融合弱层惩罚的卷积神经网络模型剪枝方法
2022-05-14房志远石守东郑佳罄胡加钿
房志远,石守东,郑佳罄,胡加钿
(宁波大学信息科学与工程学院,浙江宁波 315211)
0 概述
目前,深度卷积神经网络已在计算机视觉、语音识别、自然语言处理等领域[1-3]取得了重大突破。但由于深度学习模型的计算和存储需求巨大,在不断更新任务精度的同时,模型参数量和网络深度也随之增长,因此很难在一些资源受限的嵌入式设备上进行部署。针对该问题,研究人员提出了一系列解决方法,这些方法主要包括低秩近似[4]、知识蒸馏[5]、轻量化网络结构[6]、模型剪枝[7-8]等。它们从不同的角度考虑如何尽可能减少模型在推理过程中所需的随机存储器(工作内存)、处理器计算(推理代价)、闪存(存放模型)等资源。
模型剪枝方法作为模型压缩的重要分支,目前发现其可在保证精度没有显著下降的同时大幅减少模型大小和浮点操作数(Floating Points of Οperations,FLΟPs)。需要注意的是,卷积神经网络模型的低层卷积核趋向于提取粗级别特征(如点和线),高层卷积核则趋向于提取抽象特征(如常见的目标和形状)。因此,对于一个模型而言,每一层对最终模型的精度影响或贡献是不一样的。此外,考虑到在剪枝和训练期间网络权重的重要性是动态变化的[9],在剪枝过程中对其进行动态更新在一定程度上可以提升模型精度。
本文提出一种融合弱层惩罚的结构化模型剪枝方法。在局部层面,使用欧式距离计算各层中所有卷积核的信息距离,同时利用各层相关性值的数据分布特征判别层重要性,并对弱层中的卷积核进行惩罚。在训练与剪枝过程中,通过全局掩码技术对每一个卷积核实现动态剪枝,每次剪枝算法会从全局层面评估每一个卷积核的冗余性。
1 相关工作
模型剪枝技术是通过去除模型中的冗余参数和结构来实现深度神经网络的推理加速。现有模型剪枝方法可分为结构化和非结构化模型剪枝。
非结构化剪枝也称为权重剪枝,这些方法注重于剪枝卷积核的细粒度权重。文献[10]提出使用二进制掩码来检验连接神经元是否被剪枝,并且考虑对已剪枝神经元进行恢复,从而减少过度剪枝所带来的精度影响,在一定程度上保证了精度。但该方法需要通过专用的稀疏矩阵操作库或硬件实现加速,且这样不规则的结构很难利用现有的基本线性代数子程序库[11]。文献[12]对基于“范数小重要性低”的剪枝标准进行研究,提出基于范数标准剪枝的2 个依赖条件:1)核的范数分布应该足够大;2)核的最小范数值应该非常小。基于此,又提出新的基于几何中值的卷积核重要性判断标准。文献[13]为解决“硬剪枝”在训练过程中的不可恢复性,提出利用“软”方式进行动态剪枝,在训练过程中可对已剪枝核的权值进行更新。文献[14]提出一种融合卷积层和BN 层双层参数信息的动态剪枝方法,该方法利用注意力机制以及BN 层缩放系数选择冗余卷积核。文献[15]为加速嵌入式端的表现,采用混合网络剪枝进一步减少网络中的冗余参数并加速网络。文献[16]首先将BN 层的缩放因子与输出相乘,接着联合训练网络权重和这些缩放因子,然后将较小缩放因子的通道剪枝,最后微调剪枝后的网络。但是上述方法均存在以下问题:一方面,通常层采用固定/均匀剪枝率对各卷积层实施剪枝,忽略了各层之间的差异性;另一方面,在一层内通过局部重要性评估得到卷积核,无法说明其对于整个模型的重要性。本文将考虑对各卷积层的重要性进行判断并进行惩罚,从全局层面进行评估,改善误剪导致的精度下降问题。
对于结构化剪枝,现阶段研究人员提出了自动搜索网络结构的方法,该方法考虑各层之间的差异性,自动探索和学习网络架构,最终得到一个结构化非均匀的剪枝模型。文献[17]提出一种完全可微分的稀疏性方法,可以使用随机梯度下降方法同时学习网络的权重和稀疏结构。文献[18]使用强化学习的方法实现自动剪枝权重和卷积核,该方法得到了不错的效果,但训练成本较大。文献[19]将预训练好的模型直接部署在资源受限的手机平台上进行压缩,最后通过评估压缩后的直接性能表现进行反馈。文献[20]利用生成器产生多个候选剪枝策略,每一个剪枝策略为各层剪枝率的组合,再通过基于自适应BN 层的候选评估模块挑选出最有可能的候选策略并进行微调,该方法大幅降低了剪枝时间代价,但训练过程相对复杂。在多个模型和数据集上的实验结果表明,该方法在保证精度损失较小的同时,有效地减少了模型参数量和FLΟPs。
本文引入基于几何中值的卷积核重要性判断标准[12],提出一种融合弱层惩罚的结构化非均匀模型剪枝方法。由于文献[12]利用几何中值理论证明了距离各层中几何中值较近的卷积核可被该卷积层中其他卷积核替代,因此对这些卷积核进行剪枝,对最终模型精度影响较小。本文利用该方法中核重要性判断标准,实现了层重要性判断和惩罚,并在全局层面进行重要性评估。
2 融合弱层惩罚的结构化模型剪枝方法
2.1 符号与定义
假设一个卷积神经网络有L层,使用Ci和Ci+1分别表示ith卷积层的输入输出通道数,Fi,j表示ith层的jth卷积核,其中:Fi,j的维度为,K表示核的尺寸。ith层的输入特征图S和输出特征图O分别为Ci×Hi×Wi和Ci+1×Hi+1×Wi+1,ith层的权 值Wi可表示 为{Fi,j,1 ≤j≤Ci+1}。因 此,ith层的卷 积操作可表示 为{O=Fi,j×S,1 ≤j≤Ci+1},卷积神经网络可被参数化表示为1≤i≤L,Y=K×K×Ci+1},Fi,j的权重为
2.2 剪枝标准
利用欧式距离计算各卷积核相对于计算当前卷积层的冗余性[12]。具体而言,卷积神经网络所有卷积层中卷积核的冗余性可以通过欧式距离求得,将其称为信息距离R。例如,ith层的jth卷积核Fi,j的信息距离值可以表示如下:
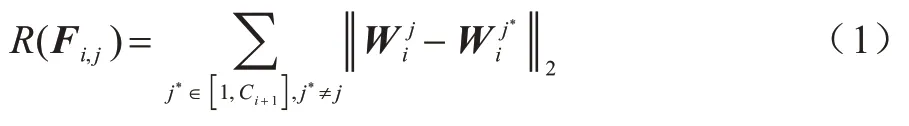
通过式(1)所求出的信息距离值的数据分布在各卷积层中存在差异,图1(a)给出了各卷积层中卷积核信息距离R的数据分布,其中黑色圆表示该层数据的平均值,曲线为R值的分布估计。图1(b)为基于贡献度归一化的卷积核信息距离,卷积核整体向左偏移。通过全局筛选Z值较低的卷积核,并利用掩码实现全局剪枝,其中黑色圆表示惩罚后的卷积核。全局剪枝后的效果如图1(c)所示,其中黑色圆为需要剪枝的卷积核。
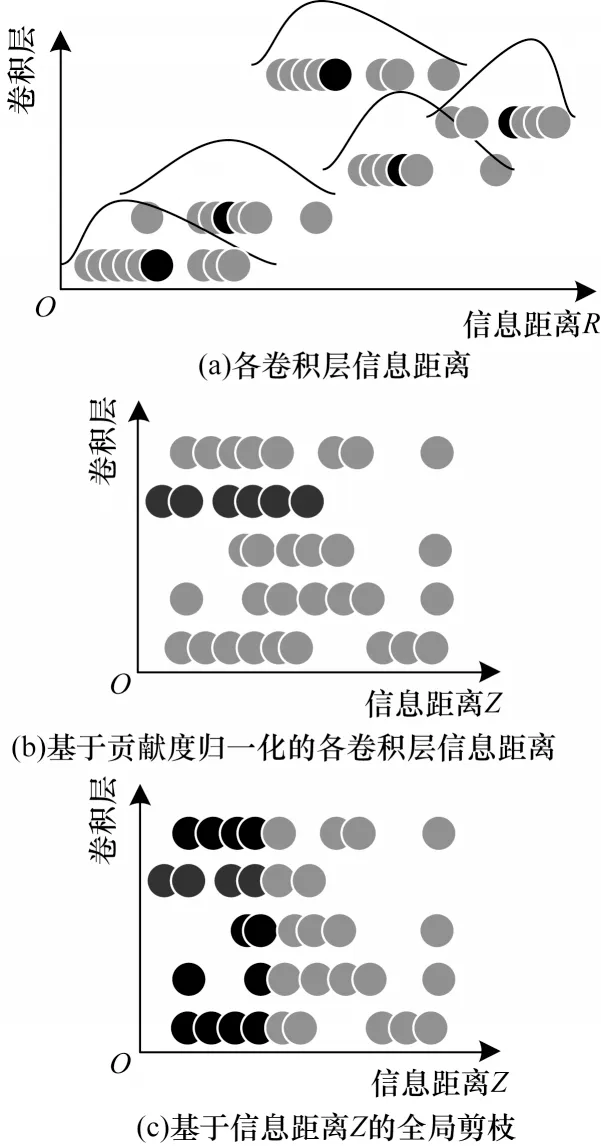
图1 卷积神经网络模型剪枝流程Fig.1 Pruning procedure of convolutional neural network model
若直接通过信息距离R进行全局剪枝可能会剪掉某一卷积层中所有的卷积核。针对该情况,对每一层中的卷积核进行归一化处理来消除这种差异性。同时,为了考虑对弱层进行惩罚,需对每层乘上贡献度,贡献度较小的层在归一化后会增加对该层卷积核的剪枝,如式(2)所示:

基于信息距离R可以较好地表明各卷积层中卷积核的冗余程度。因此,可以认为某一层卷积核信息距离R的标准偏差(STD)越小,则该层卷积核之间的信息距离越接近,卷积核之间相似的可能性越高,如图2(a)所示。相反地,如图2(b)所示,STD 越大,该层卷积核之间相似的可能性越低。
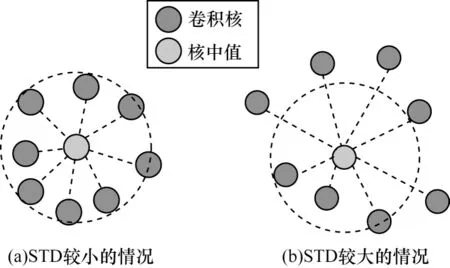
图2 卷积核信息距离与标准偏差的关系Fig.2 Relationship of information distance and standard deviation of convolution kernel
利用这种数据分布特征对弱层进行识别。假设图1 中的第2 层为需要识别的弱层,首先利用式(3)计算各卷积层相关性R值的标准偏差,再使用式(4)计算所有层的平均标准偏差,最后利用式(5)和式(6)对该层进行判断并对弱层加入贡献度,贡献度较低的层中卷积核的R值会得到惩罚,最终在全局重要性评估过程中对其进行弱化。

2.3 剪枝过程
考虑到训练中卷积核的重要性是动态变化的[17,21],引入掩码实现动态剪枝。
动态剪枝是指利用全局掩码M对模型权值W进行动态更新,其中,为二进 制掩码,W=当通过式(1)和式(2)计算出每一个卷积核信息距离Z后,根据全局剪枝率P对所有卷积核进行筛选,得到符合条件的Call个卷积核,其中根据所选卷积核对掩码M更新,并通过掩码M对权重W更新。例如,满足剪枝条件的集合为其中表示ith层的jth卷积核。经过式(7)计算掩码,再通过掩码对满足条件的卷积核进行剪枝,操作形式如式(8)所示。

算法融合弱层惩罚的结构化非均匀模型剪枝算法

3 实验结果与分析
3.1 数据集与训练策略设置
为验证本文提出方法的有效性,采用的数据集包 括CIFAR-10、CIFAR-100 和SVHN 数据集。CIFAR-10 数据集包含50 000 张训练图和10 000 张测试图,共10 个种类。CIFAR-100 数据集的图像数量和CIFAR-10 相同,共有100 个种类。SVHN 数据集为Google 的街景门牌号数据集,训练集包含73 257 个数字,测试集包含26 032 个数字,其中每一张图像都由一组数字组成,图像分辨率为32×32 像素的彩色图像。在网络结构的选择方面,包括单分支网 络(VGG16)、多分支网络(Resnet20、32、56、110),轻量化网络(Mobilenet-v1),所有实验均使用深度框架PyTorch1.6.0,运行于NVIDIA 2080TI GPU。
对于数据集CIFAR-10 和CIFAR-100 的训练策略和文献[13]相同,输入图像分辨率为32×32 像素,使用Nesterov的随机梯度下降,权重下降系数为5e-4,batchsize为128,初始学习率为0.1,在epoch为80、120、160时学习率降低10 倍,共训练200 个epoch。其中,数据增强策略和文献[22]相同。对于轻量化网络Moblienet-v1,修改第1 个卷积操作的stride 为1 以适合输入图像分辨率。
在剪枝策略上,本文方法从头开始迭代训练与剪枝模型,在每次训练后选择剪枝操作。除VGG 模型外,其他模型不需要额外的微调恢复精度,从而降低训练的时间开销。同时,将本文方法(Οurs)与FPGM[12]、SFP[13]、GDP[21]、MIL[23]、PFEC[24]等方法进行实验对比,其中,贡献度为ν,GDP 为结构化非均匀剪枝方法。
3.2 CIFAR-10 数据集上的实验结果分析
对于CIFAR-10 数据集,选择在VGG16、Resnet20、Resnet32、Resnet56、Resnet110 和Mobilenet-v1 上进行实验,实验结果如表1 所示,其中F.T 表示用较小的学习率对模型进行训练恢复精度,“—”表示无有效实验结果。

表1 在CIFAR-10 数据集上的实验结果Table 1 Experimental results on the CIFAR-10 dataset %
从VGG16 实验结果可以看出:相比于FPGM 方法,本文方法在各指标上均有所提高;相比GDP 方法,本文方法的精度虽下降了0.23 个百分点,但FLΟPs 却减少了39.9 个百分点。
从Resnet20、Resnet32、Resnet56 和Resnet110 实验结果可以看出:本文方法相比其他方法具有更高的剪枝模型精度,同时参数量和FLΟPs 也大幅减少;对于Resnet32,当ν=0.9 时,本文方法在FLΟPs 和参数量分别减少46.8%和45.2%的情况下,精度甚至超过了基准精度;对于Resnet56,当ν=0.7 时,本文方法相比于GDP 方法精度提升0.42 个百分点的同时,FLΟPs 和参数量分别减少了8.3 和14.2 个百分点,相比于FPGM 方法精度提升0.45 个百分点的同时,FLΟPs 和参数量分别减少了7.4 和3.0 个百分点,相比于PFEC 方法,精度提升了1.84 个百分点且FLΟPs减少了33.4 个百分点;对于Resnet110,当ν=0.9 时,本文方法在FLΟPs 下降66.8%的情况下,相比基准精度仅损失了0.06 个百分点;对于Mobilenet-v1,当参数量和FLΟPs 分别减少了95.3%和92.1%的情况下,本文方法精度相比于基准精度仅损失了3.24 个百分点。
综上所述,相比未考虑层差异性的SFP、PFEC、FPGM 和MIL 方法,本文方法可以剪枝出更好性能的模型,关键在于其考虑了对重要性较高的层减少剪枝,提高了模型精度,同时对Mobilenet-v1 进行剪枝的结果表明,本文方法同样适用于轻量化网络结构剪枝,经过剪枝后的Mobilenet 模型所占内存更小、推理速度更快。
3.3 CIFAR-100 数据集上的实验结果分析
对于CIFAR-100 数据集,选择在Resnet32、Resnet56 和Resnet110 上进行实验,实验结果如表2所示。

表2 在CIFAR-100 数据集上的实验结果Table 2 Experimental results on the CIFAR-100 dataset %
从Resnet20、Resnet56 和Resnet110 实验结果可以看出:对于Resnet32,当ν=0.9 时,本文方法精度相比于基准精度仅损失2.02 个百分点的情况下,FLΟPs 和参数量分别减少了49.8%和48.5%,相比于SFP 方法精度提升了0.6 个百分点,相比于FPGM 方法精度提升了0.55 个百分点;对于Resnet56,本文方法同样优于对比方法,例如,当ν=0.9 时,相比于FPGM 方法精度提升了0.32 个百分点,但FLΟPs 和参数量分别减少了6.3 和3.6 个百分点,相比于SFP方法精度提升了1.19个百分点;对于Resnet110,当ν=0.9时,本文方法精度相比于FGPM方法提升了1.49 个百分点,FLΟPs 和参数量分别减少了8.6 和5.2 个百分点,在精度和其他性能之间获得了更好的权衡。
总体而言,本文方法可以在提高精度的同时大幅减少参数量和FLΟPs,这关键在于剪枝算法引入了弱层的识别与惩罚,将卷积核从局部卷积层面的重要性评估上升为全局网络层面的重要性评估。使用该处理方式,当提高全局剪枝率时,剪枝算法会增加对弱层的剪枝。因此,最终模型精度损失在很小的情况下,却可以更多地减少模型FLΟPs 和参数量。
为验证本文提出的剪枝方法所识别的弱层的合理性,使用Resnet32 在CIFAR-100 数据集上进行实验。对本文方法所识别到的弱层分别进行剪枝与训练(剪枝率为0.8),测试各层对最终模型精度的影响。实验结果如图3 所示,其中基准精度为71.21%。从图3 可以看出,在对弱层保留较少特征的情况下,模型依然获得了较好的精度,可以认为所识别到的弱层对最终模型的影响较小,验证了本文方法的有效性。

图3 弱层在较高剪枝率下训练得到的模型精度Fig.3 Model accuracy of the weak layer trained at a higher pruning rate
3.4 SVHN 数据集上的实验结果分析
对于SVHN 数据集,本文选择在多分支网络Resnet32 和轻量化网络Mobilenet-v1 上进行实验,实验结果如表3 所示。从表3 可以看出:对于Resnet32,本文方法可以在精度仅损失0.65 个百分点的情况下,参数量和FLΟPs 分 别减少了80.0% 和82.4%;对于Mobilenet-v1,本文方法可以在模型精度没有大幅下降的情况下,参数量和FLΟPs分别减少了92.7%和95.3%;原始模型过度参数化,从而验证了本文剪枝方法的有效性。
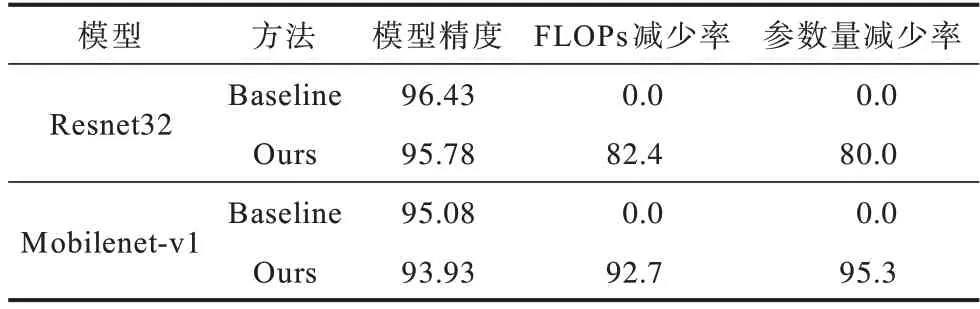
表3 在SVHN 数据集上的实验结果Table 3 Experimental results on the SVHN dataset %
3.5 相关参数对模型性能的影响
为研究贡献度对模型性能的影响程度,在CIFAR-10数据集上对贡献度为1.0、0.9、0.7、0.5 和0.1 下的模型精度、FLΟPs和参数量减少率进行统计,实验结果如表4所示。从表4 可以看出,Resnet32 和Resnet56 分别在ν=0.9、ν=0.7 时获得最佳性能,说明贡献度ν在一定程度上提升了模型性能,同时也证明了本文方法的有效性,但是过度惩罚弱层会导致精度大幅下降。
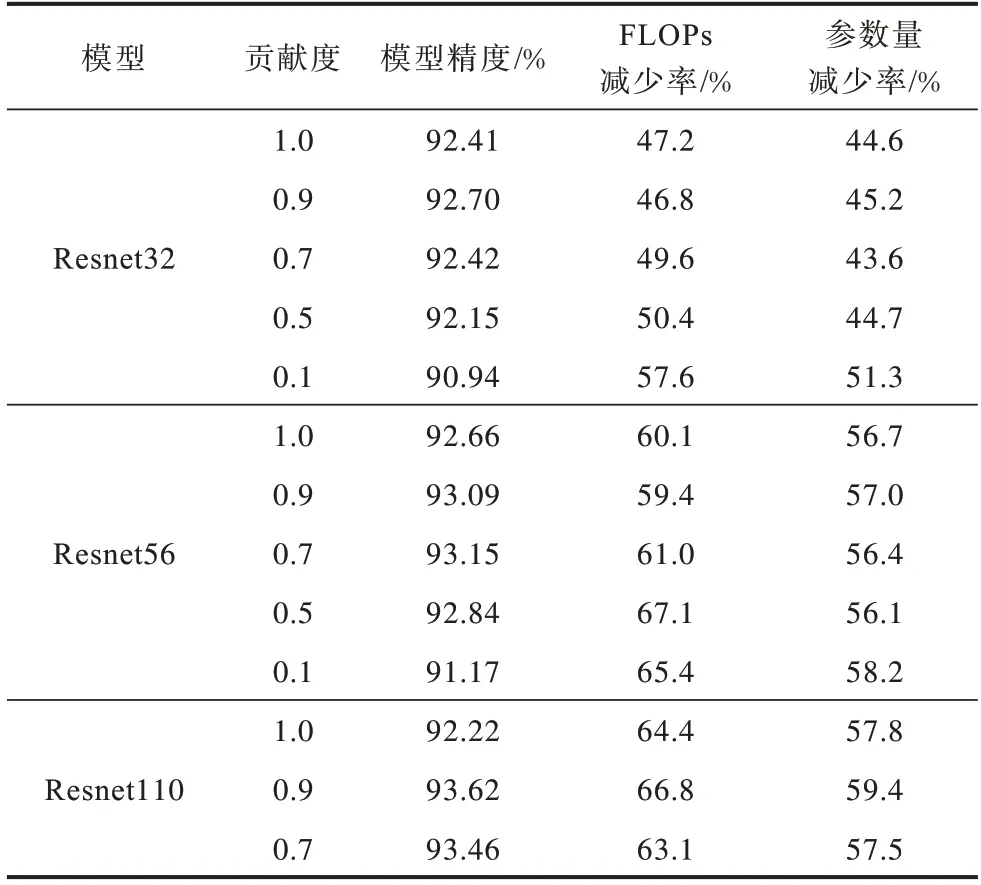
表4 层贡献度比较结果Table 4 Comparison results of layer contribution
为进一步研究剪枝算法的性能,对比Resnet110 在不同FLΟPs 下本文方法的模型精度变化情况。如图4所示:当FLΟPs 减少率约小于18%时,模型精度得到了提升,说明通过本文方法进行剪枝,当剪枝率较小时,模型得到了正则化作用,增强了模型泛化能力;当FLΟPs减少率约大于67%时,模型得到大幅剪枝,模型的表征能力受到影响,模型精度也因此下降明显。

图4 不同FLOPs下Resnet110在CIFAR10数据集上的模型精度Fig.4 Model accuracy of Resnet110 on CIFAR10 dataset under different FLOPs
对于层的重要性判断,本文采用2 种重要性判断阈值作为对比,实验结果如表5 所示。在实验中,相同网络设置相同的配置参数,每个实验进行3 次,使用平均值加上标准差作为实验结果。从表5 可以看出相比于整体性能有所提升,验证了选择作为重要性判断阈值的正确性与有效性。

表5 在不同重要性判断阈值下的模型精度Table 5 Model accuracy under different importance judgment thresholds %
4 结束语
本文提出一种融合弱层惩罚的结构化非均匀模型剪枝方法,使用欧式距离计算各卷积层中所有卷积核的信息距离,利用各层信息距离值的数据分布特征识别层的冗余性,并通过基于贡献度的归一化函数消除各层之间的差异性,同时从全局层面评估卷积核重要性,从而筛选卷积核。在多个数据集上的实验结果表明,相比于FPGM、SFP、GDP、MIL、PFEC 等方法,本文方法剪枝得到的网络模型获得了较好的性能提升,且不需要特殊的软件和硬件加速,为下一步模型部署奠定了基础。后续可将本文剪枝算法应用到基于深度学习的坐姿识别等任务中,利用其对深度学习人体姿态估计模型进行剪枝,减少人体姿态估计模型提取骨骼特征所需的计算和存储资源,使深度学习模型可在保证识别精度的情况下加快检测速度,并结合模型量化等技术,提升深度学习模型在嵌入式设备上的运行效率。
