基于颠覆性指数优化的细分领域优秀科技人才发现研究*
2022-05-12宋培彦冯超慧龙晨翔杨治安宋雨奇
宋培彦 冯超慧 龙晨翔 杨治安 宋雨奇
(1.天津师范大学管理学院 天津 300382;2 .科技部科技评估中心 北京 100081)
0 引 言
《国家中长期人才发展规划纲要(2010-2020年)》指出,“人才是指具有一定的专业知识或专门技能,进行创造性劳动并对社会作出贡献的人,是人力资源中能力和素质较高的劳动者”。2021年9月28日,中央人才工作会议强调要完善人才评价体系,加快建立以创新价值、能力、贡献为导向的人才评价体系,形成并实施有利于科技人才潜心研究和创新的评价体系,为新时代开展人才评价指明了方向。优秀科技人才是具备更高素质与能力、做出更大贡献与成果、具有较强影响力与创新力的佼佼者,其在科学研究、项目评审、成果转化、决策咨询等方面发挥着举足轻重的作用。因此,准确、快速发现优秀科技人才成为科学技术发展的关键,事关科技创新全局,意义重大。
在实践中,科技人才创新能力评价方法主要分为三类,一是基于文献计量学理论,采用h指数[1]、g指数[2]、p指数[3]、NIF指数[4]等评价模型,从论文引用角度对人才学术影响力进行总体性评价;二是基于同行评议和层次分析[5],由评估者设置评价指标体系、权重和基线(baseline),进行定性与定量相结合的标准化评价;三是采用社会网络理论[6],对限定领域的科技人才学术关系及其影响力进行网络关系分析,适于人才专题化评价。上述方法特点鲜明、各有所长,同时,由于大多依赖论文和严格的评价指标体系,评价程序刚性有余而弹性不足,导致评价结果的客观性、准确性和适用性难免时有争议。基于此,本文围绕“反五唯”背景下“科学设立人才评价指标,突出品德、能力、业绩导向”这一关键问题,以“颠覆性创新”为突破口,形成数据驱动和可量化计算的优秀科技人才创新能力发现方法。
1 相关研究
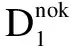
2 研究方法设计
准确判断科技人才的研究领域,有利于识别细分领域科技人才的研究专长,为进行精细化发现奠定基础。通过对科技人才发表的论文关键词聚类,可以发现其研究领域和专长。因此,首先基于科技人才的论文数据采用LDA主题模型进行文本主题发现,识别科技人才研究领域及专长。然后,采用颠覆性创新理论,改进并优化颠覆性指数,计算人才的创新能力,最后,将反映科技人才创新能力的颠覆性指数与传统指标进行对比,检验颠覆性指数在科技人才创新能力发现方法中的适用性。如图1所示。
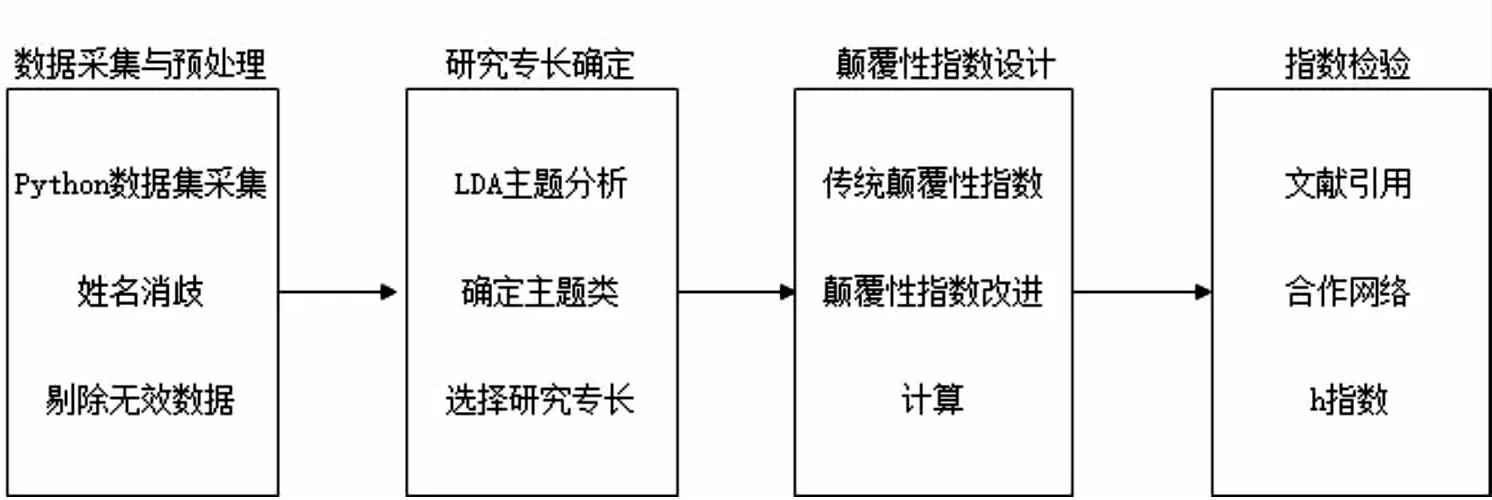
图1 总体研究思路
2.1LDA模型识别“小同行”潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型是由Blei于2003年提出的,该模型以潜在语义分析为基础,是一种基于概率分布的聚类算法,能深入语义层面对文档进行挖掘分析,可用于文本挖掘、文档相似度计算、文本聚类等场景[14]。LDA是三层贝叶斯模型,包括文档、主题和词项3层结构,其核心思想是:假设文档中词与词之间是没有顺序和先后关系的,每一个文档都是以一定概率选中某个主题,而每一个主题又是以一定概率选择特定的词项。本文将使用LDA主题模型对科技人才的成果数据进行挖掘聚类,具体过程如下[15]:
a.对科技人才的每一篇文档,从主题分布中抽取一个主题; b.每个主题会分别对应若干单词分布,从中抽取一个单词;c.对以上过程进行迭代,直到文档中每个单词都被遍历。
通过以上步骤,能够从标题、摘要等信息中以更细的颗粒度挖掘出科技人才的研究方向,为实现“小同行”精准发现奠定基础。
2.2颠覆性指数改进与优化颠覆性指数核心思想是:当一篇引用给定文章的论文也引用了该文章的大部分参考文献时,那么这篇被引文章可以被视为巩固了原有的研究,相反,如果随后论文只引用了给定文章而对被引文章的参考文献未进行引用,即未采纳或认可其他人的研究,那么这篇被引文章就可以视为对其研究领域进行了颠覆式创新。其计算方法如公式1所示:
(1)
该方法是以文献所形成的引文网络为基础,研究焦点文献(被引用或评价的论文)发表后的采纳接受状态。采纳状态分为三种情况:第一种是只引用焦点文献,将其记为F类;第二种是既引用了焦点文献又引用了焦点文献的参考文献,将其记为B类;第三种是只引用了焦点文献的参考文献而未引用焦点文献,将此类记为R类。统计以上三种状态的数量,并对F类和B 类相减然后进行占比计算。计算结果的取值范围为[-1,1],若数值趋近于1,说明创新性比较强;相反,若数值趋近于-1则代表创新性较弱。
对于传统颠覆性指数的单调性不一致,数值为负、对人才创新能力区分度不高等问题,相关学者已进行研究并提出改进方案,但该指数在人才评价方面仍需改进。因为,公式1主要计算只引用焦点文献的文献数量与同时引用焦点文献和前溯文献的文献数量的差(NF-NB)占所有引用量的比例,这就导致只要该比例相同,高被引文献和低被引文献的D值就会趋同,从而与事实可能产生偏离;其次,未充分考虑引用焦点文献的数据集的引用动机、引用质量等因素,从而可能产生聚集效应,如单纯根据文献的引用量进行衡量,焦点文献引用量越多,将会有更多人去进行引用,从而弱化了文章被引用的真实情况。
由此,针对人才创新能力发现的特点,本文进行改进,重点考虑了引用焦点文献的文献数量和质量这两个要素,并提出如下改进公式:
(2)
公式2的含义是:首先,基于质量考虑,本文在现有基础上乘以文献被引用的权值,其中文献i表示引用焦点文献的数据集,citei表示该数据集的后续被引用量,通过该方式来减小文献质量所带来的一些误差;在引用焦点文献的文献数量方面,本文将每次引用的质量指标之和作为衡量标准,同时为进一步减小或消除文献引用中的聚集效应,式中对两层引用均做了对数化处理(ln)。另外,考虑到citei可能出现值为非正数的情况,为便于计算,该式在citei的基础上加了基础质量权值2,避免了零或负值的出现,由此计算出的评价结果更合乎事实,计算结果也更便于理解和使用。
3 实验分析与检验
3.1数据采集与处理本文以干细胞领域的“杰青““优青”人才为例开展实证研究。干细胞是当前生物医学领域新兴热点,也是我国科技研究的前沿领域和优势领域,因此,本文以干细胞领域为例,收集2010年到2019年近十年内的杰青、优青称号的科技人才名单,并在Web of Science数据库中检索其发表的英文论文数据,进行作者与论文数据的关联。为了解决科技人才姓名缩写及表示形式不一、重名等问题,在数据关联前进行了姓名消歧处理,通过Wos数据库Web of Science ID 或ORCID ID来识别科技人才,辅助通过人才的工作单位、合作者以及网站信息进行进一步的筛选,最终确定人才的论文数据集。最终形成的数据集包括引用焦点文献的数据集和引用焦点文献中参考文献的数据集。由于论文发表后一般需经历一段周期才会有一定引用量,因此为了避免误差,本次实验采集科技人才数据排除了近三年发表的文献(2019年-2021年)。本文以5位科技人才为例,共采集焦点论文有效数据193篇,其发表年限主要集中在2006年到2018年间,引用焦点文献的数据集8 465篇,引用焦点文献中参考文献的数据集3 012 930篇,以提高实验效率。
3.2基于LDA的研究专长识别本文采用LDA主题模型进行文档挖掘与聚类,并通过设定困惑度来选取主题数目,以保证模型预测结果的精确性和主题间相似性的最小化。经LDA模型运行后,共获得5个主题数目,每个主题下都有以一定概率表示的词,考虑到有的词过于泛化,如“cell”等词汇,同时为确保能够准确地表达主题内容,本文将人工与机器相结合,并邀请医学专业的人员辅助进行主题的确定。接着,根据主题关联度(1/主题数,本文关联度为0.2),利用模型输出的结果对每篇文档进行归类,若出现某文档属于两个或多个主题类时,则将其归入概率最高的那一类中。归类成功后,统计各个主题的文档数量,选取数量最多的作为科技人才的研究专长领域。如郑**研究专长是造血干细胞,与之相关联的词以一定概率分布,其中leukemia、hscs、stem、hematopoietic、igfbp2等词语权重较大,能一定程度表达主题内涵,反映科技人才的研究专长。如表1所示。

表1 部分人员研究专长
3.3D值结果与分析
3.3.1 D值检验 获得公式1中的NF、NR、NB的数据,基于3.2节提出的计算公式2,利用颠覆性指数进行计算,计算结果部分如表2所示,为保证颠覆性指数可以更准确、更全面的评价科技人才总体的创新能力,本文选取了颠覆性指数的总和、均值、最大值及最小值来进行衡量。其中,根据Sum_D计算结果可以发现杰青人才杨**、郑**、项*的各项数值总体大于优青程*、刘*,说明前三个人才相对于后两个科技人才创新能力较强,可以初步判断颠覆性指数能对优秀科技人才创新能力进行发现,如表2所示。
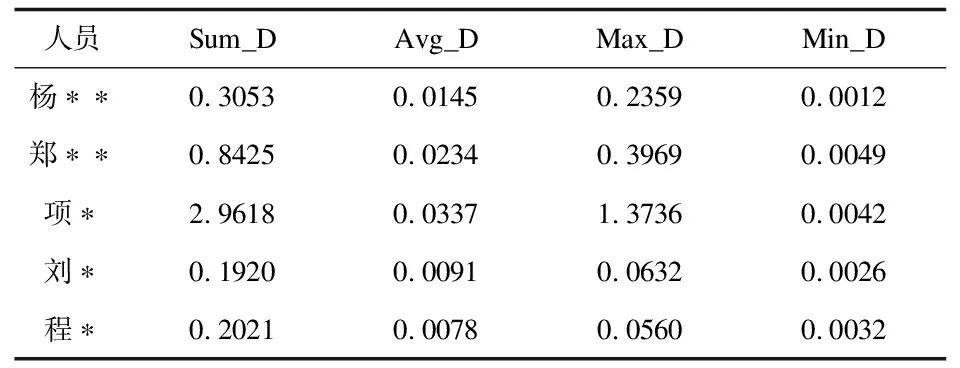
表2 科技人才颠覆性指数
为了进一步检验颠覆性指数是否能准确衡量科技人才的创新能力,本文从论文引用量、合作网络、h指数三个传统维度进行验证。
a.引用维度:总被引量是指某一科技人才发表的所有文章的被引用量,该指标能够一定程度上反映科技人才的影响力,篇均被引量则反映科技人才的平均水平。
b.合作网络维度:点度中心度是社会网络分析中的衡量指标,其指与某个点相连的其它点的个数,点度中心度越大,该点在网络中的位置越重要,代表科技人才的影响力也越大。间度中心度反映点与点之间的最短距离是否都经过某一个点,表明某一点在网络中的控制能力及重要性,若权值大,则代表该点在网络中处于核心地位,影响力较大。
c.h指数:h指数是指至多有h篇文献被引用了至少h次,指数值越高,一定程度上科技人才的学术水平也就越高。
计算各个指标,并进行对比验证。其中论文引用量与h指数两个维度指标通过Web of Science数据库获取,合作网络维度中点度中心度和间度中心度通过Gephi软件进行计算得出。验证结果如表3所示,以项*和刘*为例,项*的Sum_D值和Avg_D值分别为2.9618、0.0337,其值均高于刘*,初步判定项*要比刘*在该领域的创新影响力更大。以传统指标进行进一步验证,发现项*的点度中心度为135,高于刘*的79,说明在学术共同体构成的网络中,与项*所连接的人员更多,项*在中心位置所发挥的影响力更大;同时,项*的h值、文章总被引量、篇均被引量等也较高。这可能也与科技人才本身所发表的研究成果数量有关联,其中,项*在Wos数据库中的有效论文数据达88篇,而刘*仅22篇。另一方面,杰青获得者往往比优青获得者对创新能力的要求更高。经上述总被引量、篇均被引量、h指数、中介中心度等指标的验证,总体可以较好反映颠覆性指数的基本态势,作为参考基准是基本合适的,但因为时效性和精准性有所欠缺,因此可以考虑增加引用速度、社会反响等外部特征验证趋势的一致性,以弥补论文引用时间滞后性和分析精度偏差,增强颠覆性指数的解释力。

表3 D指数与传统指标对比
3.3.2 细分领域优秀科技人才创新力识别 从细分领域出发,有助于按照“小同行”更加精准识别科技人才。通过LDA主题模型聚类,并将所属文档进行归类,从而确定科技人才的研究领域,进一步识别该领域内的科技人才的比较优势。根据3.2小节中所确定的科技人才研究领域,发现程*和郑**属于同一个细分领域(造血干细胞研究),杨**和刘*属于神经细胞领域专家。
在此基础上,以“造血干细胞”及“神经细胞”两个细分领域为例,计算相关人员的颠覆性指数。郑**的颠覆性指数高于程*,说明在造血干细胞领域,郑**的研究成果更具创新性,其研究成果被后面追随者认可接受的程度比较高。在神经细胞领域,优青人才刘*的颠覆性指数高于杰青杨**,可以看出虽然杨**的总体D值大于刘*,但在细分领域神经细胞研究中,后者更具创新影响力。由此可见,进行细分领域科技人才识别有助于打破常规,挖掘到“小同行”领域的创新人才,为创新科技人才的发现提供了新的研究视角。如图2所示。
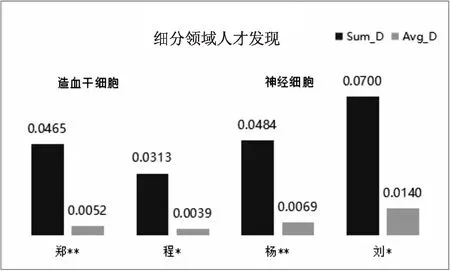
图2 细分领域人才发现指数
4 结论与展望
在科技人才评价改革背景下,从细分领域出发,以优化后的颠覆性指数为依据,通过实验初步验证了颠覆性指数能较好应用于人才发现与识别中,对细分领域优秀科技人才精准发现、评价与推荐等具有一定的参考价值。研究还发现,应用颠覆性指数进行人才识别方法具有以下特点:a.颠覆性指数通过焦点文献替代参考文献的程度来识别创新性,综合考虑了焦点文献与参考文献,用该方法所识别出的创新性人才更具权威性与全面性。b.通过LDA主题模型聚类,识别细分领域的科技人才,有助于发现细分领域的“单项冠军”,更好满足抽取“小同行”专家进行同行评议等需求。同时,颠覆性指数在实际应用过程中也存在着零被引论文、引用时间窗过长等问题,可能会对计算精度造成影响,今后可以通过引入科研项目、专利等多源信息,并通过与现有人才评价方法适度融合进行改进。
