航空发动机剩余使用寿命预测方法的融合与比较
2022-05-11宋海龙
黎 明, 宋海龙, 苟 江
(中电科航空电子有限公司, 成都 611731)
0 引 言
航空发动机系统属于高科技复杂系统,具有自动化程度高、结构复杂、专业化程度高的特点,其性能变化将直接影响飞机的安全运行。 发动机系统又因其造价高、使用频次高和保障费用高等特点,对安全性和可维护性等具有极高的要求。 基于复杂系统的可靠性、安全性、经济性考虑,对故障预测与健康管理(Prognostics Health Management,PHM)技术的需求极为迫切。
PHM 技术的核心之一是故障预测,根据收集到的发动机实时状态信息,预测发动机发生故障的时间,并在故障发生之前估计发动机能够正常运行的剩余使用寿命(Remaining Useful Life,RUL),对发动机的全寿命周期内的健康状态进行有效管理,不仅可以提高航空公司的飞行安全和整体运行品质,还可提高维修质量、降低维修成本,为机队长期可靠性运营提供有力的支持。
从数据挖掘的角度出发,基于机器学习的数据驱动预测方法,是目前行业研究的主流方向。 众多学者对航空发动机剩余使用寿命预测进行了深入研究。 裴洪等详细分析了基于机器学习的设备剩余寿命预测方法,根据机器学习模型结构的深度,将其分为基于浅层机器学习的方法和基于深度学习的方法。 周俊将数据驱动的预测方法细分为基于人工智能的方法、基于随机过程的方法、基于时间序列分析的方法、基于回归分析的方法和基于状态估计的方法,并对多种RUL 预测方法进行融合,提高了RUL 预测的精度和鲁棒性。 Schwabacher 等将数据驱动的方法分为传统数值方法和机器学习方法,传统数值方法包括线性回归和卡尔曼滤波等,机器学习方法则主要是采用神经网络、决策树、支持向量机等智能算法。 Tsui 等将数据驱动的预测技术分为基于独立增量过程的模型、基于马尔可夫链的模型、基于滤波器的模型、比例风险模型、门限回归模型。 Zhang 等则将数据驱动的方法分为随机系数模型、人工智能方法和基于趋势的方法。 于会越将一种改进的GBDT 引入发动机剩余使用寿命预测领域,与经典算法相比,改进后模型的性能评测指标有明显提升。 马忠等采用改进的卷积神经网络(CNN)方法,对发动机剩余寿命进行预测,拥有更高的预测精度。 车畅畅等应用一维卷积神经网络(1D-CNN)和双向长短时记忆神经网络(Bi-LSTM),建立航空发动机剩余寿命预测模型,结果表明混合模型更准确可靠。 胡启国等提出基于核主成分分析(KPCA) 和双向长短时记忆(BLSTM)神经网络的多信息融合寿命预测模型。李杰等针对航空发动机剩余寿命预测问题,提出了一种将卷积神经网络和长短期记忆网络相融合的数据驱动模型,融合模型结合了两种神经网络的优点,利用卷积神经网络提取数据中的空间特征,并采用长短期记忆网络提取时间特征。
本文在现有研究成果的基础之上,根据算法的功能和形式的类似性,把常用的回归类算法进行分类,选取每类中比较经典的算法进行预测与分析,最后采用基于精度的加权融合和基于信息熵的融合方法,对RUL 预测结果进行融合与对比。
1 算法分类
根据机器学习算法的功能和形式的类似性,本文尽量把常用的回归类算法按照最容易理解的方式,将其分为6 大类。 其中包括:基于线性算法、基于贝叶斯算法、基于实例算法、基于核算法、基于树算法和基于神经网络的算法。 当然,机器学习的范围非常庞大,有些算法很难明确归属于某一类。
线性回归是一种回归分析技术,本质上是一个函数估计的问题,找出因变量与自变量之间的因果关系。 线性模型形式简单、易于建模,但却蕴含着机器学习中一些重要的基本思想,许多功能更为强大的非线性模型可在线性模型的基础上通过引入层级结构或高维映射而得。 多元线性回归是基于线算法的典型代表。
贝叶斯线性回归是使用统计学中贝叶斯推断方法求解的线性回归模型,将线性模型的参数视为随机变量,并通过模型参数的先验计算其后验,具有贝叶斯统计模型的基本性质。
K 近邻法(K-Nearest Neighbor,KNN)是一种非常经典的基于实例的分类和回归算法,也是机器学习所有算法中理论最简单,最好理解的算法。 通过先选取一批样本数据,然后根据某些近似性将新数据与样本数据进行比较,通过这种方法来寻找最佳匹配。 回归时,通过找出一个样本的个最近邻居,将这些邻居某些属性的平均值赋给该样本,就可得到该样本对应属性的预测值。
支持向量机回归是一种基于核函数的学习方法, 是把输入数据映射到一个高阶的向量空间,从而可以更好的来解决各种非线性的回归问题。
决策树(Decision Tree)吸引人的地方在于其模型的可解释性,是以树状图为基础。 一般情况下,一棵决策树包含一个根节点、若干个内部节点和若干个叶节点。 决策树学习的目的是为了产生一棵泛化能力强的决策树,其基本流程遵循简单而直观的“分而治之”的策略。
集成学习(Ensemble Learning)通过构建并结合多个学习器来完成学习任务,用一些相对较弱的学习模型,独力地就同样的样本进行训练,然后把结果整合起来进行整体预测,常可获得比单一学习器显著优越的泛化性能。 本文基于树的集成学习算法,选取随机森林(Random Forest)和XGBoost 算法进行分析研究。
基于神经网络的算法是模拟生物神经网络,是一类模式匹配算法,通常用于解决分类和回归问题。人工神经网络对一组输入信号和一组输出信号之间的关系进行建模,使用人工神经元或者节点的网络来解决学习问题。
深度学习的概念源于对人工神经网络的进一步研究,是对人工神经网络的发展,尤其随着云计算、大数据时代的到来,计算能力大幅度提高的今天,深度学习试图建立更大更复杂的神经网络,用来处理大规模数据集。
本文单一预测方法中使用到的算法分类与常用算法见表1。
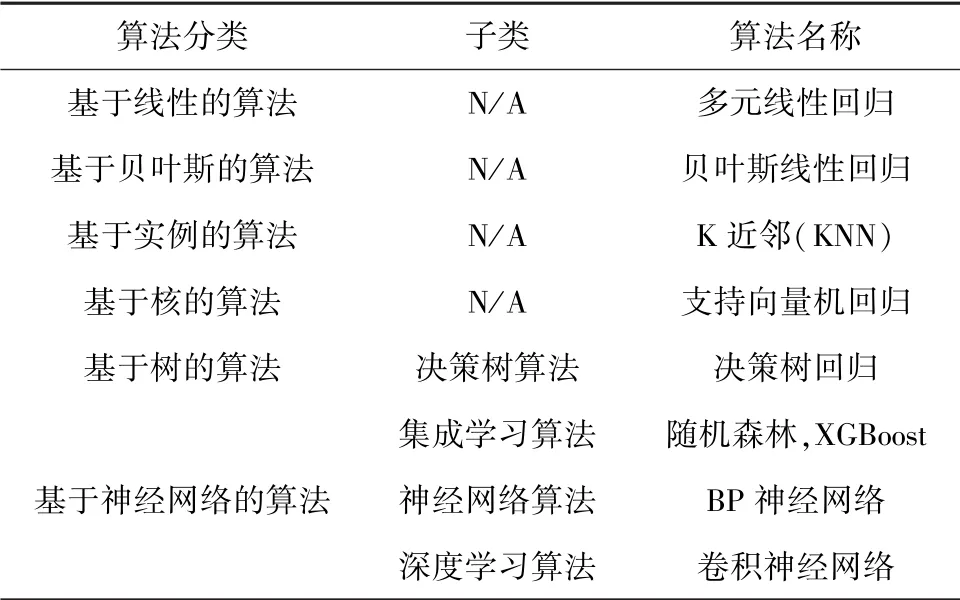
表1 算法分类与常用算法Tab.1 Common algorithm classification
2 融合方法
航空发动机系统十分复杂,零部件众多、运行环境与工作载荷复杂多变、故障模式多样,并且经常是多种失效模式复合,加上设备个体之间的差异、监测的传感器数量等因素影响,目前还没有能够适用于所有情况的预测方法。 针对于此,可采取对多种RUL 预测方法进行融合,相比单个预测方法,多种预测方法的融合能够有效提升RUL 预测的精度和鲁棒性。
为了进行比较,本文分别采用基于精度的加权融合和基于信息熵融合方法,对RUL 预测结果进行融合。
2.1 基于精度的加权融合
由于各种预测方法和模型的预测精度并不相同,有些方法的预测效果更好。 根据各种预测方法预测精度的不同,赋予不同的权重,然后对各种预测方法的预测结果进行加权求和。
基于精度的加权融合方法公式为:

关于权重的计算,本文根据单一预测方法的判定系数进行确定,判定系数越大,则权重越高。根据判定系数确定各预测方法权重的计算公式为:
2.2 基于信息熵融合
基于信息熵融合方法的基本原理是:对于各种预测方法,如果预测误差的变异度很大,在融合时其对应的权重应该比较小。
由于本文只对判定系数≥09 的预测方法进行融合,相对误差值偏小,使得权重值呈现均匀分布。 因此基于信息熵融合时,利用各种预测方法在所有时刻的预测值与实际值之间的绝对误差值构建的信息熵计算权重初始数据矩阵进行计算,具体过程如下:
假设,对种方法的预测结果进行融合,第种预测方法在时刻的预测值为rul。 首先计算第种预测方法在时刻预测的绝对误差值:
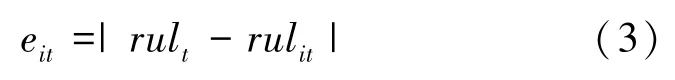
其次,对每一种预测方法计算在所有时刻点的预测绝对误差,得到由绝对误差组成的序列,并对其进行归一化处理:
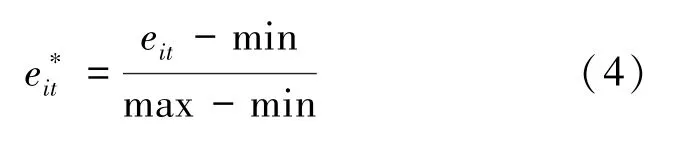
式中,min 为绝对误差序列的最小值,max 为绝对误差序列的最大值。
再次对归一化后的数据序列计算数据比重:

之后计算第种预测方法绝对误差序列的信息熵,其计算公式为:
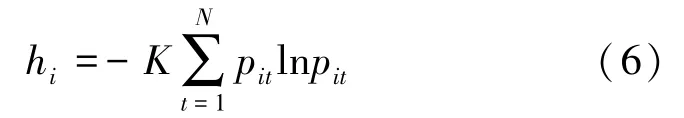
式中,为常数,1ln。
接着计算第种预测方法的变异度系数d。 由于0≤d≤1,根据预测绝对误差序列的信息熵大小与变异度相反的原则,变异度系数d的计算公式为:

最后,计算各个预测方法的权重w, 计算公式为:
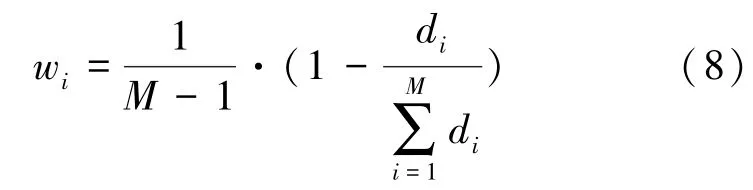
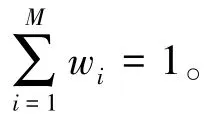
3 数据预处理
在本文中,由于难以获得航空发动机全寿命周期的完整的样本数据,所以采用美国国家航空航天局NASA 公布的涡扇发动机退化仿真数据集,作为此次剩余使用寿命预测的研究对象。
该数据集由4 组不同的数据构成,每组数据均由3 个操作参数和21 个传感器监测参数组成,本文选取其中的train_FD001 数据作为研究对象。
首先对数据进行预处理,其过程如下:
(1)计算“剩余使用寿命” (),将其作为机器学习回归模型的目标变量。 假设随时间线性下降,且在发动机最后一个时间周期的值为0。使用发动机最大运行周期(max_cycle)减去当前运行周期(cycle)计算。
(2)特征选择。 对数据进行分析发现:参数风扇入口温度(2)、风扇入口压力(2)、发动机压力比率()、燃烧室燃料烧空气比()、风扇转速(_)、校正后风扇转速(_) 等参数不含任何可用信息,因此做丢弃处理。
(3)通过盖帽法,消除可能存在的异常值。 将所有参数中小于1%及大于99%的值,分别用1%分位数和99%分位数替换。
(4)特征衍生。 选取时间窗口长度20,对于运行周期序列号20 的数据,根据当前的参数数据及前20 个连续的参数数据,衍生出新的特征——均值和波动(最大值与最小值之差除以均值)。 而对于≤20 的数据,做丢弃处理。
(5)将预处理后的数据,采用最小-最大值归一化方法,将数据归一化在[0,1]范围内。 归一化公式为:
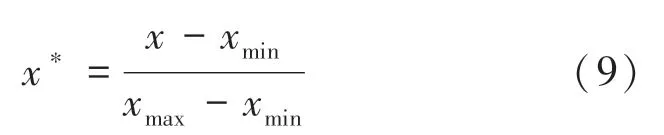
式中,为传感器参数数据的最小值,为传感器参数数据的最大值。
(6)划分训练集和测试集。 随机选取80%的数据作为训练集,20%的数据作为测试集。 评估每个算法的性能时,为保证每次划分的结果相同,随机种子设定为919。
通过对数据进行上述步骤的预处理,最终形成的数据包括影响发动机剩余使用寿命的参数共45个,作为目标变量,数据总量18 631 条。 其中训练集14 904 条,测试集3 727 条。
4 单一预测方法
4.1 单一预测方法比较
将表1 中的9 个算法分别在训练集上进行建模,并在相同的测试集上对模型进行评估。 选取均方根误差(Root Mean Squared Error,RMSE)和判定系数() 作为模型的评估指标。
表2 列出了采用单一预测方法进行预测所得结果的评估结果;图1 展示了单一预测方法均方根误差的折线图;图2 展示了单一预测方法判定系数的折线图。
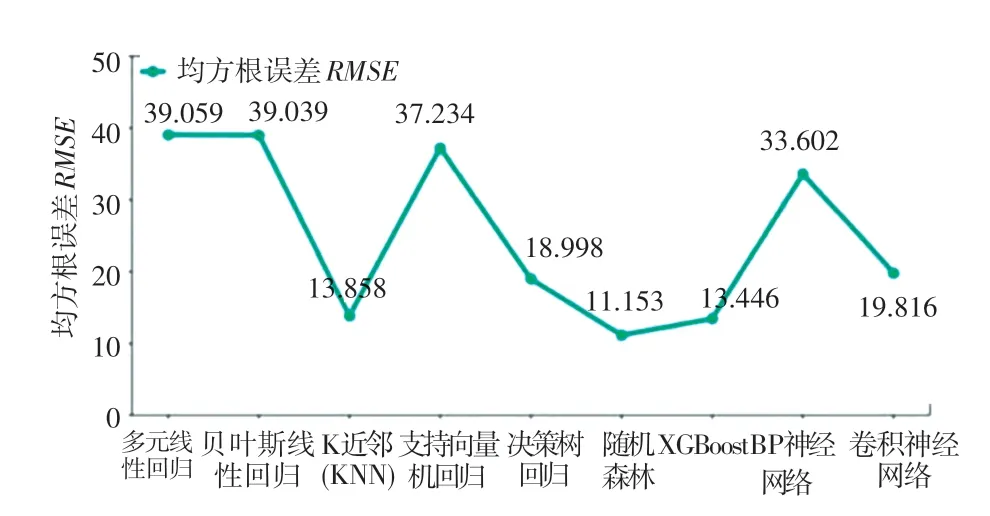
图1 单一预测方法的RMSEFig.1 RMSE of single prediction method
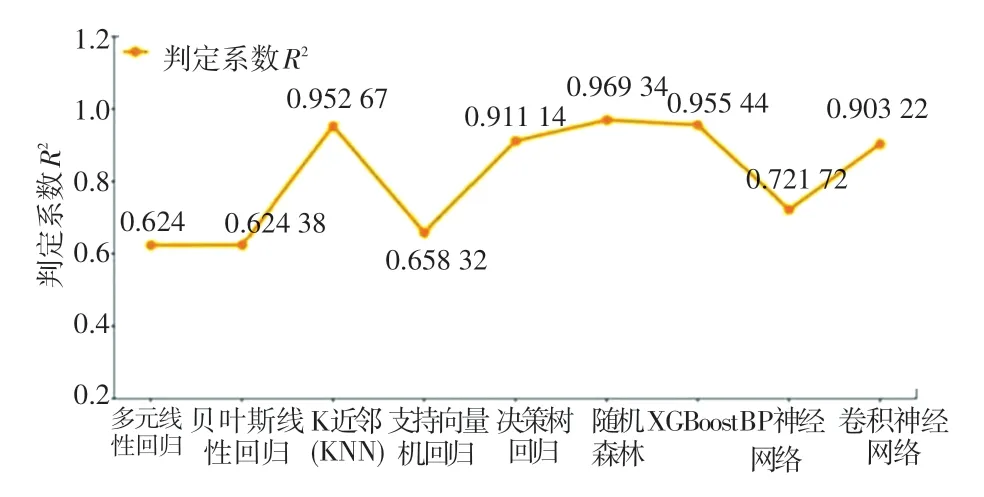
图2 单一预测方法的判定系数Fig.2 Determination coefficient of single prediction method
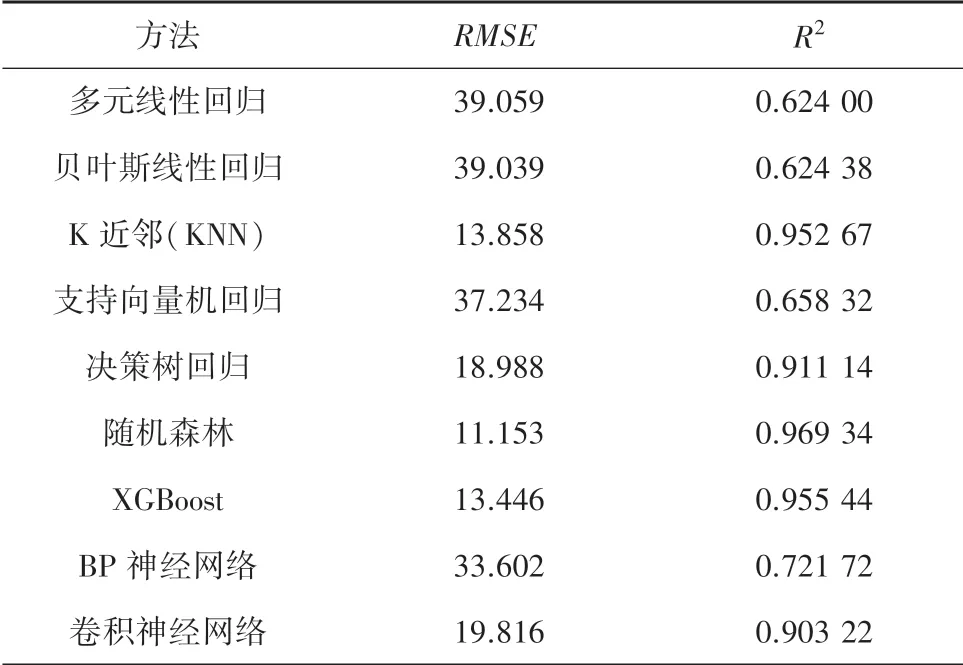
表2 单一预测方法的评估结果Tab.2 Evaluation results of single prediction method
结果显示:基于树的3 种算法(决策树、随机森林和XGBoost)预测结果中,判定系数均超过0.9,属于最佳类别;随机森林的预测结果无论是在均方根误差还是在判定系数方面均最佳。 而基于实例的算法KNN 也取得非常好的预测效果,相对于该算法的简单性,效果出乎意料。 受训练集样本量大小的限制,深度学习算法并未发挥应有的优势,但模型预测效果也比较良好。
4.2 结果分析
本节将选取单一预测方法中预测效果最佳的随机森林模型做进一步的分析。
随机选取编号25、50、62、88 的发动机,使用随机森林方法预测的和实际对比结果如图3所示。 可以看出:发动机在全寿命周期阶段,模型的预测值和实际值的拟合程度都比较准确,总体分布在实际值附近。 随机森林模型针对发动机这类复杂设备,具有较高的预测精度。
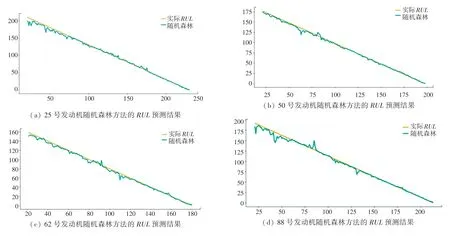
图3 随机森林方法的RUL 预测结果Fig.3 RUL prediction results of random forest
预测结果的误差范围,在一定程度上可以反映预测结果的精确性与稳定性。 随机森林预测方法在测试集的预测误差分布如图4 所示。 可以看出:预测误差主要集中在0 附近,且误差范围相对较小,表明预测模型拥有很高的精确性和很好的稳定性。
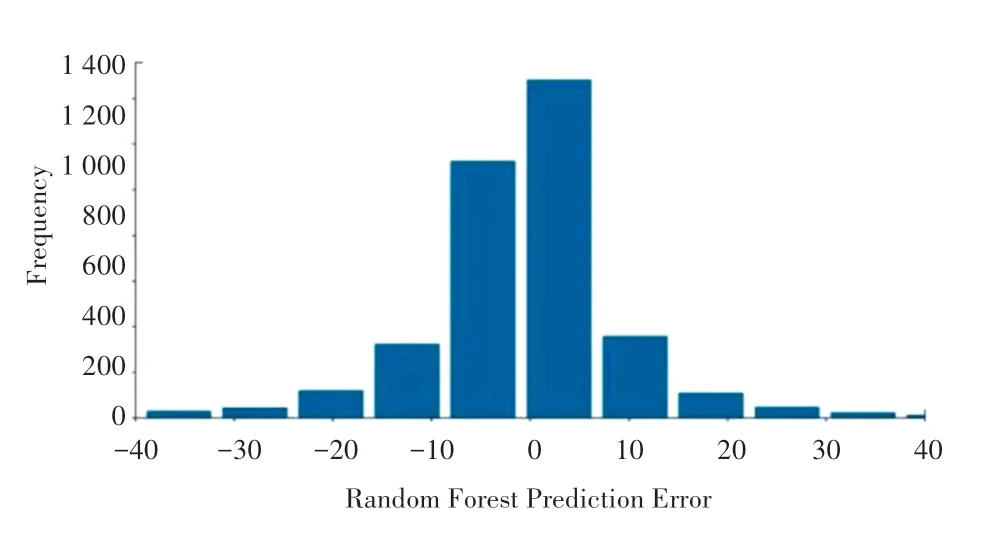
图4 随机森林方法的预测误差分布Fig.4 Prediction error distribution of random forest
5 融合预测方法
本文采用基于精度的加权融合与基于信息熵的融合方法,对RUL 预测结果进行融合。
由于不同预测方法的判定系数差异性较大,只选择判定系数≥09 的预测方法进行融合。 两种融合预测方法计算的各单一预测方法的权重值见表3。
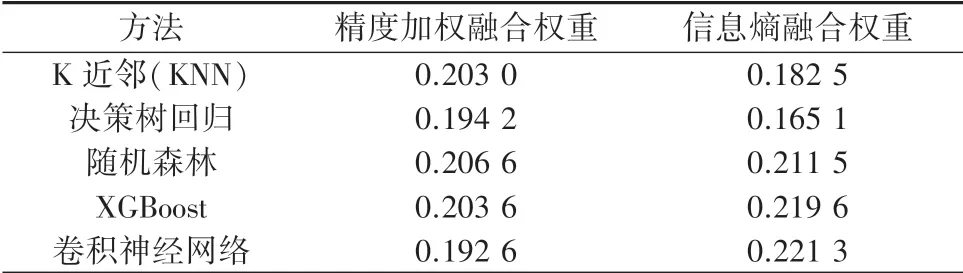
表3 单一预测方法的权重值Tab.3 Weight of single prediction method
采用单一预测方法进行预测以及对预测结果进行融合后,所得评估结果见表4;单一预测方法和融合预测方法的均方根误差的折线如图5 所示;单一预测方法和融合预测方法的判定系数的折线如图6 所示。
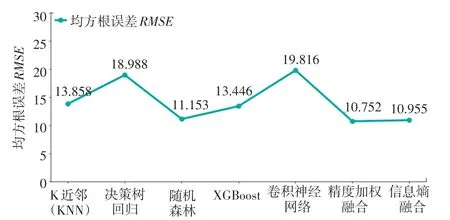
图5 单一/融合预测方法的RMSEFig.5 RMSE of single/fusion prediction method
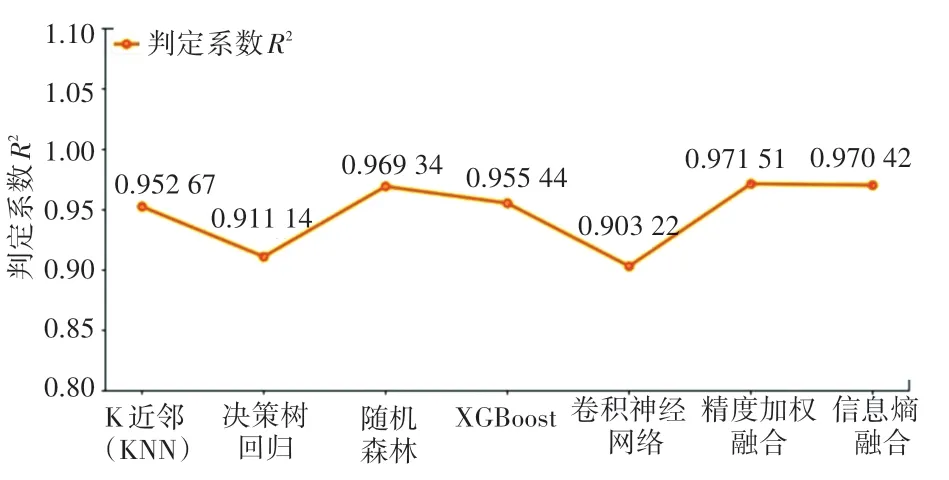
图6 单一/融合预测方法的判定系数Fig.6 Determination coefficient of single/fusion prediction method
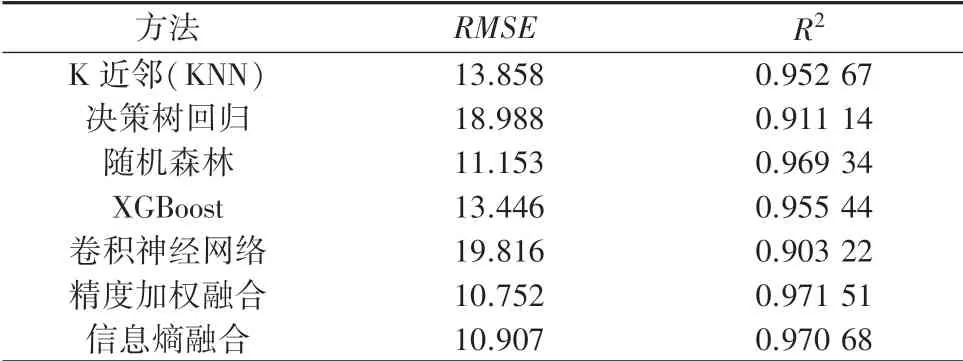
表4 单一/融合预测方法的评估结果Tab.4 Evaluation results of single/fusion prediction method
上述结果表明:融合预测方法的预测结果较单一预测方法拥有更高的预测精度,对多种预测方法的融合是提升预测精度的有效措施之一。
6 结束语
本文基于NASA 公布的涡扇发动机退化仿真数据,根据算法的功能和形式的类似性,将常用的回归类算法进行分类,然后选取每类中比较经典的算法进行预测对比。 实例分析结果表明:基于树的算法属于最佳类别。 其中,随机森林算法的单一预测效果最佳。
采用基于精度的加权融合与基于信息熵融合方法,对预测结果进行融合。 其结果表明: 融合预测方法无论在均方根误差() 还是在判定系数() 方面,较单一预测方法都有一定的提升,其中基于精度的加权融合效果最佳。
