正弦算法优化正则化ELM在NOx排放量建模中的应用
2022-06-01马良玉程善珍王永军
马良玉, 程善珍, 王永军
(1.华北电力大学 控制与计算机工程学院, 河北 保定 071003;2.山东电工电气集团有限公司, 山东 济南 250002)
0 引 言
氮氧化物(NOx)对生态环境影响很大,据统计,我国大部分的NOx排放来自燃煤电厂,其跨国界“长距离输送”增加了我国控制NOx排放的国际压力[1]。因此,降低燃煤电厂的NOx排放量已成为当前重要的研究课题。降低NOx排放的方法主要有燃烧过程中控制NOx的产生和烟气后脱硝处理两种。
尽管大部分火电厂已经安装了脱硝设备,通过优化调整降低燃烧过程NOx排放浓度,依然是锅炉运行优化的重要任务。它主要由建立NOx排放预测模型和利用模型对相关的可控参数(如各风门开度、各燃烧器煤量等)进行优化两个阶段组成[2]。因此,建立精确的锅炉NOx排放预测模型对优化燃烧可控参数、降低NOx排放量具有重要意义。
锅炉NOx排放量的影响因素很多,且具有强耦合性和高度非线性等特性,很难用具体的数学函数描述,这给NOx排放建模和优化带来了极大困难[3]。近几年,随着人工智能技术的迅速发展,智能建模和优化技术在锅炉NOx排放预测建模和优化中得到了应用。文献[4]在电厂燃烧调整试验数据基础上,建立了基于BP神经网络的锅炉效率与NOx排放浓度的双目标预测模型。文献[5]采用改进的粒子群算法优化最小二乘支持向量(LSSVM)的模型参数,并以此建立了锅炉NOx排放模型。文献[6]建立了基于集成支持向量机的NOx排放预测模型,采用距离学习粒子群算法对NOx排放优化,优化结果对电厂运行具有一定指导意义。文献[7]利用快速学习网建立了锅炉NOx排放的预测模型,以改良鸡群(A-CSO)算法优化锅炉运行的可调参数,得到锅炉燃烧的优化调整方式。文献[8]提出了一种基于压缩感知最小二乘支持向量机(CS-LSSVM)的电厂燃煤锅炉NOx排放预测模型,缩短了计算时间。文献[9]提出一种基于改进多元宇宙优化算法(IMVO)和加权最小二乘支持向量机(WLSSVM)的锅炉NOx排放优化方法,相对于其他几种预测模型具有更高的预测精度,使优化后的NOx排放浓度更低,具有更好的寻优效果。
单隐层前馈神经网络(Single-hidden layer feed forward neural network, SLFN)因其良好的学习能力在众多领域得到了广泛应用[10-14],但BP算法等传统的学习算法具有训练速度慢、易陷入局部最优等缺点。极限学习机(Extreme learning machine, ELM)采用随机产生输入权值、阈值的方式,在训练过程中不需再进行调整,只需要设置适合的隐含层节点数和激活函数,就能够获得唯一最优解[15]。ELM克服了传统SLFN参数复杂、易陷入局部最优等问题,具有良好的学习效率和泛化能力。正弦算法[16]是曲良东等在分析正弦余弦算法(Sine cosine algorithm, SCA)[17]的基本理论后提出的一种高效的简化算法,其结构简单且易于实现,具有良好的全局优化能力。
因此,本文结合某1 000 MW超超临界机组目标值寻优项目,在机组变工况历史运行数据的基础上,建立了基于正弦算法优化正则化极限学习机的锅炉燃烧NOx排放量预测模型,为锅炉配风配粉优化奠定了基础。
1 正则化极限学习机
极限学习机是一种改进的SLFN网络[18],其网络结构如图1所示。设训练样本集(xi,yi)包含N条样本,若隐含层个数为L,激活函数为g(x),则网络输出如公式(1)所示。
(1)
式中:wj表示第j个隐含层节点与输入层节点的连接权值;bj表示第j个隐含层节点的阈值;βj表示隐含层节点与输出层节点的连接权值;若记矩阵H为 ELM隐含层的输出矩阵,则公式(1)可记为
Hβ=Y
(2)
文献[19]证明:激活函数g(x)无限可微时,ELM随机获取的wj和bj在模型训练过程中不需要进行调整。则隐含层节点与输出层节点的连接权值β可以通过求解公式(3)获得。

(3)
若隐含层节点数L和训练样本数N相等,则ELM可以以零误差拟合真实值。但在大多数现实应用中,隐含层节点数远小于训练样本数,对此,文献[19]提出公式(3)的最小二乘解为
(4)
式中:H+为矩阵H的Moore-Penrose广义逆。
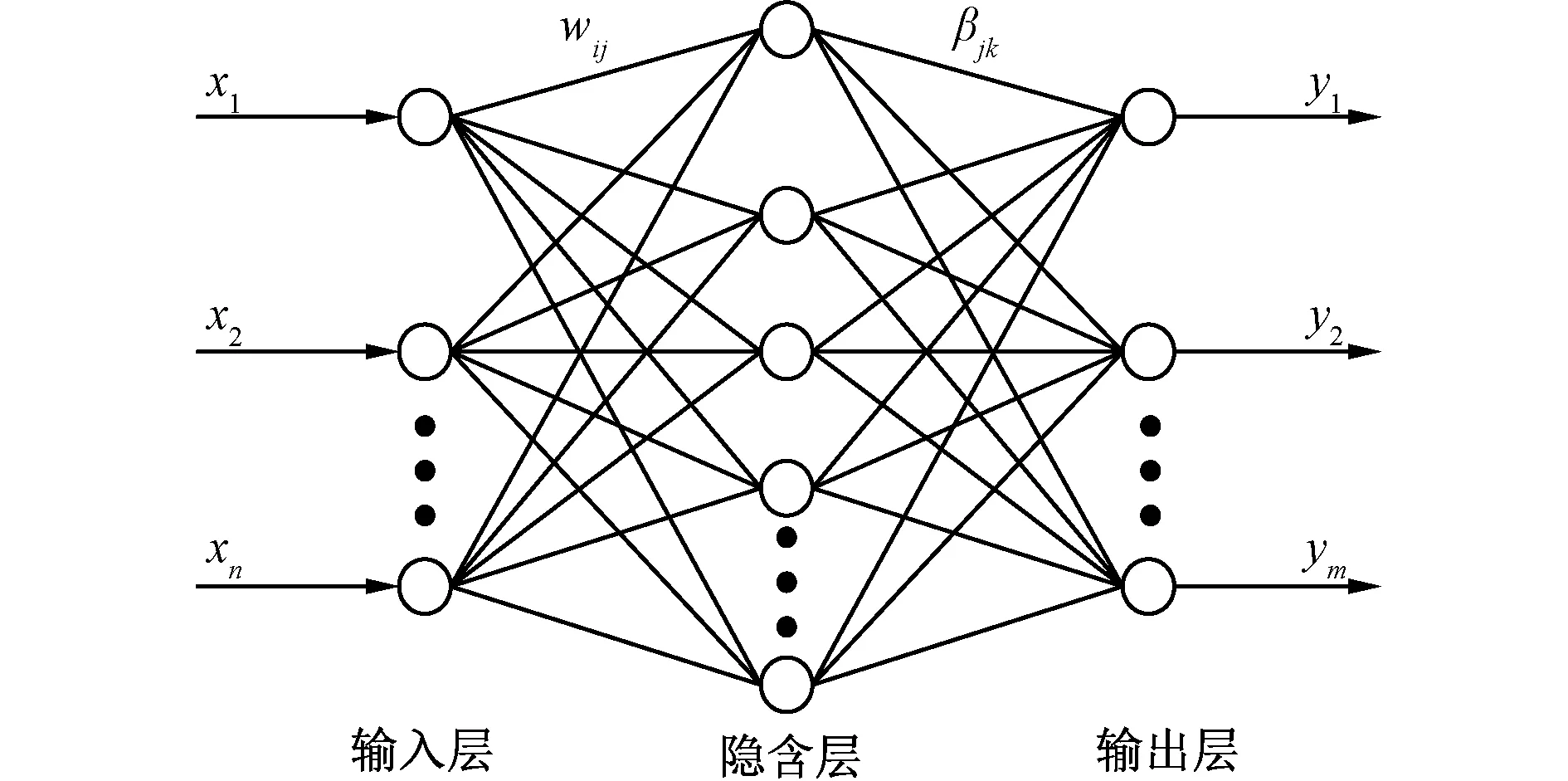
图1 ELM的网络结构Fig. 1 Network structure of ELM
统计学中的风险函数通常包括经验风险和结构风险两部分,而标准ELM算法只考虑了经验风险,隐含层节点数过多时极易出现过拟合现象[20]。因此,在公式(3)中引入L2正则化系数C,将其转化为如下问题。
(5)
式中:C为正常数。此时,公式(5)的解为
(6)
综上所述,RELM算法的计算步骤如下:
(1) 确定算法的隐含层节点数L和无限可微的激活函数g(x);
(2) 随机设置输入层与隐含层的连接权值w和隐含层节点的阈值b;
(3) 计算隐含层输出矩阵H;
2 正弦算法
SCA算法仅通过正弦和余弦函数性质迭代进行寻优,先在可行域内随机产生m个解的位置并计算各解的适应度值,然后通过全局搜索和局部开发阶段逐渐逼近全局最优解。该算法的位置更新公式为
(7)
(8)

由于正弦函数的和余弦函数的图像仅相差π/2个单位,标准SCA算法由参数r4以50%的概率决定进行正弦操作或者余弦操作。文献[13]发现正弦函数和余弦函数在(0, 2π]上数值的分布相同,即当r2在(0, 2π]上取随机数时cos(r2)与sin(r2)效果相同,并且正弦函数取正值和负值的概率相等。因此,该文献提出了一种结构更为简单但执行效率更高的正弦算法,并通过测试函数验证了其良好的全局搜索能力。简化SA算法的位置更新公式如下:
(9)
为提高算法的局部开发能力,本文在式(9)的基础上引入一种自适应调整的惯性权重,改进后的位置更新公式如下:
(10)

(11)
式中:ωmax、ωmin为分别为最大和最小惯性权重。
3 NOx排放量预测模型
3.1 变量选取数据处理
为保证预测模型的精度,辅助变量应选取对NOx排放量有直接或间接影响的可实时检测变量[21]。由于磨煤机组合方式不同,炉膛温度分布、煤粉颗粒在炉膛内停留时间以及运行磨组到燃尽风的平均距离也不同,会影响锅炉燃烧NOx的排放特性。因此,在建立NOx排放量预测模型时,需考虑磨煤机组合方式。本文采用各台磨煤机给煤量代表磨煤机组合方式。同时考虑到总风量及二次风箱与炉膛差压对NOx排放量的影响,最终确定NOx排放量预测模型的输入、输出变量如表1。

表1 NOx排放量预测模型的输入、输出变量Tab.1 Input and output variables of NOx emission model
为保证数据样本能够准确地反映电厂实际情况,建模采用的样本均源自某1 000 MW超超临界燃煤机组真实的DCS历史数据库。选取机组正常变工况运行时2 160组锅炉运行数据进行建模试验,数据采样周期为1 min,机组负荷及SCR脱硝装置入口的NOx排放量变化曲线如图2所示。

图2 原始建模数据负荷和NOx排放量变化曲线Fig. 2 Load and NOx emission curves of the original data
采用Savitzky-Golay滤波器[22]对数据进行平滑处理,将所得数据归一化至[-1,1]范围内。其中1 440组作为训练集对网络模型进行训练,剩余样本作为测试集验证模型的精度与泛化能力。SA-RELM模型在NOx排放量建模中的应用流程如图3所示,其中序列是指RELM的输入权值阈值。
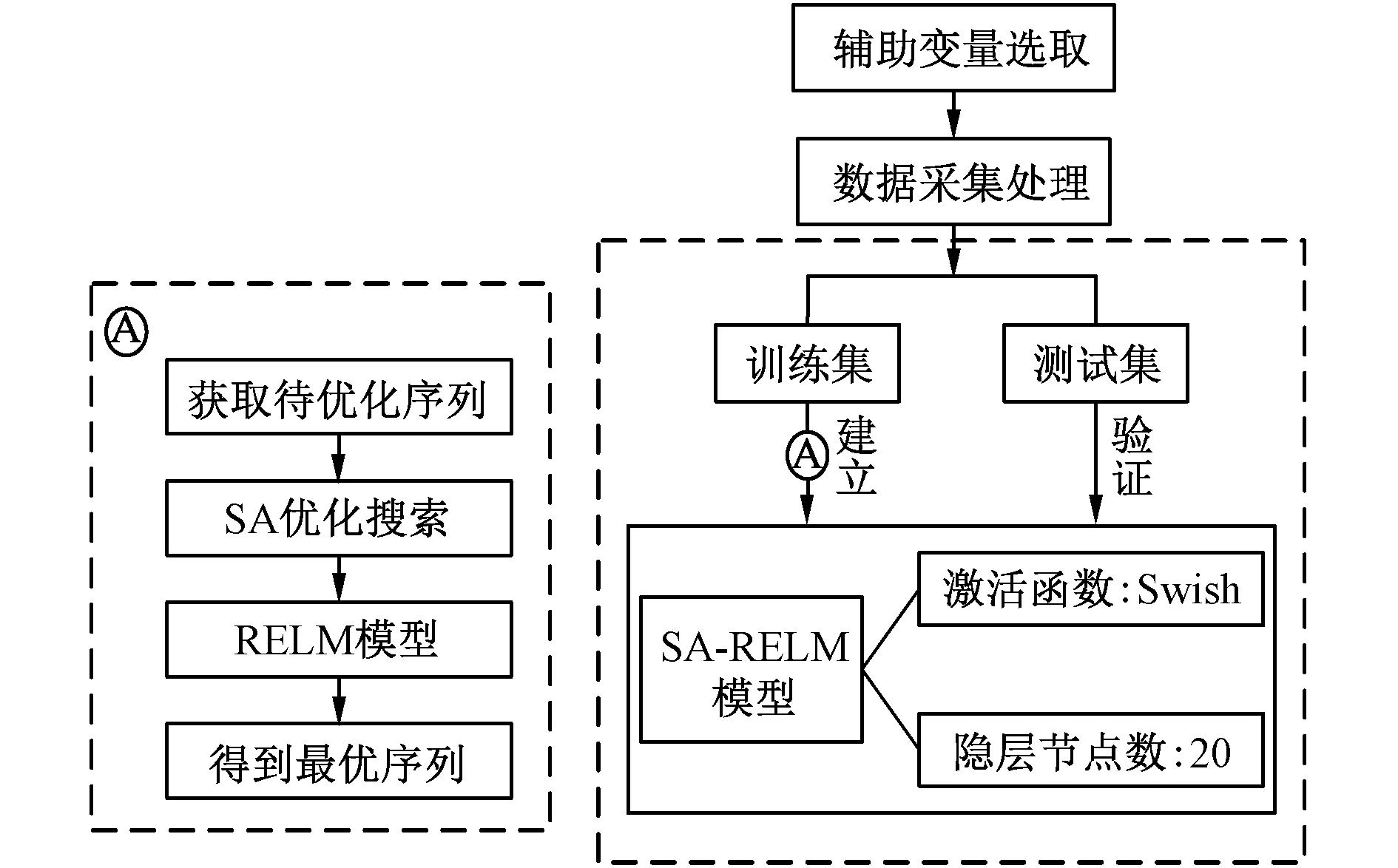
图3 NOx排放量建模流程Fig. 3 NOx emission modeling process
3.2 激活函数选取
激活函数对极限学习机的网络性能有很大影响,选择合适的激活函数能够有效提高模型的预测精度和泛化能力[11]。为分析不同激活函数对RELM的影响,选取Sigmoid、Tanh、Swish等3种不同激活函数(几何图像见图4)进行对比。其中,Swish是2017年由Google提出的一种新型激活函数[23],其表达式为
f(x)=x·sigmoid(x)=x/1+e-x
(12)

图4 不同激活函数图像Fig. 4 Image of different activation functions
为消除初始值、隐层节点数的影响,实验时保持40个隐层节点不变,计算100次实验平均相对误差(MRE)和平均绝对误差的(MAE)均值作为评价指标。实验结果如表2所示。
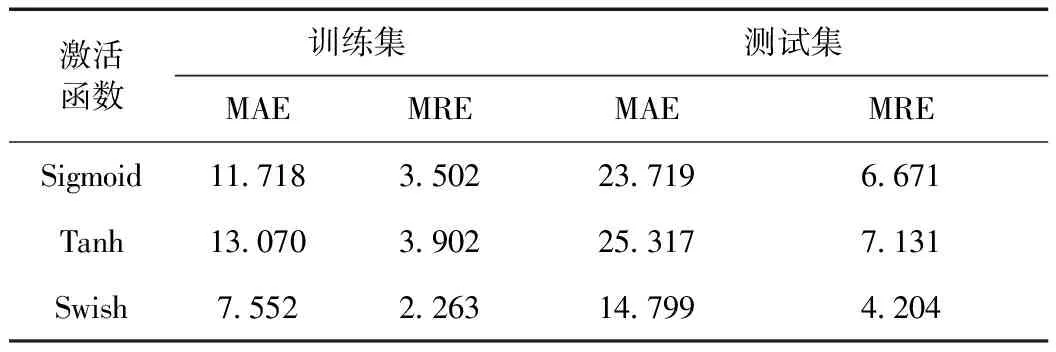
表2 激活函数测试结果Tab.2 Test results of activation function
由表2可以看出,与传统的Sigmoid和Tanh函数相比,Swish函数的MAE和MRE都有明显降低,在RELM建立的NOx模型中具有更好的表现。
3.3 隐含层节点确定
隐含层节点是影响RELM算法网络性能的一个重要因素,节点过少不能保证模型的预测精度,过多可能会导致过拟合现象,影响RELM的泛化能力。本文采用奇异值分解的方法确定隐含层节点个数,其基本理论如下[24]:


图5 隐含层节点的贡献率Fig. 5 Contribution rate of hidden layer nodes
实验结果如图5所示。可以看到i=20时的累计贡献率已经达到99.95%,此时以Swish为激活函数的RELM模型预测结果评价见表3。

表3 20个节点模型评价结果Tab.3 Evaluation results of 20 nodes model
对比表2、表3隐含层节点数分别为40和20时的模型预测结果可见:节点数取20时RELM训练样本集建模精度略有下降,但针对测试集的预测精度不降反升,模型泛化能力明显提高。因此最终确定基于RELM的NOx排放模型的网络结构为:34-20-1。
3.4 模型建立与验证
考虑到RELM随机产生的输入权值阈值会影响网络性能,采用SA对RELM 的初始输入权值和阈值进行优化。
根据上文所述分别建立SA-ELM、PSO-RELM及SA-RLEM三种NOx排放量预测模型,激活函数g(x)均选用Swish函数,隐含层节点数取20,比较不同模型的预测效果。3种模型的预测值与真实值对比及相对误差曲线如图6至图7所示。
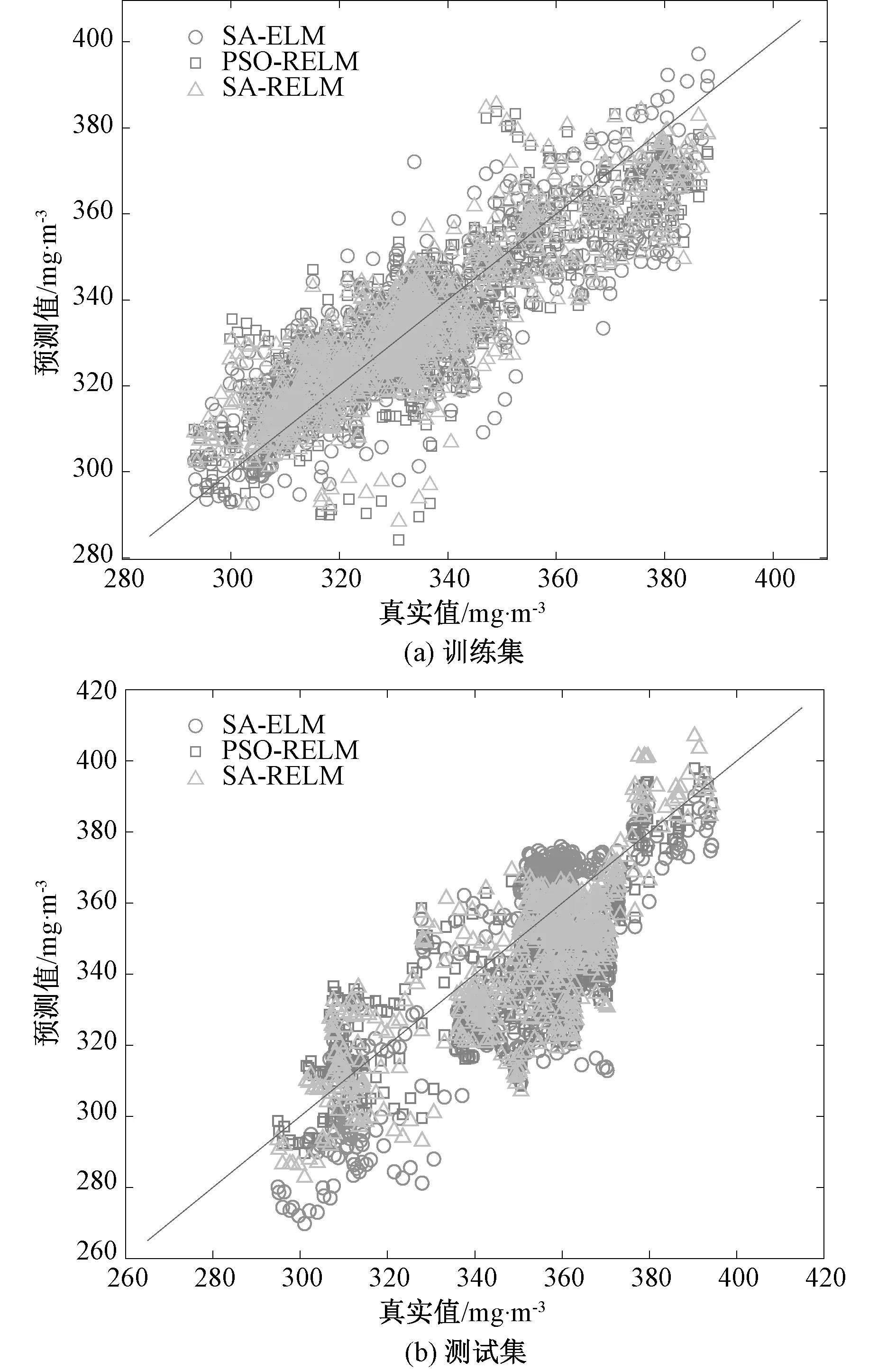
图6 各算法不同样本集预测结果Fig. 6 Prediction results of different sample sets for algorithm

图7 相对误差曲线Fig. 7 Relative error curve
由图6(a)可知:SA-ELM等3种算法建立的预测模型对训练样本的拟合程度都很高。图6(b)表明:针对测试样本,SA-RELM和PSO-RELM建立的模型具有更好的泛化能力。而图7表明,SA-RELM算法在测试集的预测相对误差更小、更稳定。采用MAE、MRE以及相关系数(R2)对网络模型的预测结果进行评估,结果见表4。

表4 模型评估结果Tab.4 Results of model evaluation
由表4可见,引入L2正则化系数的SA-RELM建立的NOx排放量预测模型比SA-ELM模型具有更好的泛化能力;对比RELM(见表3)、PSO-RELM与SA-RELM模型的评估结果可见,经SA算法优化RELM输入权值和阈值的预测模型具有更高的精度。
4 结 论
为降低锅炉燃烧的NOx排放量,建立了基于SA-RELM的1 000 MW火电机组NOx排放量预测模型。分别对影响RELM的激活函数和隐含层节点数进行实验分析,确定了Swish为算法激活函数,隐含层节点为20个。为减小输入权值阈值对RELM精度的影响,提出一种引入自适应调整惯性权重的正弦算法对其进行优化。将SA-RELM与SA-ELM、PSO-RELM的预测结果进行对比,实验结果表明:基于SA-RELM算法的NOx排放量预测模型具有更高的精度和更强的泛化能力,为利用预测模型优化锅炉配风配粉,降低NOx排放奠定了良好的基础。
