数据驱动的自动化机器学习流程生成方法
2022-05-31陈高建栗倩文袁云静曹嘉琛
陈高建, 王 菁, 栗倩文, 袁云静, 曹嘉琛
(北方工业大学大规模流数据集成与分析技术北京市重点实验室, 北京 100144)
生活中很多领域需要用到数据分析,根据不同的数据集选择合适的模型并训练、优化参数是一件专业、复杂并且耗时的事情,对业务人员的专业水平和经验都要求非常高。如何根据数据集自动生成机器学习流程(pipeline)是一个难点问题。针对此问题,不少学者开展了自动化机器学习(automated machine learning,AutoML)的研究。自动化机器学习旨在学习如何学习以数据驱动、客观和自动化的方式做出决策,在优化性能的同时解决与数据集有关的任务,用户只需输入数据集和任务,自动化机器学习系统就会自动生成最适合的方法[1]。
目前的自动化机器学习工具普遍存在耗时长和性能低的问题,对系统的资源消耗较大,极大地影响了机器学习的效率。因此解决自动化机器学习耗时长和性能低的问题十分必要,一方面可以使人们更快地得到更准确的结果,另一方面可以扩展机器学习在其他领域的应用范围,促进机器学习的发展。
分析当前自动化机器学习方法,大多针对数据集和任务需求组合机器学习算子来构造流程,尚没有考虑到利用相似数据集的历史知识来加快流程构造效率。随着大数据时代的到来,产生了海量数据,如在流行的数据分析服务平台OpenML[2]上,存在着21 000左右用户上传的数据集。针对这些数据集,用户创建了大量的数据分析任务。由于存在海量的数据集,往往会存在相似较高的数据集,可以通过借鉴和利用相似数据集的历史知识,辅助构建机器学习流程。
本文从数据集相似性和强化学习的角度入手,提出一种数据驱动的自动化机器学习流程的生成方法,根据数据集的数据特征与历史数据集进行相似度匹配,复用相似数据集的历史知识,指导机器学习流程的生成。实验结果表明:该方法在耗时方面缩短至分钟级别,对比同类别工具,流程性能也得到进一步提升。
1 相关工作
自动化机器学习可以为给定的任务和数据集找到最佳的机器学习流程,主要实现方法有:可微分编程[3](differentiable programming)、贝叶斯优化[4]、树搜索[5]、进化算法[6]和强化学习[7]等。
可微分编程是一种新型的编程方式,它强调组装可微分组件并且通过端到端优化来学习整个程序。自动化机器学习中常用的BP算法(error back propagation)就是以求“微分”为基础的。不同于传统编程方式,可微分编程可以让机器机械地处理自动微分,很大程度上减少人力的繁重工作[3]。超参数选择对于机器学习流程的性能有着很大作用[8],贝叶斯优化算法则主要用来进行超参数优化。AutoWEKA[9]和Autosklearn[10]在可微分编程和贝叶斯优化基础上,利用高斯过程、随机森林或TPE(tree-parzen estimator)算法[11]来捕获参数值和性能度量之间的关系,从而解决组合算法选择和超参数优化问题。树搜索将搜索空间表示为一颗树,该树的节点是算法或超参数,并使用相应搜索策略搜索最佳分支,使用树搜索方法的代表工作是Auto-Tuned Models[12]。进化算法的代表工作主要有TPOT[13]和Autostacker[14],TPOT将机器学习流程表示为树,而Autostacker将它们表示为堆叠的层。强化学习通过学习策略以达成回报最大化或实现特定目标。随着AlphaZero[15]的出现,标志着强化学习在围棋方面的成功应用。受其启发,AlphaD3M[16]使用神经网络预测流程性能和行动概率,并使用MCTS(蒙特卡罗树搜索)和神经网络相互指导,生成对应的机器学习流程,极大地降低了机器学习流程生成的时间。AlphaZero每次迭代更新都始终维护着一棵MCTS树,但是对于AlphaD3M来说,由于输入数据集的不同,每个数据集相当于独自维护着属于自己的MCTS树,多个数据集之间无法产生关联,历史搜索知识无法复用,这大大增大了资源的浪费。
上述自动化机器学习系统分别使用不同的实现方法,具有各自的优点,但是都没有考虑到数据集的相似性。历史相似数据集往往有很多可以复用的历史信息,如果能够将相似数据集历史信息进行借鉴和复用,一方面可以节省分析人员的时间,另一方面可以复用过去数据集的历史搜索知识,减少机器学习流程生成的时间,提高机器学习流程的性能水平。大量研究表明,相似的数据集在算法适用性上存在关联。Gama等[17]利用统计和信息论的方法提取数据集特征,其结果证实统计相似的数据集可推荐相同的算法。本文对数据集进行特征提取,通过不同数据集的数据特征偏差衡量数据集的相似性。目前相似性的度量方法主要有以下3种:欧氏距离、皮尔逊相关系数和余弦相似性。欧氏距离[18]最初用于计算欧几里德空间中2个点的直线距离,皮尔逊相关系数[19]一般用于计算2个定距变量间联系的紧密程度;余弦相似性[20]用于计算2个向量的夹角。同时,MCTS在寻找高维空间中搜索问题的解决方案时非常高效,可以大大减少搜索的量级[21],从而减少机器学习流程的生成时间。综上所述,本文从数据集相似性入手,将MCTS与神经网络相结合,指导机器学习流程的生成。
2 数据驱动的自动化机器学习流程生成
2.1 方法原理
本文提出的方法是将机器学习流程的生成类比于自博弈[22],行动方可以通过在一组基本算子中选择插入、删除、替换流程基本算子,以迭代的方式构建流程。原理如图1所示,主要阶段可以分为:数据集匹配、博弈模型生成、博弈和机器学习流程的输出。
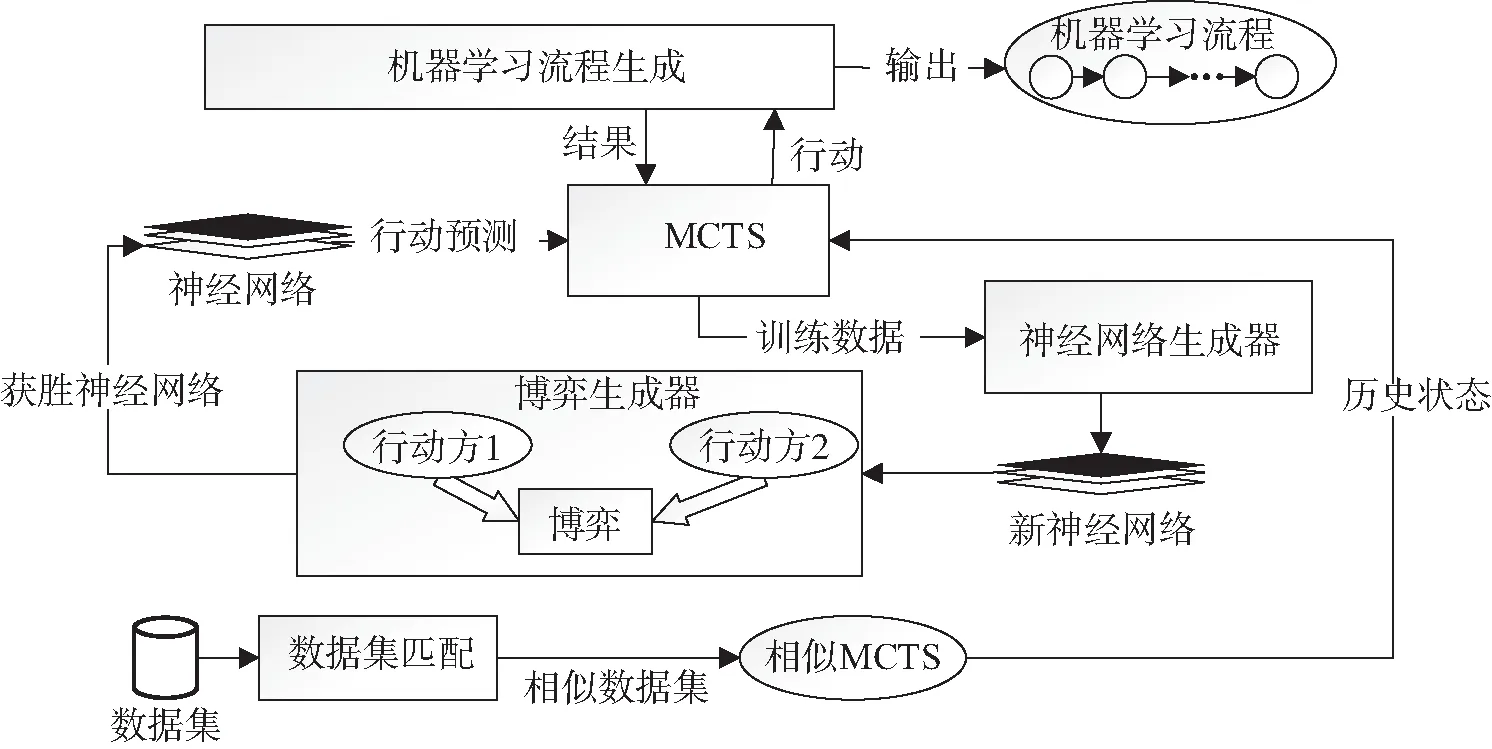
图1 机器学习流程生成原理Fig. 1 Schematic diagram of machine learning pipeline generation
本文提出方法的具体步骤为:
数据集匹配:首先将数据集输入到数据集匹配模块,通过算法匹配到与当前数据集相似性最高的数据集,获取相似数据集的MCTS历史搜索知识。
博弈模型生成:将目前的机器学习流程片段、任务和数据集转化为MCTS对应的节点,神经网络和相似数据集的MCTS历史搜索知识两者共同指导MCTS进行节点扩展和选择,多次的MCTS搜索后,进行对应节点的选择。然后神经网络生成器利用MCTS搜索过程中产生的数据训练神经网络,生成一个新的网络。
博弈:博弈生成器会将新的网络和旧的网络生成一个新的博弈模型,博弈模型中包括2个行动方,两者进行博弈,胜者对应的网络将用于下次MCTS的指导。神经网络和MCTS进行多次迭代优化,MCTS将最优的基本算子输入到机器学习流程合成阶段。机器学习流程生成模块将基本算子添加到目前的机器学习流程中,如果没有结束则继续进行博弈和博弈生成过程。
机器学习流程的输出:当流程生成结束时,会将生成的所有机器学习流程(搜索过程和最后)全部输出。
2.2 数据集相似性比对
对于2个具有相似特征的数据集,如果一个机器学习流程在一个数据集上表现良好,那么它在另一个数据集也往往表现较好[23]。从数据集相似性的角度入手,一方面可以节省数据流程生成的时间,另一方面可以复用过去已建立的流程信息,借鉴或复用以往状态,指导新的机器学习流程的生成,减少资源消耗,并扩展MCTS搜索广度。本文首先通过数据集的文本描述信息进行分类,然后再利用数据集的数据特征,在同一类的数据集中做相似性比对,最后得出相似性较高的数据集。
2.2.1 文本描述信息挖掘
由于数据集的数量庞大,如果将数据集逐一地进行比对,会大幅降低数据分析流程生成的效率。对于同类的文本描述信息,往往存在相似的信息。本文使用数据集的文本信息训练出一个分类器,用来判断数据集的类型,通过类型的限定可以很大程度上减少数据集搜索的数量。
本文首先对所使用的数据集的文本信息进行分词操作,然后进行特征工程处理,将分词后的文本数据转换成特征向量,采用TF-IDF[24]向量作为特征训练一个分类器。SVM算法进行分类器的训练能取得较好的结果[25],更加适合进行文本分类,并且可以使用核函数将原始的样本空间向高维空间进行变换,可以解决原始样本不可分的问题。所以本文采用SVM算法对数据集进行分类。
2.2.2 数据特征挖掘
对于数据集特征,本文参考AlphaD3M使用的数据特征,如数字特征的最大标准、最大基数差、最大标准差、分类特征数等,用于后续数据集相似性的比对,对OpenML上数据集Vehicle进行特征提取,如表1所示。

表1 数据集数据特征Tab. 1 Datafeatures of dataset
2.2.3 相似数据集查找
2.2.3.1 数据特征的相似度衡量
目前相似性的度量方法主要有以下3种:欧氏距离、皮尔逊相关系数和余弦相似性。本文采取余弦相似性来衡量数据集数据特征的相似性,主要考虑如下:一是皮尔逊相关系数和余弦相似性效果类似,但皮尔逊相关系数值要转换区间为[-1,1];二是数据集数字特征之间的量级相差可能较大,用欧氏距离进行计算难以准确算出相似性,而余弦相似性对量级不敏感,在处理量级相差较大的特征时比欧氏距离拥有更好的效果[26]。
余弦相似性用于计算2个向量的夹角,余弦相似性计算公式为
(1)
式中x和y分别代表不同数据集相同特征的特征值。
2.2.3.2 相似数据集查找算法
相似数据集查找算法如算法1所示:输入的数据集通过SVM分类器获取到输入数据集对应的类别;遍历该类别下的所有历史数据集,通过余弦相似度比较数据集的相似性,经过遍历和数据集的相似性对比,得出相似性最高的数据集。
算法1:数据集相似性比对。
输入:数据集D;
输出:相似性最高的数据集bestdb;
1.dts ← SVMClassifier(D);
2.df ← FeatureExtraction(D);
3.FOREACHDiINdts:
4.bestsimilart ← SimilarityComparison(Di,df);
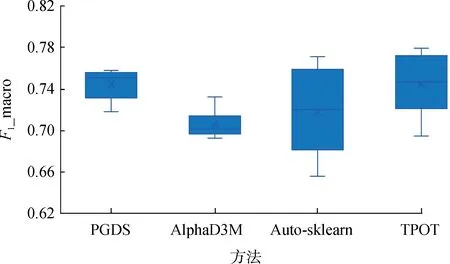
5.IF(currentbest 6.curbest ← bestsimilar; 7.bestdb ←Di; 8.RETURNbestdb。 2.3.1 符号标记 下文所使用到的对应符号标记和说明如表2所示:将当前输入的数据集(D)、任务(T)和目前的机器学习流程(pipeline)记为当前对应状态S(State);将机器学习流程对应基本算子的插入、删除、代替3种行动记为a(action);将机器学习流程的最终性能评估值记为z;当生成机器学习流程状态处于S时,MCTS所采取a(action)的搜索概率的值记为π。 表2 符号标记Tab. 2 Symbol mark 2.3.2 网络博弈 神经网络的博弈原理如图2所示,首先将相似数据集的历史搜索知识、神经网络预测行动概率p以及评分v用于当前搜索过程。然后将上一轮搜索过程中产生的数据用于新的神经网络的训练,网络输入数据为(St,πt,et),其中St为t时刻的状态,πt为t时刻MCTS采取a的搜索概率,et为状态为St流程的实际评估。经过训练,会产生一个新的网络,新网络与旧网络进行博弈,获胜的网络用于下一轮的MCTS。 图2 网络博弈原理Fig. 2 Principles of network game 博弈过程:将2个网络和同一棵MCTS输入博弈生成器,根据这些输入生成为2个行动方:行动方1、行动方2,两者分别使用新的网络和旧的网络在同一棵MCTS树指导下生成机器学习流程。最后对两者生成的机器学习流程进行评分,内部进行多次博弈,最后根据胜场数多少判断最终胜者,胜场数多者为胜。 2.3.3 迭代优化 本文提出方法的迭代优化过程如图3所示,神经网络和相似数据集的历史搜索知识共同指导MCTS的过程,MCTS过程中产生的数据用于神经网络的生成,两者以迭代的方式构建流程。 图3 迭代优化 Fig. 3 Iterative optimization of PGDS a:将任务输入程序,将数据集和当前的机器学习流程转化为状态St,并在MCTS中找到对应的状态,使用最新的神经网络和相似数据集的状态信息共同指导MCTS的搜索,得到目前状态St的最高得分的行动a,指导机器学习流程的生成。 b:神经网络将状态St作为输入,通过带有参数θ的多层卷积层,输出目前状态St的移动概率分布向量Pt和流程最终评分Vt。 策略迭代的过程中反复进行上述步骤,使移动概率和fθ(s)=(p,v)更接近改进的搜索概率和自博弈赢家(π,z)。 2.3.4 MCTS过程 MCTS在寻找巨大维数空间中搜索问题的解决方案时非常高效,因为MCTS在搜索过程中平衡了利用和探索,搜索树的每条边都存储着一个先验概率P(s,a)、访问次数N(s,a)和一个行动值Q(s,a)。同时,本文进行数据集的相似性比对,得出最高相似性的历史数据集,根据规则转换成相似数据集的当前状态sd,从历史搜索知识中获取对应参数P(sd,a)、Q(sd,a)、N(sd,a)等,将这些参数用于MCTS搜索中,如图4所示。 图4 MCTS的扩展策略Fig. 4 Expansion strategy of MCTS a.选择:每次模拟通过选择U值最大边来遍历树,其中U兼顾了奖励值较好的边和探索的广度。 b.叶子节点的扩展:神经网络和历史数据集的历史搜索知识共同指导叶子节点的扩展。 c.操作值更新:每完成一次叶子节点的扩展相当于一次搜索,每次搜索完成都需要对操作值更新,包括历史数据和当前数据集的Q值,访问次数N等。 具体做法是:在MCTS的基础上利用相似数据集相应状态下的评分,使用相似数据集的历史状态值和神经网络的预测值及奖励值共同决定评分,从而使MCTS的选择更加准确高效,对应的公式定义为: (2) Q(sd,a):历史相似数据集在当前行动a状态为sd时的奖励值。 Q(s,a):当前行动a在状态为s时机器学习流程中的预期奖励值。m和n是根据输出值大小制定的权值,将奖励值和对应的数量的比值限定相同数量级,以确保他们同时兼顾利用和探索。 P(s,a):神经网络对从状态s采取行动a的概率的估计值,c是决定探索量的常数。 N(s):当前数据集的状态为s时被访问的总次数。 N(s,a):当前数据集的状态为s,行动为a时被访问的总次数。 N(sd,a):历史相似数据集在对应状态sd,行动为a时被访问的总次数。 需要注意,只有当第一次搜索到N(sd,a)时,将相似数据集对应状态的访问次数作为初始值累加到目前数据集的N(s,a)和N(a),这样增加了MCTS的搜索宽度,增大了获得较好表现机器学习的概率。 2.3.5 机器学习流程生成算法(PGDS) 如算法2所示,首先获取sd和s,然后进入循环,如果完成机器学习生成,则跳出循环。然后通过MCTS获得动作a,确定(sd,a)是否存在,通过公式计算U,将U与curbest进行比较,如果大于curbest,将U赋值给curbest,a赋值给bestact,循环直到构建完成。 算法2:机器学习流程生成算法(PGDS)。 输入:数据集Di任务Ti; 输出:机器学习流程pipeline; 1.WHILE(!gameend)DO: 2. Get theQ(sd,a),N(sd,a) fromDi 3.FOREACHa∈movesDO: 4.IFexists(sd,a)THEN: 5.U(s,a)=mQ(sd,a)+nQ(s,a)+cP(s,a)*((sqrt(N(s)))/(1+N(s,a)+N(sd,a))); 6.ELSE: 7.U(s,a)=Q(s,a)+cP(s,a)*((sqrt(N(s)))/(1+N(s,a))); 8.IF(U>curbest)THEN: 9.curbest=U; 10.bestact=a; 11.(s,sd)=Getnextstate(s,sd,bestact); 12.RETURNpipeline。 实验使用的数据集来源于OpenML。实验执行分类任务,单标签和多标签性能评价指标选择分别为F1和F1_macro,求出对应混淆矩阵,然后通过混淆矩阵求出对应的P(精确率)和R(召回率),通过P和R计算出F1,每个标签F1的平均值便是F1_macro,F1对应的公式为 (3) 实验环境:操作系统Ubuntu20.04;Intel Pentium(R) CPU W-2125 4.00 GHz;Nvidia RTX 2080Ti 11 GiB; 32 GiB RAM。 为了进行数据相似性对比,本文选用OpenML访问率排名前100的数据集,对100个数据集执行分类任务并且记录历史搜索知识。然后分别使用TPOT、Auto-sklearn、AlphaD3M和PGDS对Vehicle、Breast cancer、Spectf数据集执行分类任务并对输出结果做对比。实验过程中,对每个数据集运行多次,分别记录生成的有效流程的性能和总耗时,最后对实验结果进行对比分析。 将本文提出的PGDS方法与TPOT、Auto-sklearn、AlphaD3M在生成的机器学习流程性能和总耗时方面进行比较,性能结果比较如图5、图6和图7所示,总耗时比较如表3所示。 图5 Vehicle数据集生成流程的性能比较Fig. 5 Pipeline performance comparison for Vehicle dataset 图6 Breast cancer数据集生成流程性能比较Fig. 6 Pipeline performance comparison for Breast cancer dataset 图7 Spectf数据集生成流程性能比较Fig. 7 Pipeline performance comparison for Spectf dataset 由图5、图6、图7可知,在Vehicle数据集中,使用PGDS方法产生的性能结果好于AlphaD3M,仅次于TPOT。在Spectf数据集中,使用PGDS方法产生的性能结果略高于AlphaD3M,但在Vehicle数据集中,PGDS方法所生成的pipeline最低性能明显好于其他三者。从中可以看出,使用PGDS方法生成的流程性能达到了目前自动化机器学习的良好水平。 表3显示的是生成的所有流程的总耗时对比。从中可以看出,在运行同一数据集的总耗时方面,AlphaD3M和PGDS方法远低于TPOT,执行任务的总耗时从TPOT的小时级别下降到分钟级别,PGDS的耗时稍微多于AlphaD3M。 表3 生成流程总耗时对比Tab. 3 Comparison of total time-consumption s 分析实验结果,相比于AlphaD3M工具,生成流程总耗时略有增加的原因是由于本文的PGDS方法需要跟相似数据集的状态进行比对,会增加数据集比对和匹配的时间。由于使用MCTS和强化学习的结合可以大大减少搜索的量级,相对于其他工具生成时间明显减少,性能也达到较好水平,主要原因是借鉴和复用了相似数据集的历史知识,同时在搜索时间不变的情况下,增大了MCTS树的搜索宽度,从生成的有效流程的数量来看,在同样的参数配置下,PGDS生成流程数量是AlphaD3M两倍,证明了PGDS的搜索宽度明显大于AlphaD3M,并且在生成流程的性能方面PGDS明显优于AlphaD3M。综合上述分析:该方法在耗时方面缩短至分钟级别,流程性能也得到了提升。 本文提出一种数据驱动的自动化机器学习流程的生成方法。通过对相似数据集比对和匹配,历史数据集搜索知识可以重新用于MCTS搜索,以指导机器学习流程的生成。与主流的自动化机器学习工具相比,该方法大大减少了生成机器学习流程的时间,提高了流程的性能。作为未来的工作,我们计划融合更多相似性算法和更多种类数据集的兼容性,以减少机器学习流程的合成时间和进一步提高性能。2.3 机器学习流程生成




3 实验结果及分析
3.1 实验设计
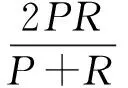
3.2 结果分析



4 结语
