基于深度全卷积神经网络的图像识别研究
2022-05-16姬壮伟
姬壮伟
(长治学院计算机系,山西长治 046011)
深度学习的深入研究,促进了领域的快速发展,图像识别是最先使用深度学习的领域之一。该领域的快速发展得益于可以收集庞大的数据集,搭建复杂的深度学习模型,以及GPU 计算能力的飞速提高。
当前的图像识别方法基本上都使用了深度学习方法,为了提高深度卷积网络的训练效率,我们借鉴当今最热的卷积网络参数少的优势,将图像识别网络中的全连接层都用卷积网络来替代。这种做法在不影响正确率的前提下,具有两个优势:一是提高了网络的灵活性,相比AlexNet[1],摆脱了对输入图像分辨率的限制,这是由于在网络后端用1*1的卷积替换了全连接层导致的;二是卷积网络是用卷积核在提取图像中的特征,因此可以将每一层卷积结果的特征图可视化,进一步加深对模型的理解并做出修正。
使用kaggle 猫狗大战[2]的数据集,带标签数据共25 000 张图像,网络结构采用全卷积网络结构,使用AlexNet 的预训练模型初始化前5 层卷积网络的参数,随机初始化后三层卷积网络,使用交叉熵作为训练的损失函数,用Adam 优化器[3]进行参数优化。数据集在第一部分做详细的说明,在第二部分将详细说明所使用的卷积网络模型细节,以及对第一层卷积和第二层卷积的可视化展示,第三部分则是对模型进行损失值记录分析,以及测试模型的分类准确率。第四部分对整篇论文的研究做总结。
1 数据集
kaggle 猫狗大战数据集分训练集和测试集两部分,训练集包含25 000 张猫狗图片,并具有标签,其中猫的数据集和狗的数据集各占一半,测试集共有12 500张,都不具有标签。使用训练集中的25 000张图片来做训练、验证和测试,其中训练集占80%,验证集占10%,测试集占10%。
该数据集的图像为三通道彩色图像,每张图像分辨率各不相同,因此在进行训练和测试时,将图像做如下预处理[4],先将图像短边缩放至256像素,长边做等比缩放,再上下左右以及中心将图像裁剪成5张224 图像,如图1 所示,这样做大大增加了数据的数量,避免过拟合的产生,提高了网络的泛化能力。
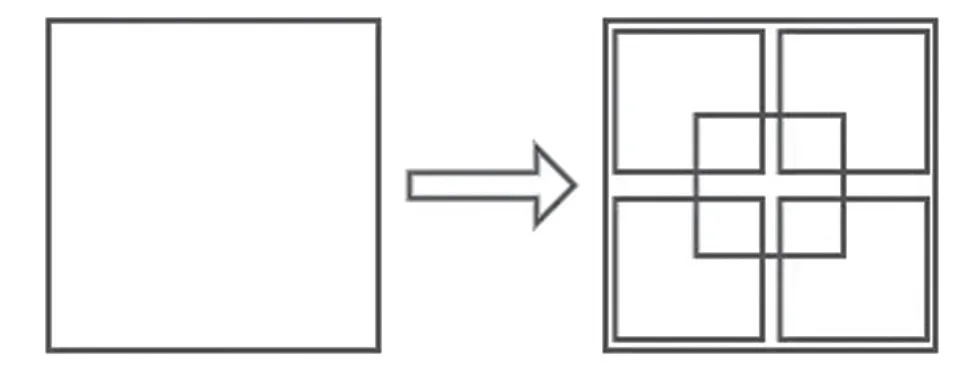
图1 图像预处理裁剪示意图
2 全卷积网络架构
2.1 架构
网络架构是对AlexNet 网络的进一步优化,具体包含八个卷积层,三个最大池化层,使用pytorch 进行搭建[5]。第一个卷积层使用96 个卷积核提取224×224×3 图像的基本特征,核大小为11×11,步长为4,后接最大池化层,第一层卷积得到的特征图输入到第二层,再使用256 个卷积核提取特征,核大小为5×5,步长为1,后接最大池化层,第3、4、5 卷积层互相连接,中间不插入池化层,3个卷积层都使用3×3的小卷积核,依次使用384、384、256个卷积核来形成目标特征图。
网络后三个卷积层是原网络全连接层[6]的替代,如图2 所示,第6 层卷积用了上层输出同等大的卷积核,大小为6×6,卷积核的个数等于原网络全连接层的神经元个数4 096,以保证特征没有丢失,第7 层和第8 层卷积则是采用1×1 卷积降维,最后输出图像为猫狗的预测值,通过softmax函数[7]计算图像为猫狗的概率值。
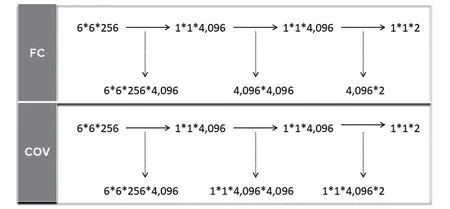
图2 全连接与全卷积对比示意图
2.2 定性评估
深层网络学习中,网络层数的堆叠就是对原图像特征一次次更深的提取,通常网络的浅层学习到的都是具体、清晰的特征,比如线条、颜色等等,而网络的深层学习到一般都是抽象、模糊的特征[8],是不能够理解和识别的。
为了让卷积核学习到的特征更加直观,利用TensorBoard 可视化工具,将网络某些层学习到的特征进行可视化学习,其中第一层的可视化特征图如图3所示。

图3 可视化卷积核和特征图
第一层卷积在224×224×3 的图像上学习到了96个11×11×3的卷积核,图中便是网络第一层卷积核对应所学习到的特征图像,可以看出,学习到的特征大致可分为两类,一类是图像中线条的方向,一类是颜色的频率大小。从特征图像中可看出每个卷积核都在学习不同的特征。由于是第一层卷积,网络学习到的特征都很简单,因此两类特征都是我们能清除认识到的,而当在网络深层时,特征会抽象模糊,根据深层卷积核的可视化图像显示,这些特征过于抽象,我们不好理解到底是个什么样的特征,是语义更高阶的表达。
卷积核的特征可视化[9-10],有助于我们直观理解神经网络中神经元的具体作用,以及分析不同神经元对不同特征的敏感程度,提高对网络的具体认识,帮助我们对网络参数进一步调整。
3 实验论证
3.1 参数数量优化
将全连接层替换为全卷积层大大提高了网络的灵活性,并且卷积核的数量和全连接层神经元数量相等,不会丢失图像特征影响分类准确率,主网络卷积层在不降低精度的前提下,参数数量大幅减少。
据统计,全卷积网络参数总和为6 000 万,在前向传播中,不需要做网络转换,网络传播更加流畅。
3.2 实验结果分析
用猫狗数据集对深层迁移网络进行长时间训练,为了让损失值能够达到最低,训练中随着epoch的增加,网络学习率在慢慢减小,减少深层网络损失值的波动程度,具体损失值的变化如图4所示。
如图4 显示,网络快速收敛,并记录了验证集中损失值最小的网络参数,最低可达0.03,在测试集中猫狗图像的预测准确率可达97.3%,网络对猫狗的辨识程度已经达到人类的水平,并且不受输入图像中猫狗图像的占比影响,即使目标图像仅仅占据一角,也能正确识别。
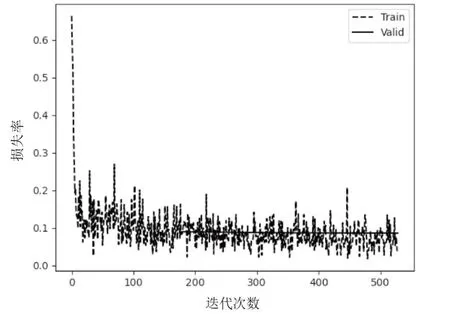
图4 损失值变化曲线图
4 结论
全卷积网络相比全连接有很大的优势,不需要在网络中途构建从卷积层向全连接层的连接,对输入图像分辨率不再做严格要求。在全部使用卷积层的前提下,将损失值降到更低,图像分类准确率更高。
