基于双向循环神经网络的游客目的地印象分析算法及应用
2022-05-30李霖张俊坤王燕陈尧鲜冰洋
李霖 张俊坤 王燕 陈尧 鲜冰洋


摘要:文本情感分析已成为智慧旅游中一项关键技术。为了提升景区及酒店等旅游目的地美誉度及其相关竞争力,如何从海量的用户评论中获取相关数据,并从中整理出具有价值的信息,将其运用到智慧旅行的构建中,成为文旅主管部门和旅游相关企业非常重视的工作。文章基于数据挖掘技术对相关景区和酒店评论进行内在信息的挖掘与分析,研究基于双向循环神经网络的游客目的地印象分析算法及应用。首先,对获得的评论数据集利用Python的Pandas库、正则表达式进行数据预处理;其次,利用中文分词组件jieba对数据进行分词与停用词过滤操作,保证模型构建的准确性;最后,通过构建中文词向量模型拟合双向LSTM回归模型,分别对每个景区和酒店进行评分,采用了基于BRNN的中文情感倾向分类模型,分别对每条评论进行情感正负面分类;基于最终得出的有效评论,并且采用TF-IDF算法,分别对总得分各个层次的景点和酒店的评论进行关键词提取,并保存为词云图,以便更加直观地分析。阐述了基于双向循环神经网络的游客目的地印象分析算法过程及应用。
关键词:BRNN算法;中文情感倾向分类;LSTM算法;算法应用
中图分类号:G633 文献标识码:A
文章编号:1009-3044(2022)29-0016-05
本文所采用的数据为亚马逊商城评论数据集——onlineshopping数据集,开源数据集总计693573条,开源数据集中情感置信度越接近1的文本为积极情感的可能性越高,置信度越接近0,文本为消极情感可能性越高。采用基于BRNN(Bidirectional Recurrent Neural Networks)模型的数据挖掘方法,在对数据集进行基本的数据预处理、中文分词、停用词过滤后,通过自构建中文文本情感倾向分类模型,实现对数据集文本的情感倾向判断,提取出对智慧旅游构建的有效信息。并将建模的模型运用到实际中,对各个景区和酒店的优劣势进行挖掘,为游客和政府部门提供数据保障[1]。
1 相关算法概念
1.1 BRNN(双向循环神经网络)理论
BRNN将传统RNN的状态神经元拆分为两部分,一部分负责positive time direction,另一部分负责negativetime direction。由于Forward states的输出并不会连接到Backward states的输入,因此与传统RNN相比,BRNN的结构提供了输出层输入序列中每一个点的完整的过去和未来的上下文信息,使得在任何时刻t都能获取到所有时刻的输入信息。BRNN的结构图如图1所示。
其中,s表示隐藏层的向量,o为输出层的向量,x为输入向量数据。U是输入层到达隐藏层的权重矩阵,V为隐藏层到输出数据权重矩阵,W是隐藏层上时间戳步到下一个时间戳计算 s的权重矩阵。当引入时间步 t,t在文本中就代表第t个词或字。xt代表第t个词(字)的词(字)向量,st代表第t个时间步的隐藏状态,ot代表第t个时间步的输出向量。
1.2 LSTM简述
LSTM(长短期记忆网络)是一种较为特殊的RNN网络,它能够对相对长序列间的依赖进行学习。在LSTM算法中,每个神经元便是一个“记忆细胞”,每个细胞里都有“三重门”,分别是一个“输入门”、一个“遗忘门”、一个“输出门”。LSTM与一般的神经网络的神经元相比,增加了遗忘门。其结构如下图2所示。
它较一般的RNN结构在本质基本相同,但是使用不同的函数去计算隐藏层的状态,如图3所示。在LSTM中,i结构被称为cells,可以把cells看作是黑盒,用以保存当前输入x_t之前保存的状态h_(i-1),这些cells决定哪些cell抑制,哪些cell兴奋。它们可以结合前面的状态、当前的记忆与当前的输入。该结构在对长序列问题中非常有效[2]。
1.3 TF-IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与数据挖掘的常用加权技术,因为其算法简单高效的特点,常被用于最开始的文本数据清洗。TF-IDF有两层意思,一层是“词频”(Term Frequency,缩写为TF),另一层是“逆文档频率”(Inverse Document Frequency,缩写为IDF)。
词频(TF):指的是在一份给定的文件里,某一个给定的词语在其中出现的频率。在对某一特定文件里的词语ti而言,它的重要性可表示为公式(1):
(1)
其中ni,j{\displaystyle n_{i,j}}是该词在文件{\displaystyle d_{j}}中的出现次数,而分母则是在文件dj{\displaystyle d_{j}}中所有字词的出现次数之和。逆向文档频数(IDF):指的是一个词语普遍重要性的度量。其值可由公式(2)表示:
[idfi=lgDj:ti∈dj] (2)
其中|D|:表示语料库中的文件总数。[j:ti∈dj:]包含词语ti的文件数目,如果词语不在资料中,就导致分母为零。因此,一般情况下使用[1+j:ti∈dj]。然后[tfidfi,j=tfi.j×idfi],某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤常见的词语,保留重要的词语[3]。
2 数据预处理
2.1删除异常值与重复值
根据观察,原始数据集中存在少量英文評论,包含缺失值和无意义的标点符号,为了保证数据的精准性及模型的泛化能力,将少量英文评论、空值和标点符号除去。原始数据集中存在部分重复评论,这类评论是连续的、重复的主体,也是毫无意义的评论,需要进行删除。
2.2特征提取
特征提取是深度学习的重要步骤,往往好的特征选择能达到更高的精度。在数据预处理后,通过机器+人工的方式筛选出情感倾向较为明显的文本作为自定义词典部分内容。筛选后总文本量为522948行。
2.3中文分词
在中文的句子中,词是最小的语言单位,因此,要判断句子的整体含义就必须将句子进行分词操作。分词结果是否准确对算法模型的优劣有重要影响,采用Python中jieba分词库,来达到分词效果。其原理使用动态规划查找最大概率路径,找出基于词频组合的最大切分组合,jieba分词有四种分词模式,采用jieba.cut()精确模式对数据集进行分词。为了节省存储空间和提高检索效率,在处理对情感分析任务中对没有实际影响的功能词和词典词,应予以删除。
2.4构建中文字典
由于中文语意主要由词语决定而不是单独的汉字,因此需要对待训练的中文文本进行分词处理,并以此构建词典。将Python字典中键0对应的值设为空字符串。将常用数字,英文字母直接添加至Python字典中,将分词后的数据录入字典,最终得到字典键值对261089对[4]。
3 算法模型构建
3.1构建中文词向量
机器不能识别自然语言,只能将向量(数字数组)作为输入数据,因此需要对文本进行向量化(将字符串转为数字),再将其输入模型。传统One-hot的编码得到的向量是二进的、稀疏的、纬度很高。为了规避以上问题,本文采用词嵌入(word embedding)编码方式,这种编码较One-hot编码相比,更加高效且密集,使得相似的词组具有相似的编码,且操作人员不必手动指定编码。将特征提取后的文本保存为Python列表,对列表中的句子进行分词,并查找词语对应的中文词典索引,将其保存为NumPy数组。
3.2构建文本情感倾向分类模型
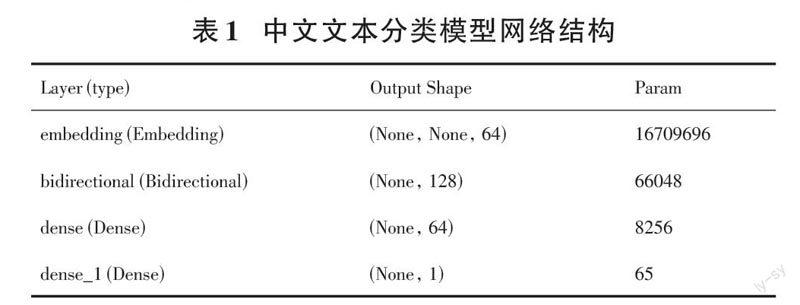
根据回归模型拟合的用户评分,评论数据集中存在部分评分与评价内容相差较大的文本。实际用户评价和用户给出的评分相差过大,明显为无相关内容,为了保证分析结果的准确性,采用双向循环神经网络(Bidirectional Recurrent Neural Networks)构建中文文本情感分析模型,通过模型对每一条评论进行情感分类,筛选出分类后情感倾向为负,但总评分较高的文本,判定为无效评论,并将其剔除,模型网络结构如表1所示[5]。
经过测试发现,将BRNN模型迭代次数设置为5轮,模型即可达到最优,准确率在99.6%,模型对用户评论情感分类具有较高精确度,能较好地对评论进行分类判断。
3.3构建双向LSTM算法模型
利用双向LSTM模型,首先,对每个景区和酒店的每条评论进行打分操作。其次,根据模型拟合出的各个酒店和景区的评论各项得分之和,以此计算各项平均值,将所计算出的平均值作为酒店和景区在各个方面的最终得分,得出的各个酒店和景区的结果,部分如表2所示。
4 算法模型评估
4.1均方差(MSE)评估
根据所得出的评分,对模型按照均方差(Mean Squared Error, MSE)进行评价如图4所示。
通过模型拟合的数值与专家的评分进行对比,得出绝大多数酒店的各项评分和专家给出的得分接近,专家的评分与实际用户评分基本拟合,专家给出的酒店以及景区评分对用户而言也具有实际的参考价值。
4.2情感置信度评估
采用了中文文本情感分類模型对每一条评论都进行了情感分类,并返回了0-1的情感置信度,越靠近于1的文本,其为正向情感的可能性越高,情感置信度越靠近0的文本,为负面情感的可能性越高。通过预测的每条文本的情感置信度和得分,剔除情感为负,但评分较高的评论。情感分类模型分析结果如表3所示。
从模型返回的情感置信度结合人为判断文本的实际情感[6],如H01酒店评论:“升级了房间,延迟退房很赞”模型预测的情感置信度为0.97,接近于1为正向评论。H50酒店评论:“隔音极差,睡眠让人崩溃”,模型预测的情感置信度为0.005,接近于0为负面情感。由此,从表3可以看出,如H50酒店评论:“隔音极差,睡眠让人崩溃”这种为负面评论,但评分为4.6,这种评论明显没有意义,不具有参考价值,因此将这类评论剔除。
4 算法模型分析
采用TF-IDF算法,分别对总得分“低”“中”“高”三个层次的各3家景点和各3家酒店的所有评论进行了关键词提取,并保存各自的词云图以便更直观地分析。部分酒店及景区相关词云图如图5所示:
由图5可以得出,在同为总分低层次的酒店中,H38酒店的特色主要由“沙滩”“海水”“温泉”这类词语构成,从中可以推断出H38酒店开设于海边,主要面向的顾客为喜欢大海、沙滩、玩水的这一人群,又由“私人”“幽静”这一热度词可知,H38酒店较为安静,在宣传时可用“私人沙滩”“清净”等这类词汇作为主要卖点,以此来吸引顾客。H48酒店特色主要由“国贸”“罗湖口岸”“老街”“服务号”词语构成,H48酒店开设于深圳罗湖区,在市中心附近,主要面向的顾客可能为商业出差人士,可用“商业休息”“高品质服务”作为宣传特色。
由图6可知,这三家高评分的景区主要特色内容都不一样。如景区A23主要特色由“苏州园林”“岭南”“中山”构成,景区A38主要特色为“温泉”“阳西县”“游泳池”。从中推断,景区A23主要面向喜欢中式园林风格的游客,景区A38主要游客可能为阳西县及其附近地区人群。
6 算法模型应用场景
6.1 城市交通短期客流预测
随着城市的发展和人口的聚集,公共交通旅行问题变得越来越重要。城市交通由于其大容量、高速度和安全性等各种问题交错已成为目前研究的热门方向。近年来,城市交通发展迅速,但在追求大众“优质”出行的过程中,诸如交通拥堵、交通不便等问题亟待解决。基于预测的时间范围,客流预测可以大致分为两类:长期预测和短期预测。长期预测通常是指预测未来时间3~10年的客流变化范围;短期预测通常是指,进行以周为单位或月为单位的预测。长期预测和短期预测分别有诸多优点,长期预测可提高城市的科学管理水平,短缺预测能够提高城市的线路优化和客流组织水平,从而进一步提高城市的科学管理水平。LSTM神经网络非常适合从经验中学习,LSTM神经网络适合于短时间客流预测。在LSTM基础上进行改进或者采用线性模型,同样可以做到很好地短期预测,该预测可以为先进的客流控制和诱导方法提供证据,该方法可以防止拥塞,践踏和其他安全事故。
6.2 彈幕情感分析
以视频为媒介﹐观众可以针对视频内容发送弹幕,用于表达自己在观看影片或视频后的情绪和感受,通过对弹幕内容的进一步分析,一方面可以对视频内容进行信息挖掘,优化视频内容。另一方面可以根据用户的真实情感表现,能够快速获取网民的情感倾向,为有关部门治理网络安全和舆情提供参考,结合中文预训练模型和长短期记忆网络的模型来完成弹幕文本的情感分类,可为弹幕文本分析提供较大帮助。
6.3 制定设备维护计划
基于状态监测数据,借助智能化的算法模型,实时评估系统健康状况及预测设备剩余使用寿命并据此制定维护计划。其在器械翻译、时间序列预测等多个场景应用广泛,针对复杂工况下的设备系统维护问题,可以结合时间序列网络研究复杂工况下的设备健康状况,以无监督学习的方式展开训练,可有效提高复杂情况下设备监测数据的预测,对复杂工况下的设备数据具有很好的鲁棒性。
6.4 网络谣言分析
随着互联网的急速发展,网络信息急剧增多,谣言也随之而来,如何识别谣言也成为热点问题之一。较早时期的谣言检测通常利用转发量、发布者的注册时间等统计特征,时间序列网络能够使人们获取信息以及信息检测更加方便快捷,互联网中存在的谣言对当前社会稳定具有较大的影响,将文本向量输入时间序列网络中,基于文本内容充分发掘其特征,并利用Softmax分类器进行训练与分类,能够更好地拟合互联网中出现的谣言,对识别谣言具有一定意义。
7 结论
根据酒店和景区评论的特点,利用双向LSTM算法模型以及采用开源数据集构造的中文文本情感分类模型,对其进行处理和信息挖掘,最终得到具有一定价值的结果,实现对相关景区和酒店在服务、位置、设施、卫生、性价比五个方面的评分和相关评论有效性的分析,以及相关酒店和景区的特色分析。这些分析结果对外来游客,外来投资者以及酒店公司和当地政府等都具有一定性的指导意义。酒店公司可以根据数据得出的信息,了解用户所关注的方面,对用户反馈较好的方面进行宣传,对用户反馈的问题进行改进。双向LSTM算法模型,还可用于城市交通短期客流预测、弹幕情感分析、定制设备维护计划、网络谣言分析等多种应用场景。
参考文献:
[1] 李岩.基于深度学习的短文本分析与计算方法研究[D].北京:北京科技大学,2016.
[2] Du L P,Li X G,Liu C L,et al.Chinese word segmentation based on conditional random fields with character clustering[C]//2016 International Conference on Asian Language Processing (IALP).Tainan ,China.IEEE,2016:258-261.
[3] 缪亚林,姬怡纯,张顺,等.CNN-BiGRU模型在中文短文本情感分析的应用[J].情报科学,2021,39(4):85-91.
[4] 邢梦来,王硕,孙洋洋.深度学习框架PyTorch快速开发与实战[M].北京:电子工业出版社,2018.
[5] Schuster M,Paliwal K K.Bidirectional recurrent neural networks[J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[6] 范昊,李鹏飞.基于FastText字向量与双向GRU循环神经网络的短文本情感分析研究——以微博评论文本为例[J].情报科学,2021,39(4):15-22.
[7] 丁涛.基于用户兴趣建模的协同过滤推荐方法研究[D].太原:山西大学,2020.
【通联编辑:唐一东】
