基于空间域注意力机制的车间人员检测方法
2022-05-25李成严马金涛赵帅
李成严 马金涛 赵帅






摘要:车间人员检测是指使用目标检测技术对工厂生产车间内相应区域进行人员检测,保障生产车间内人员生命健康安全。车间内人员检测存在图像模糊、检测效率低、实时性要求高等问题,将改进的暗通道优先处理策略用于图像增强、用空间域注意力机制相结合的SSD(Single Shot MultiBox Detector)网络提高检测效率,同时保障实时性要求,并在本文测试集及VOC2012数据集上进行验证,结果显示出较好的定位效果及检测率。
关键词:车间人员检测;SSDSN网络;空间注意力机制;暗通道优先策略;区域划分
DOI:10.15938/j.jhust.2022.02.012
中图分类号: TP399
文献标志码: A
文章编号: 1007-2683(2022)02-0092-07
Workshop Staff Detection Method Based on Spatial
Domain Attention Mechanism
LI Cheng-yan,MA Jin-tao,ZHAO Shuai
(School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080, China)
Abstract:Workshop staff detection is to use the target detection technology to detect the staff in the corresponding area of the factory production workshop, to ensue the life, health and safety of the staff in the production workshop. In this paper, the improved dark channel priority processing strategy is applied to image enhancement and SSD (single shot multibox detector) which combines spatial attention mechanism detector (detector) network improves the detection efficiency while ensuring the real-time requirements. It is verified on the test set and VOC data set in this paper, and the results show that the positioning effect and detection rate are better.
Keywords:workshop staff detection; SSDSN network; spatial domain attention mechanism; dark channel priority strategy; regional division
0引言
车间人员安全是工业生产活动中的重要问题。传统的安全监测机制与系统功能的不足,导致频繁发生人身安全事故。车间内人员安全问题需要迫切得到解决。目前,通常采取视频监控的方式监控车间内人员安全情况,由人工进行实时查看,但人工监
测费时、费力、反应慢、成本高、收益低。随着计算机技术的发展,传统行业也逐渐走向智能化。车间人员检测是基于智能信息处理的目标检测,具有实时性、准确性、低成本的优点,采用智能监测的方法实时检测监控视频,一旦发生意外立即报警,采取相应措施,避免事故的发生。因此,车间人员检测具有重要研究价值。
目标检测[19-20]已经从传统的目标检测过渡到基于深度学习的目标检测。传统的目标检测采用人工特征提取方法获得目标的特征描述,并输入到分类器中学习分类规则,如VJ检测器[1]、HOG检测器[2]、DPM[3]等,这些方法时间复杂度高,窗口冗余,手工设计的特征鲁棒性差。随着深度学习概念的提出[4],目标检测可以从原始数据中獲取特征信息,避免了传统目标检测中繁琐的特征工程步骤,如文[5-9]等。
基于深度学习的目标检测被广泛应用,文[10]将目标检测用于非法流动摊贩检测,但其对图像像素要求较高,像素较低时检测效果不佳。文[11]提出了一种车辆目标检测方法,对图像特征进行规格化和并行的回归计算,检测效果较好,但检测速度低,影响实时性。文[12]提出结合语义信息的行人检测方法,图像像素较低时也可识别,但准确率、召回率较低。
车间人员检测包括从车间的监控视频中检测和定位人员两部分。检测速度应满足实时性要求;烟雾、粉尘、光照等因素导致检测图像质量较差,影响检测率与准确率,检测准确率有待提高;由于车间内区域复杂,需对车间内区域进行划分,并判断车间人员所在区域。
SSD(single shotMultiBox detector)是单阶段的目标检测网络,检测速度较快,本文将SSD作为车间人员检测的基础网络。在图像质量较差时,暗通道优先的图像处理方法效果显著,如文[13]使用暗通道进行图像去雾。为提高目标检测的定位能力及准确性,文[14]利用注意力机制提高检测精度。文[15]使用注意力机制来提高目标的定位能力。注意力机制关注图像中辅助判断的信息,忽略不相关的信息[16],可从大量信息中筛选出高价值信息,极大地提高信息处理的效率与准确性,提升目标检测定位能力。
本文提出一种基于空间域注意力机制的车间人员检测方法。该方法将改进的暗通道优先处理策略用于图像增强;用与空间域注意力机制[17]相结合的SSD网络提高检测精度,提出SSDSN(SSD Spatial attention mechanism network)车间人员检测网络;使用区域划分方法解决车间区域复杂问题。
1车间人员检测系统结构
1.1区域划分与判别
将整个生产作业区域划分为安全区、报警区和危险区三类。安全区是指车间内车间人员正常工作的区域,报警区是有一定危险,应提示注意的区域,危险区是指可能对车间人员造成伤害的区域。
通过车间内监控摄像头获取该区域实际布局图,并对此区域进行划分。图1为某运输皮带车间实例,其中(a)为车间实际布局,包括中间的行人通廊,两侧的护栏及两条运输皮带;(b)为区域划分图,即呈现在显示屏中(a)与(c)的叠加效果。(c)为设定的背景图,图1(c)中间黑色区域为安全区,对应(b)中的行人通廊,(c)中的白色区域为报警区,对应(b)护栏区域,(c)中的灰色区域为危险区,对应(b)运输皮带区域。
通过目标检测网络输出车间人员位置中心点坐标,与各区域边界坐标对比,判断车间人员位置,若处于报警区内则通过声光报警提醒,若车处于危险区则控制设备停机,以保障车间人员安全。
1.2改进的暗通道优先图像降噪策略
受烟雾、粉尘、光照等因素影响,车间图像质量较差,导致检测率与准确率不高。
暗通道优先图像处理策略将暗通道有关结论当作先验条件使用,在图像增强和图像修复方面存在一定优势。
暗通道优先图像处理策略公式为
其中:J(x)为降噪后的图片;B为车间背景光;t(x)
为x处的透射率;t为一个阈值,当投射图的值较小时,会导致J值偏大,使图像向白场过度,因此当投射图的值小于t时,令其等于t,令t=0.1,B通过暗通道图从原图中获得,在暗通道图中按照亮度大小取最亮的前0.1%像素,在原图中找对应位置上的最高亮度的点的值,以此点的色素值为B值。
根据暗通道理论建立车间光照成像模型:
由于车间内光照原因,导致图像亮度差异较大,式(1)中B值是原始像素中的某一个点的像素,如果取一個点,各通道的B值很有可能全部很接近255,这会造成处理后的图像偏色和出现大量色斑。
为避免上述问题,对车间内背景光重新计算,取暗通道图像各通道灰度值最大的前0.1%的像素点的灰度平均值作为B值。
根据式(6)和式(7),可以得到最后的透射率为
式(10)中X是阈值,根据噪声强度对X进行取值,用于调节B值。若噪声较大,可适当增大X的值,通过调整X值,可获得一个较好降噪效果,改进的暗通道优先处理策略效果如图2所示。其中(a)为原始图,(b)为暗通道优先图像处理策略处理的降噪图,(c)为改进的暗通道优先图像处理策略处理的降噪图。
1.3系统框架
结合空间注意力机制改进SSD目标检测网络,为保障对车间人员的检测能力,用监控图片数据作为训练集,并对训练集进行降噪处理、人工标注,通过训练得到网络模型。为保障检测实时性,采用RTSP获取实时视频流。为保障检测的准确性,将帧图片降噪后,再传入检测网络中检测,若检测到有人员,则通过矩形框框出人员轮廓,并通过矩形框边界估算人员位置坐标,通过检测算法返回车间人员位置坐标与划分的区域坐标比较,判断车间人员所处区域,通过警报提醒车间人员及监控人员,并输出相应的报警、危险状态标志。该状态标志采用串口通讯的方式发送信息报文至报警控制器,由报警控制器将信息报文解析后发送相应控制指令至PLC(programmable logic controller)控制系统。现场PLC控制系统则依据控制指令分别进行声光报警或停机操作,确保车间人员安全。具体框架如图3所示。
2车间人员检测方法
2.1基于空间域注意力机制的SSDSN网络
空间域注意力机制是将原始图像中的空间信息变换到另一个空间中并保留关键信息的一种方法,将图像中的空间域信息进行空间变换,把关键的信息提取出来,找出图像信息中被关注的区域,同时又具有平移不变性、旋转不变性及缩放不变性等强大的性能。
本文将空间域注意力机制与SSD算法结合,提高人员检测的准确率与定位能力。在SSDSN车间人员网络中,空间网络变换模块使分类的准确性得到提升。
SSDSN网络在SSD基础网络的图像输入层即Cov1_2之后引入空间域注意力机制。此模块共有两个作用,其一为数据增强,将网络的注意力放在图像中的目标区域,并进行缩放操作,增强后的图像进入下层网络进行特征提取;其二为根据输入的特征图回归空间转换的参数,使用这个参数去生成一个采样的网格,根据这个网格及输入的特征图得到经过空间变换的特征图,作为SSDSN网络用于检测的特征图,加上Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2共提取了7个特征图用于检测,空间转换模块增强数据、采用卷积对不同的特征图进行提取检测结果、将不同特征图获得的预测框结合起来、经过非极大值抑制方法抑制掉一部分重叠或者不正确的框,生成最终的框集合,即检测结果。SSDSN网络结构如上图4所示。
2.2SSDSn网络特征提取
SSDSN利用不同尺度、不同层级的特征图进行人员目标框检测,各层特征信息由上层特征信息决定,每层特征图只负责对应尺度的检测,因此,对于SSDSN每层特征足够复杂才能更精确地检测目标。特征图应具有足够的分辨率以表达细节特征,足够深的网络提取得到更抽象特征,低层特征对应于细节信息,高层特征对应于抽象的语义信息。空间域注意力机制将网络的注意力放在车间人员上。由于空间注意力机制对图像所有的通道信息进行统一处理,在图像输入层之后加入空间域注意力机制可以更充分提取图像中的信息,每一个卷积核产生相应通道信息,含有的信息量及重要程度得到提升。
SSDSN网络中低层网络结合VGG16的前4层及空间域注意力机制,其中空间域注意力机制中的定位网络用来回归变换参数θ,生成仿射变换系数,输入是C×H×W维的图像,输出是一个空间变换系数。参数θ的大小根据要学习的变换类型而定,本文中主要用到的变换类型为缩放,则是一个4维向量,然后经过一系列全连接或卷积,再加一个回归层,输出空间变换参数。采样网络依据变换参数来构建一个采样网格,输入图像中的点经过采样变换生成一个采样信号,采样网络得到的是一种映射关系T(G),利用采样网格和输入的特征图或图像同时作为输入产生输出,得到经过变换之后的特征图,即提取到图像的关键信息。
SSDSN为提高低层网络的语义信息、提高网络的特征提取能力,对输入图像进行数据增强。输入为图像,输出为特征图,利用注意力机制中的定位网络学习到一组参数θ,这组参数作为采样网络的参数,生成采样信号,采样信号是一个变换矩阵,与原始图片相乘之后,可以得到变换之后的变换矩阵,也就是变换之后的图像特征。经以上操作,目标区域得到缩放,目标区域得到关注。坐标矩阵变换关系如下式所示:
θ矩阵就是对应的采样矩阵,是一个可以微分的矩阵,每一个目标点的信息是所有源点信息的一个线性组合。
图像基本的三通道或经过卷积层之后,不同卷积核都会产生不同的通道信息,目标图像在原图像上采样,每次从原图像的不同坐标上采集像素到目标图像上,把目标图像贴满,每次目标图像的坐标都遍历一遍,是固定的,而采集的原图像的坐标是不固定的,因此可提取出关键信息。
SSDSN主要利用低层细节特征检测小占比目标,高层抽象特征检测中等占比目标和大目标。用于车间人员检测的低层卷积层为空间域注意力机制中的子网络和Conv4_3,空间域注意力机制中的定位网络增强了特征表达能力,注重细节信息,提取的语义信息更加充分,低层网络特征提取能力更强,对小目标提取有较大提升。高层卷积层包含5层,网络更加关注于目标区域,特征提取更加充分、准确,特征信息经过卷积、池化等操作生成最终的检测结果,检测的准确率得到较大提升。
3实验结果及对比分析
3.1实验环境及应用案例
硬件环境:1台服务器,配置为3T硬盘,128G物理内存,第六代Intel处理器。显卡为RTX 2080Ti,顯卡驱动为Nvidia-410。
软件环境:操作系统为Ubuntu16.04,CUDA 10.0,cuDNN10.0,Opencv 3.3.1,python 2.7,MySQL5.7。
某生产车间,工人作业时,易发生人员伤亡事故且受烟雾、粉尘光照等噪声影响,人员检测受到较大干扰。应用本文提出的基于空间域注意力机制的车间人员检测方法验证本文提出方法的性能。
3.2实验数据
本文数据集由两部分组成,98%的数据集来自某生产车间内的监控视频,大小为70GB,视频格式为MP4。其中50G视频被裁剪成像素为1080×720的图片,选取具有车间人员的图片数量为30138张,背景图片数量为18975张,用于SSDSN车间人员检测网络模型的训练,其余20G视频作为测试集;2%数据集来自Pascal VOC2012中的图片,Pascal VOC2012是目标检测、图像分割网络对比试验与模型评估中的基准数据之一,为公开数据集,被广泛使用。其中图片中有人的图片数量为2000张,用于SSDSN车间人员检测模型的训练,增大训练集丰富性,防止训练过程中出现过拟合。
3.3车间人员检测对比试验
3.3.1各算法在VOC2012数据集上的比较
本文使用VOC2012数据集和车间图片数据集对各类目标检测算法及本文提出的算法进行车间人员检测,对各类目标检测网络使用相同训练集做训练。
将VOC2012数据集分为训练集和测试集,分别用于网络训练和得到测试结果。Faster R-CNN[6]、SSD[8]、YOLOV2[18]、YOLOV3[7]、Mask RCNN[22]、YOLOV5[21]及本文算法,使用VOC2012训练集训练,找出各网络生成的最优模型,验证算法准确率与召回率。结果如表1所示,在VOC2012测试集上本文算法的准确率和召回率较其它算法有所提升,以及采用FPS(frames per second),即画面每秒传输帧数评估模型的检测速率,来进行速度对比。
3.3.2各算法在车间数据集上的比较
选取车间内不同位置的摄像头进行分场景测试,测试时长为8 h,期间车间人员正常通行。检测的帧图片总数为3456000张,其中约2160000张图片为车间人员图片,剩余1296000张图片均为背景图片。测试本文算法的效果,结果如表2所示,数据统计由数据库中的帧图像计数得到。
由表2分析得到,本文算法的平均准确率为准确率取平均值,计算得平均准确率为95.0%,其平均召回率为召回率取平均值,计算得平均召回率为93.1%,据计算本文算法的平均误检率较低,约为3.3%,但存在漏检情况,平均漏检率约为5.5%,本算法已经具备了较强的车间人员检测能力。
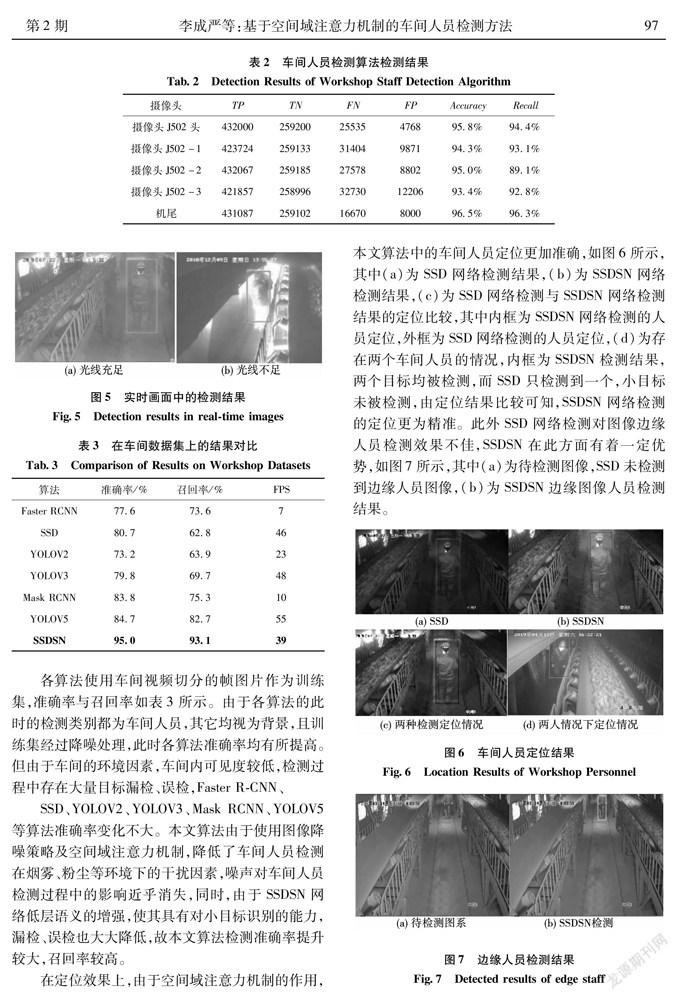
图5为现场摄像头实时画面中的人员检测结果,其中(a)为车间内光线较为充足的情况下的识别结果,(b)为车间内光线不足的情况下的识别结果,(a)、(b)内均有烟雾、粉尘干扰,图像较模糊。在不同环境因素影响下,本文提出的车间人员检测方法均能识别。实验证明该方法具有可行性。
各算法使用车间视频切分的帧图片作为训练集,准确率与召回率如表3所示。由于各算法的此时的检测类别都为车间人员,其它均视为背景,且训练集经过降噪处理,此时各算法准确率均有所提高。但由于车间的环境因素,车间内可见度较低,检测过程中存在大量目标漏检、误检,Faster R-CNN、
SSD、YOLOV2、YOLOV3、Mask RCNN、YOLOV5等算法准确率变化不大。本文算法由于使用图像降噪策略及空间域注意力机制,降低了车间人员检测在烟雾、粉尘等环境下的干扰因素,噪声对车间人员检测过程中的影響近乎消失,同时,由于SSDSN网络低层语义的增强,使其具有对小目标识别的能力,漏检、误检也大大降低,故本文算法检测准确率提升较大,召回率较高。
在定位效果上,由于空间域注意力机制的作用,本文算法中的车间人员定位更加准确,如图6所示,其中(a)为SSD网络检测结果,(b)为SSDSN网络检测结果,(c)为SSD网络检测与SSDSN网络检测结果的定位比较,其中内框为SSDSN网络检测的人员定位,外框为SSD网络检测的人员定位,(d)为存在两个车间人员的情况,内框为SSDSN检测结果,两个目标均被检测,而SSD只检测到一个,小目标未被检测,由定位结果比较可知,SSDSN网络检测的定位更为精准。此外SSD网络检测对图像边缘人员检测效果不佳,SSDSN在此方面有着一定优势,如图7所示,其中(a)为待检测图像,SSD未检测到边缘人员图像,(b)为SSDSN边缘图像人员检测结果。
4结论
本文使用深度学习方法来解决车间安全监测问题,提出基于空间域注意力机制的车间人员检测方法。SSDSN车间人员检测网络保障了车间人员检测的实时性,为提高检测准确率和召回率,改进暗通道优先处理策略,降低车间内烟雾、粉尘、光照等因素对检测的影响。用区域划分方法解决车间区域复杂问题,实际应用证明,本文算法检测网络准确率较高,为车间安全管理提供支持,具有广泛的应用前景。下一步将考虑检测过程中目标遮挡问题。
参 考 文 献:
[1]VIOLA P, JONES M J. Robust Real-Time Face Detection[J]. International Journal of Computer Vision, 2004, 57(2):137.
[2]DALAL N, TRIGGS B, SCHMID C. Human Detection Using Oriented Histograms of Flow and Appearance[C]// European Conference on Computer Vision. 2006:428.
[3]FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D. Cascade Object Detection with Deformable Part Models[C]// 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010: 328.
[4]HINTON G E, OSINDERO S, TEH Y W. A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation, 2014, 18(7):1527.
[5]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580.
[6]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(6): 1137.
[7]PANG L, LIU H, CHEN Y, et al. Real-time Concealed Object Detection from Passive Millimeter Wave Images Based on the YOLOv3 Algorithm[J]. Sensors, 2020, 20(6):1678.
[8]SUN X, WU P, HOI S. Face Detection Using Deep Learning: An Improved Faster RCNN Approach[J]. Neurocomputing, 2018, 299(19):42.
[9]CHANG T, HSIEH J W, CHANG T C, et al. EMT: Elegantly Measured Tanner for Key-Value Store on SSD[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2021(99):1.
[10]陈晋音, 王桢, 郑海斌. 基于深度学习模型的非法流动摊贩检测方法研究[J]. 小型微型计算机系统, 2019, 40(7):72.CHEN Jinyin, WANG Zhen, ZHENG Haibin. Research on Detection Method of Illegal Mobile Vendors Based on Deep Learning Model[J]. Mini Computer System, 2019, 40(7): 72.
[11]曹诗雨, 刘跃虎, 李辛昭. 基于Fast R-CNN的车辆目标检测[J]. 中国图象图形学报. 2017,80(5):56.CAO Shiyu, LIU Yuehu, LI Xinzhao. Vehicle Target Detection Based on Fast R-cnn [J]. Chinese Journal of Image and Graphics, 2017,80 (5): 56.
[12]劉丹,马同伟.结合语义信息的行人检测方法[J].电子测量与仪器学报.2019,33(1):54.LIU Dan, MA Tongwei. Pedestrian Detection Method Combined with Semantic Information[J]. Journal of Electronic Measurement and Instrumentation,2019,33 (1): 54.
[13]HE K, JIAN S, FELLOW, et al. Single Image Haze Removal Using Dark Channel Prior[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(12):2341.
[14]储岳中, 黄勇, 张学锋, 等. 基于自注意力的SSD图像目标检测算法[J]. 华中科技大学学报(自然科学版), 2020,453(9):75.CHU Yuezhong, HUANG Yong, ZHANG Xuefeng, et al. SSD Image Target Detection Algorithm Based on Self Attention[J]. Journal of Huazhong University of Science and Technology (NATURAL SCIENCE EDITION), 2020,453 (9): 75.
[15]李红艳,李春庚,安居白,等.注意力机制改进卷积神经网络的遥感图像目标检测[J].中国图象图形学报,2019,24(8):1400.LI Hongyan, LI Chungeng, AN jubai, et al. Remote Sensing Image Target Detection Based on Improved Convolutional Neural Network with Attention Mechanism[J]. Chinese Journal of Image Graphics, 2019,24 (8): 1400.
[16]XU K, BA J, KIROS R, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention[J]. Computer Science, 2015,37(1):2048.
[17]JADERBERG M, SIMONYAN K, ZISSERMAN A, et al. Spatial Transformer Networks[J]. 2015,25(2):156.
[18]REDMON J, FARHADI A. YOLO9000: Better,Faster,Stronger[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2017:6517.
[19]GAMAGE S, SAMARABANDU J. Deep Learning Methods in Network Intrusion Detection: A Survey and an Objective Comparison[J]. Journal of Network and Computer Applications, 2020, 169(2):102767.
[20]LIU Y, SUN P, WERGELES N, et al. A Survey and Performance Evaluation of Deep Learning Methods for Small Object Detection[J]. Expert Systems with Applications, 2021, 172(4):114602.
[21]LIU W, WANG Z, ZHOU B, et al. Real-time Signal Light Detection Based on Yolov5 for Railway[J]. IOP Conference Series: Earth and Environmental Science, 2021, 769(4):42.
[22]YU Y, ZHANG K, YANG L, et al. Fruit Detection for Strawberry Harvesting Robot in Non-structural Environment Based on Mask-RCNN[J]. Computers and Electronics in Agriculture, 2019, 163(10): 46.
(编辑:王萍)
