适用于多维迫选测验的IRT计分模型
2022-06-06郑蝉金李云川
刘 娟 郑蝉金 李云川 连 旭
·研究方法(Research Method)·
适用于多维迫选测验的IRT计分模型
刘 娟1郑蝉金2,3李云川1连 旭1
(1北京智鼎优源管理咨询有限公司, 北京 100102) (2华东师范大学教育心理学系;3华东师范大学上海智能教育研究院, 上海 200062)
迫选(forced-choice, FC)测验由于可以控制传统李克特方法带来的反应偏差, 被广泛应用于非认知测验中, 而迫选测验的传统计分方式会产生自模式数据, 这种数据由于不适合于个体间的比较, 一直备受批评。近年来, 多种迫选IRT模型的发展使研究者能够从迫选测验中获得接近常模性的数据, 再次引起了研究者与实践人员对迫选IRT模型的兴趣。首先, 依据所采纳的决策模型和题目反应模型对6种较为主流的迫选IRT模型进行分类和介绍。然后, 从模型构建思路、参数估计方法两个角度对各模型进行比较与总结。其次, 从参数不变性检验、计算机化自适应测验(computerized adaptive testing, CAT)和效度研究3个应用研究方面进行述评。最后提出未来研究可以在模型拓展、参数不变性检验、迫选CAT测验和效度研究4个方向深入。
迫选测验, 自模式数据, TIRT, MUPP, GGUM-RANK
1 引言
心理测评可依据测量的内容分为认知测验和非认知测验。认知测验测量个体认知能力, 如数值计算能力。这种测验通常具有标准答案, 答对即得分, 总分越高代表其相应的能力越高。非认知测验是了解个体的性格特点、价值观和态度倾向等方面最重要的方法之一, 被广泛应用于临床心理诊断、职业生涯规划、人事决策中, 有相当多的效度研究证明了性格对工作绩效有很好的预测效力(SHL, 2018; Sitser et al., 2013; Hurtz & Donovan, 2000)。与认知测验不同的是, 大部分非认知类的心理测评通常使用李克特形式的等级评定量表(rating scale), 其要求个体每次独立地评价一个题目(如, 我是一个做事有条理性的人), 从最不符合我—1到最符合我—5 (5级李克特)中选择与自己最接近的一项, 答案没有对错之分。当在应聘、选拔等高利害的测评情境中使用此种题型的量表时, 个体很容易有意地操控某些题目(如体现高责任心、乐观性的题目)的分数使自己看起来更符合组织期望, 即使自己并不是这样的人。这种可能的倾向被称为作假、装好, 由此得到的测评结果便失去了对人才的区分效力, 严重损害了测验的公平性。
为了消除或降低作假倾向的影响, 通常会采用事前控制或事后控制技术(骆方, 张厚粲, 2007)。事后控制技术包括嵌入作假识别量表、使用双因子模型控制作假因素(Brown et al., 2017; Hendy et al., 2021)、使用混合Rasch模型甄别作假反应模式人群(骆方, 张厚粲, 2007)和基于历史数据建立决策树模型判别作假人群(Ziegler et al., 2012)等, 其目的都是识别出作假数据, 以避免依据作假数据做相关决策。这些方法均涉及的一个关键问题是如何保证较高的识别准确率, 因为误将诚实的个体判为造假是非常不可取的, 而相对于处理已经受到污染的数据, 事前控制技术旨在阻止个体在答题前或答题中作假以获得无污染数据, 这类技术包括警告、假渠道技术(bogus pipeline)和迫选测验。警告是其中最容易操作的方法, 分为作假识别警告和后果警告, 前者为告知个体可以识别到他们回答中的任何不诚实行为, 后者为告知个体不如实作答会带来什么后果, Dwight和Donovan (2003)的元分析结果表明后果警告才能起到抑制作假的作用, 而在他们后来的研究中进一步指出了两种警告方式一起使用才能产生统计学上有意义的结果。另外, 当个体被警告时, 潜在的作假者可能会决定在作答时不那么极端, 或者为了看起来更诚实而选择一些“错误”的答案, 即警告可能会诱发更加老练的作假, 那么警告并没有实质性的改变个体作假的机制。警告还可能会造成被试在测验过程中焦虑程度提升等一些负面影响, 因此只警告那些表现出作假趋势的被试被认为是更好的解决办法, 而决策树模型可用于决定何时警告作假者(Ziegler et al., 2012)。假渠道技术是通过故意引导个体以为其在进行测谎实验(假渠道), 以迫使其在实际测验中做出最真实的反应。但这种技术是在欺骗个体的基础上实现的, 有违伦理道德, 因此备受谴责(Aguinis & Handelsman, 1997)。
迫选测验要求个体在一组称许性水平相似的题目中强制选择最符合自己和最不符合自己的两项, 或对题目进行偏好排序, 个体无法对所有题目都给予积极的选择。由于题目的称许性相似, 没有一个题目比其他题目更可取, 那么个体根据社会称许性做选择/作假的可能性就会降低。相比李克特式量表, 个体更不易在迫选测验上作假(Saville & Willson, 1991; Jackson et al., 2000; Wetzel et al., 2020)。强制选择的作答形式也消除了李克特式量表其他的一些潜在作答反应偏差(responses biases), 如光环效应, 趋中倾向, 极端倾向, 默许(总是选择同意或不同意)等。另外, 迫选测验形式能有效降低分数在社会称许方向的膨胀性(Cao & Drasgow, 2019), 也没有明显降低个体的作答积极性(Sass et al., 2020)或给个体带来情绪或认知上的不利影响(Zhang et al., 2020)。Bartram (2007)的一项元分析结果表明, 相比李克特式评定量表, 由迫选测验获得的评估结果对工作绩效的预测效度可以提升50%。但迫选测验的传统计分方式会产生自模式数据(ipsative data), 分数的高低体现了个体在各个维度上内部自比的排序结果, 这种数据形态的特殊性限制了迫选测验在个体间比较场景(如人才选拔)中的应用与发展。近十几年来, 几种迫选测量模型的发展使研究者能够从迫选测验中获得接近常模性的潜在特质估计结果, 克服了自模式数据问题后的迫选测验似乎成为了更有应用潜力的抗作假技术。
本文旨在系统地介绍迫选测验的题目类型、特点及传统计分方式和自模式数据的弊端, 然后从题目反应模型和决策模型两个方向, 介绍与评价6种迫选IRT模型, 其次从模型构建思路、参数估计方法和应用研究现状几个方面对比分析6种模型, 最后从迫选模型实践的角度提出4个未来研究的展望方向:模型拓展研究、参数不变性研究、迫选CAT研究和效度研究。
2 迫选测验设计与传统计分方式
迫选测验通常由测量不同维度的数个迫选题块(item block)组成。题块内由固定数量的来自不同或相同维度的、社会称许性水平相似的题目/描述(item/statements)组成, 题目/描述即为维度(也即潜在特质)的外显指标。同一题块的题目通常分别测量不同维度, 因此也被称为多维迫选题(multidimensional forced-choice, MFC)。
2.1 迫选测验设计
根据Hontangas等(2015)的分类, 迫选题块有3种常见的形式:PICK、RANK和MOLE。这种分类主要体现在指导语类型上。PICK (表1)要求个体从题块中选择最符合自己的一项。RANK (表2)要求个体对题目进行从最符合到最不符合的完全排序。MOLE (表3)要求个体分别选择出最符合自己(MOst)和最不符合自己(LEast)的一项。超过3个题目的MOLE题型也称部分排序题(partial rankings)。

表1 PICK题型

表2 RANK题型

表3 MOLE题型
题块大小即题块内包含多少个题目/描述选项, 2~4个题目的题块大小是最为常见的。为节省篇幅, 在后文中将结合指导语类型和题块大小对迫选题型做简称, 如称3题目题块的RANK题型为RANK-3。题块大小会影响个体选择任务负荷的高低, PICK-2仅需个体将2个题目对比一次即可, 题目越多, 个体需要进行题目间对比的次数越多, 使用大题块会增加选择任务的认知复杂性, 可能对受教育程度较低或阅读能力较差的人有不利影响(Brown, 2016)。目前已有的迫选测验中较为常用的题块类型有:PICK-2 (Oswald et al., 2015)、RANK-3 (连旭等, 2014; SHL, 2018)、MOLE-4 (SHL, 1997)。其中RANK-3既没有MOLE-4的高认知负荷, 也比PICK-2更加高效, 且提供的信息量也最大(Hontangas et al., 2015; Joo et al., 2018)。
另外还有Q分类(Q-Sort) (Block, 1963)这种特殊的迫选题型, 它是将问卷中所有的题目(如超过30个题目)组合为一个大型题块一起呈现给个体, 然后要求个体逐步地将每个题目分配到少数几个偏好等级中, 如先从所有题目中选择出最符合自己的几个题目, 然后从剩下的题目中选择最不符合的几个, 直至完成所有题目的分类。这种方法需要个体一次处理大量描述, 因此适用于词汇型的题目(Brown, 2016)。
迫选测验组卷时, 需考虑的首要原则是题目称许性的匹配, 这是保证测验具有抗作假效力的关键步骤, 然后才是题块大小、指导语等外显因素。通常会计算题目称许性的平均绝对差值来衡量匹配程度, 差值越大代表越不匹配, 然而这种仅用均值判断的方式会忽略不同评价者对同一题目称许性评价的差异。Pavlov等人(2021)提出了一种替代性指标:IIA (Inter-item agreement)指数, 该指数将BP指数和AC指数(Gwet, 2014)纳入到题目称许性的匹配中, 可更好地匹配那些原本在称许性均值上没有差异的题目。实践人员可借助R (R Core Team, 2021)包autoFC (Li et al., 2021)计算IIA指数并进行自动组卷。
2.2 传统计分方式与自模式数据
2.2.1 传统计分方式
通常, 迫选测验的传统计分方式是将每个题块中被选为最符合或排序最高的题目计1分, 最不符合或排序最低的题目计−1分, 未选择或中间等级的题目计0分, 最后将各维度下题目分数进行累加得到维度总分。
题目的描述方向将影响各维度题目计分的方式, 负向描述的题目在计分时需乘以−1进行分值的转换, 如负向描述(如:我时常预期消极的结果)被选为最符合时需计为−1分。负向描述的称许性通常很低, 所以很难匹配不同计分方向题目的称许性。如果将称许性相差较大的正负向题目放在一个题块里, 个体很容易选择正向题目为更符合。尤其是在高利害情境中, 几乎所有被试都会选择看起来更积极的选项(Bürkner et al., 2019), 进而会产生测量精度问题, 也会使测验丧失抗作假的作用, 因而实际应用中很少使用混合计分型的题块。
2.2.2 自模式数据及其问题
以表3的MOLE-4题型为例, 无论个体如何选择, 其在每个题块上所选出最符合和最不符合的题目都将分别计为1和−1分, 那么各个题块内题目的得分和均为0, 进而在整个测验上的总分也为0。由此可见, 各个维度的得分是互相依赖的, 有高分维度则必然存在低分维度, 不会出现所有维度得分同高或同低的情况, 这种数据则为自模式数据。与之相对的是常模性数据(normative data), 如李克特式量表的数据, 不同个体对每个题目的评定是互相独立的, 评价分数互不影响, 因此测验的总分是不固定的。自模式数据内部的分数依赖性违反了经典测验理论的基本假设之一, 即误差方差的独立性, 这对迫选测验分数的统计分析和解释都有影响(Baron, 1996), 如信度分析、方差分析、回归分析等, 它会增加犯I类错误的概率, 同时也会影响统计检验力(王珊等, 2014)。同时, 自模式数据对维度关系的扭曲会污染测验的结构效度与效标关联效度(Brown & Maydeu-Olivares, 2013), 并无法进行因子分析(Closs, 1996)。最后, 将自模式数据做常模化的分数解释, 进行个体间对比是不妥的, 这可能会扭曲个体的真实情况, 如在兴趣测验中, 自比结果仅代表个体内部的倾向性排序, Closs认为直接进行人群间比较会严重高估或低估个体真实的兴趣特征。
迫选测验所测的维度数量及维度间的关系对数据自模程度的影响较大。Bartram (1996)的研究表明当维度数量低于10个时或者维度间的相关性达到0.3及以上时, 自模式分数结果将不可靠, 且信度会随维度个数的降低和维度间相关性的提高而大幅度降低。Clemans (1966)也指出低维度数量的迫选测验意味着更严重的自模式数据问题。Baron (1996)指出如果真实分数均匀地分布在平均值周围, 那么自模式分数与常模性分数就会相似, 反之如果多数维度高于或低于平均值, 自模式分数与常模性分数则有很大区别, 但这种区别会随着测验所测的维度数量的增多而下降, 因为人群中出现多个维度分数同高或同低的可能性会大幅下降。相似的, 当维度间的相关关系均为高正相关或高负相关时, 出现分数同高或同低的可能性也会变高, 当维度间的相关关系有正有负时, 出现同高或同低这种高度偏态的维度特征的可能性就低了很多。Saville和Willson (1991)的研究也证明当维度数量超过30个且维度内部相关性较低时, 由自模式数据计算的测验信度达到了可接受范围, 且维度的性状恢复性与常模性数据相似, 此时使用常模化的自模式数据进行分数解释和个体间的比较是可行的。因此, 增加测验的维度数量是抵抗自模式数据特点较为有效的传统做法之一, 但也只是折中的办法。
综上, 自模式数据的诸多问题限制了迫选测验的应用, 虽然可通过增加维度等方法抵抗自模性问题, 但可以看到, 传统计分方式是把个体对题目的排序结果当作对其的绝对评分, 它并未体现个体比较决策的心理过程, 应用在迫选测验上是不恰当的。要解决自模式数据的问题, 需要从根本上跳出传统计分方式, 采用现代测量模型来反映个体在回答迫选题目时的决策过程(Brown & Maydeu-Olivares, 2013), 从外显的比较结果中获得影响决策过程背后的潜在特质分数, 从而实现恢复个体分数的常模性。
3 用于迫选测验的IRT计分模型
在过去的十几年间, 众多适用于迫选测验的IRT计分模型被开发出来以建立外显作答与潜在特质的关系, 从而获得具有常模性特点的潜在特质分数进而实现个体间分数的比较。其中被研究与应用最为广泛的模型之一是由Brown (2011)提出的瑟斯顿IRT模型(Thurstonian Item Response Theory, TIRT), 由Stark等人(2005)提出的MUPP (Multi-Unidimensional Pairwise Preferences)框架也因其灵活性在近几年引起了较多研究者的关注, 并发展出了2个新模型(Morillo et al., 2016; P. Lee et al., 2019)。另外还有Wang等(2017)开发的Rasch自模模型(Rasch ipsative model, RIM), H. Lee和Smith (2020a)基于贝叶斯题组模型(Bayesian testlet model) (Bradlow et al., 1999)提出的贝叶斯随机题块模型(Bayesianrandom block item response theory, BRB-IRT)。这些模型均包含三个层面的内容:迫选题型、题目反应模型、决策模型。模型之间的本质区别在于所假设的题目反应模式(Morilloet al., 2016)和采用的决策模型类型(Brown, 2016)。题目反应模式反映的是题目反应强度和所测维度之间的关系, 决策模型类型反映的则是个体在题目间做出选择的过程。题型和决策模型共同决定了模型的基础框架, 决策模型在外显作答与题目反应强度之间起到了桥梁作用, 并进一步由题目反应模型链接到个体的潜在特质水平, 最终形成整体的迫选分析模型。本文将首先厘清不同题目反应模式和决策模型类型, 再依据这两种概念类型对上述模型进行分类和系统介绍, 最后从模型构建思路、参数估计方法与应用研究现状3个方面进行模型比较。
3.1 题目反应模式
题目是特质的外显测量指标, 题目与潜在特质之间的关系需使用测量模型进行链接。在人格测验中, 不同测量模型依据其所假设的个体对题目的反应过程, 可划分为优势模型(Dominance Models)和展开模型(Unfolding Models)两大类。优势模型假定个体被评估的特质水平越高, 其会以越高的概率对相应题目做出正面回答, Rasch模型、2PL模型(Two-Parameter Logistic Model, 2PLM)等均假设个体对题目的回答遵循优势反应模式。展开模型假定个体正面回答的概率与题目和被评估的特质水平位置的接近程度直接相关。如题目“我喜欢和朋友在咖啡馆里安静地聊天”, 太过内向的个体会因为不喜欢公共场所而选择不同意, 而极端外向的个体因为喜欢更加刺激的环境而选择不同意(Drasgow et al., 2010), 处于中间水平的个体更倾向于同意, 其项目反应函数曲线为单峰钟型, 即个体的特质水平与题目位置越接近, 其正面回答的概率越高。展开模型的代表模型为广义等级展开模型(Generalized Graded Unfolding Model, GGUM) (Roberts et al., 2000)。
到底哪种模型更能反映出个体在作答非认知类题目时的反应特点, 至今仍未有定论(王珊等, 2014; Morillo et al., 2016; Hontangas et al., 2016)。一些模拟和实证研究(Chernyshenko et al., 2001; Tay et al., 2011)支持展开模型, 特别是针对态度类特质的测量, 展开反应题目的表现与优势反应题目一样好或更好。展开模型被认为更灵活, 因为当题目的位置参数在末端时, 它可以等同于优势模型。然而研究表明这种优越性在实践中并非普遍存在, 与优势反应题目组成的量表相比, 完全由展开反应题目组成的量表的心理测量学特性大为逊色, 包括较低的信度和较低的效标关联性(Huang & Mead, 2014)。此外, 由于展开模型对负向题的评分无法直接反向转换, 估计结果可能不如优势反应题目准确(Brown & Maydeu-Olivares, 2010)。从模型复杂度上来说, 优势模型一般比展开模型更节俭、有更少的参数, 通常情况下除非有明确的证据证明复杂模型的优势, 否则应首先考虑更节俭的模型(Oswald & Schell, 2010)。另外, 展开反应题目更加难以编写, 题目所反映的确切含义也难以界定。更多关于优势还是展开模型的讨论可参考Drasgow等人(2010)的研究。
题目反应模式是题目层面的特点而非特质特点, 与迫选题型无关。在将单个题目组合为迫选题块时, 可使用任何反应模式的题目, 因为它们都能测量同样的潜在特质, 潜在特质的分布对于同一批人群来说是不变的。在实际应用中, 需要研究者结合题目特点或数据特点, 选择优势或展开模型中的一种作为题目与潜在特质间的测量模型, 尚未看到在同一测验中混用两种模型的情境。
3.2 决策理论
迫选测验要求个体对一组题目进行比较判断进而决策产生答案, 而非对每个题目进行独立的评价, 而个体对题目的绝对评价是衡量其特质水平的基础。基于Brown (2016)的观点, 个体对一组题目进行比较判断的基础是其在每个被比较题目上的绝对评价水平, 对迫选数据的建模需要依托于合适的决策理论来阐释决策结果(外显作答)与绝对评价之间的关系, 进而评估个体的潜在特质水平。目前已被用于迫选数据建模的决策理论主要有两类, 第一类是最古老和被使用最广泛的瑟斯顿比较判断法则(Thurstone’s Law of Comparative Judgment) (Thurstone, 1927), 第二类是Luce选择公理(Luce & Duncan, 1959)和布拉德利−特里模型(Bradley-Terry Model) (Bradley & Terry, 1952), 后者是前者的特例情况(Brown, 2016)。
3.2.1 瑟斯顿比较判断法则
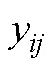
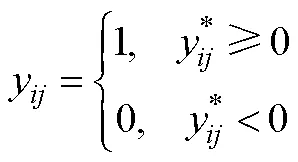
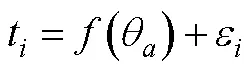
3.2.2 Luce选择公理
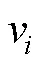
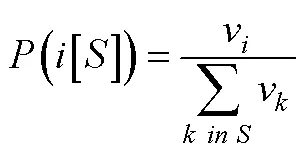
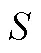


其他类型的决策理论还有, 如Coombs的展开偏好模型(Coombs’s Unfolding Preference Model)、Andrich的强制赞同模型(Andrich’s Forced Endorsement Model)。前者是瑟斯顿比较判断法则的一个特例, 后者简化后与布拉德利−特里模型等价, 具体可参考Brown (2016)。
3.3 TIRT模型
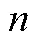
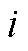
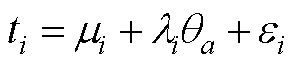
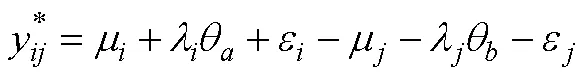
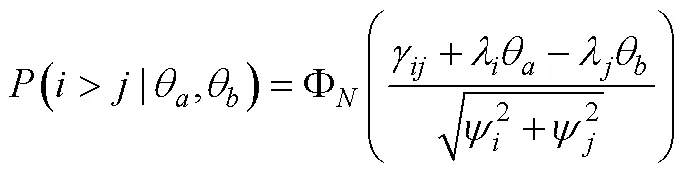
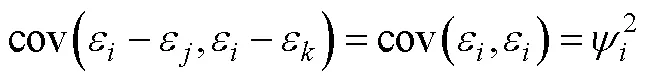
TIRT发展至今, 有众多研究者通过模拟与实证研究探索了其在多种条件下的适用性 (Bürkner et al., 2019; Brown & Maydeu-Olivares, 2013; Schulte et al., 2021; 李辉等, 2017; 连旭等, 2014)。这些研究一方面证明了TIRT确实在一定程度上克服了传统计分下的自模性问题, 相比传统计分具有测量精度的提升, 也更接近李克特式单一刺激量表的结果(Joubert et al., 2015); 另一方面也指出了TIRT若要显示出比传统计分优良的性质, 需对测验设计有较多限制。如TIRT在低维度数情境中使用时, 其潜在特质的良好恢复性建立在测验包含一定比例的混合计分型题块的基础上(Brown, 2011)。Schulte等(2021)的研究也指出在维度数量低于10时, 如果所有题目同为正向题, 即使是在高因子载荷情况下, 测验的信度也会急剧下降。不过与传统计分的相关研究相似, 在高维度情境下(维度数量高于30), 即使不使用混合计分型题块, TIRT对潜在特质分数及特质间关系的恢复性也非常准确(Schulte et al., 2021; Bürkner et al., 2019)。最后需注意的是, 使用混合计分型题块可能存在以下几个问题(Bürkner et al., 2019; Morillo et al., 2016):(1)增加个体的认知负荷; (2)反向描述可能会带来较大的方法论变异, 可能会组成一个独立的方法因子, 进而会影响题目的协方差矩阵; (3)可能会损害使用迫选题型来控制作假的效力, 进而导致对使用迫选测验意义性的质疑。
3.4 MUPP框架及衍生模型
3.4.1 MUPP框架与MUPP-GGUM模型
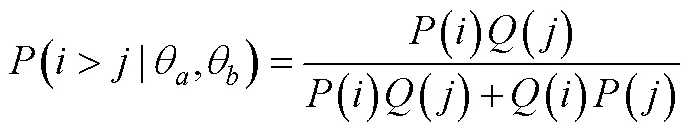
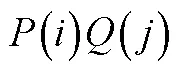
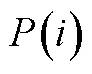
(1)为每个所要测量的维度出大量的题目描述(建议3倍于目标题量);
(2)将题目以1~4级量表或1~5级量表进行施测(各维度约1000人左右的被试);
(3)分维度估计题目的参数, 并进行单维性检验;
(4)对题目进行社会称许性量表的评定, 取人群平均值作为题目的称许性水平;
(5)通过前四步完成迫选题库的搭建后, 就可以将称许性等级相似且测量不同特质的题目进行配对组卷, 以减少个体依据称许偏好作答。为确定潜在特质分数的尺度, 需要包含一定比例的同维度题对;
(6)投放迫选测验施测;
(7)使用MUPP-GGUM模型对个体进行特质的估计。
MUPP-GGUM模型是使用最为久远和广泛的迫选模型之一, 不仅在开发流程上有规范的流程指导, 也是最先被应用到计算机化自适应测验开发的迫选模型, 并应用在了美国军队选拔的多个人格测验中(Stark et al., 2012; Stark et al., 2014)。在MUPP-GGUM之后, 有众多基于MUPP框架的衍生模型被开发出来以适应多种迫选题型, 同时在Stark等人(2012)自适应算法的基础上, 迫选自适应测验研究也开始蓬勃发展。
3.4.2 MUPP-2PL模型
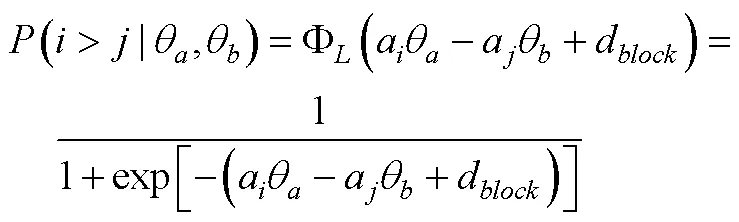
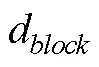
3.4.3 GGUM-RANK模型
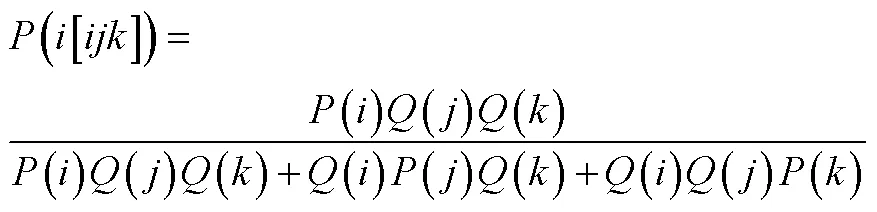

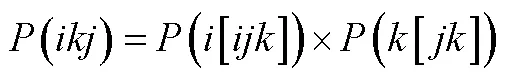
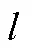
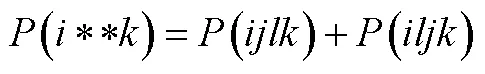
3.5 RIM模型
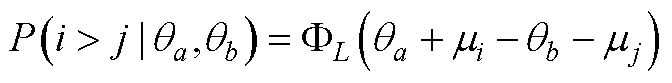
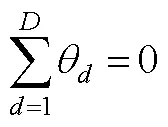
Wang等(2016)拓展了RIM, 使之适用于RANK题型, 形成了ELIRT (exploded logit IRT)和GLIRT (generalized logit IRT)两种迫选模型。其中ELIRT的拓展思路与Hontangas等(2015)对RANK的拓展逻辑一致。GLIRT的拓展思路是对每个题块的可能作答模式进行枚举, 依次写出每种作答模式的反应函数, 并限定所有可能的作答模式的概率和为1, 来实现对个体作答模式概率模型的构建, 具体可参考Chen等(2020)的研究。当用于配对迫选题型时, ELIRT和GLIRT均等价于RIM。两种拓展模型的模拟研究结果非常相似, 研究者可自由选择其中之一。
3.6 BRB-IRT模型
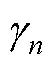
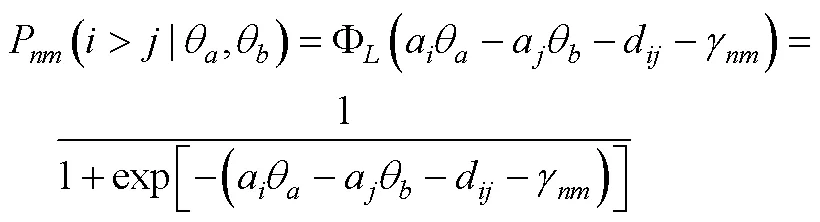
对于包含混合计分型题块会带来潜在的抗作假效力降低的这一争议问题, H. Lee和Smith认为适合BRB-IRT的应用场景为低利害的作答情境, 尤其是可以充分利用迫选测验能避免李克特式量表带来的其他作答反应偏差的这一优势, 又不对抗作假有较高需求的场景。如2012年PISA (Programme for International Student Assessment)就在对学生的数学意向和学习策略量表上采用了迫选测验形式, 通过控制潜在的由不同文化所带来的作答反应偏差来更好地了解学生的国际/跨文化差异。在BRB-IRT模型中, 可以灵活地加入可能影响题目和特质分数的协变量, 从而可以更好地分析人群间的差异。在公式(17)的基础上进行拓展, 当包含影响所有特质的协变量(以性别变量为例)时, 则为:
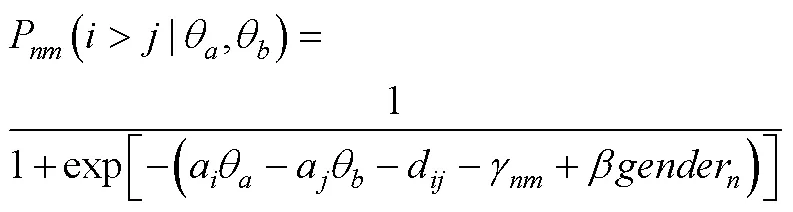
当包含影响每个潜在特质的协变量时, 为:
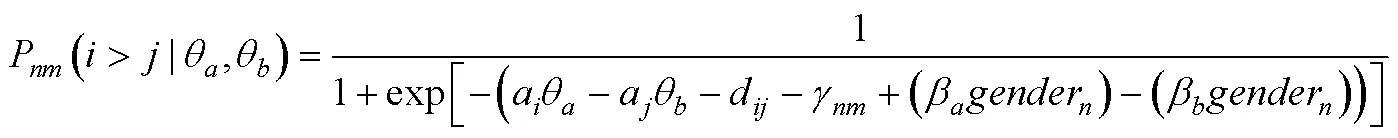
4 模型比较
4.1 模型构建思路
从实践的角度出发, 通过已有的迫选IRT模型可以看到, 迫选模型开发的一个方向是使其适合更多的题块组合方式, 如PICK、RANK或MOLE, 另一个方向是使其适合不同反应模式的题目。依据题型和题目反应模型, 已有迫选模型的总结见表4。
TIRT、MUPP-2PL和BRB-IRT均适合于优势反应模式题目, 且选择了2PLM作为题目反应函数, 只不过MUPP-2PL仅适合于PICK-2题型, 其他两个均可通过对数据的二元编码应用于多种题型。TIRT在应用于PICK-2题型时, 在题块反应方程构建上与MUPP-2PL等价(Morillo et al., 2016), 只不过TIRT使用的是Probit链接函数, MUPP-2PL使用的是Logit链接函数, 而两模型在理论上的等价性在模拟研究中也得到了体现, 两模型在大部分条件下的估计结果非常一致, 除了MUPP-2PL对潜在特质及潜在特质之间关系的估计优于TIRT在同等条件下的结果。另外Morillo等人的实证研究发现, MUPP-2PL与TIRT无论是对题目参数还是对潜在特质的估计均具有极高的相似性(相关系数均在0.9附近), 这在一定程度也证明了TIRT所采用的瑟斯顿比较判断法则与应用在PICK-2题型上的布拉德利−特里模型的内在等价性, 只不过TIRT由于没有使用题目的先验信息导致估计结果总体偏极端化。为了将题块内题目之间的相互依赖性考虑到参数估计中, BRB-IRT在MUPP-2PL的基础上加入了随机题块效应, 而在TIRT中, 则是通过构建题目间的协方差矩阵来实现的, H. Lee和Smith (2020a)的实证研究也表现出BRB-IRT与TIRT结果的高度一致性。
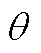
4.2 参数估计方法
在迫选模型的参数估计中, 从估计内容上分为题目参数估计和潜在特质估计, 从估计算法上主要分为传统估计算法和MCMC方法, 从估计流程上主要分为联合估计和两步走策略。

表4 模型总结
TIRT是基于结构方程模型开发的, 且提出时间较长, 现有多种成熟的软件(如Mplus等结构方程建模软件)和开源R包thurstonianIRT (Bürkner, 2018)可用于其参数估计。为方便实践者使用, Brown和Maydeu-Olivares (2012)提供了输入测验设计就可以导出Mplus语句的Excel宏(http:// annabrown.name/software)。而在thurstonianIRT包中, Bürkner提供了数据模拟的函数, 并作为一个接口供用户选择lavaan包(Y. Rosseel, 2012), Mplus或者Stan (Stan Development Team, 2020)来作为模型拟合的内在处理方法, 并可根据用户提供的信息自动生成三种方法的代码(Bürkner et al., 2019)。在Mplus或lavaan中, 题目参数可使用未加权的最小二乘法或对角加权最小二乘法来估计。而Stan是一种概率编程语言, 使用MCMC来拟合贝叶斯模型, 因此Bürkner也提供了使TIRT能够采用MCMC估计的方便接口。潜在特质的估计可使用期望后验算法(Expected A Posteriori, EAP)或MAP, EAP适用于维度数量为1~2个时, MAP适用于维度数量较多时(Brown, 2016), 因为维度数量升高时, 会导致EAP中的数值积分的节点数呈指数级增长。
显然TIRT配套软件的开发为实践者提供了极大的便利性, 这也是TIRT应用广泛的原因之一, 但也存在一些质疑, 如Bürkner等(2019)在使用Mplus和Lavaan拟合TIRT时发现有严重的模型无法收敛问题, 特别是在大型测验的条件下(如5维度测验, 每维度有27个题块, 模型收敛率仅0.3左右)。除此之外还需要较高的运行内存(如30维度测验, 每维度有9个题块, 模型需要32GB的运行内存), 否则需要在代码中指定不计算卡方和标准误等拟合指标以减少运行时间和运行压力。最常见的报错是方差为负, 通常需要指定维度间关系或因子载荷来促进收敛, 但估计结果同样也会非常依赖这些固定值。使用MCMC方法拟合TIRT时没有不收敛和内存不够的问题, 这得益于贝叶斯算法的自身优势。因此, 考虑到TIRT在模型识别上的敏感性, 如若在维度较高的测验中考虑使用TIRT, 需要在测验开发时就要充分保证题目的质量, 如对题目进行单维性检验以保证题目的单维性特征。在选择估计方法时, 需要考虑运行内存的问题。否则模型不收敛或因内存受限而无法获得任何估计结果会非常影响测验开发者对测验质量和模型的信心。最后从估计速度上来说, 可能由于Mplus采用的未加权的最小二乘法是有限信息估计方法, 在相同的测验条件下, 其比Stan的估计速度通常会快数倍, 因此在非大型测验情境下, 推荐先使用上述所举资源中Mplus进行分析。
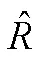

表5 模型参数估计方法总结
5 应用研究现状
迫选IRT模型被广泛应用于工业组织心理学领域, 如TIRT在多种商业化测验中得到了应用, 如OPQ32r (Occupational Personality Questionnaire)和CCSQ (Customer Contact Styles Questionnaire)两种性格测验(SHL, 2018; Brown & Maydeu- Olivares, 2011), 也被用于开发评估适应不良人格特征的测验(Assessment of Work-Related Maladaptive Personality Traits) (Guenole et al., 2016)。在360度反馈测验中也被证实使用迫选题型的测验并采用TIRT进行计分比使用传统李克特评分题目有更好的结构效度与聚合效度(Brown et al., 2017)。MUPP-GGUM在员工人格自适应测验(the Adaptive Employee Personality Test, Adept-15) (Aon Hewitt, 2015)和美国军队选拔所开发的自适应人格测评工具TAPAS (Tailored Adaptive Personality Assessment System) (Stark et al., 2014)上得以应用, 这2个测验也是迫选模型在计算机化自适应方向的突破性尝试。同时, 题目参数不变性检验作为测验开发流程的一个重要环节, 在迫选模型上的检验方法也正逐步被开发与完善。在实践人员更加关注的效度研究领域, 也积累了相当多的证据。因此, 本文将对迫选模型在参数不变性检验、计算机化自适应测验和效度研究3个方面进行迫选模型应用研究的现状分析。
5.1 参数不变性检验
通常, 测验开发者需要对题目参数的不变性进行检验(也即测量一致性检验), 以保证所有作答者对题目的理解或者题目所表达的内涵是相同的。在迫选测验情境下, 题目参数不变性可根据不变性情境分为2个具体问题:跨题块一致性和跨人群一致性。不具有参数不变性的题目意味着其作答概率会受到除测量目标外其他因素的影响。
跨题块一致性是指同一题目在与不同题目组合为题块时, 其是否具有参数不变性, 如有题块1{A, B, C}和题块2{A, D, E}, 它们的共同题目为A描述, 如果A的题目参数在两题块的估计结果差异不大, 则说明参数没有受到其他题目的影响, 具有跨题块参数不变性。Lin和Brown (2017)基于TIRT模型, 比较了RANK-3和MOLE-4两种题型的两套迫选测验的参数不变性, 后者仅在前者的每个题块上新增了一道题目, 所以每对题块之间的共同题比例为75%, 结果发现仅有少量题目存在较大偏差。
跨人群一致性是指一道题目在来自不同背景的人群组(如不同性别、不同文化背景、不同测验情境的人群)之间是否具有参数不变性, 而对此不变性的检验也称之为题目功能性差异检验(Differential Item Functioning, DIF), 如果题目参数在不同组之间发生了较大改变, 就意味着此题目的作答概率会受到个体背景的影响, 如果测验中包含较多此类题目将会降低测验效度, 也有失公平性。在开发迫选测验时, 首先需确保单题题库具有良好的测量学指标, 如可接受的区分度指标、没有DIF等(Stark et al., 2005; SHL, 2018), 这些题目质量分析通常采用李克特等单一刺激量表形式进行, 但当题目组合为题块时, 则可能产生新的DIF (不同组别的人群因为题目情境发生改变而产生与单一刺激题目不同的反应偏好)。因此, 基于迫选数据进行DIF检验是势在必行的。
H. Lee和Smith (2020b)基于多组CFA (multiple group confirmatory factor analyses)框架提出了通过模型的整体拟合指数差异来检验TIRT测量不变性(Measurement Invariance, MI)的分析方法, 并建议将ΔCFI > 0.007和ΔCFI > 0.001分别作为尺度非一致性(metric non-invariance)和标量非一致性(scalar non-invariance)的临界值, 但此方法无法具体到题目来进行筛查, 而题目层面的参数非一致性即为DIF。P. Lee等(2020)则针对TIRT模型的区分度和截距指标提出了一种综合Wald检验TIRT-DIF方法(omnibus Wald tests), 并通过模拟研究证明在自由基线(free baseline)方法下检出效率较高:随着样本量和DIF量的增加, 检出率接近1, I型错误率接近0.05。Qiu和Wang (2021)提出了3种RIM的DIF检验方法, EMD (equal-mean- difficulty), AOS (all-other-statement)和CS (constant- statement) 方法, 最终通过模拟研究发现CS方法在测验含有DIF题目时的表现优于其他两种方法。
5.2 计算机化自适应测验
由于人类性格特点的复杂性, 性格测评工具的测量维度也通常是高维的, 如OPQ32r测量了32个性格维度。维度越多, 意味着所需要的题目也越多, 测验总长度就会达到惊人的程度。从个体感受而言, 题量过长会使个体疲惫度增高进而对测验感到厌烦导致粗心作答, 特别是在招聘情境下使用时, 甚至会对应聘企业或测评提供方产生不好的印象。从测评效率来说, 当个体在某些维度上通过少量题目已经达到可接受的测评精度时, 即可以对个体在这些维度上有比较确定的判断, 在后续集中投放对其评价不确定性更高的维度的题目, 就能尽快使对个体所有维度的评估都能达到一个可靠的程度, 从而提升测评效率, 降低企业招聘在测评上花费的时间和成本。而解决以上问题的思路之一就是开发CAT版本的迫选测验。
早在15年前, 迫选CAT测验就已经在美国海军人员选拔中得到了应用, 该测验由Houston等人(2006)开发, 全称为美国海军自适应人格量表(Navy Computer Adaptive Personality Scales, NCAPS),共测量了19个性格维度。在进行自适应评估时, 会依据个体当前能力抽取同一维度下处于两端的题目并参考其称许性水平进行配对, 因此其为单维PICK-2题型的自适应测验。Stark等人(2012)在MUPP-GGUM的基础上提出了适用于多重−单维PICK-2题型(可使用单维和多维题块)的共6个步骤的迫选自适应流程, 与传统CAT最大的区别是需要考虑单维题块的比例和预先遍历并存储多维题块的维度组合形式。如对于一个3维度的测验, 它的维度组合形式有1-1、2-2、3-3、1-2、1-3、2-3, 并在此基础上控制内容的平衡。为了加速对特质水平的估计, 该流程推荐使用环形维度链接策略(Circular Dimensional-Linking), 即使用最少的题块链接所有的维度, 如一个5维度测验可使用维度组合1-2、2-3、3-4、4-5、5-1。以上两个研究均证明了CAT相比非CAT对效率的提升是非常明显的, 迫选CAT只需要非自适应测验一半的题目就能达到同样的准确性。另外, TAPAS也是为美国军队选拔所开发的自适应人格测评工具, 同样基于MUPP-GGUM (Stark et al., 2014)。
除以上提及的配对题型的迫选CAT测验外, 近期Joo等人(2020)基于GGUM-RANK提出了适用于RANK题型的迫选CAT方法, 并通过模拟研究指出单维题块似乎不是必须的, 而在Stark等人(2012)的研究中推荐加入总题量5%的单维题块。
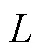
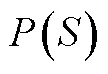
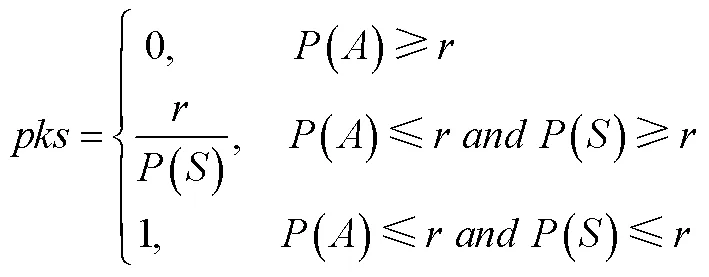
就迫选CAT测验的重测信度这一问题, Seybert和Becker (2019)指出题目不一致带来的误差降低了CAT测验的重测信度, 因为在测验施测过程中受到作答者能力、选题策略等多方面影响, 很难找到完全相同的两份CAT试卷, 所以CAT的重测信度更像是传统测验的复本重测信度(在不同时间点对个体施测2份复本测验)。其研究表明迫选CAT测验的重测信度低于传统李克特式量表, 但与传统李克特式量表的复本重测信度相当。
5.3 效度研究
6 研究展望
迫选测验作为一种能有效抵抗作假、作答反应偏差且能提升个体作答效率的测评形式, 迫选IRT模型的研究依然具有很大的潜力, 尤其是在非认知类、高利害情境测评的应用上。结合已有研究未解决的问题提出以下几个对未来研究的展望方向:模型拓展研究、题目参数不变性研究、迫选CAT研究和效度研究。
6.1 模型拓展研究
目前已有的迫选模型均适用于常规题型, 如PICK-2, RANK-3。未来还可以探索这些模型是否可以通过对数据的重新编码来支持Q分类题型。另外, 还存在PICK-2题型的变体形式, 如Adept-15测验(Aon Hewitt, 2015), 即在让候选人选择最符合自己的一项时, 同时给出选择此项的意愿程度(见表6)。Brown和Maydeu-Olivares (2018)称这种题目为等级题块(graded blocks), 并基于瑟斯顿比较判断法则开发了适用此题型的因子分析模型和信息量函数。

表6 PICK-2等级题型
这种题型细化了个体的选择行为, 提供了更多信息量, 从原来的2个计分点, 扩充至了多个, 但也增加了题目的认知负荷。未来仍需更多研究探索在其他框架下(如MUPP), 如何对此种题型进行计分和其相比传统迫选题型的优势性, 以及其是否对作答者有认知负荷方面的负面影响。
6.2 基于各模型的参数不变性研究
针对参数的跨题块一致性问题, 延续Lin和Brown (2017)针对TIRT的研究, 当共同题比例降低时, 是否还能有较高比例的题目的参数具有跨题块不变性还有待研究。另外针对其他模型的跨题块一致性的研究有待展开。
目前仅有针对TIRT (H. Lee & Smith, 2020b; P. Lee et al., 2020)和RIM (Qiu & Wang, 2021)的参数不变性检验的研究, 未来研究除了需要开发其他迫选模型DIF检验方法, 也需丰富或提升已有的DIF检验方法, 使之对多种来源的DIF更加敏锐。
6.3 迫选CAT研究
虽然迫选CAT在实证研究上积累了较多的经验, 但已开发的自适应流程在进行潜在特质估计时所采用的题目参数均为通过单一刺激量表数据预先标定的, 所使用的题库均为单题题库, 并非题块库, 在进行题目选择时将即时进行题目的组合形成迫选题块, 那么题目的跨题块一致性在这种CAT流程下对潜在特质估计的影响需要进一步研究。另外高维情境下题块维度组合形式和测验长度均会大幅增加, 这对内容平衡和测验效率带来了挑战, 未来可进一步探索如何在高维情境下发挥CAT的优势。虽然Chen等(2020)提出的子题库选题策略和题目曝光控制方法不涉及计分相关内容, 可以拓展至基于其他非RIM模型构建的CAT测验中, 但具体表现如何还需要研究去探索。另外, 多项式策略等控制方法无法直接应用于变长测验, 未来可进一步探索在变长测验中如何构建更合适的选题策略。
6.4 效度研究
目前有较多研究集中于对比迫选测验与李克特式量表在针对同一测量内容时是否产出了相似的结果, 以此来证明其抗作假效力和常模性分数的恢复程度, 但二者在测验形式上的区分性和李克特题型所带来的作答反应偏差必然会引入一些误差, 未来如何最大限度控制这些偏差或者是否存在更好的效度研究思路值得探索。在迫选形式上, 题块越大, 抵抗作假能力越强, 但也增加了认知负荷(Wetzel et al., 2020), 在未来研究中可以探索抗作假效力和认知负荷在题块大小上的平衡点。另外, 已有的效度研究大多数围绕TIRT展开, GGUM-RANK等新模型的效度研究有待探索。
连旭, 卞迁, 曾劭婵, 车宏生. (2014). MAP职业性格迫选测验基于瑟斯顿IRT模型的拟合分析[摘要]., 北京.
李辉, 肖悦, 刘红云. (2017). 抗作假人格迫选测验中瑟斯顿IRT模型的影响因素.,(5), 624–630.
骆方, 张厚粲. (2007). 人格测验中作假的控制方法.(4), 78−82.
王珊, 骆方, 刘红云. (2014). 迫选式人格测验的传统计分与IRT计分模型.(3), 549−557.
Adams, R. J., Wu, M. L., & Wilson, M. R. (2015).. Melbourne: Australian Council for Educational Research
Aguinis, H., & Handelsman, M. M. (1997). Ethical issues in the use of the bogus pipeline.,(7), 557–573.
Aon, Hewitt. (2015).. Lincolnshire, IL: Aon Corp.
Baron, H. (1996). Strengths and limitations of ipsative measurement.,(1), 49–56.
Bartram, D. (1996). The relationship between ipsatized and normative measures of personality.,(1), 25–39.
Bartram, D. (2007). Increasing validity with forced-choice criterion measurement formats.,(3), 263–272.
Block, J. (1963). The Q-sort method in personality assessment and psychiatric research.,(3), 230–231.
Bradley, R. A., & Terry, M. E. (1952). Rank analysis of incompleteblock designs: I. The method of paired comparisons.,(3/4), 324–345.
Bradlow, E. T., Wainer, H., & Wang, X. (1999). A Bayesian random effects model for testlets.,(2), 153–168.
Brown, A. (2016). Item response models for forced-choice questionnaires: A common framework.,(1), 135–160.
Brown, A., Inceoglu, I., & Lin, Y. (2017). Preventing rater biases in 360-degree feedback by forcing choice.,(1), 121–148.
Brown, A., & Maydeu-Olivares, A. (2010). Issues that should not be overlooked in the dominance versus ideal point controversy.,(4), 489–493.
Brown, A., & Maydeu-Olivares, A. (2011). Item response modeling of forced-choice questionnaires.,(3), 460–502.
Brown, A., & Maydeu-Olivares, A. (2012). Fitting a Thurstonian IRT model to forced-choice data using mplus.,(4), 1135–1147.
Brown, A., & Maydeu-Olivares, A. (2013). How IRT can solve problems of ipsative data in forced-choice questionnaires.,(1), 36–52.
Brown, A., & Maydeu-Olivares, A. (2018). Ordinal factor analysis of graded-preference questionnaire data.(4), 516–529.
Bürkner, P.-C. (2018). thurstonianIRT: Thurstonian IRT models in R.,(42), 1662.
Bürkner, P.-C., Schulte, N., & Holling, H. (2019). On the statistical and practical limitations of Thurstonian IRT models.,(5), 827–854.
Cao, M., & Drasgow, F. (2019). Does forcing reduce faking? A meta-analytic review of forced-choice personality measuresin high-stakes situations.,(11), 1347–1368.
Chalmers, R. P. (2012). mirt: A multidimensional item response theory package for the R environment.,(6), 1–29.
Chen, C.-W., Wang, W.-C., Chiu, M. M., & Ro, S. (2020). Item selection and exposure control methods for computerized adaptive testing with multidimensional ranking items.,(2), 343–369.
Chernyshenko, O. S., Stark, S., Chan, K. Y., Drasgow, F., & Williams, B. (2001). Fitting item response theory models to two personality inventories: Issues and insights.,(4), 523–562.
Clemans, W. V. (1966). An analytical and empirical examination of some properties of ipsative measures.,.
Closs, S. J. (1996). On the factoring and interpretation of ipsative data.,(1), 41−47.
Coombs, C. H. (1950). Psychological scaling without a unit of measurement.,(3), 145–158.
Doornik, J. A. (2009).. London, England: Timberlake Consultants.
Drasgow, F., Chernyshenko, O. S., & Stark, S. (2010). 75 years after Likert: Thurstone was right!,(4), 465−476.
Dueber, D. M., Love, A. M. A., Toland, M. D., & Turner, T. A. (2018). Comparison of single-response format and forced- choice format instruments using Thurstonian item response theory.,(1), 108–128.
Dwight, S. A., & Donovan, J. J. (2003). Do warnings not to fake reduce faking?,(1), 1–23.
Gelman, A., & Rubin, D. (1992). Inference from iterative simulation using multiple sequences.,(4), 457–472.
Guenole, N., Brown, A., & Cooper, A. (2016). Forced-choice assessment of work-related maladaptive personality traits: Preliminary evidence from an application of Thurstonian item response modeling.,(4), 513–526.
Gwet, K. L. (2014).. Gaithersburg, MD: Advanced Analytics, LLC.
Hendy, N., Krammer, G., Schermer, J. A., & Biderman, M. D. (2021). Using bifactor models to identify faking on Big Five questionnaires.,(1), 81–99.
Hontangas, P. M., de la Torre, J., Ponsoda, V., Leenen, I., Morillo, D., & Abad, F. J. (2015). Comparing traditional and IRT scoring of forced-choice tests.,(8), 598–612.
Hontangas, P. M., Leenen, I., de la Torre, J., Ponsoda, V., Morillo, D., & Abad, F. J. (2016). Traditional scores versusIRT estimates on forced-choice tests based on a dominance model.,(1), 76–82.
Houston, J., Borman, W., Farmer, W., & Bearden, R. (2006).(NPRST-TR-06-2). Millington, TN: Navy Personnel Research, Studies, and Technology.
Huang, J., & Mead, A. D. (2014). Effect of personality item writing on psychometric properties of ideal-point and Likert scales.,(4), 1162–1172.
Hurtz, G., & Donovan, J. (2000). Personality and job performance: The Big Five revisited.,(6), 869–879.
Jackson, D. N., Wroblewski, V. R., & Ashton, M. C. (2000). The impact of faking on employment tests: Does forced choice offer a solution?,(4), 371–388.
Joo, S.-H., Lee, P., & Stark, S. (2018). Development of information functions and indices for the GGUM-RANK multidimensional forced choice IRT model.,(3), 357−372.
Joo, S.-H., Lee, P., & Stark, S. (2020). Adaptive testing with the GGUM-RANK multidimensional forced choice model: Comparison of pair, triplet, and tetrad scoring.,(2), 761–772.
Joubert, T., Inceoglu, I., Bartram, D., Dowdeswell, K., & Lin, Y. (2015). A comparison of the psychometric properties of the forced choice and Likert scale versions of a personality instrument.,(1), 92–97.
Kiefer, T., Robitzsch, A., & Wu, M. (2016).(R package version 1.995-0) [Computer program]. Retrieved from https://cran.r-project.org/web/packages/ TAM/index.html
Kim, J.-S., & Bolt, D. (2007). Estimating item response theory models using Markov chain Monte Carlo methods.,(4), 38–51.
Lee, H., & Smith, W. Z. (2020a). A Bayesian random block item response theory model for forced-choice formats.,(3), 578–603.
Lee, H., & Smith, W. Z. (2020b). Fit indices for measurement invariance tests in the Thurstonian IRT model.,(4), 282–295.
Lee, P., Joo, S.-H., & Stark, S. (2020). Detecting DIF in multidimensional forced choice measures using the Thurstonian item response theory model.,(4), 739–771.
Lee, P., Joo, S.-H., Stark, S., & Chernyshenko, O. S. (2019). GGUM-RANK statement and person parameter estimation with multidimensional forced choice triplets.,(3), 226–240.
Li, M., Sun, T., & Zhang, B. (2021). autoFC: An R package for automatic item pairing in forced-choice test constructionAdvance online publication. https://doi.org/10.1177/01466216211051726.
Lin, Y., & Brown, A. (2017). Influence of context on item parameters in forced-choice personality assessments.,(3), 389–414.
Luce, & Duncan, R. (1959). On the possible psychophysical laws.,(2), 81–95.
Luce, R. D. (1977). The choice axiom after twenty years.,(3), 215–233.
Lunn, D., Spiegelhalter, D., Thomas, A., & Best, N. (2009). The BUGS project: Evolution, critique and future directions.(25), 3049−3067.
Maydeu-Olivares, A., & Brown, A. (2010). Item response modeling of paired comparison and ranking data.,(6), 935–974.
Morillo, D., Leenen, I., Abad, F. J., Hontangas, P., de la Torre, J., & Ponsoda, V. (2016). A dominance variant under the multi-unidimensional pairwise-preference framework: Model formulation and Markov chain Monte Carlo estimation.,(7), 500–516.
Oswald, F. L., & Schell, K. L. (2010). Developing and scaling personality measures: Thurstone was right—But so far, Likert was not wrong.,(4), 481–484.
Oswald, F. L., Shaw, A., & Farmer, W. L. (2015). Comparing simple scoring with IRT scoring of personality measures: The navy computer adaptive personality scales.,(2), 144–154.
Pavlov, G., Shi, D., Maydeu-Olivares, A., & Fairchild, A. (2021). Item desirability matching in forced-choice test construction.,, 111114.
Plummer, M. (2003, March).Paper presented at the 3rd International Workshop on Distributed Statistical Computing, Vienna, Austria.
Press, W. H., Flannery, B. P., Teukolsky, S. A., & Vetterling, W. T. (1986).New York: Cambridge University Press.
Qiu, X.-L., & Wang, W.-C. (2021). Assessment of differentialstatement functioning in ipsative tests with multidimensional forced-choice items.,(2), 79–94.
R Core Team. (2021):Vienna, Austria. Available online at https://www.R-project.org/.
Roberts, J. S., Donoghue, J. R., & Laughlin, J. E. (2000). A general item response theory model for unfolding unidimensionalpolytomous responses.,(1), 3–32.
Roberts, J. S., & Thompson, V. M. (2011). Marginal maximum a posteriori item parameter estimation for the generalized graded unfolding model.,(4), 259–279.
Rosseel, Y. (2012). lavaan: An R package for structural equation modeling.,(2), 1–36.
Sass, R., Frick, S., Reips, U.-D., & Wetzel, E. (2020). Taking the test taker's perspective: Response process and test motivation in multidimensional forced-choice versus rating scale instruments.,(3), 572–584.
Saville, P., & Willson, E. (1991). The reliability and validity of normative and ipsative approaches in the measurement of personality.,(3), 219–238.
Schulte, N., Holling, H., & Bürkner, P.-C. (2021). Can high- dimensional questionnaires resolve the ipsativity issue of forced-choice response formats?,(2), 262–289.
Seybert, J., & Becker, D. (2019). Examination of the test- retest reliability of a forced‐choice personality measure.,(1), 1−17.
SHL. (2018).. SHL.
Sitser, T., van der Linden, D., & Born, M. P. (2013). Predicting sales performance criteria with personality measures: The use of the general factor of personality, the Big Five and narrow traits.,(2), 126–149.
Spiegelhalter, D., Thomas, A., & Best, N. (2003).[Computer program]. Cambridge, UK: MRC Biostatistics Unit, Institute of Public Health.
Stan Development Team. (2020).. http://mc-stan.org/
Stark, S. E. (2002).(Unpublished doctorial dissertation). University of Illinois at Urbana-Champaign.
Stark, S., Chernyshenko, O. S., & Drasgow, F. (2005). An IRT approach to constructing and scoring pairwise preferenceitems involving stimuli on different dimensions: The multi-unidimensional pairwise-preference model.,(3), 184–203.
Stark, S., Chernyshenko, O. S., Drasgow, F., Nye, C. D., White, L. A., Heffner, T., & Farmer, W. L. (2014). From ABLE to TAPAS: A new generation of personality tests to support military selection and classification decisions.,(3), 153–164.
Stark, S., Chernyshenko, O. S., Drasgow, F., & White, L. A. (2012). Adaptive testing with multidimensional pairwise preference items.,(3), 463–487.
Tay, L., Ali, U. S., Drasgow, F., & Williams, B. (2011). Fitting IRT models to dichotomous and polytomous data: Assessing the relative model–data fit of ideal point and dominance models.,(4), 280–295.
Tendeiro, J. N., & Castro-Alvarez, S. (2018). GGUM: An R package for fitting the generalized graded unfolding model.,(2), 172–173.
Thurstone, L. L. (1927). A law of comparative judgment.(4), 273–286.
Tu, N., Zhang, B., Angrave, L., & Sun, T. (2021). Bmggum: An R package for Bayesian estimation of the multidimensional generalized graded unfolding model with covariates.(7–8), 553–555.
Usami, S., Sakamoto, A., Naito, J., & Abe, Y. (2016). Developingpairwise preference-based personality test and experimental investigation of its resistance to faking effect by item response model.,(4), 288–309.
Walton, K. E., Cherkasova, L., & Roberts, R. D. (2020). On the validity of forced choice scores derived from the Thurstonian item response theory model.,(4), 706–718.
Wang, W.-C., Qiu, X.-L., Chen, C.-W., & Ro, S. (2016). Item response theory models for multidimensional ranking items. In L. A. van der Ark, D. M. Bolt, W.-C. Wang, J. A. Douglas, & M. Wiberg (Eds.),(pp. 49−65). New York, NY: Springer.
Wang, W.-C., Qiu, X.-L., Chen, C.-W., Ro, S., & Jin, K.-Y. (2017). Item response theory models for ipsative tests with multidimensional pairwise comparison items.,(8), 600–613.
Watrin, L., Geiger, M., Spengler, M., & Wilhelm, O. (2019). Forced-choice versus Likert responses on an occupational Big Five questionnaire.,(3), 134–148.
Wetzel, E., Frick, S., & Brown, A. (2020). Does multidimensional forced-choice prevent faking? Comparing the susceptibility of the multidimensional forced-choice format and the rating scale format to faking.,(2), 156–170.
Zhang, B., Sun, T., Drasgow, F., Chernyshenko, O. S., Nye, C. D., Stark, S., & White, L. A. (2020). Though forced, still valid: Psychometric equivalence of forced-choice and single-statement measures.,(3), 569–590.
Ziegler, M., MacCann, C., & Roberts, R. D. (Eds.). (2012).. Oxford, UK: Oxford University Press.
IRT-based scoring methods for multidimensional forced choice tests
LIU Juan1, ZHENG Chanjin2,3, LI Yunchuan1, LIAN Xu1
(1Beijing Insight Online Management Consulting Co., Ltd., Beijing 100102, China)(2Department of Educational Psychology, East China Normal University, Shanghai 200062, China)(3Shanghai Institute of Artificial Intelligence for Education, East China Normal University, Shanghai 200062, China)
Forced-choice (FC) test is widely used in non-cognitive tests because it can control the response bias caused by the traditional Likert method, while traditional scoring of forced-choice test produces ipsative data that has been criticized for being unsuitable for inter-individual comparisons. In recent years, the development of multiple forced-choice IRT models that allow researchers to obtain normative information from forced-choice test has re-ignited the interest of researchers and practitioners in forced-choice IRT models. First, the six prevailing forced-choice IRT models are classified and introduced according to the adopted decision models and item response models. Then, the models are compared and summarized from two perspectives: model construction ideology and parameter estimation methods. Next, it reviews the applied research of the model in three aspects: parameter invariance testing, computerized adaptive testing (CAT) and validity study. Finally, it is suggested that future research can move forward in four directions: model expansion, parameter invariance testing, forced-choice CAT, and validity research.
forced choice test, ipsative data, TIRT, MUPP, GGUM-RANK
B841
2021-07-06
郑蝉金, E-mail: chjzheng@dep.ecnu.edu.cn
