融合异质信息网络表示学习的跨领域推荐研究
2022-05-19冯翠翠
易 明,刘 明,冯翠翠
(华中师范大学信息管理学院,武汉 430079)
1 引 言
当前,个性化推荐的应用主要局限在单一领域,即:根据某一领域(如图书领域、音乐领域等)的用户数据获取其兴趣偏好,并据此开展面向该领域的个性化推荐。然而,单一领域的个性化推荐不可避免地受到数据“稀疏性”和用户“冷启动”等问题的影响。事实上,很多互联网平台所涉及的领域是多样化的。以豆瓣网为例,它同时涉及书籍、电影、音乐等多个领域,由此会产生不同领域的用户数据。不同领域的用户数据并不都是随机的,可能会蕴含着许多潜在的模式,例如,喜欢推理类图书的用户,可能也对推理类电影非常感兴趣。这种在不同领域内具有潜在相似的模式使得跨领域推荐成为可能。所谓跨领域推荐就是利用源领域的用户数据实现目标领域的个性化推荐,其本质就是将源领域已有的知识迁移到目标领域,一方面可以缓解目标领域数据“稀疏性”、用户“冷启动”等问题,另一方面可以构建更为优化的推荐模型。现有的大部分跨领域推荐的工作都只使用了用户对物品的评分信息。在领域评分数据高度稀疏的情况下,仅利用评分信息无法有效识别用户的真实兴趣偏好,尤其是在领域内用户完全没有数据的情况下,很可能导致跨领域推荐知识迁移的偏差以及“负迁移”的状况。除了评分信息以外,现实世界还存在大量的物品特征信息,利用这些特征信息可以捕捉用户高阶的潜在偏好,进而提高跨领域推荐中知识迁移的效果。然而,这种复杂的高阶特征关系往往难以建模。考虑到异质信息网络表示学习可以将领域内的各种实体映射为低维稠密的向量进行输出,且能够捕捉到这种高阶相似,对跨领域推荐中知识迁移具有较好的适用性,因此,本文试图将异质信息网络表示学习与跨领域推荐有机融合,并开展相应的研究探索。本文的主要贡献如下:
(1)优化了联合矩阵分解。传统的联合矩阵分解在跨领域推荐场景中共享了用户的潜在因子,导致提取到的用户特征没有体现出充分的领域性,从而出现“负迁移”,为此本文利用神经网络实现联合矩阵分解,通过“映射函数”将用户特征映射到不同领域,体现领域间的差异性。
(2)提出了一种新的跨领域推荐方法。该方法同时利用评分信息和特征信息,在神经网络优化联合矩阵分解的基础上,融合了异质信息网络表示学习的高阶特征,从而达到充分利用领域知识的目的,有效缓解了单领域推荐中存在的数据“稀疏性”和用户“冷启动”问题。
2 相关研究
2.1 跨领域推荐
跨领域推荐的实质就是借助源领域用户数据优化目标领域的推荐性能。从目前的研究现状来看,具体的优化路径主要包括缓解数据“稀疏性”和用户“冷启动”两个方面。
在缓解数据“稀疏性”问题方面,Berkovsky等[1-2]将多个领域的评分矩阵直接合并,从而在推荐过程中引入了更多的领域信息,进而利用协同过滤完成跨领域推荐;Li 等[3]对源领域用户和物品分别进行聚类,通过引入“密码书”形成聚类后的“浓缩矩阵”,由此将源领域的知识迁移到数据稀疏的目标领域;Singh 等[4]提出了将相关联的矩阵进行联合分解的方法,从而使矩阵分解适用于跨领域推荐,通过联合矩阵分解获取不同领域间的潜在特征,有助于解决目标领域的数据“稀疏性”;陈文珺等[5]利用领域中的用户-物品评分矩阵,分别对多领域用户和物品进行潜在特征提取,并将用户-物品特征向量分别进行特征聚类,同时对多领域特征矩阵进行领域适应融合,得到共享知识模型并进行迁移学习,提高了目标领域推荐性能;Zhu 等[6]提出了一种基于迁移学习和深度学习的跨领域推荐方法,在评分矩阵分解的基础上利用深度学习映射不同域的特征,并用域内评分稀疏性指导参数的学习;Gao 等[7]将注意力机制引入跨领域推荐,以项目级注意力层和域级注意力层区分不同项目以及领域的重要性;Hu 等[8]和 He 等[9]提出的 CoNet(cross networks) 利 用 NCF (neural collaborative filtering)组成三个隐层和两个交叉单元,其中NCF 是矩阵分解在神经网络上的广义扩展,因此,CoNet 充分利用了用户和物品之间的非线性交互关系;Vijaiku‐mar 等[10]改进了 CMF (collective matrix factorization),并用堆栈自编码器优化领域内用户和物品的特征表示,使模型同时具有矩阵分解和深度学习的优点。
在缓解用户“冷启动”问题方面,Kazama 等[11]通过构建用户对物品的评分网络,利用word2vec 得到不同领域用户的特征向量,然后学习一个线性映射函数将源领域用户特征映射到目标领域,从而可以完成目标领域“冷启动”用户的推荐;Man 等[12]提出的 EMCDR (embedding and mapping framework for cross-domain recommendation) 算法通过评分矩阵进行矩阵分解得到特征向量,进而利用多层感知机学习了重叠数据的非线性映射,取得了比之前线性映射更好的效果。
由上文不难发现,目前大多数跨领域推荐算法主要利用的是评分信息,而对于源领域和目标领域所包含的其他特征信息,如电影的导演、图书的作者等,都没有充分融入跨领域推荐算法。评分信息的“稀疏性”是个性化推荐中无法避免的问题,过于稀疏的信息会导致用户兴趣识别的偏差,进而降低推荐效果。在跨领域推荐中也是如此,虽然能够通过知识迁移获取其他领域的知识,但领域内兴趣识别的不充分性会增加知识迁移的误差。解决此问题的关键是将领域内实体之间的相似性进行高阶扩散,从简单的一阶关系扩展为高阶关系。特征信息可以作为相似性扩散的桥梁,从不同的特征角度出发,获取具有不同语义的相似性度量,能够有效缓解兴趣识别偏差问题,有利于提高跨领域推荐知识迁移的准确性。
2.2 网络表示学习
网络表示学习是一种将网络中节点的结构信息和属性信息用低维稠密向量形式表示的一种技术。传统的网络表示一般使用高维的稀疏向量,但高维稀疏向量在使用统计学习方法时存在诸多局限,学者们转而探索将网络中节点表示为低维稠密的向量表示的方法[13]。Perozzi 等[14]提出的 DeepWalk 算法通过随机游走的方式产生训练语料,利用word2vec的思想,学习节点表示。Grover 等[15]在DeepWalk 的基础上提出了node2vec,并引入了偏置参数,在随机游走的过程中运用了宽度优先搜索和深度优先搜索的策略,指导语料的生成。然而,DeepWalk 和node2vec 都只考虑了一阶相似性。Tang 等[16]提出的LINE(large-scale information network embedding)算法考虑了二阶相似性,认为两个节点的共享邻居越多,则两个节点存在的相似性越高,并利用不同的目标函数保存网络的一阶相似性和二阶相似性;Wang 等[17]提出的SDNE (structural deep network em‐bedding)算法将有监督学习的拉普拉斯矩阵和无监督学习的自编码器进行结合,分别捕捉一阶相似性和二阶相似性,提出了一种半监督学习方法来学习节点的表示。然而,这些经典的网络表示学习方法都只针对同质网络。
异质信息网络是一种特殊类型的网络,由多种类型的节点、链接关系以及属性信息组成,具有大规模、异质性等特点[18]。针对异质信息网络,学者们提出了相应的网络表示学习方法。Chang 等[19]针对不同类型的节点进行向量表示,然后将所有的向量映射到相同的空间,从而让向量有了相同维度的表达。Dong 等[20]提出了metapath2vec 算法,先通过元路径指导随机游走,再用Skip-Gram 训练节点序列产生节点嵌入向量。在元路径的基础上,Zhang等[21]提 出 的 MetaGraph2Vec 算法 ,以 及 Zhao 等[22]提出的FMG(factorization machine with group)算法,利用元图的方法代替元路径,弥补了元路径不能获取部分语义的缺陷。Fu 等[23]提出了HIN2Vec 算法,采用完全的随机游走的策略选取训练集,通过神经网络模型预测两个节点是否存在特定的关系,同时学习异构网络中节点和元路径的向量表示。异质信息网络表示学习的优越特性使其在各种场景都得到了广泛的应用。例如,刘云枫等[24]构建由作者、论文、出版物等节点组成的异质信息网络,利用元结构提取语义,有效提高了学者推荐的准确性;林原等[25]构建了作者-作者、作者-机构、作者-关键词、机构-关键词的异质信息网络,利用DeepWalk 得到节点低维向量,最后通过向量的相似度计算实现合作对象、合作领域挖掘;Zheng 等[26]通过元路径提取异质信息网络中的多种相似性,通过将相似性加入损失函数的正则项,提高了推荐算法的准确性;Shi 等[27]在传统矩阵分解的基础上,加入了异质信息网络表示学习的特征向量,取得了比传统矩阵分解更好的效果;肖璐等[28]用网络表示学习的方法将网络中的知识单元表示成低维稠密的向量,其中知识单元网络可以视为一个异质信息网络,最后以丁香园心血管论坛为例,挖掘了社区网络中多元知识的联系。
针对当前跨领域推荐存在的一些问题,利用异质信息网络表示学习,可以得到用户和物品的嵌入向量,不仅保存了异质网络的结构特征,而且低维稠密的向量能够很好地完成推荐任务。更重要的是,通过异质网络表示学习得到的低维稠密向量包含了领域中丰富的特征信息,将这些特征信息在源领域和目标领域加以利用,可以同时达到缓解数据“稀疏性”和用户“冷启动”的目的。
3 融合异质信息网络表示学习的跨领域推荐模型
基于上文的分析,本文提出一种融合异质信息网络表示学习的跨领域推荐模型。该模型主要由两个模块组成:异质信息网络表示学习和评分预测。其中,异质信息网络表示学习模块提供一个异质网络表示学习框架(如图1 所示),可以针对源领域异质信息网络和目标领域异质信息网络,通过元路径、DeepWalk 算法生成网络表示学习向量,获取领域内的特征信息。评分预测是跨领域推荐的核心模块,此部分由一个复杂的神经网络架构组成,在神经网络中借用了联合矩阵分解(CMF)[4]的思想,以此获取领域内的评分信息。具体来说,神经网络共享了源领域和目标领域的用户嵌入,用多层感知机(multilayer perceptron,MLP) 将共享用户嵌入映射到不同领域,一方面体现了用户在不同领域的差异性,另一方面对于在某一领域有数据而在另一领域没有数据的“冷启动”用户,可以通过映射函数将其映射在冷启动领域,从而完成面向“冷启动”用户的推荐。同时,神经网络融入了源领域和目标领域的物品异质特征信息,并以损失函数为依据,采用梯度下降的方法学习模型的参数,从而完成最终的评分预测。
3.1 异质信息网络表示学习
定义异质信息网络为G=(V,E)。其中,V代表领域内节点集合(如用户、物品、物品的特征等),E是领域节点之间边的集合,每条边代表各个节点之间的关系。网络模式是对异构信息网络的元描述,表示为S= (A,R),其中,A为节点类型,R为链接类型[14]。考虑到异质信息网络包含有大量复杂的、异质的结构关系信息,其中的冗余信息(如特征节点与特征节点之间的关系)便成为了节点表示学习的“噪音”。由此,需要引入元路径过滤掉此类冗余信息,并将异质信息网络表示学习问题转换为同质信息网络表示学习问题,在降低学习难度的同时有效排除“噪音”,进而利用经典的DeepWalk算法进行特征信息的学习。
元路径是在网络模式上的一条路径P=其中,A为节点类型,R为链接类型,R=R1∘R2∘ … ∘Rl,∘表示关系上的合成算子。给定一条元路径P,便可计算节点的连接矩阵,计算方法[22]为

其中,WAi,Aj表示节点类型Ai到Aj的邻接矩阵。不同的元路径会产生不同的连接矩阵,每个连接矩阵都可以视为一个同质网络。针对每个同质网络,采用经典的DeepWalk 算法进行学习。DeepWalk 算法在网络中随机游走产生训练语料,然后用Skip-Gram 进行训练,目标函数[14]为

其中,Φ:V→Rd是一个将每个节点映射到d维空间上的函数;Nv⊂V表示在给定一个元路径下节点v的邻居。
通过不同元路径生成的同质信息网络有着不同的语义信息。这些语义信息是异质信息网络中所包含信息的子集,是排除了“噪音”信息之后的关键信息。将其输入DeepWalk 中能够得到体现各自语义的向量,此时,多个同质信息网络之间的关系就演变成了多个向量之间的关系,需要设置合理的融合向量的函数。用户对不同的语义应有不同的偏好,同时,向量之间的融合关系往往不是简单的线性关系,为了更好地拟合这种关系,个性化非线性的融合方法是相对较优的选择。因此,融合后节点v的异质特征信息向量ev[27]为
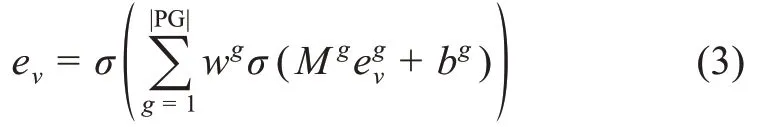
3.2 评分预测
评分预测模块是一个复杂的神经网络架构,借鉴了CMF 的思想。CMF 是传统矩阵分解的扩展,在源领域和目标领域含有重叠用户的情况下,将源领域和目标领域的评分预测用共享用户潜在因子cu、源领域物品潜在因子和目标领域物品潜在因子之间的点积进行计算。此时,用户u对源领域物品i的预测评分以及对目标领域物品j的预测评分分别为

由式(4)和式(5)不难发现,对于CMF,共享用户潜在因子cu同时参与两个领域评分预测的运算,没有体现出源领域和目标领域的差异性,可能导致“负迁移”。为此,本文借用CMF 共享用户特征的思想构建神经网络,借用神经网络强大的灵活性,引入了映射函数MLP 来体现领域的独有特征,同时,为了充分利用领域内物品特征信息,还对物品异质特征信息向量进行联合计算,最终完成评分预测,如图2 所示。

图2 融合异质信息网络表示学习的神经网络架构
3.2.1 用户和物品的评分向量表示
建立评分向量查询层,将用户和物品的0/1 编码转换为评分信息向量,即用户和物品的评分信息表示。以源领域为例,给定一个用户u和物品i,表 示 它 们 的 0/1 编 码 , 评 分向量查询层以参数矩阵表 示用户和物品的评分信息向量,其中,d表示向量的维度,|U|和|I|分别表示用户和物品的数量。向量查询操作实现为

其中,cu为共享用户向量,为源领域物品i的物品评分信息向量,分别代表了用户和物品的评分特征。
3.2.2 共享用户嵌入的映射
以源领域为例,在查询到共享用户向量cu之后,cu并不直接参与和的点积运算,而是通过MLP 的映射函数将cu映射到源领域,得到源领域用户评分信息向量以此突出不同领域的差异性。同时,对于在某一领域完全没有数据,而在另一领域有数据的用户,通过映射函数就可以实现其在“冷启动”领域的推荐,完成知识的迁移。除此之外,映射函数的引入抛弃了CMF 中必须是相同维度的前提,增强了模型的灵活性。
同理,对于由公式(3)计算得出的物品i的异质特征信息向量ei,MLP 将cu映射到相应空间得到与ei进行计算。之所以不在异质信息网络表示学习模块直接学习的表示,是因为对于一个领域内完全没有数据的用户来说,直接学习会导致模型无法进行“冷启动”用户的推荐。综上,其计算方法为

3.2.3 评分预测
评分预测由两部分组成。第一部分为用户和物品的评分特征的点积,借鉴了CMF 的思想,代表了用户和物品评分模式的特征;第二部分为用户和物品异质特征信息向量的点积,物品异质特征向量由领域内的异质信息网络表示生成,代表了领域内丰富的领域物品特征信息。最终的预测评分由二者求和计算得出。据此,用户u对源领域物品i的预测评分为
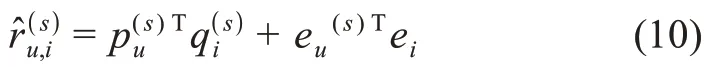
同理,用户u对目标领域物品j的预测评分r̂(t)
u,j为

3.2.4 模型训练

4 实验分析
4.1 数据集
实验数据集来自豆瓣网的电影和图书两个领域,主要包括用户的评分数据和物品特征信息。其中,评分数据是用户对某一物品的评分,评分范围为1~5;物品属性主要包括图书的作者、出版商,以及电影的演员、导演、类型、地区。用Python 的Scrapy 框架编写爬虫程序,采用滚雪球的策略,随机选取一批种子用户并抓取其数据,在此基础上,从种子用户的关注或粉丝列表中获取更多的用户,不断递增。在获取数据集之后,分别删除电影和图书领域评分数量少于10 的用户;同时,对于那些只在单一领域内有评分行为的用户,无法对其推荐结果进行验证,因此将这部分用户删除。豆瓣网数据集最终的基本统计信息如表1 所示。由于电影领域相比于图书领域的数据稀疏程度较低,因此,将电影领域视为源领域,图书领域视为目标领域。

表1 豆瓣网数据集的基本统计信息
4.2 实验设置
实验主要分为两个部分。第一部分为推荐效果的实验,评分数据不包括在某一领域内没有评分行为的用户,即全部为“热启动”用户。随机移除一部分用户的评分作为测试集,剩下的作为训练集,训练集的比例分别为80%、60%和40%。第二部分为“冷启动”效果的实验,将图书领域视为目标领域,随机选取了一定比例的用户,保留其电影领域的数据,移除他们在图书领域的全部评分数据,作为图书领域的完全“冷启动”用户参与实验,冷启动用户比例分别为10%、30%和50%,即锚用户比例分别为90%、70%和50%。实验环境CPU 为Inter(R) Core(TM) i7-8750H@2.20GHz, GPU 为 NVIDIA GeForce GTX 1060 6G,RAM 为 16G,并采用 Ten‐sorFlow 编写算法。以上实验分别做5 次,最终的数据结果为5 次实验的平均值。
在参数设置方面,经过多次实验,最终确认参数为:共享用户特征向量、源领域和目标领域评分信息向量的维度都为64;根据文献[12,27],融合后的异质特征信息向量的维度为64,MLP 和非线性融合函数都为包含一层隐藏层的神经网络,隐藏层神经元的个数为128,其中MLP 的隐藏层的激活函数为tanh,非线性融合函数隐藏层和输出层激活函数都为Sigmoid 函数,学习速率为0.0001,正则化参数λ为0.01,由于学习速率较低,迭代次数为3000 次。
在元路径的选择方面,先分别构造了图书领域和电影领域的异质网络。在图书领域,提取了以图书开头和结尾的元路径;同理,在电影领域,提取了以电影开头和结尾的元路径。不同的元路径代表了不同的语义,例如,元路径“BUB”表示两本书被同一用户阅读,代表了两本书在用户层面的相似性。本实验所使用的元路径和代表的语义如表2所示。

表2 豆瓣网数据集的元路径及其语义
4.3 对比模型和评价指标
为了验证本文方法的有效性,将选择一系列对比模型进行效果对比。总体上说,对比模型分为单领域推荐模型和跨领域推荐模型。单领域推荐模型用来证明本文模型可以有效提升推荐效果;跨领域推荐模型则用来证明本文模型能更有效地迁移源领域数据,从而缓解目标领域的数据“稀疏性”和用户“冷启动”问题。由此,本文选择了以下6 种模型作为对比模型。
(1) PMF (probabilistic matrix factorization)[29]:概率矩阵分解,经典的单领域矩阵分解算法,将某个领域的评分矩阵分解为用户矩阵和物品矩阵,从而预测缺失评分。
(2)CDCF-U(user-based cross-domain collabora‐tive filtering)[30]:基于用户的跨领域协同过滤模型,将多个领域视为同一领域进行矩阵合并,使用传统的基于用户的协同过滤进行评分的预测。
(3) CDCF-I(item-based cross-domain collabora‐tive filtering)[30]:基于物品的跨领域协同过滤模型,与CDCF-U 类似,将多个领域视为同一领域进行矩阵合并,使用传统的基于物品的协同过滤进行评分的预测。
(4)CMF[4]:联合矩阵分解,经典的跨领域推荐模型,将源领域和目标领域的评分矩阵进行联合分解,共享不同领域的用户矩阵,从而预测缺失评分。
(5)EMCDR[12]:解决“冷启动”问题的跨领域推荐模型,对用户评分矩阵进行分解,然后使用非线性映射函数进行领域间的知识迁移。
(6) NeuCDCF (neural cross-domain collabora‐tive filtering)[10]:一种新的跨领域推荐算法,利用用户对物品的评分,通过构建矩阵分解和深度神经网络两个模块进行评分预测。
其中,PMF 作为经典的单领域推荐方法,相关的研究成果与应用实践都取得了较好的效果[31],故将其作为对比模型验证跨领域推荐相比于单领域推荐的优越性;CDCF-U 和CDCF-I 将跨领域推荐问题简单转化为单领域推荐问题,可能导致“负迁移”,以此作为对比模型,可以有效验证本文模型的知识迁移能力;CMF 是一种经典的跨领域推荐方法,也是本文模型思想的基点,以此作为比对模型来验证CMF 改进后的推荐能力;EMCDR 是专门用于解决“冷启动”问题的跨领域方法,可以有效验证本文模型的用户“冷启动”的推荐效果;NeuCDCF 是一种新的跨领域推荐模型,可以进一步检验本文模型的跨领域推荐能力。
考虑到本文是对评分进行预测,故选择RMSE(root mean squared error) 和MAE(mean absolute er‐ror)作为评价指标,计算公式分别为

其中,Test 为测试集;ru,i为用户u对物品i的实际评分;r̂u,i为用户u对物品i的预测评分。MAE 衡量的是预测评分与实际评分的绝对误差的平均值;RMSE 是预测评分与实际评分之间平方差异的平均值,然后再取平方根。RMSE 和MAE 越小,代表预测评分与实际评分的差异越小,推荐准确性也越高。从总体上来说,RMSE 和MAE 的趋势一致,但RMSE 受异常值影响更大。
4.4 实验结果
1)推荐效果实验结果
表3 列出了6 种模型在不同领域和训练集比例下得到的RMSE 和MAE。总体来看,CDCF-U 模型和CDCF-I 模型取得的推荐效果较差,甚至不如单领域推荐的PMF 模型;CMF 模型虽然能够在图书领域超越PMF 模型,但提升幅度并不大,在电影领域还取得了相反的效果;NeuCDCF 是CMF 和堆栈自编码器的结合,因此在推荐效果上优于CMF,但NeuCDCF 只用了评分信息,无法充分获取用户偏好和领域知识。本文模型的推荐效果均优于以上方法,与5 种对比模型相比,RMSE 和MAE 降低的百分比如表4 所示。同时,由于本文模型融入了异质信息网络表示学习获得的表示向量,包含丰富的物品特征信息,对于数据量较少的物品或用户来说,可以通过这部分特征信息补充评价数据的缺失,使得不同训练集比例下RMSE 和MAE 结果的变化幅度较小,进一步表明本文模型的优越性。

表3 6种模型推荐效果实验结果的比较

表4 本文模型与5种对比模型相比推荐效果的RMSE和MAE降低的百分比 %
2)用户“冷启动”实验结果
表5 列出了6 种模型在用户“冷启动”方面的RMSE 和MAE。总体来看,CDCF-U 模型和CDCF-I模型表现依然较差;CMF 模型本质上是一种线性算法,所以在用户“冷启动”方面效果不能尽如人意;EMCDR 模型作为非线性映射算法,在两个领域之间学习了一个非线性映射函数,针对“冷启动”用户具有较好的应用价值;NeuCDCF 在“冷启动”方面表现优异,仅次于本文模型。本文模型在用户“冷启动”方面都优于以上模型,与5 种对比模型相比,RMSE 和MAE 降低的百分比如表6 所示。同时可以看到,随着“冷启动”用户比例的上升,所有模型的RMSE 和MAE 结果都有明显的提升,说明锚用户的数量在各个模型中起到了举足轻重的作用。

表5 6种模型用户“冷启动”实验结果的比较

表6 本文模型与5种对比模型相比用户“冷启动”的RMSE和MAE降低的百分比 %
4.5 元路径分析
不同的元路径代表了领域内不同的语义特征。本节将从推荐效果和用户“冷启动”两个方面探讨元路径对模型的影响。
在推荐效果方面,结果如图3 所示。总体来说,在不同训练集比例下,不管是RMSE 还是MAE,加入元路径的模型都比不加入元路径的模型要低,这一结果符合元路径能有效提高推荐效果的猜想。但电影领域RMSE 和MAE 的下降幅度比图书领域大,这是因为电影领域数据较为稠密,在加入更多的特征信息后推荐效果能得到较大幅度提升;而图书领域数据相对稀疏,虽然能够在一定程度上提高推荐效果,但幅度不大。

图3 是否加入元路径在推荐效果上的对比
在用户“冷启动”方面,将图书领域的部分用户设为完全“冷启动”用户,结果如图4 所示。与上文类似,RMSE 和MAE 都有一定程度的下降。对于一个在图书领域完全没有数据的“冷启动”用户来说,一方面通过MLP 的映射,将电影领域的知识迁移到图书领域,可以使用户在图书领域也能取得较好的推荐效果;另一方面,元路径的特征知识也能为冷启动用户提供数据支持,从而比没有元路径的模型效果更好。
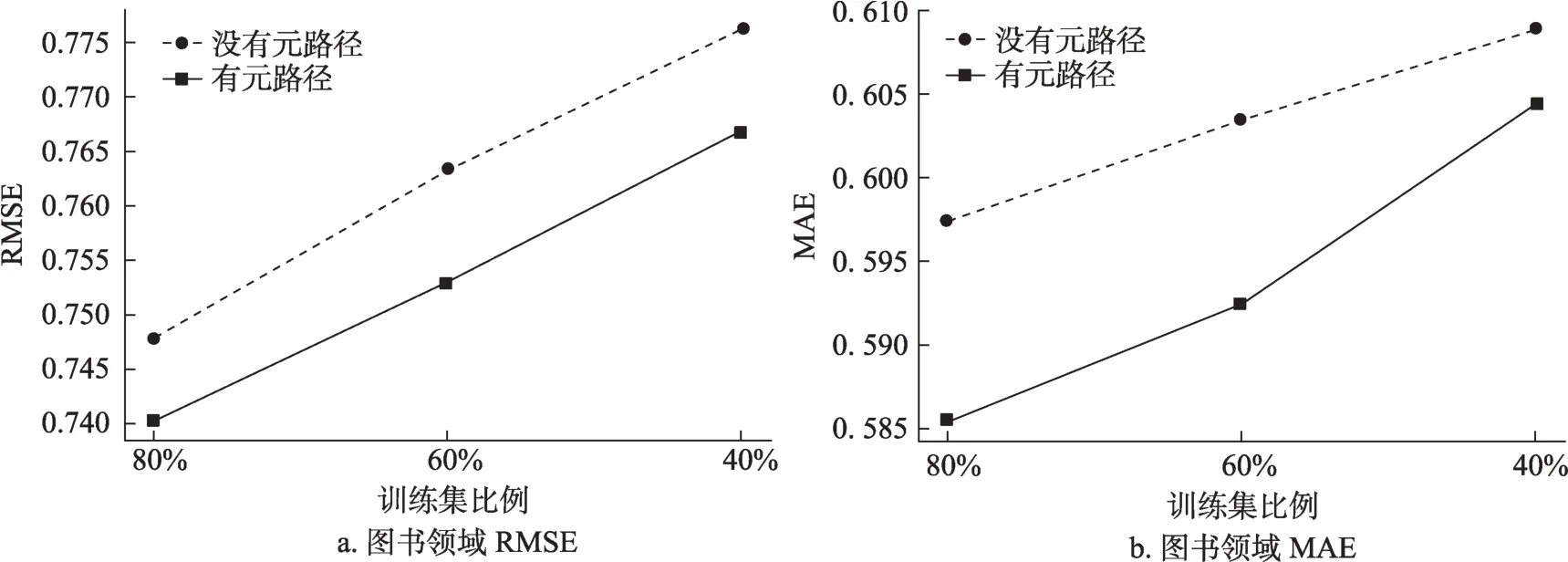
图4 是否加入元路径在用户“冷启动”上的对比
4.6 特征维度分析
本文模型的特征维度主要包括共享用户特征嵌入cu的维度(CK)、源领域评分信息向量的维度(SK)、目标领域评分信息向量的维度(TK)、源领域异质特征信息向量和ei的维度(SHK)、目标领域异质特征信息向量和ej的维度(THK)。其中,SHK 和THK 的维度根据文献[22]设为64,本节主要探讨CK、SK 和TK 的最优参数设置。
CK 的维度特征决定了SK 和TK 的特征表示。先将CK、SK 和TK 设为相同维度,取值范围为{8,16,32,64,128,256},试图找出最优的CK 值,其结果如图5 所示。当CK、SK、TK 的维度都为64 时,图书领域和电影领域的RMSE、MAE 同时达到最小,因此,CK 的最佳维度为64。

图5 CK、SK、TK取值相同情况下不同领域的RMSE和MAE
在CK 维度为64 的情况下,分别对SK 和TK 的参数进行调整,取值范围为{8,16,32,64,128,256},结果如图6、图7 所示。当SK 和TK 同时取值为64时,图书领域和电影领域的RMSE 和MAE 达到最小。从上述结果可以发现,不管是共享用户潜在因子还是不同领域内特有的用户潜在因子,RMSE 和MAE 随着特征维度的增加均呈现出先上升后下降的趋势;同时,电影领域相对于图书领域受到参数调整的影响较小,这是由于电影领域评分数据量较多,数据的“稀疏性”不明显,而图书领域评分数据量小,受参数调整影响大。

图6 不同SK、TK取值下电影领域的RMSE和MAE(CK=64)

图7 不同SK、TK取值下图书领域的RMSE和MAE(CK=64)
4.7 模型普适性分析
以上实验所使用的电影、图书领域的数据集相关性较高,且只针对豆瓣网一个平台,不足以突现本文模型的普适性。为此,本节以Amazon 平台的电影和唱片领域为例,将电影领域作为源领域,唱片领域作为目标领域,进一步验证模型的普适性。Amazon 数据集的基本统计信息如表7 所示。
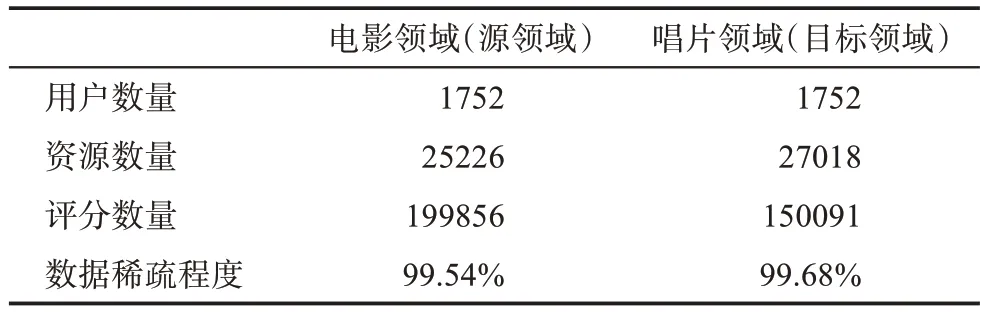
表7 Amazon数据集的基本统计信息
在元路径的选择方面,考虑到Amazon 数据集的特征信息较少,可用的特征信息仅包括品牌、价格、种类,其中价格和种类所包含的标签较少,无法体现出差异性,所以仅使用品牌作为特征信息。本实验所使用的元路径和代表的语义如表8所示。

表8 Amazon数据集的元路径及其语义
与上文相同,本实验也分为推荐效果实验和用户“冷启动”实验。在推荐效果实验中,同时删除电影领域和唱片领域20%的用户评分数据作为测试集,剩余80%的评分作为训练集来学习模型参数;在用户“冷启动”实验中,随机挑选20%的用户,删除其在唱片领域的所有评分数据,作为唱片领域的完全“冷启动”用户参与测试。实验参数与第4.2 节中的设置相同,最终实验结果如图8、图9所示。
从图8、图9 可以看出,在Amazon 数据集上,不管是推荐效果还是用户“冷启动”效果,本文模型评分预测的准确性都是最高的。对比豆瓣网的电影领域和图书领域,Amazon 的电影领域和唱片领域关联性明显更低,且数据稀疏程度更高,容易出现“负迁移”。在推荐效果方面,CMF 完全共享用户特征的机制导致推荐效果不理想,而NeuCDCF和本文模型都设置了用户独特的领域特征,出现“负迁移”的可能性更低,因此推荐效果更好;在用户“冷启动”方面,EMCDR 作为专门处理“冷启动”问题的跨领域推荐方法,其前提是要求两个领域之间的用户存在一种映射关系,在电影和唱片领域关联性不大的情况下,用户行为特征差异也较大,因此EMCDR 拟合出的映射关系误差大,导致推荐结果较差。总的来说,Amazon 数据集的实验结果充分说明了本文模型的普适性。

图8 Amazon电影领域和唱片领域的推荐效果对比

图9 Amazon唱片领域的用户“冷启动”效果对比
5 结 语
针对当前跨领域推荐存在的相关问题,本文提出了一种融合异质网络表示学习的跨领域推荐模型。该模型同时利用领域内的评分信息和特征信息,采用神经网络架构,优化了传统跨领域矩阵分解,利用非线性映射函数体现不同领域的差异性,同时还将物品属性特征以异质信息网络表示学习的形式融入跨领域推荐中,达到了有效利用领域间丰富特征信息的目的,从而进一步缓解了数据“稀疏性”和用户“冷启动”的问题。研究结果表明,本文模型在提高推荐效果和优化用户“冷启动”方面比现有相关模型更具有优越性和稳定性。然而,本文模型也存在一些不足,尤其是在算法设计过程中,需要学习的参数过多,导致算法时间成本较高。因此,在今后的研究中,应继续优化适用于个性化推荐的异质信息网络表示学习方法,在保留异质网络中信息的基础上,简化异质信息网络表示学习的步骤;还可以进一步深入研究多领域推荐方法,将单一的辅助领域扩展到多辅助领域,进而从不同的领域获取更多的领域知识,增强模型的表达能力。
