智能化煤矿数据仓库建模方法
2022-05-13王霖方乾张晓霞苏上海施展王雅琨
王霖,方乾,张晓霞,苏上海,施展,王雅琨
(1.煤炭科学研究总院有限公司,北京 100013;2.煤炭资源高效开采与洁净利用国家重点实验室,北京 100013)
0 引言
随着大数据、人工智能、物联网等技术的高速发展,煤矿智能化建设进程得到极大推动,煤矿生产模式发生极大转变[1]。在该过程中,煤炭行业数据量呈现爆炸式增长,而传统的煤矿数据处理方式中,煤矿主数据、实时监测监控类数据、管理业务类数据及决策分析数据各自离散存储,数据集成、业务应用及数据分析难度大,无法有效满足煤矿企业在自动化、信息化业务层面的应用需求,更无法满足智慧化决策分析需求[2],具体体现在以下3 个方面。
(1)“数据孤岛”现象。当前数据共享和交换大多仍采用人工方式,缺乏数据处理系统之间的业务协同,时效性差,且数据仍以分散和弱关联方式存在,系统效率低,无法满足智慧矿山建设需求[3]。
(2)数据关联性弱。井下局部系统虽然实现了运行数据的采集、分析、展示功能,但没有进行相互关联,难以挖掘开采过程的动态演进规律,无法实现大数据应用[4]。
(3)缺乏数据管理体系,数据质量差。煤矿内部系统众多,各类数据间没有统一标准[5],缺乏数据管控体系等,导致煤矿大数据质量较差[6]。
上述问题本质上是由煤矿缺乏统一数据管理造成的。如何将煤矿大数据有效组织起来,打破底层子系统数据与上层智能化应用之间的屏障,成为亟待解决的问题[7]。对此,许多学者提出了建设智能化煤矿数据仓库的思路。王国法等[4]提出智能化煤矿大数据构建涵盖全矿安全监管、生产、运销、综合服务等业务的大数据仓库,挖掘数据价值,使各类信息通过各种手段及时推送到矿端各级决策层中去辅助决策,以解决数据滞后、多种类型数据难以统一等问题。杜毅博等[8]提出建设智能化煤矿大数据仓库和数据服务化,根据业务对煤矿大数据集进行结构划分,形成煤矿数据主题域。吴群英等[9]提出利用数据仓库可实现煤矿大数据的数据挖掘。
上述研究均指出了智能化煤矿建设数据仓库的重要性,但没有详细阐述具体建设方法。鉴此,本文针对智能化煤矿数据仓库建模方法展开研究,以综采工作面为例展示了建模过程及应用效果。
1 数据仓库及其建模
1.1 数据仓库
数据仓库可定义为支持管理决策过程的、面向主题的、集成的、随时间变化的持久的数据集合[10],其核心是对数据进行组织、划分,构建面向分析的集成化数据环境,提供统一的数据标准。数据仓库的核心过程是将累积的大量数据资料进行汇聚与融合,建立规范化统一的数据环境,支撑各种类型数据分析与展示。其运转流程如图1 所示。

图1 数据仓库运转流程Fig.1 Data warehouse operation process
业务系统在满足业务功能需求的同时产生大量业务过程数据,将各类业务过程数据进行统一汇集,形成数据仓库中的原始数据。多数据源的集合解决了“数据孤岛”难题。
ETL(Extraction-Transformation-Load,抽取、转换、加载)是数据仓库的数据加工技术。数据仓库的原始数据标准不统一、数据质量差,可通过ETL 进行数据内容清洗、数据结构统一、数据关联融合,形成数据仓库模型[11]。
1.2 数据仓库建模
数据仓库建设首先要选择合适的分层架构对数据进行组织划分。按照层级划分数据的方式具有以下优点:①明确数据定位。每个数据分层都有明确的作用域和职责,使用模型时更容易理解数据的作用。② 避免重复建设。规范的数据分层为金字塔结构,数据自底向上逐步汇聚,避免“烟囱式”建设方式的低效性。③统一数据口径。通过分层可实现计算逻辑的高内聚、低耦合,相同类型数据口径在特定层级内实现,统一数据出口,避免多次计算造成口径差异。
目前常用的数据仓库建模方法包括范式建模、维度建模、DataVault 建模及Anchor 建模[12-13]。范式建模用实体和关系对整体业务架构进行抽象,适用于较成熟的业务场景,对建模能力要求较高。维度建模从分析主题的角度出发,通过指标刻画分析主题并进行维度扩展,对原始数据做大量预处理并转换为星型结构,迭代快速,适用于灵活多变的业务场景。DataVault 建模和Anchor 建模在范式建模基础上扩展了对数据变更场景的支持,适用于对数据强约束的场景。
当前煤矿智能化建设仍处于初级阶段。为满足未来高速发展、快速迭代的建设需求,本文基于维度建模思想,针对煤矿数据特点,研究智能化煤矿数据仓库建模方法。维度建模流程主要包括主题选择、粒度选择、维度选择、事实选择、模型选择[14]。结合对分析需求调研与数据业务过程的理解,明确模型所属主题是维度建模的第1 步。确定主题后需要进一步确定模型的粒度,原子粒度能够表达最细节的业务明细,但不适合直接用于分析,需根据应用场景进行粒度选择。维度用于分析所需的角度,模型添加更多的维度能扩展更加丰富的分析方式。事实即统计指标,事实选择需要确定将哪些事实放到事实表中,事实必须与粒度吻合,因此在选择事实时可能会对粒度和维度进行调整。维度模型包括星型模型、雪花模型、星座模型。其中最常用的是星型模型,其数据结构是1 张事实表为中心,维度表分布在事实表周围,从不同的维度描述数据情况[15],形成一个有别于实体关系图的数据结构,如图2 所示。星型模型适用于以分析查询为主的应用场景。雪花模型、星座模型适用于维度之间关联复杂的场景。

图2 星型维度模型数据结构Fig.2 Data structure of star dimension model
2 智能化煤矿数据仓库建模
煤矿数据主要包括由综合自动化、井下监测、生产管理、安全管理、地测、经营管理等业务系统采集及人工录入台账的数据。智能化煤矿数据仓库建模时需要综合考虑煤矿数据的领域特点与煤矿智能化应用分析需要,先设计整体架构,再研究建模方法。
2.1 数据仓库整体架构
为了保证煤矿数据的有序流转,满足智能化应用对数据的需求,智能化煤矿数据仓库整体采用分层架构,如图3 所示。

图3 智能化煤矿数据仓库分层架构Fig.3 Layered architecture of intelligent coal mine data warehouse
原始数据层存放从煤矿各业务系统汇集的原始数据。该层数据模型保持与源业务系统结构和内容上的一致性,记录数据变化,为上层数据计算提供充分的扩展性。
明细数据层存放经过标准化处理的结构、类型、命名统一的规范化数据。在进行标准化处理时需使用业务字典、配置说明及点表映射等信息对原始数据进行转换,数据质量方面需要解决数据内容中的异常值、缺失值、无效值等问题。
基础指标层是整个分层架构中最重要的一层,在明细数据层提供高质量标准数据的基础上,通过实现具体机理逻辑、统计逻辑及算法逻辑,构建基础指标体系。该层数据模型主要沉淀基础指标结果,保证指标口径的一致性。
服务数据层面向煤矿智能化分析应用提供定制化的数据模型,在基础指标层基础上计算衍生指标,实现跨主题指标关联拼接,提供多维度、多指标的综合型分析模型。
公共维度层主要由维度数据模型构成,为各个层级数据模型计算提供统一的维度信息,同时为煤矿智能化分析应用提供用于维度扩展的属性信息。
2.2 数据仓库建模过程
煤矿子系统众多,各子系统包含的数据具有很高的相似性,如各类设备的控制信号、运行状态及监控数据,不同区域环境感知数据,不同业务系统人工操作、手工填报数据等。
综采工作面作为煤矿生产的关键环节,生产过程复杂,设备数量庞大,动作繁多[16],其数据具有煤矿生产数据的典型特点。限于篇幅,本文以综采工作面为例对智能化煤矿数据仓库建模方法进行论述,展示实际数据仓库建模过程。
2.2.1 业务数据分析
综采工作面是指综合机械化采煤工作面,其核心设备主要包括采煤机、液压支架、运输“三机”(刮板输送机、转载机、带式输送机)、泵站等,按照数据来源进行数据分类整理,结果见表1。

表1 综采工作面核心数据分类Table 1 Classification of kernel data of fully mechanized working face
按照数据来源进行组织会忽略同类数据间的关联性,造成数据和业务概念间的割裂,因此本文采用业务过程、业务事实、数据域的3 级结构重新对数据进行组织划分。业务过程是指煤矿业务的基本活动事件;业务事实是指具体某一业务事件下的度量,是业务定义中不可拆分的指标,具有明确的业务含义;数据域是对同类型业务过程的抽象。以综采工作面开采过程为例,其数据组织如图4 所示。

图4 综采工作面数据3 级组织Fig.4 Three-level data structure of fully mechanized working face
综采工作面生产流程包括破煤、装煤、运煤、支护、采空区处理、回采巷道运输等,将其中与生产相关的过程归属到生产域,在业务过程内对各自的业务事实(如破煤过程中的采煤机位置、方向、倾角、滚筒高度等)进行管理。按照业务过程划分数据能够指导数据模型的构建。
2.2.2 应用需求分析
通过实地调研国能宁夏煤业有限责任公司、国能神东煤炭集团有限责任公司等大型煤炭生产企业,对综采工作面典型的智能化应用分析需求进行了梳理,将需求划分为设备、生产、安全、自动化4 个分析主题,如图5 所示。

图5 综采工作面智能化应用分析主题Fig.5 Intelligent application analysis subjects of fully mechanized working face
设备主题主要包括功效分析、停机分析、状态分析、能耗分析;生产主题主要包括工作面推进分析、液压支架支护分析、割煤过程分析;安全主题主要包括液压支架压力分析、端头端尾推进分析、液压支架移架阶段分析;自动化主题主要包括循环割煤自动化分析、泵站自动化分析、跟机自动化分析。
2.2.3 分层架构设计
基于对业务数据与应用需求的分析,按照分层架构对综采工作面数据仓库进行设计,如图6 所示。
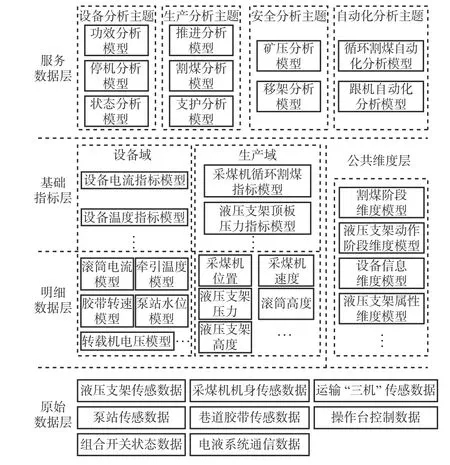
图6 综采工作面数据仓库分层架构Fig.6 Layered architecture of data warehouse of fully mechanized working face
原始数据层按照数据采集单元划分为液压支架传感数据、采煤机机身传感数据、运输“三机”传感数据等。该层数据模型记录所有类型的历史采集数据,最大程度地保留数据原始特征。
明细数据层和基础指标层数据模型按照数据域进行组织,划分为生产域和设备域。生产域包括割煤、装煤、运维、支护等生产过程的明细事实及基础指标;设备域包括与设备运行状态和参数相关的基础指标。明细数据层数据模型按照基础事实信息构建,主要包括滚筒电流模型、牵引温度模型、胶带转速模型等。在此基础上,基础指标层按照指标计算逻辑构建设备电流指标模型、设备温度指标模型、采煤机循环割煤指标模型等。
服务数据层按分析主题进行组织,对主题下相关指标进行整合,构建主题分析模型,如设备分析主题下的功效分析模型、停机分析模型等,安全分析主题下的矿压分析模型、移架分析模型等。
公共维度层包括基础属性模型,如设备信息维度模型、液压支架属性维度模型,还包括基于机理模型阶段划分模型,如割煤阶段维度模型、液压支架动作阶段维度模型等。
2.3 数据模型构建方法
煤矿原始数据多为时序类型数据,包含名称、时间、数据值等信息(不同数据类型通过名称区分)。该类型数据缺少关联性,难以直接用于分析决策。将原始数据转换为数据仓库维度模型需要经过维度对齐、维度关联、维度化指标聚合等过程。通过多维度的联系将不同类型数据进行关联,解决数据间关联性的问题。
2.3.1 维度对齐
由于不同设备、监控系统采集数据时的频率、延时存在差异,所以原始数据无法在时间维度直接关联。经过对底层采集方式调研,目前测点采样多采用“惰性上报”方式,即当采样值变化超过特定范围才上报一次数据,因此采用右邻插值方法进行冗余数据填充,如图7 所示。
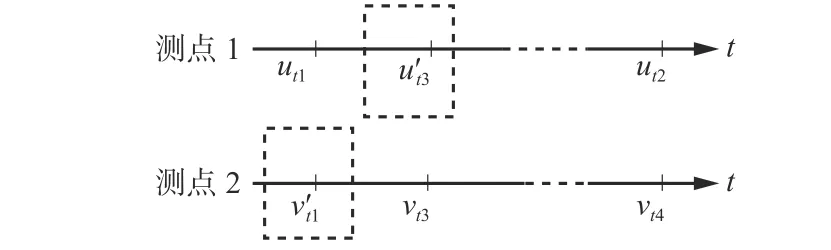
图7 测点数据时间维度对齐Fig.7 Time dimension alignment of measured point data
测点1 在时间轴上有2 个采样值ut1和ut2,测点2 在时间轴上有2 个采样值vt3和vt4。为测点1 补充t3时刻采样值u't3=ut2,为测点2 补充t1时刻采样值v't1=vt3,按时间轴进行迭代,即可实现测点1 与测点2 的采样值对齐。
2.3.2 维度关联
在实际井下环境中,环境传感器或监控系统采样点存在丰富的维度信息,如所属区域、系统、设备、过程、环境等。但受限于采集设备及采样方式,采集上报的数据仅包含采样值,因此在建立数据模型时必须对维度信息进行关联扩展,如图8 所示。

图8 维度信息关联扩展Fig.8 Association expansion of dimension information
主要采用2 种方法进行维度关联:①配置型维度关联。矿井各系统存在大量相对静态的配置型维度信息,如矿井区域划分、设备属性、所属业务系统等。配置型维度模型数据量小、定制化强,可通过手工方式建立并维护测点与维度信息属性之间的映射关系,借助映射关系直接实现配置型维度信息的关联扩展。② 计算型维度关联。基于原始采样数据,经过不同计算型维度(如割煤阶段、液压支架移动阶段、环境安全等级等)的关联实现计算型维度模型构建。计算型维度数据变化频繁、数据量大,无法通过手工建立映射关系的方式与测点进行关联,因此采用拉链化方法,将原始维度模型时间点分布转换为时间区间分布,再通过计算采样时间的包含关系,实现计算型维度关联。
2.3.3 维度化指标聚合
通过维度扩展可将离散的测点时序数据模型转换为多维度的指标数据模型。但在某些综合分析场景中,需要将不同分析主题、数据模型指标进行关联分析。为了同时满足单主题分析与跨主题的综合分析需求,基于多个分析主题数据模型进行维度交叉关联,生成多维度多指标的多维数据立方体,满足不同维度切片下的分析需求。
2.4 数据仓库迁移
不同煤矿的井下开采情况、运行环境、设备型号等存在较大差异,在实际调研和部署过程中发现存在以下问题。
(1)不同煤矿基于各自数据仓库计算出的数据模型指标不一致,导致无法跨矿井进行数据比较分析,且数据模型难以在不同煤矿复用。
(2)算法训练需要大量样本数据,不同矿井由于数据不一致,导致无法使用同一算法。
(3)数据仓库建设是一个持续迭代的过程,会不断沉淀业务指标计算逻辑及口径,不同煤矿之间的经验积累难以借鉴和利用。
为了解决上述问题,提出建设煤矿参数化数据仓库思想(图9),对数据仓库架构进行优化,以解决数据仓库迁移问题。

图9 煤矿参数化数据仓库Fig.9 Parametric coal mine data warehouse
参数化数据仓库包括煤炭行业通用数据仓库和参数化ETL 方法2 个部分。煤炭行业通用数据仓库从行业角度进行抽象设计。虽然不同矿井地质条件、开采环境、规模存在较大差异,但是行业内开采方法、工艺,采用的设备、系统,开采过程都具有相似性,为建立煤炭行业通用数据仓库提供了基础;参数化ETL 方法是指在构建数据处理逻辑时采用参数化方法,将不同矿井间的差异化因素抽象为矿井系统参数配置单独进行维护管理,可通过修改配置信息实现不同矿井的异构数据源统一接入。
3 煤矿数据仓库应用
3.1 数据仓库平台构建
在实验室环境下搭建5 台服务器集群(CPU32核,内存128 GB,数据盘4 TB),在集群上安装分布式文件存储系统(Hadoop 2.6.0-cdh5.13.0),安装分布式数据仓库系统Hive 1.3.0(基于Hadoop 的数据仓库工具[17])作为数据模型的承载系统,从而构建煤矿数据仓库平台,其核心架构如图10 所示。首先从各类数据系统中接入数据到原始数据层;然后将Hive作为数据库进行数据存储,同时使用其ETL 功能进行数据仓库各层次结构的抽取、转换、加载,在服务数据层之上接入应用层数据库,如MySQL 等;最后可接入常见的数据可视化应用,如商业报表工具或智慧大屏幕。

图10 煤矿数据仓库平台核心架构Fig.10 Core structure of coal mine data warehouse platform
煤矿数据仓库平台数据来源于山西天地王坡煤业有限公司(以下称王坡煤矿)综采工作面。数据通过液压支架电液控系统进行采集,数据采集时间为2019 年12 月至2020 年5 月,数据存储于MySQL 数据库,从中抽取部分数据,见表2。

表2 综采工作面采煤机位置数据Table 2 Location data of shearer in fully mechanized working face
原始数据每个数据类别下包含具体的测点信息,每个测点通过标签字段进行唯一标志,每个测点的采样值按时间序列组织,如数据类别、时间、标签、数据值、数据状态等。
3.2 实际应用
3.2.1 辅助机理模型分析
以采煤机采煤过程中液压支架压力变化分析需求的实际场景为例,采煤机在综采工作面每割一刀煤,液压支架会进行降柱、移架、升柱、推溜4 个动作,以割煤周期对液压支架压力变化趋势进行分析。通过原始的采煤机位置序列数据无法直接获得割煤循环周期信息。由于采用两端斜切进刀割三角煤工艺,所以通过割煤机理模型算法与采煤机位置明细数据生成工作面割煤阶段维表,其数据结构见表3,其中方向1,2 分别为上行、下行。

表3 割煤阶段维表数据结构Table 3 Dimension table data structure of coal cutting stage
通过将割煤阶段维表与液压支架压力明细数据进行关联,即可得到每个液压支架压力值对应的割煤阶段信息,再结合液压支架高度、刮板输送机行程明细数据,实现液压支架移架机理模型算法,生成液压支架循环动作阶段维表,表结构及样例数据见表4,其中动作阶段1,2,3 分别为降柱、移架、升柱。
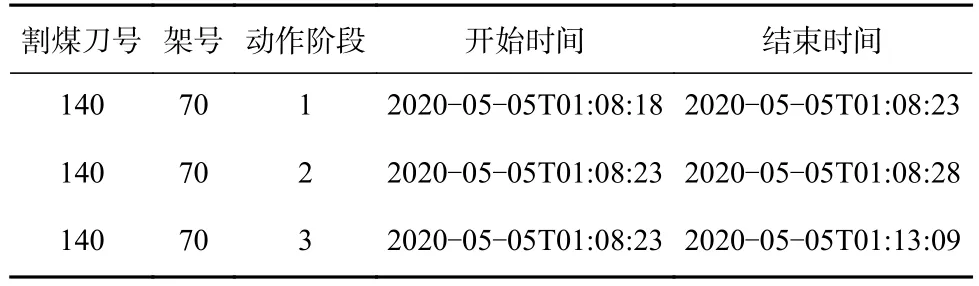
表4 液压支架循环动作阶段维表数据结构Table 4 Dimension table data structure of cyclic hydraulic support action
将带有割煤阶段信息的液压支架压力数据与液压支架循环动作阶段维度数据关联,可得出液压支架压力随割煤刀号的变化规律,如图11 所示。

图11 液压支架压力随割煤变化规律Fig.11 Changes law of hydraulic support pressure with coal cutting
从图11 可判断液压支架升降情况,以割第139 刀煤为例,该过程中液压支架压力最大值点对应降柱开始时间点,压力最小值点对应降柱结束、升柱开始时间点,压力从最小值增大直至平稳的拐点对应升柱结束时间点。
从图11 可看出每次液压支架动作过程中压力变化特点。利用不同维度数据之间的关联,可建立一种关于割煤刀号和液压支架压力变化的离散矿压预测模型。
3.2.2 煤矿可视化应用
设计的智能化煤矿数据仓库已成功应用于王坡煤矿管理驾驶舱,如图12 所示。通过对数据仓库进行可视化分析,可清晰地得出煤矿生产、运营、安全监控等指标,实现煤矿大数据的互联互通和充分应用,实现指标分析及决策场景落地。面向角色的管理驾驶舱可展示煤矿领导及生产、机电、调度中心、安监、通风、信息中心等部门领导最关心的生产、经营、安全类综合性指标130 个。

图12 智能煤矿管理驾驶舱Fig.12 Management cockpit of intelligent coal mine
3.3 应用效果对比
将从业务系统中采集的未经处理数据标记为原始数据模型,与本文设计的智能化煤矿数据仓库进行定性和定量对比。从定性角度主要比较数据组织度、模型复用度和迭代难易度,见表5。可看出通过智能化煤矿数据仓库组织数据,能够全面提高数据使用效率。

表5 原始数据模型与煤矿数据仓库的定性对比Table 5 Qualitative comparison between primary data model and coal mine data warehouse
从定量角度选取综采工作面典型的10 个分析指标对数据查询响应时间进行对比,结果见表6。基于原始数据模型的查询直接在原始数据上进行,基于智能化煤矿数据仓库的查询选择在基础指标层进行(基础指标层数据模型实现了完整的指标体系,是数据仓库的核心)。
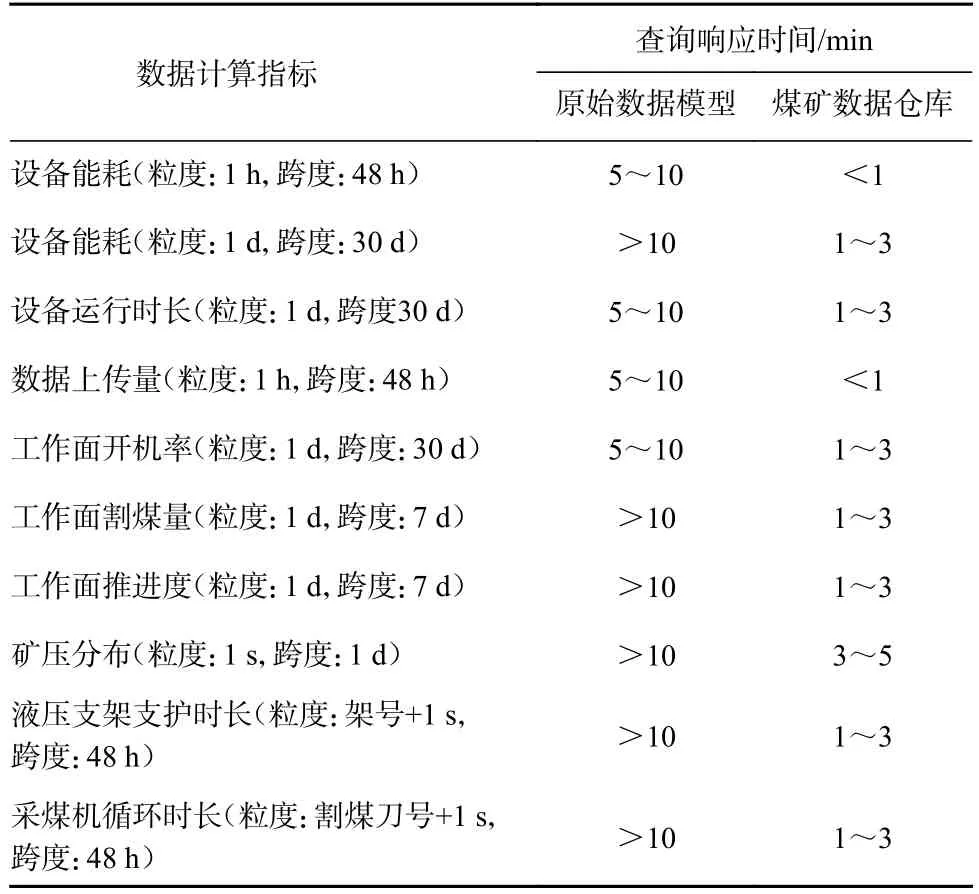
表6 原始数据模型与煤矿数据仓库的定量对比Table 6 Quantitative comparison between primary data model and coal mine data warehouse
从表6 可看出,本文数据仓库在多个指标查询过程中均优于原始数据模型,查询时间均缩减50%以上,原因在于基于原始数据模型的查询要实现数据清洗、预处理、关联、指标统计等逻辑,而数据仓库在基础指标层已完成基础指标预计算,只需进行轻度的聚合计算即可。
4 结论
(1)阐述了智能化煤矿建设过程中数据仓库模型设计方法,以综采工作面为例介绍了煤矿数据仓库建模过程。
(2)针对煤矿数据仓库的可迁移性问题,提出了煤矿参数化数据仓库设计方法,可满足不同类型的煤矿数据仓库建设需求,降低重复建设成本。
(3)利用数据仓库收集不同业务系统的数据并进行统一组织、划分、利用,解决了“数据孤岛”问题。在煤矿数据仓库建模过程中,通过不同维度信息的关联,将不同类型数据融合分析,解决了不同粒度的煤矿数据关联应用问题。在对数据进行提取、转换过程中采用统一标准,提高了煤矿数据质量。
(4)对智能化煤矿数据仓库进行了现场应用,在对多个数据指标分析计算过程中均取得了明显效果,验证了该数据仓库的实用性。
