期刊论文题名、关键词、摘要的差异性研究
2022-05-14陆凤琳
陆凤琳 袁 润,2
(1.江苏大学科技信息研究所 镇江 212013;2.江苏大学图书馆 镇江 212013)
0 引言
随着信息技术、网络技术等科学技术的迅速发展,大数据时代来临,文献数量增长迅猛,以中国知网为例,截止2020年,中外文文献量已逾3亿篇[1]。海量的文献信息为科学研究和社会实践提供了依据,但同时也为文献检索带来了挑战。
题名、关键词、摘要是学术文献传播的重要形式,能够准确揭示论文主题,也是文献检索的重要依据,俗称文献检索的“三把斧”[2]。题名应该是以最恰当、最简明的词语反映论文最重要的特定内容的逻辑组合[3],准确的题名既能充分反映论文的研究范围和研究深度,也能高度概括并准确揭示论文的核心内容和重要论点[4]。关键词是为了著录和标引的需要从论文中选取出来用以表示文献主题的单词或术语[3],它较为规范,遵循专业性原则,能全面、准确地反映了论文主题[5]。摘要是科技文献不可或缺的一个重要部分,它是以提供文献内容梗概为目的,不加评论和补充解释,简单明确地表述文献重要内容的短文[6],是文献主题的高度浓缩[7]。题名、关键词和摘要应该为文献检索与文献传播服务,三者既存在共性,也存在一定的差异性。摘要作为论文内容的高度浓缩,相较于题名、关键词,能够更全面地揭示文献内容。题名、关键词应以精炼的短语或术语反映论文主题,使读者对论文内容有一个大概了解[8]。摘要、题名、关键词因其作用不同,各具特点,在表达上应各有侧重。
但实际上,科技论文存在关键词直接选自题名,导致题名与关键词过于一致,不能充分展示文献特色[2]的问题。更有甚者,为了追求“新”“奇”“特”,吸引读者眼球,存在题名或关键词与文献内容无关,或者与摘要差异过大等问题。这些问题不仅会影响文献检索的结果,也会影响文献传播的效果。因此,探索题名、关键词、摘要的差异性具有较强的现实意义。
本文通过实验研究,提出了“差异度”定量测度指标,计算了13种学术期刊近10年以来刊载论文的题名、关键词、摘要的差异度,探索了差异度的分布特征,可为学术论文的撰写、编辑和检索提供参考。
1 文献综述
本研究主要通过定量测度指标,研究期刊论文题名、关键词与摘要的差异。其中,题名、关键词与摘要的差异性定量测度的指标建立在文本相似度计算方法的基础上,因此,本文的重点集中在题名、关键词与摘要的差异性问题及文本相似度计算方法研究上。
目前,已有学者关注到题名与关键词之间的差异问题并开展了相关研究,如徐鸿飞等[9]、张紫玄等[10]分别对医学领域、农产品品牌评价领域的论文题名与关键词的差异性进行比较分析;陈红琳等[8]、王婧等[11]分别提出定量测度题名和关键词差异性的指标,并基于各自的指标对图情类期刊论文、十余年期刊论文的一期ESI数据的题名与关键词的差异进行分析;Hunt C Aetal[12]以顶级旅游期刊为例,对文献题名和关键词之间的差异进行可视化分析,但并未得出具体结论;Yuret T[13]提出并研究了题名与关键词对检索结果影响的差异。如上所述,题名与关键词之间差异问题的研究数量较多,但这些研究存在主观性较强[9]、数据局限[8]的问题,题名与关键词差异性问题仍有很大的研究空间。除了题名与关键词间的差异,摘要与题名、关键词的差异鲜有学者关注,即使有学者关注该问题,如T Kim[14]研究了题名、摘要作为关键词时的表达差异,但也未得出一定的结论。
相似度算法与差异度定量测度指标息息相关,陈红琳等[8]、王婧等[11]提出的定量测度题名和关键词差异性的指标以文本相似度为基础。本研究提出的差异度定量测度也建立在文本相似度的基础上,因此,有必要对文本相似度算法进行综述。文本相似度计算是指通过一定的策略比较两个或多个实体(包括词语、短文本、文档)之间的相似程度,得到一个具体量化的相似度数值[15]。文本相似度计算方法有基于字符串的方法、基于语料库的方法、基于知识库的方法和混合方法四类[16]。基于字符串的方法直接针对原始文本,作用于字符串序列或字符组合,以两个文本的字符匹配程度或距离作为相似度衡量标准[15];基于语料库的方法为基于词袋模型、神经网络和搜索引擎等方法从语料库中获取信息计算文本相似度,考虑了语义的重要性;基于知识库的方法是指利用具有规范组织体系的知识库计算文本相似度,大多利用页面链接或层次结构,能较好地反映出词条的语义关系;混合方法指的是综合运用两种或两种以上上述方法计算文本相似度,一定程度上提高了文本相似度计算效果。上述四种文本相似度算法已较为成熟,被广泛应用于信息检索、自然语言处理等领域[15],能够满足本研究对题名、关键词与摘要的差异度计算需求。
2 差异度的定义
“主题”这一概念的外延较为宽泛。题名、关键词、摘要皆可以视为论文的“主题”,三者既有区别,也有关联,两两比较,既有相似性,也存在差异,它们结合起来应能最大限度地表达“主题”。为了定量研究,本文定义学术期刊论文的题名、关键词、摘要的差异度为题名与摘要的差异度(d1)、关键词与摘要的差异度(d2)、关键词与题名的差异度(d3)三者的几何平均值,如公式(1)所示。

差异即差别、不相同,差异度是量化不同对象存在差别的程度,是比较的结果。一般而言,学术论文的题名、关键词、摘要应从不同的角度,以不同的形式揭示文献主题,将其两两比较,必定存在一定的差异。差异度越大,说明彼此越不相似,三者组合所蕴含的信息量就越大;反之,差异度越小,说明三者越趋于一致,三者组合所蕴含的信息量就越小。
由于同一对象的差异度与相似度的值域互为补集,因此可以用相似度表达差异度。题名、关键词、摘要的比较属于文本比较。文本比较有多种方法,本文研究对象是学术期刊论文的题录信息,从语言表达一致性角度来看,可以采用“字面”相似性算法计算题名、关键词、摘要三者之间两两比较的相似度。所谓字面相似性,其本质就是字符串的比较,较为常用的算法有“字符匹配”、杰卡德相似度和余弦相似度。杰卡德相似度体现集合思想,以两个集合的交集与并集中包含的元素个数之比表示两个集合间的相似度。余弦相似度体现向量思想,通过计算两个向量的夹角余弦值来表示两者的相似度。
字符匹配算法是将比较对象视为由1~m个汉字或词组组成的字符串,用ni表示第i个词组的字长,用ni’表示与第i个词组匹配的汉字个数,差异度的定义如公式(2)所示[11]。
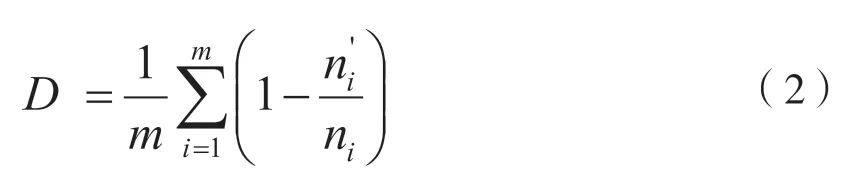
杰卡德相似度算法是利用分词技术将题名、关键词和摘要拆分成词组集合,若待比较的两个集合记为A和B,则其差异度的定义如公式(3)所示。

余弦相似度算法也是利用分词技术将题名、关键词和摘要拆分成词组向量,若待比较的两个向量记为A和B,则其差异度的定义如公式(4)所示。
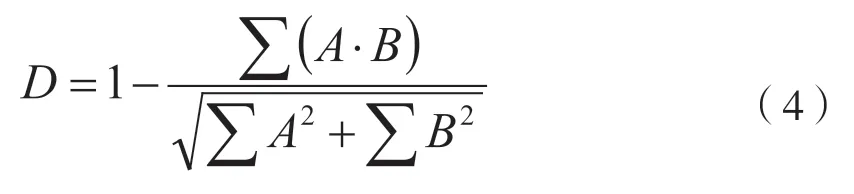
三种算法的计算结果差别较大。字符匹配算法结果偏小,杰卡德相似度算法结果偏大,其结果分布皆不均匀。余弦相似度算法的结果适中,且基本呈现正态分布。本文对此开展了探索性实验研究。
3 实验研究
本文采用字符匹配、杰卡德相似度、余弦相似度三种不同算法,分别计算了学术期刊论文的题名、关键词、摘要三者之间两两比较的差异度。字符匹配算法精确到单个汉字,其它两种算法精确到词组,这些词组由jiebaR分词所得。
3.1 实验步骤
本文在RStudio平台(x86-64-pc-linux-gnu,R version 3.6.3)上开展实验研究,实验过程分为数据采集、导入、预处理、计算、分析等步骤。
步骤1:下载期刊题录数据。从CNKI平台选择并下载了13个学科的13种期刊近10年以来的题录数据,文献导出格式选择“自定义”,“全选”所有字段,导出到Excel保存。
步骤2:在RStudio环境下读取题录数据。当Excel文件较多时,可以先用list.files()函数读取文件名,再循环读取数据,结果保存为数据框。
步骤3:数据预处理。删除无题名、无作者、无关键词、无摘要等字段的记录,剔除英文文献,去除重复记录等预处理,保留题名(TI)、作者(AU)、关键词(KW)、摘要(SU)、出版年(PY)、刊名(JN)等字段信息,最后得到25 566条记录。用xtabs(~JN+PY, data=mydata)函数创建二维列联表,结果如表1所示。
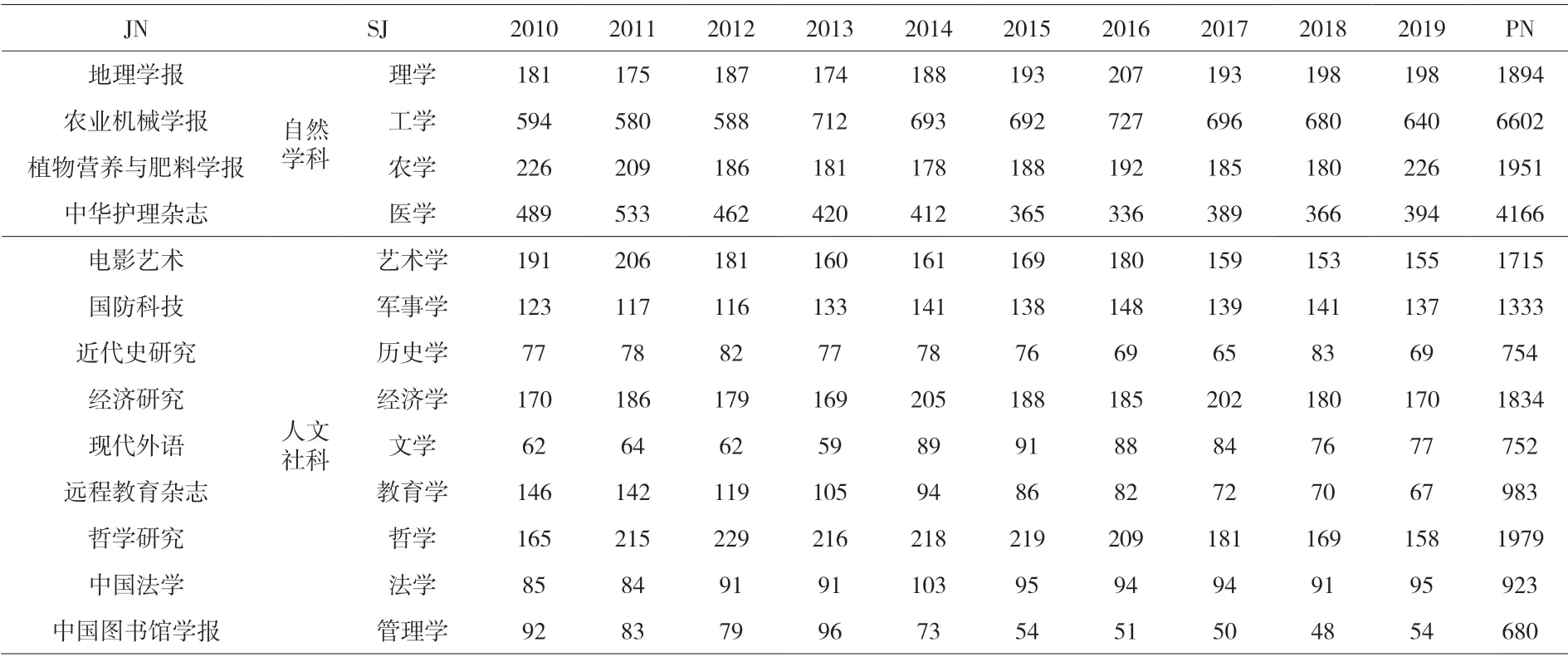
表1 13个学科的期刊发文数(《学位授予和人才培养学科目录》[17])
步骤4:计算每条题录的题名长度、关键词个数和摘要长度。用stringr包中的str-split()函数,拆分字符串,统计其长度,结果以新的变量TL、KN、SL保存,按照刊名分类统计,其平均值如表2所示。
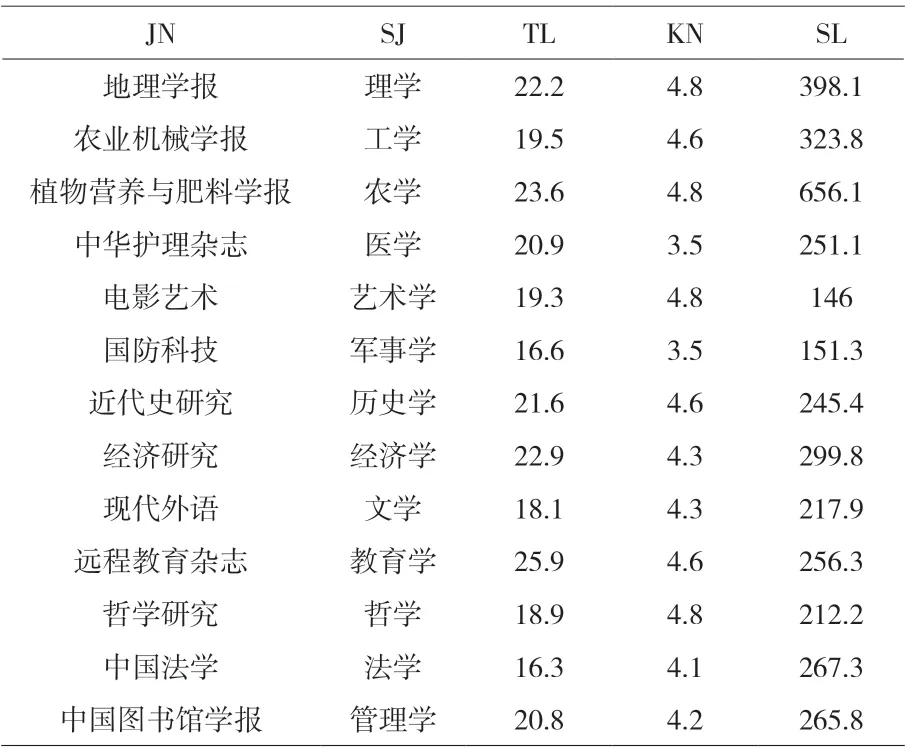
表2 13种期刊题名、关键词与摘要的长度统计指标
步骤5:字符匹配算法的差异度计算。该算法无需分词处理,比较对象皆视为字符串。题名与摘要比较时,先将题名拆分成“字”,若这些“字”在摘要中全部出现,则其差异度为0,若这些“字”在摘要中全部不出现,则其差异度为1,若仅有部分出现,则其差异度为未匹配的“字”的个数与题名长度的比值;关键词与题名、摘要比较时,需要分别将每个关键词与题名、摘要比较,然后计算其平均值。
步骤6:杰卡德相似度算法的差异度计算。该算法需要用jiebaR分词处理。题名和关键词较短,采用分词引擎的缺省算法,摘要相对较长,采用关键词算法,即将摘要转变成10个关键词,分词引擎函数为worker(type="keywords",topn=10)。为了提高计算精度,本文考虑了词频因素,将题名、关键词和摘要统一转变成“词组+词频”格式,如表3所示。如此,可以通过自编函数计算题名、关键词和摘要两两比较的差异度。

表3 “词组+词频”格式
步骤7:余弦相似度算法的差异度计算。与步骤6类似,用公式4计算题名、关键词和摘要两两比较的差异度。
步骤8:结果分析。按照期刊分类统计的三种算法的计算结果均值如表4所示。字符匹配算法的差异度偏小,杰卡德相似度算法的差异度偏大,余弦相似度算法的差异度适中。
表4 三种算法的结果比较
3.2 三种算法的比较
通过上述计算得到了关于题名、关键词和摘要的四组数据。题名长度、关键词个数、摘要长度反映了学术论文的基本特征,即学术论文题名一般用20个左右汉字表示,选用3~5个关键词,摘要长度一般为300个汉字左右。本文重点是探索三者之间的差异情况,其两两比较可以形成三种组合(TS, KS, KT),每种组合又分三种算法来计算其差异度。
以题名-摘要差异度(TS)为横坐标,关键词-摘要差异度为纵坐标,将三种算法结果绘制成散点图,如图1所示。图1(a)是字符匹配算法差异度分布,图1(b)是余弦相似度算法差异度分布,图1(c)是杰卡德相似度算法差异度分布。从图1可见,基于字符匹配算法差异度偏小,杰卡德相似度算法差异度偏大,余弦相似度算法差异度值较为适中。
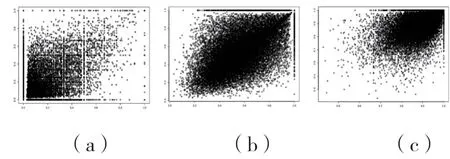
图1 三种算法结果分布
三种算法(chm, jac, cos)分别计算题名(T)、关键词(K)、摘要(S)的两两比较结果共有9种组合,其结果分布如图2所示。
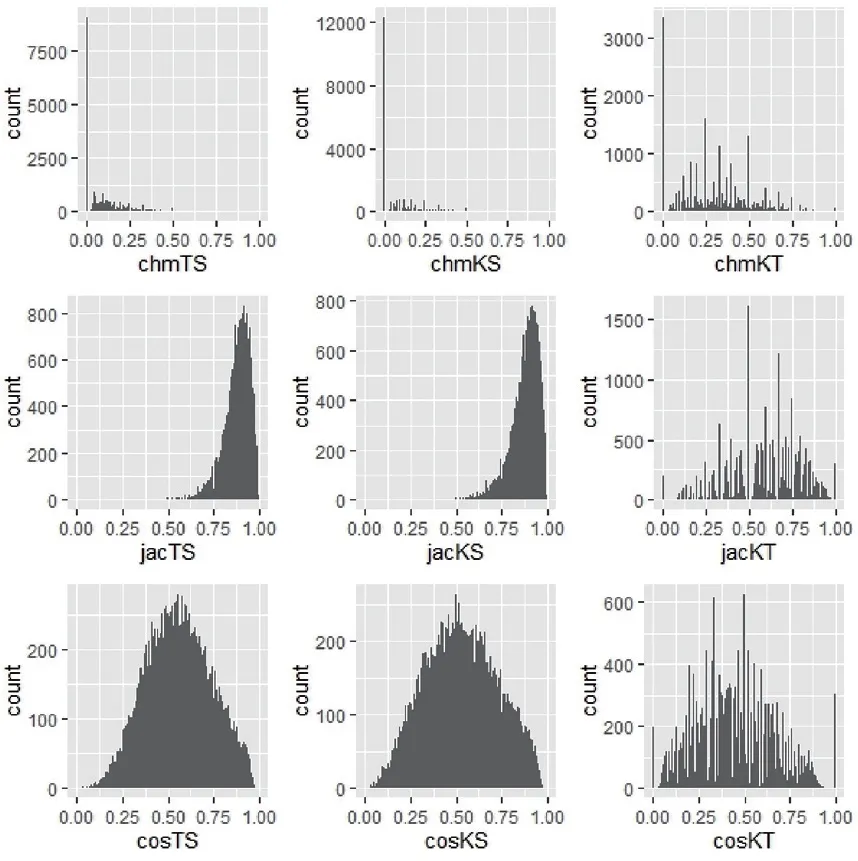
图2 三种算法的结果分布
字符匹配算法存在大量的0差异度情况,分布基本无规律,杰卡德相似度算法的结果呈现偏态分布,只有余弦相似度算法的结果呈现正态分布。所以,以余弦相似度算法分别计算题名-摘要的差异度(cosTS)、关键词-摘要的差异度(cosKS)和关键词-题名的差异度(cosKT),再计算三者的几何平均值,并以此作为题名、关键词和摘要的差异度(cosDD)。
3.3 实验结果
根据三种算法的结果分布情况,本文采用余弦相似度算法计算了13种期刊10年以来的题录数据,得到题名、关键词、摘要在揭示学术期刊论文主题上差异度的平均值如表5所示。实验结果表明,题名、关键词、摘要三者两两比较的差异度的几何平均值具有较好的分布特征和区分度,可以作为题名、关键词、摘要的差异度指标。
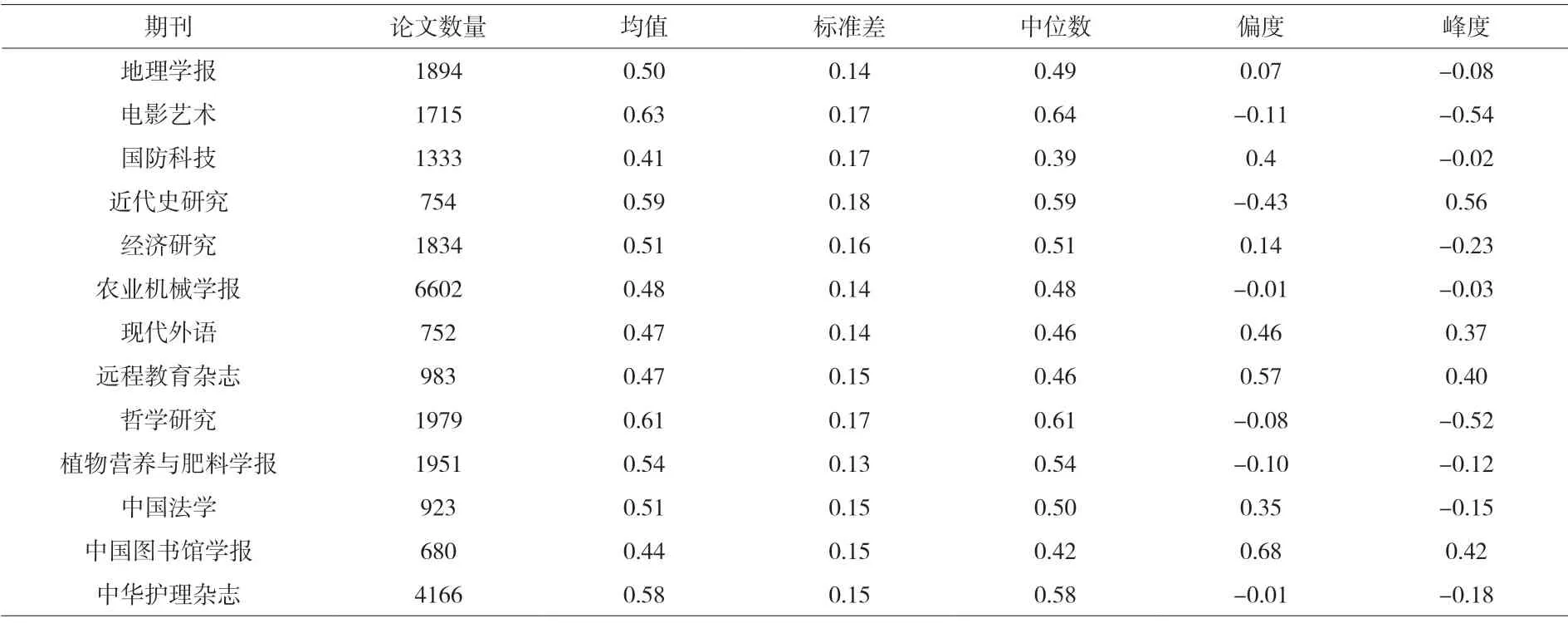
表5 题名、关键词、摘要的差异度(2010-2019)
为进一步分析差异度分布特征,根据公式(1)分别计算了25 566篇学术期刊论文的题名、关键词、摘要的差异度,再根据题录数据的刊名(JN)和出版年分面,绘制的差异度分布密度图,如图3所示。由图3可见,同一期刊在不同年度的差异度分布(按列)以及同一年度不同期刊的差异度分布(按行)皆有所变化,且并无显著特征,表明题名、关键词、摘要在揭示论文主题上的差异度具有随机性,这与现实情况较为吻合。
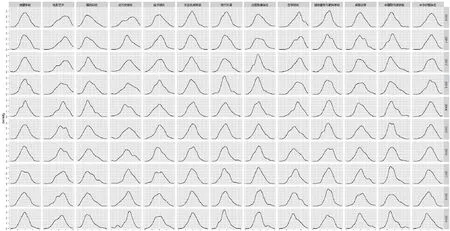
图3 差异度分布密度图
4 结果分析
4.1 题名、摘要、关键词长度统计情况
由表2可得,13种期刊的论文题名长度均值约在16-25间,摘要长度均值约在146-656间,关键词个数均值约在3-5间。《中国学术期刊(光盘版)检索与评价数据规范》对题名、摘要长度及关键词个数做出了规定,其对题名的规定为中文题名字数不超过25字;对摘要的规定为字数在300-600之间;对关键词的规定是个数在3-8之间。表2中的数据统计结果显示,13种期刊的论文题名、关键词长度均值均符合相关规范,虽然个别期刊存在摘要长度均值不规范的情况,但大部分期刊的摘要长度均值仍是符合要求的。这说明,目前大部分期刊论文的题名、摘要、关键词的长度是符合规范的。
4.2 题名、关键词与摘要两两间差异度的整体分布情况
本文基于字符匹配算法、杰卡德相似度及余弦相似度算法对25 566篇论文的题名、关键词与摘要的差异度进行了计算,得出余弦相似度算法差异度值较为适中,因此以基于余弦相似度算法算出的差异度作为题名、关键词和摘要的差异度。如图2所示,题名-摘要的差异度(cosTS)、关键词-摘要的差异度(cosKS)均呈现中间多、两头少的状态,差异度频数最多的值在0.5左右,这说明大部分论文题名与摘要、关键词与摘要存在一定的差异;且这两者差异度为0或为1的情况几乎不存在,这说明这些论文的题名、关键词既不完全来自于摘要,与摘要间又不存在太过显著的差异,这得益于近年来多数期刊严格要求论文作者在投稿时提供完整的题录信息的做法,CNKI平台因关键词缺失而需从论文摘要中抽取关键词的情况较少,维普、万方等其他平台也是如此。而关键词-题名的差异度(cosKT)呈现中间多、两头多的趋势,这说明大部分论文题名与关键词间存在一定的差异,但部分论文存在关键词全部来自题名或题名、关键词完全不符的情况。经分析发现,关键词完全来自题名的论文多属于理学、工学、农学及医学这些自然学科,如表6所示。这可能是由学科特点决定的,自然学科中的术语大多形成了一定的标准,这些术语在题名与关键词中的表达一致。但论文关键词全部来自题名,也意味着自然学科的作者缺乏一定的学术论文写作素养,将题名与关键词混为一谈,忽视了两者的区别。而关键词与题名完全不符的论文则多属于人文社科,如经济学、艺术学及法学等。关键词与题名完全不符,可能是由于人文社科的相关术语尚未形成统一标准,同样的术语在关键词与题名中的表达不一致,如表6中属于经济学的论文题名中的通胀与关键词中的通货膨胀,虽含义一致,但一个是简写一个是全称,这种情况应尽量避免。
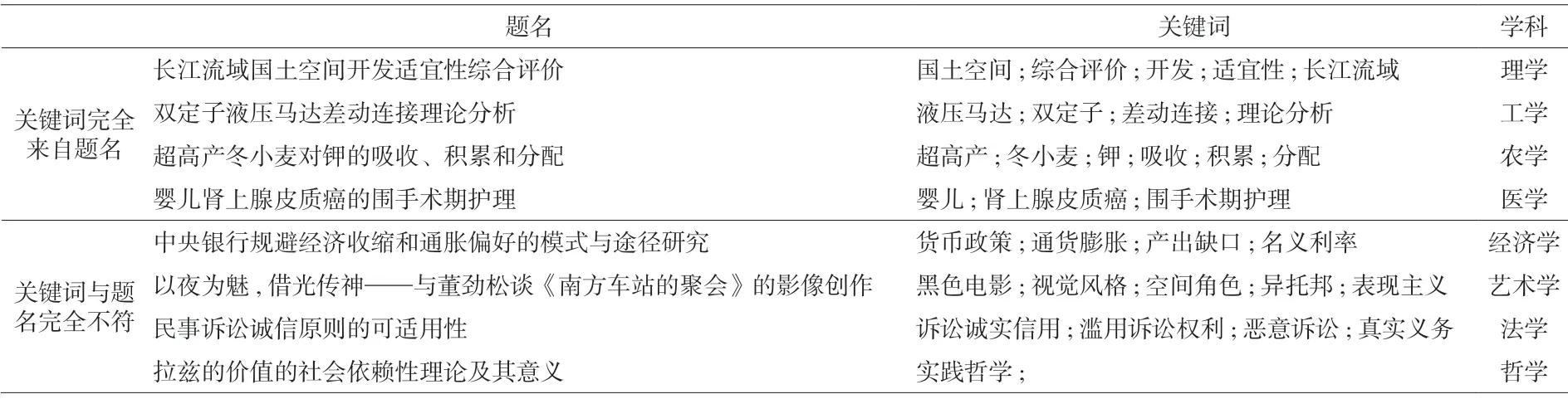
表6 题名与关键词间的特殊情况
4.3 不同年份与期刊的期刊论文差异度分布情况
如图3所示,不同期刊在不同年份的论文差异度虽有变化,但无显著规律。这说明期刊论文的差异度具有随机性。这与现实情况较为吻合,题名、关键词、摘要的差异度可能受多种因素影响,如学科总词汇、作者行文习惯等,并无明显规律。
结合表5、图3可得,各期刊论文的差异度分布规律较一致,都呈现“中间多,两头少”的趋势,各期刊的论文差异度平均值均在0.4-0.6之间,位于该差异度范围内的论文数最大,而差异度过低或过高的论文数都较少。这说明13个学科的期刊论文的题名、关键词与摘要间既不完全相似,也不存在太大的差异,互补性与差异性并存,因此应避免孤立对待期刊论文的题名、摘要和关键词,将三者结合起来,才能够获取更多的信息。
5 结论
本文在定义差异度的基础上,采用基于余弦相似度算法计算的题名与摘要的差异度、关键词与摘要的差异度、关键词与题名的差异度三者的几何平均值表征题名、关键词、摘要差异性,并采用实验研究与数据分析方法,以CNKI平台收录的13种期刊近10年来的全部论文为例,对题名、关键词及摘要间的差异性进行了探索性的研究。数据分析结果为余弦相似度算法计算的差异度大致呈现正态分布,但存在部分论文的关键词全部来自题名或题名与关键词完全不符的情况,不同期刊在不同年度的差异度分布无显著差别。本文的研究无论是对论文题录标引、论文检索,还是差异度计算方法都有一定的参考价值。
