基于正则性辅助的多目标优化进化算法研究*
2022-06-10龙娟
龙 娟
(广西财经学院信息与统计学院,广西南宁 530003)
多目标优化是在多个优化目标之间选取最优的折中解,即帕累托最优解集(Pareto Optimal Solutions Set,POSS),POSS在目标空间中的映射是帕累托前沿(Pareto Front,PF)。多目标优化方法大致可分为两种:一种是基于聚合技术的传统优化方法,如加权约束法,但该方法需要明确问题的有关信息,权重和约束参数调节困难[1];另一种是多目标优化进化算法(Multi-objective Optimization Evolutionary Algorithms,MOEA),其对冲突目标进行折中,在一次运行中获得一个近似解集,同时在优化进化过程中,将维持种群解视为常数以逼近POSS (或PF)[2],因此非常适合于解决多目标优化问题(Multi-objective Optimization Problems,MOP)。
现有的多目标优化进化算法是先初始化种群,然后循环执行子代重组和环境选择,直到满足终止条件[2]。Zhang等[3]和Zhang等[4]表明环境选择算子和子代重组算子是多目标优化进化算法中的两个关键因素。现有的环境选择研究大多集中在环境选择算子的设计和分析上[5]。一般来说,根据环境选择方法可以将算法分为3类:基于帕累托显性的MOEA是根据帕累托优势关系对种群进行排序,然后估计个体密度,从而选择优势水平和密度较好的解提供给后代[6];基于指标的MOEA是给出每个解的适应度值,并通过优化总体指标间接求解一个多目标优化问题[7];基于分解的MOEA是将一个MOP分解为一系列子问题,然后在基于分解的多目标优化进化算法(Multi-Objective Evolutionary Algorithm Based on Decomposition,MOEA/D)中协同优化这些子问题。MOEA/D作为一种通用的多目标优化进化算法,在分解方法[8]、权重调整、后代繁殖等多方面得以改进。上述MOEA都直接使用为单目标优化设计的子代重组算子,例如模拟二叉交叉(SBX)、粒子群优化(PSO)、微分进化(DE)和分布估计算法(EDA)。这些单目标优化的子代重组算子,在一定程度上忽略了MOEA的性质,导致重组算子在求解多目标优化时的性能较差。与单目标优化不同,MOP需要多个POSS。决策空间中MOP的POSS是分段连续的(m-1)维流形(m是目标数),也可被看作是正则性[3]。正则性对种群解进行划分和建模,然后用(m-1)-D正则性模型(D是维数)来显式逼近POSS。在此基础上,基于概率模型的、具有流形性质的抽样复制也有较多研究[9]。另外,近期的研究主要集中在基于流形性质的交配约束条件[10],利用聚类方法学习种群结构信息,定义解之间的邻域关系,并通过基于邻域的交配重组进行局部利用。上述两种基于规则特性的子代重组算子处理MOP各有优缺点[11],具体来说,基于概率模型的采样和基于邻域的交配重组代表两种不同的子代生成策略。基于概率模型的采样通过概率模型提取种群的全局分布信息,并从构建的模型中抽取新的子代解;而受限于交配限制策略的遗传算子则利用个体的局部信息生成子代解。Sun等[12]指出子代的生成可以结合局部信息和全局信息。在此基础上,Li等[13]提出一种自适应策略,以平衡不同子代重组算子之间的关系。因此,在子代中将局部信息和全局信息结合起来是一种更有效的方法。
为在子代重组中利用更多的信息,通过结合基于概率模型的采样和基于邻域的交配重组,生成子代解和MOEA的流形结构信息,本研究提出一种基于正则性辅助的多目标优化进化算法(Regularity Assisted Multi-objective Optimization Evolutionary Algorithm,RAMEA)。该算法拟使用k-均值聚类方法学习种群结构信息,并用聚类的平均向量建立高斯模型,通过高斯采样和基于邻域的交配重组生成新的子代解;取样的子代解作为交配父代嵌入每个集群中,以生成其他子代解,实现联合全局和局部信息的多目标优化算法,丰富多目标优化算法中输入信息量,提高多目标优化算法的性能。
1 MOEA概述
根据正则性,可认为连续MOP的最优解不是一个随机分布,而是一个规则的拓扑结构。因此,MOEA既可以通过流形结构的近似实现POSS,又可使用聚类算法提取流形结构,并使用结构化信息指导个体的复制,从而提高算法的搜索效率。POSS正则性在MOEA中的应用主要从以下两个方面进行:一是用概率模型来逼近从种群中学习到的MOP的POSS,并从中迭代抽取子解,再利用已建立的(m-1)-D正则性模型来近似多目标分布估计算法[3]中POSS的流形结构;二是进一步提出基于分解和概率建模的MOEA,通过邻域解围绕子问题建立多元高斯模型[11]。简而言之,POSS的流形结构可以用概率模型来近似。
Zhang等[4]提出一种自组织多目标进化算法(Self-organizing Multi-objective Evolutionary Algorithm,SMEA),利用种群的流形结构特性设计交配限制机制,即使用聚类学习方法提取种群结构信息进行重组。自组织映射用于定义解之间的邻域关系,则可通过与相邻解匹配来生成新的子代解。此外,k-均值和谱聚类方法用于执行交配限制。自适应多目标进化算法(Adaptive Multi-objective Evolutionary Algorithm,AMEA)可以利用学习到的种群结构信息进行基于自适应模型的采样和交配限制的混合设计[12]。然而,基于正则性的MOEA也面临诸多挑战。例如,作为分布算法的多目标估计,在基于正则性属性的建模方法中,种群全局分布信息用于建模和采样,因此缺乏单个局部信息,无法保证对个体信息的有效利用[14]。而且,在这些建模方法中,由于概率模型不足所导致的参数敏感性、高计算成本和低效率也受到质疑[12]。就交配限制策略而言,全局探索和局部开发之间的平衡始终是一项具有挑战性的任务,这是由交配限制概率定义所决定的[4]。上述研究虽然设计了一些自适应匹配策略来调整交配限制,但算法的复杂度和计算开销相应增加,其有效性有待进一步验证。
综上所述,减少参数的影响、平衡筛选和交配重组是影响算法性能的关键因素。另外,在基于模型的方法中,种群的全局分布信息可被提取出来用于建模和采样,而个体的局部信息可被用于邻域交配重组。因此,本研究提出一种结合全局信息和局部信息,并基于正则性生成MOEA的高质量解的算法,即RAMEA算法,以期实现多目标优化。
2 RAMEA算法
2.1 RAMEA算法框架
本研究提出的RAMEA算法的主要特点是将子代生成的全局信息、局部信息与POSS正则性相结合。在子代生成中,RAMEA维护一个群体Pop和一个外部种群存档Arch,其中Arch用于保存生成的新解以供环境选择。采用k-均值聚类方法提取种群结构信息,并用每个聚类的均值向量集建立多元高斯概率模型。然后进一步从高斯概率模型中抽取K个采样的子代解嵌入每个聚类中,以改进基于邻域的交配重组。RAMEA算法中,N表示种群的大小,T表示最大进化子代,K表示聚类的数量。算法初始化时,使用种群N的随机解定义Pop的初始值,通过k-均值聚类方法将种群划分为K个聚类,并使用外部种群存档Arch辅助RAMEA进化。计算平均向量μ和协方差矩阵Σ,以建立多元高斯概率模型:
(1)
算法1RAMEA 框架
输入:
N:种群的大小;
T:最大进化子代;
K:聚类的数量;
输出:
总量Pop;
①随机初始化总量:Pop={x1,…,xN};
②令t=1,…,T
③将总量Pop分成K个簇:
C={C1,…,CK},and an archiveArch=∅;
// 高斯建模和采样
④计算均值矢量μ 和协方差矩阵Σ;
⑤每个j=1,…,K
⑥用高斯采样生成试探解:yj=GaussianSample
(μ,Σ)
⑦令Gau=Gau∪yj;
⑧结束
⑨更新Arch:Arch=Arch∪Gau;
// 匹配邻域
⑩每个Ck∈C,k=1,…,K
2.2 RAMEA的子代解生成
RAMEA使用高斯采样和基于邻域的交配重组来生成新的子代解,其中采样解不仅作为子代解,还可以作为交配父代添加到每个集群中。RAMEA的高斯采样算法流程如算法2所示。y=GaussianSample(μ,Σ)是高斯采样函数,其通过Cholesky分解方法将协方差矩阵Σ分解为下三角矩阵Λ,然后从标准高斯分布n(0,1)中采样向量sj(j=1,…,n),最后生成子代解。
算法2高斯采样函数y=GaussianSample(μ,Σ)
输入:
平均方差μ;
协方差矩阵Σ;
输出:
一种新的试验解y;
①执行Cholesky分解:Σ=ΛΛT;从N(0,I)中采样一个向量s=(s1,…,sn);
②生成试验解:y=μ+Λs;
③通过(i=1,…,n)修复解y:
其中ai和bi是变量xi的上下边界;
④返回 采样的试验解y
由于DE算子在单目标优化中的性能往往优于其他遗传算子,RAMEA使用基于邻域的交配重组生成新的子代解,如算法3所示。差分进化函数y=DE(xi,x1,x2)通过使用当前解xi及其交配父代x1、x2生成子代解y。首先使用DE算子生成一个子代解,然后使用多项式变异算子对子代解进行变异。在该算法中,F是DE算子的控制参数,pm为交叉概率,η为交叉分布指数。对于处理复杂的POSS,将另一个DE的参数CR在RAMEA中设置为1,这样可以保证DE运算符在对任何正交坐标旋转保持不变[7]。
算法3差分进化函数y=DE(xi,x1,x2)
输入:
xi和它的两个父代解x1和x2;
输出:
新的解y;
①通过该式产生新的解:y′=xi+F×(x1-x2)
其中ai和bi是变量xi的最低和最高的边界值;
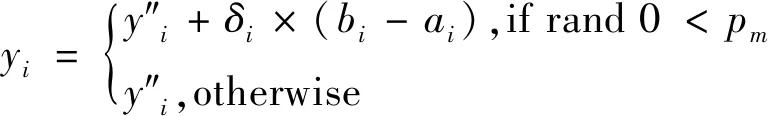
其中r=rand()是一个随机值;
④返回 新解y
2.3 进化算法
RAMEA使用基于超体积度量(Hypervolume,HV)的种群选择方法来更新种群。在算法4中,种群在Pop=Select(Pop,Arch)中更新。FNS()表示快速非支配排序,用于将Pop∪y划分为L个不同的非支配层,其中B1是最好层,BL是最差层。然后,在最差层BL中找到超体积值最差的个体进行移除。在Zhou等[11]中有超体积计算Δφ的详细描述。
算法4Pop=Select(Pop,Arch)
输入:
新的试验解集Arch;
Pop总量;
输出:
更新Pop总量;
①对于每一个yi∈Arch,i=1,…,n执行
②{B1,…,BL}=FNS(Pop∪{yi})
③x*=argminx∈{Pop∪{yi}}Δφ(x,BL)
④令Pop=Pop∪{yi}/{x*}
⑤结束
⑥返回 更新Pop存档
在每一代中都需考虑总体时间复杂度。就子代而言,RAMEA的两种操作包括k-均值聚类过程和复制算子。k-均值聚类过程需要O(TKNn),其中T是迭代次数,K是聚类数,N表示种群大小,n为样本个数。复制算子的时间复杂度为O(Nn)。此外,RAMEA中的基于超体积度量的选择方法,其快速非支配排序的运行时间为O(mN2),HV计算中的运行时间为O(Nm)。综上所述,每一代RAMEA的时间复杂度为O(TNKn+Nn+mN2+Nm)。
3 实验分析
为验证RAMEA的正确性和有效性,实验用44个测试实例比较分析RAMEA与AMEA (Assisted Multi-Objective Optimization Evolutionary Algorithm)、RM-MEDA (Regularity Model-based Multi-Objective Estimation of Distribution Algorithm)、IM-MOEA (Improved Multi-Objective Evolutionary Algorithm)、SMEA、MOEA/D-DE、NSGA-Ⅱ (Nondominated Sorting Genetic Algorithm-Ⅱ)、SMS-EMOA (S-metric Selection-Estimation Multi Objective Algorithm ) 7种算法,其中NSGA-Ⅱ和SMS-EMOA算法中的模拟二进制交叉算子被DE算子替换。实验使用F1-F10[3]、IMF1-IMF10[9]、ZDT1-ZDT6[15]、F1-F9[16]和WFG1-WFG9[17]测试数据。实验参数设置对算法的性能有很大的影响,因此实验为每个被比较的算法选择最佳参数,其中NSGA-Ⅱ和SMS-EMOA算法只需要DE和PM的控制参数。
为证明RAMEA的性能,并衡量MOEA解的收敛性和多样性,实验采用反世代距离(Inverted Generational Distance,IGD)[18]和超体积度量两种常用的质量指标。假设P*表示沿整个PF均匀分布的一系列已知最佳点,P表示由MOEA获得的近似前沿(Approximation Front,AF)。IGD指示器的定义如下:
(2)
超体积度量定义为
HV(P,z)=
(3)
式中,VOL()是勒贝格测度,z=(z1,…,zm)T是所有帕累托最优解的参考点,设置z=1.1×max(f1,…,fm)。通过计算近似前沿和参考点之间的空间体积,HV可以判断近似前沿的优劣。HV值越大,近似前沿越好。
表1总结44个实例中8种算法在IGD和HV方面的指标性能,包括通过Wilcoxon秩、检验获得的平均秩和统计结果。在测试实例上的实验结果表明,RAMEA的平均秩显著低于其他对比算法,因此RAMEA具有良好的收敛性和多样性。

表1 8 个 MOEAs 在 44 个测试实例上关于IGD和HV指标的性能Table 1 Performance of 8 MOEAs on 44 test instances in terms of IGD and HV metrics
在RAMEA中,聚类数K是一个重要参数,决定了高斯模型和采样子代解的序列解数。为研究该参数的灵敏度,使用GLT测试实例分别在K=3,5,8,10,15的情况下测试RAMEA,每个实例执行20次。从表2可以看出,不同的K值对ZDT1-ZDT5实例的IGD值的平均值和标准差没有明显影响。对于ZDT6,平均值为相邻值,且当K=8时标准差最低。简而言之,RAMEA能够为ZDT1-ZDT6产生相对较小的IGD值,但不是非常显著,这表明RAMEA对聚类数K不敏感。

表2 RAMEA获得的IGD度量值的统计结果[平均值(标准差)]Table 2 Statistical results(mean(std.dev.)) of the IGD metric values obtained by RAMEA
为研究高斯采样对RAMEA性能的影响,研究比较了RAMEA的两个其他变体:RAMEA*(RAMEA中无高斯采样)和RAMEA+(取样解仅作为子代)。实验在WFG测试实例(2个目标,11个变量)中进行,最大生成数设置为300。如表3所示,在9个文本实例中,RAMEA在其中6个实例上的表现优于另外两个变体。平均秩越小,说明算法效果越好。就平均排名而言,RAMEA是最好的,而变体RAMEA*排名最后。RAMEA性能优异的两个原因在于高斯采样与邻域交配相结合,以及把取样子代解作为交配父代,而不仅仅是子代。

表3 RAMEA*、RAMEA+和RAMEA在WFG测试实例上得到的IGD统计结果Table 3 Statistical results of IGD obtained by RAMEA*,RAMEA+ and RAMEA on WFG test instance
4 结论
本研究提出的RAMEA综合了高斯概率模型采样和交配重组两种策略的优势,且利用种群全局分布信息和个体局部信息,通过k-均值聚类方法将每一代种群划分为K个不同的聚类,用K个聚类的均值向量建立高斯模型,通过高斯采样和基于邻域交配重组生成子代解。实验结果表明,RAMEA算法的收敛性和多样性优于文中对比的算法,未来可以将本研究方法与不同的MOP及应用结合,用于动态多目标优化、特征选择等研究领域。
