基于双向语言模型的社交媒体药物不良反应识别
2022-05-31李正光林鸿飞
李正光, 陈 恒*, 林鸿飞
(1. 大连外国语大学语言智能研究中心, 辽宁大连 116044; 2. 大连理工大学计算机科学与技术学院, 辽宁大连 116024)
药物不良反应(adverse drug reaction, ADR)是医疗健康领域死亡和发病的主要原因之一[1-2]。因此,有必要对上市药物的不良反应进行监测,以避免潜在的风险[3]。目前,人们在美国联邦药品管理局的官方不良事件报告系统上登记ADR记录。然而,现有的上市后药物监测方案效率低下,导致现实中的ADR识别时效性差。另一方面,社交媒体因其受欢迎而成为分享健康相关信息的有效平台[3]。社交媒体平台往往早在官方报告发布之前就包含了时效性更强的相关ADR信息,如Twitter。因此,社交媒体是一种有效的公共卫生监督手段,尤其是在重大ADR病例中[4]。
然而,从社交媒体中提取上市药物的不良反应目前面临着一些挑战[3],包括:1)因受篇幅限制,文本内容较短;2)文本中充满噪声同时有用文本稀疏,即文本量大但是有用信息较少;3)都是口语化和非正式的文本。传统的药物不良反应识别方法先预定义药物或药物不良反应的有效特征[5],再利用自然语言处理(natural language processing, NLP)工具和医学资源进行匹配。但这类方法并不能有效地识别社交媒体中的ADR,常被社交媒体文本中语法错误、拼写错误和单词缩写等问题误导。因此,多数学者将ADR识别视为命名实体识别(named entity recognition, NER)[6]任务,以提高识别的准确性。
神经网络学习方法主要包括集成条件随机场(conditional random fields, CRF)和Bi-LSTM[7]、迁移学习[8]、知识增强[9-10]等。许多神经网络学习方法已被提出并用于识别书面文本中的实体名称[11],如疾病名称、药物名称和ADR[11-12]。例如:Pandey等[13]结合CRF和注意力机制的优势,提出一种基于双向长短期记忆网络,以此提取复杂的医学实体,取得了较好的性能;Peng等[14]利用生物医学数据训练BERT和Elmo,评估了10个生物医学语料,取得了最优结果。
上述方法在处理书面生物医学语料库时表现良好,但社交媒体文本涉及ADR的数据稀疏以及各种不规则的语法错误等,这类方法常常表现欠佳。因此,部分学者利用数据增强提高低资源高噪声[15]下的ADR事件检测性能。为了更好地从社交媒体文本中提取ADR,受宋雅文等[16]的字符级特征和Pandey等[13]的注意力机制启发,本文提出一种集成注意力机制和双向语言模型的新型神经网络模型。本文主要工作为:1)采用注意力机制来捕获社交文本中的局部和全局语义上下文;2)采用双向字符级神经语言预训练模型自动学习字符级特征;3)本文模型结合了字符级和词级特征,用预训练的字符向量来代替协同训练,其中字符向量是将每个字符视为“词”,利用已有预训练模型(如Glove、BERT)训练而得。上述优化提高了辨识性能和算法的效率。
1 注意力机制的字符级双向语言模型
ADR识别系统主要由基于双向字符级语言模型的神经网络层、CRF层和注意力层组成,如图1所示。

图1 算法整体框架Fig. 1 Overall architecture of the proposed model
1.1 字符级双向语言模型
假设句子s=(w1,…,wm)的前向概率为
(1)
式中:pforward(wi|w1,…,wi-1)是学习参数;m是一条推文中单词的最大数量;wi是句子中第i个词。考虑到与ADR相关推文的内容相对较短、嘈杂且稀疏,必须采取额外的步骤来协助识别过程。首先选择字符序列作为训练的输入,同时,构造由前向和后向LSTM组成的双向LSTM单元,以获得更好的全局语义上下文。在以往的研究中,字符级向量通常使用随机初始化生成,没有考虑到字符与字符间的依赖关系。相对于书面文本,用户通常依据网络习惯来输入社交文本,因此考虑用户的网络习惯是很有必要的。本文将推文中的字符视为一个词,然后利用预训练模型,如BERT,单独训练字符的向量表示。推文中的字符序列最终被训练为字符级LSTM模型,以获得文本的结构和句型,包括拼写错误和表情等干扰因素[17]。最后使用4个高速公路网(highway networks)生成相应的语义向量[18]。
HT(x)=σ(Wx+b)。
(2)
(3)
(4)
(5)
同理,后向概率分布表示为
(6)
将式(5)和式(6)联合,最终的双向预测概率分布为
(7)
1.2 注意力机制
为了提高识别ADR的准确率,结合已有的研究[19],本文引入注意力机制以识别社交媒体文本中的药物和ADR[20-21],描述为
(8)
式中:wt、wj、wk是第t、j、k个词的隐层输出;score(·,·)是对齐函数,譬如曼哈顿距离、余弦距离等,输出定义为
(9)
式中Wa是权重矩阵。将JLM与注意力计算相结合,每个双向字符级LSTM模型输出加权和gt定义为
(10)
将JLM和gt向量拼接成输出向量[JLM;gt]。最终将[JLM;gt]输入激活函数tanh得到注意力层的输出
zt=tanh(Wh[JLM;gt])。
(11)
为了预测每个词对应每种可能标签的置信度,再次使用激活函数tanh作用于zt,
et=tanh(Wezt)。
(12)
式中Wh和We是权重矩阵。
1.3 CRF输出
为了解决标签偏差问题,避免不合法的标签,而从所有可能标签中解码得到最合理的标签[22-24],将标签迁移矩阵Ti,j引入CRF中,在式(8)和式(12)的基础上,CRF的最优预测概率描述为
(13)
式中Ti,j={et}表示词的标签i到标签j的转换分值,该值通过注意力层计算得到。归一化输出概率为
(14)
CRF层的输出为
(15)
将式(7)和式(15)联合,最终语言模型的输出为
(16)
2 实验
本文模型和现有模型都在基于Tensorflow的开放性平台Keras上实现,开发语言版本采用Python3.6。硬件平台包含2块NVIDIA RTX 2080Ti GPU和16 GiB内存。
2.1 数据和标注
本文的实验数据由2个推文语料库组成:第一个语料库是来自PSB2016评测的涉及ADR的推文数据,其中包含1 340条训练集和444条测试集[22];另一个语料库包含203条由药物相关事件组成的推文[22],推文的标注依据Twitter ADR指南完成。在数据处理阶段,发现一些推文由于用户删除而丢失。最终,在文本实验中,完整的数据集包含837条训练推文和444条测试推文。本文通过以下步骤对数据进行标记[24]:
步骤1:将推文转换为小写,然后采用特殊标签代替涉及“@”的相关词语,如“@username”形式,并且删除超链接。
步骤2:使用推文工具ark-twokenize-py(1)https:∥github.com/myleott/ark-twokenize-py对推文分词。
步骤3:采用标准的BIO模式对其标注,即将每个词标注为B-ADR、I-ADR和O。
2.2 字符/词向量和超参
实验中使用的词向量是通过大量推文训练得到的,可以从Github上下载(2)https:∥github.com/loretoparisi/word2vec-twitter。字符向量的训练语料除了实验中的语料外,还包括PSB2016-Task1[23],即ADR帖子识别的语料,总计6 700条推文。首先将这些推文中的词按照字符分割为单词的形式,如“#2013ada”,拆分为“# 2 0 1 3 a d a”。最后将新的推文表示送入Glove模型,得到字符向量表示。
受Lai等[25]的启发,针对影响实验性能的关键参数进行了9组实验,以获得更好的词向量维度和预训练字符级向量,如表1所示。与PubMed 摘要等其他文本相比,使用推文训练所得的词向量可以获得更好的性能。预先训练好的字符语言模型在adr_ner9实验中取得了最好的效果。因此,在预训练和训练过程中,字符向量、单词向量的维度均为100,采用Adagrad优化器进行训练[26]。其他的超参如表2所示。

表1 参数选择Tab. 1 Selection parameters
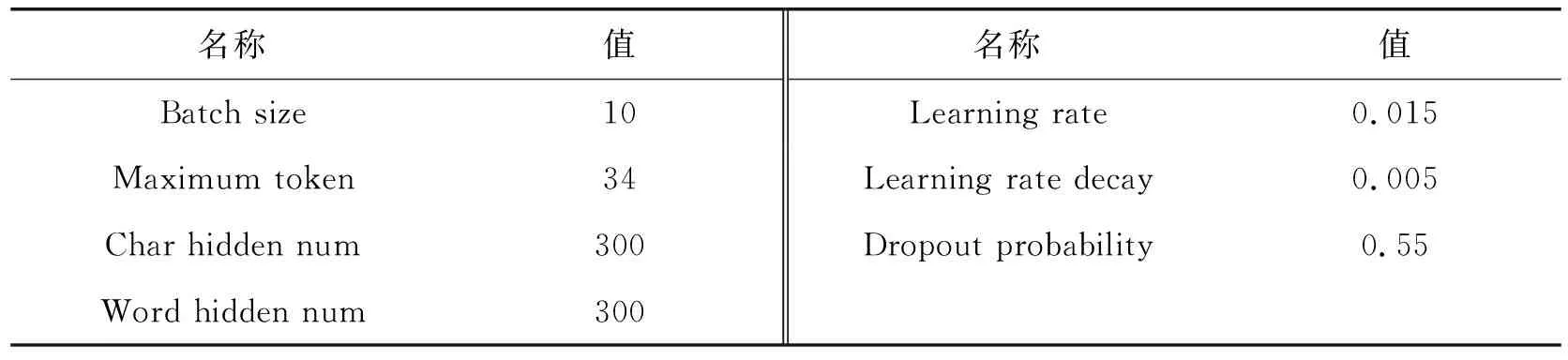
表2 超参Tab. 2 Hyperparameters
3 结果与分析
3.1 与现有系统的性能比较
为了验证本文模型的有效性,在PSB语料上,与现有ADR识别系统进行了比较,如表3所示。从表3可以看出,本文模型取得了最高的准确率和F1值,Chowdhury等[27]获得了最优的召回率。同时,Cocos等[22]和Chowdhury等[27]取得的召回率和准确率差值分别为12.5和15.2个百分点,而本文模型这2个指标的差值为3.7个百分点。Cocos等[22]以不同词向量表示句子,然后利用Bi-LSTM和CRF对ADR进行识别,因为没有关注到重点词,所以取得最差性能。Chowdhury等[27]注意到ADR分类和ADR识别的关联性,通过多任务学习达到两个任务之间的相互注意,准确率略有提升,召回率提升近5个百分点,从而提升了整体性能。Cocos等[22]和Chowdhury等[27]都忽略了短文本与书面文本的差异,即不完整性、随意性和稀疏性,因此准确率较低。本文模型以注意力机制捕获短文本的重点词汇,并以社交文本训练字符级向量来表示词的形态学特征,从而减少负例的误判,在基本保证召回率的同时提高准确率,减少二者之间的差异,提升整体性能。

表3 与现有系统比较结果Tab. 3 Comparision with existing methods %
3.2 组件分析
为了探讨每个组件对系统性能的影响,在PSB2016语料以及5倍交叉验证数据上进行消融研究,结果如表 4和表5所示。
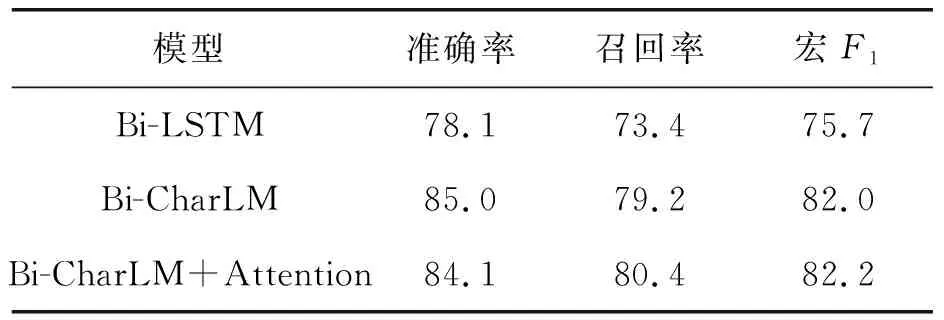
表4 PSB2016划分上的消融实验Tab. 4 Ablation experiment on PSB2016 %

表5 5倍交叉数据划分的消融实验Tab. 5 Ablation experiment on 5 folds of PSB2016 %
相对于基线Bi-LSTM,即不使用字符级语言模型,在PSB2016和5倍交叉验证数据集上,准确率、召回率和宏F1值都获得了较大提升,其中宏F1值分别提高了6.3和4.8个百分点。而加入注意力机制后,提高了召回率,从而略微提升了宏F1值。
以上结果说明:前向和后向语言模型提供的字符特征有效地区分了ADR和非ADR词,提高了准确率。相反,注意力机制导致准确率下降。其原因可能与本文模型的机制有关,因为它只关注与ADR相关的药物名称,而忽略了药物与ADR之间的关系。此外,在一句话中只有一种药物被标记,这可能是有问题的,因为标记的药物不一定与ADR有关,特别是当多个药物名称出现在同一条推文中时。
3.3 注意力分析
为了验证注意力机制在识别ADR的有效性,对推文“The most common adverse reactions observed in the trial patients with relapsed or refractory PTCL treated Beleodaq were nausea”进行注意力分值分析。使用注意力机制前,融入字符级双向语言模型的LSTM单元的输出加权和分布如图2所示。同时,使用注意力机制,即使用tanh激活函数后的输出分布如图3所示。比较图2和图3可以发现,“adverse”“reactions”“nausea”(ADR)分值非常突出。注意力机制使得系统能够聚焦于突出信息,并在每个预测步骤中预测相关的序列。通过式(10)计算序列,并且执行tanh操作来标记文本序列,注意力得分的可视化结果如图4所示。图4显示“adverse”“reactions”“patients”和“nausea”分值突出,即注意力机制过滤掉了不太关注的词语,同时保留了与药物、药物不良反应和疾病实体相关的词语。结合本文模型的结果,可以发现,对重要实体的注意可以提升对ADR识别的准确率,提升模型的整体性能。

图2 tanh操作前的注意力分值分布Fig. 2 Attention score without tanh operation

图3 使用tanh的注意力值分布Fig. 3 Attention score with tanh operation

图4 注意力可视化分布Fig. 4 Visualization of attention score
4 结语
针对社交媒体中文本稀疏、短而噪声大导致ADR识别性能不佳的问题,结合字符级特征和注意力机制,本文提出了一种基于注意力机制的双向字符级语言模型。该模型利用注意力机制有效地捕获了短文本局部和全局语义上下文,促进了序列内的交互,关注到与药物、药物不良反应和疾病实体相关的词语。同时,利用社交文本预训练的字符级特征向量自动表征推文中的字符级特征,有助于在形态学上区分ADR和非ADR。微调的预训练字符向量取代了协同训练,提高了效率。在Twitter语料上的实验结果验证了本文算法的有效性。
