基于深度学习的监督型典型相关分析
2022-05-14陈晓红蓝宇翔李舜酩
张 恒,陈晓红,蓝宇翔,李舜酩
(1.南京航空航天大学 理学院,南京 211106;2.南京航空航天大学 能源与动力学院,南京 211106)
0 概述
典型相关分析[1-3](Canonical Correlation Analysis,CCA)是经典的多视图数据降维方法,其广泛应用在计算机视觉[4]、故障检测[5]和风险评估[6]等领域,基本原理是将两个视图映射到同一个子空间中,使其在该子空间中的相关性最大。
由于在CCA的建模过程中未利用样本的标签信息,因此其属于无监督降维方法。针对有标签信息的多视图数据,文献[7]提出判别型典型相关分析(Discriminative Canonical Correlation Analysis,DisCCA),能够同时最大化类内相关性且最小化类间相关性。文献[8]将CCA与线性判别分析相结合,提出多视图线性判别分析(Multiview Linear Discriminative Analysis,MLDA),多视图不相关线性判别分析[9](Multi-view Uncorrelated Linear Discriminative Analysis,MULDA)进一步消除了MLDA降维后样本特征之间的冗余信息。
CCA 作为线性降维方法,无法有效处理非线性可分的数据。为此,在CCA 中引入核技巧[10]、流形学习[11]和深度神经网络[12]作为处理非线性可分数据的主要方法。文献[13]将核技巧引入到CCA 中,提出核典型相关分析(Kernel Canonical Correlation Analysis,KCCA)。针对数据量较大的数据集,KCCA 计算复杂度较高,文献[14]提出随机非线性典型相关分析(Randomized Nonlinear Canonical Correlation Analysis,RCCA),利用随机非线性投影处理数据的非线性特征,大幅降低了计算复杂度。文献[15]提出局部保持典型相关分析(Locality Preserving Canonical Correlation Analysis,LPCCA),旨在尽可能地保留数据的局部线性特征,并且降低全局非线性特征。文献[16]提出一种基于低秩表示的多视图典型相关分析方法(LRMCCA),该方法保留了数据的局部特征和全局特征,利用低秩表示代替欧氏距离,降低了对噪声的敏感度。文献[17]将CCA与深度学习相结合,提出深度典型相关分析(Deep Canonical Correlation Analysis,DCCA),即利用深度神经网络对两个视图进行非线性变换,通过训练使这两个深度神经网络输出数据之间的相关性最大。文献[18]提出深度典型相关自动编码器(DCCAE),不仅保证了两个深度神经网络输出数据的相关性最大,而且能准确地重构出原始数据。
文献[19]提出监督型深度典型相关分析(Supervised Deep Canonical Correlation Analysis,SDCCA),旨在样本经深度神经网络映射后,利用两个视图的类内散度矩阵寻找使不同视图间的相关性更大且同类样本更紧凑的特征。类似地,文献[20]将DCCA 与DisCCA 相结合,提出深度判别型典型相关分析(Deep Discriminative Canonical Correlation Analysis,DDCCA),利用深度神经网络对两个视图的数据进行非线性变换,引入指示矩阵使得两个网络输出数据的类内相关性最大且类间相关性最小。SDCCA和DDCCA 同时克服了CCA 的线性和无监督的局限性。
本文提出一种基于深度学习的监督型降维方法DL-SCCA。在2 个独立的深度神经网络结构上,通过增加1 个共同的全连接层,以softmax 函数作为该层的激活函数,利用该层的输出与标签信息之间的交叉熵对深度神经网络进行训练,以降低计算类内散度矩阵和指示矩阵的计算量,并且减少信息冗余。
1 相关工作
1.1 典型相关分析

其中:Cxx=Ε(XXT);Cxy=Ε(XYT);Cyy=Ε(YYT)。由于wx和wy具有尺度不变性,因此可将式(1)改写为:
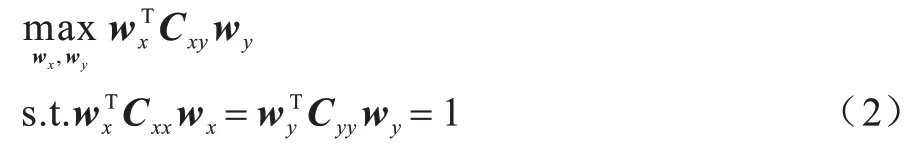
如果将原始数据投影到多维空间,CCA 的目标函数如式(3)所示:

1.2 深度典型相关分析
DCCA 将深度神经网络引入到多视图学习中,通过两个深度神经网络分别对两个视图进行非线性变换,并对这两个网络进行训练,使其输出之间的相关性最大。
令fx(X;θx)和fy(Y;θy)为两个视图所对应的深度神经网络,其中θx和θy分别为两个网络中的参数,则DCCA 如式(4)所示:

其中:

2 监督型典型相关分析
监督信息和深度学习的融入提高了CCA 的性能,受此启发,本文提出基于深度学习的监督型典型相关分析(DL-SCCA)。DL-SCCA 分别对两个视图的样本建立不同的深度神经网络进行非线性变换,同时对输出的样本矩阵进行相关性分析,在2 个独立的网络上增加1 个共同的全连接层,利用softmax 函数对该层的输出进行非线性变换,最后计算该层输出与类别标签信息之间的交叉熵,使得两个网络输出数据之间的相关性与交叉熵的相反数之和最大化。

在两个独立的深度神经网络结构上,再增加一层带有C个神经元的输出层,记为L+1 层。该层根据标签信息指导训练网络。L+1 层与两个深度神经网络均为全连接,连接权重为,偏置为bL+1,激活函数为softmax,其输出如式(8)所示:


图1 DL-SCCA 的深度神经网络结构Fig.1 Structure of deep neural network of DL-SCCA
令标签q∈RC是one-hot 向量,若该样本属于第i类,则qi=1,qj=0(j≠i)。与DCCA 类似,DL-SCCA同样采用批次输入的方式训练网络。假设每次输入的样本数量为m,Q=[q1,q2,…,qm]∈RC×m为类别标签矩阵,Hx∈Rk×m和Hy∈Rk×m为2 个深度神经网络的输出矩阵,P=[p1,p2,…,pm]∈RC×m为L+1 层的输出。DL-SCCA 旨在使Hx与Hy的k个相关系数之和以及P和Q的交叉熵相反数最大化。DL-SCCA采用与1.2 节相同的方式定义,则目标函数如式(9)所示:
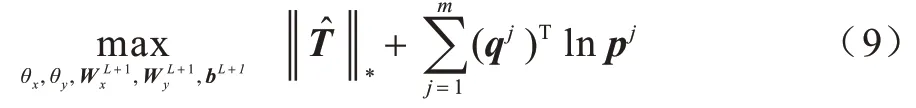
本文采用基于梯度的优化方法对DL-SCCA的网络参数进行更新。式(9)第一项对Hx和Hy的偏导数方法与式(6)一致。令式(9)第二项为Ε=下面计算Ε对于L+1 层m个样本的线性加权和Z∈RC×m的偏导数。由于:
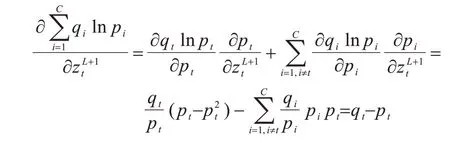
因此:

则:

根据链式求导法则,本文求得目标函数对所有参数的梯度,从而基于梯度对参数进行更新。
DDCCA、SDCCA 和DL-SCCA 均将深 度神经网络和样本标签信息分别与CCA 相结合。图2 所示为DCCA、DDCCA、SDCCA 和DL-SCCA 的深度神经网络结构。DCCA、DDCCA 和SDCCA 具有相同的深度神经网络结构。DCCA 的深度神经网络对每个视图数据进行非线性变换,然后对变换后的数据进行相关性分析。该过程未利用样本的标签信息,属于无监督降维。在相关性分析时,基于DisCCA 原理,DDCCA 实现了类内相关性最大化和类间相关性最小化。SDCCA 在相关性分析时,不仅使两个视图的相关性最大,并且使得两个视图的类内散度最小。这两种方法在构造指示矩阵和类内散度矩阵时,不仅耗时,而且存在信息冗余的问题。
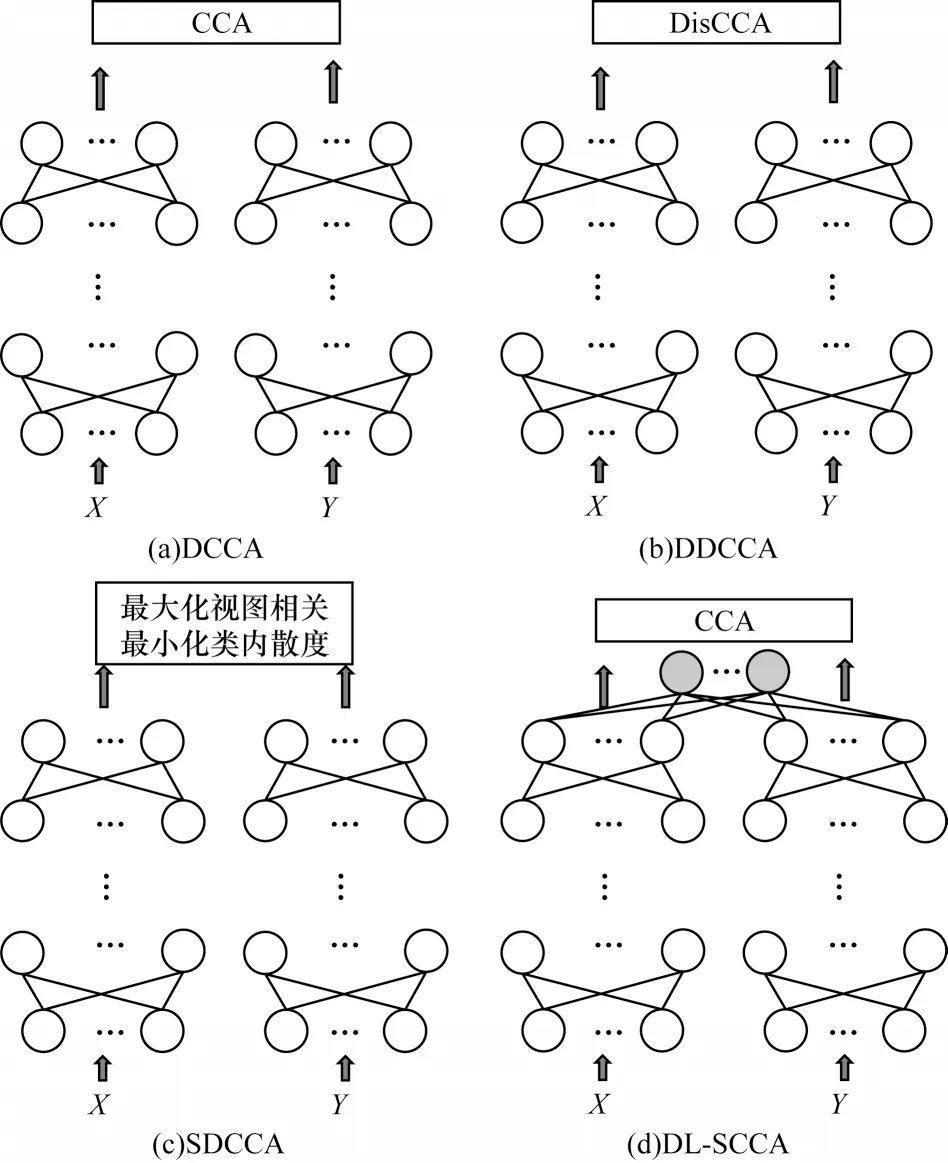
图2 深度神经网络的结构Fig.2 Structure of deep neural networks
针对该问题,DL-SCCA 将标签信息与DCCA相结合,在DCCA 网络结构的基础上增加一个公共的全连接层如图2(d)的阴影部分,不仅关注两个视图数据之间的相关性,还通过交叉熵相反数最大化的方式直接将数据的标签信息运用在深度神经网络的训练中。这种方式提取的特征保证了两个视图的相关性最大化,同时使得不同类样本之间的可分性最大化。与DDCCA和SDCCA相比,DL-SCCA具有2 个优点:1)无需构造类内和类间散度矩阵,降低了计算复杂度;2)该方法不仅对原始高维数据进行降维,而且增加的公共全连接层使其具有分类功能。
3 实验与分析
3.1 实验设置
3.1.1 实验数据集
本文分别在如下6 个数据集上进行实验。
1)WDBC数据集有2个视图,包含2类,共计569个样本。
2)WebKB 数 据集有2 个视图,包含2 类,共计1 051 个样本。
3)MFD 数据集有6 个视图,包 含10 类,共计2 000 个样本。
4)Dermatology 数据集有2 个视图,包含6 类,共计358 个样本。
5)ForestTypes 数据集有2 个视图,包含4 类,共计523 个样本。
6)ULC 数据集共有2 个视图,包含9 类,共计675 个样本。
3.1.2 不同方法对比
本文选择CCA、DisCCA、DCCA和DDCCA这4种降维方法进行对比,其中DisCCA 在CCA 的基础上加入了判别信息。DCCA 由CCA 与深度神经网络相结合得到,利用深度神经网络的非线性特征将CCA非线性化。DDCCA 将DCCA 与DisCCA 相融 合,在DCCA 的基础上引入判别信息。
3.1.3 评价指标
在CCA和DisCCA中,提取数据集X和Y的前k对典型向 量,即本文采用串行的方式将两个视图的特征进行融合,得到[XTWx,YTWy]T,使用最近邻分类器进行分类,最后将分类准确率作为该方法的性能指标。
在DCCA 和DDCCA 中,深度神经网络最后一层的输出即为降维之后的样本,同样采用串行的方式将2 个视图的特征进行融合。本文使用最近邻分类器对测试样本进行分类,并将统计的分类准确率作为该方法的性能指标。
在DL-SCCA 中采用2 种分类方式:1)采用和DCCA、DDCCA 相同的分类方式;2)采用DL-SCCA特有的网络结构,即根据第L+1 层的输出直接判断样本的类别,最终计算得到的分类准确率作为实验的性能指标。
3.1.4 参数设置
由于MFD 数据集有6 个视图,因此本文将所有的视图两两组合进行实验。WebKB 数据集为非常稀疏的离散数据,在实验之前应使用主成分分析对其进行预降维,仅保留方差不为0 的主成分。在DCCA、DDCCA 和DL-SCCA 的实验部分中,深度神经网络的深度L统一设置为4,宽度cx、cy为数据维数dx、dy的130%,非线性激活函数φ(·)为tanh 函数,学习率为0.5。在每次实验时,本文令输出的维数k在min(dx,dy)的20%~80%之间变化,并重复10 次实验,选取所有k值对应平均准确率的最大值作为最后的实验结果。每批次输入的样本数量m设为40。在每次实验中,从每个类别中选取60%的样本作为训练集,剩余作为测试集。
3.2 实验结果分析
CCA、DisCCA、DCCA、DDCCA、DL-SCCA Ⅰ、DL-SCCAⅡ这5 种方法在MFD 数据集上的分类准确率对比如表1 所示,其中,DL-SCCAⅠ方法利用最近邻分类器得到分类准确率,DL-SCCAⅡ方法采用网络本身结构得到分类准确率。

表1 在MFD 数据集上不同方法的分类准确率对比Table 1 Classification accuracy comparison among different methods on MFD dataset %
从表1可以看出,DL-SCCAⅠ方法和DL-SCCAⅡ方法在MFD 数据集的15 种视图组合方式的性能相比于CCA、DisCCA、DCCA、DDCCA 方法均大幅提升。DL-SCCAⅡ方法通过深度神经网络自身结构进行分类,由于直接利用样本的类别信息,因此其分类性能相比于最近邻方法的分类性能较优。由于DisCCA、DDCCA 和DL-SCCA 方法利用类别标签信息提取低维特征,因此均比无监督学习的CCA 和DCCA 方法的分类性能好。这说明利用数据本身包含的类别标签信息,可以提升低维特征的分类性能。而非线性降维方法DCCA、DDCCA 和DL-SCCA 相比于线性降维方法CCA 和DisCCA 的性能更优。这说明原有的线性降维方法经过非线性拓展后,能够有效解决非线性可分的问题。DL-SCCAⅠ和DL-SCCAⅡ两种分类方式得到的分类准确率相比于DCCA 平均提升了5.26 和6.37 个百分点,相比于DDCCA 提高了1.25和2.36 个百分点。DL-SCCA 方法能够有效利用数据的类别标签信息,使降维之后的低维特征具有较优的分类性能。
CCA、DisCCA、DCCA、DDCCA、DL-SCCA Ⅰ、DL-SCCAⅡ这5 种方法在不同数据集上的分类准确率对比如表2 所示。
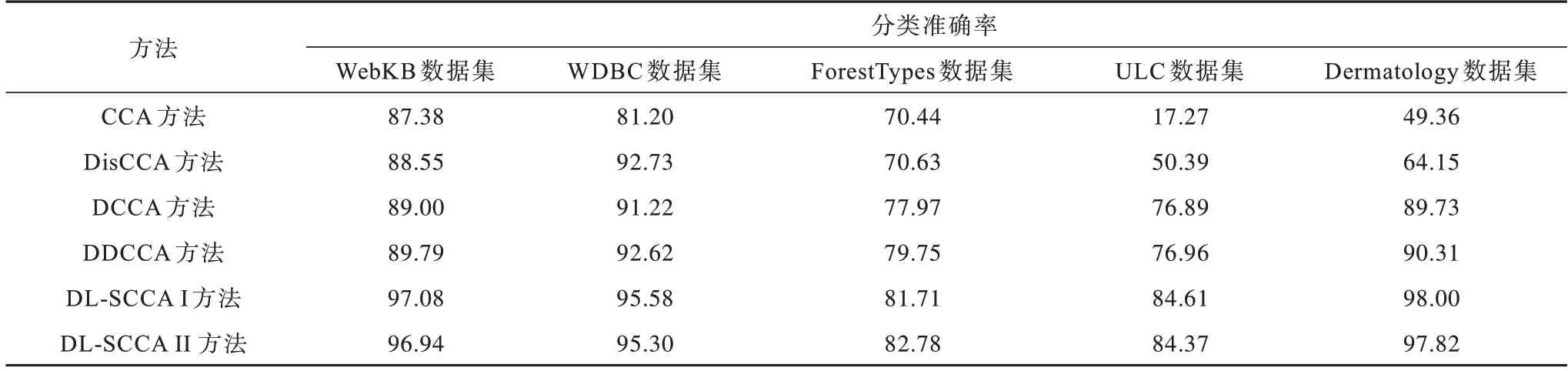
表2 在不同数据集上各方法的分类准确率对比Table 2 Classification accuracy comparison among different methods on different datasets %
相比无监督的CCA 方法,在ULC 数据集上,DisCCA 方法的分类准确率提高了33.12 个百分点。在ULC 数据集上,DCCA 方法相比CCA 方法的分类准确率提高了59.62 个百分点。DDCCA 方法融合DisCCA 和DCCA 的特点,其兼具非线性和监督学习的性质,相比其改进前的DisCCA 和DCCA,能够大幅提高分类准确率。本文DL-SCCA 方法和DDCCA方法都对DCCA 进行监督型扩展,但是DL-SCCAⅠ和DL-SCCAⅡ方法得到的分类准确率均比DDCCA高。因此,DL-SCCA 能够直接有效地利用数据本身包含的类别标签信息,使其提取的低维特征具有更优的分类性能。
3.3 网络层数对实验的影响
深度神经网络的层数是模型复杂度的一个重要参数,其对模型的性能影响较大。为探究网络层数对实验结果的影响,本文将网络层数L设置为2~14,步长为1,其他参数的设置与3.1.4 节相同。在WDBC、Dermatology、ForestTypes 和ULC数据集上,网络层数对实验结果的影响如图3所示。

图3 网络层数对实验结果的影响Fig.3 Influence of number of network layers on experimental results
从图3 可以看出,随着网络层数的增加,所有数据集上的分类准确率均呈下降趋势。其原因为样本数量太少和模型复杂度过高,导致发生过拟合现象。DL-SCCAⅡ方法的分类准确率下降程度更大,说明网络结构分类器更容易发生过拟合。DL-SCCAⅠ方法在一定程度上可以缓解过拟合现象的发生。
3.4 批次样本数量分析
由于本文方法需要计算相关性,在训练模型时本文按批次输入样本。本文研究了每批次样本数量对模型性能的影响,每批次样本数量m设置为20~140,步长为20,其他参数设置与3.1.4 节一致。本文在WDBC、Dermatology、ForestTypes 和ULC 数据集上进行批次样本数量分析。由于模型在不同数据集上的训练时间差异比较大,因此本文对每个数据集的训练时间进行了归一化。每批次样本数量对分类精度的影响如图4 所示。

图4 每批次样本数量对分类精度的影响Fig.4 Influence of number of samples per batch on classification accuracy
从图4 可以看出,随着每批次样本数量的增加,模型的分类精度变化并不明显,说明每批次的样本数量对模型性能的影响不大。当每批次样本数量足够多 时非奇 异,可去除 其中的正则 化项。为验证样本数量对训练时间的影响,本文将每种方法的训练时间规范化至0~1,如图5 所示。
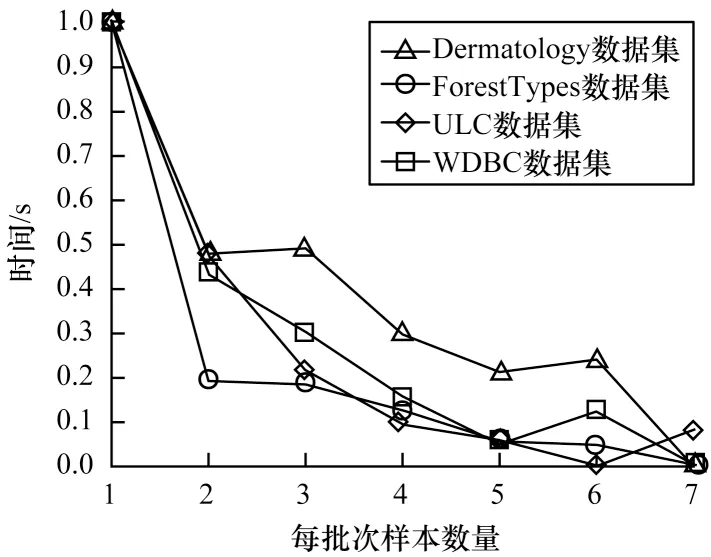
图5 每批次样本数量对计算时间的影响Fig.5 Influence of number of samples per batch on calculation time
从图5 可以看出,随着每批次样本数量的增加,训练时间大幅缩短,因此,在内存足够的前提下可以适当地增加样本数量。当获得的数据是数据流形式时,DL-SCCA 方法能够达到增量学习[21]的效果。
4 结束语
本文提出基于深度学习的监督型典型相关分析方法DL-SCCA,通过增加一个公共的全连接层,将softmax函数作为激活函数,利用模型输出与样本标签的交叉熵训练深度神经网络,获得具有强判别性的低维表示。实验结果表明,相比CCA、DisCCA、DCCA 等方法,该方法具有较优的分类性能。后续将通过计算多个视图的相关性和交叉熵,同时训练深度神经网络,使本文方法适用于不完全多视图数据。
