基于高斯特征均衡的改进图像修复模型
2022-05-20李维LIWei
李维 LI Wei
(西南交通大学,成都 611730)
0 引言
数字图像修复是指利用数字图像已知区域修补未知区域的技术,是计算机视觉领域中极具挑战性的研究课题。随着社会数字化发展,图像修复技术在生活、娱乐、安防和医疗等领域都具有广泛的应用价值[1]。
图像修复技术早期使用基于物理和数学的传统方法。该类方法基于图像信息冗余性理论,利用前后帧的领域信息来填充未知的待修复区域。
传统修复方法在纹理简单、语义性单一的修复任务中表现优秀,但对于诸如人脸、动物、建筑等破损图像结构复杂的修复任务则表现不佳,因为无法从数学或者图形学的方法重建图像的语义。基于深度学习的图像修复具备较好的学习能力,能够学习其他图像的先验知识,通过训练模型,生成原图中没有的形状和纹理。
最初基于深度学习的图像修复网络采用自编码方式,用已知区域像素信息重新编码再解码生成缺失内容。PATHAK等人[2]提出了结合GAN(Generative Adversarial Network,生成式对抗网络)的思想,通过生成器和判别器对抗来提高修复质量。IIZUKA等人[3]使用了局部和全局的双判别器WGAN,增加了GAN修复模型训练的稳定性。Yu J等[6]结合了注意力机制的思想,在自编码的双阶段网络中加入了内容注意力机制CA(Contextual Attention)的模块。基于内容注意力机制的修复模型能从背景区域选择更相似的补丁块来填充缺失区域,从而提高生成图像的语义完整性,但对于结果容易出现模糊、伪影、暗沉等问题。
在后续的研究中,Yu J等[4]认为自编码网络中,一般卷积会使提取的特征包含破损区域的无效像素;而局部卷积虽能够提取有效特征,但由于缺乏对掩码的处理手段,在深度神经网络层会出现丢失掩码信息的问题。Yu认为促使生成图像具有暗沉、伪影等问题来自于此,为此,该研究提出了一种门控卷积模块。门控卷积在普通卷积的基础上增加了一倍的权重用于学习掩码信息,同时对掩码加上软门控的Sigmoid函数,通过卷积保留掩码信息,从而屏蔽无效像素对特征的影响。Zeng等[7]加入了特征金字塔的结构,旨在从不同特征尺度下处理图像的特征信息,使生成图像在细节表达更清晰,从而减少模糊、伪影。但这些方法仅在图像特征的利用效率上优化模型,使得模型的参数增多,增加了网络结构的复杂度,加大了模型的计算量。
本文提出了一种基于双边滤波的特征融合的思想,对Yu等人的CA模型中注意力分数的计算方式进行改进,从而使图像在特征利用上能够同时获取最大注意力分数的背景块以及其周围块的建议,使生成的图像在局部和全局有更强的一致性,从生成的角度解决模糊、伪影问题。
1 相关工作
1.1 基于内容注意力机制的感知模型
Yu J等人[5]提出了一种基于内容注意力机制的方法来生成图像缺失部分。作者采用基于自编码的双阶段网络结构,在第二阶段网络部分加入了基于上下文注意力机制的感知模块,该模块使用图像的背景区域的特征分块作为卷积核,对缺失部分进行转置卷积生成缺失图像,沿着通道方向利用余弦相似性计算每个特征块和前景区域的相关性分数,以此作为注意力分数进行反卷积生成精修图像。该论文中作者使用注意力感知模块有效地利用了背景区域的相似特征来逐像素修补缺失区域,使用基于局部和全局的WGAN[8](Wasserstein GAN)判别器进行训练,使得生成前景具有局部和全局的语义一致性。但使用余弦相似性作为修补区域每个像素点的相关性分数导致生成的前景特征像素之间缺乏相关性,使得修复区域的图像在结构特征上缺乏全局一致性,在生成图像上缺乏正确的语义表达。
1.2 基于特征均衡的双边滤波函数
Liu H等[6]在U-Net结构[11]的网络提出了基于结构约束的特征均衡修复网络。作者认为以往的论文对于修复任务没有很好地融合图像结构特征和纹理特征来生成缺失部分,导致生成图像在局部的语义表达上不完整,直观表现在生成图像的结构、纹理模糊。因此,作者提出了在编码解码的过程中,对图像特征加入纹理和结构特征来提高修复图像的质量。在纹理特征中,该模型使用了SE-Block的通道方向的注意力模块来均衡纹理特征;而在结构特征的均衡上,作者提出了类似双边滤波函数,该函数使用值域(range)和空间域(spatial)两个分支对结构特征做均衡。其中值域分支融合前景区域每个特征点和周围3x3区域的像素信息;空间域分支则是使用高斯分布加权融合全局的特征点来生成前景的特征点。这种均衡方法有效地融合了前景像素和相邻像素之间的特征信息,有利于生成图像的结构表达。
1.3 基于高斯特征融合的改进内容注意力模块
受双边滤波函数的启发,本文注意到,CA模块契合了特征均衡中对纹理特征的均衡思路,而在CA模型中,没有很好地解决对结构特征的均衡,简单地逐像素点的选取相似度较大的背景块将破坏前景区域的特征结构,因此,本文在CA模块中加入了对前景和背景特征的融合边。通过在内容注意力模块中加入基于高斯分布函数的全局特征像素融合的方法来增强修复图像与全局图像的语义一致性,从而提高修复结果的直观效果。
1.3.1 修复模型结构
本文章选用Yu等人的CA模型作为模型框架。模型分两个修复阶段。模型的一阶段网络基于自编码网络的结构,对破损图像进行编码、解码生成一张模糊的粗略修复结果。该阶段的网络由6块卷积层(K5S1C32*1,K3S1C64*2,K3S2C128),4块空洞卷积模块(K3D8S1C128*4)以及5块转置卷积层(K3S1C128*2,K3S1C64,K3S1C16,K3S1C3)构成。
模型的二阶段为基于改进CA模块的精修网络。该阶段将前一阶段生成的模糊图像和掩码信息分别通过两个分支:分支1将通过6块卷积块(K5S1C32,K2S2C64,K3S1C64,K3S2C128),改进的内容注意力模块以及2块转置卷积块(K3D8S1C128*4);分支2将通过5块卷积块和4块空洞卷积块。最后将两个分支生成的特征图进行拼接进行转置卷积生成最后的输出图像。分支一的作用是使用注意力方法均衡背景特征生成可靠的前景建议,而分支二则是对粗修结果进行进一步编码来融合背景和模糊前景的特征。
1.3.2 基于高斯分布特征融合的改进注意力分数
本论文的内容注意力模块使用改进的注意力分数。其计算公式加入了以每个像素点自身出发通过二维高斯分布函数获得的所有背景块的建议分数Px,y,x′,y′。如公式(1)所示,其中bx′,y′为图像特征的背景区域的特征块,j为特征块中的特征像素点,xj和yj分别代表该像素点的坐标,公式(1)使用二维高斯分布函数算出特征块bx′,y′中各个点对于前景特征点的权值后取平均值作为特征块bx′,y′对于前景fx,y的补正注意力分数。补正后的注意力分数为公式(2)所示,其中Sx,y,x′,y′为前景fx,y与bx′,y′背景的余弦相似分数,如公式(3)所示。
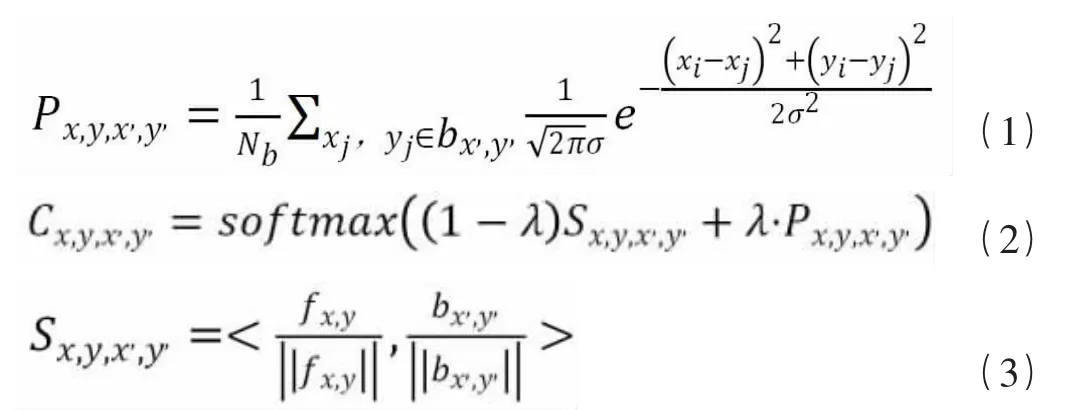
1.3.3 基于特征融合的内容注意力模块
本论文在内容注意力模块中加入改进补正的标准化内积计算前景区域每个像素点的注意力分数。改进的内容注意力模块首先提取待修复区域并作为前景区域,将背景区域划分成等大小的背景块(Patch),使用公式(1)计算每个背景块与前景区域中每个像素点的平均高斯分数,并将该分数作为当前像素点位置的特征融合分数。同时,使用背景块和前景区域进行卷积,得到包含所有背景块在每个前景像素点位置的原注意力分数的特征图。最后,如公式(2)所示,根据像素点位置将原注意力分数特征图与特征融合分数相乘,得到补正的注意力分数特征图。不同于原论文中提出的感知偏移(Attention Propagation),使用特征融合能够在不使用额外的卷积计算得到不同背景块的相邻块的高斯分数作为其感知分数。同时,采用高斯分布计算权重也能有效地提高图像的一致性,同时在训练过程提供更加丰富的梯度。
2 实验与结果
本模块在CelebA-HQ[9]人脸数据集和Paris Street View[10]街道数据集两个数据集上进行了评估。其中,CelebA-HQ是一个通过高分辨率GAN加工的CelebA的人脸数据集,该数据集总计30,000张人图片,每张图片的分辨率都是1024*1024,将其中26752张图片作为训练样本,余下图片中选择2688张图片作为测试样本。Paris数据集是由6412张巴黎街道图片组成的数据集,本实验将其中随机5760张图片作为训练样本,余下图片中随即选择640张图片作为测试样本。本实验模型在不同数据集上均训练同等的50个周期,根据实验的硬件内存大小将batch设置为64。
实验在CelebA-HQ人脸数据集的验证集上计算了平均l1误差和平均l2误差、平均峰值信噪比(PSNR)和结构相似性(SSIM),这些数据都是常用的图像修复质量评价指标。并采用不同覆盖程度的随机掩码在CelebA-HQ测试集上对上述的Yu等人,Zeng等人以及本文的算法进行实验。
在低覆盖率(<30%)掩码的修复任务上,三种算法在上述指标表现相当,其中Zeng等人的算法SSIM指标最高,本文的算法平均SSIM为90.2%,平均PSNR值达到了34.79dB。随着掩码覆盖率的增高,三种算法的PSNR和SSIM指标有所下降,在高覆盖率掩码的实验中,本文算法具有最优的PSNR值和SSIM值,平均PSNR为28.0dB,平均SSIM为86.74%。造成这一现象的原因是,在小面积缺失的任务中,三种算法对于图像修复的水平相当,而随着缺失区域的增大,Yu等人的修复网络没有很好地解决细节修复的问题;而Zeng等人的算法通过不同尺度的特征处理,可以在低层的特征结构中处理更丰富的纹理细节,在更高层的特征结构中处理更抽象的语义,在大面积缺失的修复任务中,仍然具有较好的PSNR和SSIM指标;本文的算法则是使用了融合全局特征的方式,让每一个背景块融合相邻块的特征,在通过注意力分数较大的块进行修复像素的同时也参考了周围其他块的建议,能更好地替代Yu等人提出的感知偏移(Attention Propagation)的效果,使得修复区域在亮度、对比度上具有更为符合周围像素的表现。
图1是Paris Street View数据集下本文算法的修复效果展示,在该数据集下,本文章使用大量随机的小掩码来遮盖街道图片中的一些边缘结构;图2是在CelebA-HQ验证集下对3种算法部分的修复结果对比展示;图3是通过消融实验分析来对比改进前(CA模型)和改进后(本文章模型)对修复区域的像素修补情况,本文章使用了与Yu等人相同的方法来生成前景区域的染色图,该染色图的色块显示了每个前景特征像素来自背景区域位置,可以看出,加入后在相邻像素之间颜色变化更小,说明像素之间的关联性增大了。

图1 改进算法在Paris验证集上的修复效果

图2 Cel ebA-HQ上三种算法的主观修复效果

图3 改进内容注意力模块消融实验对比
3 结论
本文提出了一种基于特征融合思想的改进内容感知的图像修复模型,该模型从融合图像特征的角度出发,针对现有网络生成图像的细节模糊、伪影的问题,通过使用高斯分布函数计算每个像素点到各个背景块的距离,并以距离作为权重融合相邻背景块的特征信息,使模型能够更生成局部结构更清晰,与周围像素更连贯的结果,经实验结果验证本算法在客观数据上达到了颇为优秀的水平,主观修复结果符合人类视觉的需求。本文为讨论改进的内容注意力模块的修复效果,在修复网络的网络结构部分仍沿用了Yu等人(2018)的Deepfill-v1的框架,在一些大面积缺失任务上依旧会存在伪影问题,未来将在本文提出的改进内容注意力模块的基础上,在修复网络的结构的优化上做进一步的研究,此外,具有人机交互,可以通过人为输入干预的修复结果的风格的网络模型同为本文的进一步的研究和改进方向。
