面向工业互联网隐私数据分析的量子K近邻分类算法
2022-05-09林雨生黄思维张仕斌
昌 燕 林雨生 黄思维 张仕斌
(成都信息工程大学网络空间安全学院 成都 610225) (先进密码技术与系统安全四川省重点实验室(成都信息工程大学) 成都 610225)
工业互联网是新一代信息通信技术与工业经济深度融合的新型基础设施,蕴含了海量的人、机、物、系统相关的数据信息,分析和利用这些数据将会对优化覆盖全产业链、全价值链的制造体系和服务体系产生重要的指导价值.然而对工业互联网大数据进行处理和分析,在给个人、企业和国家带来无限机遇的同时,也带来了前所未有的隐私忧患.对敏感工业互联网大数据的直接处理和分析,意味着个人、企业和国家隐私信息的泄露,这给人们的生命财产安全,乃至国家安全带来威胁[1].因此,隐私安全是工业互联网安全的重要组成部分,研究可以保护隐私的工业互联网大数据处理和分析算法在工业互联网大数据时代已经非常紧迫和严峻.工业互联网大数据处理中的隐私保护需求、高效率需求和高准确率需求等,都对传统计算理论与计算技术提出了新的挑战[2-3].
量子机器学习算法是利用量子叠加态提高机器学习效率的一种全新的工业互联网数据分析方法,隐私保护是量子机器学习研究的一个重要组成部分[4].目前已有不少关于量子机器学习隐私保护方案的研究,然而,这些方案几乎都很难同时保证算法的隐私性、准确性和可用性,从而影响了算法的实用性.基于噪声的差分隐私保护方案[5-9],其准确性和可用性受噪声的不确定性影响,并且隐私保护只在鲁棒界内有效;基于量子同态加密的隐私保护方案[10-12],需要完全可信的第三方来协助完成量子机器学习过程,运算复杂度极高;基于量子多方安全计算的隐私保护方案[13-16],对用户计算能力有较高要求,难以得到推广.因此,工业互联网环境下,基于量子机器学习的大数据分析研究的关键是隐私性、准确性、复杂性和可用性的平衡.
本文的主要贡献包括3个方面.
1) 提出了保护隐私的量子KNN算法,找到了一种对原始训练样本集和待测样本的加密方法,使得向量子云服务器输入密文样本可以得到与输入原始样本相同的预测结果.输入数据的隐私得到了保护,且服务器的量子算法本身不需要改变.由于输入云服务器的是密文数据,虽然输出的结果与直接输入原数据的输出结果相同,但输出结果不能揭示原数据的任何信息,即:①无法从输出结果中提取和训练数据有关的信息;②无法从输出结果中取得模型内部的参数或结构;③无法从输出结果中获知某个特征数据是否包含在模型的训练集中.
2) 从模型隐私、预测结果隐私和输入数据隐私等3个方面分析了本文方案的隐私安全性.本文算法中一个预测结果z反演回去对应N+1个输入数据,很难通过多次访问量子云服务器得到的预测结果反推模型、参数、输入数据及其相关属性特征,因此本文算法可以很好地抵御模型提取攻击、模型逆向攻击、成员推断攻击、属性推理攻击等.
3) 与已有的量子机器学习算法的隐私保护方案相比,本文隐私保护方案在隐私性、复杂度、可用性等3个方面均优于已有方案,实现了保护隐私性的同时,不增加额外计算开销,不降低算法效率和可用性,不影响算法准确性.经典数据在输入量子算法前由用户进行经典加密,量子算法本身不需要改变,因此不会增加除经典加密之外的其他工作量,更不会增加量子算法的计算工作量.经典加密运算可以依据量子加密运算和量子化编码运算倒推得到,因此不是复杂运算,也不会给用户带来过多的加密负担.
1 相关工作
现有的量子机器学习隐私保护主要围绕着以下3类隐私保护技术展开研究:基于差分隐私的隐私保护技术、基于同态加密的隐私保护技术和基于安全多方计算的隐私保护技术.
量子差分隐私是差分隐私的量子方案,目前已经被用于分类、回归和神经网络等量子机器学习模型的隐私保护.Du等人[5]利用量子信道的去极化噪声提出了量子分类器的差分隐私保护方案,给出了抗扰动的鲁棒性界.Senekane等人[6]在经典输入数据集上添加离散的拉普拉斯噪声,实现了量子逻辑回归机器学习模型的隐私保护.Zhou等人[7]基于广义振幅阻尼噪声、相位振幅阻尼噪声和去极化噪声分别给出了3种量子噪声隐私保护机制.Watkins等人[8]提出了基于差分隐私框架的量子机器学习算法,通过基于高斯噪声的差分隐私优化算法实现隐私保护.Du等人[9]利用量子去极化噪声差分隐私Lasso模拟器处理私有稀疏回归学习任务.
同态加密被广泛应用于量子计算以实现保护隐私的量子计算.Gong等人[10]提出了基于改进T门更新的量子同态加密方法,实现了基于云服务器的保护隐私的量子K-means算法,算法中H门和T门数量的增加,导致算法复杂度增加,准确性下降.Huang等人[11]首次在IBM量子云平台上实现了基于同态加密的保护数据隐私的量子线性方程组求解.Fisher等人[12]通过量子同态加密实现了保护数据隐私的量子计算.
量子安全多方计算是安全多方计算的量子解决方案,目前已被用于量子机器学习的隐私保护研究.Sheng等人[13]提出了分布式安全量子机器学习协议,协议对客户端的量子能力要求限制了它的应用和推广.Li等人[14]提出了一种基于盲量子计算的变分量子分类器私有单方委托训练协议,并将该协议扩展到包含差分隐私的多方私有分布式学习.Xia等人[15]提出量子联邦学习框架QuantumFed,让多个具有本地量子数据的量子节点一起训练模型.Chehimi等人[16]为具有量子计算能力的客户端提出了完全量子联邦学习框架.
本文提出的基于类同态加密的保护隐私的量子KNN算法,找到了一种对原始训练样本集和待测样本的加密方法,使得向量子云服务器输入密文样本可以得到与输入原始样本相同的预测结果.输入数据的隐私得到了保护,且服务器的量子算法本身不需要改变.与已有的量子机器学习算法的隐私保护方案相比,本文隐私保护方案在隐私性、复杂度、可用性等3个方面均优于已有方案,实现了保护隐私性的同时,不增加额外计算开销,不降低算法效率和可用性,不影响算法准确性.本文的研究为保护量子机器学习隐私提供了一种新方法,也为提高工业互联网大数据分析在隐私性、高效性和准确性等方面的综合性能提供了一种新思路.
2 量子计算基础知识
2.1 量子门计算
任意旋转角度的单量子比特旋转门可表示为2×2的酉矩阵U(θ)(其中θ为变量):
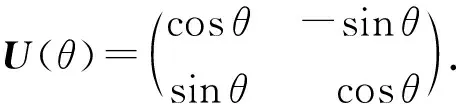
(1)
如果在任意量子态|φ〉=cosα|0〉+sinα|1〉上作用U(θ)操作,则该量子态变为
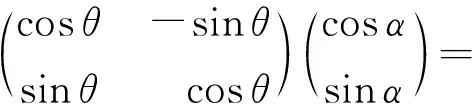
(2)
2.2 量子态的相似度计算
2个量子态|φ〉和|ω〉的保真度(相似度)是指两量子态内积范数的平方|〈φ|ω〉|2.任意2个维数相同的量子态,通过SWAP-Test量子线路(图1),可以得到2个量子态的保真度,反映了它们的重叠情况.
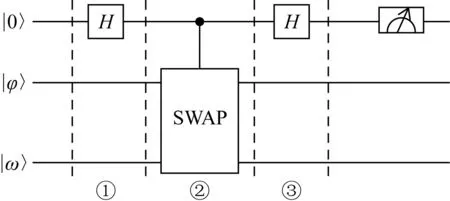
Fig. 1 SWAP-Test quantum circuit图1 SWAP-Test量子电路
量子态|0〉,|φ〉,|ω〉输入SWAP-Test线路后的运算过程为
(3)
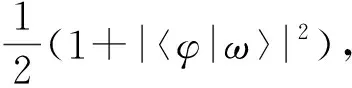
3 量子KNN算法的隐私保护方法
3.1 经典KNN算法
KNN算法是一种有监督学习方法,其原理是:当对测试样本进行分类时,首先通过扫描训练样本集,找到与该测试样本最相似的k个训练样本,然后根据这k个样本的类别进行投票确定测试样本的类别.下面我们从KNN算法的输入和具体步骤2方面来简单描述KNN算法.
1) 输入:训练样本集(含标签)和待测样本
训练样本集表示为X={X1,X2,…,XN},其中Xi=〈Xi1,Xi2,…,Xid〉(i∈[1,N])表示训练样本集中的第i个样本,Xij(j∈[1,d])表示样本Xi的第j个属性.
待测样本表示为Y0=〈Y01,Y02,…,Y0d〉,其中Y0j(j∈[1,d])表示样本Y0的第j个属性.
2) 步骤
① 通过交叉验证确定k的取值,将样本数据按比例拆分为训练数据和验证数据,先给定一个小的k值,将训练数据作为训练样本,验证数据做待测样本,运行KNN算法的步骤②~④,不断增加k值,然后计算验证数据集合的方差,最终找到一个比较合适的k值.
② 求待测样本和训练样本集中每个样本的相似度(常见计算距离的方法有曼哈顿距离算法和欧氏距离算法等).
③ 按照距离的递增关系进行排序,选取距离最小的k个点,即取k个最相似的数据.
④ 选择k个最相似训练样本中出现次数最多的分类作为待测样本的预测分类.
显然,KNN算法的步骤①本质上还是通过执行KNN算法的步骤②~④确定最优k值,因此,在后续的量子KNN算法中着重介绍步骤②~④.
3.2 量子KNN算法
量子KNN算法(quantumK-nearest neighbor, QKNN)是将量子计算思想运用到经典KNN算法中,利用量子计算的高并行性优势,对经典KNN算法进行指数级加速.下面我们从量子KNN算法的输入前准备、输入和具体步骤等3个方面来简单描述量子KNN算法.
1) 前期准备
将训练样本集和待测样本中的属性值归一化,得到归一化的训练样本集x={x1,x2,…,xN},其中xi=〈xi1,xi2,…,xid〉(i∈[1,N])表示归一化的训练样本集中的第i个样本,xij(j∈[1,d])表示归一化样本xi的第j个归一化属性.归一化待测样本y0=〈y01,y02,…,y0d〉,其中y0j(j∈[1,d])表示归一化待测样本y0的第j个归一化的属性.
2) 输入
输入归一化的训练样本集x和待测样本y0.
3) 步骤
① 将归一化的训练样本集x和待测样本y0分别编码为量子叠加态.归一化待测样本量子叠加态表示为
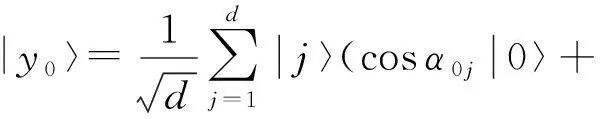
(4)
其中sinα0j=y0j.归一化训练样本集量子叠加态表示为
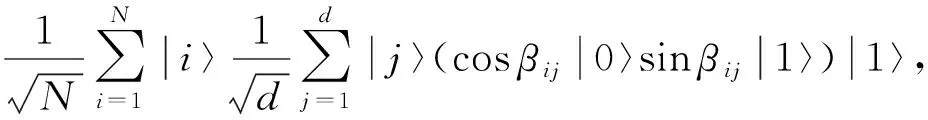
(5)
其中sinβij=xij.
② 求待测样本和训练样本集中每个样本的相似度.将|y0〉和|x〉输入SWAP-Test门,输出量子态|γ〉,即:
(6)
|γ〉也可以表示为
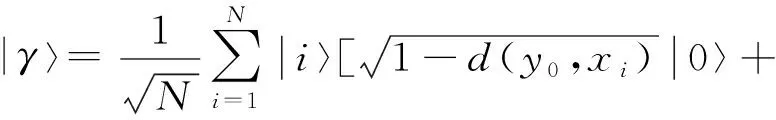
(7)
其中
(8)
式(8)中“=”两端都表示|γ〉态的第1个量子位测得|1〉的概率.
(9)
如果用d(y0,xi)来表征待测样本y0和训练样本xi的相似度,那么d(y0,xi)值越小,y0和xi的相似度越大.通过相位估计将相似度转换到量子比特上.
③ 用Grover搜索算法取k个最相似的数据.
④ 选择k个训练样本中出现次数最多的分类作为待测样本的分类.
3.3 保护隐私的量子KNN算法
1) 类同态加密
定义1.量子构件三元组表示为T(in,Bq(·),out), 其中Bq(·)是量子构件的基本量子算法,in是基本量子算法的量子态输入,out是基本量子算法的输出,三者之间的关系可表示为Bq(in)=out.
定义2.假设经典数据表示为a,Q表示对经典数据的量子化编码方法,E是一种经典数据加密方法,V为其对应的量子加密方法,存在关系:
V(Q(a))=Q(E(a)).
(10)
若能找到一种加密方法,满足条件
Bq(Q(E(a)))=Bq(Q(a)),
(11)
则称我们找到了能保护该量子构件隐私的类同态加密算法.式(11)的含义是:对经典数据先加密再量子化后输入量子构件的基本量子算法,其输出结果与直接对经典数据量子化后输入量子构件基本量子算法的输出结果相同.
如果存在经典加密算法和对应的量子加密算法满足上述关系,就可以认为:用户可以先对要输入量子构件的数据进行加密,再输入量子构件基本量子算法,其输出的结果与直接将数据(不加密)输入量子构件结果相同,输入数据(可以是训练数据集、模型的参数和权重等)的隐私得到了保护,且量子构件的基本量子算法本身不需要改变.由于输入的是加密后的数据,虽然输出的结果与直接输入原数据的输出结果相同,但输出结果不能揭示原数据的任何信息,即:①无法从输出结果中提取和训练数据有关的信息;②无法从输出结果中取得模型内部的参数或结构;③无法从输出结果中获知某个特征数据是否包含在模型的训练集中.
因此,如果能够找到满足以上3个条件的加密函数V和E,就找到了保护量子构件隐私的方法.步骤为:
① 设计或找到一种量子加密方法V满足
Bq(V(Q(a)))=Bq(Q(a)).
(12)
② 根据经典数据量子化编码的规则,反推量子加密方法V对应的经典加密方法E,使得它们满足
V(Q(a))=Q(E(a)).
(13)
2) SWAP-Test内积运算的类同态加密
① 量子化编码规则.任意的归一化经典数据y按幅度编码规则编码为量子叠加态,即:
|φ〉=cosμ|0〉+sinμ|1〉,
(14)
其中μ=arcsiny.
② 任意2个量子叠加态|φ1〉=cosμ1|0〉+sinμ1|1〉和|φ2〉=cosμ2|0〉+sinμ2|1〉输入SWAP-Test线路求内积的结果为
〈φ1|φ2〉=cos(μ1-μ2).
(15)
量子旋转门U(θ)作用在|φ1〉和|φ2〉分别得到
U(θ)|φ1〉=cos(μ1+θ)|0〉+sin(μ1+θ)|1〉,
(16)
U(θ)|φ2〉=cos(μ2+θ)|0〉+sin(μ2+θ)|1〉.
(17)
U(θ)|φ1〉和U(θ)|φ2〉输入SWAP-Test线路求内积的结果为
〈U(θ)φ1|U(θ)φ2〉=cos(μ1+θ-μ2-θ)= cos(μ1-μ2)=〈φ1|φ2〉.
(18)
③ 根据①中的量子化编码规则,推导出量子加密U(θ)|φ〉对应的经典加密函数为
E(θ,y)=sin(arcsiny+θ).
(19)
3) 基于SWAP-Test类同态加密的量子KNN隐私保护算法
① 数据集加密
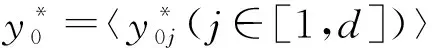
(20)
其中α0j=arcsiny0j.
(21)
其中βij=arcsinxij.
② 输入
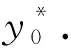
③ 步骤
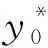
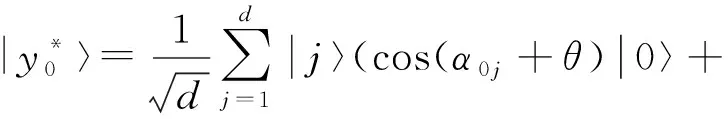
(22)
训练样本集密文x*编码为量子叠加态,即:
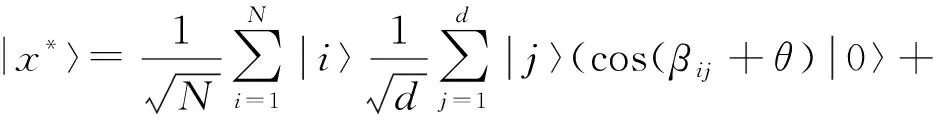
(23)
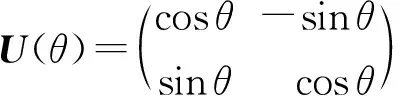
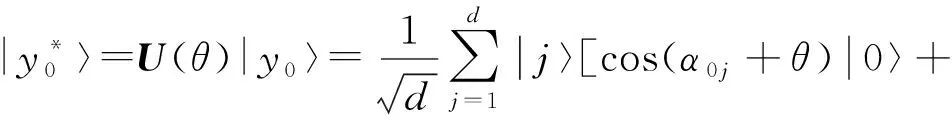
(24)
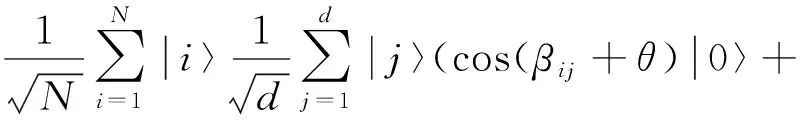
(25)
(26)
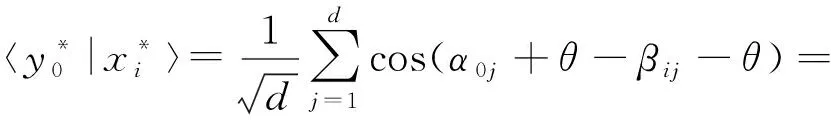
(27)
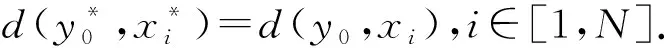
Ⅲ.用Grover搜索算法取k个最相似的数据.
Ⅳ.选择k个训练样本中出现次数最多的分类作为待测样本的分类.
4 保护隐私的量子KNN算法安全性分析
机器学习的隐私保护分为对用户输入数据的保护、机器学习模型的保护和机器学习预测结果的保护.攻击者对机器学习的攻击,因阶段不同,采取的攻击方式也不同.Rigaki等人[17]调查研究了针对机器学习的所有可能隐私攻击,并对已有的隐私攻击方式及隐私泄露的原因进行了分析和总结.下面,我们从模型提取隐私、预测结果隐私和输入数据隐私等3个方面分析本文方案的隐私安全性.
4.1 模型提取隐私攻击
在机器学习模型安全性的研究中,Papernot等人[18]引入了信息安全CIA理论,指出机器学习模型安全包括模型的机密性、完整性和可用性.现有的模型隐私攻击大部分是针对模型机密性的攻击,常用的攻击方式是模型提取攻击[19].模型提取攻击是指攻击者访问云服务器机器学习模型后,获取模型的参数或者构建一个等价的模型.一方面,如果云服务器提供收费的机器学习服务,那么通过模型提取攻击获取服务模型就会破坏云服务的收费模式,对云服务器造成损失;另一方面,攻击者通过多次访问模型得到的数据反馈,可能会推断出训练数据的信息,导致用户训练数据的泄露,对用户造成损失.
本文提出的保护隐私的量子KNN算法是一种非参数模型算法,算法中的参数k不通过用户数据训练得到.为构建一个等价模型及获取参数k的值,攻击者用多次访问云服务器量子算法模型反馈的结果以及对应的输入构建方程组:
(28)
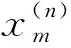
4.2 预测结果隐私攻击
攻击者常常采用模型逆向攻击和成员推断攻击等方式,对机器学习模型产生的预测结果进行隐私攻击.模型逆向攻击是指攻击者从预测结果中推断出用户训练数据的信息[19].攻击者首先使用自身构造的数据访问云服务器,得到构造数据的输出结果,进而使用模型提取攻击构建服务器等价(模拟)机器学习模型,当截获用户输入数据的预测结果时,通过攻击者模拟的模型进行反演,则可以得到用户输入的训练数据.
攻击者构建的等价(模拟)模型表示为
f(x1,x2,…,xm)=y,
(29)
其中xm为攻击者构造的输入数据的第m个属性,f(·)为攻击者模拟的模型,y为攻击者利用模拟模型获取的预测结果.
当攻击者获取到云服务器模型对用户输入训练数据的预测结果y′时,将其代入攻击者模拟的模型,则可以通过以下式子还原出用户输入的训练数据:
(30)
本文提出的保护隐私的量子KNN算法中,用户将数据(待测样本和训练样本集)传输到云服务器前先进行了加密,该加密对数据的影响等价于云服务器对原始待测样本量子叠加态和训练样本集量子叠加态分别进行了U(θ)操作(θ可以是任意角度).
(31)
其中g(·)为云服务器的真实量子算法模型,E(θN,x)表示用θN角度加密训练样本集,E(θN,y0)表示用θN角度加密待测样本,z为云服务器模型预测结果.式(31)描述了本文保护隐私的量子KNN算法的隐私保护基本原理,即只要对训练样本集和待测样本选用相同的角度旋转加密,对于选取的任意角度,云服务器模型都会得到相同的预测结果.这意味着用一个预测结果z反演回去可能会反演出N+1个输入数据:{{x,y0},{E(θ1,x),E(θ1,y0)},{E(θ2,x),E(θ2,y0)},…,{E(θN,x),E(θN,y0)}}.
假定攻击者模拟的模型无限接近云服务器的真实模型,并且获取的预测结果是准确的,攻击者进行模型逆向攻击,反演出的用户输入数据可能是用任意θ角加密原始数据的结果,因此,攻击者很难还原出用户的真实数据.
成员推断攻击[20]用于判断输入的指定样本是否为训练样本集的一部分.攻击者将指定样本输入云服务器真实模型得到预测结果,同时攻击者也将指定样本输入模拟模型得到模拟预测结果,通过对比真实预测结果和模拟预测结果,再结合模拟模型推导出指定样本是否为训练样本集的一部分.由于本文算法中一个预测结果z反演回去对应N+1个输入数据,因此很难通过成员推断攻击判断输入的指定样本是否为训练样本集的一部分.
此外,很显然,模型逆向攻击和成员推断攻击都以模型提取攻击为前提,因此,在本文算法中,模型逆向攻击和成员推断攻击都较模型提取攻击更难成功.
4.3 输入数据隐私攻击
属性推理攻击是常见的一种针对输入数据隐私进行攻击的方式[21],体现了攻击者提取没有编码为特征或与机器学习数据集不相关的属性的能力.攻击者利用提取到的无关属性进行推理,进而得到数据集中有特征的属性值,例如通过癌症患者的性别等无关致癌的属性值推理出导致癌症指标的相关属性值.
在本文的隐私保护方案中,假设攻击者有能力获取到用户输入到云服务器量子模型的数据(训练样本集密文和待测样本密文),假设攻击者也知道客户端加密的方法,但客户端加密的密钥θ是保密的,攻击者基于以上2项已知信息,无法推导出原始数据明文.假设客户端多次将同一组数据送到量子云服务器进行分类运算,每次都采用不同的密钥加密数据,那攻击者也只能推导出任意2个密钥的差值θi-θj,这对还原出原始数据集的相关属性信息没有任何帮助.
此外,用户对原始数据集进行任意角度θ加密,会导致数据集中所有属性的特征分布都发生改变,攻击者利用加密后的数据集进行推理,也只可能推理出加密后的属性信息,无法推导出原始数据集的特征属性信息.
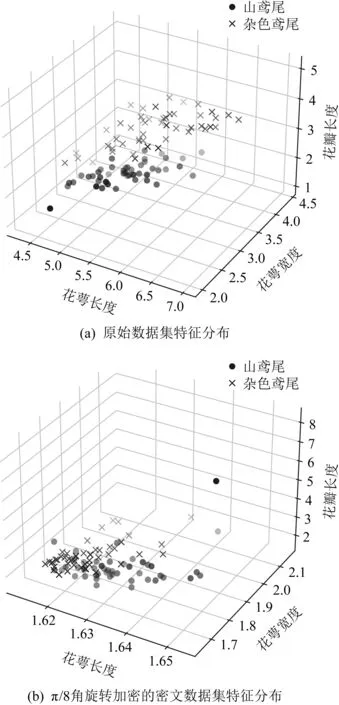
Fig. 2 Feature distribution of data set图2 数据集特征分布
IRIS数据集是常用的分类实验数据集,数据集中的每个数据包含4个属性(花萼长度、花萼宽度、花瓣长度和花瓣宽度),可通过4个属性预测鸢尾花卉的类别.本文选取了IRIS数据集中的2类花卉(山鸢尾与杂色鸢尾)作为数据隐私攻击分析的对象,考察每个花卉的3个属性(花萼长度、花萼宽度和花瓣长度),分别展示了原始数据集的特征分布和用θ=π/8角旋转加密后的密文数据集的特征分布.图2(a)是原始数据集的特征分布图,图2(b)是对原始数据集进行θ=π/8角旋转加密后的密文数据集的特征分布图.显然,θ角旋转加密操作使得原始数据集中各属性的特征分布发生了变化,攻击者利用密文数据集,很难推导出原始数据集的属性特征.
5 量子机器学习隐私保护方案对比
目前有关量子机器学习隐私保护的研究还比较少.Gong等人[10]提出了基于改进T门更新的量子同态加密方法,实现了基于云服务器的保护隐私[22]的量子K-means算法,该算法需要完全可信的第三方参与密钥的更新.Gong等人提出的量子K-means同态隐私保护方案资源花销较大,且对客户端的运算能力要求高,虽然引入了完全可信的第三方,但也造成了不稳定的因素.与之相比,本文保护隐私的量子KNN算法有4个优势:
1) 经典数据在输入量子算法前由客户端用户进行经典加密,服务端量子算法本身不需要改变,因此不会增加除经典加密之外的其他工作量,更不会增加量子算法的计算工作量.经典加密运算是简单的反三角函数运算(其作用相当于对输入量子态的一次U(θ)操作),不是复杂运算,也不会给用户带来过多的加密负担.而Gong等人使用的T门运算包含了其他基础泡利门(如泡利X,Y,Z门),其运算复杂度随着加入的量子门数量的增加而增加,运算准确度随着量子门数量的增加而降低(环境噪声影响).
2) 本文方案不涉及多次量子态叠加和去叠加,在运算过程中信息量的损失少.
3) 本文提出的隐私保护方法是基于量子构件的隐私保护,利用受控SWAP线路的运算特性,能对输入的原始数据集和密文数据集产生相同的输出结果,但云服务器只知道密文数据集,不知道原始数据集,从而实现隐私保护.本文方案的运算复杂度为普通量子KNN算法的复杂度,既实现了隐私保护,又没有增加整体分类算法的复杂度,也没有降低算法的可用性和准确性.
4) 本文提出的量子KNN算法的隐私保护方案操作简单,能够推广到其他量子机器学习算法中,而Gong等人的方案不具有一般性,只适用于某些特定的量子机器学习算法.
Du等人[5]提出了一种使用量子噪声来保护量子分类器免受对抗攻击的方法,在实现分类任务的量子电路里添加去极化噪声实现差分隐私保护,提高了量子机器学习的鲁棒性,并且鲁棒性会随着噪声的增大而增大,但由于量子噪声的不可控,也导致了使用该方法进行隐私保护时的不确定性.
与Du等人的方案对比:1)Du的方案使用去极化噪声添加到量子线路,存在量子噪声不可控、实现难度高、计算复杂度由不同机器学习任务而改变等问题;而本文提出的隐私保护方法操作简单、加密可控、易实现且计算复杂度低.2)Du等人的方案存在一定的局限性,只针对了差分隐私攻击进行隐私保护,没有对用户输入数据进行保护;而本文的方案直接对用户输入数据集进行保护,因此可以抵御常见的攻击.3)由于容错计算的要求,Du等人提出的方案中量子电路的规模与深度受到一定的限制;而本文提出的方案没有对量子机器学习过程添加噪声,可以适用于任意规模的量子机器学习算法.
Watkins等人提出了差分隐私保护的混合量子经典模型[8],能在不降低量子机器学习算法精度的同时实现对本地用户隐私的保护,并且在经典计算机上对该模型进行模拟和测试,证明了量子机器学习中使用差分隐私对数据进行保护时,仍然能保持模型的精度与机密性.
与Watkins等人提出的方案对比:1)Watkins等人提出的混合量子经典模型的隐私保护方案是在经典计算机上实现;而本文提出的方案则是在量子计算机运行实现,因此Watkins的方案在量子设备上的实现还需进一步研究.2)Watkins等人的方案是通过使用差分隐私的方法来对数据进行查询保护,由于差分隐私针对的是本地私有化查询,在云服务器的模式下该方法不能保护用户输入数据的隐私;而本文的方案在云服务模式下不仅能对用户输入数据进行隐私保护,也能抵御对数据的查询攻击.3)Watkins等人的方案使用高斯噪声进行差分隐私保护,由于噪声的不确定性,对不同量子机器学习任务进行保护时效果也各不相同;而本文的方案没有引入噪声,因此对不同的量子机器学习算法都具有普适性.
将本方案与现有量子机器学习隐私保护方案进行对比分析,如表1所示:
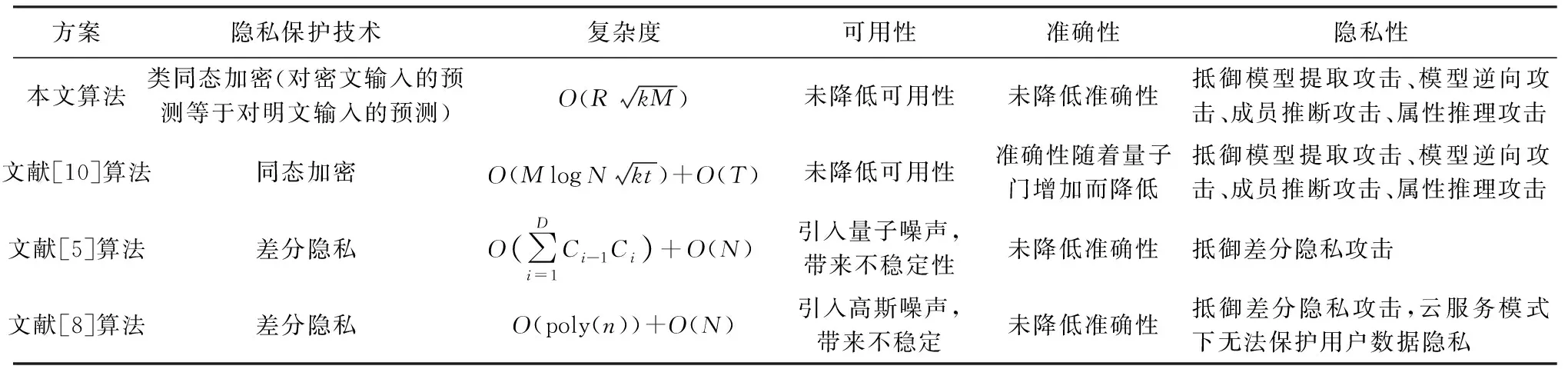
Table 1 Comparison of Quantum Machine Learning Privacy Protection Schemes
因此本文提出的量子KNN算法隐私保护方案与量子KNN算法相比,在保证复杂度相同的情况下,能达到隐私保护的目的,与目前已有的量子机器学习隐私保护算法相比,有易实现、计算复杂度低等特点,并且只需用户和云服务器两方即可完成,无需第三方的加入.综合比较可以得出,本文提出的方法能以更简单的运算达到隐私保护的目的,并且不会引起算法复杂度的提升以及较多的信息损失.
6 结 论
本文提出了保护隐私的量子KNN算法,找到了一种对原始训练样本集和待测样本的加密方法,使得输入密文样本可以得到与输入原始样本相同的预测结果.从模型提取隐私、预测结果隐私和输入数据隐私等3个方面分析本文方案的隐私安全性,发现在本文方案中攻击者很难获取与模型、预测结果和输入数据相关的隐私信息.与已有的量子机器学习算法的隐私保护方案[5,8,10]对比,本文隐私保护方案在隐私性、复杂度、可用性等3个方面均优于已有方案,实现了保护隐私性的同时,不增加额外计算开销,不降低算法效率和可用性,不影响算法准确性.
作者贡献声明:昌燕负责算法设计;林雨生负责安全性分析;黄思维负责文献整理;张仕斌负责整体文字把关.
