基于混沌映射与飞行策略的短文本分类算法
2022-05-10苑津莎张卫华班双双
苑津莎,张 瑾,张卫华,班双双
(华北电力大学 电子与通信工程系,河北 保定 071003)
0 引言
随着信息时代的到来,大数据分析已经应用到了许多生产生活领域。电力系统在运行过程中所产生的历史数据经过不断积累,数据规模逐渐扩大。电力客服系统作为电力企业与客户沟通的桥梁,其工作效率的提高意义重大。客服工单(下文简称,工单)记录了电力系统在运行中所产生的诸如故障检修、调度运行、客户咨询及投诉、运维记录等大量数据信息。对工单进行数据分析,对于发现企业内服务系统存在的漏洞具有重要意义。应用文本分类技术将工单数据进行处理,快速准确地分析客户需求,有助于提升企业工作效率。
传统的数据分析方法存在信息读取效率问题。近年来,基于机器学习与深度学习的自然语言处理方法发展快速,且在工单文本分类处理方面得到了大量应用。文献[1]提出基于循环神经网络(RNN)的多任务学习框架,设置了3个不同信息共享机制,针对特定任务和共享层的文本建模,并在文本分类任务上验证了模型的性能。文献[2]针对电力投诉文本长度差异较大以及强专业性的特点,采用长短期记忆(LSTM)方法提取了电力文本语义特征,再通过卷积神经网络模型对其进行二次特征提取,有效提高了分类的准确性。文献[3]利用Word2Vec模型将词语映射到高维特征空间,通过基于双向 LSTM 的注意力机制(BiLSTM-attention)对电力设备缺陷文本进行分类。文献[4]为了提取更具代表性的特征向量,融合文本循环神经网络(TextRNN)模型和文本卷积神经网络(TextCNN)模型,并引入注意力机制,解决了TextRNN模型、TextCNN模型的局限性,提高了文本分类的效果。文献[5]提出了层次语义理解的方法,将工单中的字符、词建模转化为描述再进行分类,实现了工单隐藏语义的准确表示。文献[6]通过使用BERT模型对工单中具有设备缺陷的文本进行预训练,将生成词嵌入向量,再利用BiLSTM网络对该向量进行双向编码以提取语义表征,使用注意力机制增强设备缺陷领域的语义权重,提高了该领域文本分类的正确率。
为进一步深入对工单文本进行分析研究,提高工单文本分类的准确性与效率,本文采用BERT模型提取特征向量,尽可能覆盖输入文本信息,并利用ELM[7]进行分类。由于ELM的初始权重和偏置随机产生,故采用收敛速度较快、局部搜索能力较强的麻雀搜索算法[8](SSA)寻找最优初始权重和偏置以提高模型精度。针对SSA算法存在的全局搜索能力较弱、易陷入局部最优的缺点,通过引入Lévy-CSSA算法来克服。
1 短文本分类算法
文本分类的关键,在于特征提取以及特征向量的表示。本文采用的BERT模型在表示词向量时能够加入上下文的语义信息,还可以减少字词因无法通过语义区分而出现歧义的情况发生。该模型首先对大量未标记语料进行训练以获取包含大量语义信息的文本表示,然后对文本的语义表示进行微调,最终将其用于特定的自然语言处理任务。
1.1 RoBERTa-全词Mask模型
RoBERTa-WWM[9]模型的输入量E(E1,E2,···,EN)为工单文本内容;输入量经过Trm模块实现文本向量化后,输出为向量T(T1,T2,···,)。Trm模块是核心模块,有多层结构。
RoBERTa-WWM 模型的优点在于其结合了中文全词掩码技术以及RoBERTa模型的优势。全词掩码技术的优势在于其更改了预训练阶段的样本生成策略,用[Mask]标签将组成同一个词的汉字全部进行掩码,示例如表1所示。
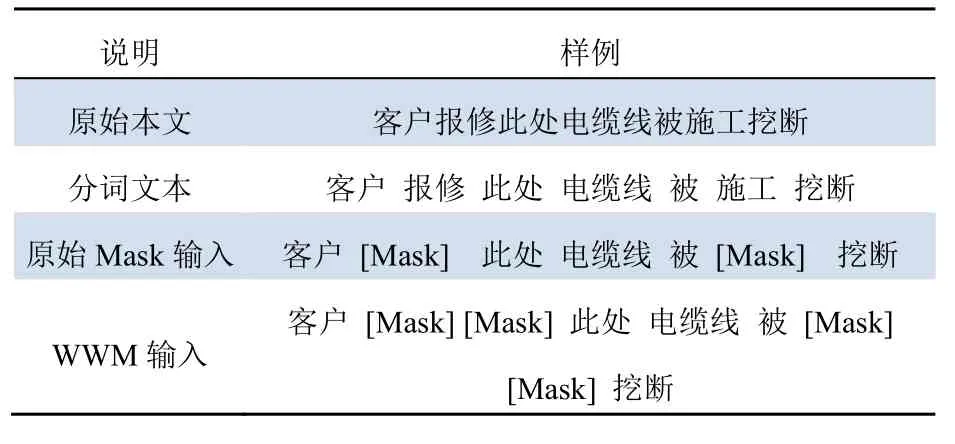
表1 WWM处理样本示例Tab. 1 Example of sample processing with WWM
RoBERTa模型主要在3个方面进行了优化:(1)优化了 Adam算法的参数。(2)对训练策略进行了优化。增加了每次训练所抓取的样本数量;同时也将静态掩码改成了动态掩码。(3)采用了更大的训练数据集,并使用了简单高效的双字母组合编码压缩了自然语言语料库中的数据。
1.2 极限学习机
在神经网络算法中,反向传播(BP)神经网络[10]的应用非常广泛。BP学习算法存在学习过程时间消耗过长,在处理经BERT模型提取出的高维特征向量时速度较慢。
ELM是一种具有求解快速特点的新型单隐层前馈神经网络模型,具有输入层、隐含层和输出层3层结构。ELM在计算过程中,首先对输入层权重和隐藏层偏置进行随机选取,对于输出层权重则通过广义逆矩阵理论计算得到。ELM模型结构如图1所示。
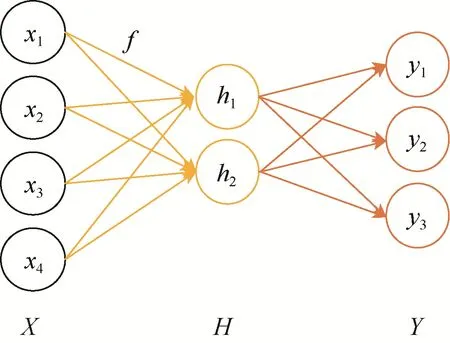
图1 ELM结构Fig. 1 ELM structure
在训练过程中,ELM无需如BP算法那样不断反向调整权重和偏置,所以学习速度较快;但其输入层—隐藏层权重与偏置的随机取值会影响模型精度,因此最优权重与偏置选取对模型的建立有重要意义。
1.3 结合BERT和改进ELM模型的分类方法
本文提出的模型结构如图2所示,具体步骤如下。
城市的发展靠大量资本、劳力等外力因素推动,而乡村的发展必须依靠内生动力。星光村人才辈出,虽然创业在外,但他们依然眷念故土,为家乡的建设投资投劳。但乡村的发展更要投智,人才对于乡村而言非常重要。星光村乡村旅游的进一步发展需要他们的支持、回归与带动。建议实施星光村精英反哺计划,鼓励部分在外发展的干部、专家、文学作家、设计师、企业老板等回乡创业,为家乡发展献计纳策,以本土化的力量增强自我造血功能,实现真正意义上的乡村振兴。
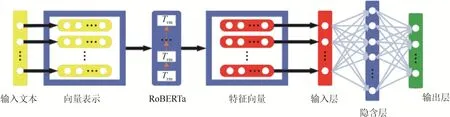
图2 分类建模流程Fig. 2 Classification modeling flow
步骤1:对训练集M进行预处理,累加位置编码后,得到M′。
步骤2:将M′输入BERT模型,根据训练集M′对预训练语言模型进行微调,最终获取对应训练集的特征向量 T。T=(T1,T2,···,TN),i=1,2,···,N。
步骤3:将步骤2中的特征向量T输入到ELM进行训练,得到文本分类结果,并与数据集标签进行比较,得到寻优算法适应度函数如式(1)所示。
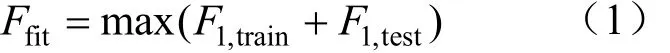
式中:F1,train是指训练集的 F1值;F1,test是指测试集的F1值
步骤4:通过ELM实现工单文本分类。
2 Lévy-CSSA算法
由于对 ELM 输入层权重和隐藏层偏置进行随机选取会影响模型性能,所以本文提出 Lévy-CSSA算法,通过改进SSA算法优化了种群初始值,并使用Lévy飞行搜索策略提高算法的全局寻优能力。该算法对ELM中输入层—隐藏层权重与偏置的初始值寻优,得到最优值使适应度函数值达到最大,进而提升模型的分类性能。
2.1 改进SSA算法
SSA算法是由文献[8]根据麻雀种群的觅食和反捕食行为提出的一种新型智能优化算法。在SSA算法中,将D维空间中的n只麻雀区分为发现者、跟随者和警戒者。发现者负责寻找食物并提供寻找的方向,适应度较好的发现者会优先获取食物;跟随者依靠发现者获取食物,且跟随者要比发现者的搜索范围小;警戒者则在危险降临时做出反捕食行为。
SSA算法局部搜索能力极强,但全局搜索能力较弱且不易跳出局部最优,从而导致其收敛精度较低。为了克服SSA算法全局搜索能力较弱的缺陷,本文利用logistic混沌映射[11]对SSA算法进行初始化,初始化产生的混沌麻雀具有随机性、遍历性等特点,提高初始种群的多样性。
2.2 Lévy飞行
2.3 Lévy-CSSA算法流程
本文定义Lévy-CSSA算法为:在麻雀种群位置信息初始化过程中加入logistic混沌映射,以增加初始种群的多样性;在麻雀位置信息更新时引入Lévy飞行策略,以提升全局搜索能力,避免陷入局部最优。具体流程如图4所示。
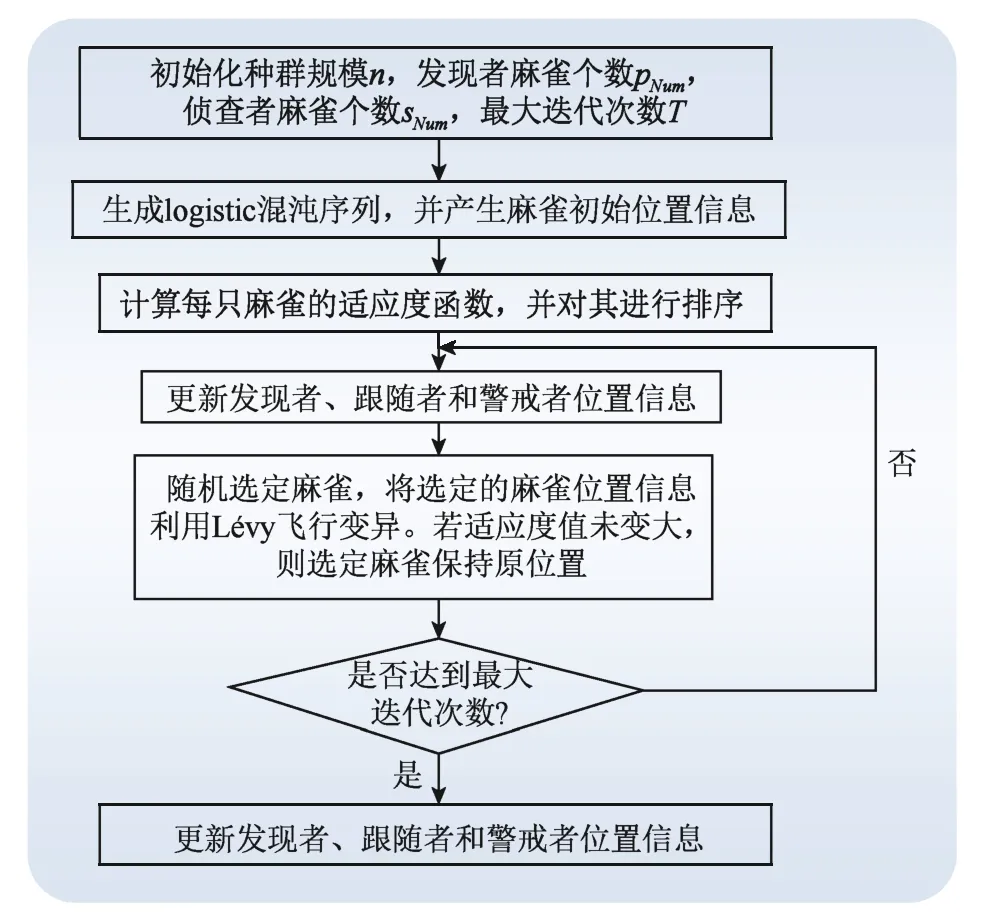
图3 Lévy-CSSA算法流程图Fig. 3 Flow chart of Lévy-CSSA algorithm
2.4 Lévy-CSSA极限学习机
针对 ELM 随机赋予输入层—隐藏层的权重与偏置的初始值会影响模型精度的问题,对ELM进行改进,具体流程如图4所示。
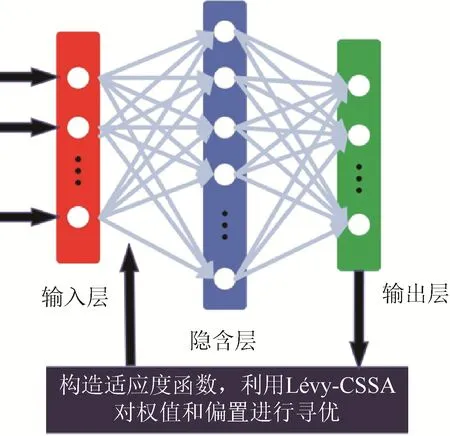
图4 Lévy-CSSA极限学习机Fig. 4 The Lévy-CSSA extreme learning machine
3 实验及分析
3.1 Lévy-CSSA算法性能测试
选取如表2所示的固定维度函数、高维单峰函数以及高维多峰函数进行仿真实验,并与GA、DE和SSA群体智能算法进行对比来验证Lévy-CSSA算法的可行性和优越性。通用条件设置为:种群规模设为30,迭代总数设为300。分别对各算法单独进行100次仿真实验并记录最优值Tb、平均值Tav和方差V。计算结果如表3所示,收敛曲线如图5所示。
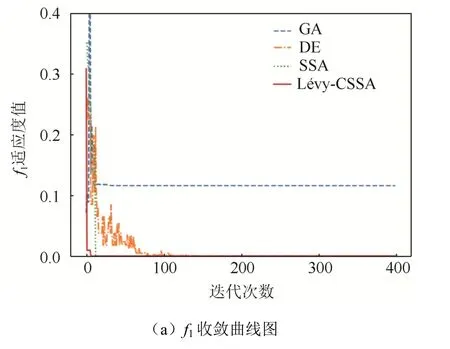
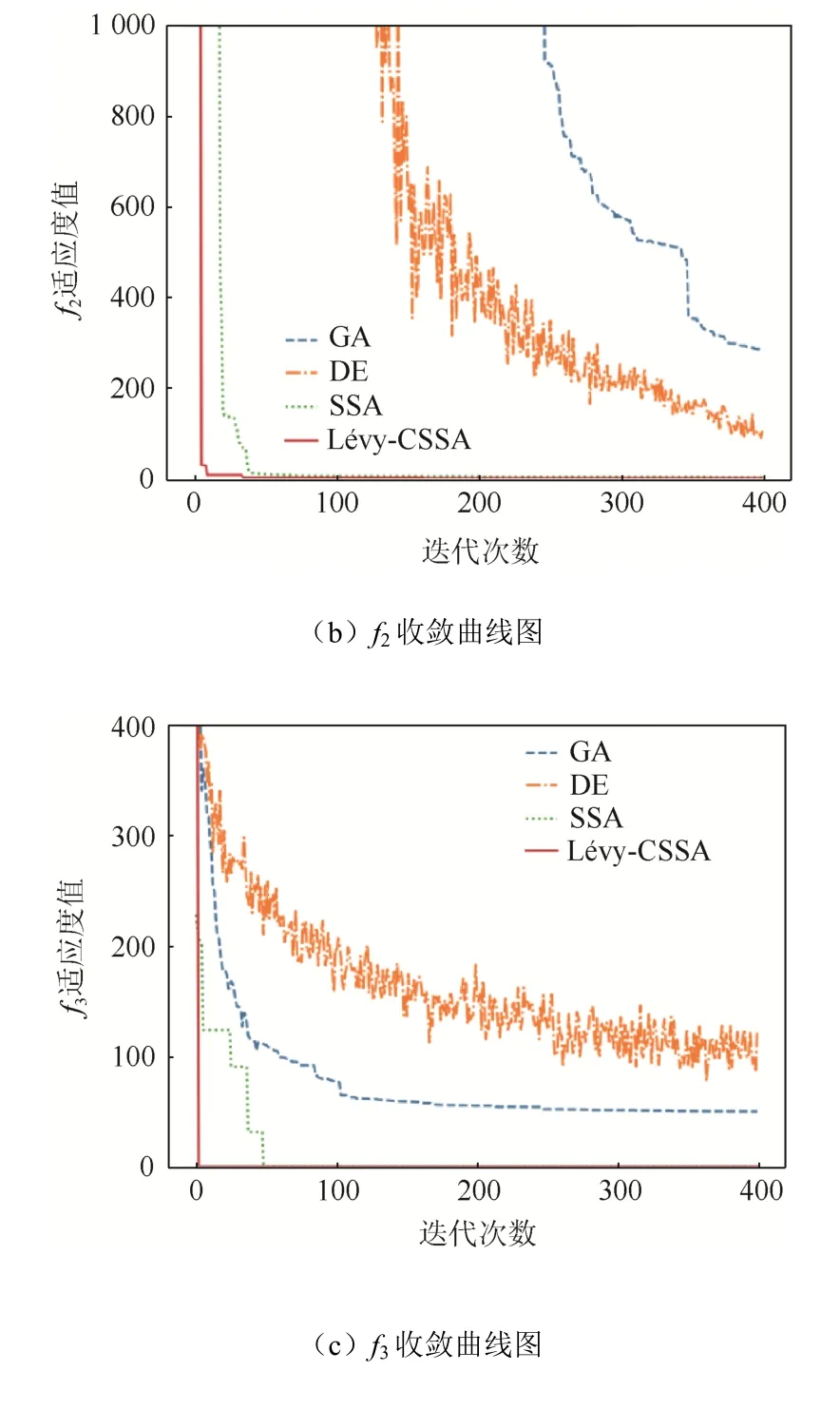
图5 收敛曲线Fig. 5 Convergence curve

表2 测试函数Tab. 2 Test functions
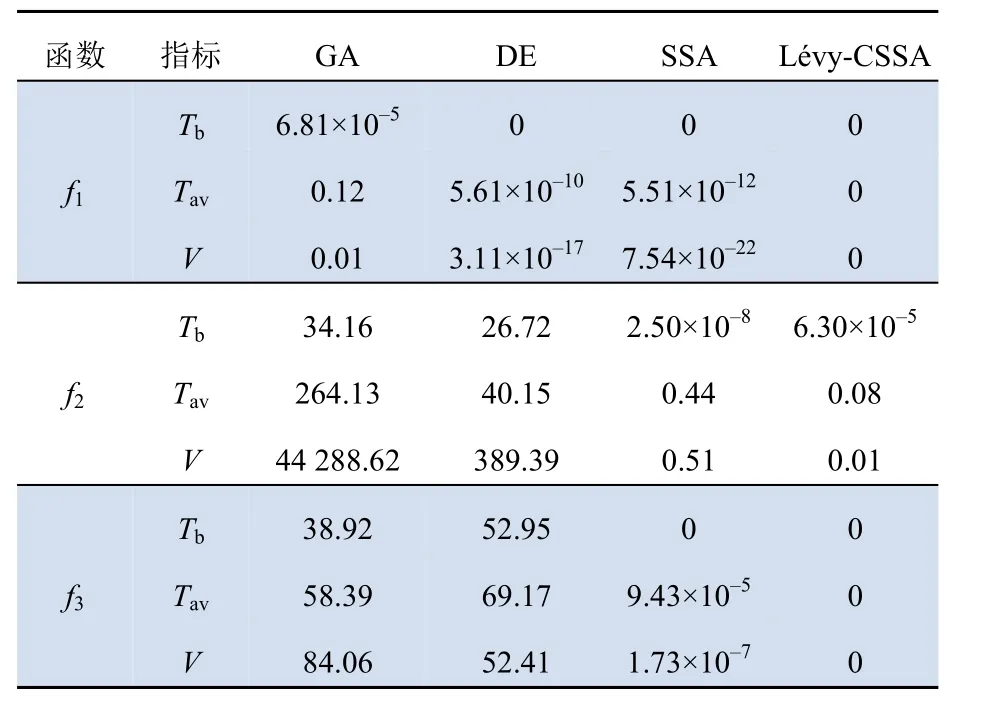
表3 测试函数寻优结果Tab. 3 Results of test function optimization
由表3可以看出:Lévy-CSSA算法在不同类型的测试函数中均可搜索至非常接近理论最优值;且相比于其他2种算法与原算法,其求解精度更高,表现更加稳定,尤其是在高维函数中凸显了算法优势。从图5可以看出:Lévy-CSSA能够清楚地显示出算法跳出局部寻优的能力,在收敛速度以及收敛精度上均优于其他算法。
工单经BERT模型提取到的特征向量具有高维度、高耦合特点,导致其在ELM中输入层—隐藏层权重与偏置维度较高,因此寻优时应使用适用于高维度的算法。本文算法对其具有适用性。
3.2 分类实验过程
实验所用数据来源于国家电网全国供电服务呼叫中心提供的文本分类数据集,其内容为某省客户向国家电网客服反映情况工单,包括电量异常、接触不良、电能表异常、安全隐患等8个类别[15],共计23 289条。现选取其中75%作为训练集,25%作为测试集进行实验,具体如表4所示。
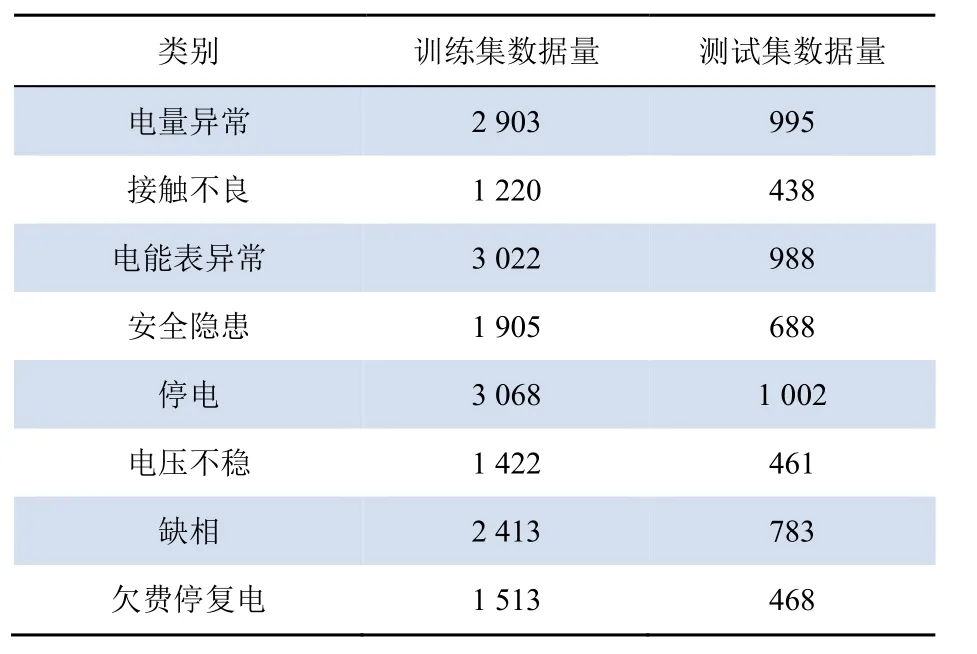
表4 实验数据Tab. 4 Experimental data 条
采用中文RoBERTa-WWM模型:有24层网络结构,其中隐含层有1 024维,共有3.3×108个参数。将训练集文本与测试集文本作为输入,通过预训练模型进行编码;每条文本数据均编码为 1 024维向量,并将训练集标签与测试集标签编码为8维向量。将1 024维文本向量作为输入,8维标签向量作为输出,对ELM进行训练;其中ELM输入层—隐藏层的权重与偏置的初始值通过本文提出的Lévy-CSSA算法进行优化。
3.3 分类评价指标
本文所研究的问题为分类问题,常用的评价指标为查准率(P)、查全率(R)与F1值[16]:
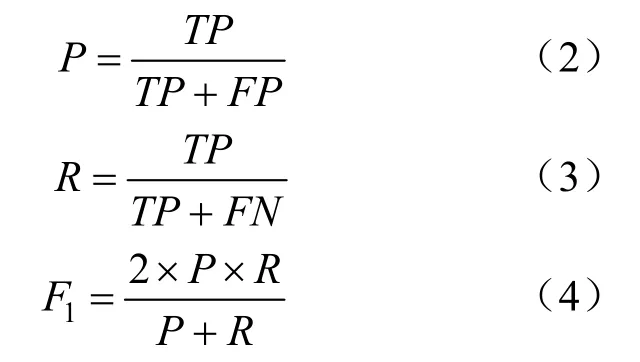
式中:TP表示预测为正,实际为正;FP表示预测为正,实际为负;FN表示预测为负,实际为正。
F1值是模型查准率和查差率的一种调和平均,可以更加全面地反映分类性能。
3.4 实验结果
结合BERT和改进ELM模型所获取的训练结果,分别与TextRNN、TextCNN以及结合BERT与随机森林模型的文本分类结果进行对比,实验结果如表5、图6所示。评价指标主要采用F1值。

图6 分类结果对比图Fig. 6 Comparison of classification results
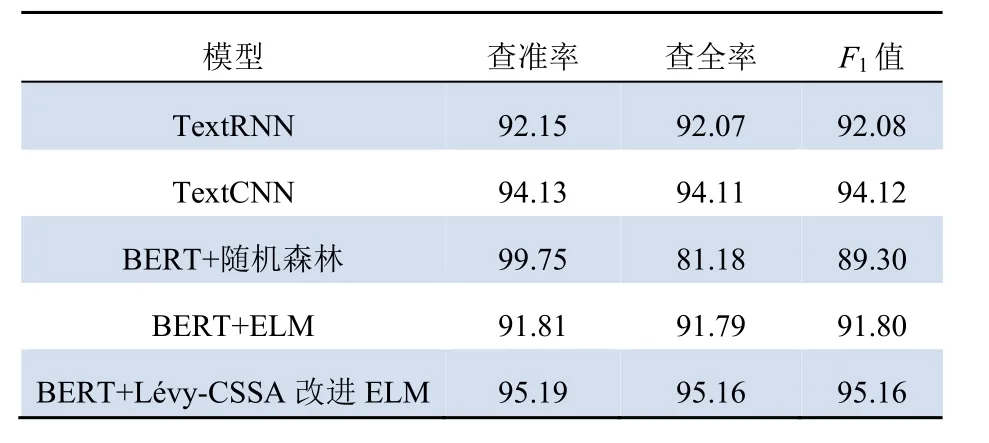
表5 不同模型的实验结果Tab. 5 Experimental results of different models %
由表5可以看出,对于工单,在模型的查准率、查全率和F1值评价指标方面,结合BERT和改进ELM模型的分类效果相比于其他模型均有明显提升。本文所提出模型的F1值达到了95.16%,相比于原始的TextRNN、TextCNN模型分别提高了3.08%、1.04%,可见本文模型综合性能更好。结合BERT和ELM模型相比于TextRNN、TextCNN模型效果较差,其原因是:即使通过BERT模型提取出更加全局的特征向量,但ELM模型的输入层—隐藏层权重与偏置的随机取值影响了模型精度,这更加体现出对模型进行优化的重要性。
由图6可以看出:本文提出的模型在8个类别上的分类性能均优于其他4种模型。结合BERT与随机森林模型表现不稳定,对于不同的类别,分类性能相差较大。结合BERT和 ELM模型相比于TextRNN在电量异常、接触不良、电能表异常、停电、缺相、欠费停复电这些类别分类表现均较差,且在各个类别中均比TextCNN分类效果差。通过Lévy-CSSA算法对模型寻优后,本文算法对每个类别的分类能力均有明显提升,在“安全隐患”类别的分类水平提升效果最为明显。
4 结论
为提高工单分类模型的分类效果,本文提出结合BERT和改进ELM模型的分类方法,并通过具体的工单分类实验验证了方法的有效性。
(1)本文提出的 Lévy-CSSA 算法提高了结合BERT和改进ELM模型的分类精度。3类经典测试函数优化对比实验的结果表明了Lévy-CSSA算法具有明显优越性。
(2)建立了BERT和改进ELM模型。使用Lévy-CSSA算法对ELM进行优化,并通过工单分类实验验证了模型效果。与TextRNN、TextCNN等模型的对比结果表明:模型在查准率、查全率以及F1值等分类指标上均有所提高;该模型可以更好地表达工单语义信息,能够有效地进行工单分类。
以上结论表明了本文结合BERT和改进ELM模型的工单分类方法的可行性。
