利用低信噪比小样本太赫兹光谱实现心肌淀粉样变检测
2022-05-28郑江鹏孙续国陈胜勇
郑江鹏,余 平,赵 萌,石 凡,孙续国,陈胜勇
(1.学习型智能系统教育部工程研究中心,天津理工大学计算机科学与工程学院,天津 300384;2.天津医科大学医学检验学院,天津 300203)
1 引言
心肌淀粉样变是一种渗透性疾病,指的是淀粉样蛋白在心肌细胞外间隙沉积的状况[1-2]。晚期患者会出现不同程度的心室壁增厚或变硬等症状,最终形成多器官衰竭或死亡[3]。目前,病理检查和影像学分析是诊断心肌淀粉样变的主要手段。心肌内膜活检属于侵入式检测,存在引起并发症的风险并需要医学专家来执行[4]。心电图筛查不具有普适性,研究证明转甲状腺素蛋白淀粉样变性的病例中只有40%出现心电图低压[3]。心血管磁共振成像不适合作为体内含有金属支架的患者用来筛查和追踪治疗反应[5]。核成像方式依赖于放射性核素,因而不可避免地存在电离辐射[6]。因此,有必要设计一种高效、准确、无辐射的诊疗方案来检测心肌淀粉样变。
太赫兹频段位于毫米波和红外波之间[7-8],因其具有高穿透性、光谱指纹特性和非电离性而在生物医学领域得到了广泛应用[9]。近年来,机器学习和深度学习技术的发展为准确分类太赫兹光谱提供了新的途径,但已有的用于太赫兹光谱分类的深度学习方法在很大程度上依赖于海量数据,而在生物医学领域,收集和标注大量的生物样本既耗时又低效[10]。因此,有必要设计一种针对小样本太赫兹光谱的分类算法,以提高模型的高效性和实用性。Barz 等[11]证明了对于小数据集而言,在未经预训练的模型上用余弦损失函数代替交叉熵函数将具有更好的预测性能。Liu 等[12]提出了一种基于生成对抗网络的数据增强方法,提高了对小样本病理切片中异柠檬酸脱氢酶的状态预测能力。Wang 等[13]为了改进小样本高光谱分类性能,提出了一种基于双向长短期记忆网络和角度模型的顺序联合深度学习算法。Wang等[14]利用孪生自编码器网络在样本数量较少的情况下增加了模型训练次数,实现了对小样本图像的分类。Cui 等[15]利用生成对抗网络扩充了太赫兹光谱数据样本量,实现了对10 种物质的小样本数据集的分类。这些已报道的方法对攻克相关领域的小样本分类问题具有重要意义,为设计分类模型提供了指导。
然而,利用深度学习算法对心肌淀粉样变的低信噪比小样本太赫兹光谱数据集进行分类仍面临以下挑战:第一,提取可区分性特征并分类重叠光谱。采集少量的最低信噪比光谱数据能够极大程度缩短数据获取时间,以此来提高心肌淀粉样变检测的效率。但是少量样本能够提供给模型学习的可用特征更少[16],同时,低信噪比光谱中噪声对特征的掩盖效应更严重[17]。因此,在这两种条件下,如何高效地提取可区分性特征并对样本进行准确分类显得尤为重要。第二,在少量样本情况下深度学习模型面临的过拟合问题。在数据特征维度高、样本量少的情况下,模型学习的特征存在冗余,因此克服过拟合问题是所面临的严峻挑战[18]。
为解决上述问题,本文提出了基于低信噪比小样本太赫兹光谱的心肌淀粉样变检测框架。具体来说,设计了一个基于卷积降噪自编码器模块、多尺度特征提取模块和密集连接模块的深度学习模型,以样本数量为100 的低信噪比(光谱平均次数取1,信噪比约为−50 分贝)数据集为输入,取得了95% 的准确率、100% 的精确度、92.30%的召回率以及95.99% 的F1 分数。通过调研大量相关文献发现:从未有过对于正常、淀粉样变心肌的低信噪比小样本太赫兹光谱展开的相关分类研究及报道。本文的实验结果证明,所提出的框架在提升以太赫兹技术和深度学习技术为基础的心肌淀粉样变检测方法的实用性和时效性方面具有巨大发展潜力。
2 材料与方法
如图1(彩图见期刊电子版)所示,下面将详细介绍本文研究的具体流程,包括生物样本制备、光谱采集设备的搭建、数据预处理的基本流程以及分类模型的构建等。

图1 整体框架图Fig.1 Overall framework of the proposed method
2.1 样本制备
实验中用到的正常和淀粉样变心肌组织均由中国天津医科大学提供,所开展全部研究均已得到该机构的许可。样本制备过程分为4 个步骤:福尔马林固定细胞形态、石蜡包埋形成组织块、切片并制片。本文中,所有的生物组织均是从人体切除并在具备相同环境条件(湿度、温度等)的病理实验室中制备。首先,将各个组织置于4%的福尔马林水溶液中固定细胞形态、保持肌体的微结构,同时防止标本腐烂。其次,将生物组织置于熔融石蜡中进行包埋,待石蜡全部凝结后取出。然后,利用病理实验室的医用石蜡切片机进行切片。在本项研究中,制备了包含0.2、0.3 和0.4 mm 的正常和淀粉样变生物组织。最后,为了与所使用的数据采集设备相匹配,将组织样本固定于厚度为0.5 mm 的JGS1 石英玻璃上,并得到了如图1 所示的实验样本。
2.2 太赫兹时域光谱系统
本文使用的紧凑型太赫兹时域光谱系统由德国慕尼黑Menlo Systems GmbH 公司开发,该系统能提供约8 太赫兹的带宽,并通过网络进行自动测量和数据传输。光路设计以透射模式为基准,所采集数据为太赫兹时域光谱。如图1 所示,该时域光谱仪主要由飞秒激光器、发射器、透射式光路、探测器、控制元件等组成。系统提供的发射器和探测器的额定功率分别为22.7 mW 和23.9 mW。光谱的时域范围是−88~12 皮秒(ps),频域范围是0~8 太赫兹(THz),信噪比动态范围大于100 分贝(dB)。飞秒激光器作为辐射源,在接通电源的情况下产生两个超快激光束1 和2。超快激光1 和偏置器产生的偏置电压一起共同激发发射器产生太赫兹脉冲。此后,脉冲束经由透镜1 和透镜2 聚焦到样品处,再经由透镜3 和透镜4 到达探测器端。该太赫兹脉冲和超快激光2 一起共同激发探测器,以获取携带物质信息的电信号。由于直接获取的电信号比较微弱,因此,本系统利用放大器进行信号放大并利用数模转换器将模拟信号转换为数字信号,最终传送到电脑端保存。
2.3 数据获取及预处理
光谱采集在空气环境下进行,无需另外填充氮气:恒定25 °C,湿度固定。实验获取的太赫兹光谱未经平均处理,即具有光谱采集系统所能提供的最低信噪比,约−50 dB。具体来说,数据采集分为两步:采集参考信号和获取样本信号。将单层JGS1 石英玻璃对应的太赫兹时域光谱作为参考信号,将正常及病变心肌组织对应的光谱作为样本信号。在采集样本信号时,将生物组织置于样品架上,首先利用太赫兹光谱成像技术确定样本所在区域,然后以0.1 mm 为步长从成像热力图中确定多个二维坐标,最后依次保存坐标对应的光谱数据。
如图1 所示,太赫兹时域光谱数据预处理包括以下几个步骤:首先,利用傅立叶变换实现时域到频域的转换,并以此来确定光谱的有效频段。以参考信号为例,高噪声频段被摒弃,只留存了0.2~2 THz 的频域光谱,以减少噪声对病变检测结果的干扰,如图2 所示。其次,为了降低样本厚度等的干扰,以透射率(Transmittance)值为基准提取生物样本的特征光谱,即样本信号与参考信号在0.2~2 THz 范围内的振幅比。除此之外,为避免量纲对分类结果的影响,对透射率进行了最大最小归一化处理。随后,利用在文献[19]提出的基于一阶差分值的阈值算法进行边缘点去除。最后,利用python 语言编写代码,以从所得纯净数据中随机挑选出100 个样本作为本文所使用的小样本太赫兹光谱数据集。最终获得的数据集包含53 个阳性样本,47 个阴性样本,比例接近1∶1。以阴性、阳性样本的均值和标准差为依据,利用Origin 2021b 软件绘制数据集的可视化结果,如图3(彩图见期刊电子版)所示。

图2 参考信号的时域及频域光谱Fig.2 Time-domain and frequency-domain spectra of the reference signal

图3 阴性、阳性样本的整体范围趋势图Fig.3 Overall trends of negative and positive samples
从图3 可以看出,阳性、阴性样本存在重叠,无法通过视觉进行区分。为应对空气环境中的水蒸气干扰、噪声干扰以及特征光谱的重叠问题,有必要设计基于深度学习的自动特征提取和分类模型。
2.4 网络架构
在本文中,模型的架构设计遵循数据降噪、特征提取、增强特征表达、结果预测4 个基础流程,以python 为编程语言。
2.4.1 卷积降噪自编码器
根据数据集噪声干扰大的特点,设计了一个具有光谱降噪能力的卷积降噪自编码器[20]模块。该模块包括编码和解码两部分[21],它通过将模型的输入特征进行压缩、重构以减少特征之间的相关性、冗余度。首先,将数据预处理得到的透射率谱线与高斯噪声进行叠加,得到模型的整体输入。然后,分别利用卷积核大小均为3,滤波器个数分别为32 和16 的一维卷积和最大池化操作进行编码。随后,利用核大小为3,滤波器个数为4 的一维卷积进行特征压缩。解码阶段是编码的逆过程,先对编码结果进行上采样再进行卷积,最终得到去除噪声的光谱特征。在该模块中,采用指数线性单元(Exponential Linear Unit,ELU)激活函数。如公式(1)所示,该函数同时兼具非线性和线性:在左侧具有软饱和性,对输入数据的噪声变化更加鲁棒;在右侧具有线性特征,能够缓解梯度消失并加快模型收敛。L1 正则化和L2 正则化是构建深度学习模型过程中用于防止模型过拟合的常用手段。在本文中,为了降低模型复杂度造成的过拟合,在每层卷积操作中都设置了L2 正则化操作,如公式(2)所示。L2 正则化方法通过惩罚系数来平衡正则项与原始代价函数之间的比重,从而实现对代价函数值变动幅度的约束,以此减少过拟合。

2.4.2 多尺度特征提取模块
考虑到所构建的光谱数据集来自于具有不同厚度、不同类别的生物组织样本,不同数据间包含的特征强度是不同的。为了捕捉光谱样本的细微差异并进行有效的特征提取,设计了以不同卷积核大小为基础的多尺度特征提取[22]模块。首先,将卷积降噪自编码模块的输出结果进行批归一化(Batch Normalization,BN),以降低不同样本之间的差异性。随后,将BN 操作的结果输入到卷积核大小依次为1、3、5、7,滤波器个数均为16 的4 个并行卷积层中,并行卷积操作保证了对模块原始输入数据进行直接处理,避免了串行卷积间的特征损失。除此之外,为每个并行卷积层执行了BN 操作,这能够在一定程度上加速模型收敛并进一步防止过拟合。在每个卷积操作中,使用线性整流函数[23](Rectified Linear Unit,RELU)作为激活函数。如公式(3) 所示,当RELU 激活函数的输入值大于零时才会产生非零输出值,因此其生成的矩阵具有元素稀疏性,可以防止因为多个并行卷积层带来的过拟合问题。
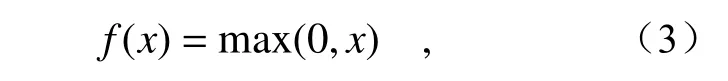
其中,x表示输入值,f(x)表示RELU 激活函数的输出。最后,利用concatenate 操作将所提取的不同尺度信息进行通道融合,这使得用来描述光谱本身的特征数增加并保证单一特征的描述信息不变,避免了特征信息冗余。
2.4.3 密集连接模块
传统的串行卷积操作会造成特征传递过程中的损失,导致最终用于样本分类的特征信息被削弱,针对这一问题,本文设计了基于密集连接操作的特征传递模块。在该模块中,将多尺度模块所提取的特征作为输入,并执行系列二维卷积操作。首先,设计了3 个尺寸为3×3×32 的串行二维卷积层,并在任意两个卷积层间建立密集连接,以保证当前层的输入为此前所有卷积层的输出在通道方向上的融合。这种在输入和输出之间建立直接连接的方式加强了特征的传递效应并实现了特征复用。其次,在密集连接后设置了尺寸为1×1×1 的卷积层,以减少由于模型复杂度提升引起的参数量增加。最后,在每个卷积层后同样执行了BN 操作,这使得数据分布得到约束并防止了该模块带来的过拟合问题。
2.4.4 输出模块
在模型的输出部分,首先将上层模块输出结果扁平化到一维,并利用神经元个数分别为128 和32 的全连接层将模型学到的特征表示映射到特定的样本标记空间。与此同时,RELU激活函数被用于对矩阵加权计算结果进行激活。随后,为了进一步抑制过拟合,设置了Dropout 层[24]使神经元以一定的概率随机失活,其参数为dropout_rate。由于在前述模型构建过程中已经使用了多种防止过拟合的措施,因此,为了保证神经元以一定概率失活并同时防止因为失活率过大造成重要分类特征丢失,将dropout_rate 设置为0.2。最后,Sigmoid 激活函数用于对样本类别进行概率预测,交叉熵损失函数被用于度量真实标签和预测值之间的差异程度。
3 结果与讨论
分类模型的输入数据集包含100 个样本:阴性样本47 个,阳性样本53 个。按照训练集与测试集以4∶1 的比例划分出20%的样本作为单独的测试集。然后,对训练集执行5 折交叉验证策略,即每次选取80% 训练集用作训练,选取20%训练集用作验证,以对测试集样本进行预测。下列结果与讨论中保存的实验结果均为五折交叉验证结果的最佳效果值,并将模型优化器设置为Adam,迭代次数设为500。
为了全面评价该分类模型的分类效果,使用准确率(Accuracy)、精确度(Precision)、召回率(Recall)和F1 分数(F1-score)4 个评价指标进行评价。本部分将从模型的整体分类性能、参数设置、对比实验、消融实验、样本量分析5 个方面展开讨论。
3.1 模型的整体分类性能
如图4(彩图见期刊电子版)所示,在模型分类预测得到的混淆矩阵中,阴性样本全部被正确预测,阳性样本只有1 个被错分。因此本文所设计的检测框架不存在假阳性,在一定程度上可以对阳性样本实现高度准确的预测。根据混淆矩阵计算得到的各项评价指标,如图5(彩图见期刊电子版)所示。从图5 中可以看出,本文算法的准确率为95%,精确度为100%,召回率为92.30%,F1分数为95.99%。不仅如此,对于每个光谱,其采集时间均在1 s 以内,利用训练好的模型进行分类的时间在0.004 s 以内。根据模型的上述综合分类表现可以看出,本文设计的心肌淀粉样变检测框架对实现病变的精准分类具有一定的应用潜力,此外,其对于利用低信噪比、小样本太赫兹光谱数据集进行模型时效性提升具有重要意义。

图4 模型分类预测得到的混淆矩阵Fig.4 Confusion matrix obtained by classification prediction of the model

图5 该模型的不同评价指标值Fig.5 Evaluation indicators of the proposed model
为了进一步验证模型的性能稳定性及实验结果的可重复性,在同等条件下进行了10 次独立重复试验。实验结果如表1 所示,仍以上述4 个指标进行评估,并加入每个指标的极差作为判断实验结果稳定性的辅助工具。

表1 10 次独立重复实验结果Tab.1 Results of 10 times of independent repeated tests
从表1 可知,本文模型的准确率、精确度、召回率和F1 分数的极差分别为0.46%、0.38%、0.66%和0.38%,这表明本文算法的预测性能在一定范围内具有稳定性,且分类结果具有可重现性。10 次独立重复实验中的准确率在94.66%以上、精确度在99.62%以上、召回率在91.66%以上、F1 分数在95.61%以上,并且各项指标的极差分布均在0.66%以内,由此可知,其在一定程度上符合生物医学中病变检测的可靠性要求。除此之外,与心肌淀粉样变的传统检测手段相比,本文方法在时间效率上有大幅提升。通常,传统检测方法进行病理组织切片约需耗费2 day 才能获取检测结果,心脏磁共振、放射性核素成像、超声心动图均需耗费2 h 左右得到检测结果[19],而本文研究方法最多需要1 h 即可实现心肌淀粉样变诊断:制备生物样本约需40~5 min 左右,采集一个平均次数为1 的太赫兹光谱则耗时不到1 s,利用训练好的模型分类一个光谱耗时低于0.004 s。通过上面对比可知,本文方法在时间效率上优于传统医学检测方法。
3.2 参数设置对模型分类的影响
在深度学习的模型设计中,学习率大小和批大小是影响模型分类效果的重要参数。学习率是调整损失函数梯度下降的超参,设置合适的学习率数值有助于加快模型的训练和收敛;批大小作为每次调整参数前选取的样本量大小,其大小对于网络的训练效果具有重要意义。在该部分,为分析参数变化对模型分类效果的影响,设置了两类学习率(0.001、0.000 1)和三类批大小(3、5、10),并在同比对照条件下通过组合不同的学习率和批大小分别进行了6 次分类预测。将准确率、精确度、召回率和F1 分数作为综合评价指标,实验结果如表2 所示。
从表2 可以看出,当学习率一定时,模型的分类能力基本随着批大小的增大而提高,说明对于所构建的模型而言,增大批大小有助于提升模型分类能力。当批大小一定时,值为0.000 1 学习率下的分类效果优于0.001 的学习率,说明适当减小学习率有助于提高本文模型预测的准确性。通过上述分类实验结果可知,在学习率为0.000 1,批大小为10 的条件下模型性能最优。究其原因,在样本量小的时候,增大批大小有助于在一次训练迭代中学习到更多的样本特征,使得分类器每次迭代的预测效果更加稳定,有助于削弱准确率和损失值的震荡现象。同时,减小学习率使得模型可以学习更加优化的权重集合,以使模型收敛到更好的最小值。

表2 不同参数对模型分类效果的影响Tab.2 Effects of different parameters on model classification
3.3 对比实验
选取15 种用于一维光谱分类或一维序列分类的机器学习算法、深度学习算法与本文算法进行对比。具体包括:k-最近邻算法[25](KNN)、逻辑回归算法[26](LG)、朴素贝叶斯算法[27](NB)、随机森林算法[28](RF)、决策树算法[29](DT)、线性判别分析算法[30](LDA)、Adaboost 分类器[29](AC)、二次判别分析算法[31](QDA)、支持向量机[25](SVM)、长短期记忆网络[32](LSTM)、双向长短期记忆网络[31](BiLSTM)、卷积长短期记忆网络[33](CLSTM)、残差网络[34](ResNet)、密集连接网络[35](DenseNet)和卷积神经网络[36](CNN)。在对比实验中,以100 个样本作为输入,并保持所有参数相同,实验结果如图6(彩图见期刊电子版)所示。

图6 与15 种机器学习算法和深度学习模型的对比实验Fig.6 Comparative experiments of proposed model with 15 kinds of machine learning algorithms and deep learning models
从图6 可以看出,在15 种对比算法中,机器学习算法得到的各项评价指标普遍高于深度学习,这是因为深度学习的分类能力在一定程度上依赖于数据量大小。但尽管如此,本文提出的分类模型在4 个指标上均高于最优对比算法(指标提升幅度:准确率15%,精确度18.44%,召回率11.28%,F1 分数14.71%)——线性判别分析(准确率80%,精确度81.56%,召回率81.02%,F1 分数81.28),这表明机器学习算法缺乏自动从含噪数据中提取特征的强大能力,并进一步证明了我们的分类模型对克服低信噪比的小样本数据集带来的分类挑战具有重要作用。
3.4 消融实验
为了深入分析本文所构建网络中主要模块的贡献度,针对卷积降噪自编码器模块(模块1)、多尺度特征提取模块(模块2)和密集连接模块(模块3)设计了相应的消融实验,实验结果如图7(彩图见期刊电子版)所示。

图7 各模块的消融实验结果Fig.7 Ablation experimental results of different modules
实验结果表明,当3 个模块全部消除时各项评价指标均出现大幅度下降,召回率仅为30%,F1 分数仅为42.85%,远远不能满足检测心肌淀粉样变的任务要求。当仅使用1 个模块时,分类效果均得到提升,且单一的卷积降噪自编码器模块具有最高贡献度,其综合性能评价指标F1 分数达到87.99%。当组合使用任意两个模块时,分类效果均较单一模块高,且最佳F1 分数达到90%。消融实验证明本文所设计的3 个模块对于分类心肌淀粉样变的低信噪比小样本太赫兹光谱数据均有一定贡献度,且3 个模块顺次组合能使得模型分类效果最大化。与此同时,这也证明所采用的降噪、特征提取、特征表达的基本流程是合理、正确的。
3.5 样本量大小对模型分类效果的影响
上述实验结果及分析证明了本文所提出的模型在样本量大小为100 时具有超越同比机器学习算法及神经网络模型的优势。本节将从两个方面分析样本量大小对模型分类效果的影响。
首先,选取样本量分别为20、40、60、80、100,分析本文设计模型的各项分类指标,结果如表3 所示。
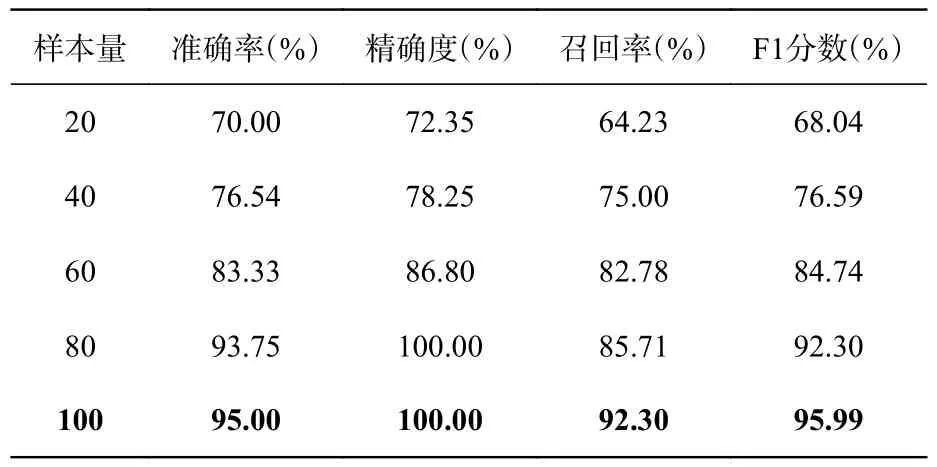
表3 样本量对本文模型分类效果的影响Tab.3 Influence of the number of sample on model classification effect
实验结果表明随着样本量的增加,各项指标均逐渐提升,并在样本量为100 时达到了最佳效果。当样本量仅为20 时,本文模型仍能达到70%的准确率、72.35% 的精确度、64.23% 的召回率和68.04% 的F1 分数。实验结果说明本文分类网络在应对样本量变化的条件下具有一定的抗敏感性,并且当样本量下降到60 时,仍能够取得令人满意的心肌淀粉样变检测效果。
其次,通过向原始数据添加噪声的方式将本文的实验数据扩增到3 000 个。在此基础上,利用本文提出的模型进行分类,并与ResNet[34]、DenseNet[35]、CNN[36]3 个用于大型光谱数据集分类的模型进行对比,实验结果如表4 所示。
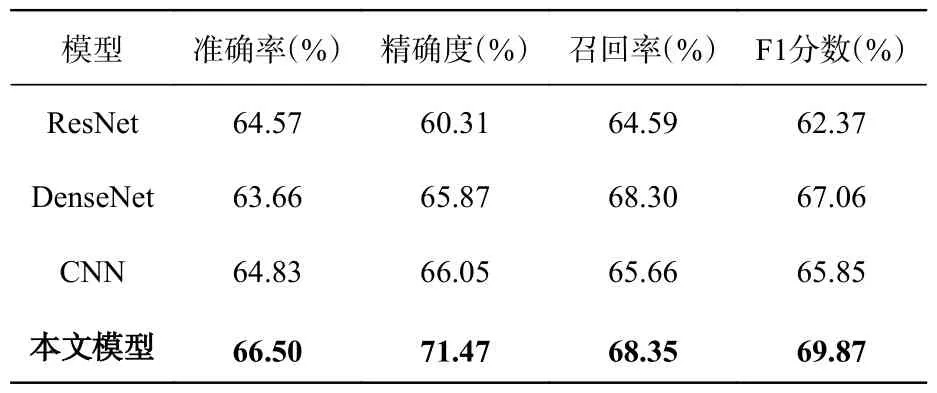
表4 扩增样本量对模型分类效果的影响Tab.4 Influence of the number of expanded samples on model classification effect
实验结果表明,本文模型对于扩增数据集的准确率为66.50%,精确度为71.47%,召回率为68.35%,F1 分数为69.87%。与其他3 个分类模型相比,本文模型的4 个指标均最优。尽管如此,本模型在扩增样本后的分类结果仍与未扩增样本时有约30%的差距。这进一步说明,单纯扩增样本量并不能对低信噪比数据进行准确分类,表明本文的研究思路是行之有效的。
4 结论
心肌淀粉样变的早期诊断对于治疗该类疾病具有重要意义,已有研究为结合太赫兹光谱技术和深度学习算法实现心肌淀粉样变检测提供了指导。但是当太赫兹光谱数据集具有低信噪比和数据量少的特点时,深度学习方法难以高效提取可区分性特征且存在过拟合。基于此,本文提出了一种基于多模块顺序级联的太赫兹光谱分类模型。设计了以卷积降噪自编码器模块、多尺度特征提取模块和密集连接模块为基础的心肌淀粉样变检测模型。实验结果表明,在最低信噪比水平和小样本量条件下,该模型可以实现F1 分数为95.99%的心肌淀粉样变检测效果,超越同类机器学习算法和深度学习算法。与此同时,独立重复实验证明了该模型的稳定性和可重复性。因此,本文所设计模型在利用低信噪比的少量太赫兹光谱实现心肌淀粉样变检测方面具有一定应用潜力。
