基于深度学习的短文本语义相似度计算模型
2022-05-31周圣凯富丽贞宋文爱
周圣凯, 富丽贞*, 宋文爱
(1. 中北大学软件学院, 山西太原 030051; 2. 山西省军民融合软件工程技术研究中心, 山西太原 030051)
近些年来,随着互联网的发展和个人智能设备的普及,互联网用户交流频率爆炸式增长,用户交流的信息常常是比较短的文本,同时带有明显的个人偏向,这些特点推动了一系列自然语言处理任务的发展和应用,例如利用舆论监测系统[1]防止网络舆论被不法分子有意引导,利用用户评价信息判断商品是否受市场欢迎[2]等。互联网上众多的短文本中蕴含着各种重要信息,如何从这些浩如烟海的文本中提取和筛选出有用的信息是一个复杂且方向繁多的任务,这些任务共同的基础都是短文本语义相似度[3]的计算,所以研究和推动短文本语义相似度计算的发展是重中之重。
语义相似度计算是自然语言处理(natural language process, NLP)的基石,问答系统[4]、情感分析[5]、临床医学文本分类[6]等NLP任务都需要用到语义相似度计算,故语义相似度计算也是NLP领域的重点和难点。在Word2Vec[7]问世之前,人们使用词频与逆文档频率[8](TF-IDF)来度量文本的相似度,或者用其平面特征向量[9]来表征它的语义相似度。但是这些方法仅仅通过计算词语出现的频率,找出最能代表文章的词语并以此作为文本向量,无法将语义信息作为相似度度量的因素,所以其准确率很低,无法有效应用于自然语言处理任务中。后来,随着计算机算力的快速提升,2013年Mikolov 等[7]提出通过文本语料库获得词向量的方法Word2Vec。至此,向量化的语义信息正式应用于NLP任务中[10],语义信息的数字化和深度学习的快速发展,使得各种自然语言处理任务的表现越来越好。
在语义相似度计算中最为重要和最有意义的就是文本编码器的改进,随着深度学习在NLP领域的应用和发展,逐步出现了将长短期记忆神经网络[11](long short-term memory, LSTM)和卷积神经网络[12](convolutional neural network, CNN)作为编码器的模型。但是,随着深度学习的发展和应用,这些语义编码器固有的缺点也逐渐显现出来。例如,LSTM相较于循环神经网络虽然可以拥有长期记忆,从而兼顾上下文总体内容来为文本进行编码,但是对文本语义信息的提取采用兼顾的提取策略,从而所生成的文本向量无法强调其中的重要语义信息,所生成的文本向量也就不能最大化代表此文本内容。而CNN[13]则相反,它将注意力过于集中在文本的重要语义信息中,从而忽略了文本的上下文语境。
为了在提取文本信息时给文本的重要语义信息施加更高的权重,且能兼顾短文本的上下文顺序信息,从而提高短文本相似度计算的准确度,本文提出基于卷积神经网络和双向门控循环单元(bidirectional gated recurrent unit, BiGRU)的神经网络模型作为文本编码器。此模型采用孪生神经网络[14]结构进行训练,在提取文本重要语义信息的基础上,对上下文的语义信息进行综合考虑。
1 相关工作
在语义相似度计算领域中,词向量、文本编码器和相似度计算方法是3个主要的突破方向。在词向量方面,Yin等[15]提出元嵌入的概念,将使用不同的数据集和向量化方法所获取的词向量库按照一定的规则进行组合,以融合其不同的语义信息,获取包含更为丰富和全面的语义信息的词向量库。之后,韩越等[16]对其做了进一步研究。Poerner等[17]在词元嵌入的基础上提出句子元嵌入。在相似度计算方面,Santuse等[18]提出秩度量,vor der Brück等[19]提出范数度量等计算方法。此外,还有基于词典[20]的相似度度量方法,基于主题[21]的相似度度量方法,等等。
短文本语义相似度分析最简单的方法就是基准方法。这种方法将文本中所有的词向量进行平均计算,将获得的平均向量作为文本的向量。但是这种方法所生成的文本向量表现不稳定,大部分时候准确率较低。Kusner等[22]在基准方法的基础上提出一种改进方法词移距离,将一个文本中的所有词语与另一个文本中的所有词语进行距离计算,每个词语选择最短距离参与平均计算,所获得的距离平均值即为2段文本的语义相似度。在这之后,陆续有人提出应用主题词[23]来表征文本语义的方法,以及应用文本的词语相对位置信息表征文本相似度[24]的方法。
用词移距离进行短文本语义相似度计算无法将文本中词语的相对位置和上下文的语义信息纳入计算中,因而准确率低,但是基于深度学习的文本编码器可以通过滑动窗口[25]和词向量库来学习获取文本的语义信息。常用的文本编码器训练方式是先利用词向量库获取文本向量矩阵,矩阵中包含文本中的所有词语以及相对位置信息,再将其放入文本编码器中进行训练。
句子编码器的使用为文本的向量化提供了更好的方法,随着CNN、LSTM、Attention逐渐应用于自然语言处理任务中,句子编码器也在不断发展。2015年,Severyn等[12]首次将CNN应用于NLP任务中,并且在问答匹配任务中综合表现相较于传统方法提高了3%;2016年,Mueller等[11]提出将孪生LSTM应用于语义相似度度量中,在皮尔逊相关系数标准下精确率为88.22%,斯皮尔曼相关系数下精确率为83.45%;2017年,Google公司提出Attention[26]机制并将其应用于翻译任务中,获得了当时最好的效果;2018年,Google公司提出的BERT模型[27]可用来解决大部分的自然语言处理任务;2020年,Peinelt等[28]将BERT模型与主题模型相组合,提出了tBERT方法进行语义相似度度量。这些语义相似度模型的应用和改进,使得问答系统[29]、文本分类[30]等用到语义相似度模型的自然语言处理任务表现也水涨船高,极大推动了自然语言处理的发展。
本文所提出的文本编码器,使用2个共享权值的COV-BiGRU模型作为编码器,2个模型的输入分别为2个不同的短文本词向量矩阵,最后的输出为短文本语句对的语义是否相似的度量,相似为1,不相似为0。
2 卷积双向门控循环单元模型
本文采用孪生神经网络结构作为模型结构(如图1)。孪生神经网络的左右2个神经网络在结构完全相同的基础上共享网络权重,非常适合处理2个输入“比较相近”的情况,因此,该网络非常适合于短文本语义相似度计算。本文在此结构基础上提出卷积双向门控循环单元模型(convolutional bidirectional gated recurrent neural network, COV-BiGRU)用于短文本语义相似度计算。COV-BiGRU模型的训练目标是使2个相似句子的距离尽可能小,不相似句子的距离尽可能大。
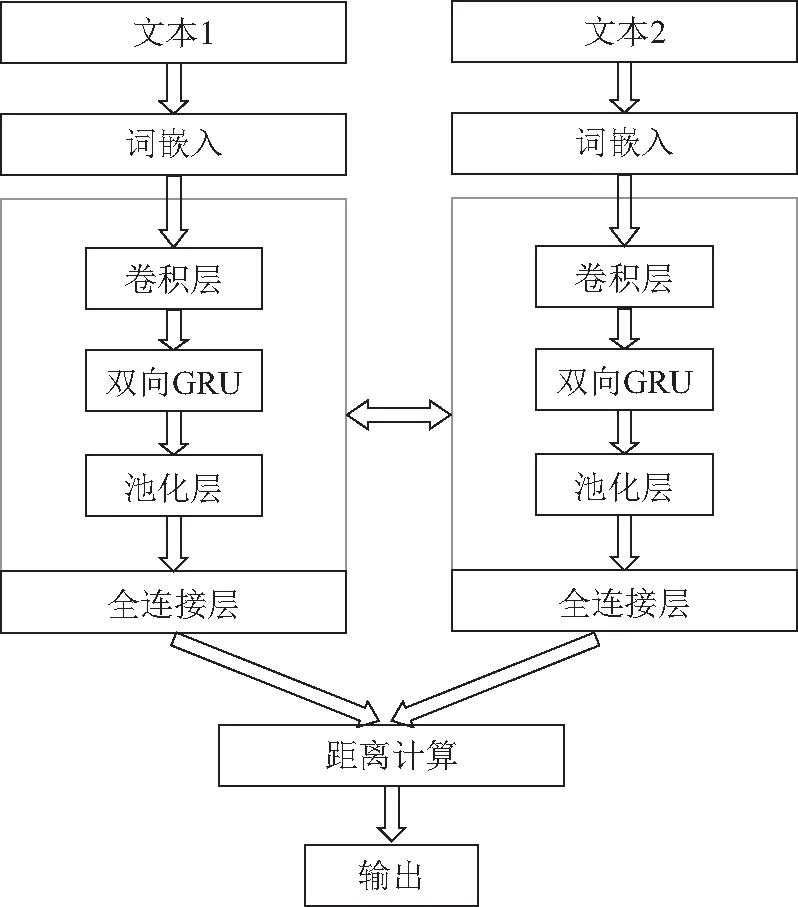
图1 语义相似度计算模型Fig. 1 Semantic similarity computing model
模型的输入是一个文本对。先通过预训练的词向量库将句子对映射为2个低维稠密向量;之后通过卷积层提取文本的名词信息、情感信息等重要语义信息;再通过双向门控循环单元捕捉时间序列里长期的依赖关系,将文本的上下文重要语义信息整合使其相互联系;然后进行最大池化处理对数据降维,压缩特征数量,从而减小过拟合的风险;最后,接一个全连接层将所有的局部特征通过权值矩阵重新组装作为文本句子的整体语义向量。模型最终通过曼哈顿距离判断2个孪生模型所输出的文本向量相似程度,从而获得语义分类的结果。
2.1 输入层
输入层的作用是将人类能读懂的文本转换为神经网络模型能处理的低维稠密向量。具体处理流程如下:首先,对文本进行清洗,即去除停用词、缩写词、特殊字符等;然后,将每段文本截取为固定的长度L,本模型中取L的值为20,长度不足20的文本在超出文本长度的部分填充零向量,例如文本对{"What was your first sexual experience like?","What are the laws to change your status from a student visa to a green card in the US, how do they compare to the immigration laws in Canada?"},其第一个文本长度为8,输入层会将其长度不足20的位置填充零向量,而第二个文本长度为31,输入层会将其截取到长度20,最终文本对为{"What was your first sexual experience like? 0 0 0 0 0 0 0 0 0 0 0 0","What are the laws to change your status from a student visa to a green card in the US, " };最后,将文本中的每个词语都利用词向量库映射为词嵌入向量。本文采用Word2Vec已训练好的300维词向量对文本进行映射,上例文本对中第二段文本映射后的直观表示如图2所示。通过词向量的映射,将字符串文本转换为L×d维的向量作为模型的输入。

图2 词嵌入后文本的向量化表示Fig. 2 Vectorized representation of text after word embedding
2.2 卷积层
卷积层的作用是提取文本中的重要语义信息[12]。卷积层对模型输入层L×d维的向量进行一维Same卷积。输入张量长度为300,深度为20,输出大小即卷积核数目为128,卷积核k长度为3,深度和输入张量的深度相等。卷积核k的锚点在张量长度范围内依次移动,卷积移动步长为1。同时,卷积特征图m的大小为18。卷积层示意图如图3所示。

图3 卷积层示意Fig. 3 Schematic diagram of convolutional layer
一维卷积特征图计算公式为
m=L-k+ 1。
(1)
文本类型不同,其语义关注的部分也不同,通过反向传播,卷积核会学习到最能代表此类文本的语义信息,从而学会提取短文本的局部语义特征。
2.3 双向门控循环单元层
BiGRU层的作用是提取和学习上下文的位置信息,其结构如图4所示。

图4 BiGRU结构Fig. 4 BiGRU structure
GRU[31]网络是LSTM网络的一种变体,相较于LSTM,它的内部只有更新门和重置门,其中更新门用来代替LSTM中的遗忘门和输入门。GRU相对于LSTM来说,对短文本的语义信息提取效果更好,BiGRU层可以同时对上文到下文和下文到上文的语义信息进行提取,并且对上一层CNN所提取的重要语义信息进行整合,本文的双向GRU层接在卷积层后面,输出张量长度为64。
2.4 文本向量生成层
这一层的作用是生成最终的文本向量。先采用最大池化对上一层的输出进行降维,然后通过全连接神经网络对其语义信息进行整合。这个全连接层将所有的局部特征通过权值矩阵重新组装,所输出的128维向量即为文本整体语义的数字化表示。
2.5 相似度计算层
这一层将2个神经网络所生成的2个n维短文本语义向量x1和x2进行曼哈顿距离计算,从而获悉文本的相似度,其相似度值d的计算公式为
(2)
最终,输出层中相似句子对的输出为1,而不相似句子对的输出为0。
2.6 模型的理论分析
短文本句子一般分为主语和谓语,主语部分是说明的对象,谓语部分是对主语的叙述和描写。例如:“我开蓝色的车去沃尔玛超市买菜。”和“我去街角的超市买菜去,开我的小汽车。”的主语都是“我”“车”“超市”“买菜”。主语是最能表示文本语义的部分。
本文通过卷积层为短文本中的主谓语分配不同的权重,最能代表句子语义的主语可以获得较高的注意力。2个短文本中权重大的元素的距离越近,句子的相似度就越高,通过卷积层的处理可以使“我”“车”“超市”“买菜”有更高的权重。卷积层可以最大限度保证语义信息的提取,但是却无法保证词语的顺序,无法很好地提取单词顺序与语义的关系,GRU可以有效提取上下文中的位置信息,BiGRU则可以同时提取正向和反向的语义信息,从而2个句子的主要语义信息可以提取为“我开车去超市买菜。”同时,因为短文本中的语义信息少,在训练过程中会出现过拟合现象,相较于RNN和LSTM,使用BiGRU可以有效减少过拟合现象,同时,通过池化层的处理也可以有效减小过拟合,提高模型的性能。
3 实验分析
3.1 数据集
本文实验采用Quora、MSRP和Sick数据集。Quora问答数据集是SNS问答网站于2017年开放的一个问题对数据集,有404 000个短文本对,每一行包含问题编号、短文本对完整文本和语义标签,语义相同的短文本对标签为1,语义不同则为0。MSRP数据集是微软公司开放的一个数据集,包含训练集和测试集共5 400个短文本对,语义相同的文本对标签为1,语义不同则为0。Sick数据集是一个有10 000个短文本对的公开数据集,语义标签分为相似、相互中立和互斥3种,我们在数据读入内存时将相似标签动态导入为1,中立和互斥标签动态导入为0。
将数据集短文本对去除停用词等处理后,用已经训练好的词向量库Word2Vec将句子对转换为词嵌入,然后将映射后的300×20维的词嵌入作为模型的输入。
3.2 模型参数设置
输入层中使用公开的词向量库Numberbatch-en进行文本映射,维度为300。卷积层输出空间维度为128,卷积核长度为3,填充模式设为Same模式,使用的激活函数为ReLU。双向GRU层的输出空间维度为64,返回全部序列值设为true。全连接层使用softmax激活函数,其输出空间维度为128,这也是最后所生成的文本向量的维度。模型优化器为Adam,模型训练时使用均方误差作为loss的评判标准,使用精确率、召回率和F1值作为评价指标,每次梯度更新的样本数量为512,模型迭代次数为50。
3.3 评价标准
本文采用精确率、召回率和F1值来进行评价。精确率是针对于预测结果中,实际正样本占预测正样本的比例。召回率是针对于实际样本中,被预测为正样本数占总实际正样本的比例。F1值是综合精确率和召回率的综合指标,用于反映整体情况。
ηprecision=NTP/(NTP+NFP),
(3)
ηrecall=NTP/(NTP+NFN),
(4)
F1=2×ηprecision×ηrecall/(ηprecision+ηrecall)。
(5)
式中:NTP表示将正例预测为正例的数量;NFN表示将正例预测为负例的数量;NFP表示将负例预测为正例的数量。
3.4 实验结果和分析
本文将90%的数据作为训练集,10%的数据作为测试集,将COV-BiGRU模型与已有的模型进行对比实验。LSTM模型来自Mueller等[11]2016年的研究;CNN模型来自Severyn等[12]2015年的研究;Attention机制和BERT模型由谷歌公司提出并应用于自然语言处理当中。
从表1的实验结果可以得出,CNN模型表现优于LSTM,而CNN-Attention的表现在CNN的基础上获得了一定的提升,而本文的COV-BiGRU在精确率、召回率、F1值上相较于CNN-Attention 都有明显的提升。这说明采用CNN和GRU的混合编码方式,既可以通过CNN来提取文本嵌入的重要语义信息,同时也通过GRU考虑了上下文的时序语义信息,克服了CNN和循环神经网络固有的缺点,从而提高了文本向量的语义表达准确度。由于短文本的语义信息少,用广而深的模型反而会分散对重要语义信息的关注,本文在提出假设并且实验验证阶段发现越是深而广的模型表现效果越差。

表1 文本相似度实验结果对比Tab. 1 Text similarity comparison %
为了进一步做对比,本文将GRU替换为RNN网络变体进行对比实验。设计3种不同的实验模型用于对比,将双向门控循环单元替换为双向长短期神经网络,获得COV-BiLSTM、COV-BiGRU、COV-BiLSTM-GRU等3种神经网络,表2给出了3种模型的实验结果。从表中可以看出,这3种神经网络的表现相近,但是COV-BiGRU的F1值比COV-BiLSTM和COV-BiLSTM-GRU高,COV-BiGRU作为语义相似度度量的模型表现最好。

表2 变体模型对比Tab. 2 Variant model comparison %
4 结语
本文将CNN和BiGRU的混合模型应用于文本相似度的计算中,同时考虑上下文的语义联系和文本中重要词语的深层语义信息,从而提高了短文本语义相似度计算的精确率和召回率。实验结果表明,COV-BiGRU模型能够有效提高对相似句子对的辨识能力。当然,COV-BiGRU模型局限在于对文本编码器的改进中,未来在改进文本编码模型的基础上也应聚焦于文本的向量化和相似度计算方法的改进上。
