基于量化修正的低复杂度LDPC译码算法*
2022-06-10杜立婵黄绎珲王文静黎相成
杜立婵,黄绎珲,王文静,聂 晶,黎相成,3**
(1.南宁职业技术学院人工智能学院,广西南宁 530008;2.广西大学计算机与电子信息学院,广西南宁 530004;3.广西多媒体通信与网络技术重点实验室,广西南宁 530004)
现代通信系统自出现以来,实现更安全、更高效及更可靠的通信方式是人类一直以来追求的目标。随着信息技术的高速发展,特别是在深度学习和人工智能等领域取得的巨大进步,大大加速了云计算、无人驾驶以及车联网等新型技术的应用。同时,对通信系统也提出了更高的可靠性、更小的时延以及更大的数据带宽要求。信道编码是通信系统中的基础核心技术,(Low Density Parity Check,LDPC)译码作为优秀的信道编码方案,具有纠错性能好且易于并行译码的特点,吸引了来自国内外众多研究者的关注。LDPC码由Gallager[1,2]首次提出,但受限于当时的硬件技术水平,其译码算法难以实现,在此后的30多年间基本被研究者忽略。到20世纪90年代中后期,随着计算机及硬件技术的发展,特别是Mackay等[3-6]开展的系列研究,重新掀起了人们对LDPC码的关注,围绕LDPC码的研究取得了大量实用的研究成果[7-11]。由于众多研究者的努力,在2016年底,3GPP RAN1#86次会议决定将准循环LDPC码确定为5G-eMBB通信环境下大数据包(长码)的信道编码方案。
一般情况下,可以将LDPC码的译码算法分为以下3个种类[12]:①软判决译码算法,②硬判决译码算法,③基于可靠度的译码算法。软判决译码算法主要为和积译码算法(SPA)与其改进算法,在上述算法中性能最优,但由于在算法中采用浮点数乘法以及对数运算,其计算复杂度非常高。早期的硬判决算法主要有Gallager教授[1]的比特翻转(BF)译码算法,以及Lin等[13]提出的一步大数逻辑译码(OSMLGD)算法。其中BF译码算法的核心思想为采用该比特参与运算的校验和进行判断是否翻转该位,而OSMLGD是首个类MLGD译码算法,两者的计算复杂度都极低,由于采用信道的硬判决信息进行译码,译码信息损失较大,所以译码性能较差。最近,Liu等[14]通过引入比特位自适应阈值门限策略,避免了全局最大值搜索处理,实现了高吞吐量、低时延的BF译码算法,特别适合硬件实现。硬判决与软判决译码算法均存在明显的优缺点,研究者们结合两类算法的特点展开研究,提出了一类基于可靠度的译码算法,实现了性能与复杂度之间的均衡。例如,Huang等[15]提出基于可靠度的迭代大数逻辑译码(RBI-MLGD)算法,该算法对初始信道信息进行量化处理,作为信道信息的可靠度量,在译码迭代过程中,通过在校验节点获取外信息对变量节点的可靠度信息进行更新处理,结合大数逻辑的处理策略实现译码性能的提升。此外,Chen等[16]在RBI-MLGD算法的基础上提出了改进的译码(MRBI-MLGD)算法,该算法的核心思想是在迭代译码信息更新过程中引入修正系数,同时,只在初始信道信息的基础上进行信息更新处理,提高了译码信息的迭代更新效率,以此实现了译码性能的提升。由于MLGD类算法具有低复杂度、低时延的特点,研究者一直对其开展相关研究。最近,Song等[17]针对多元LDPC译码算法,基于软可靠度迭代IISRB-MLGD译码算法,提出了一种裁剪的CM-IISRB译码算法。该算法采用非饱和截切策略,在较低复杂度的情况下,实现了更优的译码性能。
在MRBI-MLGD译码算法中,由于引入了缩放因子,即采用了乘法修正系数,不可避免地增加了大量的浮点数乘法运算,其译码复杂度随着迭代次数的递增而明显增大。受MRBI-MLGD算法在译码迭代过程中引入缩放因子的启发,本文提出了一种基于量化修正的低复杂度LDPC译码算法,该算法在对信道信息预处理时引入量化信息修正处理策略,从而避免在译码迭代过程中进行译码信息修正处理操作,在保持译码性能的同时,较大幅度地降低了译码复杂度。基于上述算法思想,针对均匀和非均匀量化方案,本文具体实现了基于修正系数的均匀量化和基于列重信息修正的非均匀量化两种译码方案设计,期望所提出的译码方案在降低译码复杂度的同时,还能保持一定的译码性能。
1 数字通信模型及相关定义
定义H=[hi,j]m×n(hi,j∈2)为一个稀疏矩阵,如矩阵H具有恒定的行重ρ,即每行非零元素个数,恒定的列重γ,即每列非零元素个数,则定义为规则LDPC码。为方便接下来对本文算法进行描述,定义以下两个集合:①定义矩阵H中第i行非零列下标集合Ni={j:0≤j≤n-1,hij≠0};②定义矩阵H中第j列非零行下标集合Mj={i:0≤i≤m-1,hij≠0}。设传输的信息序列为经过LDPC编码后可以得到码字序列其中,满足cHT=0。接下来对获得的LDPC码字序列c进行调制,获得发送的实数信号序列x=(x0,x1,…,xn-1),可采用BPSK进行调制,本文具体实现方法为xj=1-2cj。然后,把信号序列x经过加性高斯白噪声信道(AWGN)进行传输,在接收端即可获得一个接收信号序列y=(y0,y1,…,yn-1),该序列由发送信号叠加一个高斯白噪声信号,可以表示为yj=xj+nj,其中,nj为高斯白噪声,且满足nj~N(0,σ2)。
2 MRBI-MLGD算法描述

(1)
在获得硬判决序列z后,可以计算其相应的校验伴随式s=zHT,其中,s=(s0,s1,…,sn-1),实现计算方法如下:
(2)
式中,hi,j为校验矩阵H中的元素,符号⊕为模2加运算,上标k表示第k次迭代。如s=0则表示当前判决码字校验成功,可输出码字序列z=(z0,z1,…,zn-1);如s≠0则表明校验失败,继续进入迭代译码过程。接下来对具体的迭代译码过程进行描述。
① 计算外信息。

(3)
式中,符号Nij表示除了当前j列的其他列的序号集合。
② 计算总外信息。
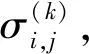
(4)
③ 更新可靠度。
(5)

3 基于量化修正的译码算法设计
基于以上分析,为降低译码复杂度,本文提出了通过在信道信息初始预处理时引入量化修正处理,在迭代过程中不再使用信息修正操作,实现译码复杂度的降低。针对均匀和非均匀量化方案,本文提出了两种量化修正方案,一种为基于修正系数的均匀量化译码方法,具体地,该方法通过在量化函数中引进修正系数,避免在译码迭代中引进浮点乘法运算,在保持译码性能的前提下,实现了译码迭代过程中计算复杂度的明显下降;另一种为基于列重γ与量化比特b的改进型非均匀量化方案,在对3-4 bits极低量化比特的情况下,也能保持较优秀的译码性能,同时,其算法复杂度和硬件资源消耗也大为降低,该方案可用于硬件资源遭受限制的场景。
3.1 基于修正系数的均匀量化及译码方案设计
由译码判决信息规则和量化原理可知,在不改变信道信息可靠度极性的情况下,不会影响LDPC码字的判决,因此,可以对可靠度值进行缩放处理。为了避免在迭代译码过程中引入乘法修正运算,降低迭代译码过程的计算复杂度,本文提出的算法1为在对信道信息量化预处理时引入修正系数β,对量化值进行预修正处理。具体计算方法如下:
(6)
式中,b为量化比特位数,Δ为量化间隔。采用修正系数β对量化值进行修正,通过修正处理,使信道初始可靠度值与译码迭代过程中的译码信息更新在数值上相适配,从而实现更有效的译码信息更新,获得译码性能的提升。其中,β值可以通过仿真搜索获得。
此外,在MRBI-MLGD算法中变量节点信息更新策略式(5)修改如下:
(7)
对本文提出的算法1——基于修正系数的均匀量化方案及LDPC译码算法具体实现步骤描述如下。
步骤1:输入。
最大迭代次数Imax,接收信号向量y,修正系数β,量化参数b和Δ。
步骤2:初始化。
按式(6)对接收信号y进行量化得到qj,将迭代次数k置0,对0≤j≤n-1,令初始可靠度
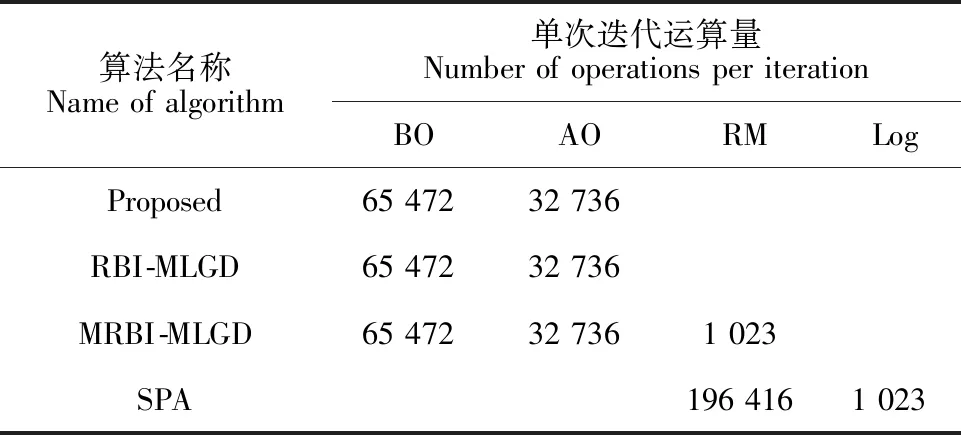
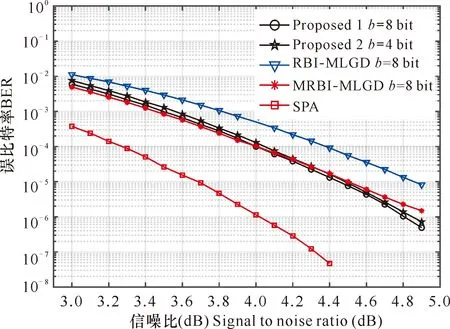
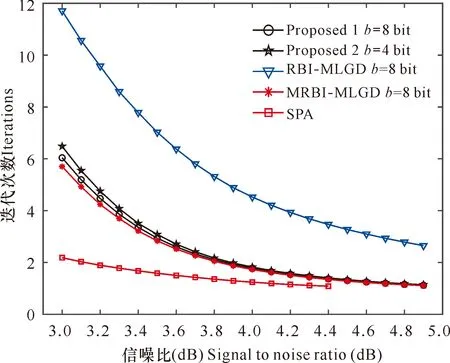
步骤3:迭代过程。对k ① 按式(1)计算硬判决序列z(k); ② 按式(2)计算校验和s(k),如果s(k)=0,则执行步骤4; ⑥ 迭代次数k=k+1。 步骤4:输出。 输出硬判决序列z(k)。 qj= (8) 本量化设计方案也是采用在量化预处理阶段对信道信息进行相应处理,因此,其译码迭代时可靠度的更新规则采用式(7)进行。 对本文提出的算法2——基于列重修正的非均匀量化及LDPC译码算法具体实现步骤描述如下。 步骤1:输入。 最大迭代次数Imax,接收信号向量y,修正系数β,量化参数b和Δ。 步骤2:初始化。 按式(8)对接收信号y进行量化得到qj,将迭代次数k置0,对0≤j≤n-1,令初始可靠度 步骤3:迭代过程。对k ① 按式(1)计算硬判决序列z(k); ② 按式(2)计算校验和s(k),如果s(k)=0,则执行步骤4; ⑥ 迭代次数k=k+1。 步骤4:输出。 输出硬判决序列z(k)。 本文提出的基于量化修正的译码算法复杂度主要由以下几个部分组成: ① 式(1)计算硬判决z(k)时,需要进行n次逻辑运算; ② 式(2)计算校验和s(k)时,需要m(ρ-1)=nγ-m次逻辑运算(其中ρ为行重,mρ=nγ为校验矩阵H的非零因子的个数); 同时,本文对RBI-MLGD、MRBI-MLGD及经典的SPA算法进行了复杂度分析。详细的复杂度对比情况如表1所示。 表1 单次译码迭代计算复杂度比较Table 1 Comparison table of computational complexity of single decoding iteration 其中,BO为二进制操作,AO为加法运算,RM为实数乘法,Log为对数运算。从表1可以看出,本文提出的改进算法与原始的RBI-MLGD算法复杂度基本一致,本算法相比MRBI-MLGD算法,省掉了译码迭代过程中可靠度更新时的实数乘法计算,将会明显降低译码迭代过程中的复杂度。为直观地看出单次计算复杂度的数值情况,下面对具体的LDPC码单次计算复杂度进行数值计算。 表2 2(1 023,781)规则循环LDPC码单次迭代计算复杂度Table 2 2 ( 1 023, 781 ) single iteration computational complexity of regular cyclic LDPC codes 表2 2(1 023,781)规则循环LDPC码单次迭代计算复杂度Table 2 2 ( 1 023, 781 ) single iteration computational complexity of regular cyclic LDPC codes 算法名称Nameofalgorithm单次迭代运算量NumberofoperationsperiterationBOAORMLogProposed6547232736RBI MLGD6547232736MRBI MLGD65472327361023SPA1964161023 表3 2(255,175)规则循环LDPC码单次迭代计算复杂度Table 3 2 ( 255, 175) single iteration computational complexity of regular cyclic LDPC codes 表3 2(255,175)规则循环LDPC码单次迭代计算复杂度Table 3 2 ( 255, 175) single iteration computational complexity of regular cyclic LDPC codes 算法名称Nameofalgorithm单次迭代运算量NumberofoperationsperiterationBOAORMLogProposed81604080RBI MLGD81604080MRBI MLGD81604080255SPA24480255 根据上文的算法描述,继续通过计算机仿真的方法,对提出的译码算法进行仿真实验,考察其译码性能。 实验1:实验采用基于欧式几何方法构造的2(1 023,781)规则循环LDPC码[18]进行仿真实验,其仿真参数采用以下设置:① 对均匀量化,量化比特b=8 bit,量化间隔Δ=0.015 6;② 对MRBI-MLGD译码算法,设置缩放因子α=3.1;③ 对算法1,设置修正系数β=0.322 58;④ 对算法2采用非均匀量化,设置量化比特b=4 bit,r=0.88。所有算法中,最大仿真迭代次数均设置为Imax=30。译码BER性能仿真曲线如图1所示。 从图1可以看出,在中高信噪比区域,算法1与MRBI-MLGD算法拥有几乎相同的译码性能,而相较于RBI-MLGD算法具有约0.3 dB的性能增益,与SPA译码算法仅有约0.6 dB的译码性能差距;算法2由于采用了较低的量化比特,译码性能稍差于算法1,但仍然明显优于RBI-MLGD算法。 图1 对2(1 023,781)LDPC码的译码BER性能比较Fig.1 BER performance comparison of 2(1 023,781) LDPC code 图2 对2(1 023,781)LDPC码的译码平均迭代次数比较Fig.2 Comparison of decoding average iterations of 2(1 023,781) LDPC code 实验2:实验采用2(255,175)规则循环LDPC码[18]进行仿真实验,其仿真参数采用以下设置:① 对均匀量化,量化比特b=8 bit,量化间隔Δ=0.015 6;② 对MRBI-MLGD译码算法,设置修正系数α=7.0;③ 对算法1,设置修正系数β=0.143;④对算法2采用非均匀量化,设置量化比特b=4 bit,r=0.88。所有算法中,最大仿真迭代次数均设置为Imax=30。译码BER性能仿真曲线如图3所示。 从译码性能曲线(图3)可以看出,算法1在中信噪比范围区间与MRBI-MLGD算法几乎具有相同的译码性能,同时优于RBI-MLGD译码算法近0.4 dB的译码性能。与SPA译码算法具有约0.7 dB的性能差距;算法2在量化比特b=4 bit的情况下,仍实现了与MRBI-MLGD算法几乎相近的译码性能,同时,与SPA算法有约0.7 dB的性能差距。而在高信噪比区域,本文算法仍具有较优异的译码性能,出现了译码性能曲线明显优于MRBI-MLGD算法的趋势。 图3 对2(255,175) LDPC码的译码BER性能比较Fig.3 BER performance comparison of 2(255,175) LDPC code 从译码平均迭代次数曲线(图4)可以看出,算法1的译码迭代收敛速度明显高于RBI-MLGD译码算法,与MRBI-MLGD算法保持了一致的迭代收敛速度。此外,在较高信噪比时,其译码收敛速度几乎接近SPA算法。算法2在量化比特较低的情况下,仍然实现了较高的译码收敛速度,收敛速度性能与算法1一致。 图4 对2(255,175) LDPC码的译码平均迭代次数比较Fig.4 Comparison of decoding average iterations of 2(255,175) LDPC code 本文在对信道信息进行量化预处理时,通过引入量化修正的信息处理策略,提出了基于量化修正的低复杂度LDPC译码算法。该算法避免了在译码迭代过程中进行信息修正处理操作,较大幅度地降低了译码复杂度,同时保持了较好的译码性能。本文具体实现了算法1为一种基于修正系数的均匀量化方案及译码算法设计;算法2为一种基于列重修正的非均匀量化方案及译码算法设计。其中,算法1通过在信道信息量化预处理时,在量化函数中引入修正系数,避免在译码迭代中的浮点乘法运算,实现了译码迭代过程中计算复杂度的明显下降;算法2通过在非均匀量化预处理时引入列重γ信息,实现了信道信息量化可靠度值与列重γ相适配的比拟关系,在迭代过程中获得更高效的译码信息传递和更新。仿真结果表明,在保持译码性能的情况下,本设计有效地降低了译码复杂度。
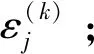
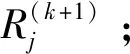
3.2 基于列重修正的非均匀量化及译码方案设计
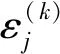

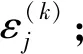
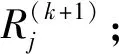
4 译码复杂度和性能仿真分析
4.1 译码复杂度


4.2 译码性能


5 结束语
