道路交通模糊图像多尺度清晰化复原方法研究
2022-05-12范晋卿文成林
吴 兰,范晋卿,文成林
(1.河南工业大学 电气工程学院,河南 郑州 450001;2.广东石油化工学院 自动化学院,广东 茂名 525000)
0 引 言
近些年科技的不断发展使人们逐步进入智能化时代,智慧交通的出现为城市发展增添了新的活力,然而智慧交通中道路交通监控图像由于成像距离、成像设备分辨率、相机抖动等因素的影响,图像在获取的过程往往发生退化,也就导致图像模糊的发生。其中最常见的当属运动模糊,严重限制了交通成像和交通监控等领域的发展,这给道路交通管理带来极大不便,因此对道路交通模糊图像进行复原显得格外重要。
日常生活中模糊图像的模糊核往往是未知的,只能基于退化图像的一些先验信息,使用数学模型对原始图像进行最优估计,这种复原方法称为盲复原。文献[4]基于Hough 变换原理估计离焦模糊图像的模糊核半径的方法,能够有效应用在图像复原的参数估计中,然而该方法仅在信噪比低的图像中能得到理想效果。文献[5]提出了一种借助强大的TV⁃L1 模型即可同时估计物体运动光流场和模糊核,但是内容相对不丰富的图像复原效果往往不好。文献[6]基于交替最大后验(Maximum A Posteriori,MAP)估计框架下,利用低秩先验约束对模糊图像分步迭代进行盲去卷积,但是该方法步骤繁琐复杂且模糊核的估计往往不稳定。
近些年,深度学习因较强的学习和适应能力得到了较好的发展,卷积神经网络开始逐渐应用于图像处理领域,使图像复原的过程和结果得到了较大突破。文献[7]提出一种能够有效提取清晰图像强边缘的卷积神经网络,该模型包括抑制多余细节和增强恢复图像边缘两个阶段,能够快速高效地进行图像复原,但局限于均匀模糊图像。文献[8]提出DeblurGAN 的去模糊网络,使用生成对抗的思想并结合多重损失函数的端到端学习法,去除图像上因为物体运动而产生的模糊,由于结构简单,因此对于尺度较大的模糊图像复原细节较平滑。文献[9]采用尺度循环网络SRN 去模糊的思路,由粗到细设计不同分辨率的模型结构,该方法在非均匀的模糊数据集上有较好的复原结果,然而整体边缘复原效果往往不够理想。
目前,使用深度学习思想处理道路交通场景下的模糊图像相对较少,但该领域对智慧交通的发展意义重大。基于卷积神经网络浅层特征包含丰富的空间信息,深层特征包含丰富的语义信息,本文根据ResNet 的阶段性特征图谱搭建特征金字塔网络(Feature Pyramid Network,FPN),充分利用多尺度的特征映射,通过对特征金字塔的融合,提出了基于特征金字塔的道路交通模糊图像盲复原方法,并引入多尺度结构相似性损失函数作为生成器网络的约束项,进而稳定得到高质量的道路交通图像输出。
1 相关理论
1.1 生成对抗网络
生成对抗网络(Generative Adversarial Network,GAN)的基本网络模型如图1 所示,主要由生成模型和判别模型共同组成,刚一出现就在计算机视觉领域展现出强大的图像处理能力。生成器不断学习真实清晰图像的数据分布,负责将模糊图像生成相对清晰的图像(),判别器则判别送进来的图片是真实图片还是生成器生成的虚假图片,两个模型相互博弈共同学习,最终生成器的欺骗能力和判别器的鉴别能力都很强,此时达到平衡状态。
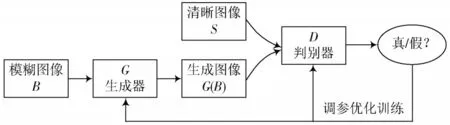
图1 生成对抗网络的基本模型
生成对抗网络在图像盲去模糊中,通常目标函数为:
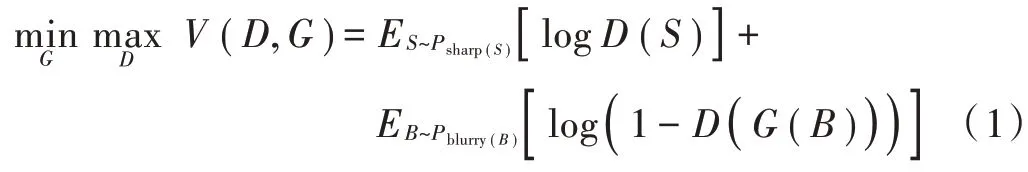
式中:为生成器;为判别器;表示期望;~表示清晰图像取自清晰图像数据集;~表示模糊图像取自模糊图像数据集。在固定生成器训练判别器时尽量最大化目标函数,固定判别器训练生成器时尽量最小化目标函数。
1.2 特征金字塔网络原理
利用网络对图片信息进行特征提取时,金字塔结构中不同次数的卷积处理就可以得到不同的特征层信息,图2 展示了不同类型的FPN 结构对比。
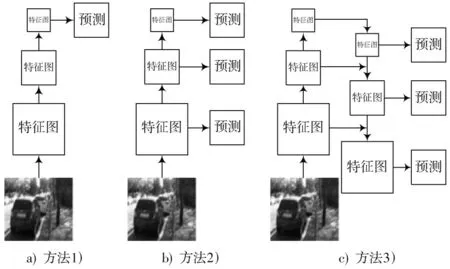
图2 三种不同的多维度特征组合方法
1)只用单一维度的图片作为输入,然后经CNN 模型处理后,仅采用网络的最后一层特征图作为最终的特征集。优点是计算简单,然而对图像中小物体细节信息检测的性能不是很好。
2)用单一维度的图片作为输入,针对目标需要从上到下将这些不同层次的特征简单合并起来用于最终的特征组合输出。然而让不同深度的特征图去学习同样的语义信息,往往没有用到足够低层的特征,因此获得的特征都是一些弱特征,鲁棒性较差。
3)输入一张模糊图像,基于先特征提取后特征上采样,最终进行特征融合的策略。根据不同尺度图像中底层特征具有高分辨率,高层特征具有多语义信息,改变网络的特征提取和融合策略,大幅度提升了模糊图片整体和细节的复原性能。
本文使用方法3)进行模糊图像清晰化复原。自上而下的过程是对更抽象、语义更强的高层特征图进行上采样,然后与自底向上具有相同尺寸的特征图横向连接操作,进而保证每一层预测的结果充分融合了高分辨率和强语义的特征,更加有利于图像清晰化复原。
2 网络模型
针对图像盲复原问题,基于生成对抗网络的思想,提出多尺度和多特征融合的特征金字塔去模糊方法,并且设计了多尺度鉴别器,整体的道路交通模糊图像盲复原网络结构如图3 所示。通过对多尺度特征金字塔生成器模块和多尺度判别器模块的交替训练,达到平衡点后输入模糊图像就可以对其进行清晰化复原。
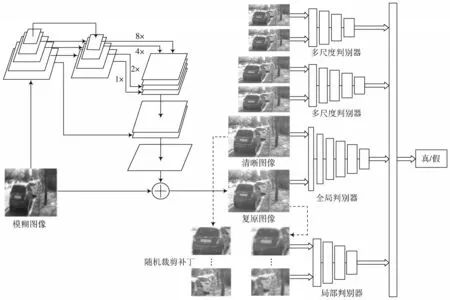
图3 整体网络结构图
2.1 多尺度特征金字塔生成器
多尺度特征金字塔构成的生成器网络如图4所示,分为特征提取和特征融合两个部分。使用ResNet⁃101模型对模糊图像进行多尺度特征提取,在网络前向传播计算过程中,图像依次经过ResNet⁃101 网络的Conv1_x,Conv2_x,Conv3_x,Conv4_x,Conv5_x 到达顶层,分别将不同等级的特征层记为,,,,,直接将作为特征金字塔的最上层,然后通过自上往下的方式进行上采样操作,每层上采样后分别与卷积层中,,相同尺寸的特征图进行融合,融合后的特征层记为,,,由于层的空间维度较高,为了不影响网络的搭建效率,故上采样过程中不使用该层。
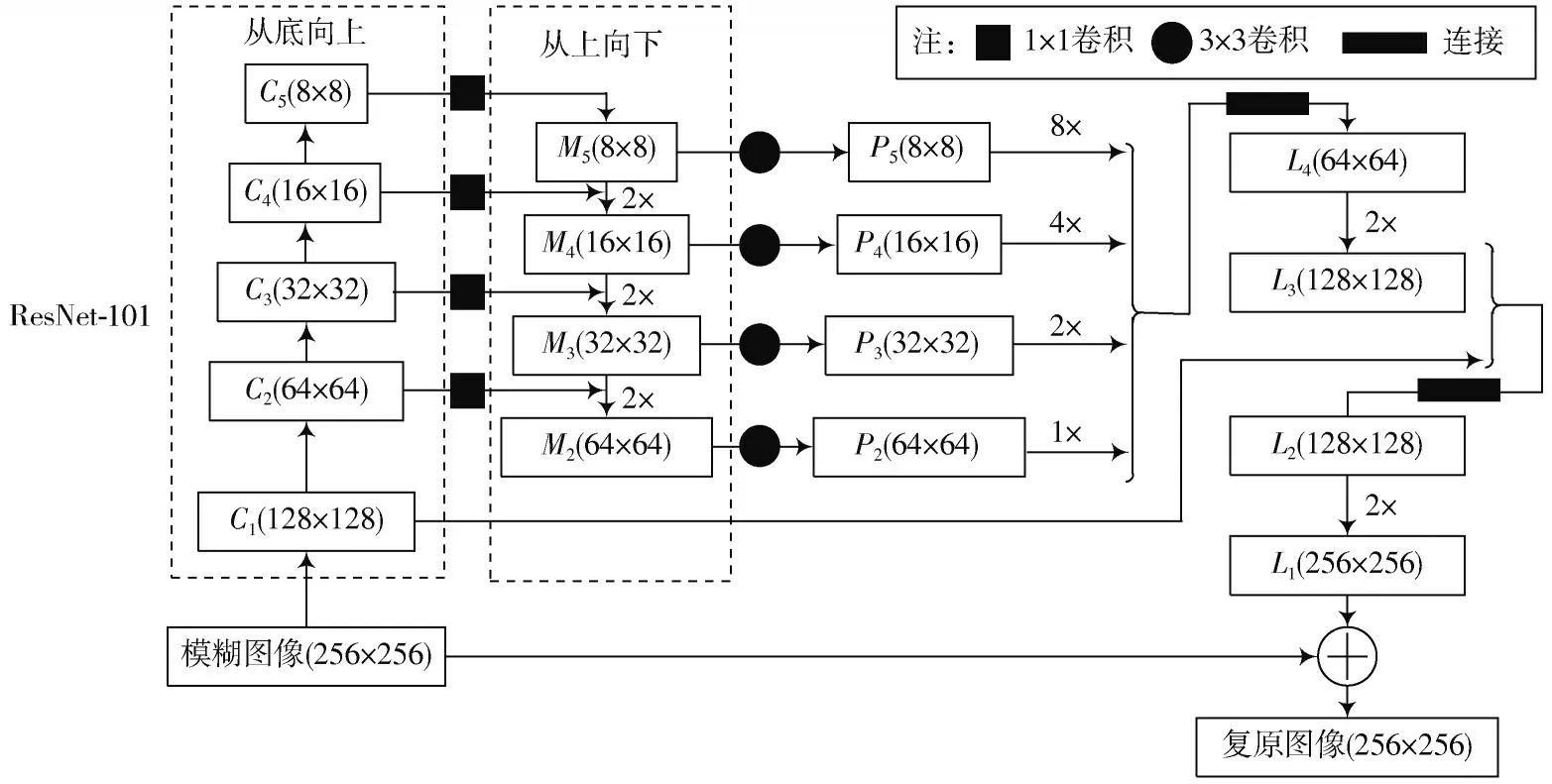
图4 特征金字塔生成器网络结构
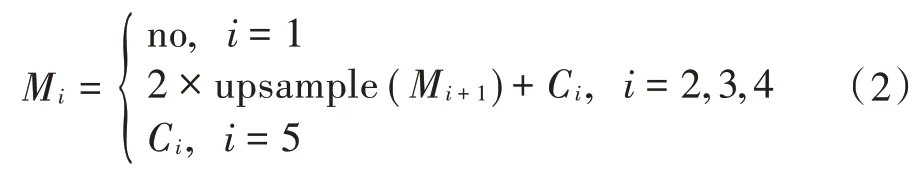
自下而上的路径是由不同尺寸的残差结构组成的模块,负责对图像进行特征提取。自上而下的路径将强语义信息的抽象特征和低层细节特征融合,通过将高层特征映射图2 倍上采样还原成与自下而上支路特征映射图对应的分辨率,并与其逐像素点相加,使得特征金字塔的每个特征层的输出都融合了不同尺度、不同语义强度的特征。这里1×1 的卷积核的主要作用是减少了Feature Map 的个数,并不改变其尺寸的大小。在特征金字塔提取的每个特征图后都附加一个3×3 的卷积以模拟抗混叠滤波器,使网络在训练中自适应地消除上采样带来的混叠效应影响。
特征提取后需要将5 个不同尺度的特征进行最终整合。首先将经过3×3 卷积后的,,,分别进行不同倍数的上采样,然后将相同分辨率的特征进行逐个元素相加、连接、合并得到,合并后的特征再次进行2 倍上采样得到。同理,相同尺寸的和逐个元素相加并2 倍上采样分别得到和。另外,在模糊图片和预测的输出结果间加入跳跃连接,最终使生成器模块更加精准地学习模糊和清晰图像之间的残差,输入模糊图像与残差之和为最终的复原图像。
2.2 多尺度判别器
多尺度判别器是基于卷积神经网络搭建的,网络结构如图5 所示。对于高度非均匀模糊图像,尤其是包含复杂目标运动的图像,全局判别器有助于判别器集成全空间256×256 图像上下文信息,而局部判别器对尺寸为64×64 的随机补丁进行操作,有助于判别器集成重要细节纹理的信息。另外,对原始清晰图像和生成器生成的图像分别进行2 倍和4 倍的下采样,训练两个多尺度判别器和,分别在128×128 和64×64 多个尺度上进行判别,更加严格地区分真实图像和生成图像,以帮助生成器提升性能,使复杂的模糊图像也能更加接近真实的复原。

图5 多尺度判别器网络结构
全局判别器是由6 个卷积块和1 个全连接层共同组成,中间4 个卷积块分别由卷积层、InstanceNorm 层和斜率为0.2 的LeakyReLU 激活函数组成,将整体图像压缩为256×256作为输入,以1 024维向量作为输出,使用5×5大小的卷积核,步长设置为2 来降低图像的分辨率。多尺度判别器和局部判别器的网络结构设置和全局判别器比较相似,对128×128 的图像对进行鉴别,因此使用5 个卷积层,和都是对64×64 的图像对进行鉴别,因此判别器网络结构相同,且卷积层的数量相应减少一层。全局判别器、多尺度判别器和局部判别器中网络细节参数如表1~表3 所示。
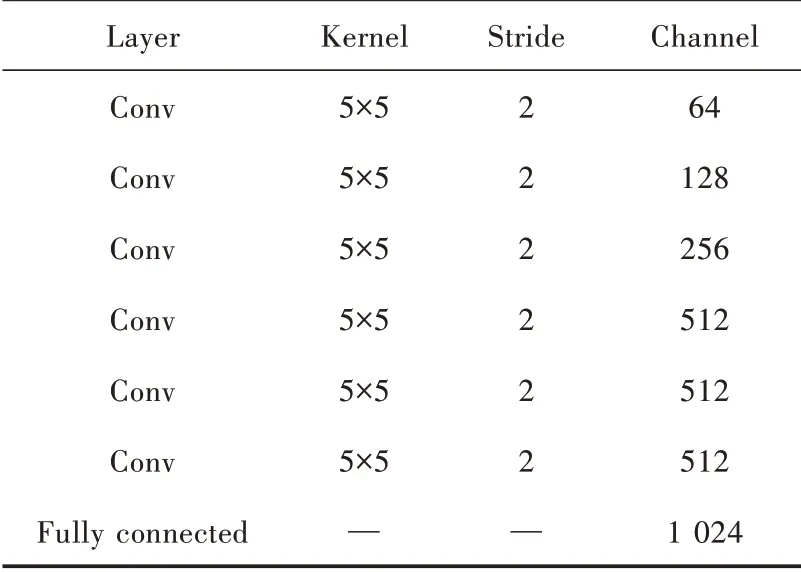
表1 全局判别器DG 参数
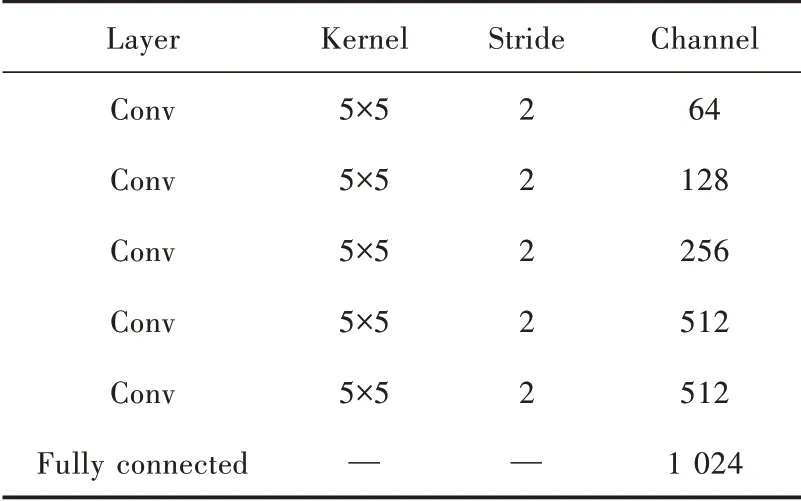
表2 多尺度判别器DM1 参数
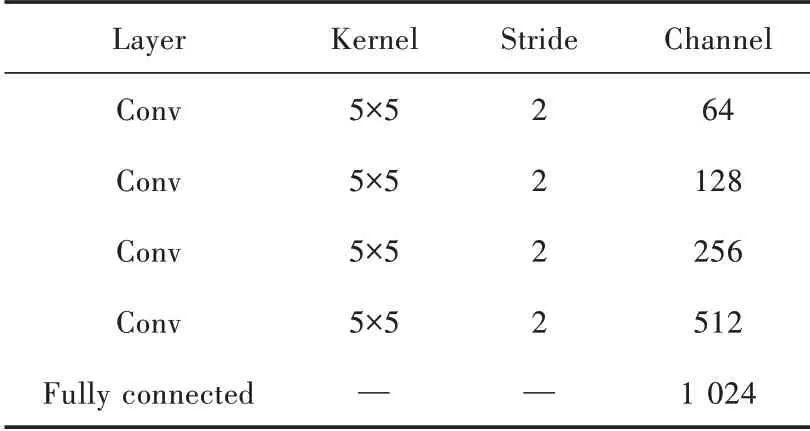
表3 多尺度判别器DM2 和局部判别器DL 参数
最终,将整体、局部图像以及不同分辨率下判别器的输出连在一起,即可得到2 048 维的向量,最终经过Sigmoid 激活函数输出0~1 之间的一个数值,就是该图像判别为真实图像的概率。
2.3 损失函数
损失函数部分由对抗损失、内容损失和多尺度结构相似性损失组成。对抗损失部分包含全局和局部的损失,全局表示整个图片的损失,局部则表示64×64 的局部图片的损失。使用感知损失代替内容损失函数,使用多尺度结构相似性损失倾向于产生和原始清晰图像相似的像素空间输出,和表示损失函数之间的权重,总体损失函数定义如下:
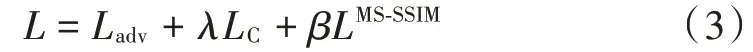
1)对抗损失
对抗式网络常用来生成高逼真的清晰图像,WGAN(Wasserstein GAN)模型使用Wasserstein⁃1距离(,)估计Jensen⁃Shannon 散度。对抗损失(多尺度和局部的损失)用梯度惩罚损失计算,定义评价函数为:
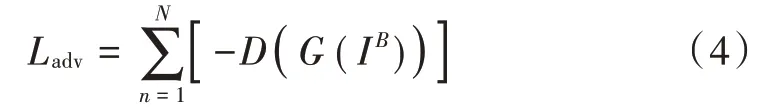
式中I为生成图片。
2)内容损失
内容损失主要用来衡量生成图像和原始清晰图像之间的距离,常使用(Mean Absolute Error,MAE)损失或者(Mean Square Error,MSE)损失。本文使用生成图像和目标图像CNN 特征图差异的正则化损失作为内容损失的计算形式,公式为:
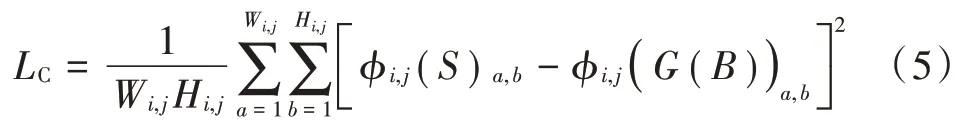
式中:φ为在VGG⁃19 网络中的第个最大层数之前的第个卷积(在激活函数之后)获得的特征图;W 和H为特征图的维度;为模糊图像;和为像素的位置。
3)多尺度结构相似性损失
原始GAN 在生成图像时是没有约束的,故生成器很容易失去训练方向,导致训练不稳定,因此引入多尺度结构相似性损失函数(Multi⁃Scale SSIM,MS⁃SSIM),除了综合考虑照明度、对比度、结构外,还额外考虑了分辨率这一主观因素,基于SSIM 的损失函数的定义为:
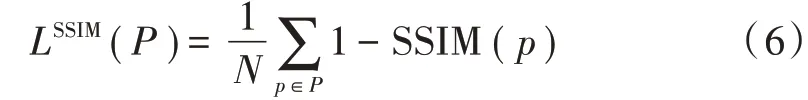
计算损失函数时,其实只用计算中央像素的损失,即:

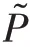
通过上述中央像素损失函数训练所得的卷积核,仍将应用于图像中的每个像素。同理,得MS⁃SSIM 的损失函数为:
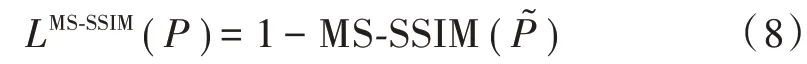
3 实验结果分析
3.1 实验设计
本实验在Linux 操作系统下基于TensorFlow深度学习框架下实现,计算机硬件环境为3.9 GHz 的i7 处理器台式机,NAVIDA GeForce RTX208TI,32 GB RAM。考虑到样本数据量比较小,初始学习率设为0.000 1,然后使用指数衰减法逐步减小学习率,衰减系数为0.3,使用ADAM 优化器对损失函数进行优化,将batchsize 设置为1,直到网络训练收敛为止,模型训练细节流程如图6 所示。
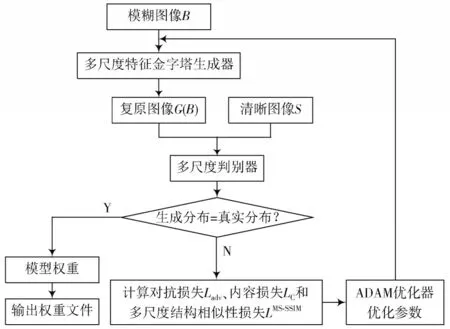
图6 特征金字塔图像去模糊训练过程
图像复原结果综合使用经典客观评价指标峰值信噪比(Peak Signal to Noise Ratio,PSNR)、结构相似性(Structural Similarity Index,SSIM)以及主观评价指标平均意见得分(Mean Opinion Score,MOS)对图像进行多方位评估。
1)峰值信噪比通过生成图像和真实图像对应像素点的均方误差(Mean Square Error,MSE)进行图像质量客观定义,其公式如下:
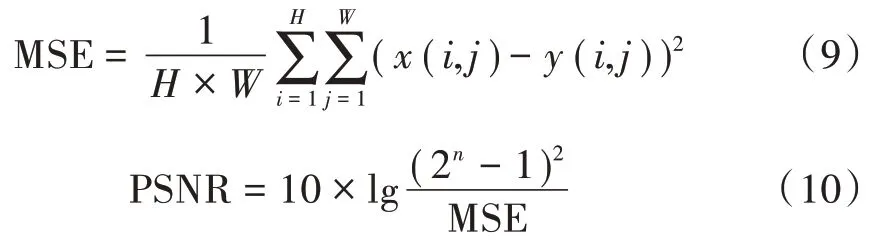
式中:为图像的高度;为图像的宽度;为每像素的比特数。PSNR 数值越大表示失真越小,即图像质量越高。
2)结构相似性分别从亮度、对比度和结构信息三方面整体度量图像的相似性,其公式如下:
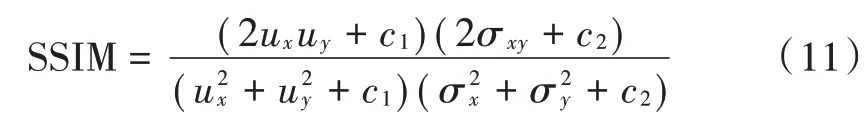
式中:u表示图像的均值;u表示图像的均值;σ表示图像的方差;σ表示图像的方差;σ表示图像和的协方差;,是用于维持稳定的常量。SSIM 取值范围在[0,1]之间,值越大代表生成图像与真实图像在结构上相似度更高,复原效果更好。
3)本实验还依据人眼的直观感知,使用平均意见得分(Mean Opinion Score,MOS)衡量图像的质量,基于16 个评分员来评价同一数据集不同场景下得到的复原图像,按照5 分制定义,分值从1~5 分别代表图像质量非常差、差、一般、好和非常好,不同复原结果得分先求和再取平均即为最终MOS 值。
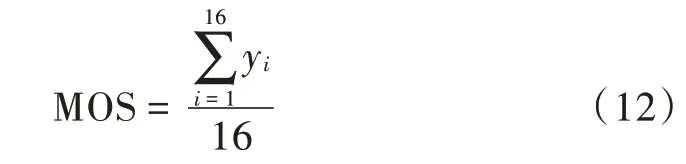
式中y表示每个评分员对图像质量的直观视觉打分。
3.2 实验对比及分析
GoPro 数据集是经典的模糊图像数据集,包含车辆、行人和街景等分辨率为720×1 280 的多个场景。由于目前公开能下载到的道路交通模糊图像数据集相对较少,为了能够更好地训练网络模型,从GoPro 数据集和网络图片库中共挑选收集整理了4 500 对道路交通数据集,每对数据集都包含清晰图像和与之对应的模糊图像。使用4 000 对用来训练,剩下的500 对用来测试,训练时将数据集剪裁为256×256 像素的图像块,测试时保持原来图片尺寸大小不变。
为了验证本文方法的有效性,首先使用预训练的YOLO模型进行目标检测,采用去模糊前后图像中物体被检测的概率来检验去模糊效果,如图7 所示。可以明显发现,经本文处理后的图像中被检测到的物体明显增多,间接证明在道路交通场景去模糊的有效性。

图7 去模糊前后目标检测对比图
为了对本文网络模型进行对比分析,使用收集的道路交通数据集与文献[8⁃9]模型的输出结果对比,见图8。使用的几种不同模糊复原方法的评价结果见表4。不同指标均值对比柱状图如图9 所示。

图8 实验结果对比图
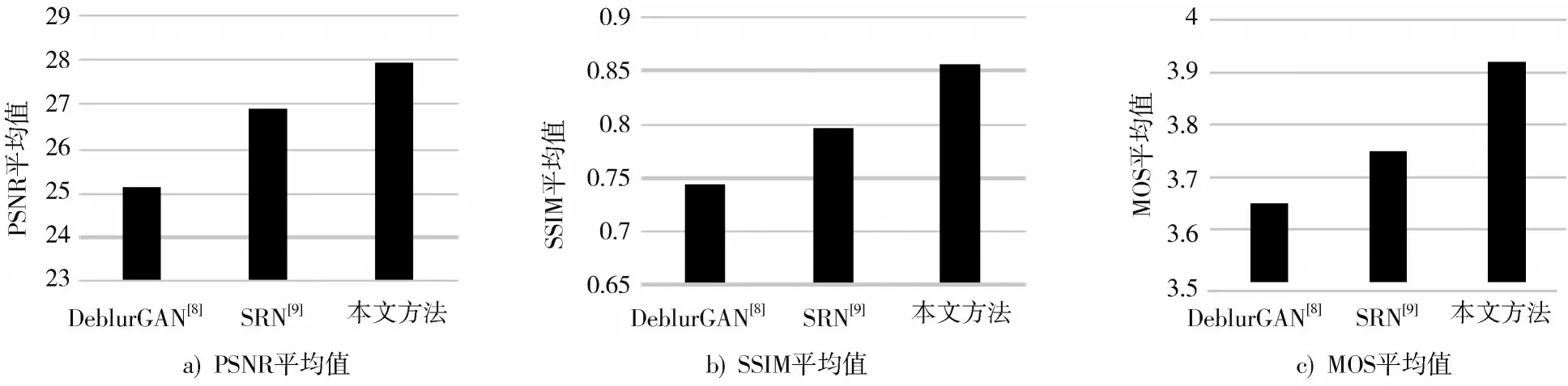
图9 实验结果不同指标对比图
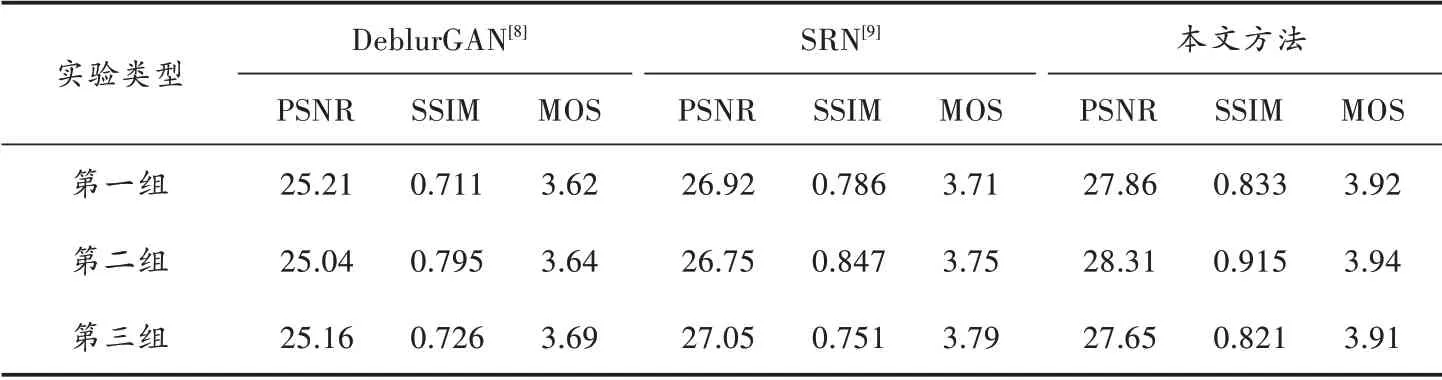
表4 图像质量评价结果
结果表明,本文算法模型在道路交通数据集上的去模糊效果比文献[8⁃9]在细节方面有较大提升,场景1 放大区域去模糊后的图像没有明显伪影存在,在去除模糊的同时还保存了清晰的边缘细节,场景2 和场景3 放大区域去模糊后明显发现车牌和车标文字内容得到较好复原,图像的局部细节和整体轮廓得到了较好的复原,然而其他两种方法得到的图像仍较为平滑。
从表4 和图9 可以发现:本文方法用在3 个测试集场景下都可得到较高的评价指标,相比于文献[8⁃9],PSNR 平均值分别提高了11.1%和3.8%;SSIM 平均值分别提高了15.1%和7.7%;MOS 平均值分别提高了7.4%和4.5%。稳定的复原效果很好地解决了道路交通模糊图像对城市智慧交通发展的影响。
4 结 语
本文以道路交通模糊图像为研究对象,在分析传统算法的缺点以及当今深度学习方法不足的基础上,设计了多尺度鉴别器,并加入了多尺度结构相似性损失函数,提出了一种多尺度和多特征融合的特征金字塔网络盲复原方法。实验结果表明,经本文方法处理后的图像在多项评价指标上都高于近些年的主流方法,能够较好地复原出细节和纹理清晰的高质量图像。未来工作的研究重点将集中在模型结构的简化设计上,确保道路交通模糊图像高质量复原的同时具有较高的效率。
