考虑数据周期性及趋势性特征的长期电力负荷组合预测方法
2022-06-08姜山周秋鹏董弘川马旭赵振宇
姜山,周秋鹏,董弘川,马旭,赵振宇
(1.国网湖北省电力有限公司经济技术研究院,武汉 430077;2.华北电力大学工程建设管理研究所,北京 102206)
0 引 言
长期电力负荷的准确预测对电网规划及电力基础设施建设具有重要战略意义。近年来,长期电力负荷预测多以年度负荷值的总体趋势预测为主[1],较少考虑预测中数据惯性增长、周期性变化以及数值的累积效应,进而影响了负荷预测的准确性。因此,模型建模需要考虑年度负荷增长应基于月度负荷累积的情况,以提高模型区间预测的分段精度,确保预测的准确性,将基于此项工作开展数据趋势性和周期性预测的组合方法研究。
电力负荷预测方法包括参数化预测方法及非参数化预测方法。基于数据参数化特性的分析算法主要有机械学习算法及时间序列算法,机械学习如神经网络学习[2]、SVM支持向量机[3]、决策树等. 该类方法采用迭代思维进行数据寻优从而求得数据最优解;时间序列ARIMA等方法通过人工参数设置实现数据自身发展趋势规律的分析预测。为提高时间序列数据的预测精度,可将多种机械学习算法与ARIMA方法复合,实现数据的耦合修正[4]。非参数方法是一类直接或间接地从实际系统的实验分析中得到的响应分析方法. 如通过实验记录得到的系统脉冲响应或阶跃响应[5],该类算法可充分挖掘数据自身规律的周期特性,基于数据的周期性通过数据的降维处理以预测区间单元内数据走势。为进一步提高长期电力负荷趋势预测的准确度,将电力负荷数据进行年度及月度分解,把用以研究数据自身发展规律的ARIMA[6]方法融入BP神经网络算法内,提出改进的BP-ARIMA负荷趋势预测模型,实现在多因素综合影响下的年度电力负荷预测功能;引入函数型非参数方法对历年月度数据进行数据分析,通过函数型时间序列预测模型对未来数据进行周期性预测,将趋势性预测及周期性预测进行分量融合以得到新型组合预测模型,从而提升长期电力负荷预测的精确性。
1 基础理论
为研究负荷数据发展特性,提出的新型组合预测模型是基于BP-ARIMA趋势性预测及函数型非参数化周期性预测的综合预测模型。BP-ARIMA模型是基于BP神经网络及ARIMA模型进行影响因素耦合获取趋势线而形成的改良方法,函数型非参数化方法通过引入适宜核函数对月度负荷开展周期性预测工作。
1.1 BP人工神经网络模型
BP人工神经网络可实现输入端与输出端非线性函数的函数映射问题[7],具体算法可通过如下步骤实现。确定输入向量X=[x1,x2,…,xn]T,输出向量Y=[y1.y2. ….yn]T。设置初始化输入层至隐含层连接权值ωij,隐含层至输出层连接权值ωjk;具体过程函数为:
(1)
式中f1()、f2()分别为输入层至隐含层、隐含层至输出层神经网络激活函数,以上为输入模式的顺向传导过程,利用顺向传导过程所得输出值求得输出层校正误差,再将输出层误差经由隐含层逆向传导至输入层,循环往复直至训练稳定。
1.2 ARIMA模型
ARIMA(p,d,q)模型[8],是一种根据数据自身规律揭示系统动态结构及发展规律的时间序列模型。文中该模型应用于影响因素趋势预测及趋势线提取校核,ARIMA模型须将序列数据进行一次或多次差分以得到平稳时间序列,基于数据的复杂程度对数据进行分析建模,模型表达式为:
(2)
式中∇d=(1-A)d为数据的d阶差分项;Φ(A)=1-φ1A-φ2A2-…-φpAp为模型的自回归相关系数多项式;Θ(A)=1-θ1A-θ2A2-…-θqAq为滑动平均系数多项式。
1.3 函数型非参数化方法
函数型非参数回归模型[9]可对周期性数据进行函数性质的数据统计及预测,将观测区间内一次观测到的数据视为整体,利用函数型数据分析方法对无限维中具有函数性质的数据进行结构分析,降低数据整体维度,提高数据推断的准确度。函数模型表达式为:
(3)
式中Xi为函数型变量;响应变量Yi为实值变量;εi为误差项,构成(Xi,Yi)数据对。通过Nadaraya-Watson(N-W)核估计方法对函数型非参数模型进行回归函数估计. 具体估计模型表达式为:
(4)
式中K为对称核函数;窗宽h=hn为正实数序列;φ(h)为小球概率。
1.4 因素相关性检验
相关系数大小决定自变量与因变量间的相关性强弱. 检查自变量与因变量间的共线性程度。通过分析数据之间的相互依存关系,为数据的远期预测提供趋势框架. 防止预测效果失真。采用皮尔森相关性系数对影响因素与年度负荷数据进行相关性检验,相关性系数表达式为:
(5)
式中Cov(X,Y)为X、Y序列数据协方差;σx,σy为X、Y序列数据标准差。
2 模型构建
所研究的基于函数型非参数方法的BP-ARIMA预测模型将时间序列数据进行分解,在采用相关性检验对影响因素进行初步筛选的情况下,利用BP-ARIMA模型对时序性数据的年度负荷数据进行趋势预测,利用函数型非参数方法对周期性月度负荷数据进行回归估计。通过两类数据的分量组合,提高模型长期预测的稳定性及准确性,流程见图1。
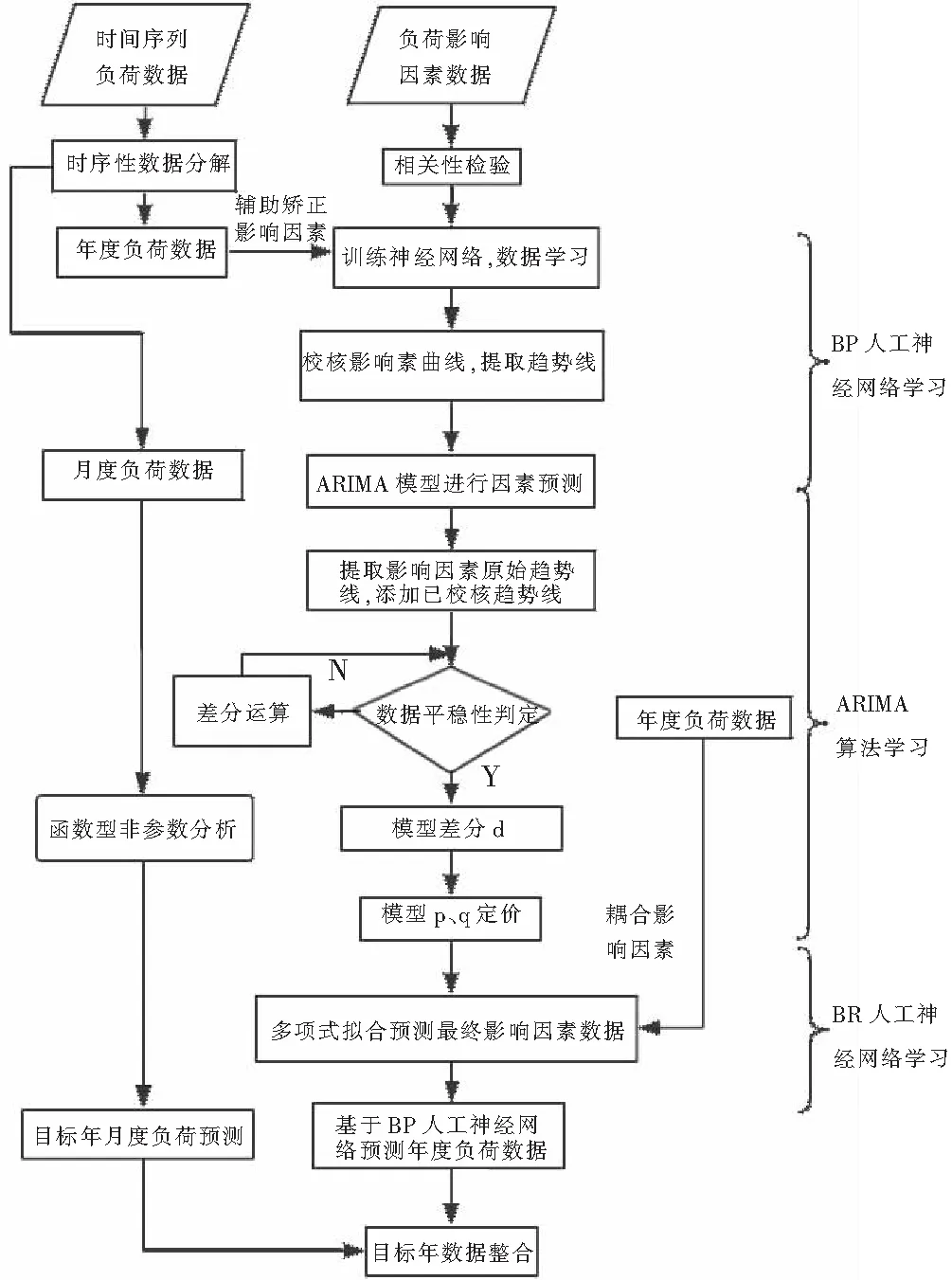
图1 负荷预测流程图
2.1 基于BP-ARIMA的年度负荷预测
模型将区域电力负荷与区域生产总值、工业增加值、可支配收入等经济性、社会性指标相关联[10]。提取各项因素数据的预测值,基于各影响因素耦合特点,对数据采取拟合分析,明确影响因素数据的精确走势,并依据各个影响因素走势及年度负荷数据进行BP神经网络的数据训练,获得年度电力负荷趋势预测值。
采用MATLAB数据分析软件[11],编制BP-ARIMA年度负荷预测模型,建模步骤如下:
(1)通过相关性检验方法初步检验影响因素与年度负荷值的相关性程度;
(2)电力负荷通过BP神经网络对各影响因素数据进行神经网络训练。基于校核后的因素预测数据. 提取影响因素趋势数据,趋势线可精确判断数据走势及数值范围;
(3)ARIMA模型进行各个影响因素的趋势预测,采用已校核的趋势线置换影响因素原始趋势线。该过程可通过趋势线预测进行进一步相关性检验,剔除呈弱相关性影响因素,利用多项式拟合方法输出因素预测值;
(4)将各校核之后的影响因素数据与年度负荷数据耦合,开展年度负荷趋势预测。
2.2 电力负荷长期预测的相关影响因素
从已有研究看,学者普遍采用经济与社会指标分析对电力负荷的影响。由于区域GDP、区域财政投资、区域人口增长等对区域电力负荷增长起到正向促进作用,因此区域电力负荷增长及电力基础设施建设与区域经济、社会指标增长存在必然联系[12]。综合现有研究,从经济发展、社会发展和工业生产角度进行相关数据的收集、整理与分析,相关影响因素如表1所示。
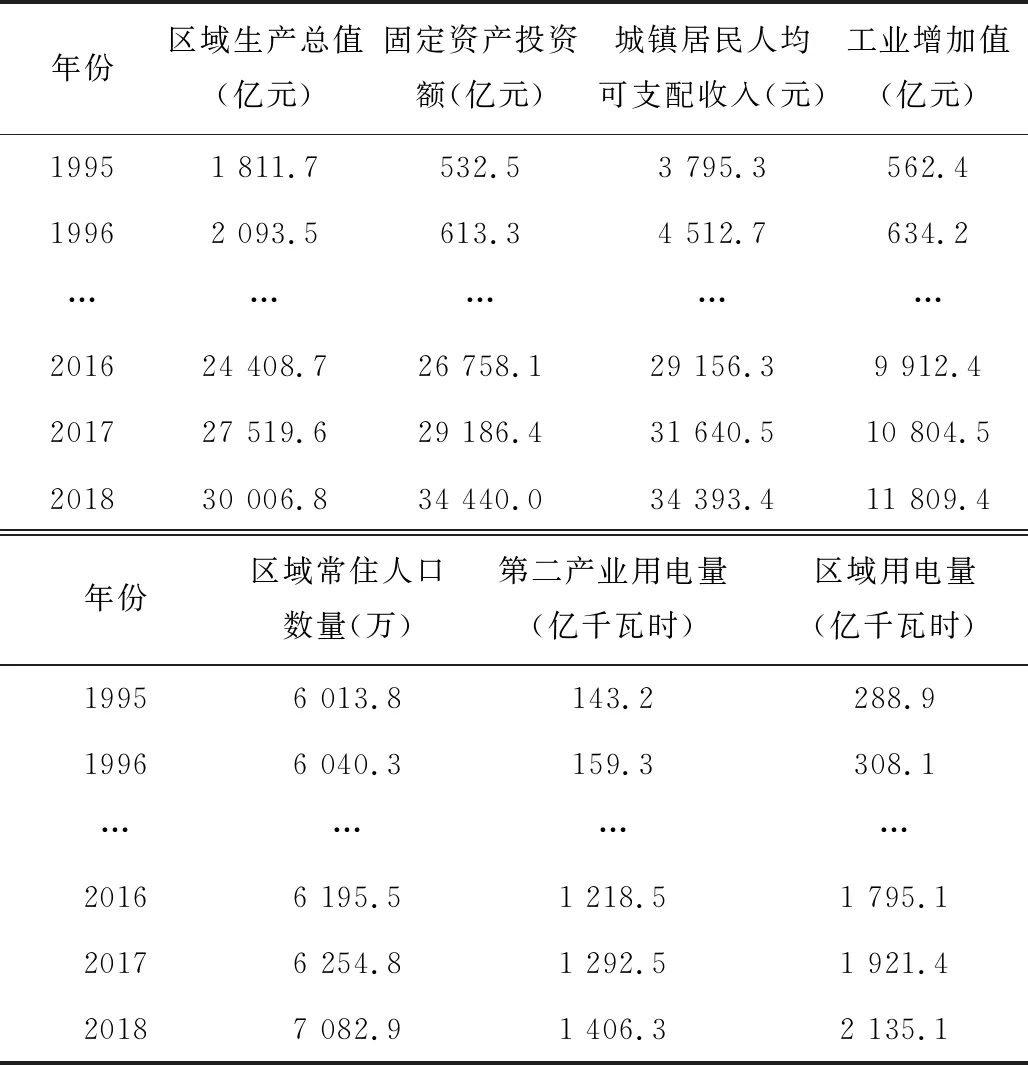
表1 1995年~2018年度用电量及相关因素统计数据
2.3 基于函数型非参数方法的月度负荷预测
区域月度负荷数据存在周期性递增特性,针对该类时间序列数据,以整年(周期T=12)为单位生成函数型数据,设生成随机变量F,F在t=a到时间t=a+nT上的观测值构成一个连续的时间序列F(t)。月度负荷数据可看成是按周期T重复统计得到的。函数型数据[13]表达式为:
(6)
式中fi为第i年负荷函数型数据,依据式(6)第三项可将观测区间的[a,a+nT]上的连续时间序列F(t)转化为{f1,f2,…fn},依据{f1,f2,…fn}即可预测fn+1等远期月度负荷数据。本预测模型通过{f1,f2,…fn}构建函数型数据对。选取的核函数及半度量参数公式如下:
(7)
半度量参数的选取基于周期曲线导数,d(xi,yi)中q值影响曲线的拟合程度。函数型非参数法还通过核函数中的窗宽(h)影响曲线拟合程度,通过交叉验证的形式自动获取窗宽。即:
(8)
从观测到的(Xi,Yi)数据对中剔除最后第n项,基于前n-1项对数据进行函数型回归分析。通过CV(h)取最小值时确定h的取值。将预测的第n项数据与负荷真实值进行比较,确定周期性函数预测的准确性。
综合预测模型将年度趋势性负荷预测与月度周期性负荷预测进行分量组合,可通过平均绝对百分误差(MAPE)权重法[14]对月度负荷及年度负荷分配权重. 提高模型预测可靠性、准确性。负荷预测权重分配函数为:
(9)
式中Pload为负荷分量组合预测值;pm,py分别为月度负荷值、年度负荷值;ωm,ωy为月度、年度负荷值权重。
3 算例分析
3.1 实例数据
引入我国中部某省区域生产总值、固定资产投资额、年度区域用电量等指标,数据见表1,为提高负荷预测准确率,引入2006年~2018年间月度负荷指标,如表2所示。

表2 2006年~2018年间月度用电量统计数据
注:月度负荷单位为:亿千瓦时
3.2 数据分析
研究采用BP-ARIMA模型的相关通用参数及改进的ARIMA算法差异性参数见表3。其中n值为采用多项式拟合方法中多项式的最高次幂[15]。

表3 BP-ARIMA模型通用及差异性参数
将各影响因素分别与年度负荷值进行相关性检验,区域常住人口数量相关性系数较低,呈弱相关性. 各影响因素相关系数如表4所示。

表4 相关性检验
采用年度电力负荷值对各影响因素值进行神经网络训练,校核各影响因素趋势线。以城镇居民人均可支配收入因素为例,如图2所示,“菱形”标趋势线从“圆形”标校核值序列中被提取出,并且将该校核的趋势线植入原始数据中,形成“星形”标改良值,该法可对影响因素趋势线进行一定程度的修正。依据ADF及AIC准则对各影响因素进行p、q、d判断,采取最优数组组合模拟,数据如表3所示。

图2 城镇居民人均可支配收入趋势线分解及优化图
通过模型校核过程中的影响因素趋势预测发现,区域常住人口数量的模型走势吻合程度较差,再次验证了该因素与年度负荷值的弱相关性,数据模拟失真,效果如图3所示。

图3 常住人口数模拟结果
经校核的ARIMA模型可基于数据结构特性对其余强相关性的影响因素开展目标年预测,研究将1995年~2015年数据作为模拟样本数据,对2016年~2018年三年进行预测,部分影响因素预测效果对比见图4和图5。

图4 固定资产投资额模拟结果

图5 工业增加值额模拟结果
将经过筛选及校核的影响因素与年度电力负荷通过BP-ARIMA预测模型进行多因素耦合预测,该模型为基于影响因素及负荷序列数据趋势性发展的一类预测,年度区域用电量预测数据如图6,图中2019年~2021年为电力负荷模型预测值,未来三年电力负荷仍为增长趋势,但增长速度有所放缓。

图6 BP-ARIMA预测模型年度电力负荷预测值
研究基于函数型非参数化方法对月度电力负荷数据开展周期性预测,算法模型采用2006年~2015年间月度负荷数据进行非参数化算法学习,预测2016年~2021年间月度负荷数据,比对2016年~2018年间月度真实数据,真实值与预测值吻合程度较好,预测及对比结果如图7所示。
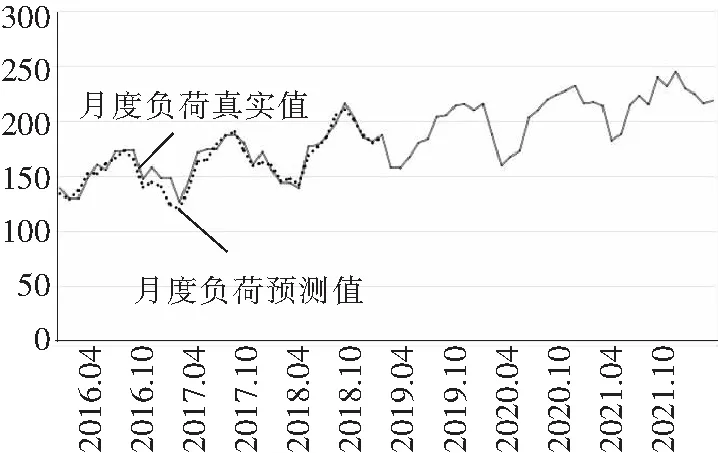
图7 函数型非参数方法月度电力负荷预测值
将BP-ARIMA模型与函数型非参数方法进行组合预测,2016年~2018年趋势性预测值与周期性预测值进行MAPE权重方法组合。函数型非参数预测方法MAPE值1.17%小于BP-ARIMA的1.93%,经两种方法的分量融合,新型组合模型的MAPE值为1.59%,误差结果相对理想,负荷预测数据如表5所示。

表5 研究模型预测结果
为体现该新型组合模型的预测优势,研究分别采用灰色预测模型GM(1,1)、GM(1,N)、BP神经网络模型、ARIMA模型等与该组合模型进行比较,误差结果见表6,新型组合预测模型预测精度最高,MAPE值仅为1.59%,具有明显的预测优势。
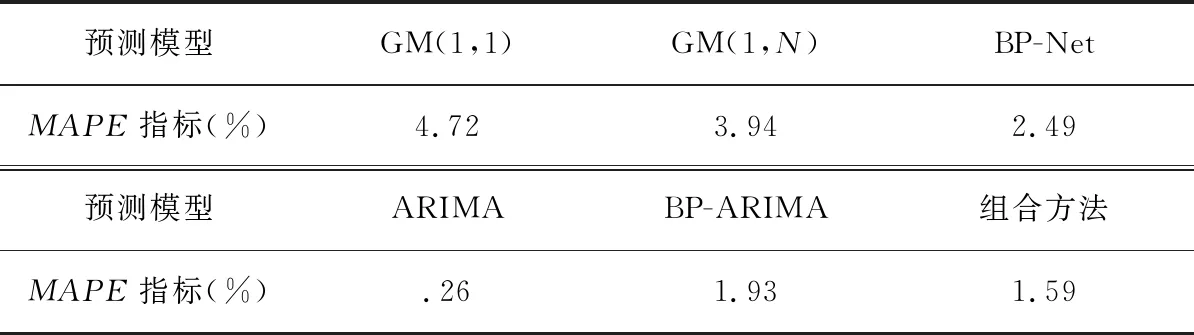
表6 模型误差对比分析
同时,为验证文中函数型非参数方法对周期性月度负荷的预测优势,研究采用随机森林预测方法进行周期性预测比对,2016年~2018年间两种方法的月度负荷预测对比结果见图8,随机森林预测方法MAPE误差值为1.78%,误差累计比非参数方法增加11.95%。从结果看,所采用的函数型非参数方法预测精度较高,适合于周期性数据预测。
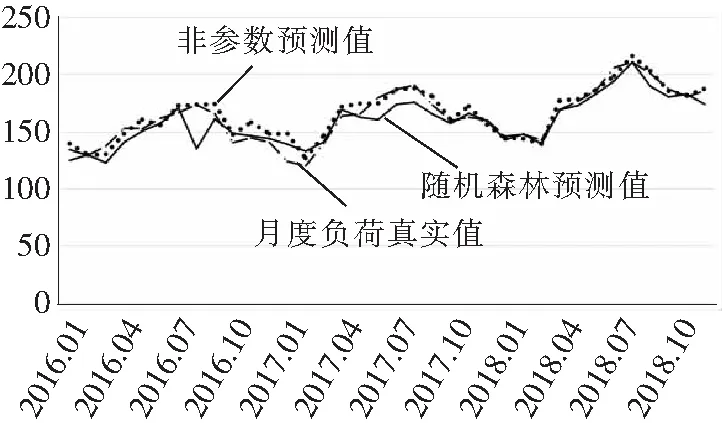
图8 非参数法与随机森林方法的预测值比较
4 结束语
提出了一种新型的组合预测模型,该模型将年度负荷的趋势性与月度负荷的周期性进行分量融合,模型既考虑了数据自身结构的趋势性、周期性特点,又通过影响因素耦合的特点增加了数据趋势预测的合理性,数据的预测精度得到大幅提升。BP-ARIMA负荷预测模型将BP的非线性处理能力与ARIMA的线性预测能力相结合,通过趋势线校核提高影响因素的预测精度及数据稳定性,模型还可筛除相关性较差影响因素,利用因素之间的耦合特性提高年度电力负荷趋势性预测的稳定性。函数型非参数方法通过降维的处理手段实现数据的周期性预测,该法可通过选用合适的核函数达到良好的月度负荷预测精度。该组合预测模型可为长期电力负荷预测提供更为符合客观事实依据的负荷预测方法。
