一种基于改进稠密卷积神经网络的表情识别方法
2022-05-12戴沁璇罗晓曙蒙志明黄苑琴
戴沁璇,罗晓曙,蒙志明,黄苑琴
(1.广西师范大学 电子工程学院,广西 桂林 541000;2.广西师范大学 创新创业学院,广西 桂林 541000)
0 引 言
人脸表情识别(Facial Expression Recognition,FER)是指从给定的静态图像或动态视频序列中分离特定的表情状态,以确定所识别对象的心理状态与情感。文献[1]的研究结果表明,人们日常交流中55%的信息是通过不同的人脸表情传达的,而只有7%的信息是通过语言传达的。人脸表情是传达人类情感和意图最有效、最自然和最常见的信号之一。
随着科学研究的蓬勃发展,特别是近年来人工智能的快速发展,人们希望机器能够相对准确地识别人脸表情。随着近年来计算机和网络技术的发展,海量图像数据可以通过计算机更好地存储、传输和处理,为人脸的表情识别提供了基础。人脸表情识别技术应用广泛,例如疲劳驾驶检测、安全监控器、教学监视和测谎仪检测等。
人脸表情识别包括三个部分:人脸检测、特征提取和表情识别。人脸检测是通过诸如眼睛、鼻子和嘴巴等关键点定位图像中人脸的位置,例如文献[11]提出的类似Haar 特征提取的AdaBoost 级联分类器。在机器学习算法中有手工提取特征的方法,例如:局部二进制模式和Gabor等。在特征提取后应采用分类方法进行人脸表情识别,例如支持向量机(SVM)、随机森林、稀疏编码、神经网络等。尽管这些方法在特定领域取得了巨大成功,但是大多数方法只能获得底层的功能,而不能获得高级语义。
为了克服上述缺点,采用卷积神经网络(Convolu⁃tional Neural Network,CNN)是识别人脸表情的一种非常有效的方法。因为卷积神经网络可以同时执行特征提取和分类过程,并且可以从数据中自动发现多级表示。因此,近年来提出了一些性能优异的卷积神经网络结构应用于表情识别。例如文献[16]提出一种深度神经网络体系结构来解决面部表情识别问题,并通过多个标准面部数据集验证所提出的结构。文献[17]提出了一种基于三个最先进的面部检测器的集成方法。文献[18]提出了一种基于轻量级卷积神经网络的表情识别方法。
在上述研究工作的启发下,本文提出了一种基于改进的稠密卷积神经网络的表情识别方法,改进了卷积层的初始化方法,并且在激活层中提出了一种新型激活函数,同时改进了稠密CNN 框架,最后在表情识别系统上得到验证。
1 基于改进卷积神经网络的人脸表情识别模型
1.1 卷积层初始化方法的改进
本文首先预先设计了一个基于Gabor 的改进滤波器库,然后在训练网络模型之前,使用该库中的Gabor滤波器初始化改进神经网络基本属性的第一层。Gabor函数是一个用于边缘提取的线性滤波器,用于各种计算机视觉应用,例如边缘检测和纹理分析。类似于人类视觉系统,从Gabor 滤波器中创建一个滤波器组,如果发生变化,它会响应频率和方向。空间域中的Gabor 滤波器是由复杂的两分量Gabor 函数产生的,这两个分量是高斯函数和正弦平面波函数。式(1)给出了这种Gabor函数的计算公式:
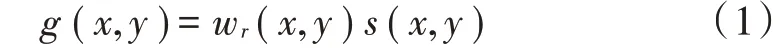
式中:w(,)和(,)分别是高斯函数和正弦函数。要将式(1)中的Gabor 函数转换为二维滤波器,可以按照式(2)重新构建Gabor 函数:
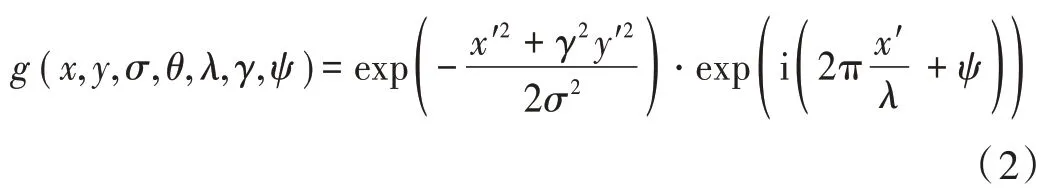
式中:是高斯函数的标准偏差;是Gabor 滤波器方向;是余弦函数的波长参数;是空间视图比率因子;是余弦函数的相位参数。
在本文提出的方法中,为第一层卷积层创建了一个Gabor 滤波器库,它代表了改进卷积神经网络的基本级别属性,库中创建的Gabor 滤波器的总数等于改进卷积神经网络第一层卷积层中的通道数(即特征图数)。由于本文使用的改进卷积神经网络的第一层卷积层具有24 个特征图,因此在库中总共生成了24 个Gabor 滤波器。创建的Gabor 滤波器所需的核心参数由表1 给出的取值范围确定,图1 是Gabor 滤波器的部分示例。
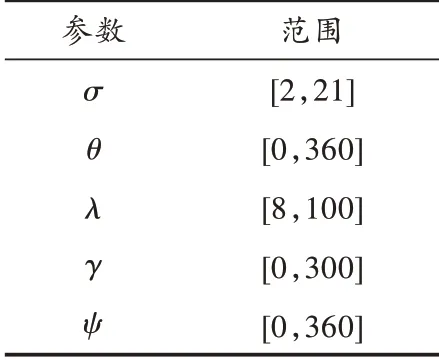
表1 Gabor 参数范围

图1 滤波的部分样例
在神经网络中对图像进行训练时,它们都倾向于学习第一层的特征,这些特征类似于Gabor 滤波器或色块。因此,在本文提出的方法中,使用预先生成的Gabor 滤波器对网络进行初始化,然后在改进模型中,用CK+、FER2013 和FER2013Plus 三个数据集进行训练。
1.2 激活函数优化
卷积神经网络中常用的激活函数包括Sigmoid、ReLU 函数等。Sigmoid 函数虽然处处连续便于求导,而且便于数据前向传输,但是在其趋向无穷大时,函数值变化很小,容易缺失梯度,不利于深层神经网络的误差反向传播,所以Sigmoid 函数梯度下降法训练网络时容易出现梯度消失现象。ReLU 函数计算复杂度低,不需要进行指数运算,而且适合用于误差反向传播,但是ReLU 函数的输出不是零中心的,而且在<0 时梯度为0,这样就会导致负的梯度被置零,那么这个神经元就有可能不会被激活。
因此,基于上述问题,本文提出了一种对数线性函数(Logarithmic Linear Unit,LLU),其表达式如式(3)所示,函数曲线如图2 所示。
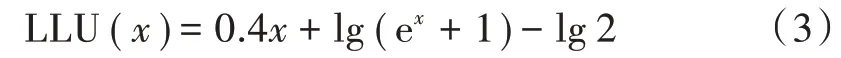
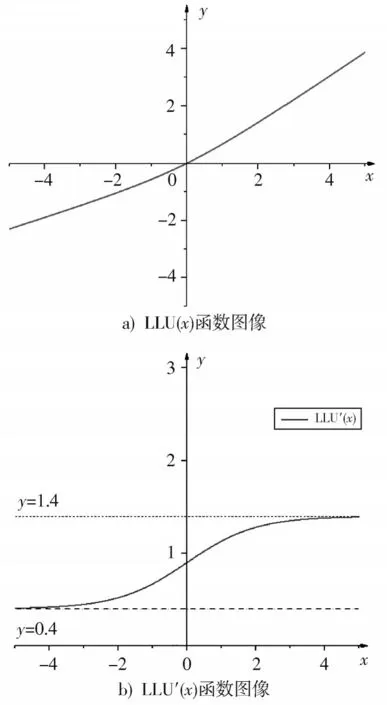
图2 对数线性函数曲线
根据LLU()表达式和图2a)可知,LLU()满足激活函数的五个基本属性:
1)非线性。LLU()函数是非线性的,可以在CNN中的非线性映射中发挥很好的作用。
2)可微性。此属性是必需的,LLU()的一阶导数如式(4)所示,因此可以使用基于梯度的训练方法。
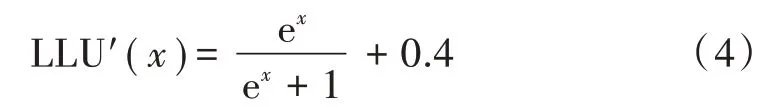
3)单调性。从LLU()>0 可以看出,LLU()是单调递增的函数,可以保证CNN 中每一层网络都是凸函数。
4)≈。当>0 时,LLU()满足此条件,参数的初始化是一个很小的随机值,对神经网络的训练将是有效的。
5)输出值是无限的。LLU()的输出值是无限的。当以较小的学习速度训练模型时,可以获得较高的训练效率。
对LLU′()函数求极限可知,当趋于负无穷大和正无穷大时,极限分别为0.4 和1.4。从图2b)所示的LLU′()图像可以看出,当太小时,它将不会为0;而当太大时,其值将接近1.4。因此在CNN 中采用LLU()激活函数可以进行有效的梯度下降训练。
1.3 稠密面部表情神经网络
稠密卷积神经网络(DenseNet)具有独特架构,它通过密集的连接模式和许多降维层最大限度地使训练参数最小化。密集连接主要由密集块和过渡层组成,前者定义输入和输出之间的连接关系,后者控制通道数。
稠密神经网络中有两个关键的超参数:增长率和稠密块数。增长率表示卷积层过滤器的数量,它决定了特征图的增长速率,例如,框架中有个卷积层,当具有个通道的数据进入这些卷积层时,则第个卷积层将具有+(-1)个输入特征图。为了更好地理解稠密网络结构,并且能够灵活地调整超参数,本文在稠密卷积神经网络中设立了另一个超参数密集块。
本文使用的稠密卷积神经网络包含49 个卷积层、4 个池化层和1 个Softmax 层。输入为48×48 的灰度图像,然后经过3×3 卷积层,3×3 卷积层采用1.1 节所述的Gabor 滤波器实现卷积层初始化。随后设计了4 个密集块,每个块包含12 个卷积层。过渡层连接在每个密集块的末端,由平均池化层、瓶颈层和压缩层组成。最后,根据不同的目标类别,连接7 类Softmax 层或10 类Softmax 层作为最终输出层,输出识别结果如图3 所示。
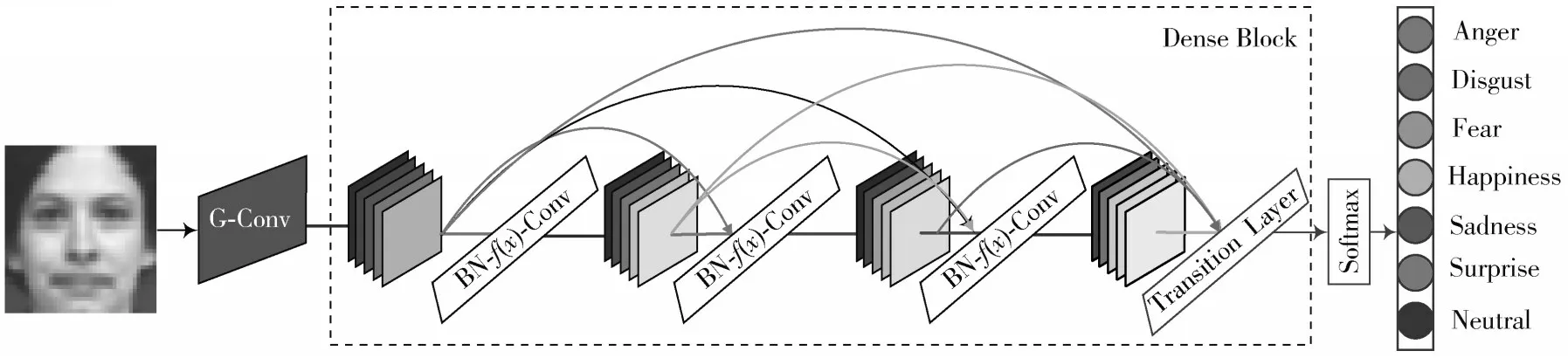
图3 改进的稠密面部表情神经网络模型
激活函数和批量归一化也包括在卷积层中,其中激活函数为式(3)的LLU()。与ReLU 和Sigmoid 相比,LLU()不会屏蔽轴负半轴的信号,信号按一定比例保留,不会造成信号为负值时某些特征损失,并且不会像Sigmoid 函数一样出现梯度消失。批量归一化的目的是确保每一层的输入均具有零均值和单位方差,它加快了网络的训练速度。
卷积层中的广义计算如式(5)~式(8)所示:
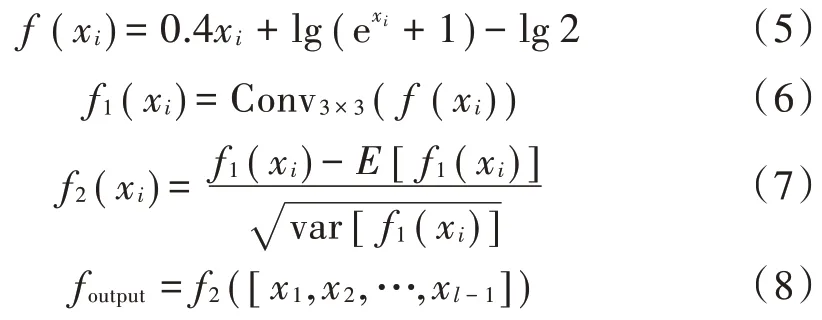
式中:(x)是本文提出的对数线性函数LLU();(x)是卷积计算函数,卷积核为3×3 大小;(x)是批量归一化函数,x是输入图像中每个像素的值;Conv 表示卷积;是期望值;var 是方差;[]中的数据是三维矩阵。
2 实验结果
2.1 实验环境和数据集
由于在模型训练中需要进行卷积计算,相对于CPU而言,GPU 的运用将极大地缩短训练时间,加快训练速度。本实验中使用的计算机配置是双E5⁃2637 v4 CPU,操作系统为Ubuntu 16.04,同时还使用了GTX1080Ti 显卡、12 GB 内存来加速训练;使用的平台是Google 开发的机器学习框架Tensorflow 1.9.0。
本文使用CK+、FER2013 和FER2013Plus 这三种数据集。CK+数据集在Cohn⁃Kanade 数据集的基础上进行了扩展,并于2010 年发布,该数据集包含123 个对象和593个图像序列。每个图像序列的最后一帧都有一个动作单元标签。在593 个图像序列中,有327 个序列具有情感标签。图4 是CK+数据集的示例。

图4 CK+数据集示例
FER2013数据集包含35 887个不同的图像。训练集包含28 709 个示例,公共测试集包含3 589 个示例,私有测试集包括3 589 个示例,这些数据集由48×48 像素的面部灰度图像组成。该数据集中标记了7 个表情:中立、快乐、悲伤、惊奇、愤怒、厌恶和恐惧。FER2013 数据集的一些示例如图5 所示。

图5 FER2013 数据集示例
FER2013Plus是FER2013 的升级版本,此版本中的表情分为10个类别,并采用多标签分类。与FER2013数据集相比多了轻视、未知和不是人脸这三个类别。
2.2 训练结果
2.2.1 CK+数据集中的结果
在数据扩充方面,使用标准的10⁃crop 方法进行数据扩充,即在每个图像周围添加零值的4行或4列,然后截取左上、右上、左下、右下和中间5 个图块,镜像翻转将数量翻至10 个图块。与使用包含数十万甚至数百万个大规模参数的ResNet 和AlexNet 这类模型相比,本文模型只有7.2×10个可训练参数。
图6显示了CK+数据集在本文提出模型上的训练曲线,以及与利用ResNet和AlexNet模型训练的比较结果。
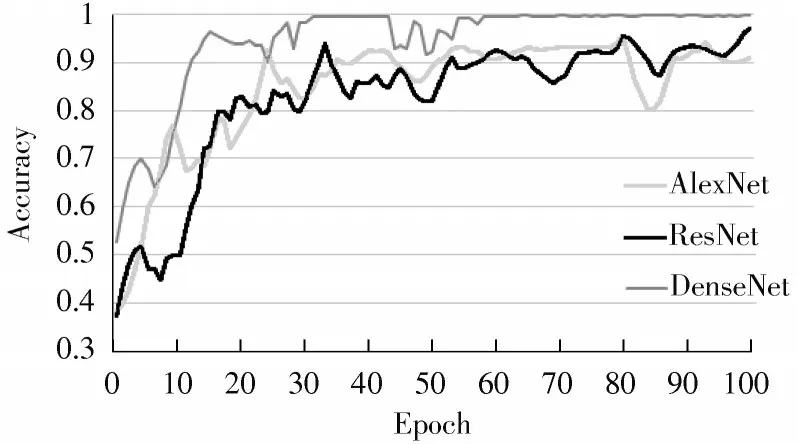
图6 CK+数据集在三种模型上的训练曲线
从图6 可以看出,经过100 个epoch 的训练,本文模型准确率可以达到99.78%,具有更好的泛化能力,相比ResNet 和AlexNet 两个网络训练的结果都要好。
2.2.2 FER2013 和FER2013Plus 数据集中的结果
图7 和图8 分别显示了FER2013 和FER2013Plus 数据集的训练曲线。结果表明:这两个数据集在本文提出模型上的准确率分别为70.78%和85.43%。FER2013 数据集在ResNet 和AlexNet 的准确率分别为67.82%和68.02%,与这两个模型相比,本文提出的模型具有更高的表情识别准确率。
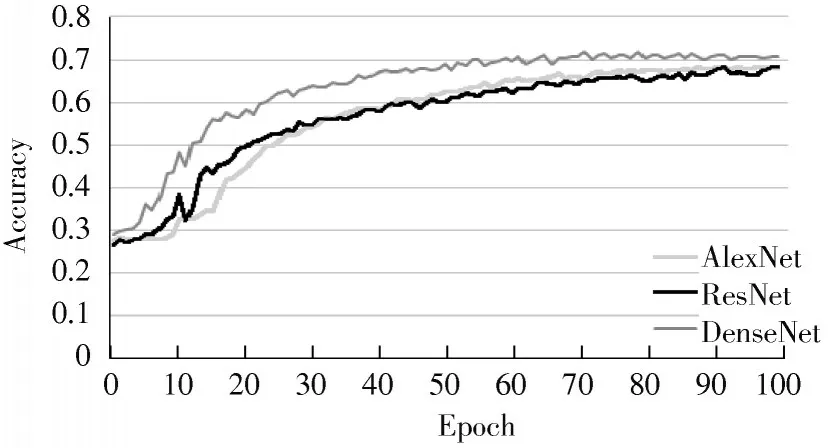
图7 FER2013 数据集在三种模型上的训练曲线
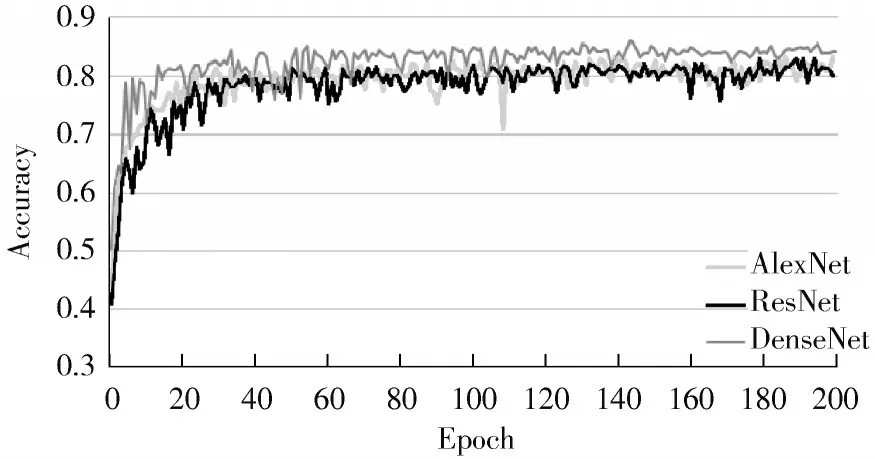
图8 FER2013Plus 数据集在三种模型上的训练曲线
在文献[23]中,FER2013Plus 使用众包提高标签的准确率,并设计了4 种方法来解决目标函数的问题。本文仅将多数表决方法用于预处理。在FER2013Plus 数据集上,ResNet 和AlexNet 的准确率分别为83.17%和81.36%。与ResNet 相比,本文提出的模型表情识别准确率提高了2%以上;与AlexNet 网络相比,本文提出的模型表情识别准确率提高了4%以上。
2.2.3 人脸表情系统设计
为了探索人脸表情识别在实际场景中的应用,基于本文模型构建了人脸表情识别系统。这个系统能够实现两个功能:其一可以识别图片上的面部表情;其二可以实时识别面部表情。在功能一中,首先将预先准备好的图片导入系统,系统获取图片并进行人脸检测,然后分析人脸上的面部表情,最后显示图像上的人脸属于哪一类表情。在功能二中,系统首先通过摄像头捕获人脸,然后循环捕获人脸图像帧并进行人脸检测,最后输出当前的人脸表情,从而实现人脸表情的实时识别。图9 为表情系统结构设计框图。图10显示了图像识别功能,包括单人图像和多人图像的识别。图11显示了实时识别结果。
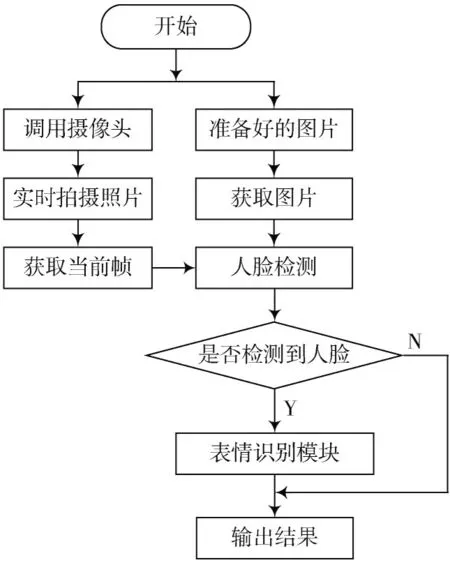
图9 面部表情识别系统结构设计框图

图10 识别单人图像和多人图像

图11 实时识别面部表情
3 结 语
本文提出了一种基于改进的稠密卷积神经网络的表情识别方法。该方法首先采用Gabor滤波器初始化卷积层,然后提出一种新型激活函数对数线性函数LLU()与稠密卷积神经网络相结合的模型。实验结果表明,该模型与现有的ResNet 和AlexNet 模型相比,不仅具有更少的参数,而且其表情识别率有明显提高。最后,设计了一个人脸表情识别系统,不仅能实现静态图像的表情识别,而且能实时识别摄像头采集的视频表情,具有一定的表情识别应用价值。
注:本文通讯作者为罗晓曙。
