结合自适应软掩模和混合特征的语音增强
2022-05-28贾海蓉张刚敏王素英
张 敏,贾海蓉,张刚敏,王素英
(太原理工大学 信息与计算机学院,山西 太原 030024)
语音增强是旨在保证语音不失真的条件下,尽可能地从带噪语音中减少或消除干扰,提取有用语音分量的技术[1]。语音增强的方法可分为有监督学习和无监督学习两类。无监督学习如谱减法[2]、维纳滤波法[3]等,都基于一些不合理假设,且在低信噪比或者非平稳噪声的条件下,抑制能力差,容易引起语音失真。有监督学习可分为基于浅层和深层模型两类,其中基于浅层模型如隐马尔科夫模型、非负矩阵分解、浅层神经网络等,学习语音非线性结构信息有限,一定程度上限制了模型的性能。深层模型具有强大的学习能力,可以有效学习带噪语音特征与学习目标之间的关系,因此成为语音增强方向的研究热点。文献[4]通过深度神经网络学习带噪语音特征和时频掩模间的非线性关系,且对理想二值掩模(Ideal Binary Mask,IBM)、理想浮值掩模(Ideal Ratio Mask,IRM)、目标二值掩蔽等一系列基于时频掩蔽的学习目标进行了对比。分析实验结果可知,当选用IRM作为学习目标进行语音增强时,增强语音的质量和可懂度最优。但IRM没有考虑与语音可懂度密切相关的相位信息,且在不同信噪比条件下,都根据语音能量在语音与噪声能量和中的比重来确定的,无法根据信噪比的不同来自动调节,容易造成目标语音成分的丢失。语音特征能够表征语音信号的特性,不同的语音特征代表的语音属性各不相同。文献[5]从人耳听觉感知特性的角度出发,提出了梅尔倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC),但梅尔滤波器在高频处容易发生泄露,从而丢失有效语音特征,且无法较好地模拟人耳基底膜的分频特性。文献[6]提出了功率归一化倒谱系数(Power Normalized Cepstral Coefficients,PNCC)。该特征进行语音增强时性能良好,但在处理混响时,会导致运算时间变长。文献[7]提出了多分辨率耳蜗(Multi-Resolution CochleaGram,MRCG)特征,通过不同分辨率的耳蜗组合来捕获语音信号的局部和全局信息,但该特征维数过高,会导致网络运算复杂度增加。
通过以上分析,笔者提出一种混合特征来改善传统特征的局限性。首先,通过根据人耳结构设计的梅尔滤波器提取MFCC特征,并采用更符合人耳听觉压缩感知的非线性幂函数提取新的伽马通频率倒谱系数(New Gammatone Frequency Cepstral Coefficients,NGFCC)。伽马通滤波器可以改善梅尔域滤波器在高频处丢失有效特征的问题,同时可以模拟人耳基底膜的分频特性。将两种特征混合可较全面描述语音信息,提高增强语音质量。其次,为使在滤除背景噪声的同时尽可能地减少语音失真,提出一种根据信噪比进行自动调节的自适应软掩模作为学习目标,该软掩模同时融入了语音的相位差信息,可改善掩蔽效应,增强语音的可懂度。最后通过设计实验,验证所提算法的优势。
1 语音增强算法
1.1 混合特征提取
梅尔频率与人耳频率呈非线性相关,符合人的听觉机理[8],但梅尔滤波器会随着频率的升高愈发稀疏,从而导致特征丢失[9]。伽马通滤波器组基于耳蜗结构设计,会随着频发升高愈发密集,同时伽马通滤波器能精确模拟人耳的听觉效应,具有极强的鲁棒性[10]。笔者将梅尔域特征和伽马通域特征混合,可避免有效特征的丢失,提高增强语音质量。其中采用指数代替对数对伽马通域特征进行压缩,更符合人耳听觉压缩感知,同时可提高人耳听觉系统的抗干扰能力。分别对提取到的梅尔域特征和伽马通域特征进行去相关处理,将去相关处理后梅尔域特征和伽马通域特征混合并求取其一阶差分导数以获得语音的瞬变信息,最后将初始混合特征与其一阶差分参数混合作为语音增强的混合特征参数。该特征可以反映语音信号的时变特性,进一步改善了神经网络增强语音的性能。图1为该特征参数的提取框图。
混合特征参数具体提取过程如下:
(1) 使语音信号经过预处理后进行快速傅里叶变换,计算得到语音数据的谱线能量。
(2) 将语音数据的每帧谱线能量谱通过可以模拟人耳听觉特性的梅尔滤波器组,得到基于梅尔域的频谱数据,对其进行对数操作和离散余弦变换,得到MFCC特征。
(3) 将每帧谱线能量谱通过基于耳蜗结构设计的伽马通滤波器组,采用幂函数对其进行压缩,使之更符合人耳听觉压缩感知,后进行离散余弦变换,得到NGFCC特征。
(4) 将MFCC特征和NGFCC特征进行拼接得到初始混合特征X,即
X(i,m)=[XMFCC(i,m);XNGFCC(i,m)] ,
(1)
其中,i表示第i帧,m表示特征维度索引,XMFCC(i,m)表示MFCC特征,XNGFCC(i,m)表示NGFCC特征。
(5) 对初始混合特征求取差分导数,得到差分特征ΔX,如下所示:
(2)
差分特征可以捕获语音的瞬变信息和相邻帧语音信息间的联系。
(6) 融合初始混合特征和其一阶差分导数,得到混合特征参数D,即
D(i,m)=[X(i,m);ΔX(i,m)] 。
(3)
最终得到的混合特征参数综合了梅尔域特征和伽马通域特征的特点,既考虑到了人耳的结构特性,又符合人耳基底膜的分频特性,避免了有效特征的丢失,可以更全面地表征语音数据的信息。

图1 混合特征参数提取框图
1.2 构造融合相位差信息的自适应软掩模
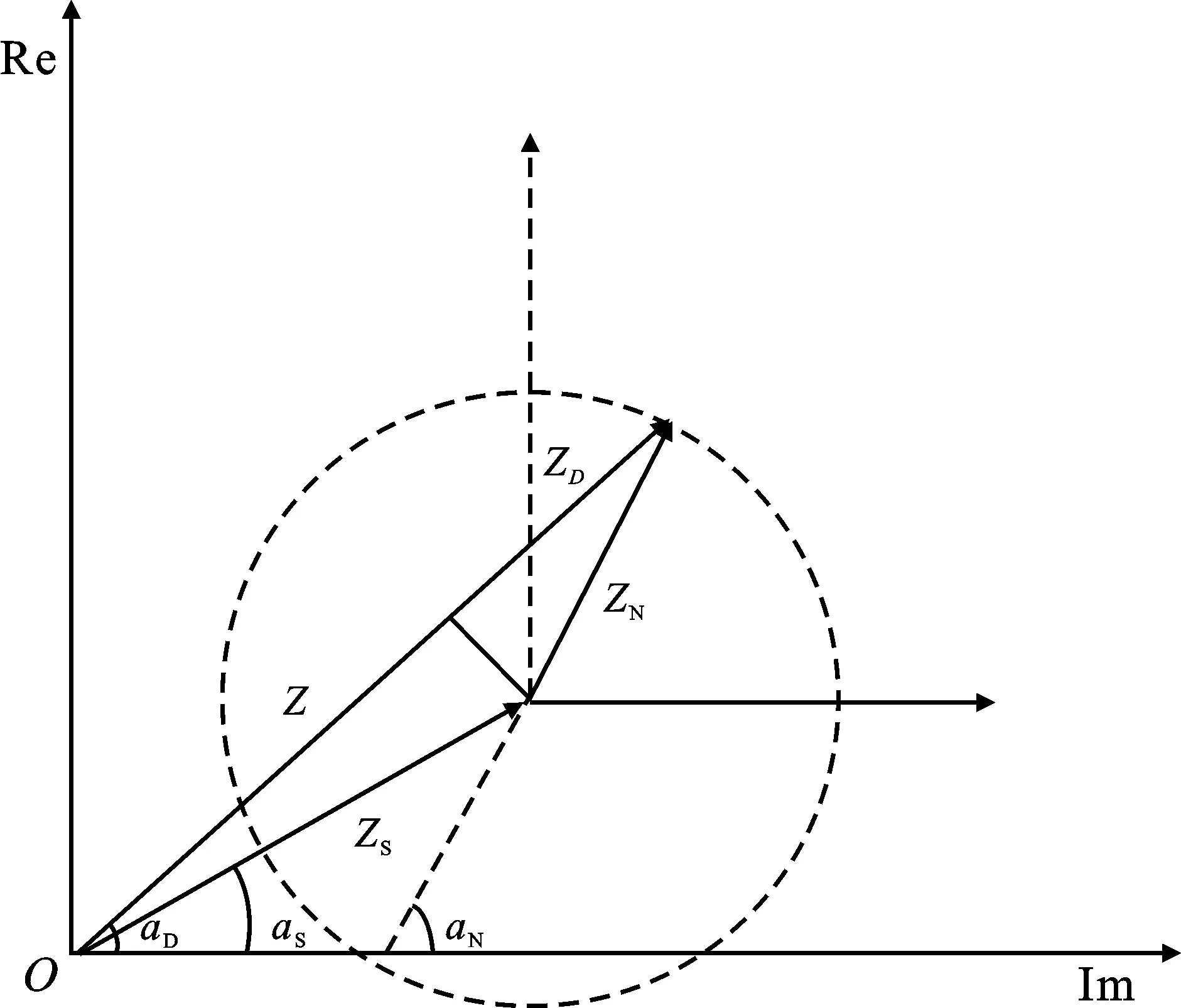
图2 相位几何关系图
在基于深度神经网络的语音增强系统中,学习目标的性能与语音增强的效果有着直接的关系,决定着增强语音的失真程度和残留背景噪声的数目。在众多学习目标中,使用IRM作为学习目标进行语音增强的效果最优,其根据每个时频单元中的纯净语音能量和噪声能量进行取值,可以有效提升增强语音质量[11],滤除背景噪声。但由于在不同信噪比条件下,IRM都是用相同的技术手段滤除噪声,无法根据信噪比信息的不同自动调节,所以经常出现把有用的语音成分消除而保留噪声成分的问题。且在传统的IRM中只考虑到了语音的幅度信息,忽略了影响语音可懂度的相位信息。因此,笔者提出新的自适应软掩模,其可以根据语音信噪比信息的不同进行自动调节,得到相应信噪比条件下的掩蔽值,同时融入语音的相位信息,在提升语音质量的同时提高语音可懂度。
图2为相位的几何关系图[12]。
图2中ZD、ZS、ZN分别表示带噪语音、纯净语音、噪声语音的幅值。αD、αS、αN分别为带噪语音、纯净语音、噪声语音的相位,从图2可知:
(4)
根据先验信噪比ξ和后验信噪比γ的定义式可推出噪声语音和带噪语音的相位差信息:
(5)
根据图中几何关系,可得出
cos(αN-αD)=(ZD-Z)/ZN,
(6)
cosαDS=cos(αD-αS)=Z/ZS。
(7)
因此,可表示纯净语音和带噪语音的相位差信息为
(8)

(9)

(10)
实验证明,当α为0.7时,效果最好,因此选用α取0.7。得到的比率掩模R融合了语音的相位信息,且结合了不同幂值掩模的优势。为保证在滤除背景噪声的同时减小语音失真,所以根据信噪比信息调整比率掩模值,得到最终的自适应软掩模S:

(11)
最终得到的软掩模可以根据信噪比信息的不同自动调节,且融入了语音的相位差信息,可以在滤除背景噪声的同时,保留有用语音成分,保持语音频谱的完整性,从而提高语音的可懂度。
1.3 深度神经网络
基于深度神经网络(Deep Neural Networks,DNN)强大的非线性学习能力,可以有效学习带噪语音特征和学习目标之间的非线性关系。DNN训练过程主要分为两个阶段,即无监督预训练阶段和有监督的反向调优阶段。深度信念网络(Deep Belief Network,DBN)由多层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成,预训练阶段通过对比散度算法(Contrastive Divergence,CD)[13]训练RBM,每一层RBM的输出作为下一层RBM的输入,逐层堆叠预训练好的RBM即可得到DBN网络。在DBN网络后增加输出层,就可以得到初始化的DNN网络结构。反向调优阶段是有监督的学习过程,目的是使经过训练得到的增强语音与对应纯净语音之间的误差达到最小。首先将小批量的语音特征数据输入深度神经网络进行正向传播,通过代价函数计算输入层和对应输出层之间的误差值,选用最小均方误差(Minimum Mean Squared Error,MMSE)作为代价函数。然后利用随机梯度下降算法将误差反向传播,修正每一层网络的权重和偏置矩阵。重复上述步骤,对网络参数进行迭代更新,直至训练完成。将最终得到最优的网络模型用于测试阶段。
1.4 结合混合特征和自适应软掩模的语音增强算法
结合自适应软掩模和混合特征进行语音增强的算法主要包括两部分,即训练阶段和测试阶段。训练阶段首先将纯净语音、噪声、带噪语音通过伽马通滤波器,得到各自的耳蜗表示值,根据1.2节中的方案计算得到自适应软掩模,将得到的自适应软掩模作为学习目标。然后提取带噪语音的混合特征参数,将混合特征参数作为DNN的输入进行训练,通过基于最小均方误差的代价函数计算误差并反向传播修正网络参数,将训练得到的最优网络模型保存。测试阶段,首先提取测试集的混合特征参数输入到已经训练好的模型中,然后通过DNN网络模型生成其特征对应的学习目标,最后根据网络估计的学习目标合成增强语音。图3为结合混合特征和自适应软掩模进行语音增强算法的系统框图。
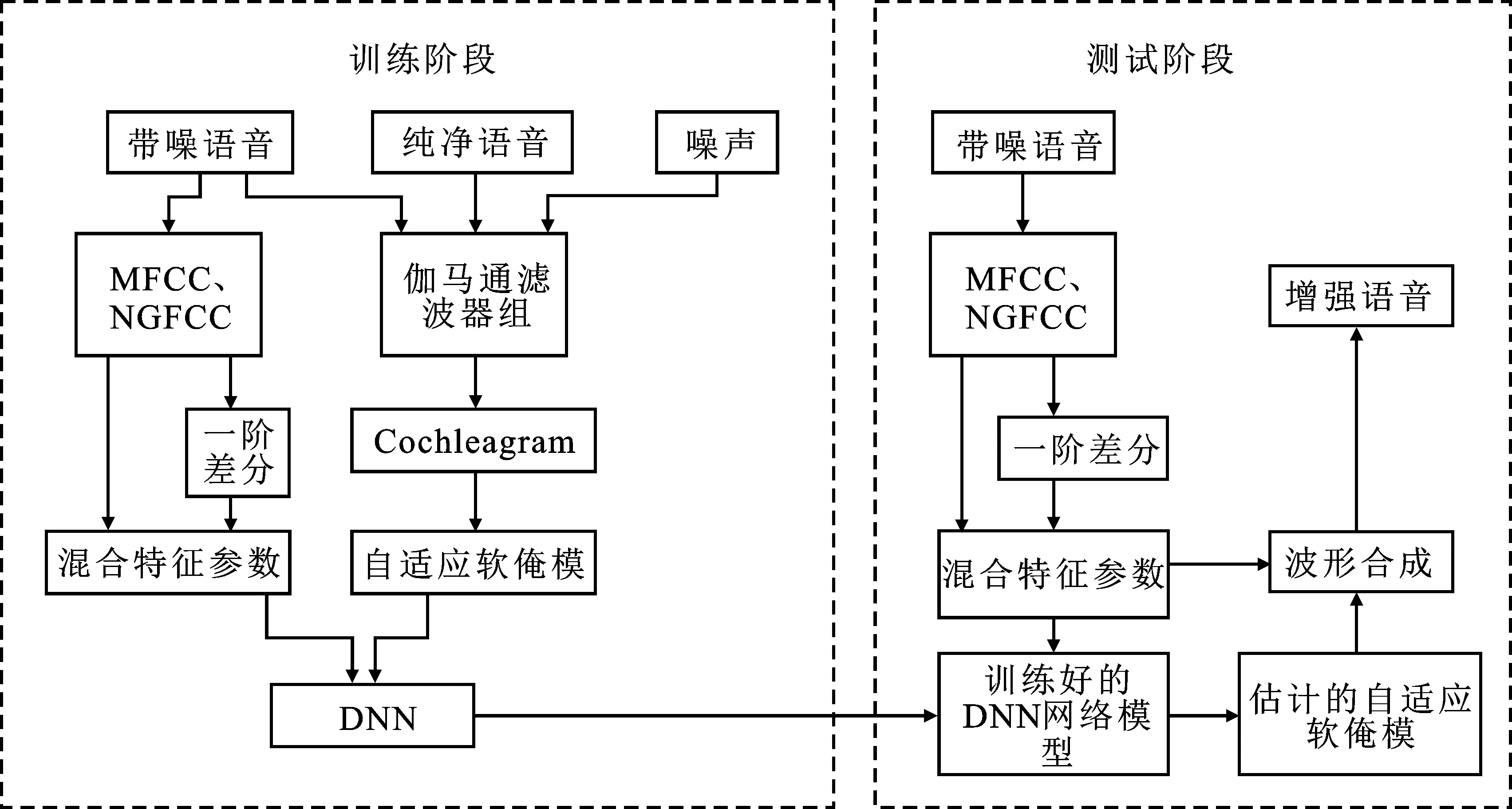
图3 结合混合特征和自适应软掩模的语音增强算法系统框图
2 仿真实验与结果分析
2.1 实验数据
为验证笔者提出算法的有效性,从IEEE语音数据库中选取60条纯净语音,选取NOISEX-92噪声库中的White、pink、Factory噪声,所选纯净语音和噪声样本采样率相等。选取50条纯净语音与3种噪声源的前半部分在分别为-5 dB、0 dB、5 dB信噪比下进行混合,组成450条训练集。将3种噪声源的后半部分与剩余的10条纯净语音在3种信噪比混合,得到90条测试集。
2.2 网络参数
为了确保深度神经网络有能力描述混合特征参数和学习目标之间的复杂关系,设计具有5层结构的神经网络模型,其中包含3个隐层,每个隐层设有1 024 个节点。由于一帧软掩模是64维向量,所以输出层设有64 个节点,用来输出学习目标。首先采用随机初始化的方法设定预训练的网络模型参数,第一个RBM的学习率设置为0.004,其他设置为0.010。隐含层的激活函数采用线性整流函数(Rectified Linear Unit,ReLU),因为ReLU可使网络快速收敛的同时防止梯度饱和与梯度爆炸,输出层的激活函数采用Sigmoid 函数。并用Dropout来防止网络模型过拟合,设置输入层的Dropout值为0,隐含层的Dropout 值为0.2。采用最小均方误差和随机梯度算法反向调优,网络迭代次数为20次,前5次动量系数设置为0.5,随后增长至0.9保持不变。学习速率初始值设置为0.08,随着训练步长自适应线性减小,直至0.001。运用上述参数进行实验,经过反复迭代对网络参数进行更新。
2.3 仿真实验与结果分析
采用主观语音质量评估(Perceptual Evaluation of Speech Quality,PESQ)[14]和短时客观可懂度(Short-Time Objective Intelligibility,STOI)[15]作为语音评价标准。其中PESQ可评估语音的感知质量,可近似客观表示主观测听打分(Mean Opinion Score,MOS),PESQ 评分范围为-0.5~4.5,分值越高,表示增强语音质量越高。STOI通过计算纯净语音和增强语音的短时包络相关性来反映语音可懂度,其取值范围是0~1,分值越高,代表增强语音的可懂度越高。选取PESQ和STOI两个指标从增强语音质量和可懂度两个方面来验证联合特征和软掩模的有效性,设计3组实验来进行讨论:
实验1 采用MFCC特征和IRM来训练神经网络。
实验2 采用MFCC和NGFCC的混合特征与IRM来训练神经网络。
实验3 采用MFCC和 NGFCC的混合特征与自适应软掩模来训练神经网络。
采取上述3组实验分别在 white、factory 和 pink噪声下对测试集语音进行仿真,实验数据如表1和表2所示。

表1 不同实验下的PESQ对比
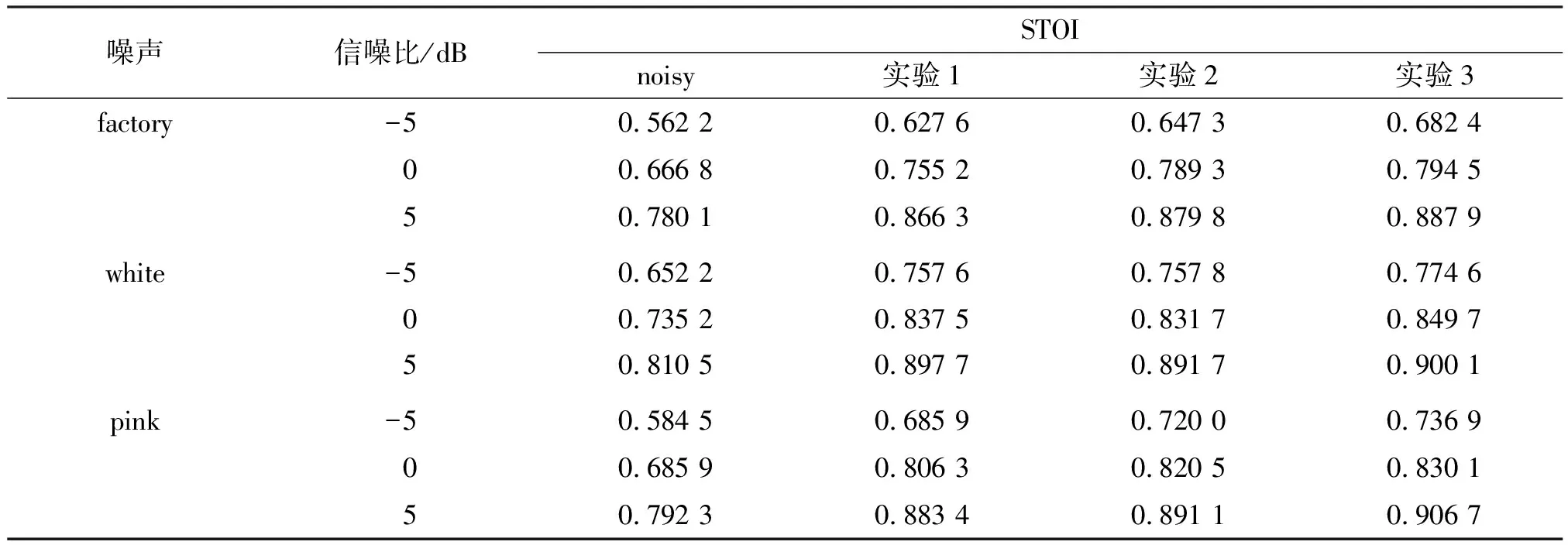
表2 不同实验下的STOI对比
分析以上结果:
(1)对比实验1和实验2的结果可知,采用特征为MFCC和NGFCC的混合特征时的增强性能优于单特征。在3种噪声下,增强语音的PESQ值平均提升了0.140,STOI平均提高了0.012,证明了笔者提出的混合特征对整个语音增强系统性能的改善有着重要的作用。
(2)对比实验2和实验3的结果可知,采用自适应软掩模作为学习目标时,PESQ平均提升了0.200,STOI平均提升了0.015。实验证明了自适应软掩模作为学习目标的优越性,在提升语音质量的同时可增强语音可懂度。
(3)对比实验1和实验3的结果可知,当采用自适应软掩模和混合特征进行语音增强时,PESQ平均提升了0.340,STOI平均提升了0.027,验证了笔者所提的基于混合特征和自适应软掩模的语音增强算法的有效性。从-5 dB到5 dB,增强语音STOI分别平均提升了0.040、0.025、0.016,PESQ分别平均提升了 0.380、0.340、0.290。随着信噪比的降低,提升值逐渐升高。由此证明了笔者提出的算法在低信噪比条件下处理带噪语音的优势。
为了直观简捷地说明混合特征和自适应软掩模进行语音增强算法的优势,给出了在上述3种实验条件下,信噪比为0 dB,以white为背景噪声的语音增强语谱图,如图4所示。
观察图4发现,基于单特征MFCC得到的增强语音存在残留噪声,混合特征得到的增强语音在去除噪声方面有所改善,但是存在部分语音丢失的现象。而使用混合特征和自适应软掩模进行语音增强时可以明显去除噪声,而且可以较为完整的保存语音频谱的结构信息。
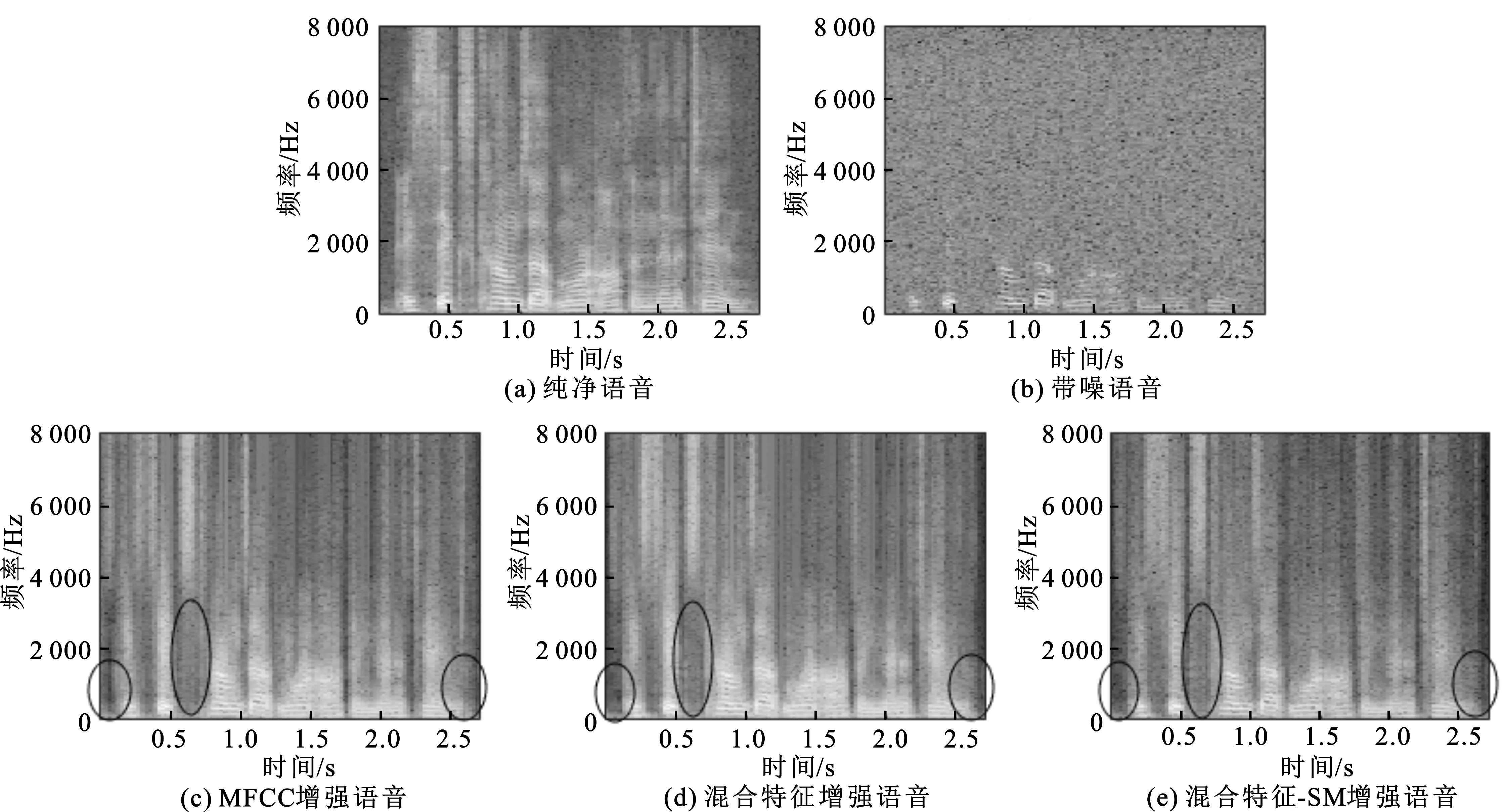
图4 语谱图
3 结束语
笔者提出结合自适应软掩和混合特征的语音增强算法。首先,采用更符合人耳听觉感知特性的非线性幂函数提取新伽马通频率倒谱系数,将其与MFCC特征混合以获得更全面的语音结构信息;其次,构建了可以根据信噪比信息自动调节的自适应软掩模作为学习目标,并在其中融入了相位差信息,该学习目标有利于保持完整的语音频谱特性,减小语音失真。实验结果证明,笔者提出的算法在不同噪声、不同信噪比条件下,能够有效滤除背景噪声,提升主观语音增强质量和短时客观可懂度。
