一种变粒度缺陷报告严重程度预测方法
2022-05-19贾焱鑫濮雪莲
贾焱鑫,林 浩,陈 翔*,濮雪莲,葛 骅
(1.南通大学 信息科学技术学院,江苏 南通 226019;2.南通大学 经济与管理学院,江苏 南通 226019)
软件内存在的缺陷会给项目带来不可预知的风险。当前,项目通常会利用缺陷跟踪系统(bug tracking system)来搜集和维护缺陷报告。其中,按照缺陷报告的严重程度进行优先级排序,并尽早修复高风险缺陷是降低项目风险的一种可行手段。然而,精准设置缺陷报告所对应的严重程度并不容易。由于受到缺陷报告提交者的能力和经验等多方面因素的影响,当提交者对严重程度的设置不重视,或者没有足够的信心时,在提交缺陷报告时经常会选择默认取值(即normal),因此,normal 取值并不能真实反映缺陷报告所对应的实际严重程度。除此之外,由于不同提交者对缺陷报告严重程度的理解并不完全相同[1],因此即使是遇到了同一缺陷,不同提交者在提交缺陷报告时也可能会设置不同的严重程度。上述问题的存在,使得提交者不得不人工审查项目缺陷报告严重程度的准确性。而缺陷报告严重程度的评估工作专业性较强,需要有经验的提交者投入大量的时间和精力,因此,构建高质量的缺陷报告严重程度预测模型[2],对节约人力和提高软件项目质量具有重要的研究意义。
目前,研究人员针对缺陷报告严重程度预测问题,一般将其建模为粗粒度分类问题(即二分类问题)或细粒度分类问题(即多分类问题)。具体来说,二分类问题是以严重程度normal 为界限,将超过normal 程度的类型归为一类;低于normal 程度的类型归为另一类。由于二分类问题的粒度较粗,因此构建出的分类模型通常可以取得不错的分类性能。而多分类问题则可以直接预测出缺陷报告所对应的具体严重程度类型,因此可以根据多分类的预测结果,更准确地确定缺陷修复的优先级[3]。但多分类问题一般受到训练数据集规模的不足、数据集内存在的类不平衡问题等因素影响,导致构建出的分类模型的分类性能不理想。基于上述分析,不难看出粗粒度分类与细粒度分类各有优势和不足,并互为补充,因此本文提出变粒度预测(variable granularity bug report severity prediction,VG-BSP)方法。变粒度指随着预测阶段的改变,对模型预测粒度和预测性能的需要产生的变化,对在不同阶段中所采用的预测粒度进行的改变。具体来说:首先对新缺陷报告进行基于二分类的粗粒度划分,然后根据二分类的结果进一步细分(即基于多分类的细粒度划分)。即先使用粗粒度二分类预测模型将缺陷报告所对应的严重程度分为严重或不严重两大类,然后使用细粒度多分类预测模型在已预测出的两大类严重程度结果基础上,继续细分严重程度的类别。与已有的多分类方法相比,VG-BSP 方法的优势在于可以利用粗粒度二分类的高准确性,并在一定程度上缓解直接使用细粒度多分类所带来的低准确性问题。
本文选择来自实际开源项目的缺陷报告(来自Eclipse 的两个子项目JDT 与CDT 的缺陷报告和来自Mozilla 项目的缺陷报告)[2,4],并分别设置了粗粒度类别和细粒度类别,与逻辑回归(logistic regression,LR)方法、K 近邻(K-nearest neighbors,KNN)方法、决策树(decision tress,DT)方法、随机森林(randon forest,RF)方法、支持向量机(support vector machine,SVM)方法等经典细粒度分类方法进行比较。基于macro-F1 指标,VG-BSP 方法的性能平均可提升19.6%。除此之外,研究还发现,采用LR 方法作为VG-BSP 方法的分类方法、采用Spacy 词向量作为文本建模方法,可以使得VG-BSP 方法取得最好的预测性能。
1 相关工作和研究背景
1.1 相关工作
Tan 等[5]通过从Stack Overflow 网站中提取缺陷相关问题贴和回复贴,来对缺陷报告的内容进行扩充,在此基础上使用逻辑回归算法预测缺陷报告所对应的严重程度,最终在预测性能上超过了基准方法中效果最好的朴素贝叶斯方法。Sharma 等[4]认为模型性能可能会因为缺陷报告的严重程度在修复过程中产生的变化而受到影响,同时认为缺陷报告的优先级、评论数量等属性也应当被纳入考虑范围,最终基于上述两点提出了基于支持向量机、朴素贝叶斯和k 近邻等算法的分类模型;Chaturvedi等[6]尝试分析了朴素贝叶斯、K 近邻、支持向量机等算法在NASA 项目中的缺陷报告严重程度预测的适用性,并使用各种性能评测指标进行了验证。Lamkanfi 等[7]比较了4 种著名的文本挖掘算法(朴素贝叶斯、朴素贝叶斯多项式、K 近邻和支持向量机)之间的准确性及所需训练集的规模。Menzies 等[8]则基于标准的文本挖掘方法和机器学习方法提出了一种高效的缺陷报告严重程度预测方法SEV ERIS。Lamkanfi 等[9]则利用来自Mozilla、Eclipse 和GNOME 3 个开源项目的缺陷报告,验证了在规模足够大的训练集上,使用文本挖掘方法是行之有效的。Tian 等[10]则转换了研究思路,尝试预测缺陷报告所对应的具体严重程度,提出了一种基于BM-25 文本相似度计算公式的自动化预测方法,并在细粒度严重性预测方面超越了基准方法。刘文杰[11]针对严重性实证分析问题和严重性预测问题,分别提出了缺陷报告严重性影响分析框架、面向领域特征的粗粒度严重性预测方法和基于特征序列重构的细粒度严重性预测方法,提升了细粒度严重性定量预测方法的性能。王婧宇等[12]则在相关工作的基础上对基于分类的严重程度预测方法进行了总结,提炼了技术框架,并对框架中的主要步骤进行了介绍。
1.2 对文本内容的建模
缺陷报告的摘要是一种非结构化文本,目前将非结构化数据转为机器学习方法可处理的数据格式,需要对文本内容进行建模,常用的文本建模方法有以下4 种:1)Spacy 词向量,由Python 第三方工业级自然语言处理库Spacy 支持,基于OntoNotes 5和GloVe Common Crawl 数据集训练生成的685 000个300 维词向量;2)Word2Vec 词向量,是使用Word2Vec 模型中的Skip-gram 模型训练生成的,可用来表示单词对之间的关系的词向量;3)BOW 词向量,是使用词袋模型表示法,通过构建基于数据集的不重复单词集合,从而将每句话表示成单词集合中各单词在该句子内的出现次数所组成的向量;4)TF-IDF 词向量,是根据一个词在单份语料中出现的次数与在语料库中出现的频率来判断一个词语的重要性,并在此基础上生成的词向量。
1.3 缺陷报告的粒度设置
本文分析的开源项目都使用Bugzilla 这一缺陷跟踪系统来维护缺陷报告。与已有研究工作[9]保持一致,在粗粒度二分类问题中,我们将blocker、critical、major 这3 种缺陷报告严重程度归为严重类别;将minor、trivial、enhancement 这3种缺陷报告严重程度归为不严重类别。
在细粒度多分类问题中,在粗粒度二分类得到的预测结果为严重程度时,则将借助对应细粒度多分类模型,进一步细分为blocker、critical 或major 类型。在粗粒度二分类得到的预测结果为不严重程度时,则将借助对应的细粒度多分类模型,进一步细分为minor、trivial 或enhancement 类型。
2 变粒度缺陷报告严重程度预测方法
本节首先给出了文本预处理方法,随后给出本文所提出的变粒度缺陷报告严重程度预测(variable granularity bug report severity prediction,VG-BSP)方法的实现细节,包含了变粒度操作的实施流程与具体操作规则。
2.1 文本预处理
缺陷报告的摘要是文本,因此需要对其进行文本预处理。首先将文本进行分词;其次借助停用词列表过滤掉停用词,停用词是指在文本中经常出现,但含有极少文本信息的高频词(例如英语中的the,at,which,on 等);然后对分词进行规范化,即去除词缀得到单词对应的词根,例如,将effective 规范为effect;最后利用Spacy 词向量文本建模方法针对该摘要信息进行文本建模。
2.2 方法过程细节分析
2.2.1 训练粗粒度二分类预测模型
根据文本预处理后生成的词向量和缺陷报告中的严重程度粗粒度类别,采用二分类算法,构建粗粒度预测模型MC,预测缺陷报告对应的严重程度是否为严重。
2.2.2 训练细粒度多分类预测模型
通过训练粗粒度二分类预测模型,预测并得到准确度较高的粗粒度类型结果,以此为基础进一步训练细粒度多分类预测模型,即本文所提方法中的变粒度操作,从而保证在预测准确度较高的前提下进一步细化预测粒度。首先根据粗粒度类型将训练数据集细分为两个数据集,其中第一个数据集包含了blocker、critical、major 等3 种类型的缺陷报告,并基于多分类方法构建出细粒度分类模型MF1;第二个数据集包含了minor、trivial、enhancement 等3 种类型的缺陷报告,并基于多分类方法构建出细粒度分类模型MF2。
2.2.3 模型组合
将粗粒度预测模型MC 与两个细粒度预测模型MF1、MF2 进行组合,构成最终的缺陷报告严重程度预测模型。VG-BSP 方法的整体框架如图1 所示。当面对新的缺陷报告时,先使用粗粒度预测模型MC预测其所对应的粗粒度类别,若粗粒度类别为不严重,则进入粗粒度为不严重所对应的细粒度预测模型MF1 进行细粒度的分类;若粗粒度类别为严重,则进入粗粒度为严重所对应的细粒度预测模型MF2 进行细粒度的分类。
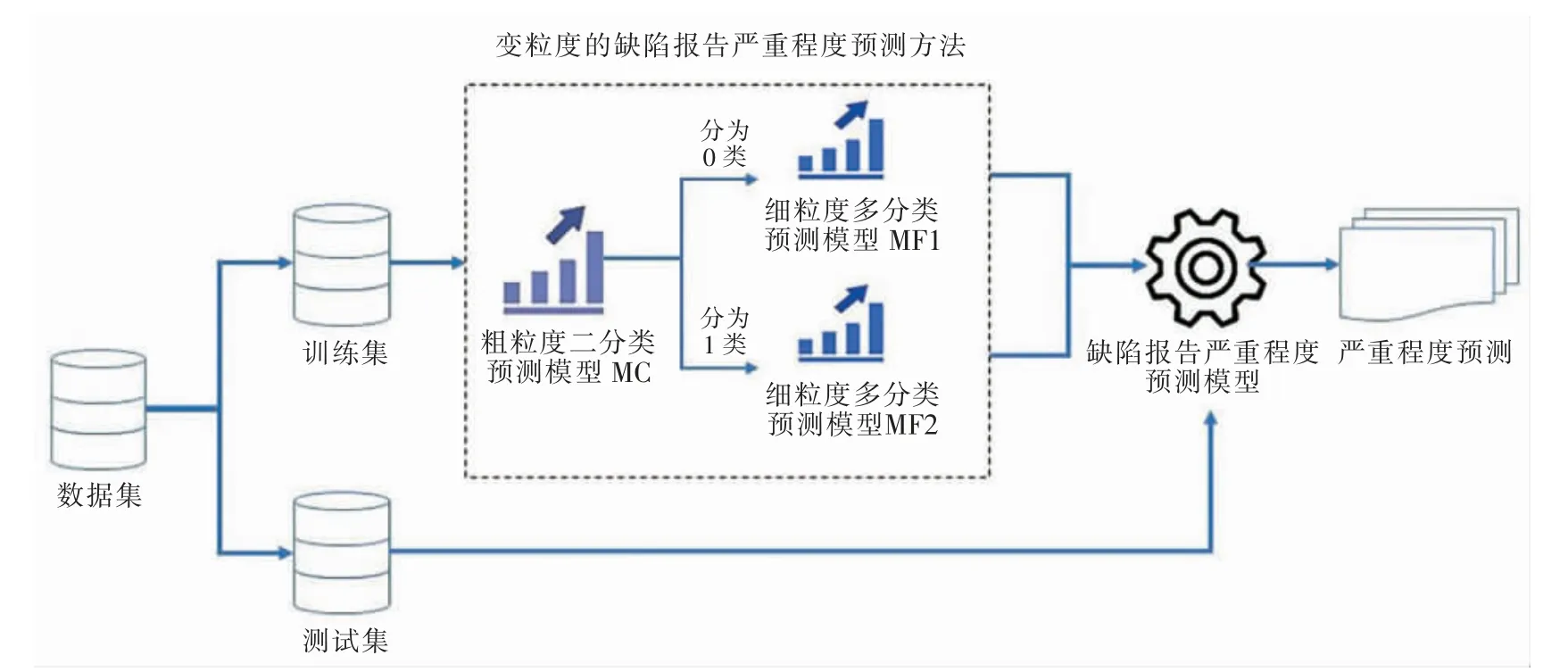
图1 VG-BSP 方法的整体框架图Fig.1 Overall framework of the VG-BSP method
3 实验设计
3.1 研究目的
为了验证本文所提VG-BSP 方法的有效性和方法内部设置的合理性,提出以下3 个研究问题:
RQ1 变粒度缺陷报告严重程度预测方法的性能是否优于现有的基准方法?
RQ2 不同分类算法对变粒度缺陷报告严重程度预测方法的性能影响如何?
RQ3 与其他文本建模方法相比,使用Spacy词向量是否能提高变粒度缺陷报告严重程度预测方法的性能?
3.2 评测对象
为了验证VG-BSP 方法的有效性,选择来自实际开源项目的缺陷报告数据集,包括来自Eclipse 的两个子项目JDT 和CDT 的缺陷报告及来自Mozilla项目的缺陷报告。其中JDT 子项目是Java 开发工具的简称,其作用是为高级用户提供工具插件;CDT 子项目是C/C++开发工具的简称,其提供了一个基于Eclipse 平台的功能完整的C 和C++集成开发环境。Mozilla 项目包含Core、Firefox、Thunderbird 等。
以上3 个项目采用Bugzilla 进行缺陷报告的管理,我们首先从Bugzilla 中搜集这些项目的历史缺陷报告,针对每一个缺陷报告,抽取该缺陷报告的摘要信息(summary)和严重程度(severity)这两个属性的信息,并构成数据集。数据集的统计特征如表1所示,包括项目的名称、总的缺陷报告数,以及不同缺陷严重程度对应的缺陷报告数。在以前的研究过程中,研究人员发现由于normal 被设置为缺陷报告严重程度标签的默认取值,因此一些对自己的经验和能力缺乏信心的提交者会将不符合normal 取值标准的缺陷报告默认标注为normal 类型[1]。在本研究工作中,我们认为引入normal 取值的数据很容易为数据集引入噪音,所以在数据集中去除了所有严重程度标签为normal 的缺陷报告。

表1 研究工作中使用的缺陷报告数据集的统计特征Tab.1 Statistical characteristics of the bug report datasets used in the study
3.3 评测指标
由于本文关注的问题是多分类问题,因此采用macro-F1 作为模型性能的评测指标。
macro-F1 指分别计算每个类别的F1 值,然后求均值。假设计算类别A 的F1 值,在属于类别A 的实例为正例,不属于类别A 的实例为反例的情况下,F1 值的计算公式为

其中:P 为查准率(Precision);R 为查全率(Recall)。计算公式为

该情况下对应的混淆矩阵,如表2 所示。
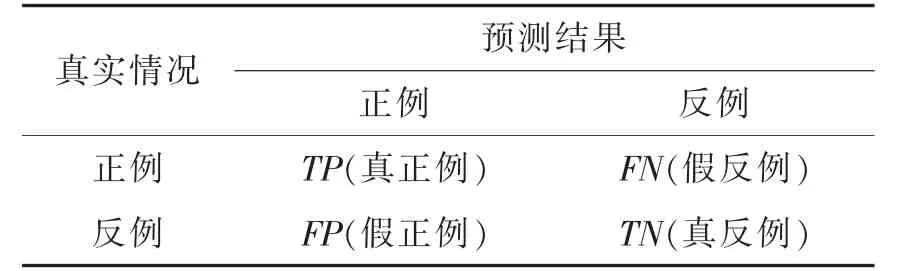
表2 分类结果混淆矩阵Tab.2 Confusion matrix of classification results
3.4 基准方法
本文所提方法通过粗粒度预测阶段得到二元分类结果,随后细化预测粒度,最终得到细粒度严重程度预测结果。因此本文主要选择已有的细粒度预测方法作为基准方法。在软件缺陷预测严重程度预测问题中,若建模为多分类问题时,逻辑回归[13]、K近邻[14]、决策树[15]等机器学习方法是目前主流的建模方法[16]。除此之外,额外考虑了随机森林[17]、支持向量机[18]等其他经典的多分类方法。
多分类任务的拆分策略有如下3 种:一对一、一对其余和多对多。在本文中,我们采用基于一对其余方式的多分类方法[19]。
除此之外,论文使用了第三方提供的成熟框架[16],主要基于Python 机器学习包scikit-learn 对如下基准方法进行了实现:
1)逻辑回归(logistic regression,LR)[13]一种对数几率模型,是离散选择法模型之一,属于多重变量分析范畴,是社会学、生物统计学、临床、数量心理学、计量经济学、市场营销等统计实证分析的常用方法。
2)K 近邻(K-nearest neighbors,KNN)[14]一种用于分类和回归的非参数统计方法,在这两种情况下,输入包含特征空间中的k 个最接近的训练样本。基于相同类别案例彼此相似度高这一原理并采用向量空间模型来实现分类的效果,借由计算与已知类别案例之间的相似度来评估未知类别案例的分类。
3)决策树(decision tree,DT)[15]在决策论中,决策树由一个决策图和可能的结果(包括资源成本和风险)组成,用来规划到达目标的路径。决策树是一种特殊的树结构,是一个包括随机事件结果、资源代价和实用性的利用了像树一样的图形或决策模型的决策支持工具,主要被用来辅助决策。决策树经常在运筹学中使用,特别是在决策分析中,它能帮助确定一个最可能达到目标的策略。
4)随机森林(random forest,RF)[17]在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别由个别树输出的类别的众数而定。随机森林天然可用来对回归或分类问题中变量的重要性进行排序。。
5)支持向量机(support vector machine,SVM)[18]在机器学习中,支持向量机是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM 训练算法将创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。除了进行线性分类之外,SVM 还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。
3.5 实验设置
为了合理评估本文所提VG-BSP 方法的预测性能,我们将数据集进行随机分层抽样,即针对事先已经标注好相应缺陷报告严重程度标签的数据集,依据各类数据在整体中所占的比例,确定从各类中抽取的数据数量,并进一步从中随机抽取样本数据,最终划分出整个数据集中70%的数据作为训练数据,并将剩余30%数据作为测试数据,以防止训练数据和测试数据产生数据重叠问题。为避免数据集划分过程的随机性,重复上述数据集划分方法10 次。为了确保实证研究的可重现,使用相同的随机种子,来完成数据集的10 次划分。
4 实验结果与分析
4.1 针对RQ1 的分析
在3 个数据集上分别使用基准方法进行预测,计算得到macro-F1 值,并与本文提出的方法结果进行比较,统计结果如表3 所示。与LR、KNN、DT、RF 和SVM 方法相比,在数据集JDT 上,本文提出的VG-BSP 方法在macro-F1 指标上最高可提升37.8%,最低可提升12.5%,平均可提升26.6%;在数据集CDT 上,VG-BSP 方法最高可提升33.5%,最低可提升4.6%,平均可提升18.7%;在数据集Mozilla上,VG-BSP 方法最高可提升19.9%,最低可提升7.4%,平均可提升13.3%。基于上述分析,可以看出,VG-BSP 方法的性能明显优于LR、KNN、DT、RF、SVM 方法,平均可提升19.6%。从原理上来解释,本文所提的VG-BSP 方法,首先应用预测性能较好而预测粒度较粗的粗粒度预测方法对数据集进行分类,在很大程度上确保了预测性能后又应用细粒度预测方法进一步地细化了预测粒度,最终得到了细粒度严重程度预测结果。本文所提VG-BSP 方法结合了粗粒度方法与细粒度方法的优点,弥补了各自的不足,因而整体表现优于直接采用细粒度预测策略的基准方法。
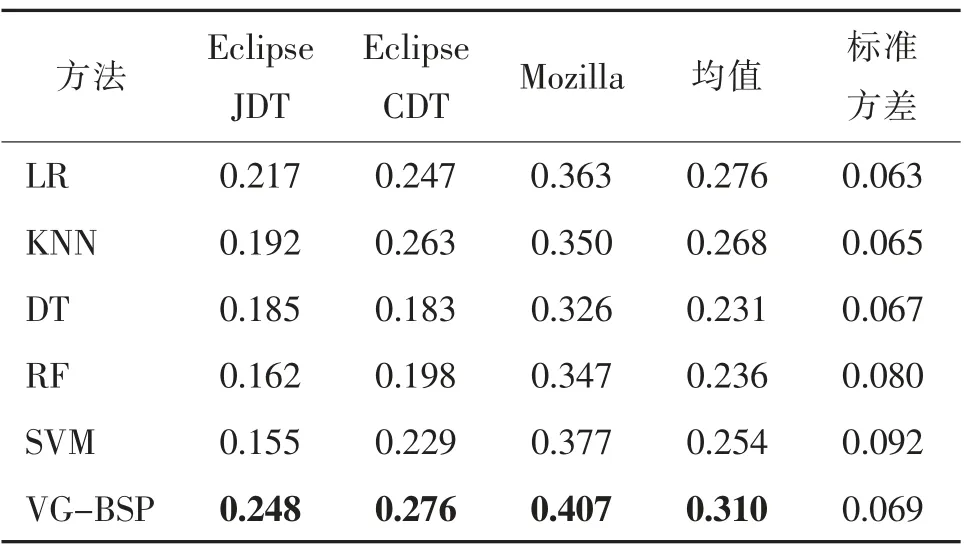
表3 VG-BSP 方法与基准方法的性能比较Tab.3 Performance comparison between the method VG-BSP and baselines
4.2 针对RQ2 的分析
在3 个数据集上分别使用6 种常用机器学习方法作为粗细粒度预测模型的分类算法,目的是验证并探寻是否存在一个分类方法,可以在本文提出的VG-BSP 方法中取得最好的预测性能,最终结果如表4 所示。总体来说LR 分类算法在VG-BSP 方法上可以取得最好的预测性能,尽管在Mozilla 数据集上,其性能稍弱于SVM 方法,但差距几乎可以忽略不计。因此,当VG-BSP 方法选择LR 分类算法时,模型的预测性能最好。
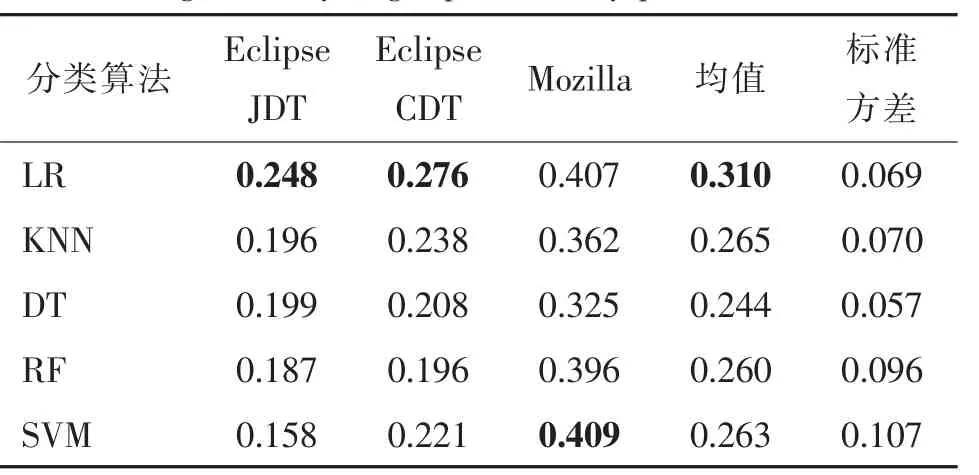
表4 不同分类算法对变粒度缺陷报告严重程度预测方法的性能影响Tab.4 Performance influence of different classifiers on variable granularity bug report severity prediction method
4.3 针对RQ3 的分析
由针对RQ2 的分析结果可知,基于LR 分类算法可使变粒度缺陷报告严重程度预测方法取得最好的性能。针对RQ3,我们尝试分析文本建模方法对VG-BSP 方法性能的影响。在3 个数据集上分别使用4 种常用文本建模方法对数据集的文本进行建模,并随后基于LR 分类算法来构建缺陷报告严重程度预测模型并计算得到macro-F1 值。最终结果如表5 所示,不难看出,Spacy 词向量在所有数据集上都可以取得最好的性能,因此我们选取Spacy词向量作为VG-BSP 方法的文本建模方法。
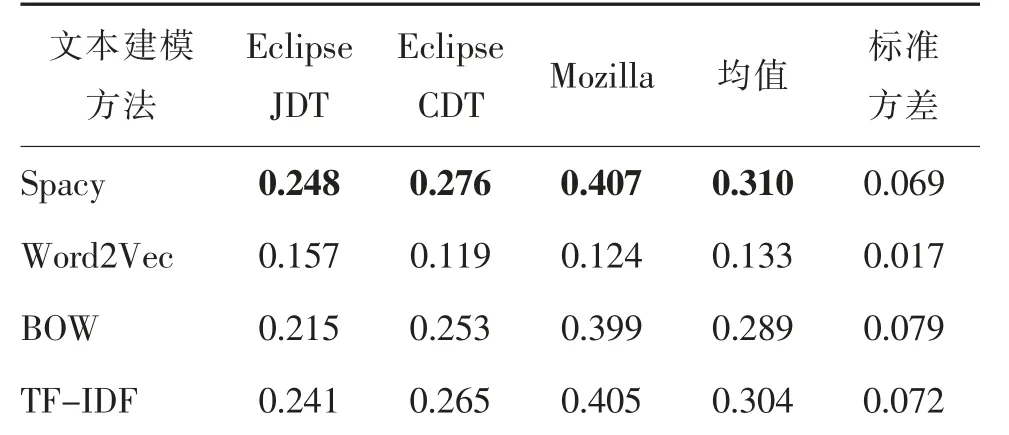
表5 不同文本建模方法对变粒度缺陷报告严重程度预测方法的性能影响Tab.5 Performance influence of different text modeling methods on variable granularity bug report severity prediction method
5 总结与展望
通过构建缺陷报告严重程度预测模型,可以有效地降低项目开发人员和用户面临的风险,节省提交者在缺陷报告严重程度设置上所花费的时间和精力。本文提出一种变粒度缺陷报告严重程度预测方法VG-BSP,尝试通过融合细粒度分类与粗粒度分类来兼顾预测的准确性与预测粒度,并基于实际大规模开源项目的缺陷报告,在macro-F1 指标上对VG-BSP 方法的有效性进行了验证。除此之外,还探讨了VG-BSP 方法内最优分类方法和文本建模方法的设置。
该方法仍然存在以下工作有待于今后继续研究:
1)尝试搜集来自其他开源项目的缺陷报告数据集,对论文结论的一般性进行进一步的探索和验证;
2)当前数据集内,不同严重程度类型的缺陷报告分布不均衡,即一些严重程度类型的缺陷报告数量很少。因此,如何引入类不平衡学习方法[20]来进一步提升模型的预测性能值得关注。
