基于特征点预测的三维表情人脸合成
2022-05-11傅钰雯杨健晟
舒 文, 傅钰雯, 杨健晟
(1 贵州大学 电气工程学院, 贵阳 550025; 2 贵州交通职业技术学院, 贵阳 550025)
0 引 言
三维人脸表情合成在近年来得到了越来越多的关注,影视领域、仿人机器人、虚拟现实、三维游戏、三维人脸识别等多个领域都对三维表情人脸合成提出了更高的要求。
三维表情人脸的合成通常分为三维人脸重建与表情合成两个部分。 目前,三维人脸重建方法主要分为基于设备的三维人脸重建与基于图像的三维人脸重建。 基于设备的三维人脸重建利用高精度的三维扫描仪对人脸扫描,得到高质量三维人脸数据。但该方法具有成本高、采集时间较长、对采集过程中采集对象的姿态要求高等特点,使基于设备的方法通常仅在实验室中完成。 此外,基于设备的方法也由于采集的三维人脸数据仅为当前采集表情人脸的数据,在表情合成上难以完成多种不同表情的转换。 而基于图像的三维人脸重建由于其成本低、灵活度高等特点,得到了大量研究者的青睐。 由于重建模型本身点云数的不同从而引起了模型精细程度不同,也使基于模型方法的三维表情合成中,基于不同模型的方法重建效果区别较大。 目前,国内对于三维人脸表情的研究大部分通过FACS(Facial Action Coding System)表情编码系统与简单三维人脸模型的结合完成。 但由于部分模型自身点云过少所带来的模型细节表现较差问题,也使最终三维人脸表情合成效果较差。 而更多细节表现良好的参数化模型中,对于三维表情合成的研究较少。一方面,利用FACS 系统对模型进行改变时,并不如部份模型那样,能够通过较少的地标点改变而达到效果;另一方面,合成更多的是通过人为调整参数的方式进行表情的改变。
徐雪绒在单张正面照片的基础上,结合CANDIDE-3 与FACS,完成对人脸的重建与三维表情合成。 郭帅磊利用Kinect 体感设备,采集多张人脸彩色图像与深度图像,在此基础上结合FACS完成人脸表情的合成,相较于CANDIDE-3 模型最终使表现得到了改良,但灵活度较低,成本较高。Garrido提出了一种基于图像的人脸视频再现方法,对不同的两个面部表情视频进行比较匹配,能够在保留背景的前提下完成表情面部替换。 但该方法对数据集要求高、且仅完成面部替换,无法完成真正的三维表情合成。
在上述基础上,本文提出一种基于表情特征点预测的三维人脸表情合成方法。 其方法在自然表情人脸的基础上,对其它表情人脸特征点分布进行预测;利 用 预 测 特 征 点, 在3DMM (3D Morphable Model)的基础上,结合FaceWarehouse 三维人脸数据库发布的表情基,完成对表情人脸的三维重建,从而完成了三维人脸的表情合成。 文章通过基于表情特征点预测的三维人脸表情合成方法,完成了对快乐表情与悲伤表情下的重建。 重建方法仅需要一张正面自然表情人脸图像,就能够完成多表情下的人脸三维模型合成。
1 基于3DMM 的三维人脸重建
基于3DMM 的三维人脸重建方法对单幅图像中人脸的特征点进行标注,之后利用所标注的特征点,结合参数化模型Basel Face Model (BFM)进行人脸的三维重建。 方法在整个重建过程中仅需要一张人脸图像,这也使得基于3DMM 三维人脸重建方法灵活度非常高,其整体流程如图1 所示。
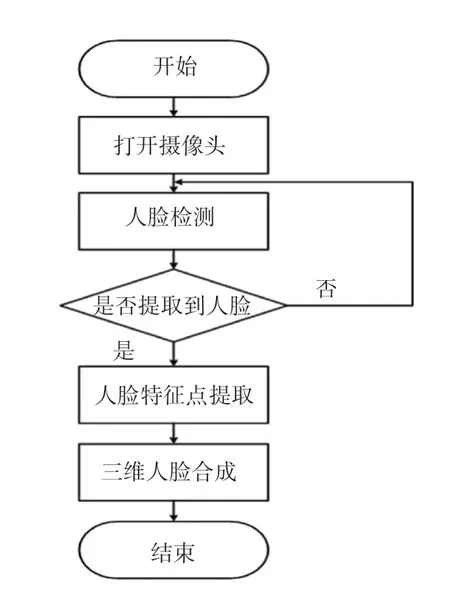
图1 三维人脸重建流程Fig.1 3D face reconstruction flow chart
在基于特征点的三维人脸重建中,首先要对图像中的人脸区域进行提取,再对人脸区域进行特征提取,最后利用三维人脸重建技术,结合提取的特征点完成人脸的三维重建。
人脸检测利用Adaboost 结合Haar 特征,在AFLW2000-3D 数据集的基础上,加入部分手动标记的生活人脸照片完成对新的数据集进行处理。将所有的图像处理为40*40 大小的灰度图像,其处理方法如式(1)所示:
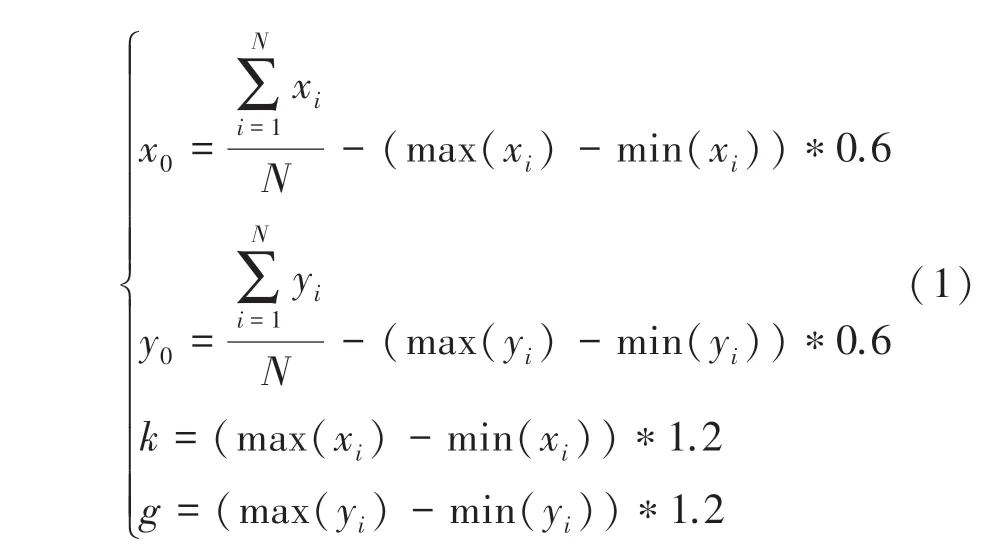
式中,(,) 为人脸区域中心点坐标,、分别为区域的宽和高。
经过处理后的部分样本图像如图2 所示。

图2 部分数据处理样例图Fig.2 Part of the data processing sample diagram
将预处理后得到的新数据集作为正样本数据集,利用无人脸的生活照与风景照等作为负样本,利用OpenCV 训练框架进行训练,最终模型人脸区域提取结果如图3 所示。

图3 人脸区域提取示意图Fig.3 Schematic diagram of face region extraction
特征点提取在ERT(Ensemble of Regression Trees)算法与ASM(Active Shape Models)算法基础上,分别进行了实验。 选用300 W 人脸数据集作为训练数据集,在AFLW2000 部分数据上进行测试,对ERT 下 的3 棵 GBDT (Gradient BoostingDecision Tree)树情况与ASM 分别进行了实验,得到结果如图4 所示。

图4 ASM 算法与ERT 算法对比图Fig.4 ASM algorithm and ERT algorithm comparison chart
由实验结果可见,ASM 算法相比ERT 算法而言,在特征点拟合上效果略差,在细节的拟合上ERT 更加的优秀。 选择在整个三维人脸重建上使用ERT 作为特征点提取方法。 后续对不同GBDT树木下的ERT 算法进行试验得到结果如图5 所示。

图5 ERT 不同树木算法对比图Fig.5 Comparison chart of ERT different tree algorithm
图5 中按照顺序分别是3 棵树、5 棵树、10 棵树、20 棵树下的特征点定位表现。 可以发现,随着树的增加其拟合效果也越来越好。 但是,树的增加带来了时效性的降低,而且在实验中10 棵树之后收敛效果有限。 综合考虑,最终采用10 棵树下的迭代模型作为特征点定位模型。
3DMM 是应用广泛的一种参数化模型重建方法,共利用三维人脸数据结合PCA(主成分分析法)建立了一个三维人脸的参数化模型。 参数化模型的搭建依赖于BFM 数据集,通过对数据集进行处理,模型得到了3*199 的特征向量矩阵。 其中,为BFM 数据集中每一张三维人脸的顶点数量,每一个顶点都有其对应的3 个三维坐标值与3 个RGB 纹理分量。 由于BFM 数据集缺少表情表达,利用FaceWarehouse 对3DMM 模型下的表情部分进行补足,得到带表情下的三维人脸重建模型:其3DMM参数化模型最终为:
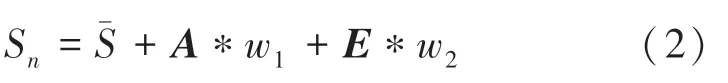
式中,S为改变后的模型;¯为归一化处理后的平均人脸(均人脸是平均中性人脸加上平均表情人脸后的分布);是BFM 模型中经过处理后的特征矩阵;是相对应的特征值(通过改变则能够得到不同的S分布);为表情向量矩阵;为其对应的特征值分布。
对应的3DMM 中的纹理模型为:

式中,T是改变后的纹理;¯是平均纹理;是经过处理过后的特征矩阵;是其相对应的特征值矩阵;改变就能够得到不同的纹理。
对AFLW2000 数据集下的部分图像进行三维人脸形状重建,其效果如图6 所示。

图6 部分图像三维人脸重建图Fig.6 Partial image 3D face reconstruction
2 基于表情特征点预测的三维人脸表情合成
为了建立同一张人脸中当前表情至其他表情的模型,需要先确定当前人脸表情,在此基础上建立自然表情人脸至高兴表情人脸与悲伤表情人脸下的特征点预测模型。 其整体流程如图7 所示。
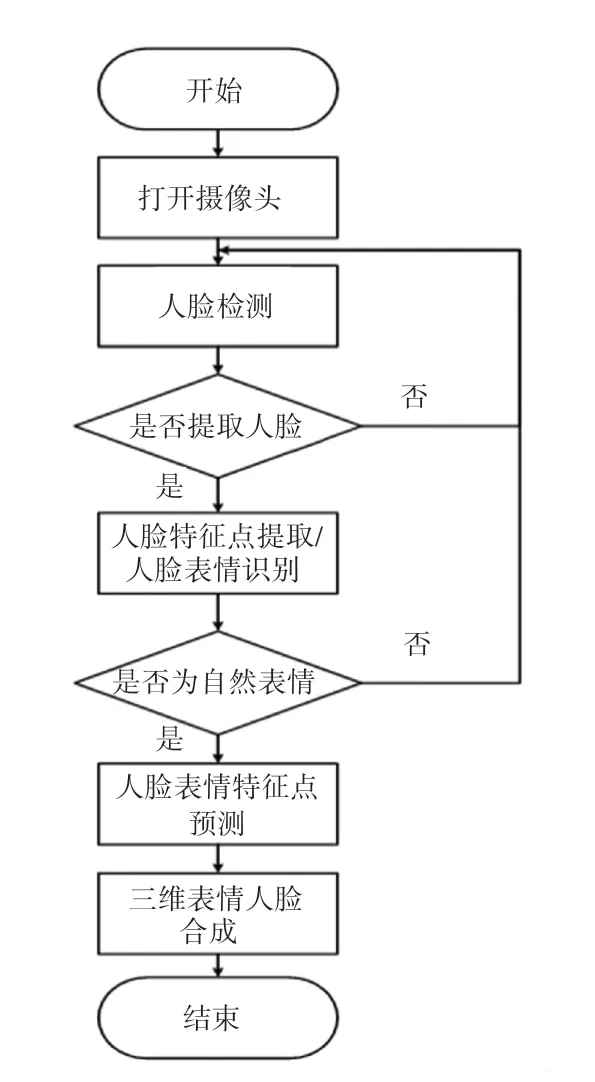
图7 整体流程图Fig.7 Overall flow chart
如图7 所示,文章在表情人脸的重建基础上,加入了表情识别与表情特征点分布预测。 通过引进这两个模块,从而完成了三维表情人脸的预测。
2.1 人脸表情识别
在当前应用较为广泛的算法中,基于卷积神经网络CNN(Convolutional Neural Networks)的表情识别得到了很多的应用。 然而,浅层CNN 在实际应用中精度仍有提高的空间。 在CNN 的基础上,牛津大学的视觉几何组与Google DeepMind 公司的研究员共同提出了一种深度卷积神经网络结构VGGNet(Very Deep Convolutional Networks)。 VGGNet 在很多图像处理应用中,效果相比CNN 更为优秀。 通过在fer2013 数据库的基础上加入了部分jaffe 数据库与ck+数据库数据作为训练及测试数据,在不同的数据集中VGGNet 与CNN 的对比结果见表1。
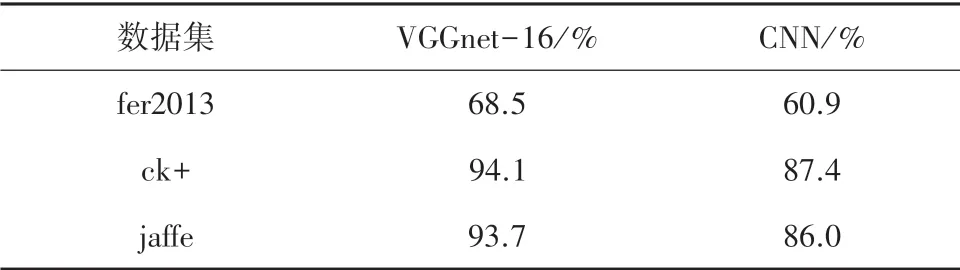
表1 不同算法对比表Tab.1 Comparison table of different algorithms
可以看到,在不同的数据集中VGGNet 较CNN拥有更高的识别率。 其中,fer2013 中识别率相对较低的原因是fer2013 数据库非常复杂,人眼对fer2013 的识别率也仅为65%左右。 综合判断下,VGGNet 模型在不同数据集中都有良好的识别效果。
由于最终目的是为了区分中性脸与表情脸,于是对表情脸识别率进行融合,最终对于表情识别中,中性脸与表情脸进行误检率与查准率的计算。 文中误检率是指表情脸被识别为中性脸的比例,而查准率是指中性脸被正确识别的比例。 在实验中,误检率越低则越好,也意味着越少表情脸被误判为中性脸,而查准率则越高越好。 其融合后的表现见表2。
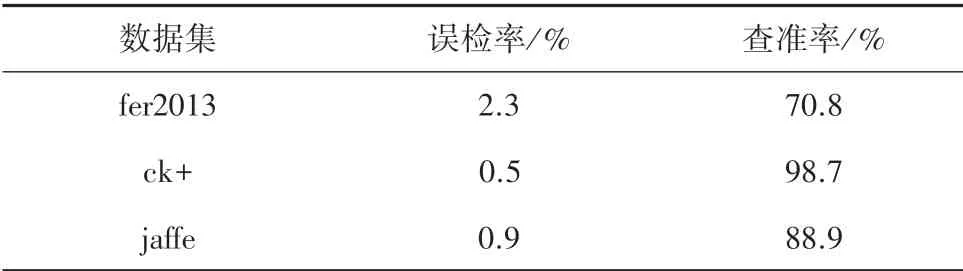
表2 融合后不同数据集验证表Tab.2 Verification table for different data sets after fusion
最终表情预测效果如图8 所示。

图8 表情预测效果示意图Fig.8 Schematic diagram of expression prediction effect
2.2 人脸表情特征点预测
特征点预测所采用的相关数据由ck+人脸数据库中得到。 在ck+人脸数据库中,共提供了包括中性脸在内的8 种表情,从其视频序列的表情库中,选取其中的中性脸与表情脸中的笑脸与悲伤脸,分类时利用ck+数据库提供的表情标签进行分类。
禅茶精品线路的设计:开发禅茶需要遵循以下原则:第一,坚持资源整合、优势共享的原则,借助庐山西海自身的资源优势,整合周边的佛教资源和茶文化资源来进行线路的设计;第二,坚持旅游线路主体化,让其成为以禅茶为主题的专题旅游线路。
在人脸表情特征点实际预测中,由于每一个人开心或悲伤时表情变化的程度难以量化(如从微笑到大笑都可属于开心的表情),所以在数据分类时,所有表情分类时都选择视频序列中由中性脸变为指定表情脸中的最终表情作为分类依据,从而最大程度上避免了由于表情程度不同带来的预测误差。
其中部分样本如图9 所示。

图9 CK+数据库部分样本示意图Fig.9 Schematic diagram of some samples of CK+database
人脸特征点提取中共完成了68 个特征点的提取,特征点分布于二维坐标系内,所以68 个特征点共产生了136 个输入。 对数据集中的部分样本特征点进行显示,红色为自然表情人脸特征点分布,黄色为对应的表情人脸特征点分布,其特征点分布图像如图10 所示。

图10 CK+部分数据特征点分布图Fig.10 Distribution map of CK+part of the data feature points
为了减小由于位置与角度带来的误差,文章对所有的人脸进行归一化处理,其归一化处理步骤如下:
(1)设两外眼角距离为、内眼角,计算其平均距离。 计算方法如下:

计算其缩放比例为:

式中,为缩放比例,100 为可修改的参数,表示将经过缩放变化到100 个像素的标准系下。 当像素标准系参数越小,缩放变换后的特征点分布越密集。
(2)通常认为正脸图片中两眼应当处于同一水平线,通过双眼眼角的偏移角来计算特征点分布的旋转角。特征点两个内眼角坐标分别为(,)、(,),其内眼角距离为,两点距离原点坐标分别为:
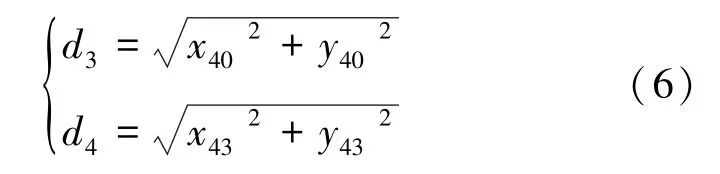
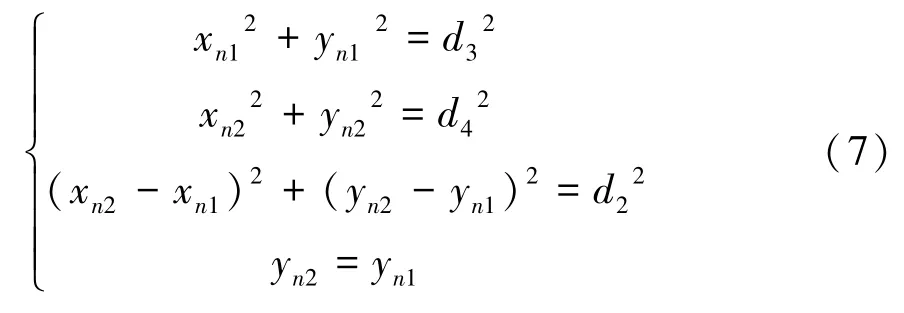
利用上式能够解出旋转后的新坐标,最终计算其旋转角为:
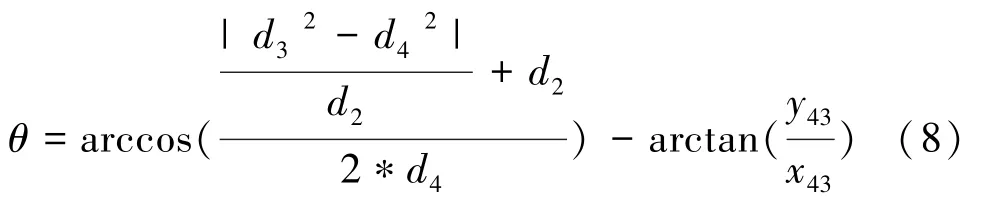
(3)在经过缩放与旋转后,将所有特征点平移至相同参考系之下,通过计算各个样本特征点轴与轴的平均坐标值,以平均点坐标为原点建立新的坐标系。 归一化缩放以及旋转公式为:
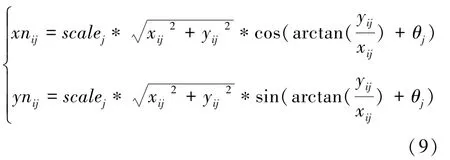
在与轴平移公式为:
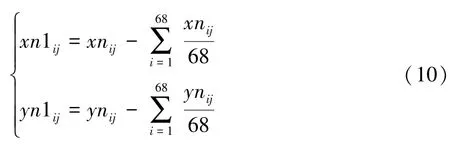
通过上述归一化后,将所有人脸特征点分布进行对齐,其对齐的人脸表情特征分布如图11 所示。

图11 部分数据特征点归一化图Fig.11 Normalized map of part of data feature points
归一化后对同一人的不同表情特征分布分析发现:在实际表情变化中,特征点位置的变化仅出现在部分位置。 如图11 中,(a)为开心人脸与中性人脸的特征点分布对比;(b)为悲伤人脸与中性表情人脸特征点分布对比。 两种表情中在表情变化时变化区域有所不同,而图12 中能够明显看出,在不同表情变化中,有很大一部分的特征点几乎没有变化,其中变化的只是一部分。 本文希望通过尽量少的特征点表示完整的人脸表情变化,于是对不同表情下的变化区域进行选取,选取方式为欧氏距离:
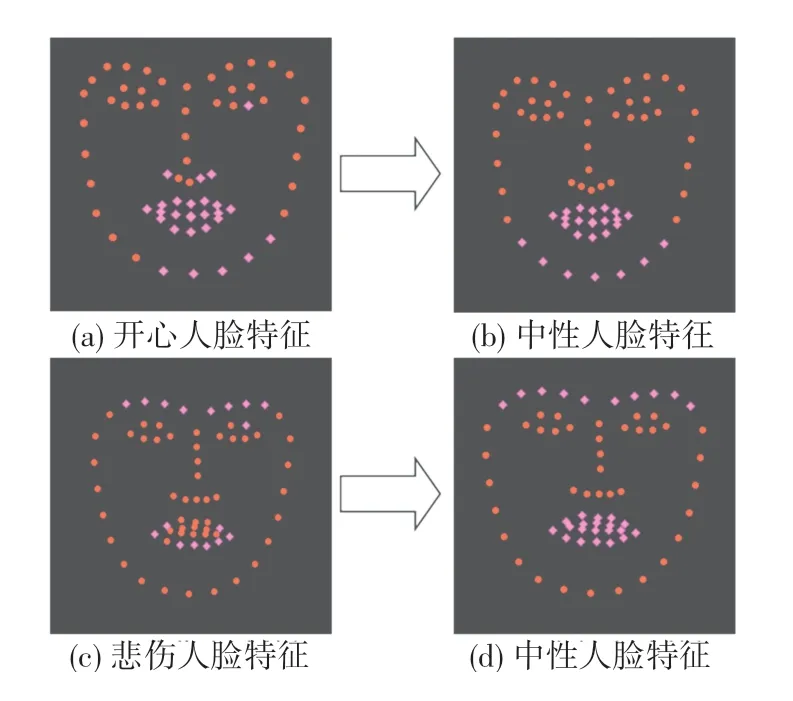
图12 不同表情下变化区域选择Fig.12 Selection of area under different expressions
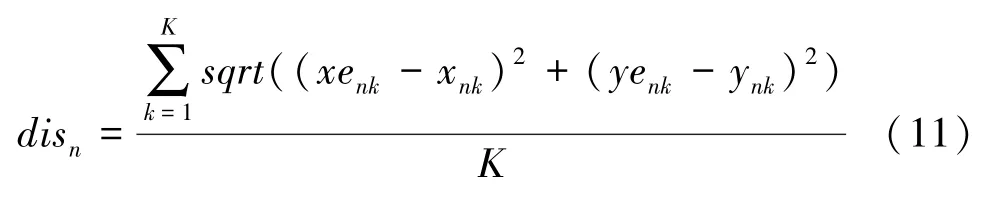
通过实验,人为选取欧式距离小于0.25 的点,得到在开心表情下变化的主要区域为嘴巴下颌,悲伤表情下变化的主要区域为嘴巴与眉毛。
针对不同表情选取出不同的变化区域与其对应的关键特征点后,利用神经网络与加权K 值最近邻算法,分别建立表情特征点预测模型。 最终效果如图13 所示。
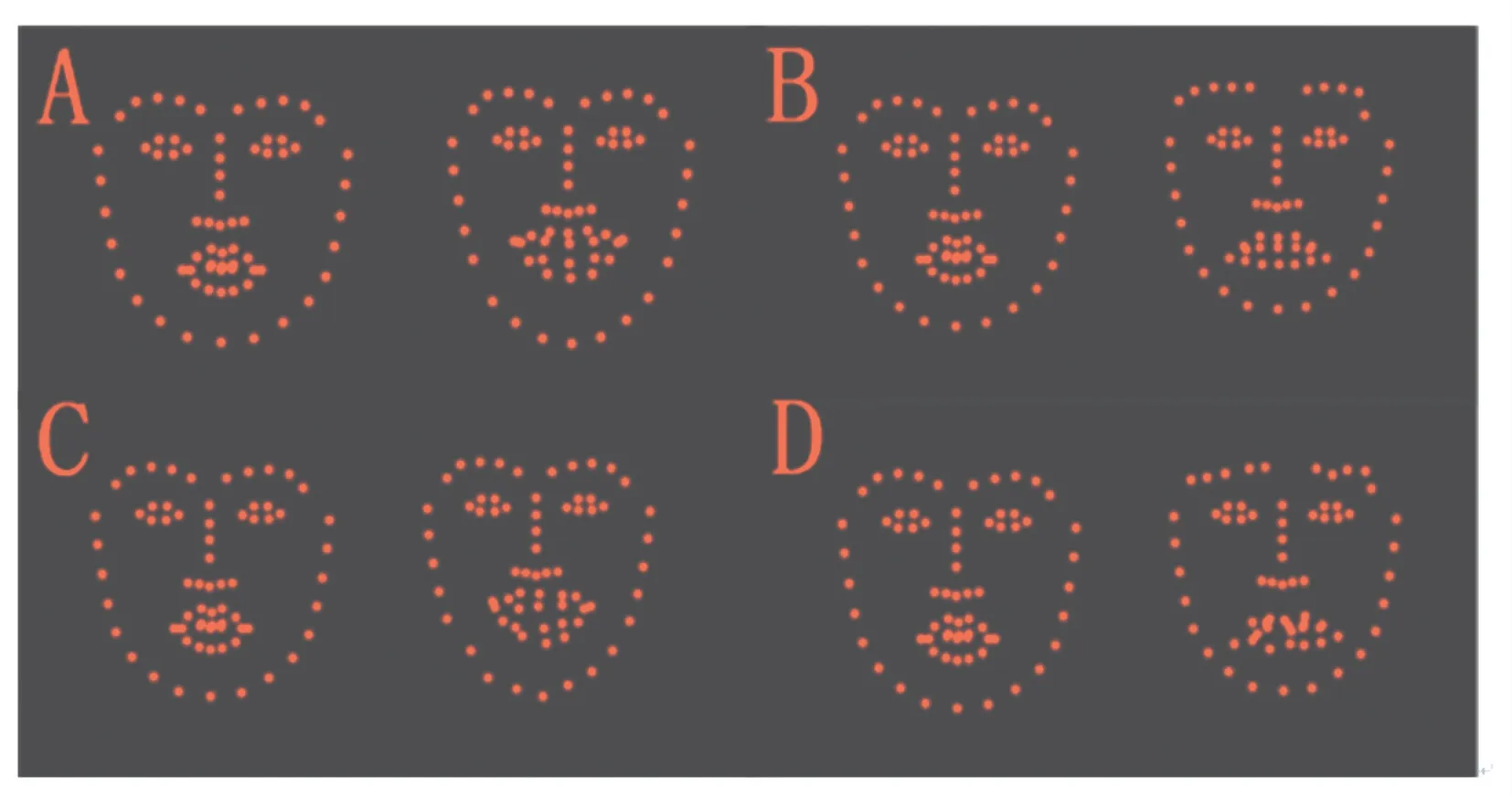
图13 不同算法下表情预测效果对比Fig.13 Comparison of expression prediction effects under different algorithms
图13 中,A、B 为加权K 值最近邻算法预测效果,C、D 为神经网络预测结果。 在真实感上能够看出,加权K 值最近邻算法预测效果要优于神经网络。 考虑是由于ck+数据集数据量不足导致。
2.3 基于特征点预测的三维表情重建
结合表情特征点预测与三维人脸重建,对三维表情模型进行预测,得到3 种表情下的三维人脸表情合成效果,如图14 所示。
图14 中,是利用特征点预测的方法结合三维人脸重建技术,达到了在仅有一张自然表情人脸的情况下,完成人脸其他表情下的三维人脸形状重建。
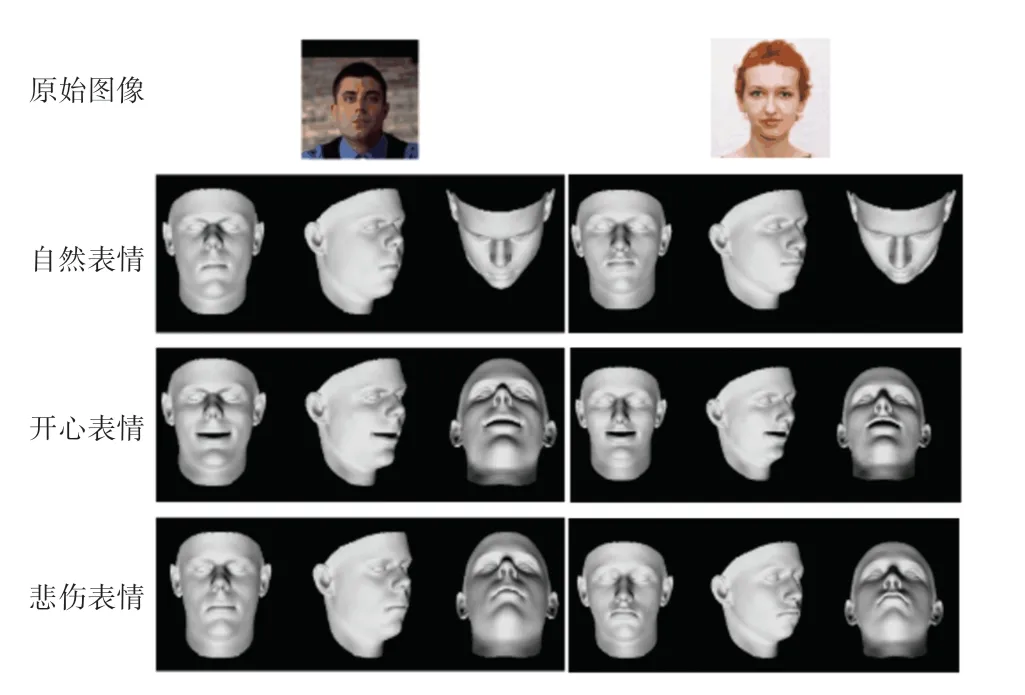
图14 三维人脸表情合成效果图Fig.14 3D facial expression synthesis rendering
在基于参数化模型的人脸重建中,由于参数化模型的纹理信息来自有限的人脸,在实际应用中与直接取得真实纹理相比,在真实感上仍然有着较大的欠缺。 然而,从二维图像中直接取得纹理时,受到图像人脸姿态影响较大,导致部分区域无法取得纹理时,会产生失真现象,如图15 所示。

图15 三维人脸真实纹理效果图Fig.15 3D face real texture renderings
如图15 所示,即便是正脸照片也存在部分遮挡带来的失真现象。 若当前姿态与正脸存在较大角度偏差时,情况会更加严重。 针对此种情况,本文提出了一种在耳部区域进行纹理逐步变换的方法,对纹理进行更新。 具体步骤如下:
(1)得到模型中耳朵的区域。
(2)对区域中的所有点,按照深度信息由低至高进行排序,即与鼻尖的深度距离远的点会排在靠后的位置。
(3)按照顺序对纹理进行更新。 更新时,利用原始参数化模型中纹理模型来进行。 记原始参数化模型中的平均纹理为,真实纹理模型纹理为,则有:
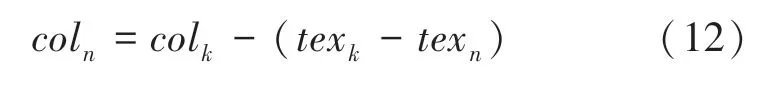
对纹理进行更新后,效果如图16 所示。
如图16 所示,经过纹理更新后失真的情况已经得到了改善。

图16 纹理更新图Fig.16 Texture update map
最终,本文方法与文献[22]中的Candide-3 模型结合FACS 系统算法进行对比,如图17 所示。

图17 表情合成算法对比图Fig.17 Comparison chart of expression synthesis algorithms
本文方法与其它表情合成与三维表情人脸建模方法比较结果见表3。

表3 不同算法对比Tab.3 Comparison of different algorithms
3 结束语
本文提出了一种基于特征点预测的三维表情人脸合成方法,实验表明,此方法相较于传统的单幅表情图像对应单个三维表情人脸方法更加的灵活;相较于人工调节表情参数的方法,实现了自动化合成;相较于candide-3 模型集合FACS 编码系统的方法,重建效果更加良好。
由于表情特征点预测对数据集依赖较大,未来可能会建立一个标准较为统一且数据量更大的表情数据集,也希望利用模型完成在拥有一副正脸图像的情况下,自动生成人脸对应的所有三维动画。
