基于知识图谱的测试用例复用方法
2022-05-23夏传林谭莉娟王小良
夏传林,郑 巍,谭莉娟,王小良
(1.南昌航空大学 软件学院,江西 南昌 330063; 2.南昌航空大学 软件测评中心,江西 南昌 330063)
0 引 言
测试用例复用是从已有的多个项目中寻找相似的测试用例,故而这些项目的测试场景要相似,而本文所有项目中的测试用例大部分是对硬件接口的测试,所以具有复用的可行性。测试用例是保证软件测试质量的关键,一个好的测试用例有利于发现更多的软件缺陷[1-4],从而缩短软件开发周期,提高测试效率。在软件测试过程中,可以修改高度相似的测试用例,以减少测试用例设计的工作量[5,6]。测试用例复用成功的关键就是找到用户真实需要的测试用例,并推荐给用户。目前,涉及测试用例复用的研究较少,大部分工作都集中在构建测试用例库,以此达到测试用例复用的目的。但是,此类方法仅使用了基于关键字的检索模型,在灵活性和复用率方面仍有所欠缺。
针对上述问题,本文提出了一种基于知识图谱的测试用例复用方法(test case reuse based on knowledge graph,TCRKG),TCRKG通过对项目测试文档数据进行处理,抽取出和测试用例有关的项目、测试项、测试用例、测试记录、问题报告单等基础特征。本文主要包括3个核心内容:构建测试用例知识图谱、改进朴素贝叶斯分类模型、测试用例相似度计算。根据专家经验和测试文档对本体进行设计,构建测试用例图谱,替换传统的测试用例库。为了使测试用例复用模型更加灵活,对改进的朴素贝叶斯分类器设置了常用的多种问题模板,相比于决策树、逻辑回归、支持向量机等分类方法,朴素贝叶斯在时间花费、泛化性能上更适合本文的应用场景。最后在实验中验证了该方法能够有效提高测试用例复用,找到软件缺陷。
1 相关工作
本文主要是通过构建知识图谱的方法来对测试用例复用进行研究,因此相关工作主要分为测试用例复用研究和知识图谱。
1.1 测试用例复用研究
测试用例的设计和编写需要花费大量的时间,而测试用例复用能够大大节约时间,提高效率[7,8]。从本质上来讲,测试用例复用就是从已有的测试用例中找出用户真实需要的测试用例。
近年来,出现了一些新的针对测试用例的方法研究,Zhang等提出了一种基于控件遍历的测试方法,能够基于深度优先算法自动生成测试用例,并且该方法能够增强测试用例的复用性[9]。Ge等提出了一种基于线性融合和项目结合的用户协同过滤算法[10],该算法虽然可以更有效地提高测试用例推荐精度,但存在计算成本高,泛化性能差的问题。Tong等利用本体对测试用例进行复用,提供了灵活的查询需求[11],却缺少测试用例相关的上下文内容,没有对问题报告单、测试记录等和测试用例极其相关的内容进行研究。综上所述,以上方法很难从海量数据中挖掘测试用例的特征以达到精准复用的目的,不能获得测试用例的上下文环境。
1.2 知识图谱
知识图谱是由谷歌(Google)公司正式向外界发布,自此,知识图谱正式走入大众视野。知识图谱本质上是语义网的知识库,由节点和边组成,节点表示实体,边表示实体与实体之间的关系。知识图谱可以分为通用知识图谱和领域知识图谱。例如通用知识图谱有DBpedia、YAGO、Freebase等;领域知识图谱有地理信息领域知识图谱[12]、中医药知识图谱等。
知识图谱的应用场景主要有智能搜索、智能问答、智能推荐、情报分析。Pedro Szekely等利用网络数据构建知识图谱[13],用来打击人口贩卖。Feng-Lin Li等将知识图谱应用到电子商务领域[14],有助于理解用户需求,回答售前问题和生成解释文本。Sen Hu等通过子图匹配知识图谱来回答自然语言问题[15],可以有效地解决歧义问题。测试用例复用也可以看成是一种智能推荐,用户提出问题,通过知识图谱来找寻答案。基于知识图谱的智能搜索可以直接给出知识卡片而不是给出相关的链接序列。在知识图谱的帮助下,检索引擎可以将搜索关键词映射到知识图谱中匹配度较高的一个测试用例上,最后以知识卡片的形式展现给用户。
2 基于知识图谱的测试用例复用方法
在本节中,首先介绍整个测试用例复用模型框架流程,然后对本文3个核心内容:构建知识图谱、改进朴素贝叶斯分类模型、相似度计算依次进行介绍。
2.1 模型框架
图1展示了测试用例复用的整个流程,包括3个核心部分。
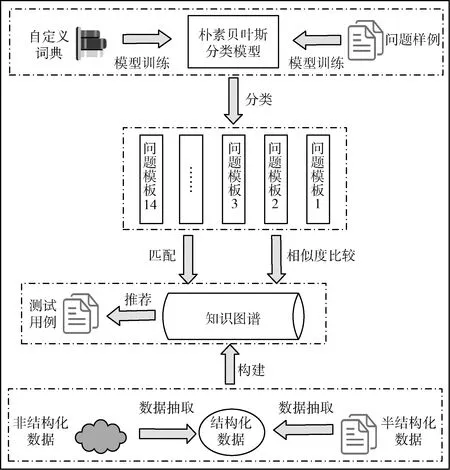
图1 测试用例复用模型
(1)构建测试用例知识图谱:构建测试用例知识图谱是本文方法的前提,其过程主要是依据专家经验结合项目文档数据对本体进行设计,从半结构化的文档数据中提取出测试用例、测试记录、问题报告单等相关的数据,最后填充实体构建知识图谱。
(2)改进朴素贝叶斯分类模型:本文设计了常用的多种问题模板,每种问题模板都有很多问题样例。首先同种问题模板中的问题样例高度相似,不同种类的问题模板也有一定的相似度,这就会引发一种情况,如果某种问题模板的问题样例数量特别多,那么其所对应的特征也很多,最后通过朴素贝叶斯分类器来计算概率就会出现特征多的类别概率偏大,所占特征少的类别概率偏小。为了解决上述问题,本文提出了两种方式来提高朴素贝叶斯分类的准确率。其一,通过设置测试用例自定义的词典;其二,通过给每种问题类别设置一个权值,从而提高模型分类的准确率。
(3)测试用例相似度计算:通过朴素贝叶斯分类之后可以确定问题模板类别,然后就是通过知识图谱寻找用户需要的答案。问题模板分为两类,一种是可以直接从知识图谱中找到答案,例如,功能测试有多少测试用例;一种是需要通过相似度计算才可以得到答案。用户可以输入一个或多个测试用例属性的内容、关键字等,通过这些与知识图谱中的测试用例进行相似度比较,具体计算方法在2.4节中阐述。
2.2 构建知识图谱
构建知识图谱主要包括3个步骤:
(1)特征提取:本文构建知识图谱的数据来源主要是项目测试文档,属于半结构化数据,依据专家经验和测试用例的特征,从半结构化数据中提取出和测试用例相关的特征数据[16,17],最终将数据转为结构化数据,测试用例设计样例见表1。

表1 测试用例设计样例
(2)本体构建:本体是用于描述一个领域的数据集合,属于知识图谱的模式层。在测试用例的本体设计中,本文采用七步法进行构建。图2中展示了核心本体,包括测试用例信息、项目、测试项、测试项明细、测试记录和问题报告单等数据,能够更加全面覆盖测试用例的关键信息。
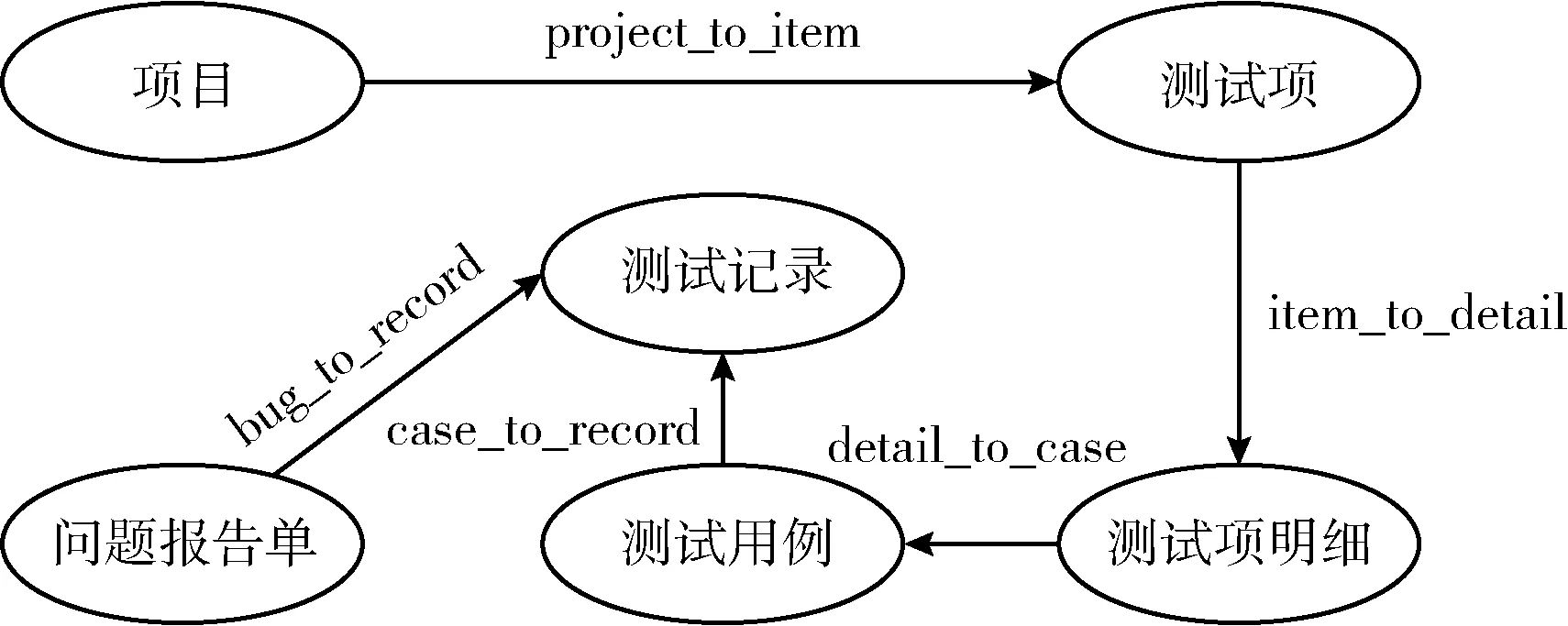
图2 测试用例核心本体
(3)生成图谱:图3为部分测试用例知识图谱,图中共有5种颜色的圆,每一种颜色表示一种实体,实体与实体之间的连线表示两者的关系,实体的属性在图中没有显示出来。通过测试用例知识图谱,可以很清晰看到项目、测试项、测试用例、问题报告单之间的关联,以及测试用例的分布、缺陷的分布。在测试用例复用中,就能够优先匹配到那些能够发现软件缺陷的测试用例。
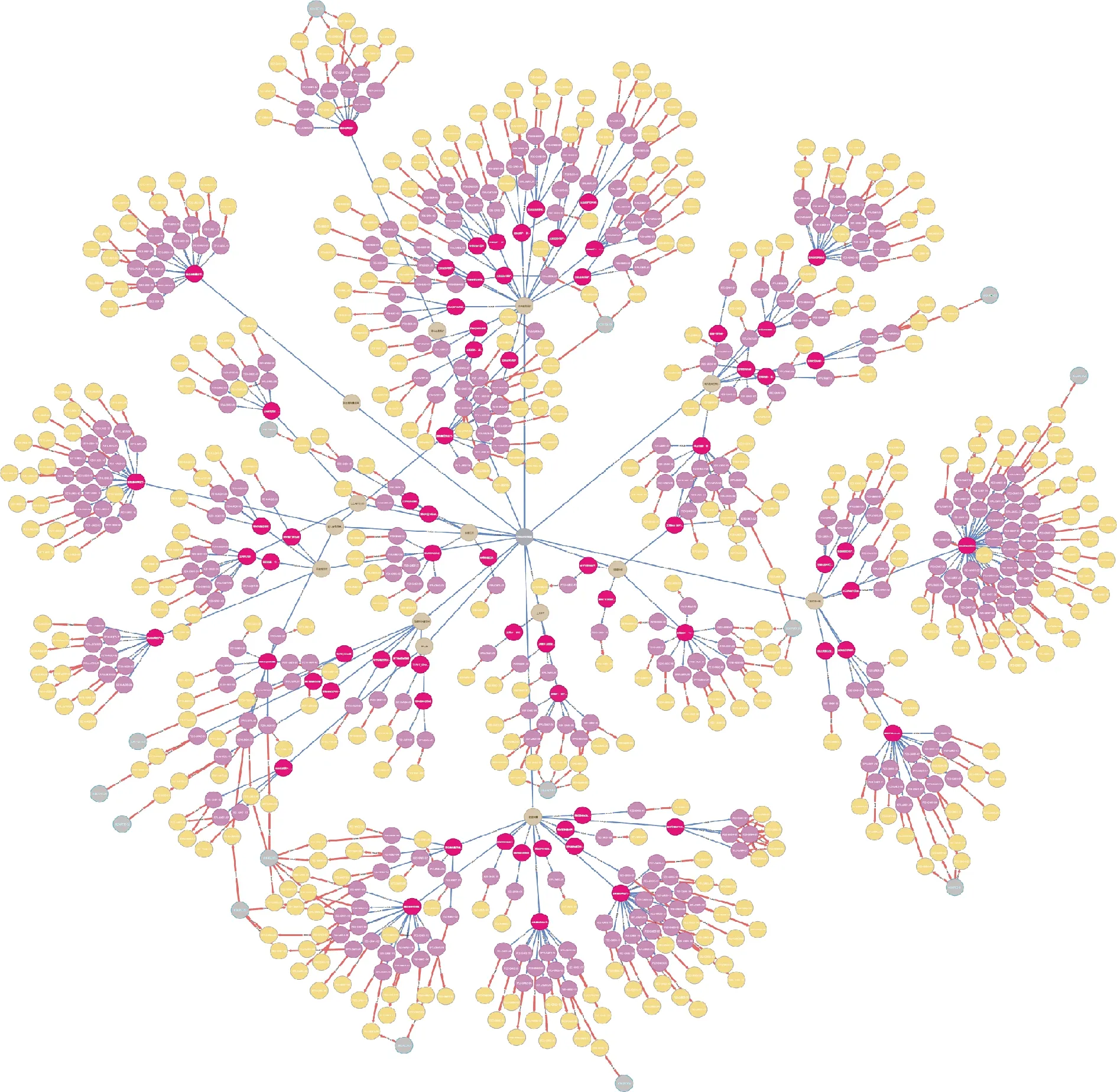
图3 部分测试用例知识图谱
2.3 基于朴素贝叶斯的分类模型
测试用例复用模型不仅应该能够检索到用户需要的测试用例,还能够找到和测试用例相关联的信息。针对这个问题,本文通过使用朴素贝叶斯分类模型,来更好满足用户各种问题需求。
为了提高朴素贝叶斯的准确率,本文通过两种方式对其进行改进:设置测试用例自定义的词典,来提升关键词的识别;对类别进行加权,减少模型过拟合。
在训练朴素贝叶斯分类模型之前,需要自定义词典和设置好问题模板。如表2所示列出了自定义词典添加的内容,词典中添加的每种内容都必需有唯一的词性。如此,利用分词工具才能准确的将用户输入的内容进行分词,并且能够识别出自定义词典中的内容。
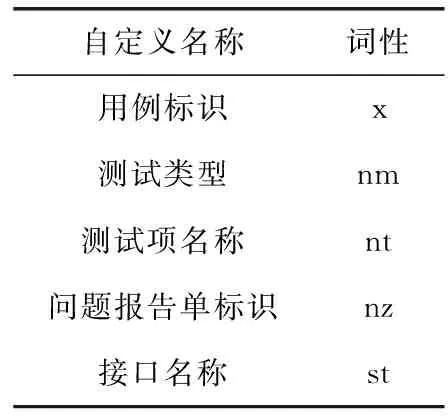
表2 自定义词典
本文设置了14种常用问题模板,每种问题模板都有很多问题样例,用来模型训练。经过朴素贝叶斯分类确定输入的是哪种问题模板后,其中有13种是可以直接生成查询语句从知识图谱中检索答案,而另一种则需要通过测试用例相似度计算来匹配。
问题模板集合C={y1,y2,…,y14}, 表示14种问题模板,I={I1,I2,…,In} 是输入集合,每一个元素是一个待分类项,Ii={x1,x2,…,xm} (i=1,2,…,n),Ii表示当前用户输入的内容,每个x为一个特征属性。对Ii分词后会得到每个Ii的特征属性x, 不同的Ii对应x的数量也不相同。
首先通过分词将所有问题模板中的样例进行分词得到k维向量,然后开始训练模型。根据条件概率可得到式(1)
(1)
为得到当前Ii所属类别,需要对每种类别设置一个权值w={w1,w2,…,w14},w∈(0,1), 通过式(2)来计算
P(yt|Ii)=max{P(y1|Ii)w1,P(y2|Ii)w2,…,P(y14|Ii)w14}
(2)
式(2)中为当前Ii属于哪种类别,则求出Ii在14种问题模板当中的所有概率,对每个类别计算P(yt), 选择概率最大的类别作为Ii的类别。式(1)中,因为分母对于所有类别为常数,所以只需将分子最大化即可
P(Ii|yt)P(yt)=P(x1|yt)P(x2|yt)…P(xm|yt)P(yt)
(3)
对每个类别计算P(Ii|yt)P(yt), 以P(Ii|yt)P(yt) 作为Ii所属的类别。
2.4 相似度计算
Mu等提出了基于文本相似性对测试用例复用进行研究[18],但没有考虑将输入内容分解对应到每个属性上。本文经过改进的朴素贝叶斯分类模型处理后,会从14种问题模板中找到概率最高的一个作为其真实类别。用户可以输入测试用例的多种属性内容,根据这些属性在知识图谱中找到一个大致范围的测试用例集,最终计算相似度来确定结果。
测试用例集合M={M1,M2,…,Mn}, 测试用例属性Sk,S={S1,S2,…,Sk}, 属性对应的权重w={w1,w2,…,wk}。 将测试用例所有属性进行分词,然后进行onehot编码,则tik表示测试用例Mi在属性Sk上onehot编码为1的数量,从而可以将相似度计算转化为式(4)中的相似值
(4)
N(Mr,Mi)是指测试用例Mr(用户输入的内容)和测试用例集合中的Mi的相似值
N=max{N(Mr,M1),N(Mr,M2),…,N(Mr,Mi)}
(5)
N就是测试用例集合M中N(Mr,Mi) 的最大值,此时的Mi就是找到相似度最大的测试用例。例如,图4显示了测试用例相似度计算的一个例子,其中图4(b)是用户输入的数据,可以根据用例标识、用例描述、测试类型、需求追溯等多种属性来计算测试用例的相似度。根据图4(b)中的信息,找到用户需要的测试用例,也就是从知识图谱中找出相似度最大的测试用例。从图4(b)中可以看出用例描述属性中的关键字“指令”、“故障”、“命令”的多个属性特征都与图4(a)相同,虽然关键字“发送”在图4(a)和图4(b)中的用例描述中都能找到,但是该关键字是无效关键字,因为其上下文明显不一致,所以在计算相似度时不会考虑该关键字。根据式(4)和式(5),求得图4(b)、图4(a)之间的相似度为12.34%,大于图4(b)、图4(c)之间的相似度4.98%。

图4 测试用例相似度计算示例
3 实 验
在本节中,首先对实验数据进行介绍,然后描述实验的评价指标,最后对实验结果进行分析。
3.1 数据描述
本文实验中的所有数据来源均为南昌航空大学软件学院软件测评中心,拥有64个软件项目,23 212个测试用例。数据格式为半结构化的测试文档,最终将半结构化的数据转为结构化的数据。
3.2 评价指标
为了更加全面的评价TCRKG,本文从3个方面对模型进行评价。首先是模型的准确度,要精准找到用户想要复用的测试用例,问题模板的精度就非常重要,因为那是找到好的测试用例的关键,因此本文通过3个广泛使用的指标:精确度(Precision)、召回率(Recall)和F1测量标准来对问题模板匹配的精度进行评价,并将改进后的朴素贝叶斯与改进前的朴素贝叶斯进行性能对比。其次,为了检测知识图谱的效率,通过和传统构建测试用例库的方法进行比较,通过检索时间,和搜索复杂度两个指标来进行评价。最后,为了检验本文中TCRKG在实践中的有效性,设置A、B两个对照组,分别对4个软件S1,S2,S3,S4进行软件测试,A组使用本文中的测试用例复用方法,作为对照组,B组使用传统测试用例库的方法。最终以测试用例复用数量,和找到缺陷的个数作为评价指标。
3.3 实验结果
3.3.1 模型精度

图5、图6、图7显示了朴素贝叶斯分类模型改进前和改进后的Precision、Recall、F1值的对比。就精确度而言,从图5中可以看出朴素贝叶斯改进后的精确度都要优于改进前的精确度,朴素贝叶斯分类改进前精确度平均为90.05%,改进后为94.09%,精确度平均提高了4%。图6中朴素贝叶斯改进后的召回率都要大于改进前的召回率,朴素贝叶斯分类改进前召回率平均为76.60%,改进后为83.76%,召回率平均提高了7%。图7中朴素贝叶斯改进后的F1都要大于改进前的F1,朴素贝叶斯分类改进前召回率平均为82.84%,改进后为88.51%,F1值平均提高了6%。从整体上来看,模板5和模板12的Precision、Recall、F1值都偏低,其原因是因为模板5和模板12的样例数量相比于其它模板的数量要少很多,所以导致这两种问题模板所占特征偏少。因此本文通过自定义词典和给问题类别加权值的方法对朴素贝叶斯进行改进,有效改善了此类问题对分类结果的影响,并且整体性的提高了朴素贝叶斯的分类性能。
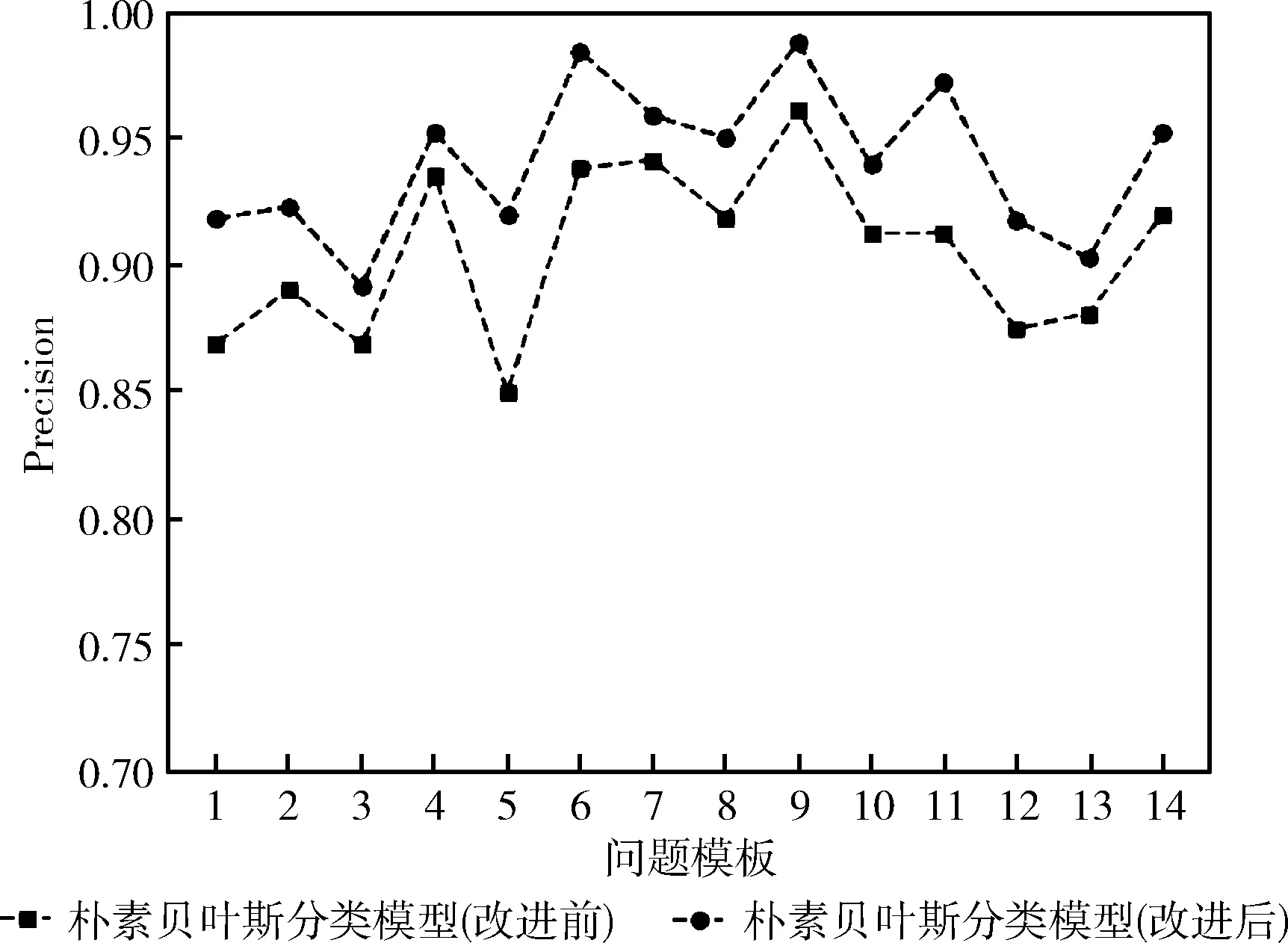
图5 精确度对比
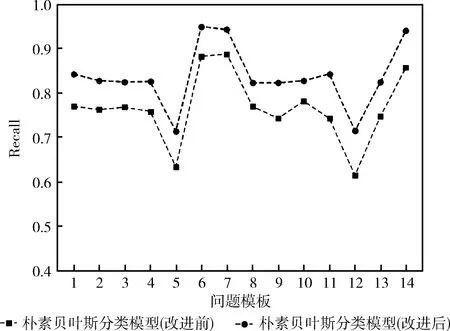
图6 召回率对比

图7 F1值对比
综上所述,通过添加自定义词典和给问题类别设置权值的方法可以有效解决问题模板样例数量相差较大所带来的影响,并且可以有效提高朴素贝叶斯分类模型的准确率,为提高测试用例复用奠定了基础。
3.3.2 检索效率
为了验证知识图谱的检索效率,本文从复杂度和时间消耗两个方面进行对比,复杂度是指两种方案解决同一个问题数据库需要进行多少步骤。对14种问题模板分别进行5次实验,将5次实验的平均数据作为时间消耗值。
图8和图9展示了传统用例库与知识图谱检索复杂度比较,为了更加直观比较两种方法复杂度的大小,本文将传统用例库每种问题模板的复杂度都归一化到1,然后知识图谱的复杂度以传统用例库复杂度大小为基准,复杂度越大,表示执行步骤越多,效率越低。可以看出,传统测试用例库的复杂度都比知识图谱的复杂度大,这就间接表明通过知识图谱进行检索的效率高。
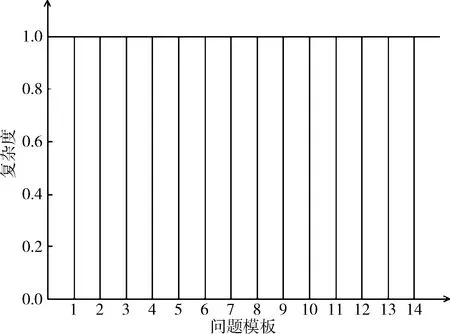
图8 传统用例库复杂度
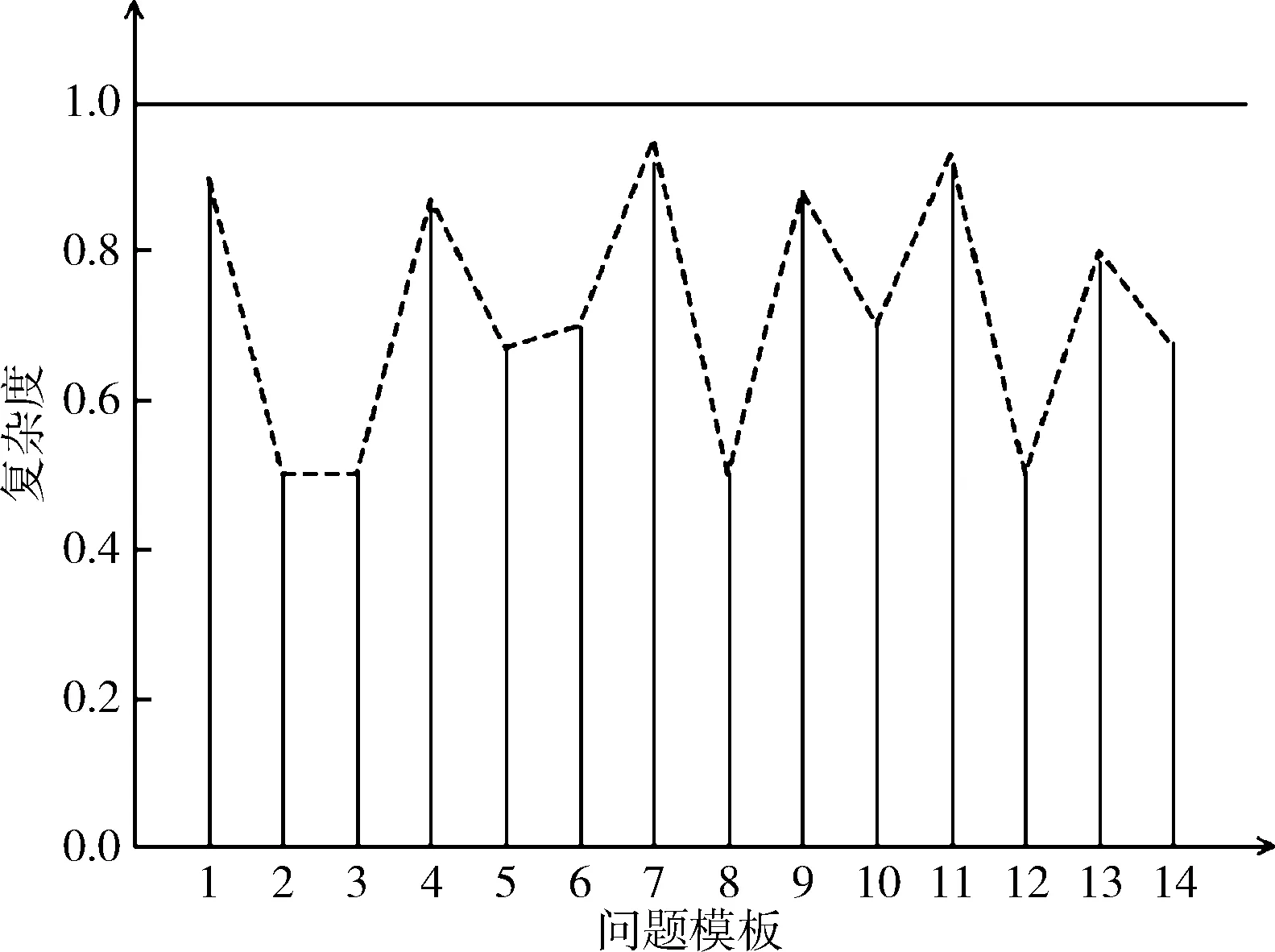
图9 知识图谱复杂度

图10 传统用例库与知识图谱检索时间消耗比较
综上所述,无论是从复杂度还是从时间消耗来看,基于知识图谱的方法检索效率都要优于基于传统测试用例库的方法。
3.3.3 实践对比
为了检测TCRKG在实际中的使用效果,由软件测评中心组织测试人员测试4个软件S1,S2,S3,S4,设置A、B对照组对4个软件进行测试。为了尽可能排除测试人员所带来的影响,A、B两组人员都是同年级学生,本科接受课程教育相同。A组为使用基于知识图谱复用方法,作为对照组,B组是基于传统用例库的方法。
图11显示了两种方法测试用例复用数量的对比,A组明显比B组复用的测试用例要多,平均高于B组20%~30%。
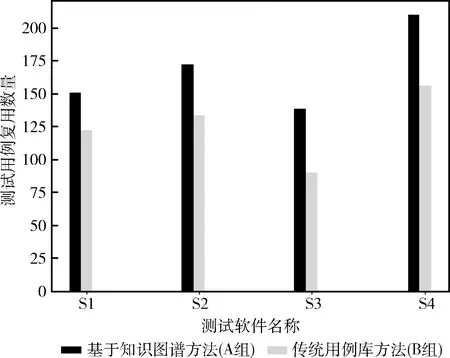
图11 测试用例复用数量
如图12所示,展示了S1,S2,S3,S4这4个软件的真实缺陷数量和基于传统用例库、基于知识图谱复用方法测试到正确的缺陷数量。4个软件的缺陷类型主要为接口问题和功能问题缺陷,其中90%的缺陷都在以往的测试中被典型测试用例发现过。A组测试出将近2/3的真实缺陷数量,而B组测试出的数量在1/3~2/3之间。不仅如此,由于A组使用的是基于本文中的复用模型,可以更加准确复用需要的测试用例,而B组只能根据少量关键字进行匹配,不能精准找到用户需要的测试用例,所以在耗时方面,A组大约只使用了B组一半的时间。通过实践对比,验证了本文的测试用例复用方法确实能够减少测试人员花费的时间,并且提高了软件缺陷的发现率。

图12 缺陷数量对比
综上所述,通过A、B两组对4个软件S1,S2,S3,S4进行测试的对照实验来看,A组也就是本文中基于知识图谱的测试用例复用方法能够复用更多的测试用例,发现更多的软件缺陷。
4 结束语
针对传统测试用例复用方法的不足,本文提出了一种基于知识图谱的测试用例复用方法。该方法首先利用已有文档提取结构化数据,构建知识图谱,从而获得了与测试用例相关的上下文信息;然后在测试用例匹配过程中,基于朴素贝叶斯分类模型和问题模板,明确用户的检索意图;最后利用相似度计算确定最佳的测试用例。实验结果表明,TCRKG比传统测试用例复用方法具有更高的推荐准确度。TCRKG不仅能够挖掘测试用例的潜在信息,还能将传统用例库中孤立的测试用例进行关联,达到“1+1>2”的效果。而本研究的不足点就是没有考虑测试用例的语义信息,在进行相似度计算的时候没有将测试用例的语义信息考虑在内。所以我们下一步工作就是将测试用例的语义信息加入到知识图谱中。
