考虑反讽语义识别的协同双向编码舆情评论情感分析研究
2022-05-12潘宏鹏刘忠轶
潘宏鹏 汪 东 刘忠轶 李 轲
(1.中国人民公安大学公安管理学院 北京 100076;2.中国人民解放军火箭军士官学校作战保障系 潍坊 262500)
0 引 言
互联网的广泛普及赋予了社会公众充分的网络话语权和舆情参与能力,并由此诞生了官方与公众两大舆论场。截至2020年12月,我国互联网普及率已达70.4%,手机网民比例高达99.7%[1],其中80.3%将新浪微博作为新闻信息的获取渠道[2]。可见,在信息平权时代,“新浪微博”已成为人们掌握新闻信息的重要源头,同时它凭借自身便捷性、时空自由性、全民参与性等特点,很容易成为情绪传递与舆情爆发的主要策源地。2020下半年以来,伴随着杭州“交警喷老人辣椒水”、南昌“谁是yuwei”等事件的网络曝光,社会公众对于舆情事件的关注度也在不断提高,舆情呈现爆发式超速传播的趋势。与其他新闻类型不同的是,舆情事件的产生极易引起社会公众的重点关注。尤其是意见领袖及其微博下网民评论的负面情绪一旦发酵,就会不断衍生出有损政府公信力的舆情风波,甚至将对社会秩序造成难以估量的影响。
文本情感分析是自然语言处理的重要研究领域,对于解决上述问题可发挥有效作用。考虑到自然语言的复杂特性,舆情评论除了直接性的情感表达外,往往伴有多种复杂的修辞特征,一类最常见的即为反讽型。例如某政府舆情事件中网民评论,“真不愧是我大天朝的人民警察,向90岁老汉喷辣椒水的身姿真英勇”,这显然是一句典型的反讽文本,看似表达的是积极健康的心态,实则蕴含着具有强烈讽刺意味的负面情绪。但传统的自然语言处理模型会根据“不愧”“英勇”等词将这句话判别为正面情感,无法做到对文本信息的精确处理,这显然是不符合任务要求的。这正是目前舆情情感识别技术的难点所在。
基于此,本文将在双向编码表征网络的基础上进行改进,通过将反讽语义/非反讽语义、正面情感/负面情感两种领域的语义信息进行合并,设计出一种协同双向编码舆情评论情感识别模型。相关部门在对掺杂反讽语义的舆情评论文本进行情感识别时,在反讽识别向量的指导下,模型会根据评论文本的不同性质进行不同的对应处理,从而增强模型对舆情评论文本的反讽识别力与泛化程度。
1 相关工作
文本情感分析技术,又称意见挖掘技术,其基本原理为:通过爬虫挖掘,对舆情事件微博话题中的意见领袖评论和网民评论文本进行收集,对其情感极性进行分析,基于此为相关部门掌握网民诉求与疏导舆论提供帮助。在舆情分析、特征画像、网民诉求量化等方面,该技术可发挥重要作用。纵观学术界关于文本情感分析技术的探索和改进,前人研究主要集中在情感词典构建、机器学习、深度学习等领域,且分别已取得优秀的研究成果。
1.1情感词典构建领域情感词典构建是一种基于词典获取待测文本中情感词的情感值,再通过加权计算以确定文本整体情感倾向的方法。黄立赫等基于BTM主题模型提取视频弹幕主题信息,基于情感词典和颜文字词典计算不同时间窗口下的主题情感类别和情感强度,建立视频弹幕在线舆情事件监控模型[3]。李永帅提出了一种基于双向长短期记忆模型的动态词典构建方法,并通过对CBOW模型的改进,构建了应用ECBOW模型的动态情感词典[4]。总的来说,以情感词典为基础的文本情感分析技术存在很大的弊端——过度依赖词典的构建质量。换句话说,只要词典内容足够丰富,就可以获得较好的情感分析效果。但词典的研究设计必然从研究伊始就受制于研究者的主观性思维,因此其分类效果很难再进行实质性改进。
1.2机器学习领域在机器学习领域,朴素贝叶斯(简称为NB)与支持向量机(简称为SVM)是常用于文本情感分析任务的经典算法。杨爽等提出了基于词性、情感、句型和语义等特征的SVM情感分类方法,可实现五级情感分类,准确率得到明显提高[5]。Pang等人使用NB、SVM等机器学习模型对电影评论数据集进行情感分类判断,实验结果表明,SVM模型的准确率可以达到82.9%[6]。Birjali等将支持向量机与朴素贝叶斯算法相结合,提出了一种基于WordNet语言词典训练集的语义分析算法,能够实现自动检测自杀内容的文本[7]。综合上述机器学习研究,可以发现:基于机器学习算法的文本情感分析能力较情感词典来说已有极大提高,但其算法局限性成为了制约自身准确率与泛化能力的关键。例如,朴素贝叶斯对样本的代表性有较高要求,因此在处理较小样本的分类任务时,会出现不能覆盖所有属性等现象。
1.3深度学习领域随着深度学习算法与神经网络的兴起,文本情感分析技术有了新的突破方向。张海涛等构建了基于卷积神经网络(CNN)的舆情情感分析模型,将深度学习算法应用于舆情研究领域,提高了舆情文本分类的准确性[8]。Dong为了解决基于目标词的情感分析问题,提出了自适应递归神经网络,在语法中使用依赖解析树来查找与目标单词相关的单词,通过自下向上不断递归得到目标单词的向量表示[9]。同样地,张柳等针对当前微博评论中常见的上下文信息有限、外语词汇较多的文本情感分析现状,提出了一种基于词向量的多尺度卷积神经网络微博评论情感分类模型[10]。综合来看,现有基于深度学习的文本情感识别技术大多围绕卷积神经网络和循环神经网络展开,虽克服了传统机器学习算法在数据采样与样本代表性方面的某些局限,但算法本身仍对样本的数据规模有较高要求。因此,对于舆情评论这样较小的数据集来说,深度学习算法仍然难以取得更加出色的分析效果。
近年来,迁移学习思想的产生拉开了预训练模型的序幕。2018年,谷歌(Google)公司研发出了基于转换器的双向编码表征网络,在包含文本情感分析在内的11项自然语言处理任务中均取得了最佳成绩[11]。Sun等提出了一种基于方面级任务的情感分类方法,对双向编码表征的预训练模型进行了微调,并运用前人文章数据集取得了较好的分类结果[12]。孙靖超用伪标签的方法克服了需要双向编码表征数据集需要大量人工标注的难题,并证明了双向编码表征模型对于舆情情感分析任务的可行性[13]。总的来说,相比于CNN和RNN等深度学习算法,双向编码表征模型只需构建注意力机制,就可解决传统方法无法并行处理的问题。同时,迁移学习思想赋予了模型将开放领域学到的知识迁移到下游任务的能力,这为同领域小规模语言处理效果改善提供了极大帮助,突破了机器学习与深度学习算法对数据规模有高要求的局限性,适用于解决舆情评论的情感极性分析。
2 协同双向编码表征的模型框架与改进思想
可见,以双向编码表征为代表的预训练模型是当前文本情感分析研究的前沿领域,可对情感词典、机器学习算法与深度学习算法的模型局限进行对应改善。需要注意的是,上述改善仅针对正常语义表征的文本,不适用于掺杂有反讽语义的复杂文本。但反讽这一修辞手法在舆情事件评论中的确十分常见,如果不能对这一问题进行考虑,文本情感分析技术就无法为帮助相关部门掌握民意发挥实质性用途。
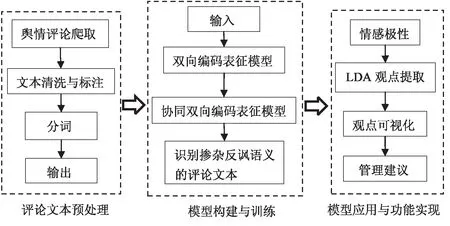
图1 技术路线图
遗憾的是,这一问题尚未引起国内外学者的重视,目前学术界关于这一问题的研究寥寥无几。[14-15]基于此,本文将在双向编码表征模型的基础上进行图1所示的改进,在爬虫抓取评论文本并预处理后,通过两个普通双向编码表征模型的协同组合,合并舆情评论文本中的反讽语义/非反讽语义、正面情感/负面情感两种领域语义信息。进一步,运用LDA等主题提取技术,对情感识别无误的舆情评论进行观点挖掘并使其可视化,致力于为相关部门提供更直观可靠的管理决策。
2.1模型框架与运行原理从框架层面分析,协同双向编码表征模型的主体结构由两个普通双向编码表征模型与一个额外全连接层组合而成,通过不同领域语义的信息融合与处理,保证了模型框架的完整性与设计合理性。而从运行原理层面分析,协同双向编码表征模型可被视为“语义理解模块”“反讽识别模块”和“协同决策模块”的功能组合。具体来说,对于输入层中的待测评论文本,“语义理解模块”通过编码和特征提取以获得情感语义信息。“反讽识别模块”通过编码和特征提取以获取舆情评论文本的反讽信息。之后,语义信息和反讽信息同时输入到“协同决策模块”中进行特征融合与协同训练,最终由“协同决策模块”给出最终的情感极性识别结果。模型结构如图2所示。
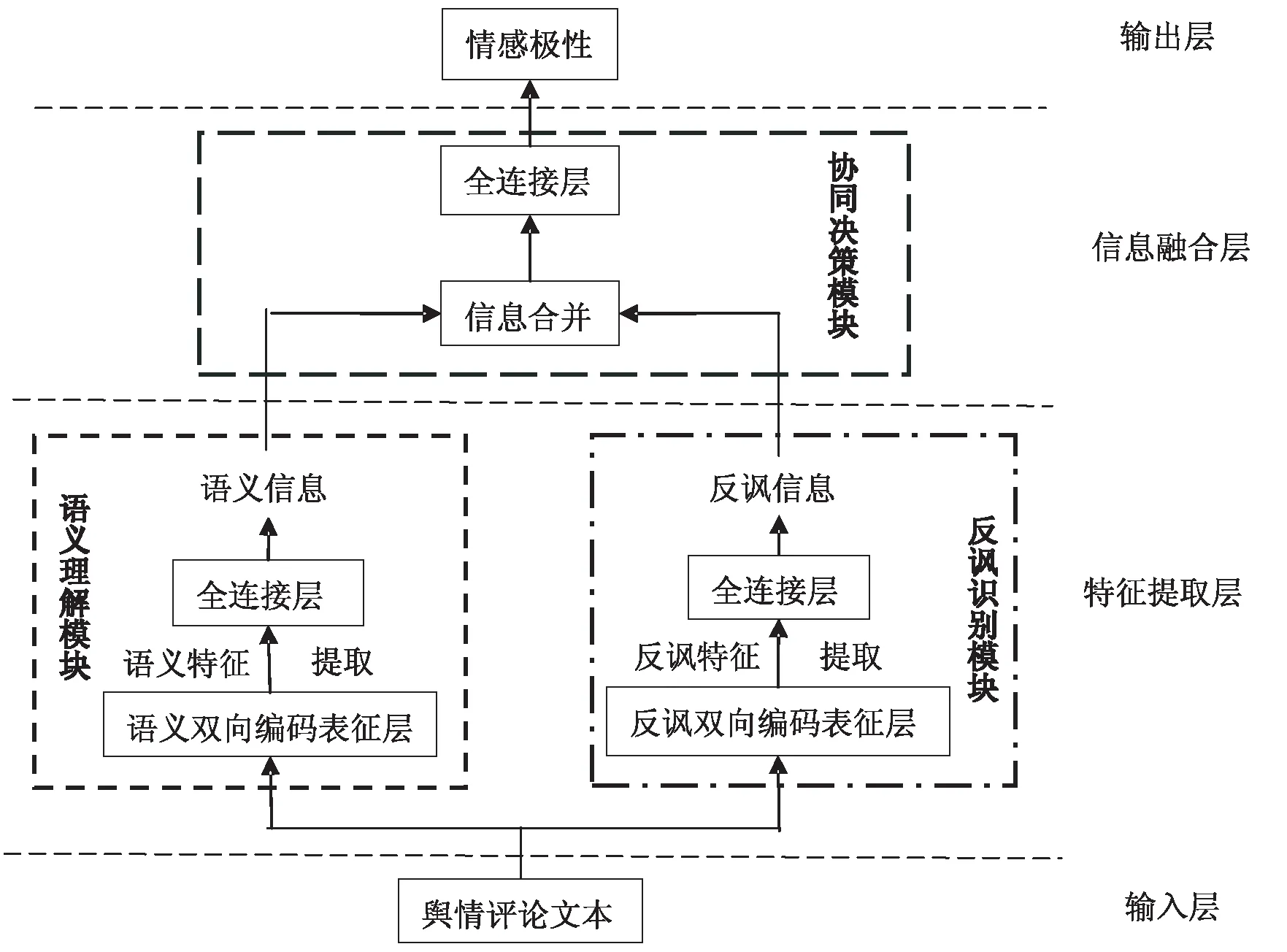
图2 协同双向编码表征模型
在特征提取层中,“反讽识别模块”通过运用预训练与迁移学习思想,负责完成舆情评论文本反讽特征抽取和分析任务。通过衔接基于双向Transformer结构的反讽双向编码表征层和全连接层,该模块可对抽取到的文本反讽特征进行深层次分析,逐渐增强模型对舆情评论反讽信息的鉴别能力。为保障预训练效果,本文专门构建了反讽语义文本数据集,用来进行“反讽/非反讽”的二值语义分类任务训练。通过大量针对性训练,该模块可出色完成舆情评论文本的反讽语义识别任务。同理,“语义理解模块”在结构上与“反讽识别模块”相似,通过语义双向编码表征层与全连接层的衔接与针对性训练,保证模块对评论文本正负语义信息的获取能力。
进一步,考虑到反讽评论文本的存在会对文本整体情感极性造成极大转折,需要在信息融合层中引入第三个模块—— “协同决策模块”。该模块由信息合并层与全连接层构成。通过信息合并层将前述两个模块中的反讽信息和正负语义信息融合,全连接层将对融合后的信息进行更深层次学习,形成以反讽信息指导、纠错、扶正正负语义信息的优化能力。
综上,针对待测的舆情评论文本,由“语义理解模块”提取正负语义信息;由预训练完成的“反讽识别模块”采用反讽识别能力,在情感极性识别任务中进行迁移应用,提取舆情评论文本中的反讽语义信息。 接下来,由“协同决策模块”对“反讽/非反讽”、“正面/负面”两种领域信息进行融合,根据待测舆情评论文本是否存在反讽语义,给出其情感极性识别结果。如此循环训练,识别结果的准确性将使得“语义理解模块”和“协同决策模块”的模型参数不断调整优化。通过上述过程的模型收敛,协同双向编码表征模型将对掺杂有反讽语义的复杂舆情评论形成较好的情感极性识别力。
2.2基于迁移学习的可行性分析从本质上说,双向编码表征模型属于迁移学习的应用范畴。迁移学习中一个较为重要的概念就是微调(fine-tuning),它允许研究者在处理新的下游任务时,不用再重复人力和时间从零开始训练模型,而只需要对模型中的参数进行微调即可实现迁移学习。因此,在模型框架层面,负责反讽语义识别与正负情感识别的两个普通双向编码表征模型均采用的是“预训练+全连接层”的结构。以反讽语义双向编码表征模型为例,反讽文本在经过预处理、向量化、输入到预训练完成的双向编码表征模型后,研究者就可通过反向传播算法对模型各部分参数、权重进行微调,然后将谷歌官方预训练模型迁移到反讽识别任务上。
协同双向编码表征模型就是通过向量拼接的方式,在图2所示的信息融合层中增加一个额外的全连接层,由其完整保留舆情评论文本的反讽语义和正负情感语义两种领域信息。从可行性上分析,通过两个普通双向编码表征模型的协同配合,协同双向编码表征模型既能理解正常语义评论的情感表达,又能准确判断反讽舆情评论的情感极性。
2.3输入序列与特征表示双向编码表征模型的输入层包含了舆情评论中各个字符的原始向量,这些向量既可以是随机初始值,也可以是通过Word2Vec等分词算法计算的输出值。模型的输出层则是经双向Transformer层提取特征后、已融合全句文本语义信息的字符向量表示,如图3所示(以评论文本“点赞,支持警方”为例)。
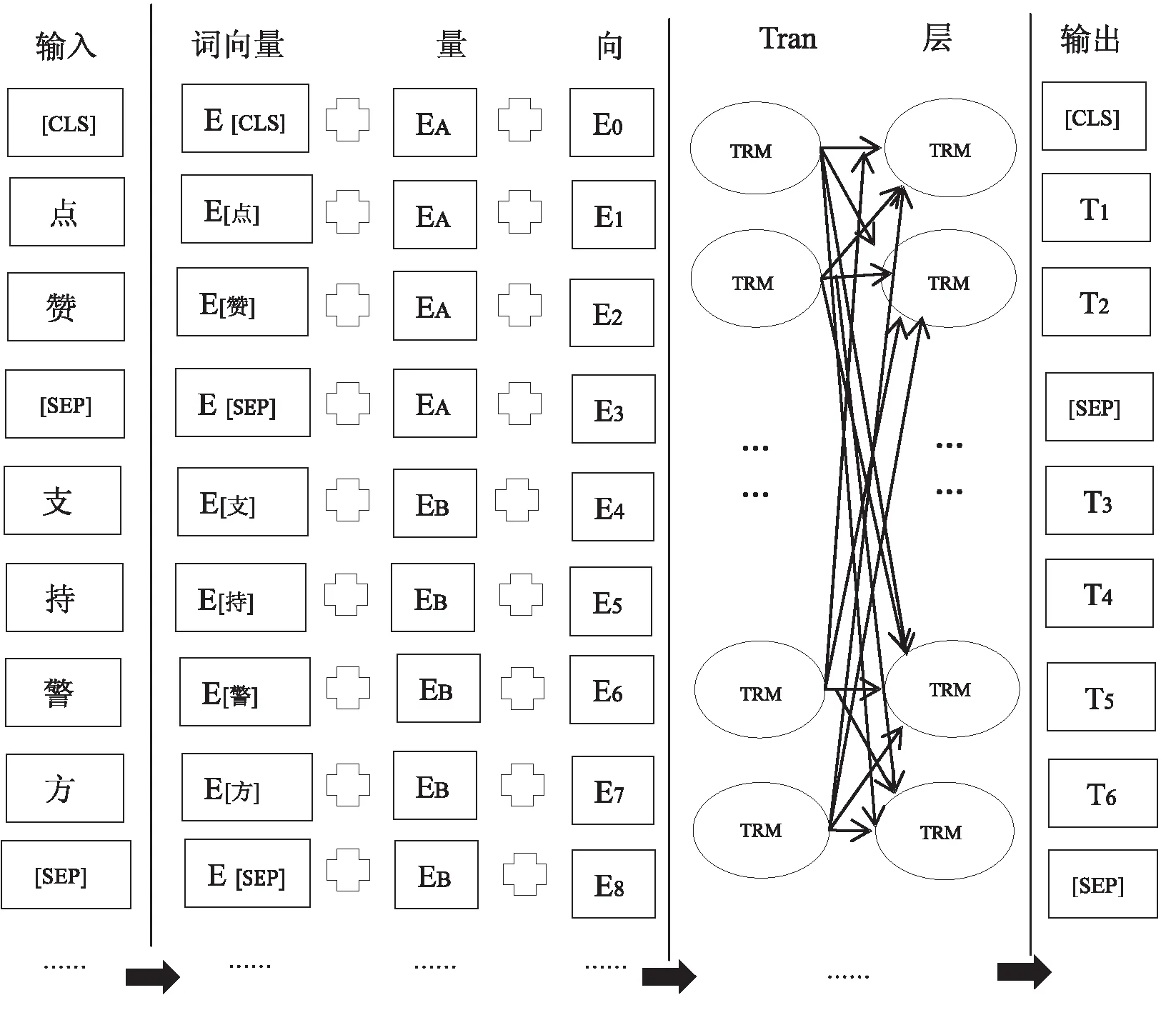
图3 输入序列与特征表示
2.4特征提取层在特征抽取层中,双向编码表征模型采用的是双向Transformer,改进了ELMo模型特征提取能力不充分和GPT模型信息不足的缺点。如图4所示,每个Transformer均由多头注意力机制层(Multi-Head Attention)、标准化层(Normalization)和全连接前馈神经网络层(Feed Forward)构成。
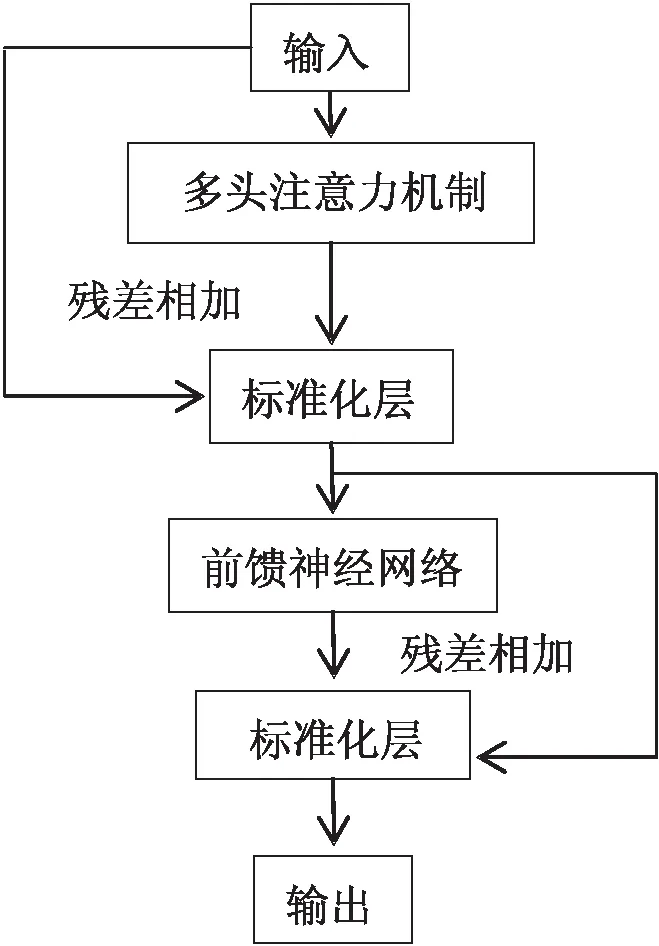
图4 编码器结构
在模型对舆情评论文本特征进行抽取的过程中,Transformer中的多头注意力机制可发挥重要作用。在图5所示的模型构成中,多头注意力机制由多个自注意力机制(Self Attention)组成,这也构成了双向编码表征模型在处理细粒度文本时的语义理解能力与信息获取能力。模型的输入层均包含有每个字符对应的Q、K和V向量,且分别通过其与权值矩阵WQ、WK和WV的相乘,可得到相同维度的矩阵。
在多头注意力机制中,每一个单独的自注意力机制关注的都仅是舆情评论文本某一种维度的信息。在经过公式(1)和公式(2)的叠加后,多头注意力机制就能够获取舆情评论文本多种范围的语义信息,保证了双向编码表征模型在处理细粒度语义任务时的信息获取能力。
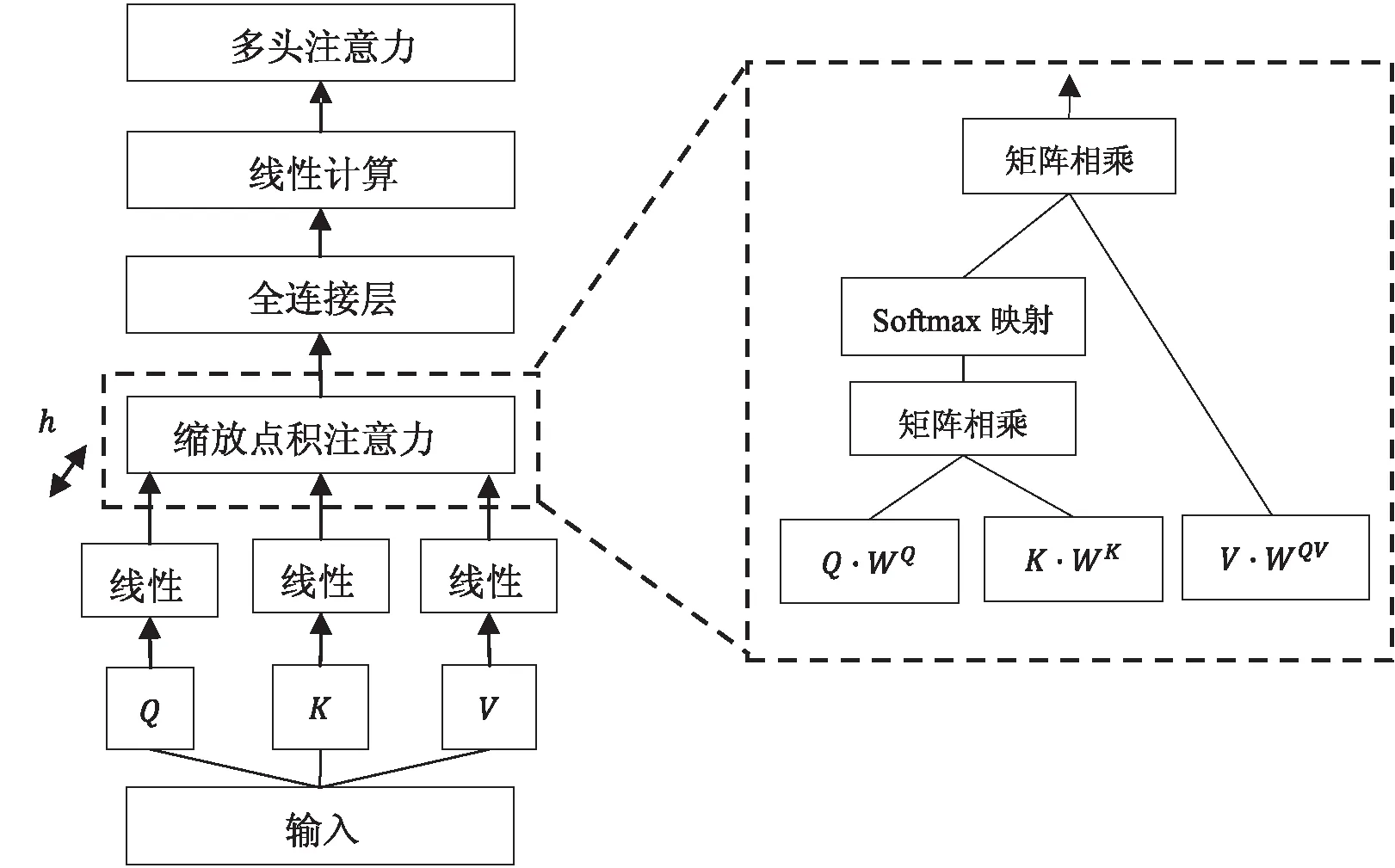
图5 多头注意力机制
MultiHead(Q,K,V)=
linear(Wlconcat(head1,head2…headn)+b)
(1)
headi=Attention(QWQi,KWKi,VWVi)
(2)
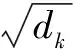
(3)
2.5模型结果输出输出层根据文本内容的不同,会有下述两种处理方案。
a.若待测文本为正常情感表征,不含反讽语义,模型就会按照普通双向编码表征模型识别方法,进行文本情感极性分析,直接输出情感极性结果。
b.若语句中掺杂有反讽语义,模型则会根据反讽识别结果,在普通识别的基础上对情感极性进行调整,帮助纠正其中识别错的文本语句后,输出真实的情感极性。
基于此,协同双向编码表征模型可提高掺杂有反讽语义的复杂舆情评论文本情感识别的准确率,为相关部门提供更加准确可靠的算法支持。
3 实验应用研究
3.1案例简介与热度分析2020年12月4日,安徽省安庆市望江县一名女子意欲跳河轻生,在民警到达现场并安抚的情况下,该女子最终不幸溺亡。这起事件发生后,迅速引起了社会的重点关注,现场围观群众拍摄的短视频也迅速在微信、抖音等社交平台传播并引起热议,微博也极快地产生了该起政府舆情的热门话题。以“知微数据公司”旗下“知微事见”为案例分析工具,可基于其公开的事件影响力指数为舆情事件热度分析提供参考(http://www.zhiweidata.com/),在“知微事见”中,事件影响力指数是指事件在自媒体(主要指微博和微信)和其他网媒平台累积传播效果的加和,并归一化为(0,100)间的指数[16]。如表1所示,从2020年12月4日到12月10日20时,该舆情事件的整体影响力指数高达68.5,社会关注度远超同期77%的社会类事件。
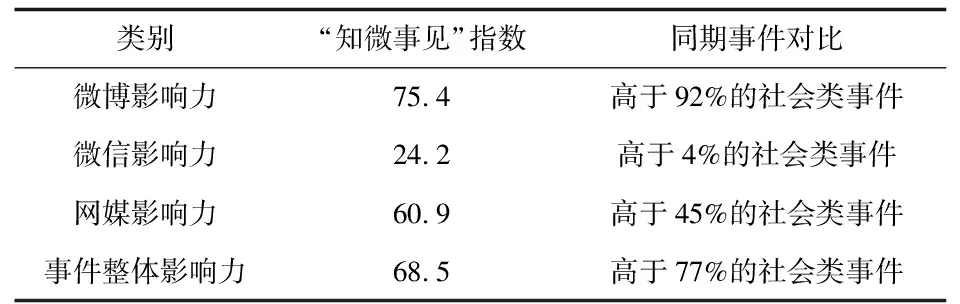
表1 “知微事见”影响力指数
为响应持续发酵的网络舆情,如表2所示,多家主流媒体相继加入讨论并发表评论。12月6日,“#央视主播评望江女孩轻生溺亡#”登上热搜,最高排名第三。

表2 媒体报道情况
3.2实验数据集的获取与预处理本次实验使用“八爪鱼”采集器进行数据抓取,该软件优势在于:软件根据新浪微博、今日头条等不同网站设计了相应采集策略与接口,研究者可根据需要自定义参数以保证目标数据的完整性与稳定性。
a.反讽数据集的获取。基于新浪微博的丰富语料资源,本文通过搜索热门舆情事件的关键词、舆情话题排行榜、微博大V等多路径进行评论文本抓取,对反讽语义的舆情评论进行收集,用“0”表示“反讽评论”,用“1”表示“非反讽评论”。
b.正负情感数据集的获取。同理,本文针对4.1中案例,对2020年12月4日至12月10日之间“#警察注视女生溺亡被停职#”等话题中媒体和大V发文下的网民评论进行数据抓取并进行标记,用“0”表示“正面评论”,用“1”表示“负面评论”。
在获得两个数据集后,为提高准确性,通常在实验之前需先对数据集进行数据清洗等预处理操作。通常包括以下步骤:
a.过滤无效文本。由于数据采集均来自于新浪微博话题,因此收集到的文本数据中往往存在“转发”以及“图片链接”等,这些无效噪声应予以过滤。
b.去除文本中的特殊字符、带有“微博话题”的空白数据、带有“http://…….com”的网络来源链接。另外,需剔除相关话题的推送链接,因为这也可能存在一定的情感倾向,会对原始案例产生干扰。例如本次研究话题下可能会出现“沉痛缅怀某牺牲民警”的推送链接,链接里包含的“沉痛”“缅怀”等词会对原本数据集的情感判定带来影响。
c.使用Jieba工具包进行分词并去除停用词,通过双向编码表征模型将文本数据转化为词向量。
d.最后,本文共得到反讽语句9 742条,非反讽语句9 647条,组成了19 389条语料的反讽数据集。同理,得到正向评论语句16 491条,负面评论语句16 830条,组成了33 321条语料的正负情感数据集。分别随机选取两个数据集中的80%作为各自训练集,10%作为各自验证集,10%作为各自测试集。
3.3实验环境与超参数取值实验工具包是Anaconda,通过谷歌官方发布的训练前权重来使用双向编码表征模型,实验环境配置如表3所示。

表3 实验环境与配置情况
在模型训练过程中,一般采用正则化方法可提高模型的鲁棒性。为保证模型具有较高的泛化能力,在微调时通常设置较低的学习率。本实验将学习率取值为2×10-5。其他超参数的取值如表4所示。

表4 超参数取值
3.4模型效果评估舆情评论情感分析,本质上属于文本情感的二分类任务,因此模型评估可采用混淆矩阵法。具体来说,混淆矩阵就是通过各项指标将数据分类结果转化为(0,1)之间的比率,并以此进行标准化衡量(比率越接近1,模型的输出结果越好)。
精确率(下文简称为“P”)是指“模型预测为正向的样本中有多少是真正的该类样本”。如式(4)所示,TP代表“真实值是正向,模型预测为正向的样本数”,FP代表“真实值是负向,但模型预测为正向的数量”。
(4)
召回率(下文简称为“R”)是指“样本中属于正向分类的数据被准确预测的比率”。如式(5)所示,FN代表“真实值是正向,但模型预测为负向的样本数”。
(5)
准确率(下文简称为“A”),是指“模型所有预测准确的结果占总样本量的比率”。如式(6)所示,TN代表“真实值是负向,模型认为是负向的数量”。
(6)
为对模型进行更好的整体性评价,在P与R的基础上,按照式(7)产生指标F1。
(7)
3.5对比实验如2.3所述,文本情感识别领域当前的研究热点在于以深度学习算法解决该任务。其中较为成熟和主流的主要是基于循环神经网络的Text-LSTM与基于卷积神经网络的Text-CNN两种方法路线。前者利用了RNN结构保留历史信息并不断增加新信息的特性,能够适应文本分析任务中综合理解上下文关系的需求,并通过遗忘门、更新门和输出门等结构较好地解决了常规RNN网络的梯度消失现象。后者则通过定义不同的卷积核,提取舆情评论文本中的不同局部特征,在池化层(Max pooling)处理基础上对特征向量进行拼接挑选,通过由局部到整体的方法实现对文本的语义理解。但当前关于上述两种深度学习模型的研究,很少就舆情评论文本中的反讽句式进行专门的针对性设计和研究。本文的协同双向编码表征模型,在“语义理解模块”之外专门引入了“反讽识别模块”,通过协同训练,在一定程度上有效弥补了上述深度学习算法的研究不足。
基于此,在对比实验中,可将协同双向编码表征模型设置为对照组,将普通双向编码表征模型、Text-LSTM、Text-CNN设置为实验组。根据公式(4)至(7),计算上述四种模型对应的P、R、A和F1值,对比结果如表5所示。
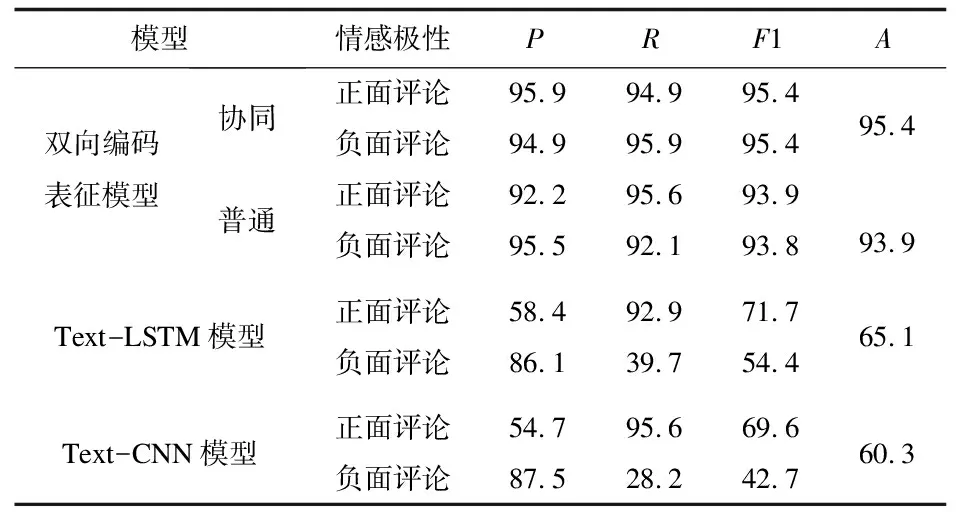
表5 实验结果 %
对比普通双向编码表征模型,协同双向编码表征模型在准确率A上有1.5%的提升,相对错误率降低了24.6%。对比Text-LSTM、Text-CNN模型,协同双向编码表征模型的准确率分别提升了30.3%与35.1%。另外,通过各模型P、R、F1指标对比也可看出,协同双向编码表征模型在精确度和查全能力上都拥有更好性能。
4 研究结果
4.1语句识别效果评价为直观看出改进后模型对反讽语句的识别效果,本文挑选了若干具有反讽语义的舆情评论,并将各对比模型的识别结果列出。
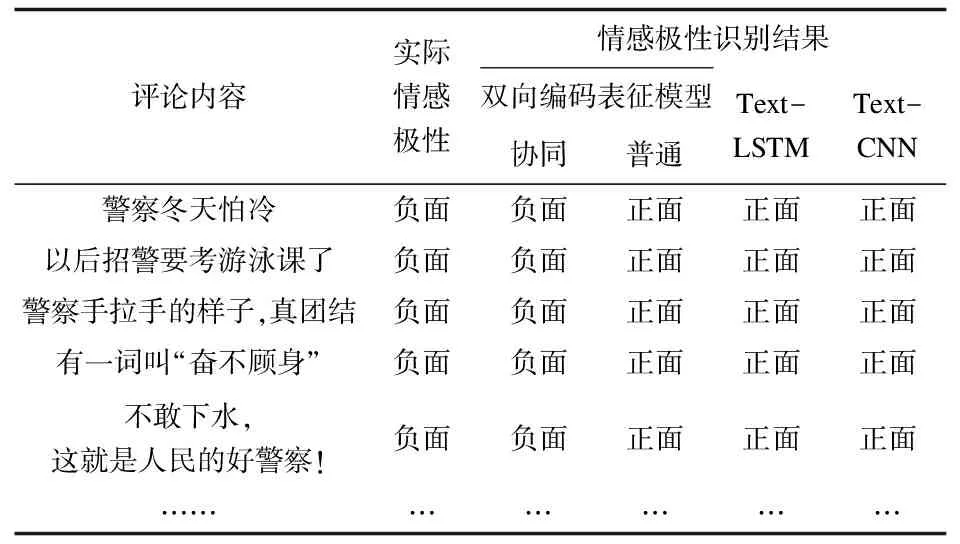
表6 语句识别效果对比
对比可见,对照组的三种模型对于掺杂反讽语义的评论均未准确识别情感极性。而协同双向编码表征模型,由于融合了反讽语义信息,因而能够对舆情评论进行针对性的处理,从整体上提升了情感识别准确性。
4.2主题可视化与管理对策在5.1的基础上,基于LDA模型进行文本主题词提取,依据词向量的权重生成如图6所示的观点词云图。

图6 词云图
正面情感极性的评论关键词,主要包括“警察”“支持”“点赞”等。此类评论主要是现场目击群众以及在安徽警方发布通告后的网民,对事发中民警施救方法的评价。如“民警的施救是科学的,贸然下水救人反而会刺激轻生者”“支持人民警察”等。
另一方面,在情感极性为负面的评论中,关键词则主要包括“围观”“救”“目睹”等。比起正面情绪评论,舆情事件中的负面情绪更应引起政府有关部门的重点关注。因为一旦发酵,网民情绪很可能会将矛盾引向线下,甚至形成“蝴蝶效应”影响其他事件。鉴于此,图6为政府有关部门及时掌握网民诉求、稳定网络社会安定提供了突破口。产生这些负面情绪的原因主要包括三个方面:第一,对于施救现场警察在岸边不下水的行为,网民认为这是不作为的表现,相关部门未尽到职责;第二,对于少女轻生现象,网民们表示对溺水事件的悲哀和对生命的敬畏;第三,网友认为民警救援时应携救生衣、救生圈等装备。
基于上述原因分析,相关部门应在未来加强以下几方面的管理:首先,各部门应加强应急预案准备工作,并提升自身职业技能,切实履行自身职责。其次,定期邀请专家学者、社会媒体等各方面力量,定期研讨舆情事件,协助政府有关部门做好网络舆情治理工作。最后,在舆情事件发生后,政府应及时组织调查力量介入,第一时间发布通告和公开视频资料,帮助网民掌握事件全貌,澄清谣言和不实言论。
5 结 论
针对掺杂有反讽语义的舆情评论情感识别,本文提出了一种协同双向编码表征模型。通过组合两个普通双向编码表征模型,将反讽/非反讽、正面/负面两种领域的语义信息进行合并,用反讽识别信息指导正负语义信息的理解。进一步,与普通双向编码表征模型和Text-LSTM等深度学习模型进行对比,实验结果证明:在处理掺杂有反讽语义的舆情评论文本情感分析任务时,协同双向编码表征模型具备更好的性能,可为相关部门进行舆情管控提供更加精准的决策支持。
