国外科学数据仓储的服务定位与服务体系研究
2022-05-14黄国彬
黄国彬 王 舒
(1.北京师范大学政府管理学院 北京 100875;2.山西财经大学图书馆 太原 030006)
1 引言
科学数据,又称“科研数据”或“研究数据”,是指在科技活动(实验、观测、探测、调查等)中或通过其他方式所获取的反映客观世界的本质、特征、变化规律等的原始基本数据,以及根据不同科技活动需要,进行系统加工整理的各类数据集[1]。在数据驱动发展的环境下,科学数据不仅是开展科学研究的基石,也是政府部门制定政策、进行科学决策的重要依据。在实际开展研究过程中,由于资金、设备、场地、时间等因素限制,部分研究人员难以通过自身努力产生科学数据。基于此,研究者通过科学数据共享渠道,利用已经产生的科学数据来开展研究工作显得尤为重要,而科学数据仓储则是科学数据共享的主要渠道之一。此外,由于科学数据本身具有类型多样、格式异构等特点,科学数据的存储、监护、获取和再利用已经成为当前信息管理界面临的重大难题之一。而科学数据仓储则能为科学数据的管理带来新的机遇。鉴于此,本文对国外科学数据仓储的服务实践进行调研与分析,总结当前国外的科学数据仓储服务体系具有重要意义。
目前,国内学者们从多个角度对科学数据仓储服务开展了相关研究,主要集中在科学数据仓储的服务功能、用户需求、评价体系和建设机制等方面,以国内科学数据仓储、国外科学数据仓储为对象展开研究。
(1)国内科学数据仓储的研究
用户需求研究。学者梅相月用问卷调查法,从注册与使用、检索与浏览、数据资源、数据服务、互动交流、平台服务六个角度调研分析科学数据共享平台的用户需求,并调研了国家林业和草原科学数据中心、国家地球系统科学数据共享平台、国家人口健康科学数据中心、国家气象科学数据中心等6个国家科学数据共享平台的用户需求满足情况,认为在用户的检索与浏览、数据资源、数据服务需求等方面用户需求没有得到很好的满足[2]。
评价体系研究。学者李赞梅构建了针对人口健康平台资源的综合评价指标体系,从资源主题、资源质量、数据规模、服务能力、服务成效和来源版权等维度对资源进行综合评价,有助于推动平台新增资源遴选和优质资源识别[3]。
(2)国外科学数据仓储的研究
服务功能研究。学者王丹丹调研了德国社会科学领域的科学数据仓储Sowi Data Net|Datorium的服务现状,从数据存储者、数据用户和科研机构的角度分析了仓储的数据服务流程,认为我国社科领域的科学数据层仓储应该拓展服务对象,注重机构用户,支持机构将平台嵌入到自己的工作流程;开展收费服务,用吸引商业机构和个人资助等方式,拓宽资金来源渠道[4]。
(3)国内外科学数据仓储的比较研究
平台建设研究。学者袁梦雪从建设基础(政策、经费、技术、团队)及管理过程(数据管理计划、采集标准与流程、描述与元数据、存储与保存、共享与保护、应用与服务)两个维度对比国内外11个健康医学科学数据管理平台的建设实践。基于国外成熟经验,本文从完善激励机制与数据政策、扩大经费来源、增强技术创新、保护数据安全和促进数据共享、深化服务内容5个方面对国内健康医学科学数据管理平台提出建议[5]。
综上,当前国内的研究多以某学科领域的科学数据仓储为研究对象展开分析,研究内容涉及服务功能、用户需求、评价体系和建设机制等方面。总体来说,国外的科学数据仓储服务实践成熟,经验丰富,而国内则略显落后,即使是国家级学科科学数据仓储在检索与浏览、数据资源种类、数据服务项目等方面也不能充分满足用户的需求。此外,目前国内的研究多集中在学科领域内,缺少对各个领域的科学数据仓储的横向研究。本研究以国外各学科领域的科学数据仓储为对象,从服务定位和服务体系两个角度展开调研与分析,总结出当前科学数据仓储的基本服务框架和先进服务实践,在理论研究方面具有一定的新颖性,同时对服务实践有一定的指导意义。
2 研究样本概况
在完整的科学研究活动中,涉及多个相关利益主体,根据其在科研活动中所承担的作用,将其概括为科研资助机构、科研承担机构、科研管理机构和科研出版机构。本研究以英、美、澳三国上述四类的网站为检索起点,搜集其政策文件中推荐(或指定)使用的科学数据仓储。由于科学数据仓储的学科属性,按照学科领域对科学数据仓储的推荐频次进行分类统计,包括生命科学、化学、地球科学、人文社科以及通用学科。此外,考虑到科学数据仓储的国别、细分学科等因素,最终选取如下的科学数据仓储为研究样本进行分析,如表1。
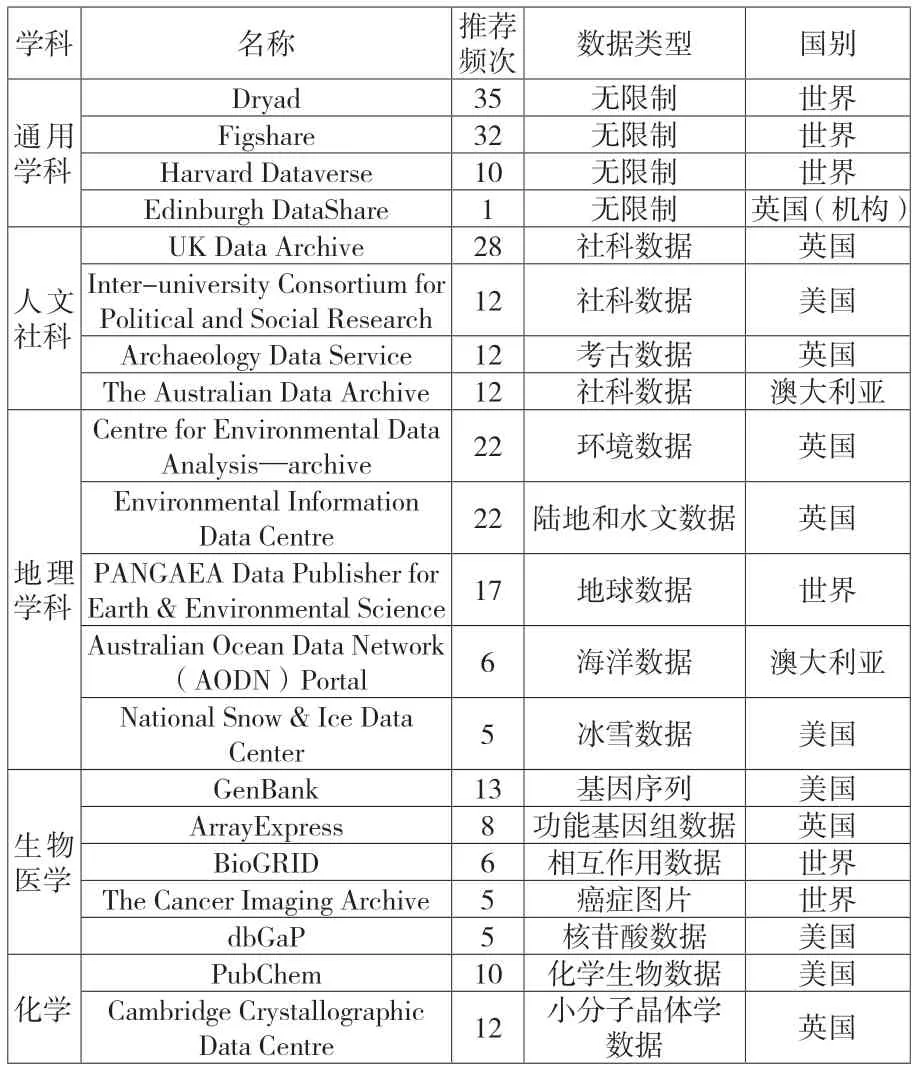
表1 国外20个科学数据仓储研究样本概况
在通用学科领域选取4个科学数据仓储,Dryad的用户侧重期刊和传统学术出版物的作者;Figshare的用户侧重科研机构及其科研人员;Harvard Dataverse面向科研机构提供科学数据仓储的系统平台,例如北京大学开放研究数据平台和复旦大学社会科学数据平台将Dataverse平台汉化,在此基础上建设科学数据仓储;Edinburgh DataShare是英国爱丁堡大学自建的科学数据仓储,代表通用学科机构科学数据仓储。人文社科领域分别选取了英、美、澳三国国家级的科学数据仓储,UK Data Archive、Inter-university Consortium for Political and Social Research、The Australian Data Archive,此外由于考古学数据是一类重要的社科数据,因此选取Archaeology Data Service作为研究样本。在自然科学领域内,地理科学、生物医学和化学领域的科学数据仓储数量多,建设较为完善,因此在这3个领域内选择具有代表性的科学数据仓储为研究样本。此外,这3个领域内的科学数据涉及多种类型的科学数据。根据科学数据的类型,选取表1中的20个科学数据仓储作为本文研究对象。
本研究通过网络调研法,从服务定位和服务体系两个方面,对表1中的20个研究样本展开调研。服务定位是科学数据仓储的发展方向,通过调研科学数据的服务目标(宗旨、远景)和服务对象来总结当前科学数据仓储的服务定位。而服务体系是科学数据仓储开展服务的底层逻辑,通过调研科学数据仓储的服务项目总结出当前的服务体系。
3 国外科学数据仓储的服务定位
服务定位包括服务对象和服务目标,即向何人提供服务,以达到何种目标。因此,科学数据仓储的服务定位包括科学数据仓储的服务对象和服务目标。
3.1 服务对象
科学数据仓储的服务对象是指接受科学数据仓储服务与利用科学数据仓储资源的个人、群体和单位等。根据所选样本的情况,目前科学数据仓储的服务对象主要包括科研人员、科研承担机构、科研出版机构、师生、公众等。需注意的是,并不是每个科学数据仓储的服务对象都完全包括上述三类,仅科研人员一项是所有科学数据仓储的共性服务对象,由此可知科研人员为核心服务对象。
3.1.1 科研人员
科研人员是科学数据仓储的核心服务对象。根据不同的服务需求,可以将科研人员分为数据贡献者和数据使用者。数据贡献者的需求是存储、共享和出版其在科研活动中产生的科学数据;而数据使用者的需求是检索和获取到满足其科研需求的科学数据。通常,科学数据仓储对数据使用者的身份没有特别规定;而不同的科学数据仓储对数据贡献者的身份有不同规定。
(1)传统学术成果的作者
传统学术成果指的是学术论文、图书、研究报告等。与一般期刊或出版机构合作的科学数据仓储,其数据提交者的身份通常为传统学术成果的作者。例如 Dryad其数据提交者通常为期刊论文的作者,这是由于Dryad与107家期刊合作,这些合作期刊要求其作者在提交论文的同时,将支撑论文的科学数据提交至Dryad[6]。同样的还有生物领域的科学数据仓储ArrayExpress,是大多数科学期刊推荐存储功能基因组数据的科学数据仓储[7],因此其数据提交者中,期刊论文的作者占很大比例。
(2)受资助的研究者
科研资助机构通常会要求其资助的科研项目产生的科学数据存入特定科学数据仓储,而不同科研资助机构通常会有不同的数据监护要求。因此,相应的,科学数据仓储会为了满足不同的资助机构对数据监护的要求,把数据提交者按不同资助机构划分。例如NSIDC将其数据提交者分为受NASA资助的研究者、受NOAA资助的研究者和受其他资助机构资助的研究者,不同类别的数据提交者提交要求与流程各不相同[8]。另外,有些科学数据仓储是由资助机构出资建立而成,这种情况下,一般分为受本机构资助的数据提交者和其他数据提交者,二者在服务项目和服务费用方面均存在差异。例如EIDC仅对受NERC资助的研究人员提供数据管理计划服务并且不收取服务费用,而对非资助项目产生的科学数据收取的服务费用取决于保存和出版数据所花费的时间、精力和财力[9]。
(3)特定机构的人员
许多科研承担机构,尤其是高校,已经建立本校的机构仓储,其中有些已将科学数据纳入其保存的资源范围内。而机构仓储的服务目标除了帮助科研人员保存和发布研究成果外,还要帮助机构本身保存和统计数据资产,以提高机构的学术影响力。在这样的目标下,机构仓储的数据提交者势必为本机构的科研人员。例如DataShare为爱丁堡大学的科学数据仓储,数据的贡献者必须为该校内部科研人员。但机构科学数据仓储也有例外的情况,如哈佛大学的科学数据知识库Harvard Dataverse,只要科研人员通过邮件在Dataverse系统进行注册,就可提交数据。
3.1.2 科研机构
除了科研人员,一些科学数据仓储也将科研承担机构、科研出版机构等科研相关机构纳为其服务对象,具有代表性的案例为Figshare。Figshare为科研承担机构和出版机构提供科学数据保存与发布的解决方案,无需机构进行本地开发与服务器的维护,为机构节省构建科学数据仓储所需的时间成本、人力成本和费用等;同时为所有合作的机构提供统一的检索界面。就科研承担机构而言,Figshare为其提供简便友好的用户界面,可以为其展示机构的所有研究成果,衡量机构研究成果的学术影响力,可以集成到已构建成功的机构仓储中等。目前,接受Figshare服务的科研承担机构包括奥克兰大学、墨尔本大学、谢菲尔德大学、巴斯斯巴大学、伦敦布鲁奈尔大学、莫纳什大学、索尔福德大学等等[10]。就科研出版机构而言,Figshare可以为论文的每个补充数据(如表格数据、图片等)添加描述信息和分配唯一标识符,使其可单独检索和引用;同时Figshare数据提交系统可以集成到期刊现有的论文提交系统和同行评议系统中,虽然这需要一定的额外开发工作,但可以极大地方便补充数据集的提交。目前,接受Figshare的出版机构包括Springer Nature、PLOS、WILEY、F1000research等等[11]。
3.1.3 其他人员
除了一线科研人员外,有些科学数据仓储还面向其他人员提供服务,主要包括师生、社会公众以及一些商业人员。例如DryadLab项目的目标用户就是高中、本科和研究生低年级的教师和学生,该项目为这些师生提供了一套免费使用的、高质量的基于科学数据的教学课件;ICPSR基于其在社科数据管理与监护领域的丰富经验,专门为本科教师与学生设计出可直接用于课堂的教学资源;此外,UKDA、NISDC、CCDC也为师生提供了相关的教学资源。
社会公众也是某些科学数据仓储的目标用户,例如UKDA基于存储于其中的数据设计出一款可供12岁以上社会大众使用APP——Quiz App,利用该APP公众可获取有趣的社会健康领域的事实性知识。
此外,商业人员也是某些科学数据仓储的目标用户,例如CEDA和CCDC。虽然CEDA的建立主要是为了促进和监护科研活动中产生的数据集,但由于其是一个国家级的服务中心,因此也为商业领域的人员提供服务,例如其专门设计了可用于商业用途的数据集列表[12]。只要数据集与CEDA归档的数据集范围一致,企业也可以将数据集存入其中,但通常会收取一定的费用[13]。
3.2 服务目标
科学数据仓储的服务目标是指通过向目标用户提供服务以达成的目标。科学数据仓储的服务目标决定了科学数据仓储开展的服务内容与发展方向,体现了科学数据仓储开展服务的核心价值与意义。目前科学数据仓储的服务目标可以分为基本目标和扩展目标。基本目标是指超过一半的样本仓储所实现的服务目标,扩展目标是个别仓储所实现的服务目标。
3.2.1 基本目标
基本目标大致可以概括为实现科学数据的有效保存、促进科学数据的合理使用和参与科学数据的发布与出版。
(1)实现科学数据的有效保存
科学数据是宝贵的过程性科研成果,如观测数据、临床数据等具有不可复制性,大型调查数据的产生具有耗时、费力、成本高等特性。因此如何对科学数据进行有效保存,是当前学术界关注的话题之一。作为科学数据的管理机构,科学数据仓储把实现对科学数据的有效保存作为其开展服务的目标之一。在科研活动中,对科学数据的保存分为两种,分别是长期保存和过渡性保存。基于对上述样本的调研与分析,目前科学数据仓储多以实现对科学数据的长期有效保存为目标;仅有极少数科学数据仓储以实现过渡性保存为目标,例如NSIDC在资助机构的要求下,对某些项目的科学数据进行临时保存。通常在这种情况下,科学数据仓储角色由保存者转变为管理者,更注重对数据的维护而不是保存[14]。
(2)促进科学数据的重复使用
保存科学数据是为了方便再次使用科学数据,因此促进科学数据的重复使用是科学数据仓储的又一个基本目标,与实现科学数据保存的目标相辅相成。科学数据作为宝贵的科研资源,其重复使用能帮助科研人员节约本该为获取数据而付出的时间、成本、精力,从而提高科研人员的科研效率。例如通用科学数据仓储Dryad促进学术文献的支撑数据的重复使用,机构科学数据仓储Edinburgh DataShare促进本机构科研人员产生的数据集的重复使用以提高学术影响力,社科科学数据仓储UK Data Archive 以提高高质量的社会经济数据集的使用率为服务目标,生物领域的ArrayExpress促进高通量功能基因组学实验产生的数据的重复使用。
(3)营造科学数据的共享氛围
科学数据仓储通过提倡科学数据公开发布、规范科学数据引用格式来营造科学数据共享氛围,是科学数据仓储的服务目标之一,这也是科学数据义不容辞的责任。如通用科学数据仓储Figshare致力于科学数据的保存、出版与发现;Harvard Dataverse旨在帮助科研机构及其科研人员共享数据;地理领域科学数据仓储AODN Portal鼓励和发展澳大利亚海洋科学领域的数据共享文化;化学领域科学数据仓储PubChem旨在为化学界提供一个发布与共享科学数据的平台。
3.2.2 扩展目标
除了上述三个基本服务目标外,还包括推动科学研究、丰富教学课堂等扩展目标。例如ICPSR以推动社会行为学的研究,为该领域提供丰富的教学资源为服务目标;National Snow & Ice Data Center把推动冰雪领域研究视为其服务目标之一;Cambridge Crystallographic Data Centre旨在为药物发现、材料研发等方面的科研与教学活动提供数据支持,以促进这些活动的发展。从上述三个案例可以看出,扩展目标通常出现在学科科学数据仓储中。这种情况的出现,与学科科学数据仓储具有丰富的领域专业知识紧密相关。
4 国外科学数据仓储的服务体系
科学数据仓储是基于科学数据的信息服务机构,开展数据生命周期全流程的基础服务,包括数据存储服务、数据出版服务、数据发现服务、数据获取服务、数据引用指导服务。此外,国外部分科学数据仓储基于庞大的数据资源、稳定的资金来源开展本仓储的特色服务,包括开发课堂教学使用资源、开设短期培训班、提供技术支持等。
4.1 数据存储服务
科学数据仓储的存储服务是面向数据提交者开展的服务,服务方式包括数据生产者自助存储与科学数据仓储工作人员协助存储两种。
4.1.1 数据生产者自助存储
数据生产者自助存储方式的存储流程为:①用户注册并登录在线存储平台;②根据数据仓储的要求填写数据基本详情,包括数据集名称、数据集摘要、数据提交者信息、数据获取与使用条款等元数据;③上传全部实体数据。经过统计,样本中共有14个科学数据仓储开展自助存储服务,包括通用学科仓储Dryad、Figshare、Harvard Dataverse、Edinburgh DataShare,人文社科领域的UKDA、ADS、ICPSR,地理学科仓储PANGAEA、AODN Portal、NSIDC,生物医学仓储GenBank、ArrayExpress,化学领域仓储PubChem、CCDC;共有10个科学数据仓储开展协助存储服务,包括地理领域的CEDA、EIDC,生物医学领域的BioGRID、TCIA、GenBank、dbGaP,人文社科领域的UKDA、ADA、ADS、ICPSR。其中,人文社科数据仓储UKDA、ADS、ICPSR和生物医学数据仓储GenBank同时提供上述两种存储方式,通常根据数据集的大小和类型为数据生产者提供不同的存储方式。
4.1.2 工作人员协助存储
除自助存储以外,数据提交者还可以在科学数据仓储工作人员的协助下存储科学数据。协助存储的流程为:数据提交者将数据实体发送给数据仓储工作人员。数据提交者通常通过线上邮件、线下邮递的方式将科学数据传递给仓储工作人员。例如UKDA要求数据作者将数据通过埃塞克斯大学ZendTo服务(内部邮件系统)或者邮寄的方式传递数据。除了通过邮件传递,还有些仓储要求通过特定的上传链接上传数据集,例如dbGaP要求数据存储者通过邮件与仓储工作人员联系,工作人员将提交链接发送给数据存储者,由数据存储者上传数据集[15]。线下邮寄,通常需要将科学数据集存储在优盘、硬盘等载体上,ADS要求通过CD-ROM、便携式硬盘传递数据集。通常根据数据集的大小和保密性来确定传递方式。与线上邮件的方式相比,线下邮寄具有安全性高、数据集传递量大的优点,但同时耗费时间、人力和物力。此外,还有些科学数据仓储要求数据提交者携带包含数据集的移动介质到固定场所,在仓储工作人员的帮助下将数据集复制到安全位置,例如ICPSR通过可移动介质(CDROM或DVD)将数据传递至物理提交场所,在工作人员帮助下将数据集复制到安全位置[16]。
此外,还有一些科学数据仓储根据数据集大小、类型等因素提供不同的存储服务。例如UKDA,根据数据集大小来确定存储方式。来自于科研人员的科学数据集,通常数据集较小,需采用自助存储方式,通过在线提交平台为ReShare存储数据;而来自于大型调查项目或系列调查项目产生的数据集,通常数据集较大,因此需要仓储工作人员协助存储,仓储工作人员会依据数据集合发展政策来对数据集进行评估,评估通过后,将其存入仓储中并纳入核心集[17]。
4.2 数据出版服务
出版或称发表,是指将作品通过任何方式公之于众并使其可被引用的一种行为。学术出版,比普通的出版更为严格,不仅要将科研成果公之于众,更重要的是,在公之于众之前,需要由专家对学术成果的质量进行评价与审核。而科学数据作为科研成果的一种,其出版内涵与学术出版一致,是指将在科学研究活动中产生的科学数据通过一定的方式公之于众,并在公布前需对科学数据的质量进行审核。目前,将科学数据公之于众的方式有如下三种:第一种,科学数据作为学术论文的补充资料或附加资料进行出版;第二种,将数据提交至科学数据仓储,由科学数据仓储单独出版或与期刊合作完成出版过程;第三种,以数据论文的形式出版,由数据期刊与科学数据仓储合作,数据论文发表在数据期刊上,数据集存储在科学数据仓储中。由上述三种方式可知,科学数据仓储作为科学数据的存储地与管理者,是数据出版服务的主要提供者与参与者。
科学数据仓储的数据出版服务是其面对数据生产者提供的服务,具体做法是:对科学数据进行质量审核,将科学数据通过特定渠道发布,规定发布时间。
4.2.1 质量审核
不同科学数据仓储的质量审核主体、对象和内容各不相同。质量审核主体是指对科学数据进行审核的人员,包括科学数据仓储内部工作人员和科学数据仓储邀请的外部人员。科学数据仓储成立专门的质量审核工作组对数据质量进行审核,例如ADS成立数据评估工作组(Collections Evaluation Working Group)对数据质量进行审核;而PANGAEA会安排数据编辑(Data Editorial)来开展审核工作[18]。科学数据仓储邀请的外部人员,往往具有该领域的专业知识,例如期刊论文的评审专家、数据提交者和使用者。例如Dryad,其合作期刊的同行评议人员在论文质量核审过程中对数据集的科学数据质量审核[19]。Harvard Dataverse规定,数据集的科学质量数据空间创建者或管理员对数据集进行审核[20]而BioGRID允许数据使用者指出数据集的错误,包括科学性方面的错误,并为用户提供专门的渠道来上报错误信息[21]。
审核对象包括科学数据实体及元数据。由于科学数据与学术论文、科技报告、科技图书等传统的科学文献不同,从形式来看可能是一组观测数值、实验数据记录、问卷数据或者一段计算机代码。如果不对其变量含义、产生背景、获取方法等进行描述,则无法掌握科学数据的具体含义。因此除了对数据集本身进行审核外,还需对元数据进行审核。审核的内容包括科学数据的形式质量和科学质量,形式质量是指数据集的可理解性、可访问性、一致性、完整性、脱敏性;科学质量是指数据集收集方法的评价、科学数据的合理性和再使用的价值。经过调查,样本中仅有NSIDC没有提及对数据集的技术质量进行审核,其余各仓储均对数据集的技术质量进行审核,其中Figshare、Edinburgh DataShare、EIDC、PANGAEA、GenBank、TCIA、dbGaP、ArrayExpress、CCDC等科学数据数据仓储仅对数据集的技术质量进行审核,而Dryad、Harvard Dataverse、UKDA、ICPSR、ADS、CEDA、BioGRID等不仅对科学数据的技术质量进行审核,还对科学数据集的科学质量进行审核。基于调查的结果,可知当前科学数据仓储对数据集本身的质量审核侧重于技术质量。此外,ICPSR、ADS、CEDA、EIDC、PANGAEA、ArrayExpress质量审核的对象包括数据集的元数据。例如,EIDC提出了元数据的审核标准,包括准确性、可用性、明确性和可检索性[22]。
4.2.2 发布渠道
科学数据仓储通过各种发布渠道,实现科学数据的最终出版。最基础的发布渠道是通过本仓储的数据目录,用户可以通过访问仓储的网站来发现和获取数据,所有科学数据仓储都使用此渠道发布数据。发布的信息包括数据集的描述信息、获取渠道、使用许可。但不同的数据仓储提供的数据描述信息详略不同,一般来说,学科科学数据仓储比通用科学数据仓储更为详细。对于学术论文、报告等传统文献的支撑数据,科学数据仓储通常将学术文献作为发布科学数据的补充渠道,在文献的引文和致谢中提到科学数据的存储仓储和访问方式。例如PANGAEA,其Web服务允许在论文页面上动态地嵌入数据信息。这是科学数据的补充发布渠道,相较于基础发布渠道而言,在这种方式下发布科学数据,科研人员可通过文献更好地理解数据集。而数据搜索引擎的集成目录是科学数据仓储发布数据集的扩展渠道,数据仓储允许数据搜索引擎收割数据集的元数据并发布在数据引擎的集成目录中,以增加数据集被发现的可能性。例如,CEDA允许科学数据的元数据被NERC的数据目录(NERC Data Catalogue)收割;EIDC允许科学数据的元数据被英国政府数据门户(data.gov.uk)和欧洲INSPIRE门户(EU INSPIRE portal)收割。
4.3 数据发现服务
数据发现是科学数据重新利用的开始,只有准确地发现并定位科学数据,才能顺利获取数据,从而利用数据。数据发现服务是科学数据仓储基于存储与保存的大量科学数据,面向数据需求者提供的服务,包数据检索服务和数据推荐服务。
4.3.1 数据检索
数据检索是数据发现的方式之一。科学数据仓储拥有庞大的数据集,通过提供检索入口来帮助数据需求者快速、便捷、高效地检索数据。不同科学数据仓储提供的检索方式和检索结果显示不同。
(1)检索方式
科学数据仓储的检索方式有两种:简单检索和复合检索。简单检索即提供单一检索入口,配合数据过滤器(filters)使用。数据过滤器的作用是通过添加条件以缩小和精简检索范围。而具体添加的条件通常因数据仓储的学科属性决定。通用科学数据仓储数据过滤器设置的条件通常包括数据集名称、作者、学科类别、发布日期等通用条件。如Dryad添加的条件包括题名、作者、学科类别、发布日期、相关出版物名称等。机构科学数据仓储除了设置通用的条件外,还设置了本单位的二级单位,如西澳大利亚大学的科学数据仓储UWA Research Repository,将其院系设为缩小检索范围的条件。学科科学数据仓储的数据过滤器条件,与上述两种仓储相比,学科性更强,粒度更细致。例如社科领域的数据仓储ADA的数据过滤器条件包括采样程序、数据收集模式等;生物领域的数据仓储ArrayExpress将生物体、阵列设计、分析、技术等设为精简检索结果的条件;地球科学领域的数据仓储通常将地理覆盖范围设为过滤条件,用户通过提供地图的方式进行数据集过滤,如EIDC可通过在地图上选定地点来查看相关数据集。
复合检索也是科学数据仓储提供的检索方式之一,即提供复合检索入口,为每个字段设定特有的输入框,可以在其中填入字段值,以实现从多角度预先限定检索结果,从而找到更符合检索需求的结果。通常字段的设置与过滤器条件的规律一致。
(2)检索结果显示
从数量来看,检索结果通常有三种可能:有且仅有一项,这种通常是以DOI或者本仓储的数据集编号这种唯一标识符为检索项进行检索所得结果;两个及两个以上的结果,通常是以关键词、数据集作者等为检索项进行检索所得结果;无结果,通常是使用错误的检索技巧或者数据仓储中确实没有相关的数据集。在第一种情况和第三种情况下,数据需求者无需从检索结果中挑选出符合需求的数据集。但对于第二种情况,从众多检索结果中挑选出符合需求的数据集,对检索结果进行排序和分面是十分必要的。
从调研的结果来看,大多数科学数据仓储支持用户对检索结果进行排序和选择分面。最常用的排序项为相关度、标题名称首字母、发布日期、下载热度。此外,学科科学数据仓储的排序标准包含本学科的数据特征,例如地理学科的仓储NSIDC根据覆盖范围的大小排序,分子量是生物科学数据仓储dbGaP、Pubchem的排序项,生物体是ArrayExpress的排序项。对检索结果进行分面与数据过滤器情况一致,在此不再进行赘述。
此外,有些科学数据仓储支持对检索结果进行保存,如爱丁堡大学的Edinburgh DataShare支持检索结果的网址可以被复制或者添加书签;社科数据仓储ADA、生物医学数据仓储TCIA支持对检索结果进行保存。
4.3.2 数据推荐
数据推荐与数据检索是科学数据仓储面向数据需求者提供的发现服务的两个方面,二者的最终目标一致,都是帮助数据需求者发现数据。但对数据需求者而言,二者略有不同,具体表现在发现方式上,数据检索是数据需求者主动发现数据的过程;而数据推荐是数据需求者被动发现数据的过程,由科学数据仓储将数据集以一定的规则进行整合后,推荐给潜在数据需求者。数据推荐服务通常有两种方式:无差别推荐和个性推荐,推荐途径有网站推荐、社交媒体推荐和邮件推荐。
无差别推荐,即对数据集的潜在需求者不进行差别对待,以统一的维度对数据集进行整合推荐,通常推荐的数据集会出现在科学数据仓储的首页,或者科学数据仓储在社交软件上注册帐号所发布的内容中。推荐的维度包括但不限于此:发布时间、下载次数、重要程度等。发布时间维度具体表现在,科学数据仓储通常将最近更新的数据集通过仓储网页推荐给用户,使用户了解到该仓储最新收录的数据集。例如Dryad、Figshare、ICPSR、Edinburgh DataShare、TCIA、dbGap、ADA向用户推荐最新发布数据集;Dryad、Figshare、ICPSR等数据仓储均根据数据集下载次数向数据需求者推荐数据集。此外,科学数据仓储会对数据集的重要程度和特色性进行判断,对数据需求者推荐具有特色或重要的数据集,具有代表性的是地理领域的科学数据仓储PANGAEA和通用数据仓储Dryad。但二者不同的是,前者通过仓储网站推荐数据集,用户访问网站即可看到特色数据栏目;而后者是通过社交软件对重要的和有特色的数据集进行推送,只要用户关注了该仓储的社交网站(如Titter、Facebook)帐号,即可看到推荐和介绍的数据集。个性推荐,即指仓储通过收集数据需求的研究领域和研究需求等信息,通过仅个人可见的渠道向用户推送相关的数据集。依据笔者对样本的调研,发现该推荐方式在科学数据仓储中尚未普及,仅Dryad根据用户填写的关注点与需求点向用户推送相关数据。
4.4 数据获取服务
科学数据仓储向数据需求者提供获取数据的途径,包括在线获取和现场获取。现场获取是指数据需求者需到特定的现场、在规定的时间内才能获取数据,这通常是由被获取的数据安全级别决定的。笔者将对上述两种方式展开分析。
4.4.1 在线获取
在线获取是指数据需求者利用个人计算机,通过网络,可以实现在线浏览数据集内容或者将需要的数据集下载到本地,在线获取数据通常需要注册或者登录,是最常提供的获取途径。在线获取包括以下几种情形:点击下载按钮直接下载、通过使用下载工具下载以及填写表单申请后下载。
①通过点击按钮直接下载的获取方式,对数据需求者而言是最简洁的获取方式,通常在检索或浏览数据过程中,确定目标数据集后,直接点击即可下载,适用于单个数据集的下载。通过该方式获取数据,对数据需求者而言,获取数据所花费的成本最低,对科学数据仓储而言,对数据集进行保护的级别也最低。但从数据共享和再利用的角度来说,这是最有效的方式。因此,该方式适用于以促进数据公开共享为目的的科学数据仓储,如Dryad、Figshare、Edinburgh DataShare、ADS、PANGAEA、AODN Portal、PubChem等。对于数据集按照访问级别进行划分的科学数据仓储,该方式适用于访问限制最低级别的数据集,例如适用于UKDA、CEDA的开放数据。此外,有些仓储的数据集是否可通过该方式获取,取决与数据提交者的决定,例如Harvard Dataverse,在提交过程中,数据提交者可对数据集的获取权限做出选择,但该方式是默认选项。
②通过使用工具下载,通常出现在学科科学数据仓储中,适用于大型数据集批量下载。常用批量下载工具是FTP、Rsync,如生物领域的数据仓储PubChem、UniProt、ArrayExpress都支持使用FTP站点进行批量下载,Harvard Dataverse支持使用Rsync下载大文件。此外,有些科学数据仓储支持程序化获取数据,例如ArrayExpress支持使用Web服务或JSON查询和下载数据。与点击按钮直接下载相比,该方式虽然一次下载的数据集量大,但在便捷程度上略逊色于前者。
③与上述两种获取方式相比,填写表单后下载,对科学数据仓储及数据提供者而言,具有上述两种方式不可比拟的优势。具体来说,通过该方式获取数据,数据提供者能获得其提交的数据的使用信息,如何人使用、为何使用、如何使用等;对科学数据仓储而言,能够保证数据集的合理使用,从而增加科学数据仓储在数据提交者心中的信任度,使更多的数据拥有者愿意将数据提交至该仓储。以英国社科数据仓储UKDA为例,访问UKDA的受保护数据时,不仅需要注册(注册时必须提供个人信息),还要签署最终用户协议(End User Licence),该协议中涉及用户使用目的、使用要求等方面内容,如需要用户保证数据非商用、保护数据中涉及的个人隐私、按要求销毁副本等。
4.4.2 现场获取
与在线获取方式相比,科学数据仓储提供的现场获取方式所花费的人力、物力、时间、精力都远远高于前者,因此普及度也低于前者。当然,该方式仅适用于安全要求级别高的数据,而并不是所有的科学数据仓储中都收录了如此高安全级别的数据集(如通用学科科学数据仓储和机构科学数据仓储不会收录此类数据集),这也是造成该方式普及度低的原因。样本中,提供在线获取方式的科学数据仓储集中在社科领域,包括英国的UKDA和美国的ICPSR。以ICPSR为例,其为部分受限制的数据集(大约20个数据集合)提供现场获取方式,这些数据中包含监狱囚犯、暴力受害者或严重罪犯的高度敏感的个人信息。ICPSR为上述数据建立了位于安娜堡密歇根大学的物理数据飞地(Physical Data Enclave)以保证数据的安全性。调查员与调查员机构负责人签署使用协议和保密协议是进入物理飞地的必要条件。调查人员使用物理飞地的要求:①调查员不能将个人笔记本或其他电子设备带入飞地,仅能使用飞地内配备的计算机设备。该设备中安装了Microsoft Office、SPSS、SAS和Stata统计软件包,若要使用其他软件,需要提前与工作人员联系;飞地中的计算机无法发送电子邮件和访问Internet。②在调查员使用飞地时,必须有ICPSR的工作人员同在现场,检查带入飞地中的材料设备和监督使用过程,如监督打印机的使用情况。③所有的输出材料,必须是电子版,并在离开飞地前提交给ICPSR工作人员以供审查。
4.5 数据引用服务
数据集的引用,不仅能对数据生产者的贡献进行认可,帮助其衡量数据集的学术影响力,还能方便后续研究者识别和定位参考数据,增加数据集的再使用率,促进研究成果的再现。科学数据仓储作为数据集的管理机构,对数据获取者提供引用服务十分必要。对获取数据的用户提供的引用服务包括两个方面:提供引用指导,帮助用户以规范的格式对科学数据进行引用;提供引用工具,帮助用户快速生成相应的引用格式。
4.5.1 提供引用指导
科学数据仓储提供引用指导,帮助获取和使用数据的科研人员以规范的格式对数据集进行引用。引用指导内容包括引用对象和引用要素。不同的科学数据仓储对引用对象的规定各不相同。就引用对象而言,主要包括三个层次:引用科学数据、引用科学数据和来源文献、引用整个数据仓储。其中,仅以科学数据为引用对象的情况,在科学数据仓储引用服务中最为常见,且出现在各个领域的科学数据仓储,如通用科学数据仓储Figshare;机构科学数据仓储Harvard Dataverse 、Edinburgh DataShare和UWA Research Repository;社科科学数据仓储UKDA、ICPSR、ADS、ADA;地理科学数据仓储CEDA、EIDC、AODN Portal、NSIDC;生物领域的ArrayExpress 、TCIA、dbGaP;化学领域的PubChem、CCDC。建议同时以科学数据与其来源文献为引用对象的情况,常出现于与期刊合作密切的科学数据仓储中,如Dryad和PANGAEA。前者要求提交于本仓储中的数据集必须有相关的来源文献,数据集相当于来源文献的补充资料,同时阅读来源文献也有助于获取和使用数据的科研人员更好地理解数据集。因此Dryad建议在引用数据集的同时引用其来源文献。以整个科学数据仓储为引用对象的情况,较为少见,出现于生物领域的科学数据仓储BioGRID和UniProt。这是由于这两个仓储并没有为每个数据集分配唯一标识符或仓储编号的机制,即使仅使用了其部分数据集,在引用时也应该以整个仓储为引用对象。例如UniProt规定,如果发现UniProt有用,请考虑引用关于UniProt的最新出版物:The UniProt Consortium.UniProt: the universal protein knowledgebase.Nucleic Acids Res.45: D158-D169 (2017)。就引用要素而言,总体上比较一致,包括数据集的作者、数据集名称、数据发布时间、数据仓储名称和资源唯一标识符5项。
4.5.2 提供数据引用工具
提供引用工具,帮助获取和使用科学数据的科研人员快速生成相应的引用格式,科研人员只用复制粘贴即可。通常,科学数据仓储会在数据集内容页面上,添加生成引用格式的按钮,例如PANGAEA支持的可导出的引用格式包括RIS、BiB TeX和文本格式。Dryad也支持引用工具,数据引用可以使用数据包页面引用框底部的链接轻松下载,目前可以以两种通用格式下载引文:RIS(与EndNote,Reference Manager,ProCite和RefWorks等软件兼容)和BibTex(与LaTeX和BibDesk等软件兼容)。Figeshare支持将引用信息以RefWorks、BibTeX、Endnote、DataCite、NLM、DC and RefMan格式输出。
4.6 特色服务
除了基于数据生命周期开展的基础服务外,部分科学数据仓储还凭借其丰富的数据资源、专业的人力资源、先进的技术力量和雄厚的资助支持,开展了一系列特色服务,包括开发课堂教学使用资源、开设短期培训班、提供技术支持、举办论文竞赛等。这些特色服务的提供,主要作用是提高数据资源的利用率和科学数据仓储的影响力。
4.6.1 开发课堂教学使用资源
科研在大学教学中具有很重的作用。在课堂中,不仅需要学习前人总结出的理论知识,还要学习科学研究方法,尤其针对研究生和高年级本科生,教师对科学方法的讲授比已有理论知识的讲授更为重要。而将科学数据引入课堂,可为学生提供原始的未经分析的科研材料,帮助学生更好地理解和应用课堂中学到的学科研究方法。科学数据仓储拥有大量的科研资料——科学数据,拥有具有娴熟数据处理能力的工作人员,尤其是国家数据中心式的科学数据仓储还有雄厚的资金支持,其可以借助这些优势,面向高校师生开展服务,以提高数据资源的利用价值。开展该服务的科学数据仓储有通用科学数据仓储Dryad、社科科学数据仓储UKDA和ICPSR。
Dryad和UKDA基于数据集,开发出直接用于课堂的教学资源。DryadLab是Dryad与研究人员和教育工作者合作开发的,是一套免费、公开授权的高质量实践教育模块,供学生使用真实数据进行科学探索。这些模块可以轻松集成到现有的高级中学、本科和研究生早期课程中。每个模块都包含每一节课所需要的一切,包括模块概述、教师讲义、PPT及其使用方法、原始数据集、学生讲义。这些模块中的资料通过Google Spreadsheet呈现,可实现在线协助使用,在课前,可以要求学生访问该模块进行预习。同时,教师也可以根据课堂需求,对资料进行个性化处理。Dryad之所以能开展此项服务,是由于其出版的数据集的使用许可协议均为CC0。这意味着,在法律规定的范围内,Dryad一直致力于实现科学数据最大程度的公开共享,同时最大限度地减少法律障碍,并最大限度地发挥科学数据对研究和教育的影响。该服务的开展具有以下好处:对教师而言,能够轻松地将科学数据带入课堂,使学生接触到除书本理论知识之外的未经加工的资料,激发学生的研究兴趣,同时增强课堂的趣味性;对科学数据仓储而言,该项服务是数据从非科研的角度得到了充分利用,增加了数据的使用价值,同时也能扩大科学数据仓储的影响力。
UKDA向老师提供了在教学中使用数据集的使用信息,包括定量数据集教学使用案例和定性数据集教学使用案例。定量数据集教学使用案例,通过一个excel表格汇总[23],通过超链接的形式可访问具体教学案例,每个案例中包含教学目的、应用数据集及对应的练习题。定性数据集教学使用案例,通过网页展示,共列出8个教学案例。与定量案例不同的是,定性案例中没有固定的模块,本文以“Last Refuge”案例为例进行介绍。Last Refuge教学资源包含了数据集(Peter Townsend 20世纪50年代末期避难研究期间收集的一系列定性材料)、原始的研究方法以及对教师使用的一些指导[24]。
ICPSR虽然没有提供教学案例,但是向教师提供怎样将数据集带入到课堂的指南如ICPSR向教师提供一系列指南,帮助教师更轻松地将“数据驱动”学习体验带入课堂。指南的形式有文本和视频两种。
4.6.2 提供短期培训
提供短期培训也是科学数据仓储开展的特色服务之一。其中,ICPSR的暑期培训历史最为悠久、国际影响最为广泛。笔者以ICPSR的暑期培训为例,对科学数据仓储开展短期培训服务进行分析。
ICPSR的暑期培训项目始于1963年,每年的参与者通常来自全球350多个学院、大学和科研组织,参与者的研究领域覆盖30多个学科,该项目是国际公认的社会、行为和医学科学研究方法和技术培训的领导者。该短期培训项目,对科学数据仓储而言,是其开展数据服务的补充。课程主要提供统计技术、研究方法和数据分析能力等方面的培训。ICPSR为暑期项目配备专门的讲师,来自各个大学,每位讲师有其专门服务的课程。暑期项目是ICPSR提供的收费服务项目,但同时为参与者提供多项奖学金,每项奖学金对应的学科领域不同,在申请时需注意学科领域限制。此外,奖学金的申请有时间限制,如2018年暑期项目奖学金申请截止至3月31日。所有的申请材料必须在线提交。审核通过后,即可免除部分或全部学费。
4.6.3 提供技术支持
科学数据之于科学数据仓储,好比数字资源之于数字图书馆。不论是科学数据仓储还是数字图书馆,其服务的开展均离不开基于计算机的技术平台。因此,有些科学数据仓储除了上述围绕科学数据的存储、出版、发现、获取、引用而开展服务外,还提供技术支持服务。提供技术支持服务主要存在于通用科学数据仓储中,样本中Dryad和Harvard Dataverse均提供技术支持服务。Dryad的技术支持是面向传统的学术期刊而提供的,向学术期刊提供提交整合服务,即将Dryad的数据提交系统的代码开放,允许期刊出版商将该系统嵌入到论文提交系统中,并且每个期刊可以根据自身需求进行定制[25]。该服务具有以下好处:简化作者提交数据的过程、向编辑或同行评审专家提供安全访问数据的机制、确保论文和数据集之间的双向链接以增加两者之间的可见性等。Harvard Datavers也向科研机构提供技术支持。Dataverse软件可供任何人在Dataverse GitHub存储库中下载,并提供深入的安装指南,以帮助科研机构启动并运行Dataverse。通过安装Dataverse软件,科研机构将拥有自己的数据仓储,并将数据存储在本机构仓储中,并成为Dataverse仓储社区的成员。目前全世界有超过26家机构使用Dataverse作为数据共享,存档和发布需求的解决方案,Dataverse仓储社区将致力于成为向所有人提供研究数据的社区[26]。
5 结语
本文对国外科研相关机构(科研资助机构、科研承担机构、科研出版机构)推荐使用频率较高的20个科学数据仓储的服务实践展开调研,研究结论具有广泛性和代表性。目前,英美澳各个学科领域的科学数据仓储服务已有较为清晰的定位,形成一套相对稳定的体系。具体来说,在服务对象方面,国外科学数据仓储面向科研人员、科研承担机构、科研出版机构、师生、公众等人群和机构。在今后的发展过程中,科学数据仓储应更多注重机构用户的维护与开发,而机构用户是个人用户的集合,有利于整合资源,减轻机构独立开展数据服务的压力。在服务目标方面,科学数据仓储应通过开展各项服务,实现科学数据的有效保存,促进科学数据的重复使用,在学术圈内营造科学数据的共享氛围。在服务体系方面,应提供基于数据生命周期全流程的基础服务,包括数据存储服务、数据出版服务、数据发现服务、数据获取服务、数据引用指导服务,和基于仓储特色资源的扩展服务,包括开发课堂教学使用资源、开设短期培训班、提供技术支持等,形成完整的服务链,以实现服务目标。
未来研究可结合国内科学数据仓储的建设情况和服务现状,进行对比分析,为我国科学数据仓储服务提供参考意见和发展方向。
