改进YOLO v4的火焰图像实时检测
2022-05-23王冠博杨俊东保利勇丁洪伟
王冠博,杨俊东,李 波,保利勇,丁洪伟
(云南大学 信息学院,云南 昆明 650500)
0 引 言
随着深度学习在目标检测领域的应用,目前基于深度学习的目标检测主要分为类:单阶段目标检测算法和双阶段目标检测算法[1]。双阶段目标检测算法会把目标检测分为两个阶段,第一阶段会生成可能包含待检物体的候选框,第二阶段会对候选框的物体进行预测识别。常见的双阶段目标检测算法有Fast R-CNN[2]、Faster R-CNN[3]、MASK-RCNN[4]等。双阶段目标检测算法精度高,但处理速度慢,无法满足火焰图像实时检测的实时性需求。单阶段目标检测算法是直接对源数据生成检测结果,处理速度较快,可满足火焰图像实时检测的实时性需求。常见的单阶段目标检测算法有SSD[5]、RetinaNet[6]、EfficientDet[7]、YOLO[8]等。其中,Bochkovskiy等[8]提出了以CSP-Darknet53为骨干网络的YOLO v4,通过增加感受野、改进多通道特征融合、马赛克数据增强等方法,达到了实时性与准确率的均衡。
针对火焰图像实时检测对实时性的需求,以及火焰特征复杂、火焰检测易受周围环境干扰的特点,本文提出一种改进的YOLO v4的火焰图像实时检测模型。该模型以YOLO v4为基础,引入了注意力机制(包括改进型通道注意力(CAB)模块和改进型空间注意力(SAB)模块),可提取出融合通道注意力和空间注意力的特征。此外,还对YOLO v4算法的激活函数、先验框、损失函数进行改进。与传统的YOLO算法和SSD、RetinaNet、EfficientDet相比,该模型在保证实时性的基础上提升了准确率,降低了损失值,从而使火焰的图像的实时检测更加准确、有效。
1 YOLO v4模型概述
1.1 YOLO v4的改进
YOLO v4是由Bochkovskiy等在YOLO v3算法的基础上,以CSPDarknet53为骨干网络,提取图像多尺度的特征进行目标检测。YOLO v4采用SPP(spatial pyramid pooling)替代了YOLO v3的FPN(feature pyramid networks),将不同尺度的特征图进行拼接,增加了模型感受域,从而使模型更快提取出有效特征[9],其结构如图1所示。YOLO v4还采用了PANet(path aggregation network),在不增加网络复杂度的前提下,使网络能获取更全面的细节特征。此外,YOLO v4还采用了Mosaic数据增强、部分网络结构采用Mish激活函数取代了YOLO v3中的Leaky Relu激活函数等[10]。这些方法在保证检测速度的前提下,提高了检测精度。
1.2 YOLO v4网络结构
YOLO v4模型可分为Input、Backbone、Neck、Head这4部分。Input部分负责输入图片;Backbone部分包含CBM(Conv2D_BN_Mish)层、CSPn(cross stage partial connections)层,负责特征提取;Neck部分包含CBL(Conv2D_BN_Leaky Relu)层、SPP层,负责上采样和下采样;Head部分会获取到Neck部分提取的特征图。
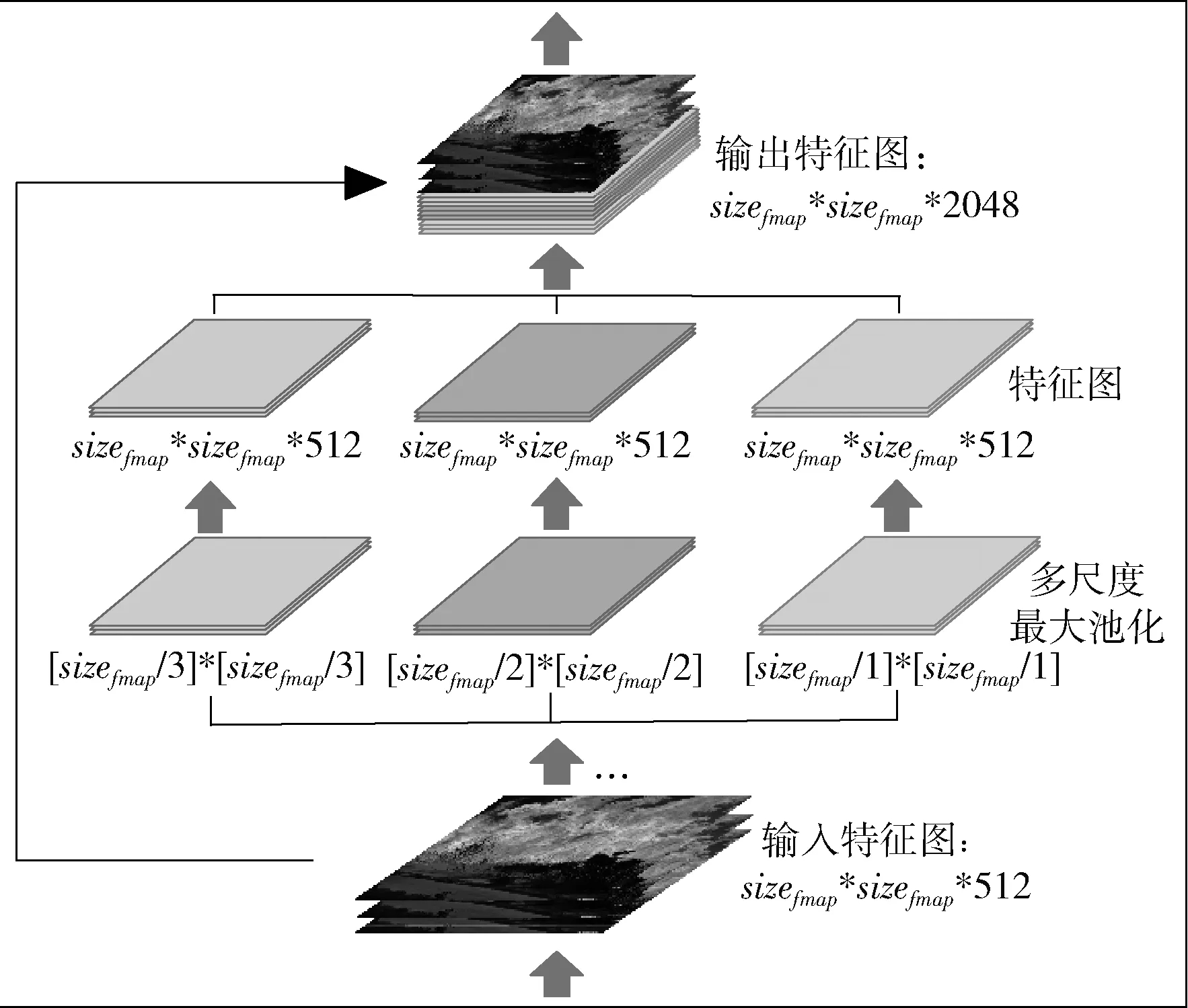
图1 SPP-YOLO网络结构
以输入尺寸为(832,832,3)的图像为例,输入图像通过Backbone部分不同尺度的CSP层进行下采样处理后,得到3个不同尺度的特征图,之后会经过Neck部分处理,增加了特征图的感受域,进一步得到经过上采样和下采样处理后不同尺度的特征图。最后,将特征图输入Head部分进行处理,得到目标检测结果。YOLO v4网络结构如图2所示。
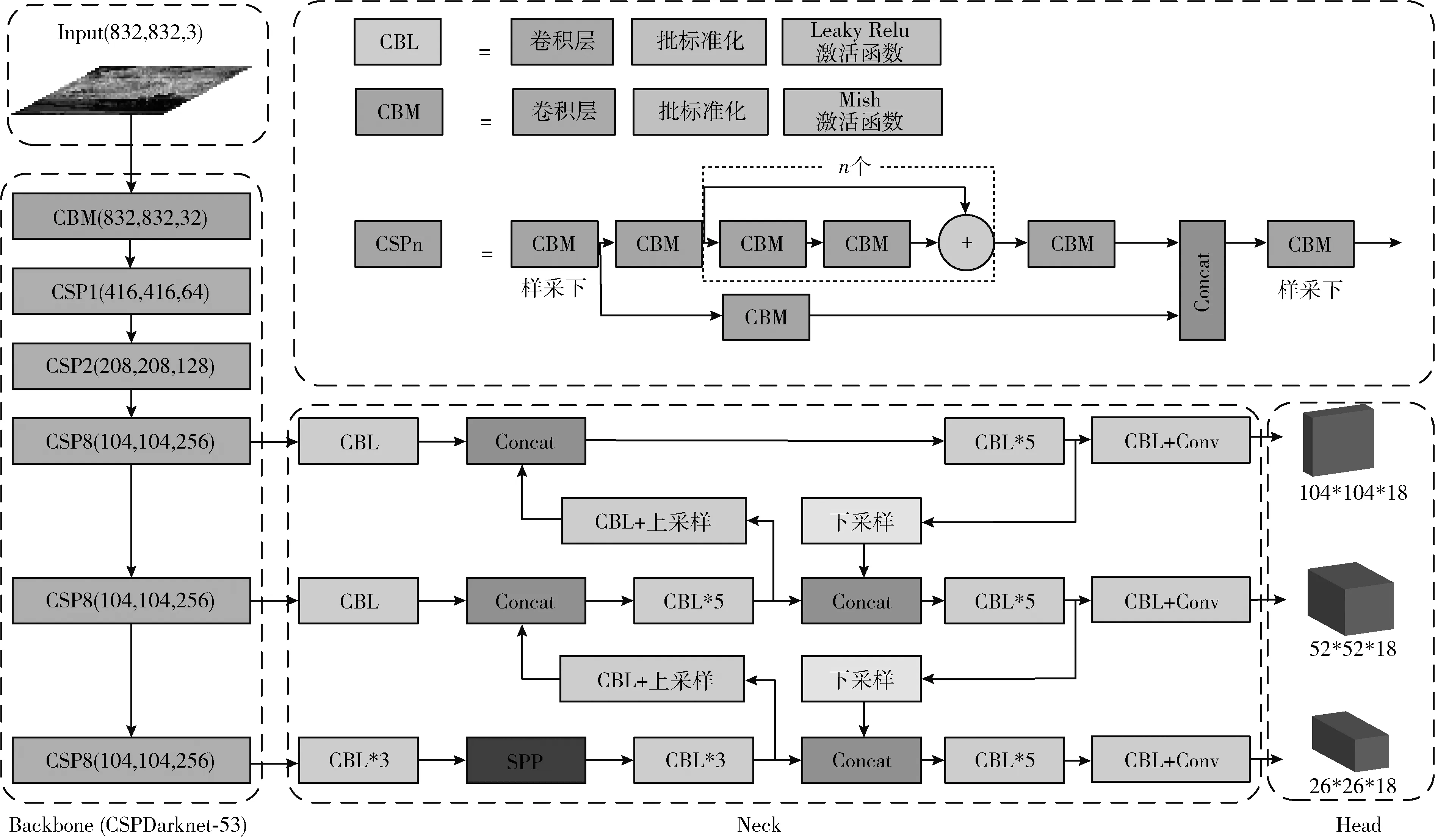
图2 YOLO v4网络结构
1.3 激活函数
Misra等[10]提出Mish激活函数,Mish是一个光滑、连续、非单调的激活函数,式(1)为Mish激活函数的表达式。Mish激活函数上下有界,范围≈[0.31,+∞]。 与ReLU、Swish等激活函数相比,Mish激活函数解决了网络层数加深,精度下降的问题,在深层卷积神经网络中能更好保持稳定性和准确性
(1)
YOLO v4的Backbone部分采用Mish激活函数,Neck部分采用Leaky Relu激活函数,其图像如图3所示。
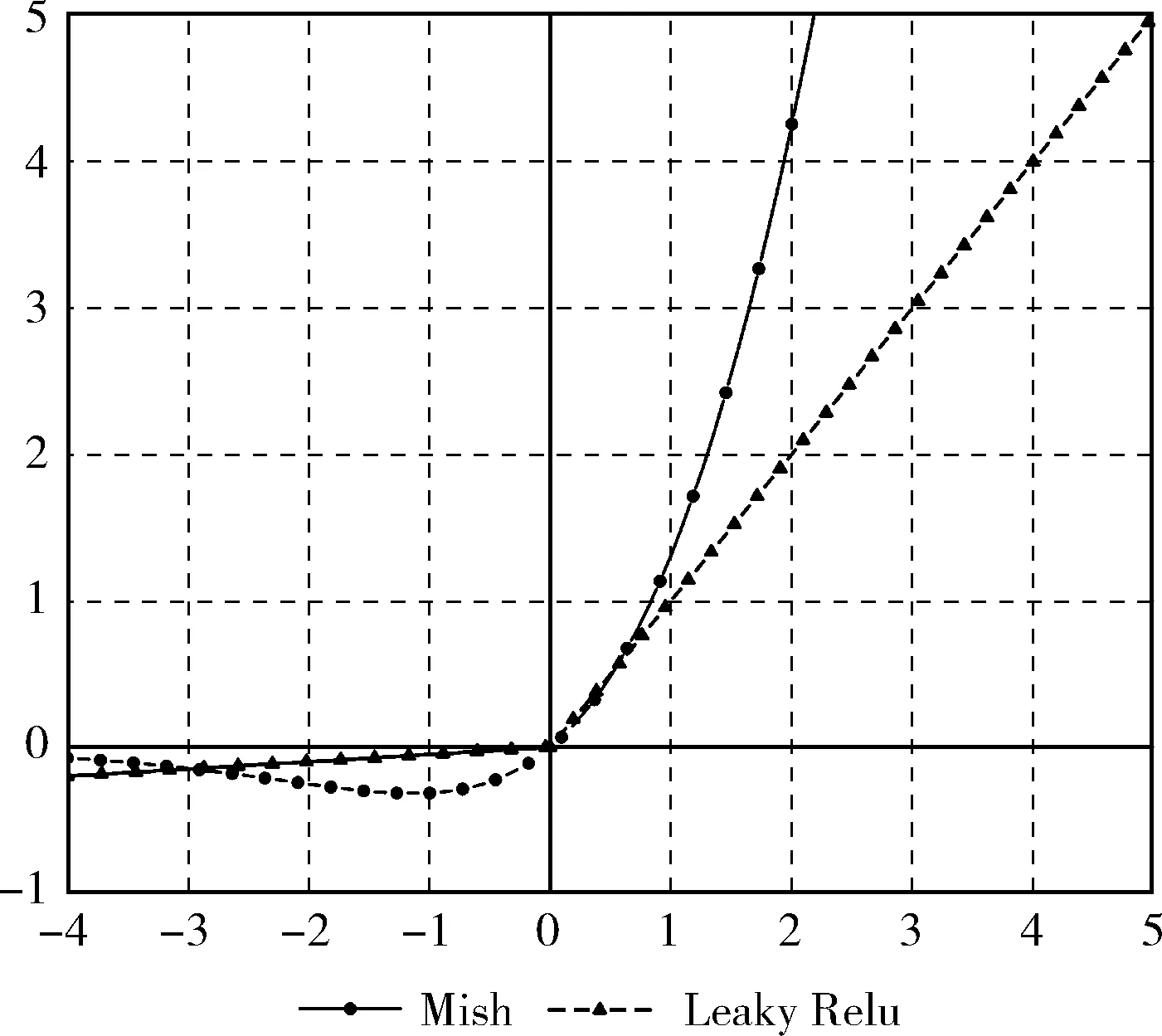
图3 Mish和Leaky Relu 激活函数图像
1.4 损失函数
与YOLO v3损失函数的结构类似,YOLO v4的损失函数也由3部分组成,分别是定位损失函数、目标置信度损失函数、分类损失函数。式(2)为YOLO v4的损失函数
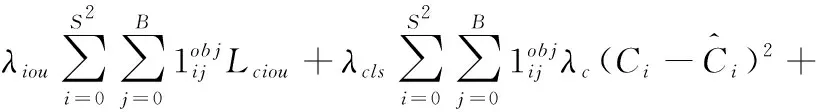
(2)
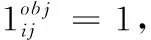
2 对YOLO v4算法的改进
2.1 激活函数的改进
YOLO v4的Backbone部分均采用Mish激活函数,Neck部分均采用Leaky Relu激活函数。Mish激活函数由Misra等[10]提出,其图像如图3所示。Relu的负半轴完全截断,梯度下降不够平滑,可能会出现死亡节点[12];Leaky Relu在负半轴加一个参数α, 可避免其在负半轴直接截断,解决了Relu进入负区间后神经元不学习的问题,减少了静默神经元的出现[13]。但该激活函数对α值的选取要求较高,目前对其性能优劣仍存在争议。Mish激活函数在负区间并不是完全截断,这可使它在负区间允许较小的梯度流入。此外,如图3所示,Mish激活函数无边界,可使其避免出现死亡节点。Misra等[10]也提到,Mish激活函数可保证每一点的平滑,在实际表现中,梯度下降效果优于Relu。
式(3)为Mish激活函数的一阶导数,图4为Mish激活函数和Leaky Relu的一阶导数、二阶导数比较
(3)
其中,ω=4(x+1)+4e2x+e3x+ex(4x+6),δ=2ex+e2x+2。
Leaky Relu的一阶导数均为常数,二阶导数为0。从图4 Mish激活函数的一阶导数可以看出,它是连续可微的,一阶导数、二阶导数均无断点,可避免出现奇点。与Leaky Relu相比,Mish激活函数的性能和稳定性更好。
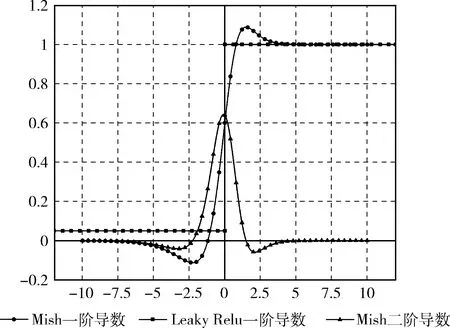
图4 Mish和Leaky Relu的一阶导数和二阶导数
本文对YOLO v4网络结构的Neck部分激活函数进行了改进,将Neck部分Leaky Relu激活函数替换为Mish激活函数。改进后的YOLO v4网络结构如图5所示。
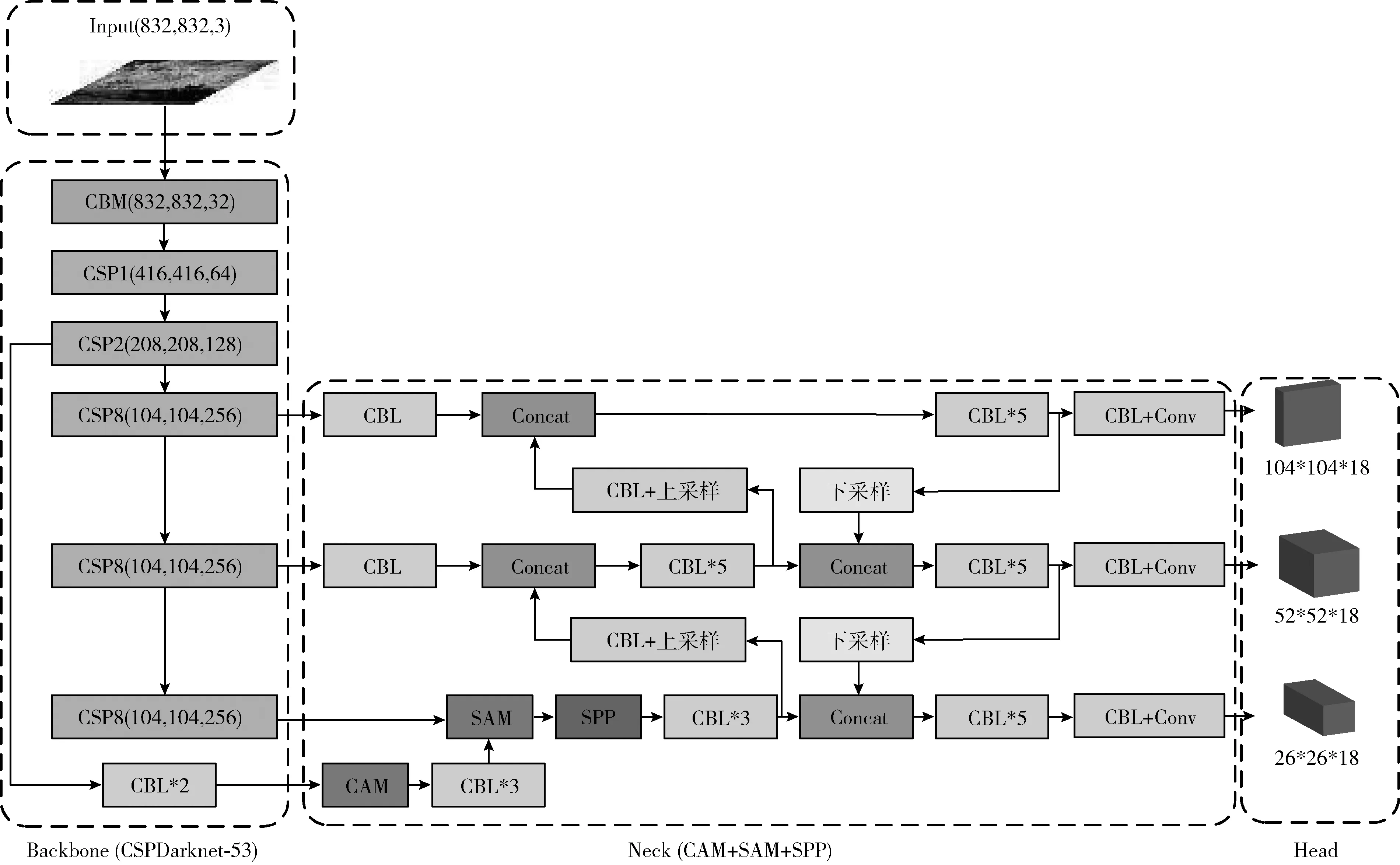
图5 改进后的YOLO v4网络结构
2.2 先验框的改进
YOLO v4中采用了K-means聚类算法来获取9个先验框,并将其运用至网络Head部分3个不同尺度的特征图,从而预测待检目标的边界框。YOLO v4中的先验框是通过对PASCAL VOC数据集进行聚类得到的,不适用于火焰图像检测。式(4)为YOLO v4中K-means聚类算法距离的计算方法
d(box,central)=1-IOU(box,central)
(4)
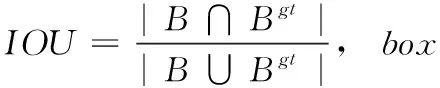
采用IOU反映预测框与真实框的检测效果时,如果两个框没有相交,则IOU=0, 无法正确反映预测框和真实框的实际距离。针对IOU的不足,Hamid Rezatofighi等[14]提出GIOU(generalized IoU),式(5)GIOU的表达式
(5)
式中:C为同时包含B和Bgt的最小框面积。GIOU不仅可以衡量预测框和真实框重叠度,还可正确衡量不重叠的情况,能更好反映预测框和真实框的重叠度。
因此,为了能更好衡量预测框和真实框的重叠度,本文采用GIOU取代IOU。 式(6)为改进后的K-means聚类算法距离计算方法
dGIOU(box,central)=1-GIOU(box,central)
(6)
以输入图像尺寸为416*416为例,采用改进后的K-means聚类算法进行距离计算之后,选取的9个先验框分别为(34,57)、(91,85)、(62,187)、(161,160)、(142,381)、(289,245)、(300,572)、(557,350)、(679,688)。表1为修改先验框前后,模型相关参数对比。

表1 YOLO v4修改先验框前后相关指标对比
2.3 损失函数的改进
YOLO v4的损失函数由定位损失函数、目标置信度损失函数、分类损失函数3部分组成,式(2)为YOLO v4的损失函数。式(7)为YOLO v4的定位损失函数
(7)
(8)
(9)
(10)
式中:Lciou为CIOU(complete IoU)损失函数,β为权重函数,ρ为预测框与真实框中心点的欧氏距离,υ可度量预测框与真实框的长宽比相似性,wgt、hgt分别为真实框的宽度、高度,w、h分别为预测框的宽度、高度,如图6所示。
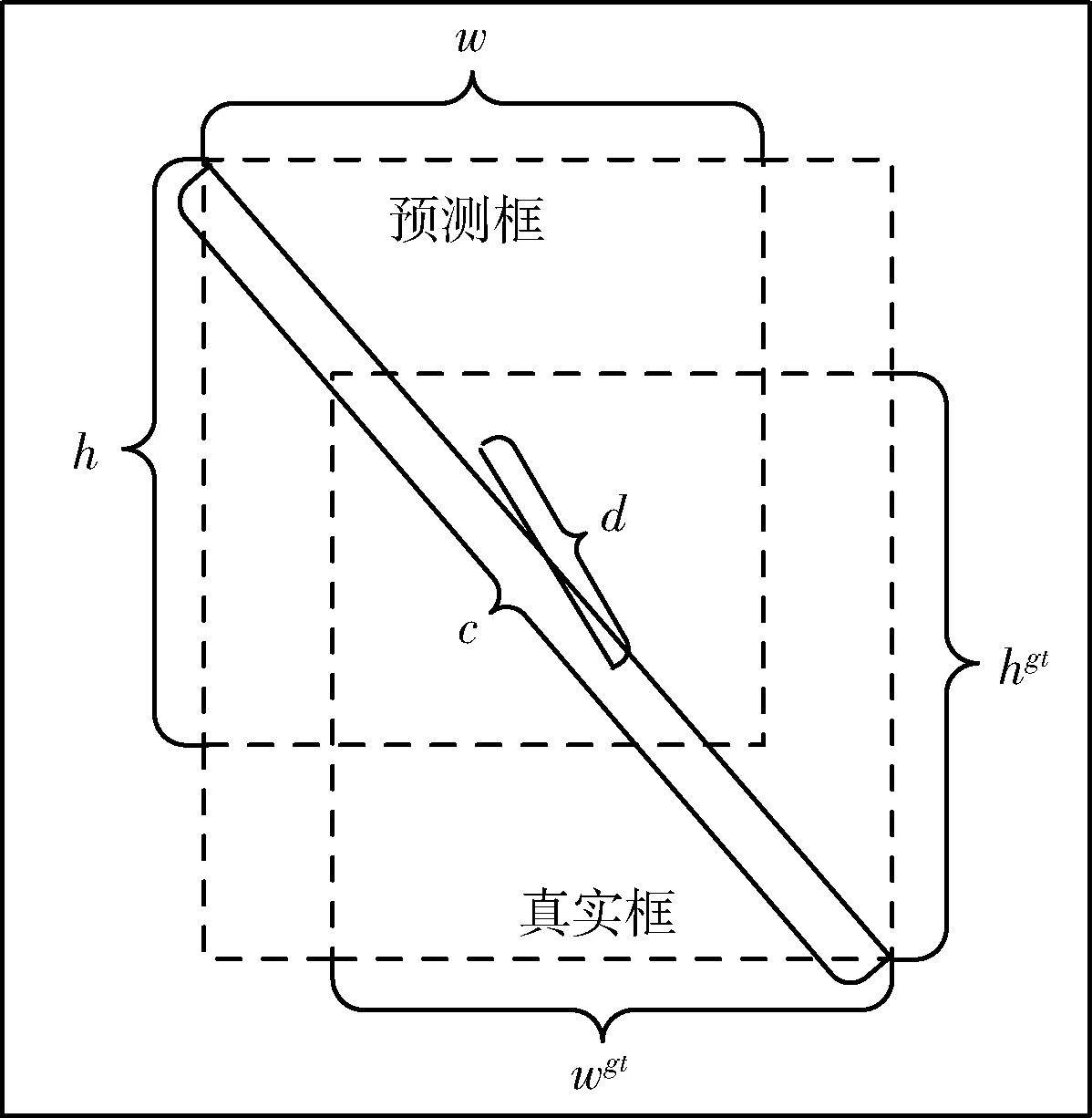
图6 预测框和真实框相关参数
CIOU考虑了预测框与真实框之间的欧氏距离、重叠率、尺度特征、预测框的宽高比。在对宽高比有一定规律的目标(比如人、汽车等)进行检测时, 能获取目标真实框的宽高比,从而可提高目标检测的AP值。但火焰特征比较复杂,且源数据集火焰图像的大小不固定,宽高比并没有特定的规律。若采用CIOU使模型学习到部分类似大小真实框的宽高比,则可能使模型对其它宽高比的图像造成误判,反而会降低模型的鲁棒性。因此,本文采用的分类损失函数采用DIOU(distance-IoU)。式(11)为DIOU表达式
(11)
式中:ρ为预测框与真实框中心点的欧氏距离,c为包含预测框和真实框最小矩形框的对角线距离,如图6所示。DIOU包含了预测框和真实框中心点的欧氏距离、重叠度等特征,但没有考虑真实框的宽高比。因此,针对火焰图像宽高比没有固定比例的特点,DIOU能更好反映预测框与真实框的关系,能有效增强模型的泛化能力。
2.4 引入注意力机制
注意力机制模仿了人类的视觉系统,融合局部视觉结构,获取场景特征,并将注意力集中于特征较为显著的区域[15]。本文引入的注意力模块包括通道注意力(channel attention block,CAB)和空间注意力(spatial attention block,SAB)。
通道注意力可对不同通道特征的依赖关系进行建模,融合多通道的特征图像,自适应调节其特征权重。在针对火焰图像的目标检测中,可对火焰的特征进行强化,其结构如图7所示。SENet采用全局平均池化来对通道特征进行压缩,可使模型侧重于关注信息量大的通道特征,但仅采用全局平均池化较难获取物体间更详细的通道注意力[16]。全局最大池化可将梯度较大的位置进行反向传播,进一步提高通道特征提取的敏感度。因此,本文同时采用全局最大池化和全局平均池化,将低阶通道特征进行全局最大池化和全局平均池化融合,实现了对高阶通道特征的引导与校准。
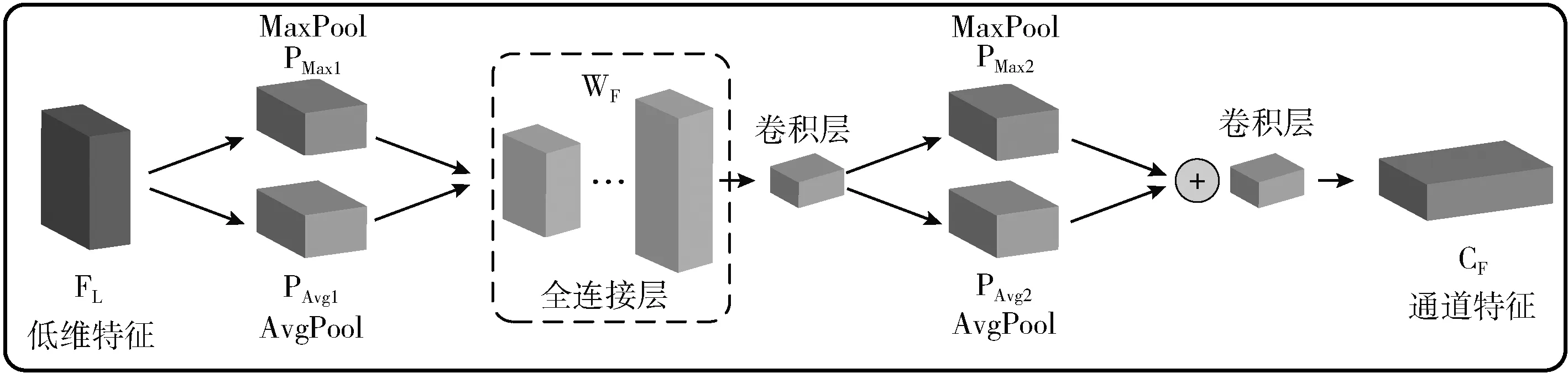
图7 通道注意力模块(CAB)
对YOLO v4算法添加空间注意力,可弥补通道注意力的不足。空间注意力对特征图有效信息的区域比较敏感,可对特征图内部像素点进行建模[17]。本文采用Bochkovskiy等[8]提出的改进型Modified SAM,其结构如图8所示。
本文采用融合CAB和SAB的注意力机制,将其用于YOLO v4算法中进行火焰图像的检测,其结构如图9所示。改进型的注意力机制将浅层卷积层的通道和空间特征进行提取,并将其与深层卷积层提取的特征进行融合,可在增加少量计算量的基础上,增强模型的特征提取能力。
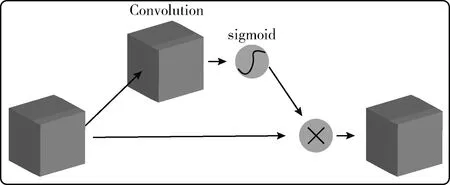
图8 空间注意力模块(SAB)
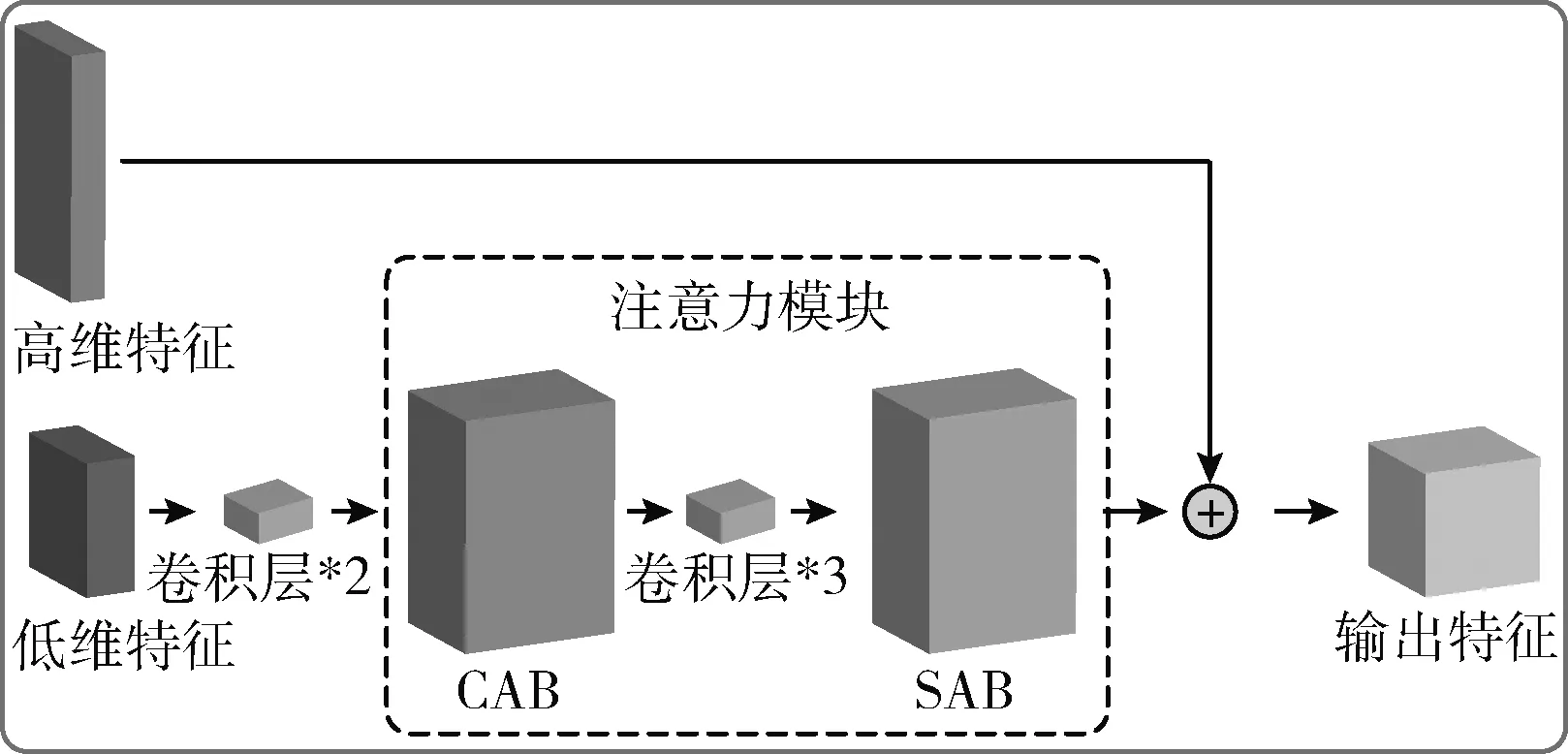
图9 融合CAB和SAB的注意力机制
由于火焰图像数据集中,火焰尺寸大小差距较大,引入注意力机制之后,可对火焰图像特征进行多尺度提取,加强了模型对火焰图像的检测能力。
3 实验结果及分析
3.1 实验环境
本实验的环境配置见表2,对比实验的硬件配置与该实验的配置相同。
表2 实验环境配置
本实验火焰图像分别来自kaggle火焰数据集(https://www.kaggle.com/phylake1337/fire-dataset)、火焰公开数据集(http://signal.ee.bilkent.edu.tr/VisiFire/)以及互联网采集,一共967张火焰图像。其中,70%(711张)为训练集,30%(256张)为测试集。所有数据集均采用labelimg进行标注。
本实验YOLO v4的参数以YOLO v4[9]为基础,经过大量实验选取最优参数,对部分参数进行了调整。实验批量大小设置为32,动量为0.949,初始学习率设置为0.0013,前1000次采用固定学习率进行学习,第16 000代和第18 000代学习率分别为0.000 13、0.000 013,总迭代次数为20 000次。
3.2 实验结果
3.2.1 改进的YOLO v4算法
首先将本文改进的YOLO v4算法与原YOLO v4算法进行比较,分别选取AP(average precison)、Loss、FPS、Recall、Average IOU作为评价指标。其中,AP为目标检测的平均精度,可评估模型在每一类别的好坏。Loss为损失函数,式(2)为改进算法前的Loss值,式(12)为改进后的Loss值。FPS为每秒处理图片的数量,可反映模型的检测速度。Recall为目标检测的召回率,可评估模型是否有漏检,式(13)为Recall的计算公式。Average IOU可反映预测框和真实框的重叠程度

(12)
(13)
在与原YOLO v4算法进行比较时,输入图像尺寸统一设置为832*832,采用Darknet骨干网络进行训练,迭代次数为30 000次。为使模型尽快收敛,本实验采用了迁移学习的方法,预训练权重文件为yolov4.conv.137(https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137)。实验数据见表3。
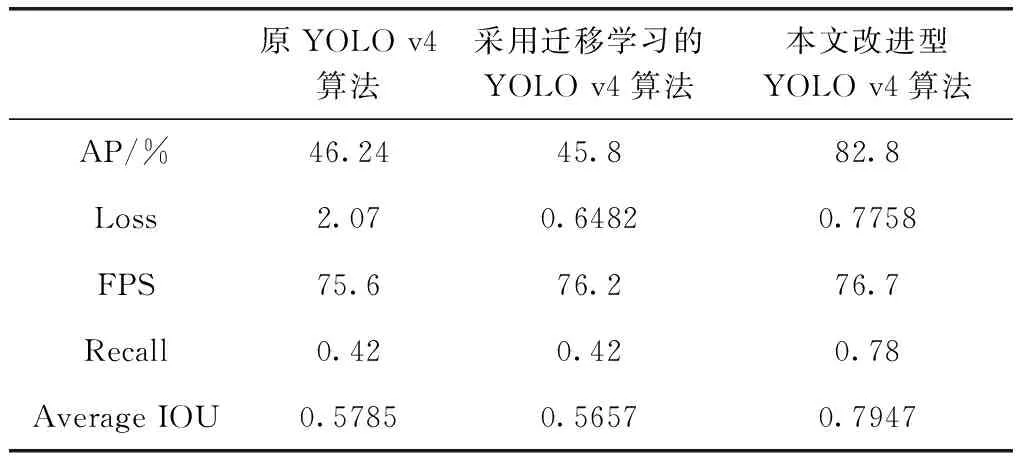
表3 原YOLO算法与本文改进YOLO算法结果对比
从表3可以看到,未进行改进的YOLO v4网络的精度较低,AP只有46.24%,Loss值较大。采用YOLO v4作者的权重文件进行迁移学习之后,Loss值下降的较低,但AP值、Average IOU与之前相比反而下降了,这可能是因为本文的目标检测只有火焰这一个类别,权重文件的类别数量远远大于本文类别数,模型参数无法完全适配。与原算法相比,采用本文改进型YOLO算法之后,模型的AP值提高了36.56%,Loss值下降了1.2942,FPS也略有提升,提高了1.1,Recall值提高了0.36,Average IOU提高了0.2162。总体而言,与原算法相比,本文的改进算法是有效的。
3.2.2 与其它目标检测算法的对比
本文改进算法与YOLO v3、SSD、Efficientdet、Retinanet进行比较,选取AP、Loss、FPS作为评价指标,对比实验结果见表4。
与上一代YOLO v3算法对比,虽然都是采用Darknet骨干网络,但由于YOLO v3采用的是FPN,且在训练过程中只进行了上采样未进行下采样,导致其AP值较低,且在本数据集上出现了过拟合的情况。虽然其FPS较高,但无法满足准确率的需求。SSD采用VGG16作为骨干网络,训练复杂度高于YOLO,AP值较YOLO v3有了一定的提升,但仍无法满足准确率的要求。Efficientdet采用Ef-ficeentnet作为骨干网络,并引入BiFPN,可实现模型的双向跨尺度连接以及加权特征融合,AP值是对比实验中最高的,但FPS较低,无法满足火焰图像检测的实时性需求。Retinanet采用ResNet作为骨干网络,整体模型由骨干网和子网组成,可提取丰富的火焰特征,其AP值优于未改进的YOLO v4算法。但其FPS是所有对比实验中最低的。
总体而言,与其它目标检测算法相比,本文改进算法的AP值和FPS都是最优的,满足了火焰图像识别对准确度、实时性的需求,但Loss值相对来说仍有改进空间。
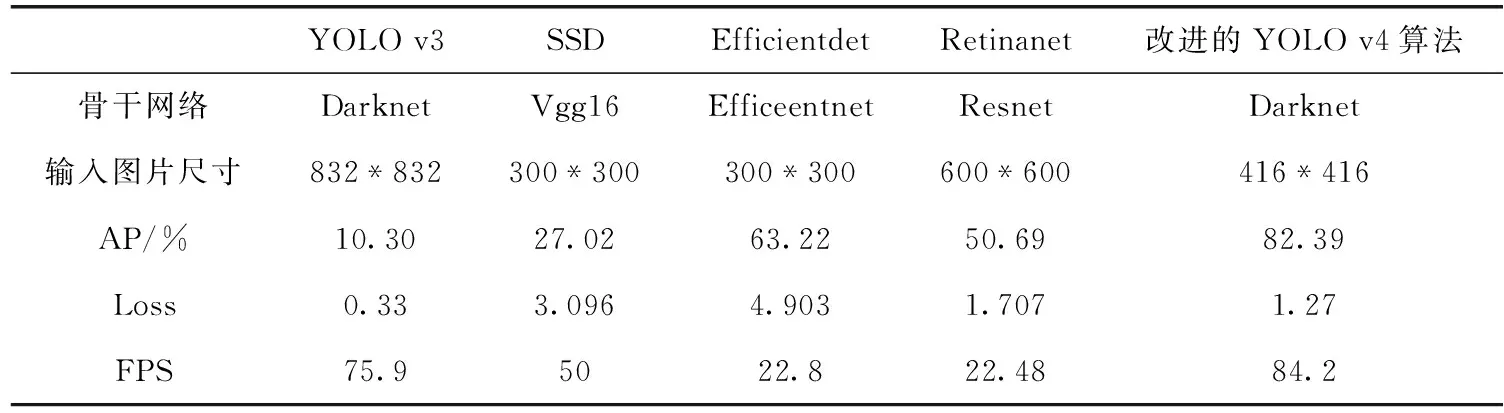
表4 不同目标检测算法实验结果对比
3.2.3 消融实验结果分析
为进一步验证本文改进算法的科学性和有效性,本文采用消融实验进行分析。为了提高训练速度,输入图像尺寸统一调整为416*416。每组实验仅改变一个变量,消融实验结果见表5。
由表5可知,仅改变激活函数时,AP、Recall、Average IOU略有提升,Loss值有较大幅度的下降,模型整体性能比原YOLO v4算法略有提升。采用改进型K-means算法对模型的先验框进行调整之后,使得模型的先验框能更好适配本实验的火焰图像,模型的AP、FPS、Recall、Average IOU均有较大的提升。采用改进型损失函数之后,模型的AP、Recall、Average IOU有了进一步提升,但FPS与之前相比略有下降,这可能是改进算法增加了模型的运算复杂度,使得模型处理速度略有下降。整体而言,改进的YOLO v4算法在火焰图像识别的准确度上有较大提升,且在一定程度上提高了目标检测的实时性。因此,本文提出的改进型YOLO v4算法是有意义的。

表5 改进YOLO v4算法消融实验结果分析
4 结束语
针对火焰图像的复杂性、传统目标检测实时性较差的情况,本文提出了改进型YOLO v4算法。通过对激活函数、先验框、损失函数进行改进,并引入了注意力机制。与原YOLO v4算法相比,模型AP值提高了36.56%,fps提高了1.1,模型整体性能有了较大的提升,满足了火焰图像检测的准确度、实时性的需求。通过与其它目标检测算法(YOLO v3、SSD、Efficientdet、Retinanet)作对比,本文改进算法的实验数据是最优的,验证了本文改进方法的有效性。最后采用消融实验进行分析,模型整体性能随着实验的进行逐步提升,验证了本文改进算法的科学性。
本文提出的改进型YOLO v4算法虽使模型的整体性能有了较大的提升,但由于火焰图像的复杂性、火焰尺寸大小的不确定性,仍有较大的改进空间。此外,针对小目标的火焰图像实时检测,模型的表现并不好,常有漏检情况。因此,下一步要针对不同尺寸火焰的目标检测进行研究,进一步提升火焰图像检测的准确度和实用性。
