网络用户数据素养、隐私关注与隐私信息披露意向
2022-05-26单孟丽付文婧张思光
单孟丽,付文婧,张思光
(1.中北大学经济与管理学院,太原 030051;2.拉夫堡大学体育、训练与健康科学学院,英国莱斯特 LE11 3TU;3.中国科学院科技战略咨询研究院,北京 100190)
中国互联网络信息中心(http://www.cnnic.net.cn/)发布的《第49次中国互联网络发展状况统计报告》显示,截至2021年12月,我国网络用户规模达10.32亿,互联网普及率达73.0%.大数据时代,人们在使用各种智能移动服务终端的同时,生产和创造了海量数据,成为网络数据的真实产出者;谷歌、阿里巴巴、百度、腾讯等数据服务商,通过智能终端收集和处理用户数据,对其进行分析开发后,将产品和服务反向输入给智能终端用户.近年来,网络用户隐私数据被非法搜集和被第三方窃取的事件频发,从2018年Facebook安全漏洞受到黑客攻击,近2900万用户隐私信息被泄露,到2021年7月“滴滴出行”严重违法违规收集使用个人信息,25款软件被网络安全审查办公室查处下架,数据隐私话题成为公众关注的焦点.
我国于2016年通过了《中华人民共和国网络安全法》,旨在约束数据收集方的行为,以保护网络用户数据隐私的安全.随着人们越来越倾向用隐私信息等换取服务和利益,前期制定的法律不一定适用于当前的数据应用情境,数据隐私悖论问题日益凸显[1],不论是平台服务商希望实现利益最大化,还是网络用户必须通过主动披露隐私信息方能享受服务,数据共享成为事实,甚至会改变人们的观念和相关行为[2].
基于此,本文使用问卷调查的方式,对网络用户数据素养水平进行评估,并探究其与网络用户隐私关注和隐私信息披露意向之间的关系,以期为有关部门推进网络隐私政策的调整提供借鉴.
1 研究假设与研究模型
1.1 变量解释和研究假设
1.1.1 数据素养与隐私关注之间的关系假设
隐私关注是网络用户对自己隐私信息的收集、控制、使用的关注[2],无法直接测量.Malhotra等[3-4]根据社会契约理论开发的IUIPC量表,依据收集、控制和意识3个维度测量公众感知个人隐私信息的风险和收益.本研究设定隐私关注是网民面对具体被泄露隐私的场景时的主观想法,利用收集、控制和意识3个维度考量网络用户对隐私信息的关注程度.
对于隐私关注的提高,个体会表现出对隐私披露意愿的降低;同时,当无法控制被收集的个人隐私信息的范围、类型、使用范围和后果时,隐私关注程度大幅度增加[5].黄如花和李白杨[6]认为,数据素养应包含数据意识、数据伦理和数据能力3个方面.结合他们对数据素养的定义,本研究将数据素养定义为网络操作技能、网络经验和是否能够避免部分隐私泄露的能力.据此提出假设:
H1:数据素养能负向影响隐私关注.
1.1.2 数据素养、隐私关注与披露意向之间关系假设
影响隐私关注的因素不会直接影响披露行为,而是会通过直接影响人们的披露意向,间接影响到人们接下来采取何种行为[7],形成影响因素-披露意向-披露行为路径.
为衡量隐私关注以及前因后果,Smith等[8]开发了APCO模型,即“影响因素-隐私关注-行为后果”路径.在该路径中,Dienlin和Trepte[9]认为,行为意向可以是积极或消极两种相反的态度,而隐私关注对公众披露意向的影响大都是消极方面.
故设定隐私披露意向为负向指标,并提出如下假设:
H2:数据素养能正向影响披露意向;
H3:隐私关注能负向影响披露意向;
H4:隐私关注在数据素养影响披露意向中起到中介作用.
1.1.3 主路径与隐私计算成本之间作用的假设
隐私计算理论把感知收益与隐私忧虑所形成的成本叫作隐私计算成本[10].感知收益指用户在使用过程中得到的回报;隐私忧虑是指在披露隐私时,对第三方滥用信息造成的损失和风险[11],二者是衡量被调查者对隐私关注程度的重要因素.Hann等[12]发现,网络用户在进行潜在风险和利益博弈时,会影响到他们对隐私信息的自我表述意愿,并且这一过程中会受到大数据个性化服务的影响.
林钻辉[13]在对顾客移动购物意向研究中证明,顾客隐私顾虑越大,隐私关注程度就越高.吴丁娟和朱侯[14]发现,被调查者的感知风险对隐私关注产生的负面影响程度非常大.而作为对冲面的感知收益,则可降低人们对自我隐私的关注程度,从而增加自我隐私披露的概率[15].故当人们经验丰富、网络技术能力较强时,隐私泄露的风险较低,从而减少担忧程度,并能从中得到更大化的收益.据此,提出以下假设:
H5:隐私忧虑在数据素养影响隐私关注中起正向调节作用;
H6:感知收益在数据素养影响隐私关注中起负向调节作用;
H7:隐私忧虑在数据素养影响披露意向中起调节作用;
H8:感知收益在数据素养影响披露意向中起调节作用.
补偿模式(人们认为某种行为会获得利益的现象)发生时,对个人信息的披露意愿增加[16].人们的披露意愿受到多种因素影响,但大部分研究者都认为,当人们得到个性化回报时,更愿意提供个人信息,这使得很多企业更倾向于个性化定制[17-18].已有研究表明,隐私计算成本在隐私关注影响隐私行为反应(自我披露)路径中既存在相关关系,又存在调节关系[19].据此,提出以下假设:
H9:隐私忧虑在隐私关注影响披露意向中起调节作用;
H10:感知收益在隐私关注影响披露意向中起调节作用.
1.2 研究模型
在上述研究假设的基础上,同时选取了性别、年龄、学历等人口统计学基本信息作为控制变量,研究数据素养、隐私关注与网络用户隐私信息披露意向之间的关系.借鉴APCO模型和IUIPC量表,提出本文的研究模型(图1).
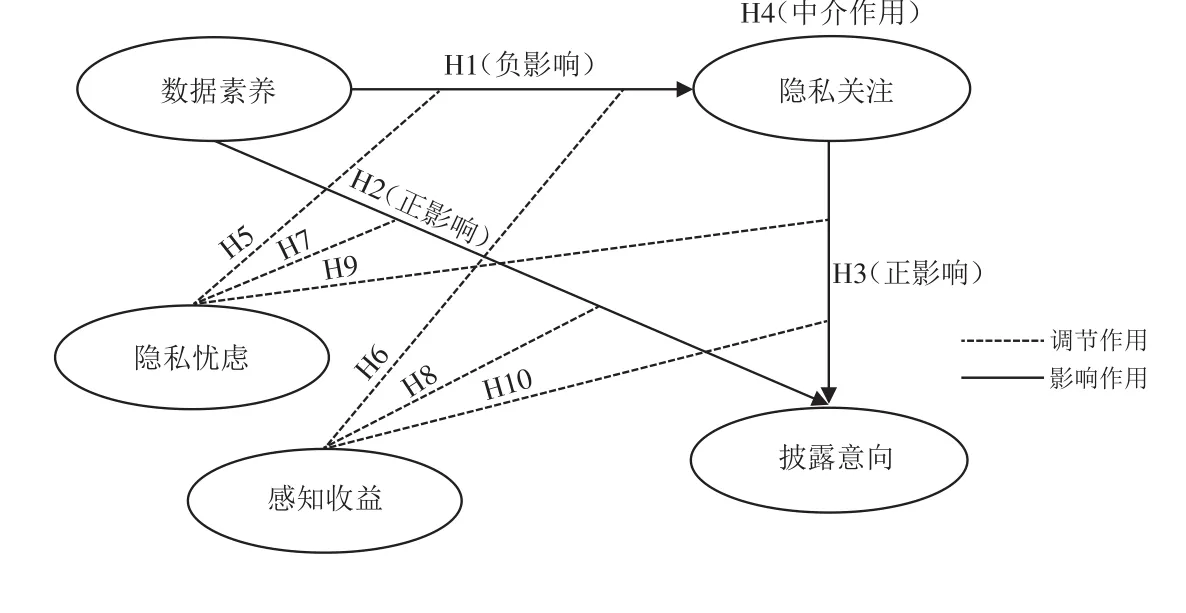
图1 数据素养-隐私关注-披露意向研究模型Fig.1 Data literacy-privacy concerns-disclosure intent research model
2 问卷设计与数据收集
2.1 问卷设计
在参考前人研究的成熟量表基础上,设计了研究变量测量问项,指标来源于文献[20],最终题项设计如表1.

表1 研究变量测量问项设计Tab.1 Question design of study variable measurement
2.2 数据收集
采取线上线下相结合的方式发放问卷,依据量表收集网络用户对网络隐私数据的影响因素,如数据素养、认知能力(隐私关注)和行为意向(隐私忧虑、感知风险、披露意向)等数据.通过使用SPSS软件分析问卷的信效度后,剔除影响问卷信效度的题目,形成正式的调查问卷.正式问卷采用问卷星网络平台进行线上发放,回收期为10 d.其中有效问卷数量1524份,合格率82.20%.筛选方式为设置验证题项、设置隐藏题项、接纳填写时间在240~6000 s的问卷(预调查填写最低时长为240 s).
3 分析与结果
3.1 问卷信效度检验
采取内部一致性信度,利用克朗巴赫系数进行测量,系数大于0.6表示内部一致性较好.根据表2所示,隐私关注、隐私忧虑、感知收益和数据素养的克朗巴赫系数均大于0.6,说明相关题目之间具有较好的内部一致性,信度较高.

表2 各变量的克朗巴赫系数Tab.2 Kronbach coefficient for each variable
问卷的效度检验是指测量项与变量之间的对应关系,可以通过探索性因子分析和验证性因子分析进行测量[21],结果统计见表3.结果显示所有变量均通过KMO系数检验(KMO系数需大于0.5)和球形检验(P值需小于0.01),测量项之间显著相关,问卷效度良好.感知收益的KMO系数虽较小,但仍然通过显著性检验,且特征值大于1,故可取.图2各独立量表碎石图显示出每个独立量表都能提取唯一一个因子(隐私关注可提取出3个因子是因为隐私关注下设3个二级指标),问卷各自设置的变量之间设计合理,表明各个潜变量之间具有良好的收敛效度和区别效度,该问卷具有良好的建构效度.

表3 各变量的KMO系数及球形显著检验Tab.3 KMO coefficients and spherical significant tests of each variable

图2 独立量表碎石图Fig.2 Scree polt of independent measure
3.2 问卷代表性测量
采用Q-Q图检验各独立量表数据的正态分布,具体结果如图3.由图3可知,实际分布和预测分布基本吻合,说明数据满足正态分布,问卷获取的数据具有一定的代表性.均衡性测量涉及被调查者对问卷的难易程度和问卷长短的测量[22],问卷调查结果中没有出现极端态度答案,可认定问卷能够较好地被参与者理解和接受.
图3 独立量表的预期常规Q-Q图Fig.3 Separate scale Q-Q graphs
3.3 描述性统计分析
在样本人群中,男女比例为2.21∶2.99,分布较为均匀;年龄在40岁以下的占比约86.94%,被调查群体比较年轻;在学历方面,大专及以上人群占比91.54%,教育程度比较高;职业分布较为广泛,以“网龄在3年以上”(97.9%)、“几乎每天都在上网”(97.51%)、“主要使用移动设备”(61.68%)为特点的人群占比较大.故本研究的调查人群具有以下特点:上网经验丰富、经常使用移动电子设备、网络用户以青壮年为主,这表明大部分调查对象有着较长的网龄,可以很好地理解情境,合理填写问卷.
由表4可知,在各独立量表中,公众对隐私的关注程度和对隐私所带来的风险比较在意,但数据素养较弱.在隐私能带给网民的风险和收益中,人们普遍更加忧虑于隐私所带来的风险.

表4 描述统计量表Tab.4 Table of descriptives
在回收问卷中,有1274人(83.6%)认为隐私是一种不被打扰的权利,但这其中有840人(96.6%)在面对所需要的商品和服务时会提供自己的个人信息,这说明公众认为的对个人隐私信息的保护程度和实际的行为操作有差别,证实自我认为的隐私素养和实际的披露意向具有一定的差异.由图4可知,人们对自己的名字、性别等基本信息不是特别敏感,但对自己的财务信息、健康信息、身份信息等信息非常敏感.原因在于性别、年龄等信息比较容易被识别,而剩下类别的信息在一定程度上会受到隐私歧视和特别对待,是公众认为不可以轻易披露的信息.而在这其中仍有44.51%的人却因为商品和服务主动披露自己的个人隐私.这在一定程度上解释了“隐私悖论”的存在,说明人们对隐私的敏感程度和实际披露行为比较不符.
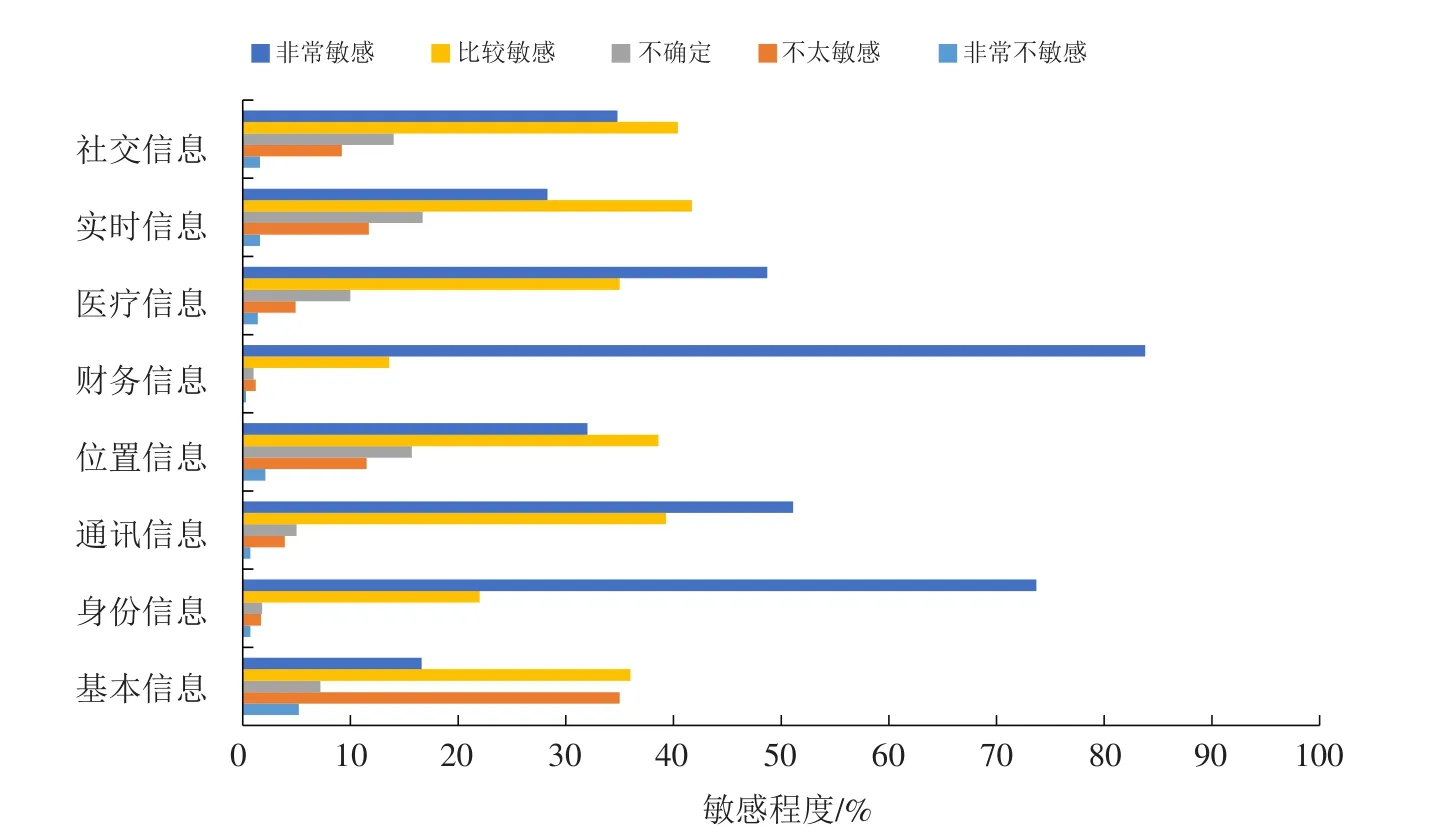
图4 公众对个人信息的敏感程度Fig.4 Sensitivity of the public to personal information
3.4 相关关系检验
相关性分析用来检验两个变量之间的相互关系,衡量标准就是相关系数.相关系数主要分为Pearson相关系数和Spearman相关系数两种.由于各量表数据呈现近似正态分布,所以在问卷中选择前者进行相关关系检验[23].表5为各变量之间的相关性矩阵,由表可知,隐私关注与隐私忧虑之间呈现正向相关关系,与数据素养和感知收益之间呈现负相关关系,披露意向和隐私关注、数据素养之间呈现正向相关关系.说明网络用户数据素养越低、对隐私越关注,越会减少个人隐私数据的披露.相关关系是模型存在调节关系和中介关系的基础,表5显示,与隐私计算成本相关的两个因素——数据素养和隐私关注,与披露意向之间两两相关,故模型符合存在被调节和被中介条件,主路径中3个因素之间存在两两相关关系.

表5 各变量间相关关系Tab.5 Correlations between variables
3.5 隐私计算成本的调节效应
调节变量可能导致相关关系的两个指标发生同方向的加强或减弱影响,也可能导致反方向的影响.利用SPSS做调节效应分析,通过隐私关注和隐私计算成本的调节作用分别设置调节模型.
1)数据素养-披露意向模型

式中:BI为因变量;DL为自变量;PB和PW为调节变量;a、b、c为系数.依式(1)和式(2)计算,结果见表6.在路径“数据素养-披露意向”中,感知收益和隐私忧虑与数据素养的交互项均不显著,二者都不能起到调节作用.

表6 数据素养-披露意向调节模型Tab.6 Adjustment model of data literacy-disclosure intention
2)数据素养-隐私关注模型
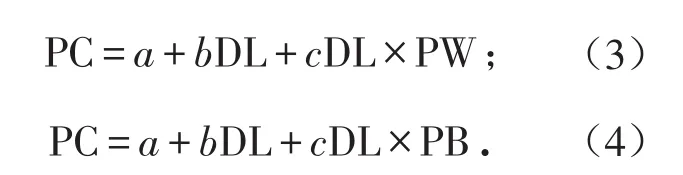
式中:PC为因变量,DL为自变量,PB和PW为调节变量;a、b、c为系数.依式(3)和式(4)计算结果如表7.自变量数据素养与调节变量隐私忧虑的交互项显著,说明存在调节效应.当加入调节变量隐私忧虑时,数据素养影响隐私关注系数减小,说明隐私忧虑能减弱数据素养影响隐私关注.自变量数据素养与调节变量感知收益的交互项不显著,感知收益不能调节数据素养影响隐私关注.
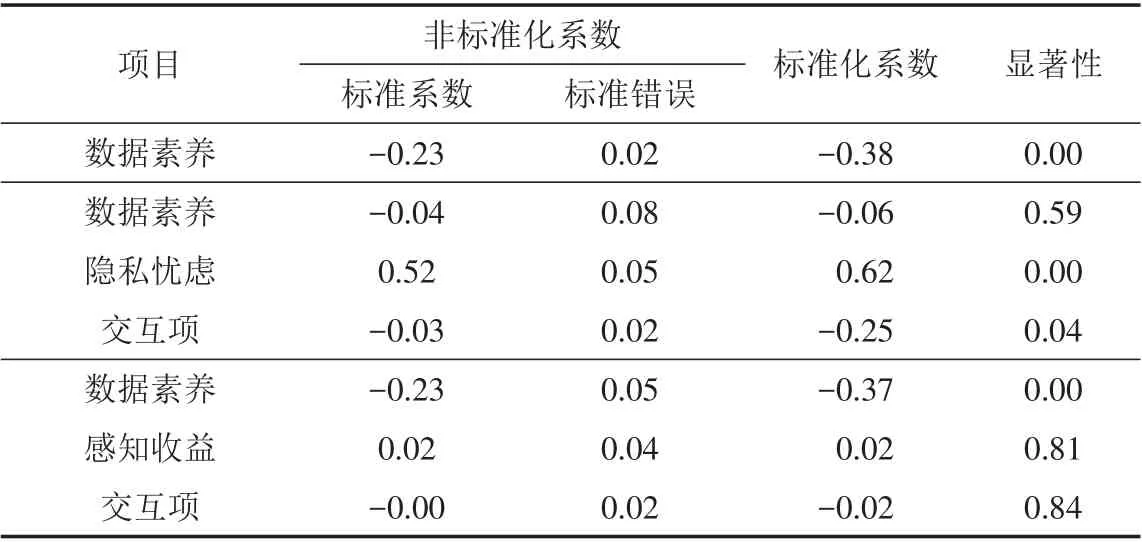
表7 数据素养-隐私关注调节模型Tab.7 Adjustment model of data literacy-privacy concerns
3)隐私关注-披露意向模型
式中:BI是因变量,PC为自变量,PB和PW为调节变量;a、b、c为系数.计算结果见表8,隐私忧虑作为调节变量影响路径“隐私关注-披露意向”时不显著;感知收益作为调节变量时,路径影响由正向变为负向影响,说明感知收益调节路径时会改变隐私关注影响,披露意向的方向.
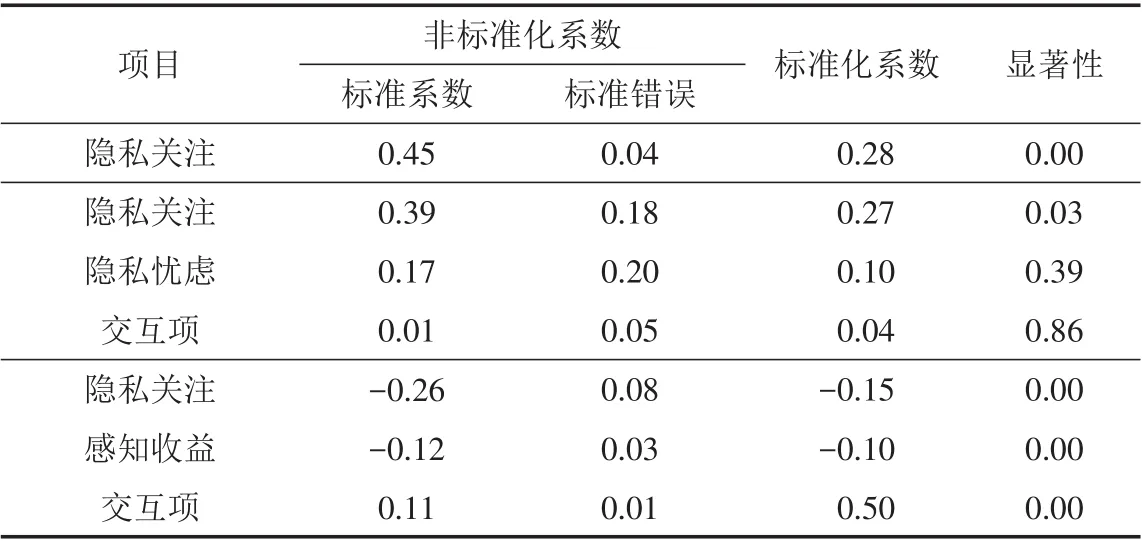
表8 隐私关注-披露意向调节模型Tab.8 Adjustment model of privacy concerns-disclosure intention
感知收益和隐私忧虑可以作为调节变量影响“数据素养-隐私关注”和“隐私关注-披露意向”路径.这说明当风险大于回报时,可能会导致隐私关注呈现较高水平,人们倾向于保护隐私信息;当风险低于回报时,对隐私关注度降低,更倾向于披露隐私信息.
3.6 隐私关注的中介模型
中介效应指的是在一条模拟路径中,在中介变量的影响下,自变量对因变量的直接影响会发生改变.由表9可知,隐私关注在数据素养影响披露意向中起到完全中介作用,说明数据素养作为影响因素在影响网民隐私关注和披露后果的路径中,符合APCO模型.

表9 中介效应Tab.9 Mediation effects
中介效应检验利用booststrap法检验,预测值置信区间不包含“0”表明存在中介效应,可以弥补逐步回归法带来的违反分布假设的问题,使结果更为可靠,抽取次数大于1000次是中介效果检验中统计效力最好的方法之一[24].运用SPSS做中介效应检验,由表10可看出,中介变量影响模型路径检验置信区间不含“0”,检验合格.

表10 中介效应检验Tab.10 Mediation effect test
在隐私计算成本影响的两条路径中,“隐私关注-披露意向”路径受到的影响更强烈,但是其作为调节变量在“数据素养-隐私关注”路径的关系也不可忽视.同时,隐私忧虑的调节效应优于感知收益的调节效应,说明人们更加在意隐私信息所带来的风险.隐私关注作为数据素养影响人们披露隐私信息的完全中介变量,其中介效应可以忽略人们的网络技能对披露意向的影响,说明人们对隐私的关注程度只能在一定程度上取决于其网络技术能力,最终模型如图5.

图5 修正模型Fig.5 Correction model
4 结论与建议
1)本研究主要基于研究对象本身报告的数据素养,数据素养越高,即人们的网络掌控能力更强时,就可以更自主地选择如何保护或披露自己的信息,进而降低对后续保护行为的意愿,减少对隐私去向的忧虑,也会直接影响到其行为动机,披露意向就是其中之一.
2)数据素养作为前因,通过隐私关注的完全中介影响人们的披露意向,模型符合APCO路径.作为整条路径的中介变量,隐私关注在面对人们报告的数据素养上呈现减弱趋势,并在同方向上影响自我披露隐私的意愿.在网络视域下是否上传隐私信息更取决于社交媒体保护信息的能力和隐私政策中的保证和契约精神,并最终产生自我表述意愿和行为.当网络用户拥有更多技能时,就会相对降低对隐私信息的关注程度,并重新评估隐私信息带来的收益和后果,最终正向影响人们的信息分享意愿.
3)在隐私计算成本所造成的中介影响和调节影响中,相比较隐私信息带来的收益,隐私信息泄露所带来的后果更受关注,隐私忧虑能更好地引导自我信息披露.对于隐私计算成本如何调节中介路径“数据素养-隐私关注-披露意向”,研究发现二者对隐私关注导致的披露意向反应更强烈,故认为人们对隐私信息泄露导致的后果更在意,而不是数据本身.在这一过程中,APCO模型中除了需要隐私关注作为中介变量,还可以通过增加其他自我评价机制进行扩充,可以使得隐私表露机制更加完整和具体.
数据素养的提升会使得网络用户在保护自己的隐私信息时更加游刃有余.隐私悖论是网络用户在网络视域下忽视自我隐私信息的主要诱因之一,简化网络隐私政策有助于人们明了自己隐私信息的去向,能够减少对隐私关注的忧虑和担心.因此,数据服务商须及时披露网络用户隐私信息的使用方向和保管程序,降低用户对隐私信息泄露的担忧以缓解隐私悖论现象,应对用户日益增长的隐私保护意识.
