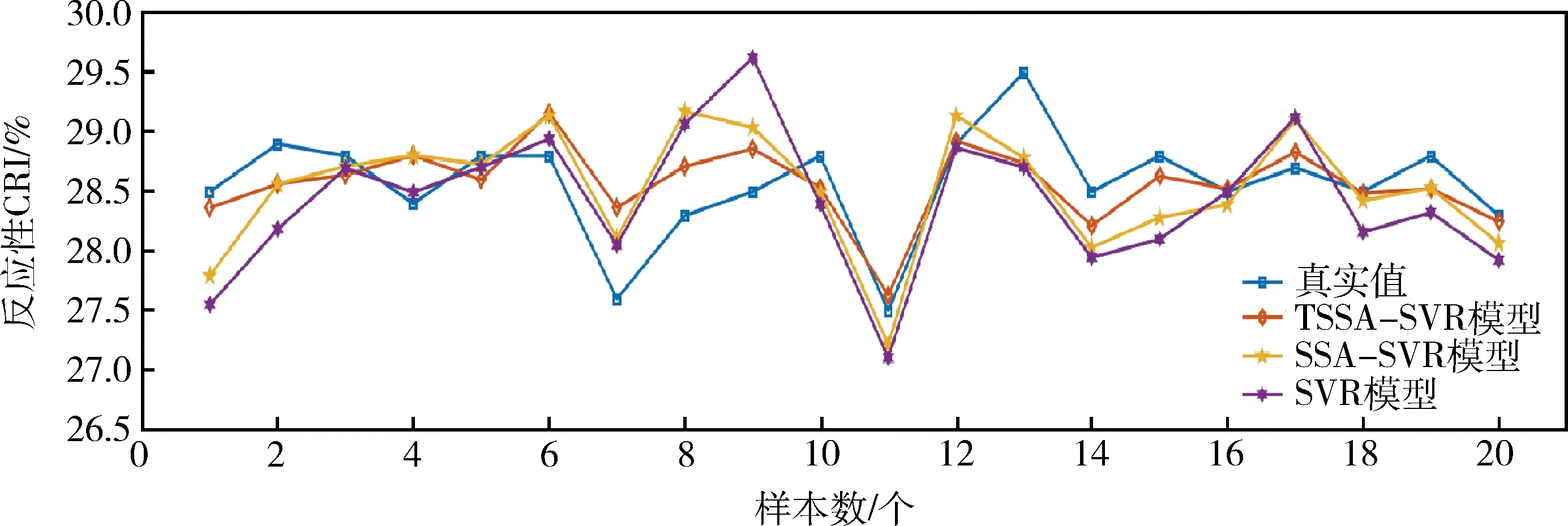
式中:t、T分别为当前迭代次数与最大迭代次数;α为(0,1)之间的随机取值;Q为服从标准正态分布的随机数;L为元素皆为1的矩阵,大小为1×d;R2(R2∈[0,1])为预警值;ST(ST∈[0.5,1])为安全值。以R2与ST的值进行判定,当R2 加入者的位置更新公式见式(11)。 (11) 侦查者一般从种群中随机取10%~20%,其位置更新公式见式(12)。 (12) 式中:β为步长的调整参数,是服从均值为0,方差为1的正态分布随机数;K为在[-1,1]之间取值的随机数,表示麻雀移动的方向;e为一个极小的常数,避免出现分母为0的情况;fi为第i只麻雀的当前适应度值,fg、fw分别为在当前种群中的最优与最差适应度值。当fi≠fg时,表示该麻雀处于边缘位置,正在受到捕食者的威胁;当fi=fg时,表示处于种群中心的麻雀意识到了危险,需要向其他麻雀靠拢。 在SSA模型的基础上引入Tent混沌映射初始化种群,增加了种群的多样性,提高了算法搜索全局最优的能力,混沌麻雀搜索算法的步骤如下所述。 Step1初始化参数,如种群数量N、最大迭代次数、发现者比例PD、侦察者比例SD、目标函数维度D,初始值上下界ub、lb,最大迭代次数T。 Step2基于Tent混沌序列初始化种群,生成N个D维向量Zi。 Step3计算各只麻雀的适应度值,找出当前最优适应度值fb和最差适应度值fw,以及相对应的位置xb、xw。 Step4从适应度值较优的麻雀中,选取部分麻雀作为发现者,并按照式(10)更新位置。 Step5余下麻雀作为加入者,并按照式(11)更新位置。 Step6从麻雀中随机选择部分麻雀作为侦查者,并按照式(12)更新位置。 Step7更新整个种群的最优位置xb和最优适应度fb,以及最差位置xw和其适应度fw。 Step8判断是否达到结束条件,若是,则结束循环,输出最优结果,否则跳转Step4。 本文基于支持向量回归机对焦炭质量进行预测,以配合煤中的水分Md、灰分Ad、挥发分Vdaf、硫分Std、黏结指数G,以及胶质层指数X和Y作为输入变量,以焦炭质量的抗碎强度M40、耐磨强度M10、反应性CRI、反应后强度CSR等四项指标为输出变量。 SVR模型中的核函数及其参数的选取模型的回归效果起到重要影响,核函数中的径向基函数(RBF)具有学习能力强、收敛范围较宽等优点,故本文采用RBF作为核函数,见式(13)。 (13) 参数选择对SVR模型的学习效果和泛化性能有直接的影响[14],在选取RBF作为核函数的情况下,影响SVR回归性能的主要参数有惩罚系数c和RBF核函数的宽度参数g。c表示SVR预测模型中误差与复杂度之间的权衡,c越小则对误差的惩罚越轻,容易导致模型欠拟合;c越大,表示模型越不能容忍误差,容易使模型对训练数据过分学习,导致过拟合。g表示RBF核函数的宽度,g值过小,则支持向量影响范围过小,会导致模型过拟合,g值过大,则支持向量影响过强,导致模型预测精度低[15]。 基于此,本文引入混沌麻雀搜索算法对SVR的参数进行优化,寻找最优的(cbest,gbest),而后对焦炭质量进行预测,其流程图如图1所示,具体步骤如下所述。 图1 基于TSSA-SVR模型的焦炭质量预测总体流程图Fig.1 The overall flow chart of coke quality predictionbased on TSSA-SVR model 1) 载入数据,并对数据进行归一化,并把归一化后的100个样本按照8∶2的比例分为训练集与测试集。 2) 初始化混沌麻雀搜索算法的各项参数,并基于Tent映射初始化种群。 3) 以式(14)的均方误差作为适应度函数并计算适应度值,以均方误差小为佳。 (14) 4) 运行混沌麻雀搜索算法,迭代寻优得出具有最小适应度值的(cbest,gbest)。 5) 将(cbest,gbest)代入到SVR模型中进行训练,而后基于训练好的TSSA-SVR模型对焦炭质量进行预测。 本文选取河南某焦化厂100组稳定生产的焦炉数据进行实例验证,部分实验数据见表1。这些生产数据存在维数高、量纲不统一、范围较大的特点,所以为了消除不同指标间的量纲影响,并且保证数据间的可比性,需要对数据进行归一化处理。本文将数据归一化至[0,1]之间,利用的公式为式(15)。 表1 部分实验数据Table 1 Partial experimental data (15) 式中:xi为数据的样本值;xmax、xmin分别为每组样本数据中的最大值、最小值;x*为数据的归一化值。 对数据进行预处理后,将数据导入TSSA-SVM模型中进行训练和预测。在TSSA算法中初始化设定种群大小N=30,最大迭代次数T=50,目标函数的维数D=2。通过TSSA算法获得四组最优参数(cbest,gbest),见表2,将最优参数带入预测模型进行计算。 表2 TSSA-SVR模型参数寻优结果Table 2 Parameter optimization results of TSSA-SVR model 式(14)的均方误差(MSE)作为算法的适应度函数fitness,以CSR的参数寻优为例,求得适应度曲线如图2所示。由图2可知,TSSA-SVR模型的适应度值始终优于标准的SSA-SVR模型,并且迭代较快,误差较小,证明该算法在全局搜索上具有较优的性能。 图2 适应度曲线Fig.2 Fitness curves 为验证模型预测结果的有效性,本文采用平均相对误差(MRE)和均方误差(MSE)两个评价指标进行验证。 平均相对误差(MRE)见式(16)。 (16) 均方误差(MSE)见式(17)。 (17) 本文选取标准SVR模型、SSA-SVR模型、TSSA-SVR模型等三种模型进行仿真实验并对预测结果进行分析,预测指标结果见表3~表6;对比拟合曲线如图3~图6所示。 表3 M40预测结果Table 3 M40 prediction results 表4 M10预测结果Table 4 M10 prediction results 表5 CRI预测结果Table 5 CRI prediction results 表6 CSR预测结果Table 6 CSR prediction results 由表3~表6可知,TSSA-SVR预测模型相较于对比模型中效果较优的SSA-SVR预测模型,TSSA-SVR模型对焦炭质量各指标预测的MRE值分别下降了0.10%、0.23%、0.39%和0.29%,MSE值则分别下降了0.20、0.07、0.07和0.23。这表明TSSA-SVR预测模型的预测精度更高,可以更好地应用于焦炭质量的预测。 图3~图6为TSSA-SVR模型、SSA-SVR模型、标准SVR模型等三种模型对焦炭质量各指标的预测值与真实值之间的拟合图。 由图3~图6可以看出,除个别点外,TSSA-SVR预测模型的预测值相比于另外两个模型都更接近真实值,稳定性更好,拟合度更高。 图3 M40预测拟合图Fig.3 M40 prediction fitting diagram 图4 M10预测拟合图Fig.4 M10 prediction fitting diagram 图5 CRI预测拟合图Fig.5 CRI prediction fitting diagram 图6 CSR预测拟合图Fig.6 CSR prediction fitting diagram 针对焦炭质量预测问题,利用基于混沌映射改进的麻雀搜索算法(TSSA)对支持向量回归机(SVR)的参数进行优化,建立了TSSA-SVR回归预测模型,通过实验证明了TSSA算法优化SVR参数的优越性。在实证中,采用某焦化厂实际生产数据进行预测,仿真结果表明,本文建立的TSSA-SVR模型对焦炭质量的预测精度更高,预测误差更稳定,并验证了TSSA-SVR模型在实际问题应用中的有效性和可行性。 炼焦生产过程较为复杂,影响焦炭质量的因素众多,其中包括配合煤的各项指标,还包括生产中的各项参数,如何分析整合更多的焦炭质量影响因素,建立精度更高,效果更稳定的焦炭质量预测模型是今后研究的重点。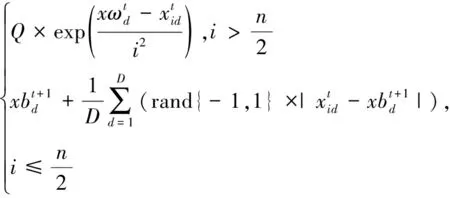


1.4 混沌麻雀搜索算法
2 焦炭质量预测模型的构建

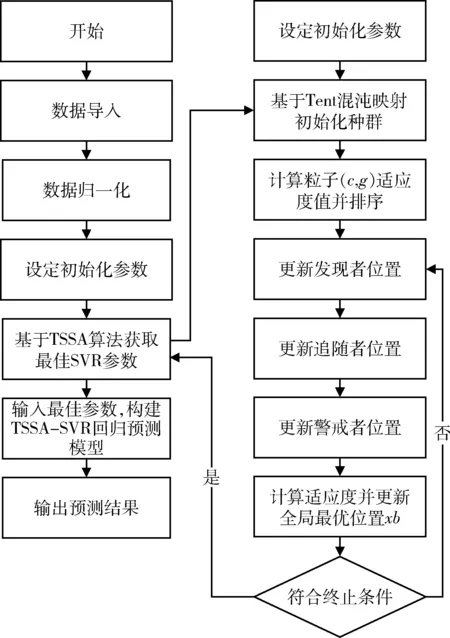
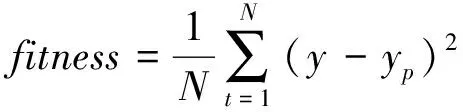
3 实例研究
3.1 数据来源及预处理

3.2 仿真分析


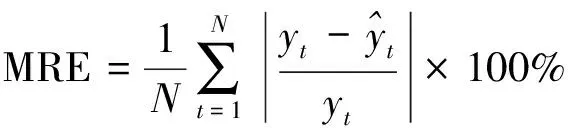
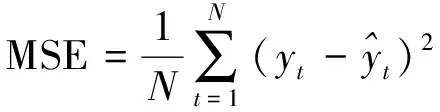





4 结 论
