面向强化当前兴趣的图神经网络推荐算法研究
2022-05-31孔亚钰卢玉洁孙中天肖敬先侯昊辰陈廷伟
孔亚钰, 卢玉洁, 孙中天, 肖敬先, 侯昊辰, 陈廷伟*
(1. 辽宁大学信息学院, 辽宁沈阳 110036; 2. 杜伦大学, 英国杜伦 DH13LE)
随着信息技术的迅速发展,为缓解信息过载问题,推荐系统得到广泛研究。在基于会话的推荐中,一些传统推荐算法,如:基于物品的协同过滤[1]和基于马尔可夫决策过程的方法[2]等,已很难满足爆炸式增长的信息需求。在最近基于会话的推荐任务的研究中,递归神经网络取得显著进展[3-5]。但是传统的RNN推荐模型只关注用户的长期静态偏好,忽略了用户当前的兴趣,导致用户在当前时间点的意图很容易被其历史购物行为所淹没,从而导致偏离用户所需要的推荐。
Liu等[6]同时考虑了用户的长期偏好和当前兴趣,长期偏好是由当前会话中的所有历史点击构建的,最后一次点击的嵌入被用来表示用户当前的兴趣。虽然取得了相当良好的效果,但是这种基于RNN的推荐系统仍然存在一些问题。他们只使用用户点击序列对连续项目之间的单向转换建模,忽略了远距离项目之间的复杂转换。并且,在基于会话的推荐中,会话大多数都是匿名且数量众多,而在会话中涉及的用户行为通常是有限的,因此很难准确地估计每个会话的向量表示。
最近,出现了许多将GNN[7]应用于基于会话的推荐的方法,Wu等[8]根据用户与项目交互的历史序列建模为有向图,通过门控图神经网络(GGNN)[9]挖掘物品之间的丰富转换特性,从而生成更准确的项目嵌入向量。Xu等[10]也通过图神经网络捕获丰富的局部依赖关系,并利用自注意力机制学习序列中上下文表示。先前的研究工作都强调了用户的当前操作对基于会话的推荐具有重要意义[6,11-12]。但是,Wu等[8]和Xu等[10]仅利用图神经网络生成的最后一次嵌入来表示用户的当前兴趣的能力有限。并且,现有的有向会话建模为图结构后缺失了其序列性,从而导致其在捕获给定节点相对于整个会话中其他节点的位置方面能力有限。
针对上述问题,为了将会话序列与图结构更充分地融合,并更加准确地获取用户当前兴趣的表示,本文提出一种新颖的方法,即面向强化当前兴趣的图神经网络推荐算法(current interest reinforced graph neural network,即CIR-GNN)。该方法的整体思路如下:首先,根据会话序列中项目的顺序引入位置嵌入信息,并把会话中的序列建模为有向图,通过图神经网络学习用户行为图中每个节点的表示,从而获得图中的所有节点的向量表示。其次,通过将位置嵌入与图神经网络相结合,能够充分利用顺序感知模型和图形感知模型的优势。同时,取原始序列的最后一次点击,通过多头注意力机制计算其对图节点信息的注意力权重,来生成当前会话的表示,以更加准确地获取用户当前兴趣的表示。最后,线性加权结合GNN和注意力机制的互补优势来表征用户的兴趣并产生推荐。
本文主要贡献可以概括如下:
1)引入位置嵌入,并与图神经网络相结合,能够充分利用顺序感知模型和图形感知模型的优势。
2)取原始序列的最后一次点击,通过多头注意力机制计算其对图节点信息的注意力权重,以更加准确地获取用户当前兴趣的表示。
3)在真实的数据集上进行大量的实验,结果表明,所提出的模型优于其他基准模型。
1 相关工作
1.1 传统的推荐方法
基于会话的推荐算法主要解决在匿名交互会话中的推荐问题。传统上,基于会话的推荐算法为基于传统近邻方法的推荐算法,主要包括基于物品的协同过滤[1]和基于马尔可夫决策过程的方法[2]。基于物品的协同过滤,即通过会话中物品的共现频率计算物品之间的相似度,选择当前会话中物品的近邻作为推荐结果。基于协同过滤的方法虽然能捕捉用户的普遍偏好,但很难发现用户兴趣的变化,无法对用户最近的需求做出适应性推荐。基于马尔可夫决策过程的推荐方法,即点击了物品1之后,下一次点击的是物品2的概率,并基于这个状态转移概率进行推荐。随着项目的增加,通过这种方法来建模十分困难。本文采用基于神经网络的方法来学习会话中项目特征向量的内部潜在联系,更容易满足会话中项目增加且兴趣变化的需求。
1.2 循环神经网络推荐方法
近年来,循环神经网络模型由于其出色的序列建模能力备受关注。在基于会话的推荐场景中,Hidasi等[13]首先将RNN引入基于会话的推荐场景,采用GRU来捕捉当前会话中用户行为间的依赖关系。之后,Tan等[3]对其工作提出一系列的改进,应用数据扩充和考虑输入数据分布偏移的方法,提升了通过RNN进行预测的准确度。Zhang等[14]在特征层面混合用户历史行为和人工抽取商品的特征,同时利用RNN来做点击序列行为的预测。Li等[15]提出在RNN的基础上利用注意力机制来捕获当前会话中用户的真实意图,从而提升了模型精度。但以上模型并没有考虑将用户的长期偏好和当前兴趣相结合,因此一些研究人员试图将二者结合来改进模型。Wang等[16]提出一种分层结构的混合表示学习模型,来建模用户事务的顺序行为和一般兴趣。Liu等[6]考虑到把用户会话向量表示中最后一次点击的嵌入,作为用户当前的兴趣表示,解决了用户无意点击引起的兴趣漂移问题。但他们均只使用用户点击序列对连续项目之间的单向转换建模,忽略了远距离项目之间的复杂转换。本文将用户会话序列建模为有向图,并取原始序列的最后一次点击,通过多头注意力机制计算其对图节点信息的注意力权重,通过图神经网络挖掘项目之间的丰富转换特性能够生成更准确的项目嵌入向量。
1.3 图神经网络的推荐方法
图神经网络是一种直接在图形结构上运行的神经网络。Yanardag等[17]提出了图神经网络的概念,由Scarselli等[7]和Micheli[18]进行了扩展。Scarselli等[7]提出的图神经网络的模型,可以直接处理大多数在图域中表示的数据。Micheli[18]提出一种在结构化领域中使用图构造神经网络进行学习的模型,该模型可以实现自适应上下文转换,从图中学习分类和回归任务的映射。GNN将前馈神经网络反复应用于图中的每一个节点,通过与其他节点状态信息进行交互来更新节点的隐藏状态,能够在考虑丰富节点连接的情况下自动提取会话图的特征,非常适合基于会话的推荐[8,10,19-23]。Wu等[8]和Yu等[19]从分离的会话序列构造有向图,并生成精确的项目嵌入向量。基于项目的向量表示,GNN能够构建更有效的会话表示,并且可以推断下一次点击的项目。但以上方法将有向会话建模为图结构后缺失了其序列性,从而导致其在捕获给定节点相对于整个会话中其他节点的位置方面能力有限。本文引入位置嵌入,并与图神经网络相结合,能够充分利用顺序感知模型和图形感知模型的优势。
2 模型算法与实现
在本章中,介绍所提出的面向强化当前兴趣的图神经网络推荐算法。正如图1所示,首先将问题公式化,然后再完整描述整个算法。

图1 面向强化当前兴趣的图神经网络推荐模型结构Fig. 1 Current interest reinforced graph neural network
2.1 公式化描述

2.2 序列节点嵌入
将会话历史序列构建为有向图后会缺失其序列性,我们研究了合并位置嵌入的效果,实验表明它会在推荐性能方面带来较好的效果。因此,将可学习的位置嵌入注入到输入嵌入中。对于在会话S中的项目ij,is,j,ps,j∈Rd分别表示d维的输入嵌入向量和位置嵌入向量。因此序列节点嵌入可以表示为
νs,j=is,j+ps,j。
(1)
此外,考虑到由于用户可能意外点击了一些不感兴趣的项目,于是将dropout应用于点击序列作为一种正则化的手段使得本文的模型对于噪声点击不那么敏感。
2.3 构建会话图
首先,所有的会话序列都被建模为有向会话图Gs=(νs,εs),有向图中的节点νs,i∈V代表会话S中的项目i,有向图中边(νs,i,νs,i+1)∈εs,表示用户在会话S中点击项目νs,i之后又点击了项目νs,i+1。其中每个会话序列可以被视为子图,如图2中会话图所示的会话序列S=[ν1,ν2,ν4,ν3,ν4],每个会话都由关系矩阵A表示,A是由邻接矩阵的出度矩阵和入度矩阵构成的,用于表示节点和相邻节点间的相互作用关系。

图2 会话图和连接矩阵示例Fig. 2 Example of session graph and connection matrix
在会话序列中难免会出现一些重复点击的项目,所以要分配给每一条边一个归一化加权值,该值被计算为该边的出现次数除以该边的起始节点的出度。将每个项目ν∈V映射到一个统一的嵌入空间,节点向量νi∈Rd表示项目i的隐含向量,d是维度。
2.4 在会话图上学习项目隐含向量
具体来说,对于图Gs的节点νi,节点向量的学习更新函数如下:
(2)
(3)
(4)
(5)
(6)

对于每个会话图Gs,门控神经网络同时处理节点。在矩阵As给出的限制条件下,等式(2)是在图的不同节点之间通过传入和传出的边传递信息步骤,等式(3)~(6)类似于门控循环单元(GRU)的更新,它们包含来自其他节点和前一个时间步的信息,以更新每个节点的隐藏状态。通过会话图中的所有节点进行更新直至收敛,可以获得最终的节点向量。
2.5 会话嵌入生成层
将会话序列输入到图神经网络后,可以得到会话图中所有节点的向量表示,即H=[h1,h2,…,hn]。
2.5.1 构建全局嵌入
得到所有节点的嵌入向量后,我们考虑通过堆叠多层的自我注意力块来得到会话图Gs的全局嵌入。一个自我注意力块包括2个子层:多头自我注意力层和逐点前馈网络层。考虑到这些嵌入中的信息可能具有不同的优先级,我们进一步采用多头注意力机制来更好地表示全局会话,并进行h次注意力运算。
S=MultiHeadAttn(Fl)=concat(Dhead1,Dhead2,…,Dheadh)Wo,
(7)
(8)
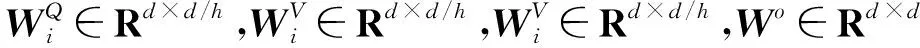
(9)

在顺序推荐中,仅可利用当前时间步之前的信息,因此在预测第t+1个项目时采用mask机制来修改Q与K之间的注意力来禁止包含后续项目的嵌入[24]以及padding位置的无用注意力。
接下来,我们添加了逐点前馈网络(FFN)以进一步增强非线性模型,定义为
F=FFN(S) 。
(10)
为了避免过度拟合,以及模型能够加速收敛,在自注意力中和FFN都使用了Dropout和LayerNorm。自注意力层和FFN层的输出定义为
F=LayerNorm(S+Dropout(S)) ,
(11)
(12)
式中W1、b1、W2、b2都是可学习的参数,并且LayerNorm是标准化规范层。在2个线性变换层间存在GELU(gaussian error linerar unit)激活函数。
最近的工作强调,不同的图层可以捕获不同类型的表征[10,24],堆叠自我注意模块可能是有益的。为了进一步建模项目序列的表征,我们堆叠了自我注意模块,将第k层定义为
EK=SAN(E(K-1)) ,
(13)
E=SAN(F) 。
(14)
式中SAN代表整个自我注意模块。经过堆叠的自注意模块提取会话的顺序信息后,获得长期的自注意力表示EK。取EK的最后维度作为全局嵌入,即Sg。
2.5.2 构建局部嵌入
先前的研究工作都强调用户的当前操作对基于会话的推荐具有重要意义[6,11-12]。我们将会话历史序列建模为有向图,通过图神经网络学习用户行为图中的每个节点的表示,从而获得图中所有节点的向量表示。同时,获取原始序列的最后一次点击,通过多头注意力机制计算其对图节点信息的注意力权重,来生成当前会话的表示。将用户的当前兴趣偏好表示为局部嵌入Si,定义为
S=MultiHeadAttn(vs,n,H)=concat(Dhead1,Dhead2,…,Dheadh)Wo,
(15)
Dheadi=Attention(vs,nW1,HW2,HW3)。
(16)
其中Attention计算方式与式(9)相同,将原始序列中的最后一次点击vs,n作为Q,经过图神经网络更新后的节点表示H作为K和V,且W1、W2、W3都是可学习的参数。
2.6 预测层
结合会话的长期偏好和当前兴趣,即将全局嵌入Sg和局部嵌入Si加权在一起,作为最终的会话嵌入,
St=wSg+(1-w)Si。
(17)

(18)

对于每个会话图,损失函数定义为预测值与真实值的交叉熵,然后通过最小化以下目标函数来训练模型,
(19)
式中:y是会话序列中下一个点击项目的one-hot向量,θ是嵌入层的权重。
3 实验与分析
为了评估提出的模型,在一些数据集上进行实验来回答以下问题:
问题1:所提出的模型是否达到最佳性能?
问题2:用户短期偏好的表示形式是如何影响模型性能的?
3.1 数据集
所提出的模型在2个公开的真实数据集上进行训练和评估,即Diginetica和Yoochoose。Diginetica数据集来自于CIKMcup2016,本研究仅使用交易数据。Yoochoose数据集来自于RecSys Challenge2015发布的公开数据集,它包括从电子商务网站收集的6个月的点击流。据统计,该数据集中大约有90%的会话有7个或更少的项目。数据集的统计数据见表1。

表1 实验中使用的数据集信息Tab. 1 Statistics of the data set used in the experiment
3.2 评价指标
为了评估所有模型的推荐性能,本文采用3个通用指标。即平均倒数排名(MRR@10)、归一化折损累计增益(NDCG@10)和命中率(HR@10)。
3.3 对比算法
将本文提出的模型与以下8种方法进行比较,以验证所提出算法的整体性能。
BPR-MF[11]是一种基于贝叶斯后验优化的个性化排序算法,其核心是针对物品的相对偏好排序进行建模。
FPMC[12]是一种基于马尔可夫链的序列预测方法。
Improved GRU-Rec[3]是一种基于GRU的推荐方法,一般用于短的基于会话的推荐场景。
SASRec[24]是一种自注意力序列模型,其可以像循环神经网络一样捕捉较长的语义信息,同时也能够基于较少的行为来做出预测。
NARM[15]用于对用户的顺序行为进行建模,并捕捉用户在当前会话中的主要目的,它同时在模拟用户的顺序行为和主要目的方面具有优势。
STAMP[6]方法根据用户的一般兴趣和当前兴趣进行推荐。
SR-GNN[8]方法把会话序列建模为图形结构数据,并使用注意力网络将每个会话表示为该会话的全局偏好和当前兴趣的组合。
TA-GNN[19]考虑了目标项目和用户兴趣的多样性,目标感知注意力自适应地激活不同用户对不同目标项目的兴趣。
3.4 参数设置
对于以上所有模型,为公平进行对比,将embedding_size固定为64,训练集、验证集、测试集按照8∶1∶1的比例进行划分,2个数据集的最大序列长度都设置为20,其他所有超参数设置均尽量根据原始论文的建议将其调到最优。对于我们提出的模型,GNN模块所有参数均采用均匀分布,均匀分布的下限设置为-d-1/2(d为embedding_size),均匀分布的上限设置为d-1/2。线性层、嵌入层参数采用正态分布,均值设置为0,标准差设置为0.2,所有偏置项若不为空初始化为0。采用Adam优化器,学习率设置为0.001,正则化系数λ设置为5×10-5。如图3所示,建议将权重因子ω设置在0.6~0.8。

图3 多头数量h和权重系数ω在Diginetica数据集上的影响Fig. 3 Influence of the number h of multi-head and the weight ω on the Diginetica data set
3.5 性能比较
为了验证本文所提出算法的整体性能(问题1),在2个数据集上将提出的模型与对比模型在MRR@10、NDCG@10和HR@10方面进行了比较,结果如表2所示,最佳结果加粗标出。本文模型(CIR-GNN)通过将位置嵌入与图结构相结合,从而利用了顺序感知模型和图形感知模型的优势。同时,取原始序列的最后一次点击,通过多头注意力机制计算其对图节点信息的注意力权重,以更加准确地获取用户当前兴趣的表示。通过实验表明,该模型方法在2个数据集上都取得了最佳性能,这验证了该方法的有效性。

表2 本文提出的模型与对比模型在2个数据集上的性能比较Tab. 2 Performance comparison between the proposed model and the baselines on the two data sets
对于像BPR-MF和FPMC这样的传统算法,仅基于重复的协同项目或连续项目进行推荐,忽略了会话上下文信息的重要性,导致它们的性能相对较差,这表明传统的基于MC的方法主要依赖连续项目独立性的假设是不现实的。
基于神经网络的方法,如Improved GRU-Rec、SASRec、NARM和STMP,优于传统算法,这足以验证基于神经网络的方法在推荐系统方面的可行性。Improved GRU-Rec基于GRU,只考虑了序列行为,无法避免用户兴趣漂移引起的问题。SASRec和NARM在对比模型中实现了比较好的性能,是因为它们不仅建模了序列行为,还同时使用了注意力机制来捕捉用户交互过程中的其他信息。STAMP通过使用最后一次点击的项目作为用户的当前兴趣,并与用户的长期兴趣相结合进行建模,一定程度上解决了用户兴趣漂移问题,从而优于传统方法。
对于像SR-GNN和TA-GNN这种基于图神经网络的方法,均考虑了会话中项目的转换,将每一个会话建模为图形结构,可以捕捉用户点击之间更复杂和隐含的联系,表现出了极为优异的性能。但是,它们的性能仍然低于本文所提出的方法,本文模型在图神经网络的基础上,结合了位置嵌入信息,从而利用了顺序感知模型和图形感知模型的优势。此外,先前的研究工作都强调了用户的当前操作对基于会话的推荐具有重要意义,因此本文模型取原始序列的最后一次点击,通过多头注意力机制计算其对图节点信息的注意力权重,来生成更准确的用户当前兴趣的表示。正如表2所示,本文提出的方法在2个数据集上实现了所有方法的最佳性能,特别是在Diginetica数据集上,所有的评价指标都提升了7%以上,MRR@10指标甚至提升了9.52%。这些结果证明了本文所提方法对于基于会话的推荐的正确性和有效性。
3.6 模型分析与比较
本节进行深入的模型分析研究(问题2),设计4种模型变体,即STOM、NARM-STO、SRGNN-STO和CIRGNN-STO,通过一系列对比实验,评估短期用户偏好的表示形式对模型推荐性能的影响。
本文提出的模型旨在同时捕获用户的长期兴趣和短期偏好,在本节实验中,将原始序列的最后一次点击与注意力机制相结合,作为短期用户偏好的表示形式,与其他3种模型变体进行比较。从图4中可以看出,CIRGNN-STO在Yoochoose和Diginetica 2个数据集上均取得了最佳结果,这证实了其表示形式的有效性。同时,从图中可以发现,基于图神经网络模型的效果要优于序列模型,这表明会话序列建模为有向图后能够捕捉复杂的项目转换关系,能显著提升推荐效果。但是,SRGNN-STO在Yoochoose数据集上HR@10指标略低于NARM-STO,而CIRGNN-STO的性能却基本可以达到最优效果,这进一步凸显了利用原始序列中最后一次点击作为多头注意力机制中的Query来自适应捕获用户短期偏好,能在更大程度上弱化意外点击等噪声行为对获取会话向量表示的影响。此外,与表2进行对比可以发现,仅使用用户短期偏好会降低推荐性能,这证明了在推荐中将用户长期兴趣和短期偏好结合的必要性。
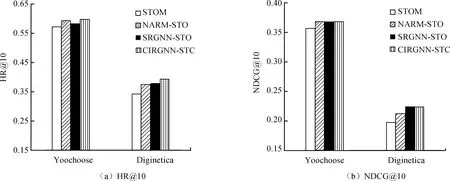
图4 不同短期用户偏好模型的效果对比Fig. 4 Comparison of the effects of different short-term user preference models
4 结论
本文提出一种面向强化当前兴趣的图神经网络推荐算法。具体来说,首先,根据会话序列中项目的顺序引入位置嵌入信息,并把会话中的历史序列建模为有向图,通过图神经网络学习用户行为图中节点的表示,从而获得图中的所有节点的向量表示。同时,取原始会话序列中的最后一次点击,通过多头注意力机制计算最后一次点击对图节点信息的注意力权重,来生成当前会话的表示。最后,线性加权结合GNN和注意力机制的互补优势表征用户的整体兴趣并产生推荐。实验证明,在MRR@10、NDCG@10和HR@10方面,本文所提出的模型能够显著提高推荐性能。
未来会借鉴文献[25]的工作,通过时间门控方法来改进注意力机制和循环单元,以便在信息过滤和状态转换中同时考虑时间信息。
