基于深度网络的滚动轴承智能故障诊断
2022-05-13李金才付文龙王仁明陈星孟嘉鑫
李金才,付文龙,2,3,王仁明,陈星,孟嘉鑫
(1.三峡大学 电气与新能源学院,湖北 宜昌 443002;2.三峡大学 梯级水电站运行与控制湖北省重点实验室,湖北 宜昌 443002;3.三峡大学 水电动机械设备设计与维护湖北省重点实验室,湖北 宜昌 443002)
0 引言
滚动轴承作为煤矿机械设备中的重要部件之一[1],其工作环境复杂,易出现损坏,从而影响煤矿生产系统的可靠性和安全性。因此,对煤矿机械设备中的滚动轴承进行智能故障诊断具有重要意义[2]。
随着机器学习的快速发展,深度学习被引入到机械设备智能故障诊断中,并取得了一定的成果。但基于深度学习的机械设备故障诊断模型却要求训练集和测试集满足独立同分布的原则,当训练集与测试集分布不同时,会出现模型泛化能力差的问题[3]。由于工业过程中大量数据样本难以被标记,且滚动轴承又常常工作在变工况情况下,导致实际故障诊断中缺少或无法获取与待测数据分布相同的大量带标签训练数据[4]。
鉴此,研究者们将迁移学习(Transfer Learning,TL)引入到故障诊断中,以实现不同工况之间的知识迁移。文献[5]使用少量的目标域标记数据对源域数据训练好的模型进行微调,以此获得目标域数据的故障诊断模型。文献[6]提出了一种基于参数迁移的改进最小二乘支持向量机迁移学习方法,实现了目标域中已知标签数据较少条件下的滚动轴承故障诊断。文献[7]通过改进TrAdaBoost 方法对源域样本重新加权,提升了分类准确率。
但上述方法均需目标域含少量带标签样本,当目标域完全不含标签时,模型泛化能力变弱且诊断准确率下降。无监督的域适应方法可通过学习源域和目标域的共享特征来减小域之间的差异,进而解决目标域数据不含标签的问题[8]。文献[9]设计了一种跨设备故障诊断模型,该模型主要引入最大均值差异(Maximum Mean Discrepancies,MMD)公式来度量源域和目标域的特征分布差异,进而帮助一维卷积神经网络(Convolutional Neural Networks,CNN)学习源域和目标域的共享特征,达到无监督迁移学习的目的。文献[10]在MMD 公式的基础上,提出多核最大均值差异(Multi Kernel-Maximum Mean Discrepancies,MK-MMD)距离,将带标签源域样本和无标签目标域样本的特征同时映射到希尔伯特空间进行度量,产生域间分布差异损失,进而使模型选择更多源域与目标域相似特征。文献[11]提出一种基于域对抗学习策略的故障诊断网络,该网络学习通用的域不变特征,以提高模型的泛化能力。文献[12]在域分类器中添加Wasserstein 距离,通过域对抗训练,实现了对无标签目标域样本的分类。但目前研究大部分集中于源域与目标域的边缘分布对齐,缺乏对数据间条件分布的研究,导致一些目标域样本被错误分类。
为避免一些目标域样本被错误分类,本文提出一种基于深度自适应迁移学习网络(Deep Adaptive Transfer Learning Network,DATLN)的诊断模型,并将其应用到滚动轴承的故障诊断中。首先,结合多尺度卷积神经网络(Multiscale Convolutional Neural Network,MSCNN)和双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)提取振动信号中多尺度和蕴含时间信息的故障特征;其次,构建域自适应模块,引入域对抗(Domain Adversarial,DA)训练,结合自适应联合分布(Adaptive Joint Distribution,AJD)度量机制,动态地减少源域和目标域数据的边缘分布和条件分布差异;最后,使用带标签的源域样本和无标签的目标域样本训练网络,进而实现对无标签目标域样本进行分类。
1 基本理论
1.1 迁移学习
假设在机械装备中存在工况A 和工况B 2 个工况,工况A 为有标签的源域:1,2,···,s,s为源域的样本个数,工况B 为无标签的目标域:,j=1,2,···,t,t为目标域的样本个数,其中,xi,xj分别为第i个源域样本和第j个目标域样本,yi为第i个源域样本的标签,源域和目标域的特征空间及类别空间均相同。但由于数据产生机制的影响,源域Ds和目标域Dt的边缘分布和条件分布均不同。因此,无监督迁移学习的目标就是利用带标签源域Ds的先验知识建立一个模型,以实现无标签目标域Dt的样本分类,如图1所示。
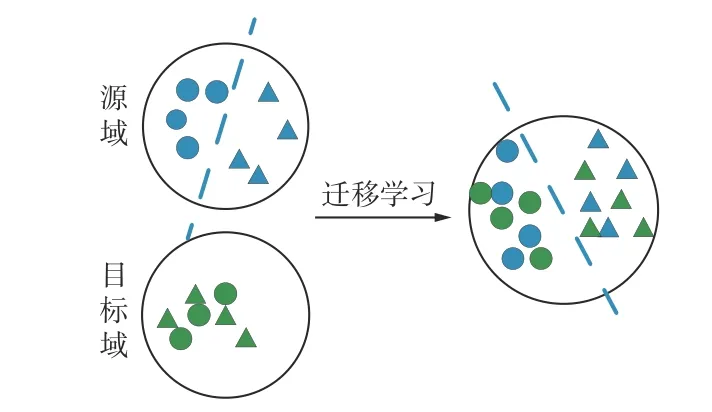
图1 迁移学习Fig.1 Transfer learning
1.2 CNN 特征提取
CNN 结构主要包含卷积层、池化层和全连接层[13]。卷积层通过卷积核对输入信号进行卷积操作,并进行故障特征提取,池化层对卷积层提取的数据进行降维,全连接层负责将卷积层和池化层处理后的数据进一步拟合。
卷积层中同一层卷积核的权值相同,即

池化层采用最大值池化函数,获得池化区域的最大值:
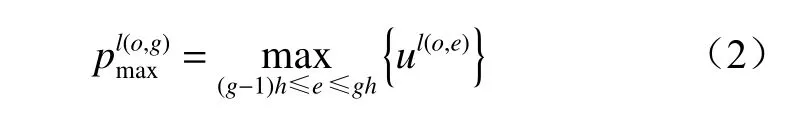
式中:h为卷积核宽度;ul(o,e)为第l层中第o个特征张量的第e个神经元,l=1,2,···,g,g为层的总数,o=1,2,…,q,q为特征张量总个数。
全连接层中采用Softmax 函数将全连接层获取的特征数据映射到(0,1),并将映射结果输出,实现故障分类。
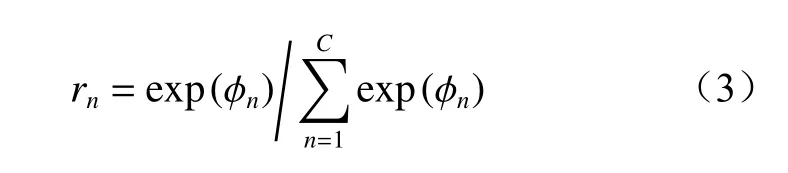
式中:rn为输出结果为第n类的概率;φn为全连接层第n类的输出值;C为数据集类别个数。
1.3 BiLSTM 网络
故障信息属于时序信号,而BiLSTM 网络适用于提取时序信号的时间关联性。关注故障信息的时间关联性可进一步有效提高深度网络的特征挖掘能力。BiLSTM 网络由前向LSTM 层和反向LSTM层组成,如图2 所示,其中Wu为输入神经元数据,ku为输出神经元结果,u为神经元个数。因此,可在前向和后向2 个方向上学习故障特征的时间信息,且2 个方向均具有独立的隐藏层。
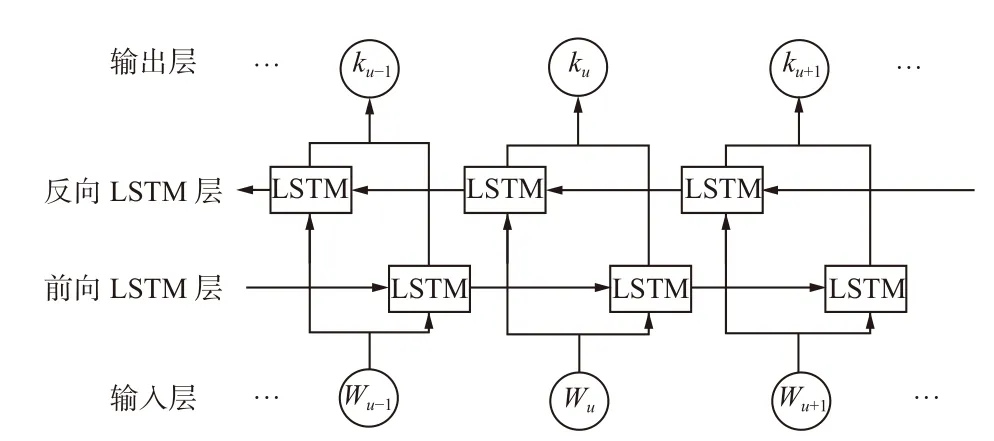
图2 BiLSTM 网络结构Fig.2 Structure of BiLSTM network
2 滚动轴承故障诊断模型
2.1 特征提取
当滚动轴承损伤时,受振动耦合影响,故障特征呈现多尺度性[14]。由于MSCNN 网络能自适应提取信号中的多尺度特征,从而可获得一些重要的故障特征信息[15];而BiLSTM 网络能从前后2 个方向学习振动信号的时间信息,使特征信息更加全面。本文结合MSCNN 网络和BiLSTM 网络的优势构建MSCNN-BiLSTM 网络,网络结构如图3 所示。
从图3 可看出,MSCNN 网络由通道1、通道2 和汇聚层组成,MSCNN 网络通道1 选用较大卷积核,以给予卷积网络足够大的感受野,进而捕获振动信号的低频特征;MSCNN 网络通道2 采用较小卷积核,以保持卷积网络提取局部特征的优势;汇聚层对通道1 和通道2 的输出结果进行特征融合,且只做张量乘积运算,因此没有设定超参数。对MSCNNBiLSTM 网络参数进行反复实验和调整,结果见表1。MSCNN 网络采用一维卷积运算,通道1 和通道2 中的卷积核尺寸分别为15 和5。为将每层卷积输出值大小保持在一定范围内,对每个卷积层输出的结果进行批量归一化处理。此外,分别在卷积层2 和卷积层6 后面接入最大池化层,采用最大池化操作降低数据维度,并将最大池化层的核(池化窗口)尺寸和步长设置为2;为保证每个通道输出尺寸为(128,4),分别在卷积层4 和卷积层8 后面引入自适应最大池化层。BiLSTM 网络包含1 层结构,神经元个数为256。
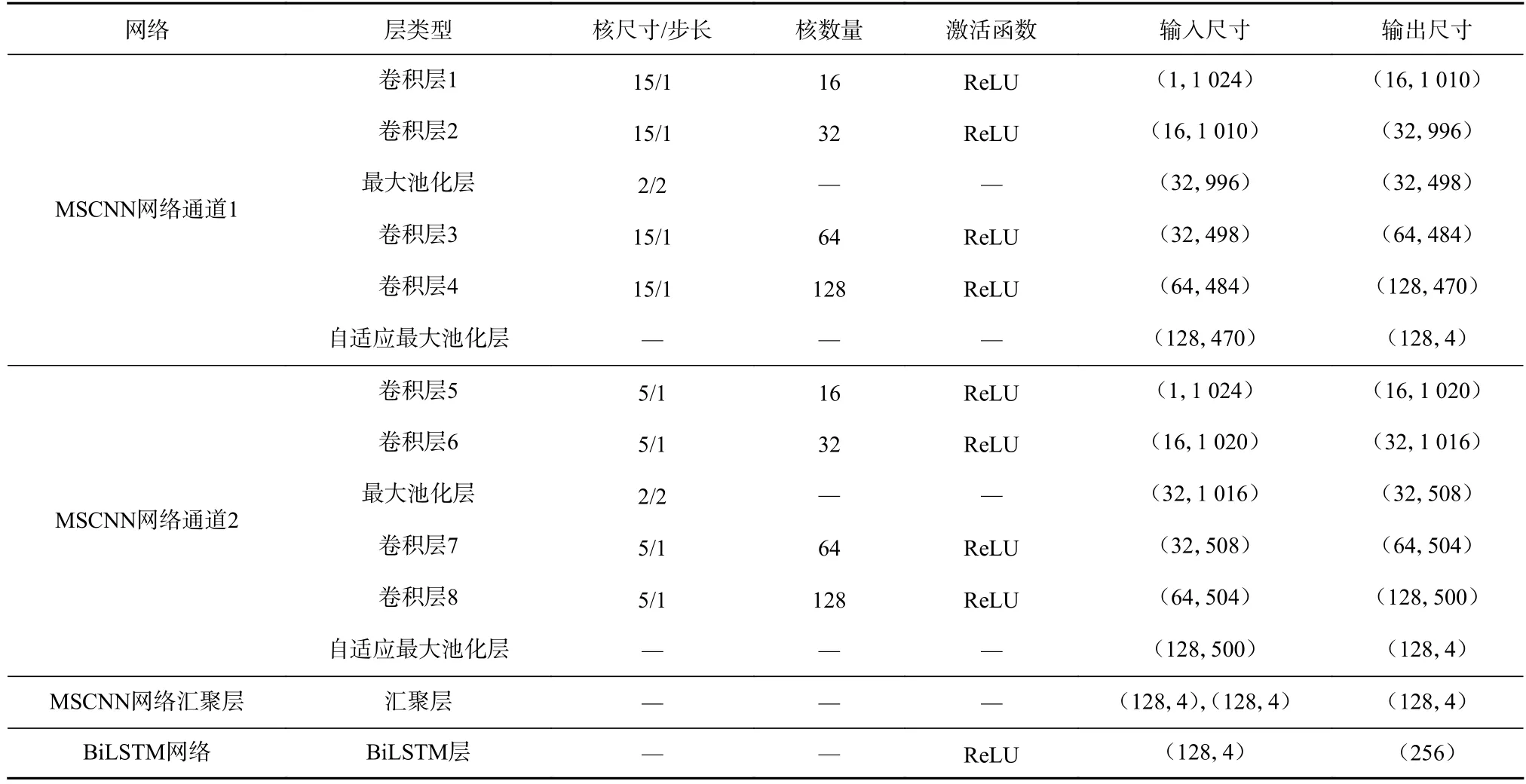
表1 MSCNN-BiLSTM 网络参数Table 1 Parameters of MSCNN-BiLSTM network
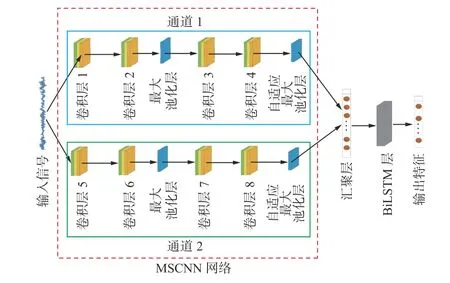
图3 MSCNN-BiLSTM 网络Fig.3 MSCNN-BilSTM network
2.2 DATLN 诊断模型
基于DATLN 的滚动轴承故障诊断模型如图4所示,DATLN 由状态识别和域自适应2 个模块组成。状态识别模块包括MSCNN-BiLSTM 特征提取网络、瓶颈层和标签分类器,其中瓶颈层和标签分类器中均采用一层全连接网络,瓶颈层神经元个数为256,标签分类器的神经元个数为样本标签类别数。域自适应模块由域分类器和AJD 度量组成,其中域分类器采用3 层全连接网络,前2 层引入Relu 激活函数,最后1 层采用Sigmoid 函数对样本进行域分类。域分类器参数见表2。

表2 域分类器参数Table 2 Parameters of domain classifier
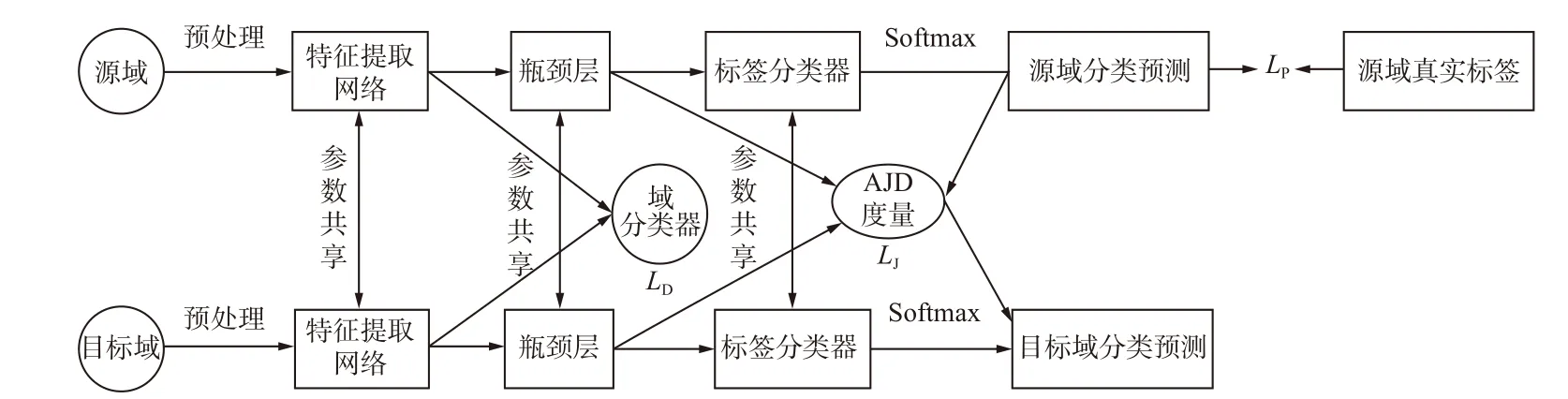
图4 滚动轴承故障诊断模型Fig.4 Model of rolling bearing fault diagnosis
DATLN 模型诊断流程如下:
(1)通过不重叠采样对源域和目标域的故障数据进行分割,获取固定长度的样本,利用归一化技术使样本值保持在一定范围内,完成对原始振动信号的预处理。
(2)在状态识别模块中,利用源域样本进行有标签监督训练,通过标签分类器识别滚动轴承的状态;在域自适应模块中,域分类器结合AJD 度量,动态减小源域与目标域的边缘分布和条件分布差异,进而实现源域与目标域样本自适应匹配的目的。
2.3 目标优化函数
DATLN 诊断模型的损失函数L包含标签分类损失LP、域分类损失LD及自适应联合分布损失LJ3 个部分。
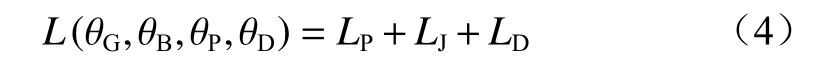
式中:θG为特征提取网络参数;θB为瓶颈层参数;θP为标签分类器参数;θD为域分类器参数。
2.3.1 标签分类器损失
标签分类器通过有监督方式对状态识别模块进行训练,识别源域样本的故障类别。采用交叉熵损失函数衡量标签分类损失。
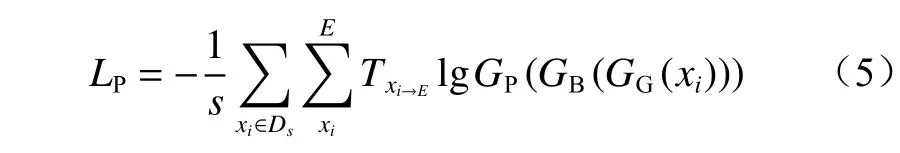
式中:E为源域样本xi所属类别;T为每类样本的概率;GP为标签分类器;GB为瓶颈层;GG为特征提取网络。
2.3.2 域分类损失
域分类器用于区分样本的所属域,通过最大化域分类损失来约束MSCNN-BiLSTM 网络,进而提取更多与目标域相似的特征。设源域样本的域标签为0,目标域样本的域标签为1,此时,域分类属二分类,因此域分类损失采用二元交叉熵损失函数衡量。
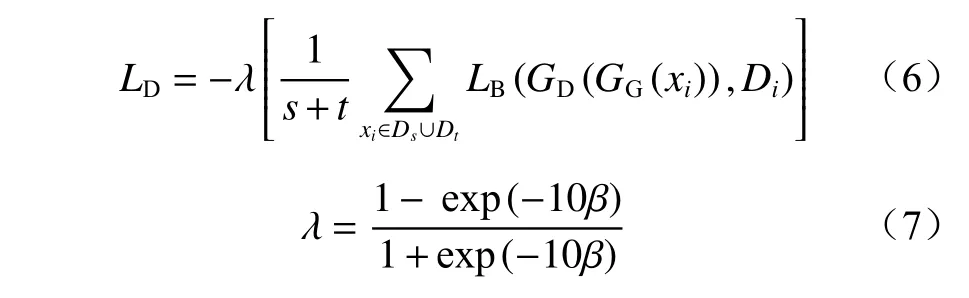
式中:λ为权衡参数;LB为二元交叉熵损失函数;GD是域分类器;Di为输入样本的域标签;β为当前迭代次数与总迭代次数的比。
2.3.3 自适应联合分布损失
迁移成分分析(Transfer Component Analysis,TCA)[16]主要用于减小源域、目标域之间的边缘分布差异。TCA 通常只关注全局分布对齐,而忽略了源域和目标域同一类别子域间的条件分布差异,从而导致迁移效果不理想。为此,本文采用联合域适配(Joint Domain Adaptation,JDA)算法[17],引入自适应联合分布(Adaptive Joint Distribution,AJD)损失,通过衡量域间联合分布距离,以减小源域和目标域的边缘分布与条件分布差异。由于目标域没有样本标签,使用标签分类器预测结果作为伪标签,参与条件分布差异计算过程。假设进行源域、目标域特征对齐时边缘分布(P)和条件分布(Q)的权值相同,可将域间联合分布距离定义为
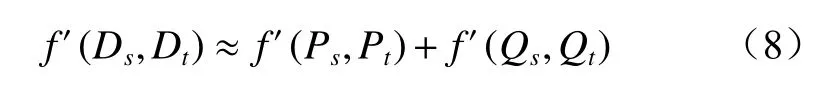
式中:f′为映射函数;Ps,Pt分别为源域、目标域的边缘分布;Qs,Qt分别为源域、目标域的条件分布。
在现实情况中边缘分布和条件分布的重要性是随着迭代训练动态变化的,所以只有动态地计算边缘分布和条件分布在迁移过程中的各自占比,才能有效地提升迁移诊断精度。引入衡量因子α,诊断模型每次迭代训练完成后,重新评估边缘分布和条件分布的重要性。
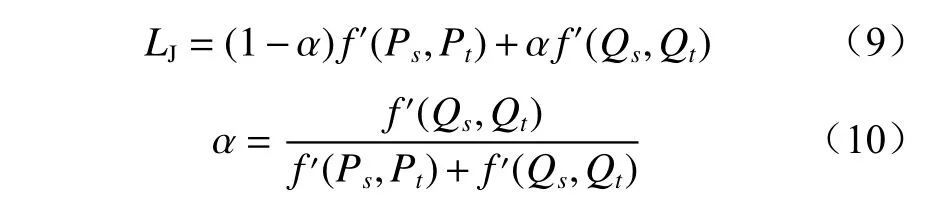
边缘分布与条件分布均采用MMD 公式计算,即
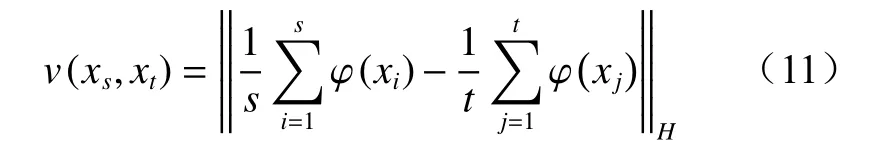
式中:v为源域与目标域分布的距离;φ为高斯核函数;H为希尔伯特空间。
3 实验与分析
为验证MSCNN-BiLSTM 网络抗噪性能及域自适应模块的迁移能力,进行抗噪实验和迁移实验。在无域自适应模块下,对MSCNN-BiLSTM 网络进行抗噪性能测试,并在凯斯西储大学(CWRU)轴承数据集上与LeNet-5,MSCNN 和BiLSTM 进行对比实验。在Spectra Quest 机械故障实验台的实测数据集上,采用Baseline,TCA 和域对抗神经网络(Domain Adversarial Neural Network,DANN)[11]3 种方法与本文DA+AJD 域自适应方法进行对比,其中Baseline 方法只采用状态识别模块,即运用源域训练好的模型对无标签目标域样本直接进行诊断。
3.1 抗噪实验
采用CWRU 轴承数据集在4 种不同强度的噪声环境中做抗噪实验。实验装置如图5所示。测试台主要由1.5 kW 电动机、功率测试计和控制设备等组成。实验轴承型号为SKF6205,在0,0.75,1.5,2.25 kW 4 种不同负载下采集实验轴承数据,采样频率为12 kHz。每种负载下均包含正常状态及内圈、外圈、滚动体3 种故障损伤状态,损伤直径分别为 0.177 8,0.355 6,0.533 4 mm,共计10 种状态。为方便表述,以0 负载下采集的数据集为例,见表3。
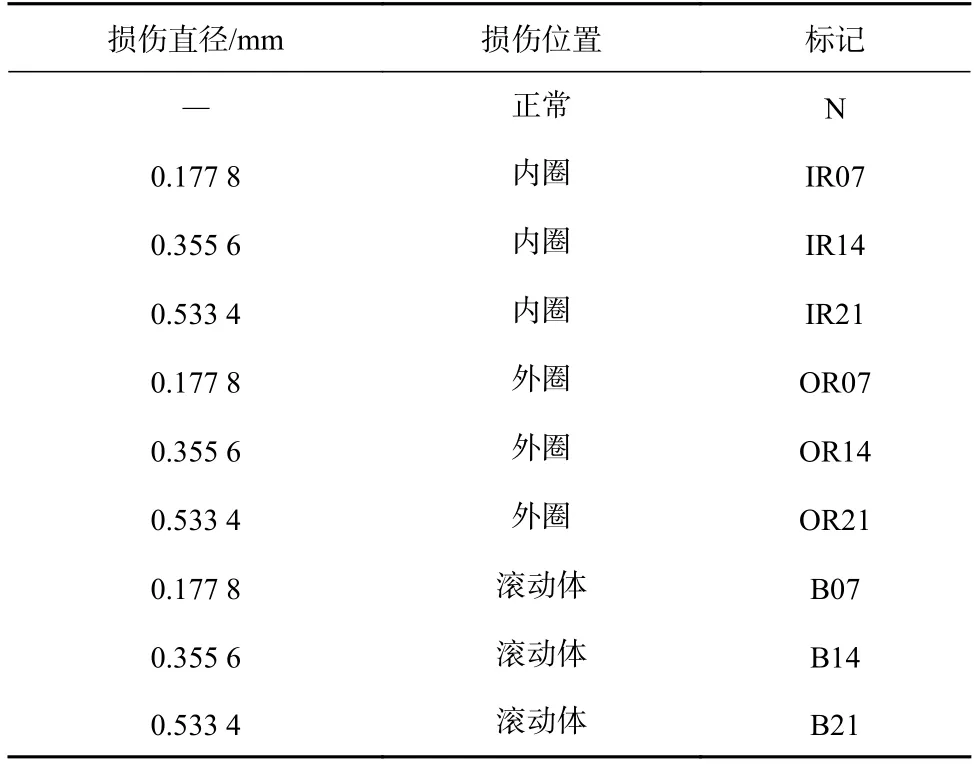
表3 0 负载下数据集Table 3 Date set under 0 load

图5 CWRU 轴承数据采集系统Fig.5 CWRU bearing data acquisition system
3.1.1 数据预处理
为避免样本之间有重叠区域,通过不重叠采样对原始信号进行分割,如图6 所示。每个样本包含1 024 个点,产生的样本数量见表4。
表4 CWRU 样本集Table 4 CWRU sample set
图6 不重叠采样Fig.6 Non-overlapping sampling
采样完成后,通过归一化公式将每个样本的数据映射到同一尺度。

式中:zη为 归一化后的样本数据;zφ为输入的样本数据;μ为样本数据的平均值;σ为样本数据的标准差。
在实际工程环境中,传感器接收的信号通常无法避免噪声干扰,故在原始故障数据中添加不同信噪比(Signalto Noise Ratio,SNR)的高斯白噪声,以测试MSCNN-BiLSTM 网络在噪声环境下的抗噪性能,信噪比公式为
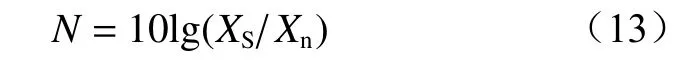
式中:XS为原始信号;Xn为噪声信号。
加入不同强度噪声后,为直接观察振动信号的变化,从滚动轴承的10 种状态里随机选取正常状态与内圈故障(IR07)状态进行展示,如图7、图8所示。与原始信号相比,添加噪声后,其周期性冲击分量明显减弱,噪声强度随着信噪比的降低而增强,深度网络对轴承故障的辨识将更加困难。在加入不同强度噪声后,其他状态下振动信号的变化趋势与正常状态和内圈故障(IR07)状态下的变化趋势一致。
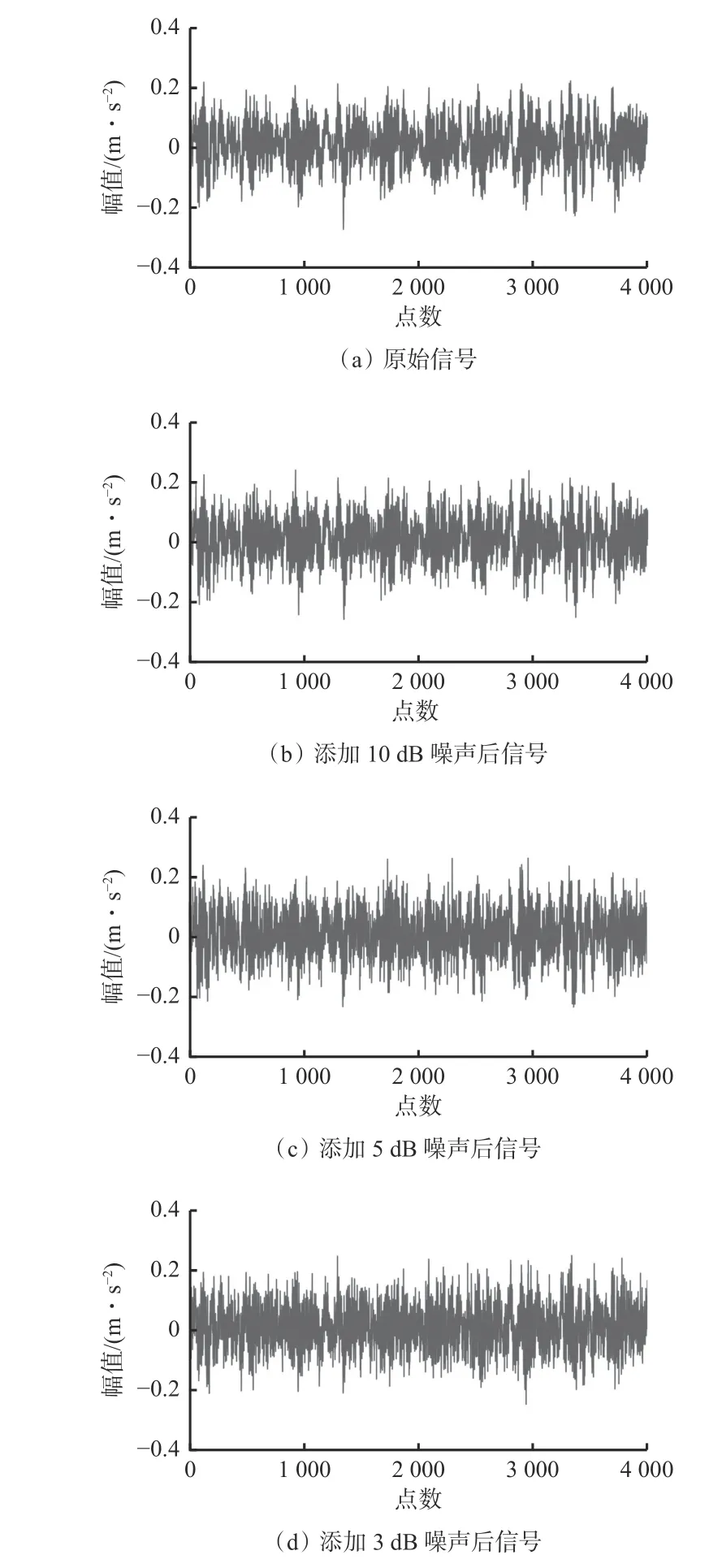
图7 正常状态下振动信号变化Fig.7 Vibration signal changes under the normal state
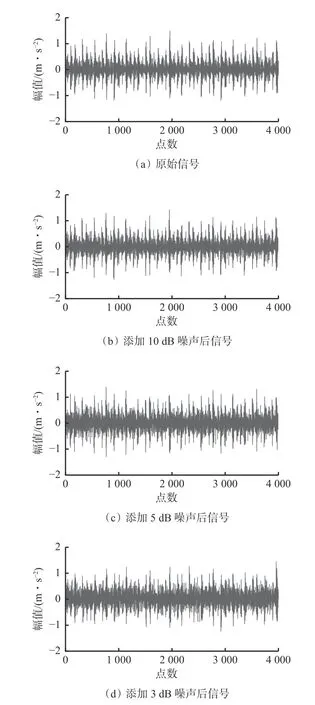
图8 内圈故障(IR07)状态下振动信号变化Fig.8 Vibration signal changes in the inner fault(IR07)state
3.1.2 实验结果及分析
为验证MSCNN-BiLSTM 网络的优势,将其分别与LeNet-5,MSCNN 和BiLSTM 进行比较。实验使用Radam 优化器,学习率为0.01,迭代次数为100,批量为64,训练集与测试集比例是4∶1。为测试本文特征提取网络在单负载场景下对轴承故障特征的提取能力,分别在4 种不同负载下实验。为消除偶然误差,采用5 次实验结果的平均值评估网络性能,如图9-图12 所示。
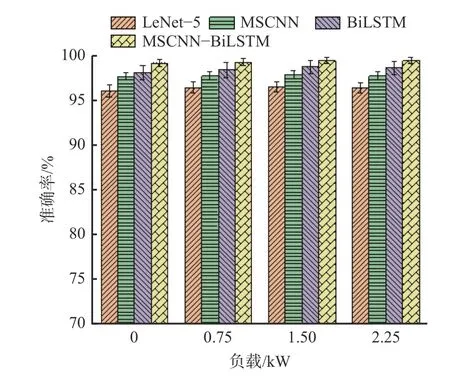
图9 无噪声环境下对比实验结果Fig.9 Comparison of experimental results in noiseless environment
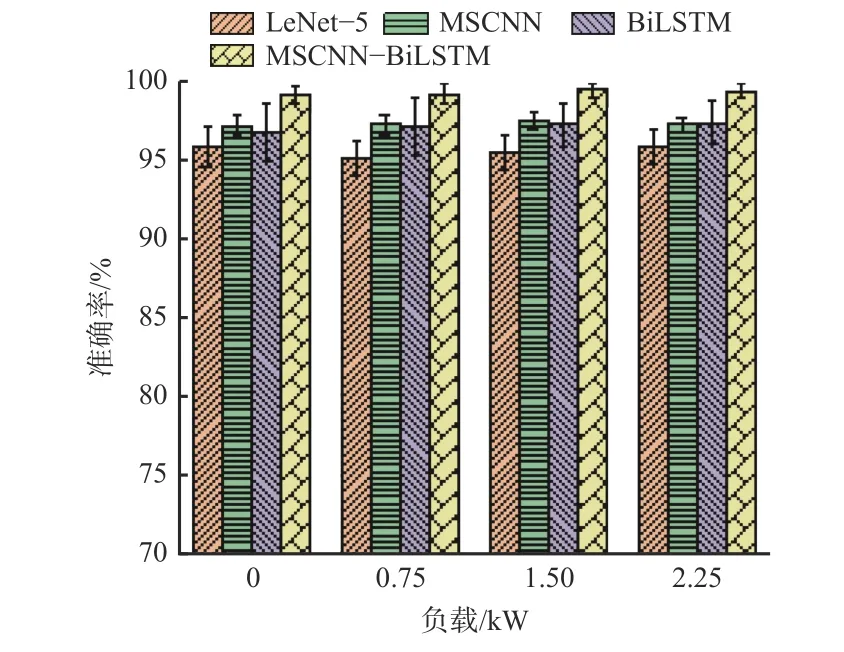
图10 10 dB 噪声环境下对比实验结果Fig.10 Comparison of experimental results in 10 dB environment

图11 5 dB 噪声环境下对比实验结果Fig.11 Comparison of experimental results in 5 dB environment
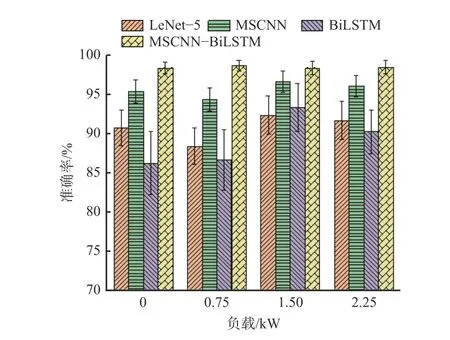
图12 3 dB 噪声环境下对比实验结果Fig.12 Comparison of experimental results in 3 dB environment
从图9 可看出,在无噪声环境下,MSCNN-BiLSTM网络的识别准确率均达到99%以上,在4 种网络中准确率最高,可见其具有较好的特征提取能力。从图10-图12 可看出,4 种网络的识别准确率随着噪声强度的增强而降低。为综合比较每种网络的性能,在3,5,10 dB 噪声下,计算每种网络在4 种负载下识别准确率的平均值,结果见表5。
由表5 可知,在3,5,10 dB 噪声环境下,MSCNNBiLSTM 网络的平均识别准确率分别为98.43%,99.00%和99.16%,比LeNet-5,MSCNN 和BiLSTM的平均识别准确率均高,实验结果证明了MSCNNBiLSTM 网络具有较好的抗噪声干扰性能。
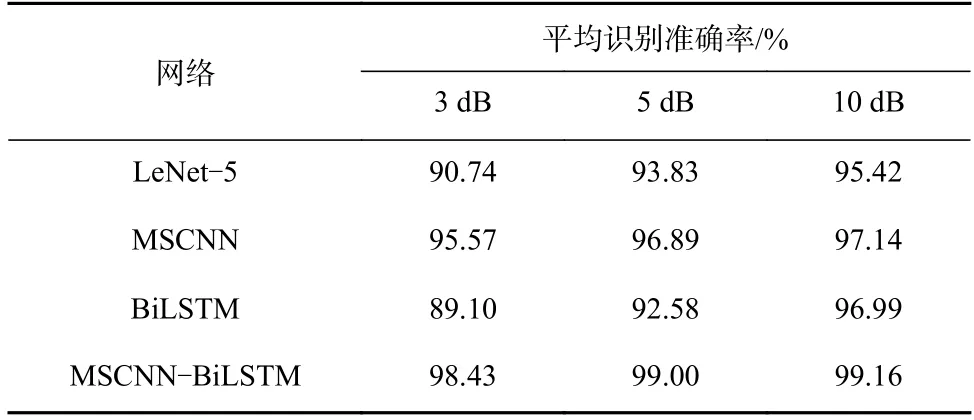
表5 不同网络的平均识别准确率Table 5 Average accuracy of different network
为了观察迭代过程中网络的故障诊断性能变化,随机选取0 负载下的数据集,在无噪声和3 dB 噪声2 种环境下进行迭代,测试集识别结果分别如图13和图14 所示。可看出MSCNN-BiLSTM 网络在无噪声环境和3 dB 噪声环境下,均最先达到收敛且波动较小。
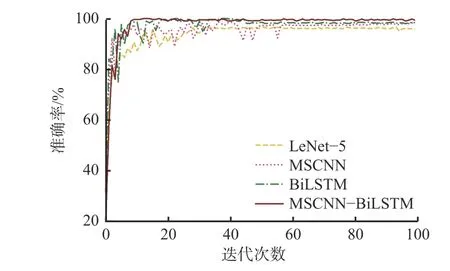
图13 无噪声环境下0 负载测试集识别结果Fig.13 Identification results of 0 load test set in noise-free environment
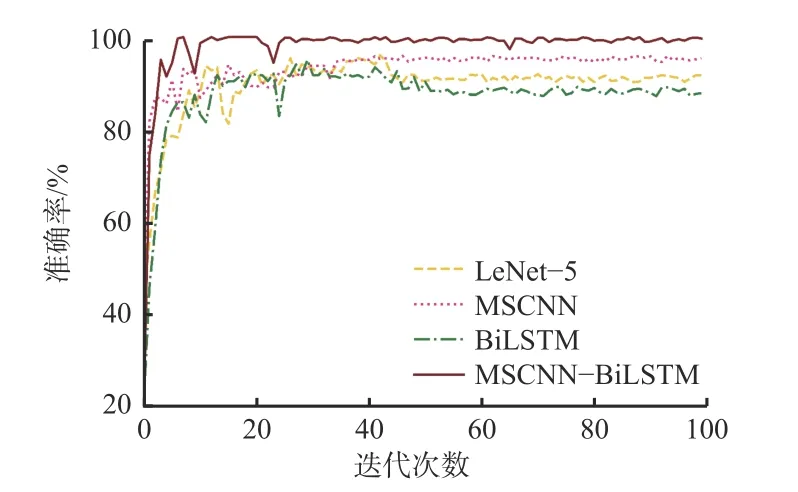
图14 3 dB 噪声环境下0 负载测试集识别结果Fig.14 Identification results of 0 load test set in 3 dB environment
3.2 迁移实验
为验证域自适应模块的迁移能力,采用机械故障模拟台收集轴承故障数据,并进行对比实验。实验台主要由电动机转速控制器、旋转轴和传感器等组成,其结构如图15 所示。实验轴承的型号为ER12KCL,在轴承转速为1 400,1 800,2 200 r/min 下收集实验数据。轴承的状态包括正常、内圈故障、外圈故障和滚动体故障4 种。所有实验轴承的直径均为19.05 mm。通过电动机驱动端轴承座上的加速度传感器,采集实验数据,采样频率为12.8 kHz,采集时间为10 s。

图15 机械故障模拟实验台Fig.15 Machinery fault simulator
3.2.1 数据预处理
通过不重叠采样对原始振动信号进行分割,生成的每个样本包含1 024 个点,正常、内圈故障、外圈故障、滚动体故障状态各125 个样本。采样完成后,对每个样本进行归一化处理。
3.2.2 迁移实验结果及分析
由于3 dB 噪声环境对滚动轴承故障诊断干扰最为严重,故选取3 dB 噪声环境做迁移实验。将1 400,1 800,2 200 r/min 3 种转速下的数据集表示为A,B,C,分别用A to B,A to C,B to A,B to C,C to A,C to B 表示3 种数据集之间的迁移。例如A to B 表示源域是转速1 400 r/min 下得到的数据集,目标域是转速1 800 r/min 下得到的数据集。选取80%的带标签源域样本和80%的无标签目标域样本作为训练集,剩余20%的无标签目标域样本作为测试集。实验使用Radam 优化器,学习率为0.01,批量为64,每组实验迭代次数为100,采用5 次实验结果的平均值评估方法性能。迁移实验结果如图16 所示。
从图16 可看出,在6 组不同迁移任务中,DA+AJD方法的识别准确率均高于其他3 种方法。
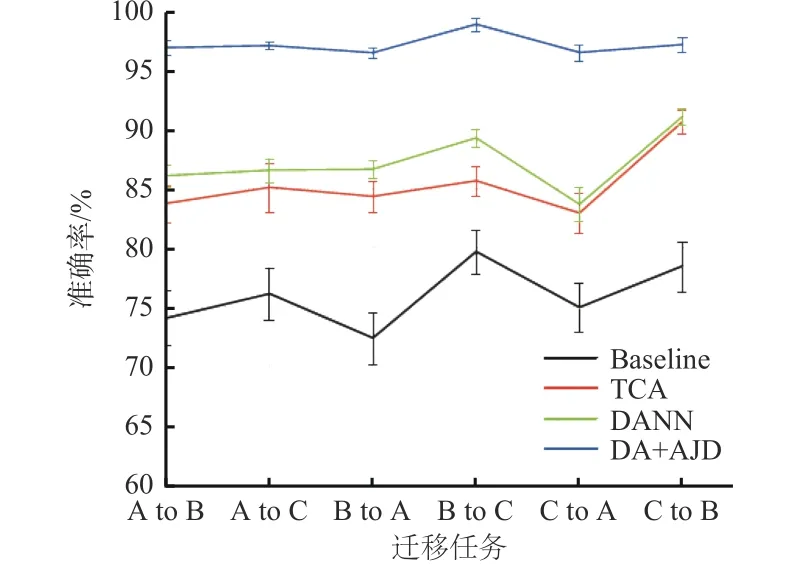
图16 3 dB 噪声环境下迁移结果Fig.16 Transfer results of 3 dB environment
为综合比较4 种方法的迁移能力,取每种方法在6 组不同迁移任务下测试结果的平均值进行对比,结果见表6。

表6 每种方法的平均识别准确率Table 6 Average results of different methods
由表6 可知,DA+AJD 方法的平均识别准确率比Baseline,TCA 和DANN 方法的平均识别准确率分别高21.46%,11.98%,10.17%。
为更加直观地对比每种方法的识别结果,随机选取迁移任务C to B,通过混淆矩阵将目标域B 测试集结果可视化,结果如图17 所示。可看出DA+AJD方法仅有1 个样本被错误识别,而Baseline,TCA 和DANN 分别有23,14 和12 个样本被错误识别,表明基于域适应的DA+AJD 方法具备更好的故障迁移诊断性能。
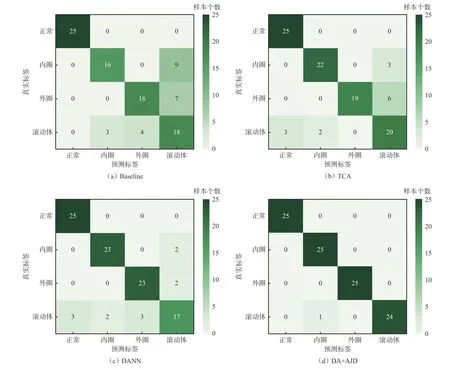
图17 迁移任务C to B 的测试集混淆矩阵Fig.17 Test dataset confusion matrix of transfer task C to B
为进一步验证DA+AJD 方法的优势,利用t-SNE算法将4 种方法处理后的源域与目标域特征样本进行可视化,其效果如图18 所示。可看出在Baseline方法下,较多目标域的内圈故障和外圈故障特征样本被错误对齐到源域的滚动体故障特征样本区域;TCA 方法虽在全局域对齐方面有优势,但未能有效减小条件分布差异,导致仍有一些目标域的内圈故障、外圈故障和滚动体故障特征样本被错误对齐到源域的其他故障特征样本区域;DANN 方法也未能有效减少源域与目标域分布差异;DA+AJD 方法只有少量目标域的滚动体故障和外圈故障特征样本被错误对齐到源域的内圈故障特征样本区域,说明DA+AJD 方法有效地减少了源域与目标域的边缘分布和条件分布差异,达到了更好的特征样本对齐效果。
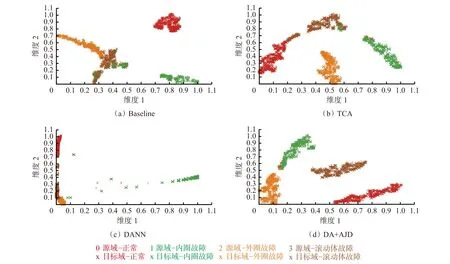
图18 迁移任务C to B 的t-SNE 特征可视化Fig.18 T-SNE characteristic visualization of transfer task C to B
4 结论
为提高噪声背景下深度网络提取轴承信号特征的能力,结合MSCNN 网络与BiLSTM 网络的优势构建MSCNN-BiLSTM 网络作为特征提取网络;为减小源域与目标域数据分布差异,设计了DA 训练结合AJD 度量机制。
(1)抗噪实验表明:在无噪声环境下,MSCNNBiLSTM 网络的识别准确率均达到99%以上,说明其具有较好的特征提取能力;MSCNN-BiLSTM,LeNet-5,MSCNN 和BiLSTM 的识别准确率随着噪声强度的增强而降低;在3,5,10 dB 噪声环境下,MSCNNBiLSTM 网络的平均识别准确率比LeNet-5,MSCNN和BiLSTM 网络的平均识别准确率高,说明MSCNNBiLSTM 网络具有较好的抗噪声干扰性能;MSCNNBiLSTM 网络在无噪声环境和3 dB噪声环境下,均最先达到收敛且波动较小。
(2)迁移实验表明:在无标签目标域数据集上,DA+AJD 方法的平均识别准确率为97.36%,均高于Baseline,TCA,DANN 的识别准确率;在测试集混淆矩阵上,DA+AJD 方法仅有1 个样本被错误识别,表明基于域适应的DA+AJD 方法具备更好的故障迁移诊断性能;利用t-SNE 算法对处理后的源域与目标域特征样本进行可视化,DA+AJD 方法只有少量目标域的滚动体故障和外圈故障特征样本被错误对齐到源域的内圈故障特征样本区域,说明DA+AJD 方法有效地减少了源域与目标域的边缘分布和条件分布差异,达到了更好的特征样本对齐效果。
(3)实验中已对滚动轴承振动数据在不同工况下进行迁移实验,但未对不同类型轴承振动数据进行可迁移性分析。下一步将在可迁移性分析的基础上,利用实验室获得的数据对实际工程设备进行迁移诊断。
