基于证据理论与云模型的火电机组节能减排绩效综合评价
2022-06-01马玉锴
马玉锴, 田 亮
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引 言
随着我国工业化进程的不断加快,资源、环境与社会经济发展的矛盾日益凸显。“资源消耗大”、“环境污染高”已经成为我国寻求高质量发展道路上的两大“绊脚石”。我国目前的能源结构仍然以火力发电为主。据统计,中国火电行业装机容量占中国总装机容量的60%,发电量占比达到70%。而燃煤电厂每年所需的煤炭占我国煤炭消耗总量的近50%。作为主要大气污染源,2019年期间,火力发电厂的SO2和NOx排放量分别占中国污染物总排放量的10.8%和7.9%。由此可见,燃煤电厂既是我国最大的煤炭资源“消耗者”,也是极其重要的环境“污染者”[1]。此外,2020 年 9 月 22 日,习总书记在第75 届联合国大会提出,中国确保 2030 年前实现碳排放达峰,力争 2060 年前实现碳中和[2]。这一发言不仅体现了我国的大国担当,也为全球气候治理向前迈进注入了新的动能。为了实现我国这一美好愿景,对火电企业的节能减排改造迫在眉睫。
虽然节能减排改造工作在电厂已经开展了多年,各项指标都有了相应的国家规定,但是依然没有形成一种公认科学合理的评价方法,综合考虑所有指标因素后,给发电企业一个全局的节能减排绩效评估,及时反映企业当前的节能减排状态。为了解决这一问题,前人为此做了大量的研究。曹丽华等[3]将灰色关联理论与TOPSIS法相结合,实现了火电机组的整体节能减排评价;孙建梅[4]等运用了模糊物元法与层次分析法,一定程度上解决了层次分析法权重设定过于主观的问题;张雷等[5]提出一种基于全排列多边形图示指标的方法,能够以图像的方式直观显示机组整体节能减排效果。
考虑到火电机组节能减排绩效评估的各个状态评级并不是一个硬性的区间,评级划分存在一定的模糊性;同时因仪器精度、测试环境、专家主观判断的影响,整个评价过程中也存在着一定的随机性。而上述方法均仅考虑到了评估过程的模糊性而忽略了随机性。云模型作为一种兼顾模糊性与随机性的建模方法,在此种情形下是一种更为符合实际的模型。此外火电机组节能减排整体的绩效评估需要从多个维度进行考量,综合各方面信息。证据理论是近年来被诸多学者广泛采用一种信息融合方法,其本身具有极强的信息融合能力及决策能力,主要用多维度信息融合及处理决策过程中的不确定性[6-8]。它采用信度函数的概率表示,引入了“不确定”元素,很好的兼容了云模型所具有的随机性及不确定性。将云模型与证据理论相结合进行某项事物的综合评价已经成为近年来的新兴方法,在变压器状态评估、电源规划综合评价等多个领域得到广泛应用[9-12]。
本文采用云模型与证据理论相结合的方法进行火电机组节能减排绩效评估。首先选取合适的评价指标构建火电机组节能减排评价指标体系;接着参考政府相关文件确定各指标的评价等级及评级范围;之后建立相应的隶属云模型,获取待评价机组各项指标评级的信度函数值;最后用一种基于动态权重系数的证据理论融合公式进行多维信息的融合,取融合结果中信度最大的评级作为最终的综合评价结果。文末结合实际算例,验证了该方法的有效性。
1 节能减排绩效评估体系的建立
1.1 节能减排评价指标的选取
火电机组的整体节能减排状况是由多个相互关联的指标所构成的有机整体,其所包含的影响因素众多。只有选取合适的评判指标,才能建立正确的评价体系,从而保证整个评价系统的合理性。火电机组节能减排绩效评价指标的选取应具有以下几点原则:
(1)要以“节能”和“减排”为指导思想,同时满足国家相关政策的要求。
(2)指标应具有代表性和全面性。
(3)指标应具有客观性和可操作性,且所需数据易于收集。
本文参考国家能源局颁布的《燃煤发电企业清洁生产评价导则》和文献[3-5],依据上述3点原则并结合相关专家意见,最终选定了以下8个评价指标:发电煤耗c1(g/kW·h)、厂用电率c2(%)、单位发电量耗水量c3(kg/kW·h)、单位发电量耗油量c4(kg/kW·h)、烟尘排放量c5(mg/m3)、SO2排放量c6(mg/m3)、氮氧化物排放量c7(mg/m3)、单位发电量废水排放量c8(kg/kW·h)。其中c1~c4为节能指标,c5~c8为环保指标。所建立的火电机组节能减排评价指标体系如图1所示。

图1 火电机组节能减排评价指标体系Fig.1 Evaluation system for energy saving and emission reduction of thermal power units
1.2 节能减排评价等级的确定
本文将发电机组节能减排状况分为 4 个评级,分别用“优秀”、“良好”、“中等”和“差”表示发电机组各项指标的节能减排效能。各等级评估标准如表1所示。
由于超临界机组是我国需要进行节能减排改造的主要机组,在此选取600 MW级超临界机组作为评估对象。本文参考《节能减排“十三五”规划》、国家质监局颁布的《电力企业节能降耗主要指标监管评价标准》及《火电厂大气污染物排放标准》结合文献[13]和相关专家意见,依据表1所给定的评级标准,最终给出具体的各评级参数取值范围。参数范围如表2所示。

表1 火电机组节能减排评估标准

表2 火电机组节能减排评级范围
2 证据理论介绍
D-S证据理论是一种严格的“与”运算方法,这种方法会加强对共同目标的支持力度,具有聚焦作用及极强的决策能力,是近年来被诸多学者广泛采用一种信息融合方法,主要用多维度信息融合及处理决策过程中的不确定性,如今已被广泛应用于系统的评估评价方面[14-16]。
2.1 证据理论的基本概念
假设研究对象的全体集合为辨识框架Θ,框架内元素具有互斥且穷举的特征。其中2Θ为Θ的幂集,A为2Θ的任一子集。若函数m满足:
m(Ø)=0
(1)
(2)
则式中m称为Θ的基本概率分配函数;A被称为基本概率分配函数m的焦元;m(A)表示相关证据对事件A的支持程度,又称为信度函数值或置信度。
假设m1与m2分别为同一辨识框架Θ上的2个独立信息源,其相应的焦元分别为A1,A2, … ,Ai与B1,B2, … ,Bj。
则D-S证据理论组合规则可表述为
(3)
(4)
式中:m(C)为融合m1与m2后得到的信度函数值;K是冲突因子,代表了证据间的冲突程度。
以证据理论的思维来理解火电机组节能减排绩效评估这一过程,可将“火电机组节能减排绩效评估”视为一个需要判断的问题,对于该问题的评判结果,即{优秀,良好,中等,差}可视为识别框架。每个评价指标都可以看作一个独立的信息源,其测量得到的数值,可从不同角度来反映该系统节能减排效能的好坏。最后将所有的信息源用证据理论融合公式进行融合,按“最大隶属度”原则,取隶属度最大的评语等级作为火电机组整体节能减排绩效评估结果即可。
2.2 基于动态权重系数的证据理论合成公式
但是经典证据理论合成方法本身存在一定的缺陷,在使用其合成两个高度冲突的信息源时,常常得到有违常理的结果。而各个指标的评价之间是相互独立的,在实验过程中经常会出现多个指标的评级结果高度冲突的情况。如下例所示,假设某电厂各指标信度函数值为表3这一较为极端的分布,其中指标c1~c7都高信度指向中等评级,仅c8一项指标被判定为优秀评级。

表3 示例电厂信度函数值Tab.3 Belief function assignment of example power plant
根据普通证据理论融合公式融合指标c1~c7,得到{优秀,良好,中等,差}的融和结果信度值分别为(0,0,1,0),按照最大隶属度原则,最终评级为“中等”,符合实际情况。但若用普通证据理论融合公式融合指标c1~c8,融合结果为(0,1,0,0),评级为“良好”的信度值为1,评级为“中等”的信度值反而为0。这样的融合结果显然不符合人们的正常认知,即使c8一个指标评级为“优秀”,但是其余七个指标的评级均高信度指向“中等”,融合c8后,评级结果理应也应显示为“中等”。这正是由于c8的信度函数值与其他信息源的信度函数高度冲突导致。
为了避免上述情况的发生,本文选用一种带有动态权重系数的证据理论融合方法进行信息融合。新的融合方法步骤如下:
若一个完整的识别框架Θ是由两两互斥的命题A1,A2,…,Am所组成。假设每个命题有n组信息源待融合,m(Ak) (k=1,2,…,m)表示命题Ak的信度函数值。
(1)求取每个命题Ak的平均信度函数值m*(Ak)。
(5)
(2)依次计算第i个信息源的信度函数值与m*(Ak)的距离di。
(6)
(3)冲突信息源i的动态权重系数discount计算如下:
(7)
(8)
(9)
(4)则带动态权重系数的信度函数计算公式如式(10)、(11)所示:
m′(A)=discount·mi(A),(A⊂Θ)
(10)
m′(Θ)=discount·mi(Θ)+1-discount
(11)
最后将按上述方法计算后得到的带动态权重系数的信息源按照经典D-S组合规则融合即可。方法细节见文献[17],在此不过多赘述。
将表3的数据通过带动态权重系数的证据理论融合规则融合指标c1~c8,融合结果为(0, 0.001, 0.999, 0),依据最终融合结果,该厂整体节能减排评估结果为“中等”,符合人们正常认知。可以看到本文使用的带动态权重的证据理论融合公式在一定程度上克服了传统证据理论对高度冲突信息源不适用的缺陷,使融合结果更加符合人们正常认知,是一种更为适合火电机组节能减排绩效评估这一情景的融合方法。
3 云模型介绍
证据理论应用过程中极为重要的一个步骤是获取各个信息源的信度函数值。传统的信度函数获取方法大多是由模糊数学中隶属度函数获取,但是在定量值与定性概念的转换中,因各人的经验及主观意识的不同而导致整个过程存在着一定的随机性和不确定性。云模型是由中国学者李德毅于2000年所提出的一种不同于传统隶属度函数的模型概念。其将模糊数学中隶属度函数的模糊性与概率论中的随机性相结合,从而得到了形象化的隶属云。实现了精确的定量值与不确定的定性概念之间的相互转换。目前已被广泛应用于评估过程当中[18,19]。
3.1 云模型的基本概念
云模型在数学上可以写为Y(Ex,En,He),该式所表达的含义是Y所代表的定性概念可以通过期望(Ex)、熵(En)、和超熵(He)这3个数字特征来表示。其中Ex相当于正态分布中的期望,是所有云滴分布的重心,也是最能代表定性概念的点。En相当于正态分布中的标准差,反映了定性概念中的模糊性,其数值越大,定性概念所表示的范畴越宽泛。He是熵的熵,反映了定量值到定性概念转变过程中的随机性,超熵越小,云滴的凝聚度也就越好[20]。图2是参数为Y(0,1,0.1)的正态云模型,其相应的数字特征如下。

图2 云模型及其数字特征Fig.2 Cloud model and its digital features
3.2 云模型获取隶属分布
根据上述云模型的定义,以火电机组节能减排绩效评估的8个指标为不同维度的信息源,以{优秀、良好、中等、差}为识别框架,分别建立各个指标对应的云模型来获取各指标的信度函数分布。

(12)
式中:λi根据不同指标的模糊性和随机性,由多次试验结合专家经验获取。
根据表2所给出的各指标对应的评语等级范围,通过式(12)可计算得到所有指标4个评级的云模型参数。计算结果如表4所示。

表4 各指标评级云模型参数Tab.4 Cloud model parameters of each index rating
对其中“优秀”和 “差”2个边界等级采用半正态云分布,“良好”和 “中等”评级采用正态云分布,绘制出各指标评级对应的云模型。以指标c1为例,其评级云模型如图3所示。

图3 c1各评级云模型Fig.3 Each rating cloud model of c1
由图3可知,指标c1各评级云模型从整体分布趋势来说,近似于标准的正态分布,这符合自然界中人们对某一概念认识的客观规律。但是在局部的取值上又是在正态分布曲线附近的一个合理区间随机波动。如281 g/kW·h这一介于“良好”和“中等”之间的概念模糊点,在云模型中,将其评判为“良好”的信度函数取值范围约为[0.55,0.65],评判为“中等”评级的信度函数取值范围约为[0.05,0.25]。这反映了不同专家对同一发电煤耗的评判,会随着各人不同的经验、知识、及当前的主观判断进行随机波动,但是取值又处在一个较为合理的范围内。在定量数值与定性概念的相互转变方面,相比于传统的模糊隶属度函数,这是一种更为符合客观实际的模型,因此本文采用云模型代替传统的模糊隶属函数来获取各信息源的信度函数值。
4 节能减排绩效评价流程
基于上述分析,给出一种基于云模型和改进证据理论的火电机组节能减排绩效评估模型。其评估流程如图4所示。

图4 基于云模型与证据理论的节能减排绩效评估流程图Fig.4 Flow chart of energy conservation and emission reduction evaluation based on cloud model and evidence theory
5 实例分析
5.1 火电机组节能减排绩效评估计算
为验证该方法的有效性,选取某600 MW电厂作为分析对象。2017年该厂因多项节能减排数据未达到最低标准或处于较差水平,收到了相关部门的整改建议。在之后的两年间,该厂积极响应国家号召,一方面对管道及锅炉运行进行了优化,同时对锅炉本体受热面及风机进行了相应改造;另一方面引入了电袋除尘、双循环脱硫、低氮燃烧及其他先进技术,使机组整体的节能减排性能得到了大大提升。该厂改造前及改造后相关数据如表5所示。
基于前文所构建的节能减排绩效评价指标体系,得到4个评语等级集U={u1,u2,u3,u4}={优秀,良好,中等,差}。将电厂数据输入对应的云模型,即可得到对应各个评级的隶属度向量ui=(ui1,ui2,ui3,ui4)。接着根据ui构造证据理论所需的信度分配函数m(ci)=(ui1,ui2,ui3,ui4,θi),其中θi表示当前指标评级的不确定度,由式(13)计算得到。
(13)
将各指标所对应的m(ci)组成信度函数分配表,利用前文所述的基于动态权重系数的证据理论进行多维信息融合。其信度函数分配表及融合结果如表6、表7所示。

表5 原始数据Tab.5 Raw data
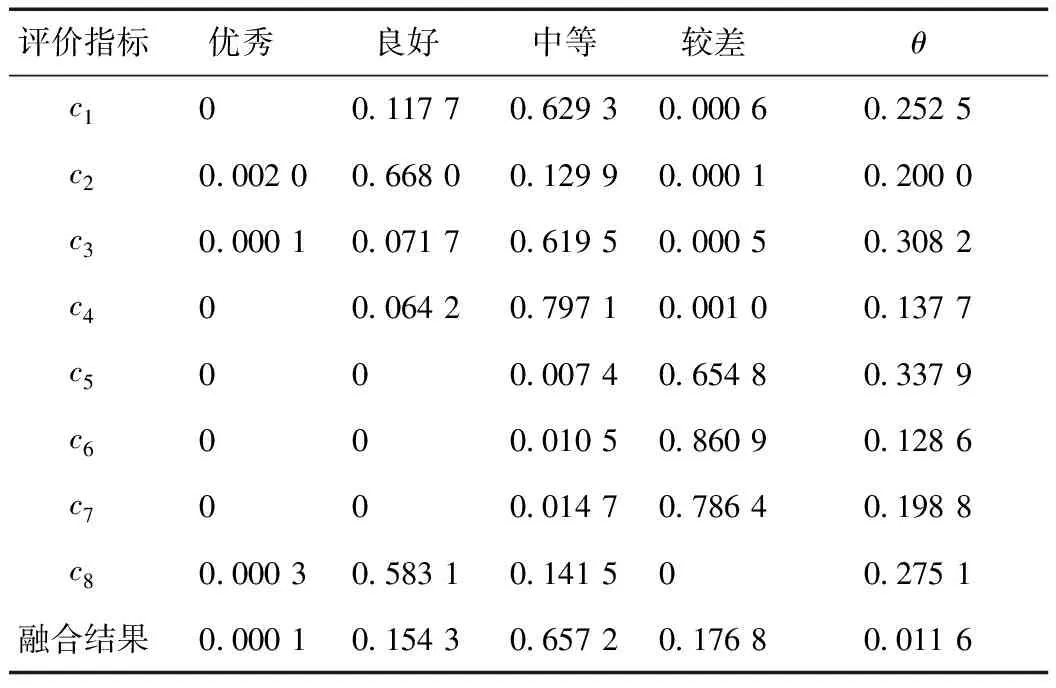
表6 改造前信度函数值及融合结果
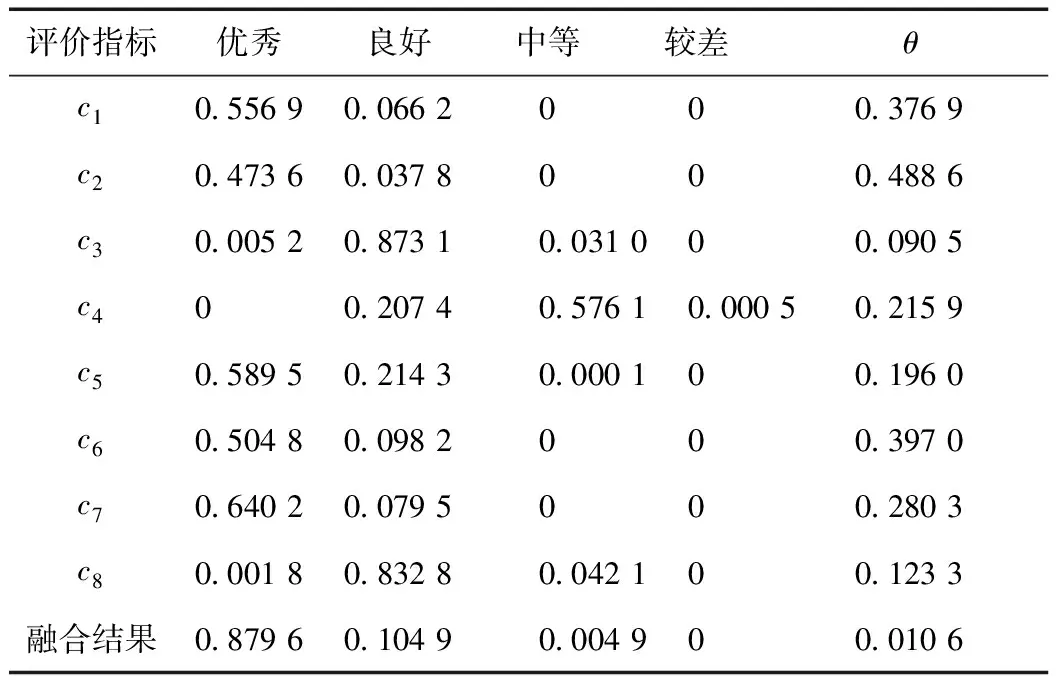
表7 改造后信度函数值及融合结果
依据最大隶属度原则,由融合结果可知该厂改造前机组整体节能减排绩效处于“中等”评级,改造后处于“优秀”评级。
5.2 结果分析
(1)通过分析该厂改造前相关数据,可知改造前该厂供电煤耗、单位发电量耗水量、单位发电量耗油量这3项指标处于“中等”评价区间;厂用电率、单位发电量废水排放量虽然处于“良好”评级区间,但也极为靠近“中等”评级;即使烟尘排放量、SO2排放量、氮氧化物排放量位于“差”评级,但是综合考虑多方面指标,本文给出“中等”的整体评价,是一较为合理的评价。
(2)再分析改造后相关数据,该厂改造后供电煤耗、厂用电率、烟尘排放量、SO2排放量、氮氧化物排放量这5项指标均得到了较大的提升,处于“优秀”评级,位于行业内领先水平。虽然单位发电量耗水量、单位发电量废水排放量评价为“良好”,单位发电量耗油量评价为“中等”,但是综合所有指标来看,本文给出“优秀”的整体评级也是一合理的评价。
(3)对于各指标评级中的不确定度,可以看到进行多维信息融合前,表5中的各评级不确定度值最大达到了0.337 9,表6中的不确定度最大值甚至达到了0.488 6。但是经过证据理论融合后,融合结果中表5的不确定度仅为0.011 6,相较于融合前各指标中不确定度最大值降低了96.6%;表6中不确定度仅为0.010 6,相较于融合前各指标中不确定度最大值降低了97.8%。因此使用证据理论进行多维信息融合的方法可以有效地应对评价过程中所产生的模糊性和不确定性,为决策者提供了更为合理的评判依据。
(4)通过对该电厂近年来各项指标的分析,可以看到该电厂通过不断地技术改进,各类节能减排指标均得到不同程度的改善,其整体节能减排绩效评级也从“中等”变为 “优秀”,电厂所实施的节能减排改造效果明显。但是单位发电量耗水量、单位发电量耗油量、单位发电量废水排放量这3项指标依然存在进步空间。因此,该电厂应继续秉持“节能减排”的战略意识,淘汰落后工艺和设备,引进先进技术,进一步提高其节能环保水平。
6 结 论
(1)由于当前火电行业还没有形成一种公认的、科学合理的火电机组节能减排绩效评估方法,结合新时代政府节能减排相关要求,本文提出一种基于云模型与证据理论的火电机组节能减排绩效评估方法。针对定量数值到定性概念这一转变过程存在的模糊性和随机性,利用云模型进行评语建模来获取信度函数值,相较于传统的模糊隶属度函数,是一种更为符合客观规律的建模方法。
(2)使用了一种基于动态权重系数的证据理论合成公式来融合各个维度的指标信息,不但兼容了云模型所具有的不确定性,而且通过证据理论合成公式,减少了最终结果的不确定度。
(3)通过实例分析,验证了该方法的正确性和有效性,为火电机组节能减排绩效评估问题提供了一种可行的方法思路,具有一定的参考价值。
