基于动态MDONPE算法的间歇过程故障检测
2022-05-08赵小强
赵小强, 刘 凯
(1. 兰州理工大学 电气工程与信息工程学院, 甘肃 兰州 730050; 2. 兰州理工大学 甘肃省工业过程先进控制重点实验室, 甘肃 兰州 730050; 3. 兰州理工大学 国家级电气与控制工程实验教学中心, 甘肃 兰州 730050)
近年来,随着工业自动化的快速发展,工业系统大规模、高度复杂化的特点使得系统故障发生的几率大大增加.在实际生产过程中,由于间歇过程生产的产品种类多、规格高、性能优、规模化生产比较灵活、工艺容易改变等优点,间歇生产比连续生产更加普遍,因此间歇过程故障检测变得愈加重要.间歇过程特性复杂,通常非线性和动态特性同时存在,影响故障检测的实时性和检测精度,因此针对这些特性进行有效的故障检测,对保障整个过程的安全生产具有十分重要的意义,成为国内外学者研究的热点.
诸如主元分析(principal component analysis,PCA)、独立元分析(independent component analysis,ICA)、偏最小二乘(partial least squares,PLS)等基于数据驱动的多元统计方法在工业过程故障检测和故障诊断方面应用广泛.复杂的现代工业生产使得传统多元统计建模的方法监控不利,流形算法作为新的数据局部降维算法得到广泛关注,如局部保持投影(locality preserving projections,LPP)和邻域保持嵌入(neighborhood preserving embedded,NPE)在数据可视化、计算机视觉、模式识别、过程监控等领域得到大量的应用,这些流形算法都是通过数据的局部特征获取整体的流形特征.Hui等[10]针对邻域保持嵌入算法忽略全局特性信息,建立了全局-局部的目标函数,有效处理数据结构信息,在间歇过程故障检测过程中取得了较好的效果;杨健等[11]将时序约束引入NPE算法,改善了由于数据动态特性导致监控不利的问题;Jiang等[12]将概率加权策略引入到流形降维过程中,有效地解决了有用信息的突出和无用信息的抑制问题,在化工过程监控中取得了较好的效果.但这些方法在故障检测过程中没有考虑投影向量非正交的问题,导致不能很好地提取数据的本征特征,增加了误差重构的难度,一定程度上影响了故障检测的精度和效果.
间歇过程故障检测中由于非线性特性使得检测效果不可靠的问题,仝奇等[13]利用神经网络对核主元分析法降维的数据进行训练处理非线性特征,对实际故障模型有很好的故障诊断效果;常鹏等[14]利用核熵成分分析(kernel entropy component analysis,KECA)进行白化处理,同时解决数据的非线性,在发酵过程得到了有效应用;赵小强等[15]在多向核领域保持嵌入(multiway kernel neighborhood preserving embedding,MKNPE)算法中引入统计模量(statistical pattern analysis,SPA)方法,可以充分提取非线性信息.这些算法在处理非线性过程时,存在神经网络泛化能力较差、训练过程复杂、引入核的方法增加了计算复杂程度的问题.张成等[16]通过引入延时测量值构成增广矩阵,一定程度上提高了动态特性过程的监视性能;张忠祥等[17]构造扩展数据动态扩展阵来考虑变量之间的相关性,在处理动态特性上具有较好的效果.这类构造扩展矩阵的动态处理方法,由于时滞关系的引入影响,并不能准确地检测到故障的发生.
因此针对由于间歇过程动态和非线性共存导致故障检测效果不佳的问题,本文提出了基于滑动窗的多向差分正交邻域保持嵌入(SW-MDONPE)算法.在考虑数据保持局部结构降维的同时利用正交约束条件保证输出基向量正交化,提高了数据的局部保持能力和特征提取能力;引入差分策略处理数据的非线性,避免引入核方法的计算复杂和神经网络方法训练过程复杂、泛化能力差的缺点;为了进一步处理数据动态特性对过程监测的影响,利用滑动窗对监测数据实现更新建模.SW-MDONPE算法通过青霉素发酵仿真平台模拟的间歇过程数据进行验证,结果表明SW-MDONPE算法比MPCA、KNPE算法检测精度更高,监测效果更好.
1 邻域保持嵌入算法
邻域保持嵌入算法是一种特征信息降维的方法,更加关注数据的局部结构,通过样本点与近邻点的欧式距离重构权重向量,从而保持数据的局部特性,获得数据的整体流形结构,发掘隐藏在高维数据的本征特征.邻域保持嵌入算法的步骤包括构造邻域图、计算权重矩阵和计算投影三步.
1) 构造邻域图.首先对给定的训练数据集X=(x1,…,xn)∈RD通过k近邻法寻找每个样本的欧氏距离最近的k个点,作为样本数据的近邻点,其中xi表示第i个结点,如果xj是xi的k个最近邻点之一,则邻域图中结点i到结点j连接;反之不具备邻域关系,则不连接,通过这样的关系就构成了邻域图.
2) 计算权重矩阵.利用近邻点重构系数矩阵W,W可通过下式最小化求解得到:
(1)
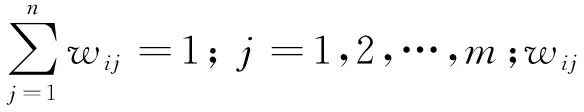
3) 计算投影.通过高维空间数据点xi的重构系数wij,可以在低维空间重构对应的数据点yi,投影矩阵A=(a1,a2,…,ad) 的求解为下式代价函数的最小化:
(2)
利用拉格朗日乘子法,将上式问题转化为下式求广义特征值的问题:
XMXTa=λXXTa
(3)
其中:M=(I-W)T(I-W) .
求解获得d个最小特征值,最小特征值对应的特征向量构成特征映射矩阵A,将数据X投影到低维空间Y:Y=ATX.
2 基于SW-MDONPE的间歇过程故障检测策略
2.1 数据预处理
2.1.1三维数据展开
间歇过程数据比连续过程多了一个“批次”维,构成三维形式,即间歇过程数据可表示为三维矩阵X(I×J×K),其中I表示批次,J表示变量,K表示时间.本文利用批次-变量(AT)法对三维数据进行展开,首先沿批次方向展开成X(I×JK),削弱了变量数据在时间轴方向的非线性,凸显批次方向的差异信息;然后对展开数据进行标准化处理再沿变量方向展开成X(IK×J),在线监测变量数据时无需考虑批次数据的完整性.AT法展开如图1所示.
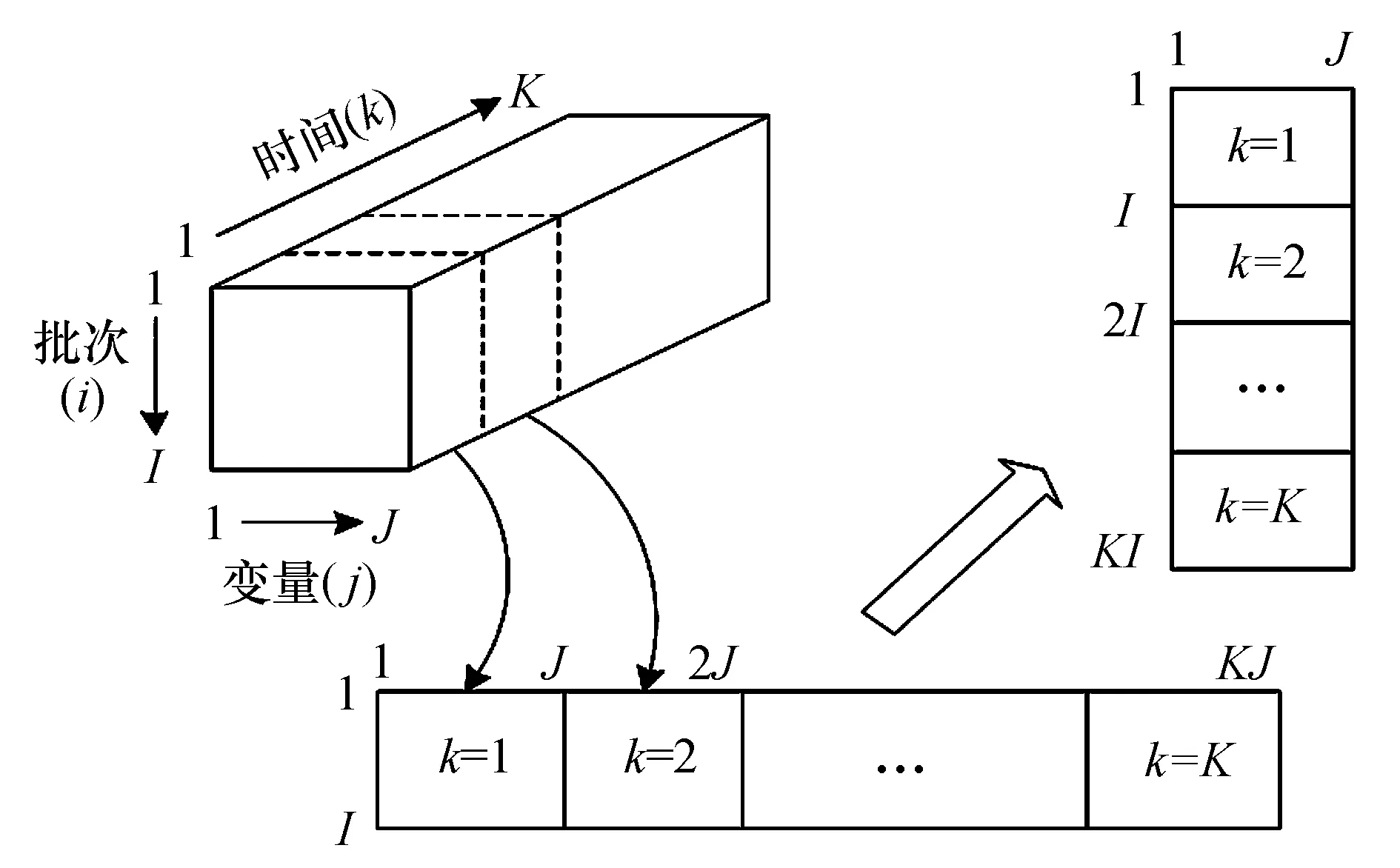
图1 三维数据展开方式Fig.1 Three-dimensional data expansion mode
2.1.2滑动窗
滑动窗是一种数据实时更新的处理方式,对采集到的数据相邻的几个数据界定为一个窗口进行处理,在下一时刻将得到的新数据填进窗口,并剔除掉上一时刻的历史数据,随着时间的推移,窗口不断填进新数据和丢掉旧数据,以此来提高构建模型数据的更新和检测的适应能力.图2所示为滑动窗的数据处理过程,当前时刻与前d时刻所有数据构成数据块,窗口沿着采样时刻线性滑动,不断更新数据块.

图2 滑动窗的数据处理过程Fig.2 Data processing process of sliding window
在实际生产过程中利用滑动窗可以有效地处理由于过程数据的动态特性引发的检测效果不佳的问题.对于训练数据添加滑动窗时,窗口宽度和窗口的移动步长选取要合适,滑动窗窗口宽度太小导致样本容量不足不利于核密度估计的效果,移动步长太大不能有效地跟踪数据的动态过程变化.本文选取滑动窗宽度d=5,可以达到检测精度要求[19].
2.2 正交邻域保持嵌入
传统NPE算法获取的投影基向量是非正交的,不利于构造过程预测误差,因此在NPE算法的基础上增加了一个正交化的约束条件,通过迭代计算得到相互正交的投影方向.经过正交约束的ONPE算法比传统NPE算法具有更好的局部保持特性.本文将正交邻域保持嵌入算法运用于故障检测中,投影后既保持了原始数据的流形结构,找到隐藏在高维观测集中更多内在的有用信息,还能够使得投影以后的向量正交.ONPE算法在NPE算法基础上改进如下:
在式(1)中加入正交约束条件:
aTa1=aTa2=…=aTak
(4)
其中:k=2,…,d.再利用拉格朗日乘子法包含的约束条件yTy=aTXXTa=1 求得:
1)a1是XXTXMXT的最小特征值对应的特征向量;
2)ak是Q(k)的最小特征值对应的特征向量:
(5)
式中:
S(k-1)=[a(k-1)]T(XXT)-1a(k-1)
a(k-1)=[a1,a2,…,ak-1]

ONPE算法是一种基于几何思想来描述数据特征的维度约简算法,可以在保持过程数据的局部特性的同时,避免局部空间的结构失真,具有更好的分类能力,适用于非线性系统,能更好地提取数据的本征特征.
2.3 多向差分邻域正交保持嵌入
过程数据的非线性特性使得原有的流形算法处理时将会导致丢失重要的信息.针对非线性数据处理的方法中,基于神经网络的方法其训练过程复杂,泛化能力难以保证;基于核方法能够有效处理数据的非线性,但引入核函数使得计算复杂,实时监测差;而差分方法解决非线性时计算简单、监测高效.
本文在ONPE算法的基础上引入差分策略,首先寻找样本的最近邻,通过样本数据与最近邻进行差分运算得到一个差分空间,将原来非线性的数据在差分空间线性化,再利用ONPE算法在差分空间充分提取模型的结构特征来建模,将差分空间分为特征空间和残差空间,分别建立统计量进行过程监控,可以在充分提取数据局部结构的同时有效地处理非线性特性.
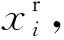
(6)
经过式(6)差分后所得差分空间数据可由下式表示:
(7)
在差分空间的每个样本寻找近邻点重构样本点,通过下式定义重构误差:
(8)
其中,权重系数约束条件为
通过求解下式的广义特征值,并在式(8)的基础上引入正交约束条件,得到最小的特征值对应的特征向量构成映射矩阵Aod=(a1,a2,…,an) :
(9)
其中:
Md=(I-Wd)T(I-Wd)
则原始数据X通过降维后的数据表示为
2.4 检测统计量
通常检测过程需要假设过程观测数据服从多元正态分布,然而当数据不服从正态分布时,会出现大量的漏报、误报情况.为了削弱对数据高斯分布的严格要求,利用核密度估计(KDE)方法确定检测统计量,T2统计量的分布可以通过下式来估计:

(10)
其中:h为窗口的宽度;n为观测数据的个数.本文选取高斯核函数,利用最佳窗宽的方法,确定最佳窗宽为3.33[25].
KDE方法能够估计T2和SPE度量的潜在概率密度函数(PDF),本文给出的置信区间为95%,即占据了这两个密度函数95%的面积.95%置信限C与显著性水平α=0.05可由下式确定:
(11)
故障检测过程中合理的控制限为故障是否发生提供了决策准则,因此需要计算极限值来确定整个过程是否处于被控状态.SW-MDONPE算法将数据划分为特征空间和残差空间,通过构造T2统计量衡量特征空间的变化情况对特征空间进行监控,SPE统计量考虑变量相关性被改变的状况对残差空间进行监控.对于新产生的数据Xnew通过投影得到低维空间数据ynew,则对应的统计量T2和SPE通过下式得到:
其中:Λ表示降维样本Y的协方差矩阵;A为投影矩阵.
2.5 基于SW-MDONPE故障检测的算法实现
基于SW-MDONPE故障检测包括离线建模和在线检测两个过程,其检测策略如图3所示.

图3 检测策略图Fig.3 Detection strategy diagram
1) 离线建模
(1) 选择一定数量批次的数据X(I×J×K)构成训练数据集,利用(批次-变量)AT法展开为二维矩阵X(KI×J);
(2) 对数据加恒定窗宽的滑动窗构成新的数据矩阵X1;
(3) 利用最近邻差分求得差分矩阵DX;
(4) 根据式(9)得到映射矩阵Aod;
(5) 根据式(11)计算数据的T2和SPE统计量;
(6) 利用KDE确定T2和SPE的统计量控制限.
2) 在线检测
(1) 获取在线检测数据Xnew对应的窗口数据进行标准化处理;
(2) 将窗口的检测数据投影到低维映射空间,得到新的投影矩阵Anew;
(3) 根据式(12,13)计算数据的T2和SPE统计量;
(4) 用检测数据的统计量与训练样本核密度估计的控制限作对比,若超过判定为故障发生,否则视为正常过程.
3 仿真结果与分析
青霉素是一种广泛应用于临床医用的抗生素,其发酵过程是典型的间歇过程.为了便于对间歇过程特性分析和数据监控,本文选择美国芝加哥伊利诺伊理工学院Birol等人设计的Pensim2.0仿真平台产生模拟间歇过程[26],该仿真平台通过对初始条件的设置产生不同状况批次数据,除了可以产生多个批次的正常工况数据,也可以通过对故障的类型以及引入故障和结束故障的时间得到故障数据集.Pensim2.0仿真平台可以设定通风速率故障、搅拌功率故障和底物流速率故障三种故障类型,引入的故障信号类型有阶跃信号和斜坡信号,可以有效模拟各个变量在多种不同操作条件下的动态特性和非线性特性,由于整个发酵过程受pH值和温度影响最为显著,因此在设定值时采用闭环的PID控制器进行控制,而进料过程则为开环控制.本文选取平台18个变量中的10个变量作为实验检测变量,其为:通风速率,L/h;搅拌功率,r/min;底物流速率,L/h;底物流温度,K;底物浓度,g/L;溶解氧浓度,%;反应器体积,L;二氧化碳浓度,mmol/L;pH值;发酵罐温度,K.
在青霉素仿真发酵平台采集30批正常工况的数据作为训练样本,设定各批次反应时间为400 h,设定采样间隔为1 h,为了使更加逼近实际工程情况的扰动,在过程数据添加高斯白噪声,得到X(30×400×10)的训练数据集;本文引入故障类型1(通风速率故障)的+20%的阶跃信号,引入故障时间为100~300 h的工况作为检测样本数据,分别对MPCA、KNPE和本文提出的SW-MDONPE算法进行验证.
MPCA的T2和SPE统计量的检测结果如图4和图5所示,由检测结果图可以看出,MPCA的T2统计量只在100~300点处个别位置检测到故障的发生,而在未发生故障的0~50点和300~400点阶段产生大量的误报警现象;SPE统计量能够检测到大部分的故障点,但在刚开始0~100点内误报严重,在300~400点处也有部分误报警.
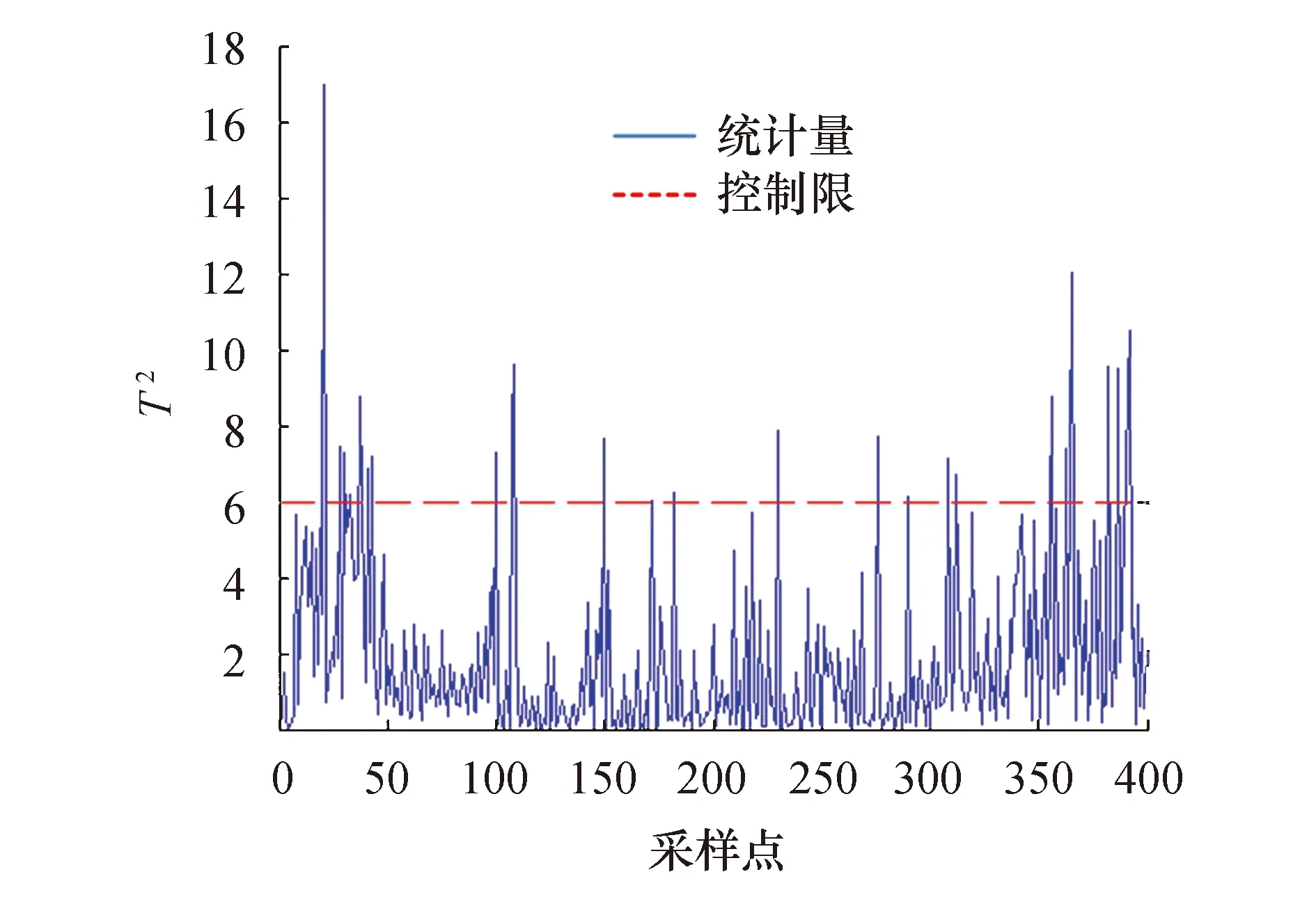
图4 MPCA的T2统计量的检测结果图Fig.4 Detection result graph of T2 statistics of MPCA

图5 MPCA的SPE统计量的检测结果图
KNPE的T2和SPE统计量的检测结果如图6和图7所示,可以看出,KNPE的检测效果较MPCA好,可以检测出大部分故障,但T2统计量检测漏报明显,在0~100点处也有许多误报;SPE统计量在0~50点内产生少量误报现象,故障过程也有漏报现象产生.
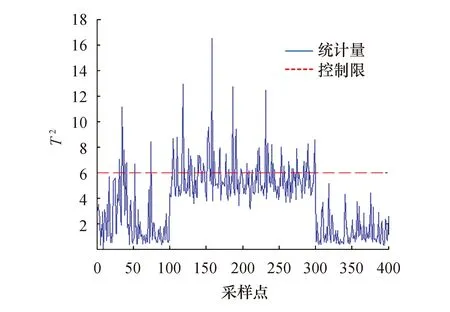
图6 KNPE的T2统计量的检测结果图Fig.6 Detection result graph of T2 statistics of KNPE

图7 KNPE的SPE统计量的检测结果图Fig.7 Detection result graph of SPE statistics of KNPE
图8和图9为本文所提出SW-MDONPE的T2和SPE统计量的检测结果图,可以看到,SPE统计量并未发生漏报和误报警的情况,T2统计量在0~50点处存在微小故障的误报警现象.本文所提方法的T2和SPE统计量在100点处迅速检测到故障的发生,较其他的方法漏报、误报率更低,检测效果更好.各方法的误报率、漏报率和检测率见表1.
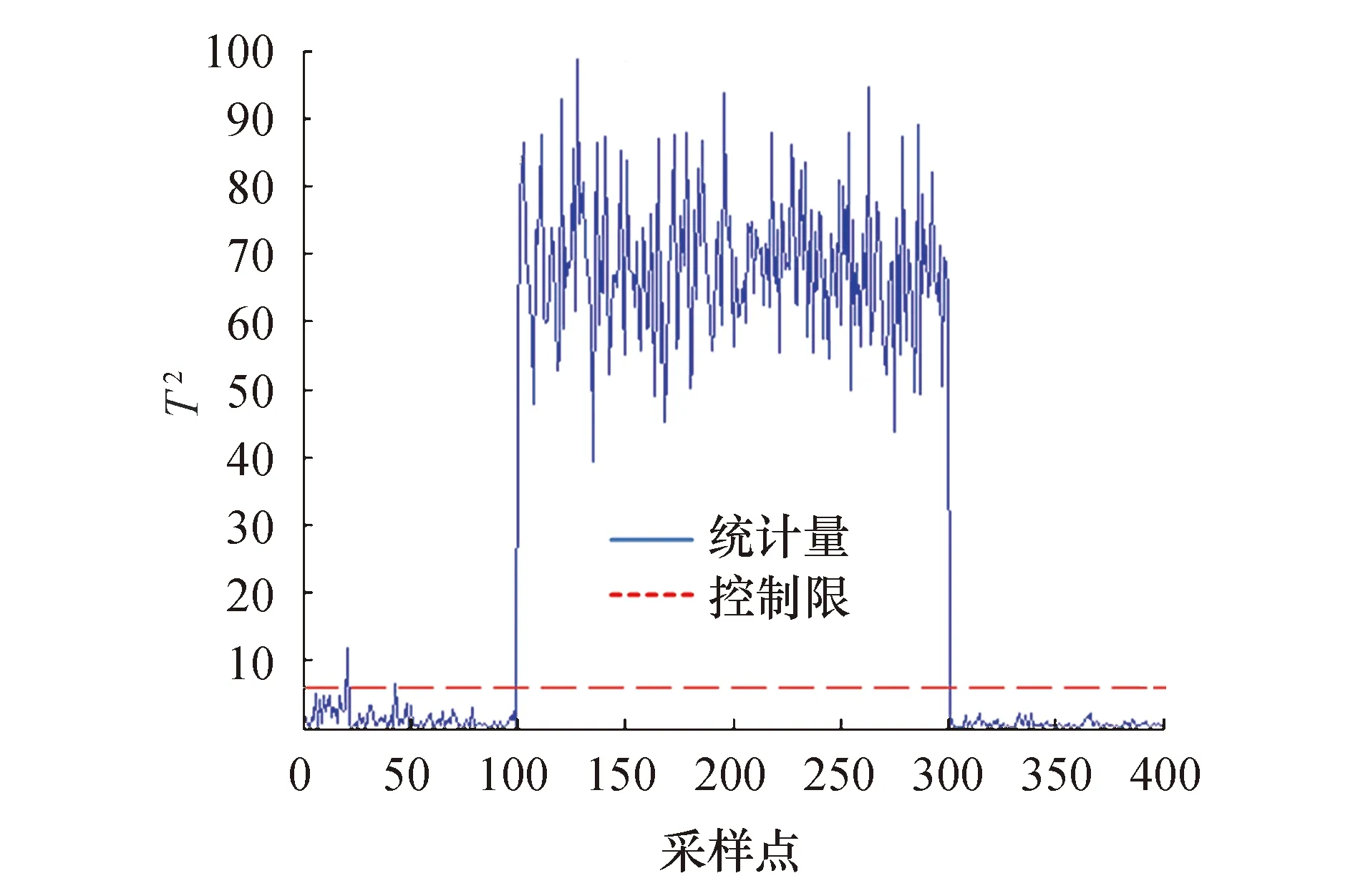
图8 SW-MDONPE的T2统计量的检测结果图Fig.8 Detection result graph of T2 statistics of SW-MDONPE

图9 SW-MDONPE的SPE统计量的检测结果图 Fig.9 Detection result graph of SPE statistics of SW-MDONPE

表1 各类方法的故障检测统计结果
由表1可以看出,本文所提SW-MDONPE算法较MPCA、KNPE具有较好的检测效果,MPCA很难准确检测到故障的发生,是因为反应过程中发生的随机性变化产生的数据具有很强的非线性,使得线性的MPCA检测效果较差;KNPE在核空间内提取数据的低维流形结构,在非线性过程故障检测中优于线性的处理方法;SW-MDONPE处理非线性的同时关注了数据的动态特性,因此在过程故障检测中效果更好.
4 结论
间歇过程数据非线性、动态特性并存的复杂特性影响着间歇过程的故障检测的效果,本文提出了基于滑动窗的多向差分邻域正交保持嵌入(SW-MDONPE)算法,利用正交邻域保持嵌入提高了局部保持和特征提取能力,并结合差分策略处理系统的非线性,同时引入滑动窗处理数据的动态特性对间歇过程进行故障检测.通过青霉素仿真过程与MPCA、KNPE比较,验证了该算法对故障检测的有效性.
