基于某组合模型的不平衡数据分类算法研究
2022-06-14龚晓峰
李 斌,龚晓峰
(四川大学电气工程学院,四川 成都 610065)
1 引言
数据不平衡,即其中一类样本的数目远远小于另一类,而往往少数类样本会蕴藏更有价值的信息,因此具有更高的错分代价。不平衡分类问题广泛存在于社会生产中,如财务欺诈[1],肿瘤识别[2],软件漏洞查找[3]。除了数据样本量的差别,不平衡数据经常存在特征空间重叠,样本分布不明显等问题,影响分类结果。
目前的研究主要从数据重采样和改进分类算法两方面解决问题。在数据处理层面,主要分为欠采样和过采样。Chawla等人[4]提出的 SMOTE算法通过分析少数类样本特征空间,生成与少数类样本相似的样本来使数据集平衡。由于SMOTE算法在合成少数类样本的随机性过大问题,Torres提出了SMOTE-D[5]。针对欠采样容易造成多数类样本丢失的缺点,学者先后提出了邻域清理法[6],基于聚类的欠采样方法[7]。
分类算法主要根据传统分类算法对不平衡数据的缺陷进行相应的改进,如单类学习中的单类支持向量机[8],引入敏感因子的代价敏感决策树[9]。集成学习是解决不平衡问题的常用算法,通过训练多个不同的基分类器,并将其分类结果按一定方式集成,从而提升单个分类器的性能[10]。集成学习算法分为Bagging和Boosting,常见的Boosting算法如XGBoost,Adaboost,GBDT[11],常见的Bagging算法如随机森林[12]。学者将数据采样技术与集成学习结合,相继提出了SMOTEBoost[13],RUSBoost[14],RHSBoost[15]去处理不平衡问题。
文献[16]提出了结合随机子空间和SMTOTE过采样技术的AdaBoostRs来增加分类样本的多样性和降低数据维度;文献[17]借鉴了Focal loss的基本思想提出了根据基分类器预测结果直接优化权重更新策略的FocalBoost。以上所列算法虽然取得了良好的识别效果,但是在某些极端条件下,如少数类样本极端少和分布不连续,很难反映数据真实的分布特性,造成算法分类误差较大;在处理高维特征数据时很难学习到潜在的最优特征表达,具有一定的局限性。
针对上述问题,本文在结合了集成学习和特征学习思想的基础上,提出了一种新的不平衡分类算法Bagging-RUSBoost。该算法对经典RUSBoost模型的样本权重更新方式进行了改进,提高少数类样本的错分代价;引入了散度自编码器进行隐含特征提取,将高维特征进行降维处理,使两类特征差异最大化,提高模型的特征学习能力;采用Bagging对RUSBoost子模型进行了加权集成,解决了单分类器泛化能力差的问题。实验结果证明相较于其它集成领域的模型,本文算法有效提高了精度,在面对高维的非平衡样本时具有更强的鲁棒性。
2 Bagging-RUSBoost算法简介
2.1 改进的RUSBoost模型
RUSBoost模型是在AdaBoost理论基础上融入随机欠采样技术的不平衡数据分类模型,是由多个弱分类器组合为强分类器的算法。但是在面对极端不平衡数据时,仍存在一些不足和改进的地方。主要分为两点:在权重更新时,所有样本错分的权值变化是相同的,这样容易造成不公平的权值分配,在两类样本相差悬殊时,少数类应当具有更高的错分代价;在基分类器训练阶段,样本权重变化主要依赖于上一轮训练的结果,然而这样的权值分配方式过于片面,例如前t次迭代某一样本x全部分类正确,样本y全部分类错误,第t+1次x,y均分类错误,那么其权值是变化相同的,这样是不公平的,y理应获得更高的权值分配,参考前t次的分类结果进行权值更新更为客观,使样本训练更为均衡。
设训练的不平衡数据集S为{(x1,y1),(x2,y2),…(xm,ym)},其中xi表示样本的特征向量,yi∈{-1,1}表示样本标签,样本权值分布为Dt={w1,w2,…wm}。t表示迭代次数,ht(xi)表示弱分类器。
2)Fort=1,2,…T
a.使用随机欠采样技术创建临时的训练集St,并产生其对应的权值分布Dt
b.将生成的训练集St,去训练第t次迭代生成的弱分类器ht
c.返回预测模型ht
d.计算第t次训练的分类错误率εt,εt为在训练集St所有样本构成的分布Λt下预测错误的概率之和,I为弱分类器的概率输出。如果εt>0.5,则返回b步骤重新训练弱分类器

(1)
e.计算样本的权值更新参数αt,即弱分类器的权重

(2)
f.更新样本权值,Dt+1(i)表示第i个样本在第t+1轮训练的权值,原始算法为

(3)
Zt表示对所有样本权重的归一化函数。
针对原更新方式的不足,本文提出了一种新的更新模式。原始算法中样本权重更新只依赖于上一轮的训练结果,本算法改为以加权历史迭代结果对样本权重进行更新。样本i在前t次的迭代,即前t个弱分类器训练的中加权分类正确率βt
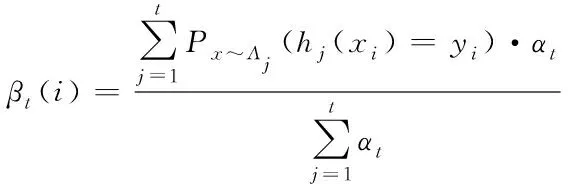
(4)
设λ为敏感因子,对少数类作特殊标记,提高每次迭代时少数类样本的错分代价,使其在下次更新时具有更高的选中率。一般取[0.1,0.2]
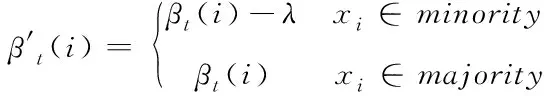
(5)
则第t+1次的样本权值为

(6)
归一化因子公式如下

(7)
3) 输出的T个弱分类器组合模型RUSBoost
(8)
最终算法会以sign[HT(x)]输出样本所属类别。如果sign[HT(x)]>0,则输出1,反之则输出-1。
2.2 基于散度自编码器的隐含特征提取
样本不平衡问题,除了样本数量的失衡,往往伴随着特征空间重叠、样本特征不明显等问题,会导致数据特征属性分布的失衡,尤其在遭遇高维不平衡特征时,其少数类样本分布更加稀疏,关键的样本特征很难得到表达,因此容易导致分类器的性能降低,甚至造成维度灾难等情况。
针对以上情况,本文从特征学习角度出发,提出了一种基于自编码器的特征提取方法, 在自编码器架构的基础上,在其瓶颈层,引入一层KL散度激励函数,和重构损失函数构成了双目标训练的模型,结构图如下:

图1 散度自编码器的结构
重构损失采用交叉熵损失函数来评价重构特征相对于原始特征的损失,KL散度激励函数用于将瓶颈层的压缩特征差异最大化。
编码阶段为对原始特征进行逐层抽象的过程,x为输入的原始特征
z=fθ(x)=σ(wx+b)
(9)
z为隐含层的抽象特征,θ={w,b}分别为编码层权值参数和偏置参数,σ为非线性激活函数,一般采用Sigmoid函数。
(10)
输入到瓶颈层的特征,会进一步降维。输入自编码器的多数类样本数目为m1,少数类为n1,因为样本是不平衡的,在瓶颈层会在多数类样本中抽样,生成m1/n1个平衡的样本矩阵。zM和zN分别代表多数类样本和少数类样本,在瓶颈层迭代m1/n1次后结束。KL散度本质是对两类数据分布差异的评估,在KL散度的激励下,模型同时学习两类样本的特征,两类特征会朝着样本差异最大化的方向训练,最终生成分布差异更加鲜明的抽象特征,公式如式(11)

(11)
解码阶段即反编码阶段,将瓶颈层的抽象特征z重构为原始输入
y=gθ′(z)=σ′(w′z+b′)
(12)
y为输出特征,θ′={w′,b′}为解码层的权值参数和偏置参数,σ为非线性激活函数。
重构损失函数即交叉熵损失,并采用了L2正则化作为惩罚项,防止过拟合。
如下

(13)
最小化交叉损失熵来调整网络内部的权值参数θ,θ′,即优化目标为

(14)
采用随机梯度下降的方式对自编码器参数进行优化,如下式

(15)

(16)
2.3 改进的加权Bagging组合模型
Bagging作为一种典型的集成学习算法,在原始样本中随机采样,对多个独立的弱分类器进行平行训练,然后利用子学习器的投票机制选出最终的结果。
结合2.2节的特征提取方法,将RUSBoost作为基分类器,利用Bagging思想对分类器进行集成。散度自编码器的特征在瓶颈层提取后,作为基分类器的训练集。
多数类样本数量为m,少数类样本数量为n,基分类器数目为k。在自编码特征训练过程中,尽可能保留少数类的特征,避免自编码器模型偏向于多数类。少数类样本抽样数目固定为n,多数类样本每次抽样2*m/k,生成数据集输入到散度自编码器训练。这样最大限度保证了自编码器能充分学习到少数类样本的特性的同时,也尽量保留了多数类的特征信息。这样反复有放回抽取k次,分别输入k个基分类器进行训练。
Bagging算法一般采用简单多数投票策略,然而没有考虑到各个基分类器分类性能的差异,不平衡样本很容易造成在Bagging随机抽样的过程中数据集出现一定的差异,因此需要综合各分类器的性能进行加权处理。
本文以多数类和少数类召回率作为分类器性能的评价指标,召回率高的分类器即给与较高的权值,最后综合基分类器给出加权投票结果。相对于原始投票法的硬阈值组合,最终输出了一个加权投票概率,降低了单一分类器随机性的影响。
ri表示单个基分类器的召回率,取两类召回率的均值,TPR和TNR分别表示少数类和多数类的召回率

(17)
即每个模型的分配权值ηi为
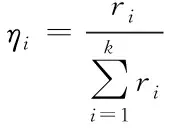
(18)
RUSBoost子分类器Hi(x)∈{-1,1},1代表少数类样本,-1代表多数类样本,Bagging加权组合后的分类器模型为
(19)
最终的分类结果Result为
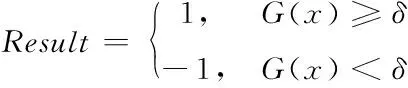
(20)
δ为分类阈值,大于阈值会被归类到少数类。δ并不是一个定值,取值范围一般在(-1,1),可以通过交叉验证对阈值进行微调以达到较好的处理效果。关于δ取值的进一步讨论在第3章阐述。算法流程如图2所示。

图2 Bagging-RUSBoost分类算法流程图
3 实验结果与分析
为了验证本文所提算法的先进性,本文选取了UCI数据集和Fashion_MNIST进行实验,选取了XGBoost,RUSBoost,AdaBoostRs[16](结合随机子空间和SMOTE过采样),FocalBoost[17](利用Focalloss优化权值更新)四种模型作为对照。对召回率、F1score、G-mean、Auc等性能指标进行了比较,并讨论了阈值对模型的影响。
3.1 评价指标
本文选取了不平衡分类常用的几种评价指标,混淆矩阵如表1,召回率为样本正确被分类的比例,TPR和TNR分别表示少数类和多数类召回率

表1 淆矩阵

(21)
TPV和TNV分别表示阳性精确率和阴性精确率
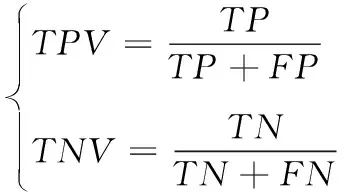
(22)
F1score是衡量精确率和召回率的分类指标
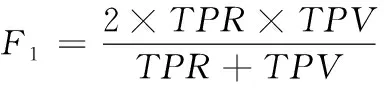
(23)
G-mean是衡量分类器识别多数类和少数类精度的几何平均值
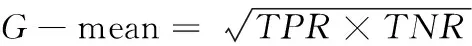
(24)
Auc是其对应的Roc曲线的面积,能很好度量分类器在面对不平衡数据的分类性能。
3.2 UCI实验
Bioassay是UCI的一个不平衡数据集,包含21个生物测定数据集,本文选取其中的AID362red,AID1608red两个特征维度较高的数据集进行实验,其具体信息如下:
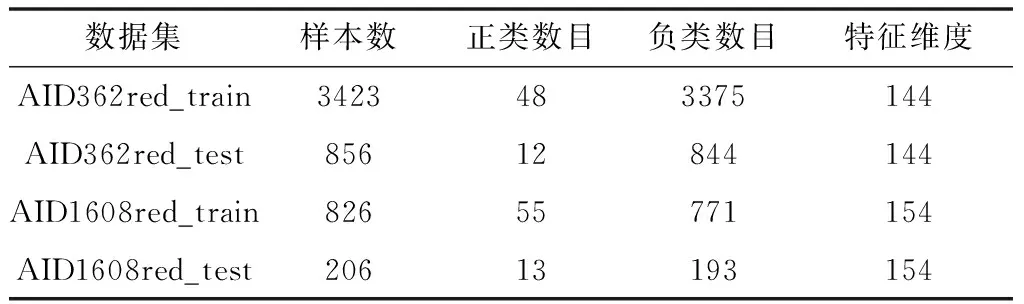
表2 UCI数据集信息
在处理非图片数据时,自编码器采用全连接即可,在瓶颈层提取到最优的特征表达去训练RUSBoost分类器,这里采用十折交叉验证去得到最优的性能指标,阈值选取0.1,基分类器数目为10,单个分类器的敏感因子取0.2,实验结果如表3和表4。

表3 AID362red的五种性能指标对比结果

表4 AID1608red的五种性能指标对比结果
由表3和表4可知,新模型的多数类召回率与AdaBoostRS和FocalBoost相差不大,而在不平衡分类中也更关注少数类的分类指标。新模型在少数类召回率更有优势,分别达到0.833和0.846。其余三种指标也优于对比模型,AUC分别达到了0.886和0.917,尤其在与单一RUSBoost模型的比较占据了全面优势,证明本模型在不平衡数据下是有明显进步的,改进的加权Bagging是有效的。
3.3 Fashion_MNIST实验
新模型在面对UCI的数据集时表现出了良好的分类效果,为了进一步证明在图片这种更高维的数据时,同样能保持性能,本文选取了Fashion_MNIST商品数据集进行实验。Fashion_MNIST有十类商品标签,相对于经典的MNIST手写数据集,Fashion_MNIST的商品图像训练更具挑战性,分类难度也更大。为了全面证明模型的泛化能力,选取了两种实验方案,为一对一和一对多。一对一为随机选取两类商品训练,多数类样本量固定为3000,少数类分别选取30,25,20,15,10,5进行训练,实验选取shirt和coat作为两类样本 ;一对多为随机选取一类商品为少数类,剩余九类商品为多数类,样本数量与一对一相同,选取dress作为少数类。
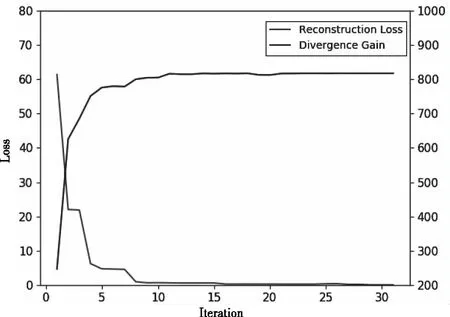
图3 散度自编码器两种损失函数的变化

图4 两类训练集下算法的性能对比图
在处理28×28的图片数据时,自编码器采用卷积结构,选取三层编码层和三层解码层,瓶颈层采用全连接层输出100维数据特征。28×28维的原始输入图经过编码层的逐层抽象,会先转换为1×1000的特征向量,在经过Relu操作和进一步降维,最终在瓶颈层输出100维隐含特征表达。
自编码的损失函数变化如图3,可知重构函数随着迭代进行逐步趋于0,而KL散度随迭代次数增加逐步增大而稳定,两类特征差异随训练是增大的,最终得到隐含层的两类特征,是分布差异明显的特征表达,更有利于分类器的训练。
五种算法的表现如图4,图5,训练选取的多数类样本固定为3000,横坐标代表训练的少数类样本数目。图4表示的两类样本的分类,而图5代表多类中识别一类的实验结果。五张子图分别对应了多数类召回率,少数类召回率,F1score,G-mean,Auc。由图4和图5可知,五种分类器的多数类的召回率比较稳定,且趋近于1。其余指标下,对照实验的四组算法,XGBoost的分类性能相对要低一些,其它三种差异并不明显,互有优劣,在某些样本集下略微重合。整体的分类效果随着少数类样本数目的降低而呈现下降趋势。
而本文所提模型在所有样本集下依然保持优异的分类性能,尤其在少数类样本减少到5时仍有0.5以上的少数类召回率,各项指标优势更加明显,证明模型在样本极端少且高维的情况下,具有优秀的特征学习能力,能学习到样本的隐含特征表达。图5实际上验证了样本在复杂的噪声背景下提取关键字的能力,虽然整体的召回率相较于图4略有下降,但仍然保持较高的精度,在少数类样本为10时,仍能保持0.6以上的召回率和接近0.8的AUC,证明了模型在面对不同的复杂数据集时,具有很强的泛化能力和较高的鲁棒性。
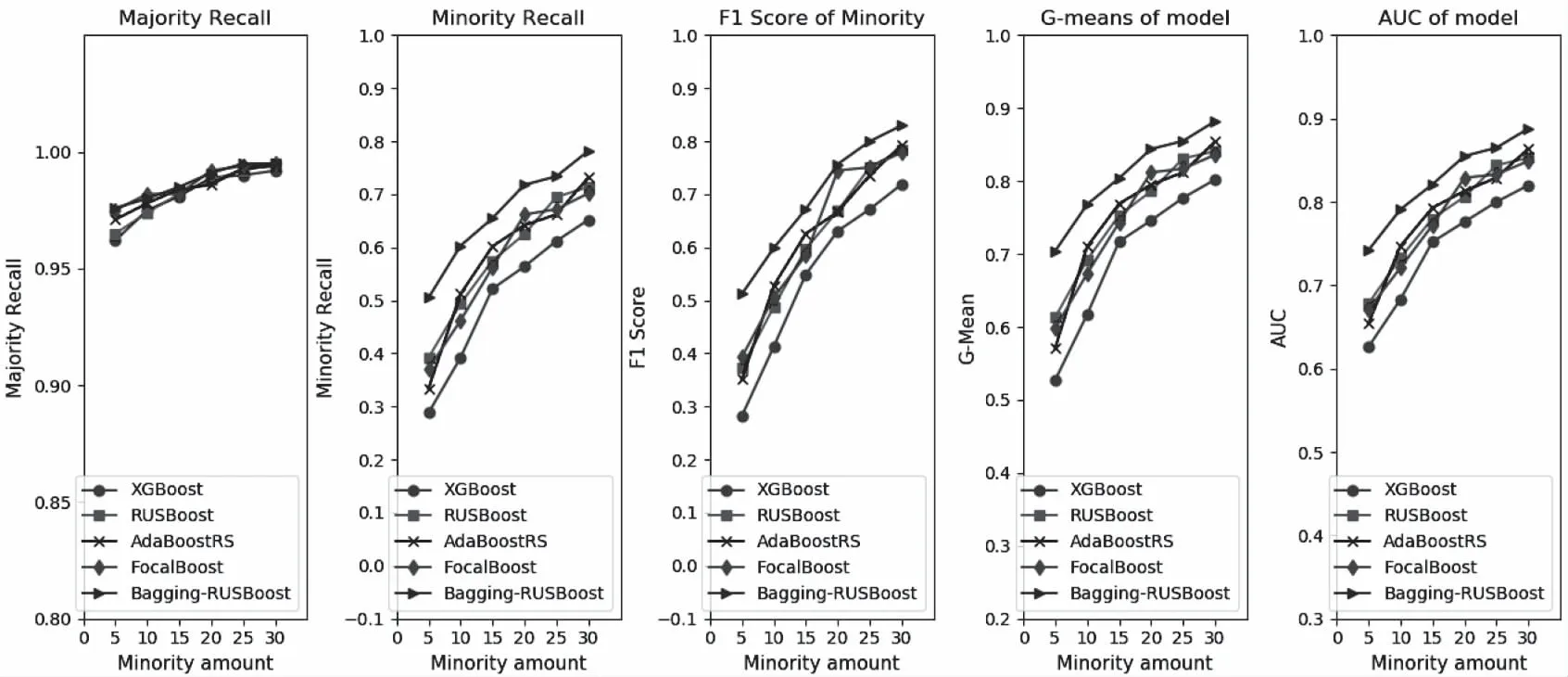
图5 多类训练集下算法的性能对比图
3.4 算法分析
以上实验可以充分证明Bagging-RUSBoost优于其它模型,本节对算法本身进行更深一步的探究。
阈值δ的取值对Bagging组合模型是有影响的,因此阈值参数的选取极为重要。当基分类器数目为10,选取UCI数据集对阈值的变化进行讨论,如图6。

图6 模型在不同阈值下的召回率表现
基分类器的输出为{-1,1},因此阈值的相对取值范围在[-1,1],通过多次实验可以发现,当阈值过大时,少数类的召回率会急剧下降;而阈值过低时,虽然少数类的召回率维持在较高水准,但是多数类性能却会下降,阈值维持在[-0.1,0.1]之间时少数类和多数类召回率都相对良好,因此在选取阈值时要尽量保证两类的召回率处于相对平衡的状态。
Bagging-RUSBoost的时间复杂度为o(kn),k代表基分类器的数目,o(n)为单个基分类器的时间复杂度。由于单个分类器的训练样本是随机抽样产生的,并在散度自编码器进行了特征降维,因此相对于传统的强分类器,样本规模和特征复杂度是降低的,因此分类器有较为良好的时间复杂度特性。在实际实验过程中,基分类器的数目要选取适当,数目过多往往会导致模型过拟合,准确率下降,并且增加了算法的复杂度。
4 结论
本文结合特征层面和算法层面提出了一种基于Bagging思想的RUSBoost组合模型,并得出以下结论:
1) 针对数据分布极端不均衡的情况,本文在RUSBoost模型的基础上,结合了样本权重更新的历史经验,提高少数类的错分代价,在UCI两组训练集少数类召回率达到了0.833和0.846,优于经典RUSBoost算法,降低了单分类器随机性的影响。
2) 采用散度自编码器处理高维数据,瓶颈层增加的KL散度损失函数对两类特征进行了差异区分,使特征表达更加鲜明,图4和图5当少数类减少到5时仍能保持0.5左右的召回率,证明了模型处理高维不平衡样本的优越性。
3) 通过Bagging组合对基分类器进行了加权投票处理,当分类阈值维持在[-0.1,0.1]时两类召回率达到相对平衡。模型在多个数据集均保持了较好的性能,具有较强的泛化能力,为不平衡数据分类提供了一种新思路。
