基于支持向量机的汽油辛烷值预测研究
2022-05-08罗维平曹长昕
罗维平, 曹长昕
(1.武汉纺织大学 机械工程与自动化学院, 湖北 武汉 430200;2.湖北省数字化纺织装备重点实验室 湖北 武汉 430200)
0 引言
在工业成品汽油生产过程中,反应汽油燃烧性能的最重要指标就是辛烷值,辛烷值越高,原油利用率越高。目前国内大部分汽油都是对原油进行催化裂化生产得到,而在工业进行催化裂化原油过程中普遍降低了辛烷值,在一定程度上造成了原油的资源浪费。在工业提纯过程中,工厂各个工序只是简单地进行线性搭配,而机械与用料之间并不只是简简单单的线性关系,这种粗略的线性关系导致了原油辛烷值降低,增加了企业成本。部分企业通过实验来测定调试汽油样品辛烷值,不仅需要花费大量的时间与人力,还需要价格不菲的实验仪器与样本试剂,因此,需要一种准确的辛烷值预测模型在为工业提纯机械与用料之间的搭配建立基础。
对于汽油辛烷值的预测目前主要有3种方法:第一种方法是传统方法,主要对汽油从分子层面进行研究[1]。第二种方法是利用仪器对汽油组成成分进行分析。王拓等[2]使用偏最小二乘法提取汽油拉曼光谱特征谱段,结合研究法对辛烷值进行定量分析,但模型整体精度偏低;孙中奇等[3]基于拉曼分析技术设计了汽油调和过程中辛烷值的测定系统,能有效测量汽油辛烷值,对辛烷值的预测提供一定的帮助;丁怡曼等[4]将红外光谱法结合偏最小二乘法建立了辛烷值快速预测方法,该方法操作简单,速度快,但预测准确率不高。第三种方法是利用汽油辛烷值数据进行模型预测。蒋伟等[5]通过构建随机森林模型实现对汽油辛烷值的预测,但只采用了单一模型进行预测,没有进行多种模型的比较选优过程;高萍等[6]通过构建BP神经网络能够较好地预测提纯工业步骤中的辛烷值损失,但不能实现对最后辛烷值的预测功能。
针对上述问题,考虑到各机械与用料之间的非线性关系,以及根据人工和通过传统的统计方法所选取的特征对模型精度有较大的影响,造成现有的辛烷值预测模型精度较低的现状,本文提出一种基于特征工程[7]作为模型特征选择,以及通过对Xgboost[8]和支持向量机[9]进行比较去劣择优的方法,以得到精度较高的辛烷值预测模型。
1 数据来源
本文的数据来源于某一大型石化企业。该企业通过对工业生产中的催化裂化汽油精制脱硫装置进行实时跟踪测量,每隔3 min完成1次记录,对2 h的数据进行取平均值的操作,获得325个样本的原始数据。
原始数据中的每一个样本包含了原油的辛烷值、硫含量等7个主要组成成分,催化裂化汽油精制脱硫装置的354个操作变量主要信息,经过工业脱硫和降烯烃过程后的成品汽油的辛烷值与硫含量以及待生吸附剂性质和再生吸附剂性质共计367个变量,是目前工业中对原油进行处理且包含装置信息的较为全面、颇具权威的数据集。
2 数据预处理
通过对该企业所提供的数据集进行整体观察,发现数据集中存在因人工记录失误或者计算错误等而造成缺失值与异常值等问题,需要对数据进行清理筛选,整理出一份较为完美的数据集,有助于后续的建模分析等流程。数据清洗流程如图1所示。
2.1 数值范围检测
数据清洗的第一步是对数据集的缺失值进行处理。观察数据发现有不少变量的记录值为0,但不排除变量本身的值为0。在缺失值填补之前,需要根据该石化企业通过实验获得的变量取值范围,对每一个变量的数值进行对比筛选,部分变量取值范围见表1。对不在其变量取值范围内的值,采用均值填补的方法。
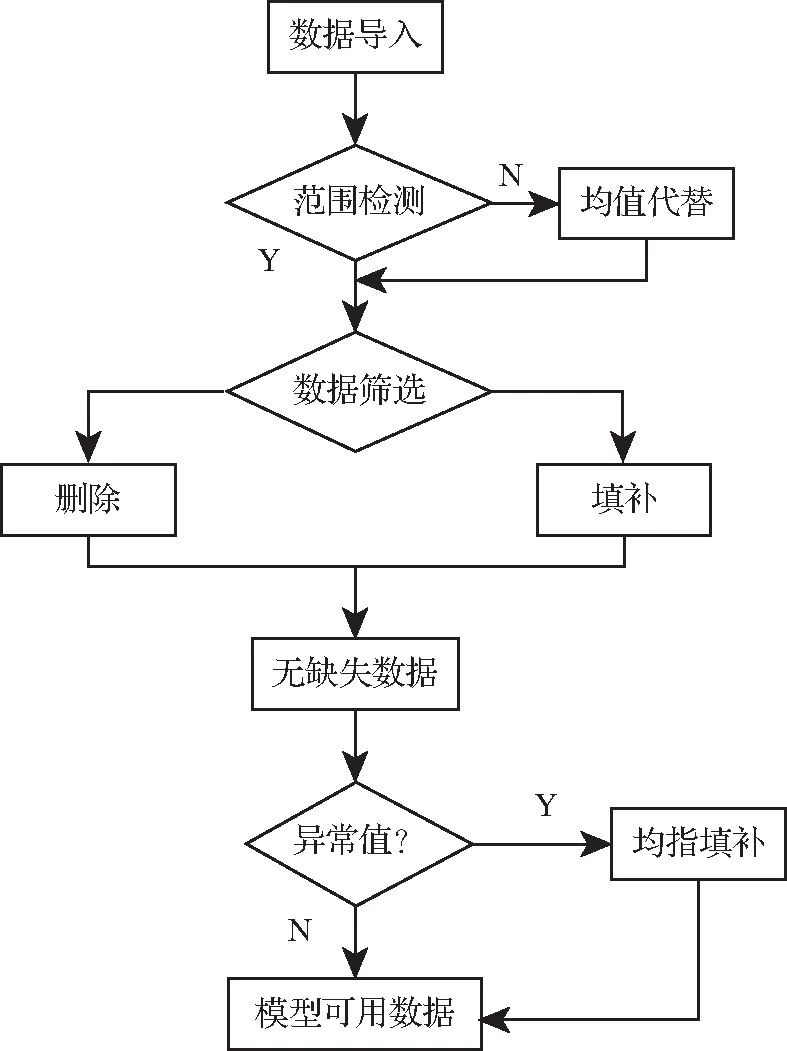
图1 数据清洗流程Fig.1 Data cleaning process

表1 变量取值范围Tab.1 Variable value range
2.2 数据筛选
范围检测完成之后,再次观察数据,进行缺失值填补。当某一变量的缺失值过多时,无论采用任意一种填补方式,其数值都不能较好地表达变量的变化趋势,将其视为无用的特征变量进行删除;当缺失值在合理范围之内时,需要对其进行填补。目前缺失值填补主要分为单变量缺失值插补和多变量缺失值填补两大类,主流的单变量缺失值插补方法主要有众数填补、平均值填补、中值填补以及上、下值填补,但这些方法或多或少会改变数据的原始分布,造成一定量的模型误差。本文采用多变量缺失值填补方法对辛烷值数据的缺失值进行填补。
随机森林是目前较为主流的机器学习集成算法,分为分类和回归2种用法,其主要思想为内部使用多个弱决策树,结合Bagging(装袋算法)方法以及特征子空间,通过随机抽样的方法在建模过程中抽取样本,通过投票的方式决定模型输出结果。由于模型的处理机制特殊,随机森林回归算法对缺失值以及噪声点具有较好的容错率,不容易过拟合,因此采用随机森林填补缺失值。
对于拥有n个特征的辛烷值数据集,其中多列存在缺失值,遍历所有特征,从缺失值最少的开始填补,将其他特征的缺失值暂时用0代替,每完成一次模型预测,就将预测值放入到特征矩阵,再进行下一次的缺失值预测填补,逐渐完成所有缺失值的预测填补,得到完整的数据集。
2.3 异常值检测
完成对缺失值的填补后,通过对变量绘制核密度图观察数据分布情况,部分变量核密度图如图2所示,分别以汽油中的硫含量和饱和烃为例。

(a)硫含量 (b)饱和烃
由图中可以看出,变量中依旧存在离群值,需要对其进行处理。本文采用孤立森林的方式进行离散值处理。孤立森林算法随机递归分割数据集,直到所有的数据均为离群值则停止运行,而离群值相较于整体数据来说偏离数据分离点,更容易被分割,所以使用较少次数分割出来的点即为离群值。采用孤立森林算法后,硫含量分布情况如图3所示。图中方形点即为硫含量中的离群值,对于孤立森林捕捉到的离群值,算法中所自带的接口可以对其索引进行缓存帮助修改。
通过数据检测到异常值检测的操作,对该数据有一个较为完整的清洗流程,得到一个共计346变量的、相对于之前较好的辛烷值数据集,有利于后续的数据降维与建模分析。

图3 硫含量分布情况Fig.3 Sulfur content distribution
3 降维
主成分分析(principal component analysis)是一种用来探索高维数据结构的技术,一般被用来实现高维的数据集的探索与可视化以及用来进行数据压缩。
本文中的辛烷值数据集,除去标签共计345个特征变量,在高维数据的情况下会出现数据样本稀疏,距离计算困难等问题,更容易导致模型的过拟合问题,被统称为维度灾难。PCA的本质就是找一些投影方向,且这些投影方向是相互正交的,使得数据在这些投影方向上的方差是最大的。方差越大,说明其在对用正交基上包含更多的信息量,证明原始数据协方差矩阵的特征值越大,对应所包含的信息越多。
根据PCA降维的原理,可以分为以下几个计算步骤:
①对数据进行标准化处理,转化为无量纲的纯数值,去除单位的限制,便于不同量级的指标之间能够相互比较。
(1)
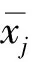
②计算相关系数矩阵。
(2)
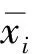
③对相关系数矩阵进行求解,得出其特征向量和特征值。
④进行主要成分提取。根据累积贡献率进行特征提取,主成分zi的方差贡献率为
(3)

图4 主要成分和累积解释方差Fig.4 Main components and cumulative explanatory variance

利用PCA降维对原始辛烷值数据集进行降维,其方差贡献率如图4所示。从图中可以明显看出,当提取36个主要成分之后,剩余提取特征对原本数据的解释能力几乎为0,单解释方差曲线趋向于平滑,所以决定提取36个主要成分,由原来的345个特征变量通过PCA降维,成功降到36个特征变量。
4 模型建立
本文要解决的问题为回归预测问题,所以根据问题选择目前较为主流的支持向量机回归以及Xgboost2种回归算法进行预测对比,使用k折交叉验证(k-fold cross validation)对模型的稳定性及其对数据集外的数据的泛化性进行验证,再通过模型评估指标MSE(平均均方误差)以及R2(决定系数)对模型进行评估,选取最优模型。模型构建流程如图5所示。

图5 模型构建流程Fig.5 Model building process
4.1 支持向量机
不同于上文介绍过的随机森林回归,支持向量回归(SVR)是由支持向量机(SVM)从分类问题推广到回归问题,SVM分类是找到超平面,让2个分类集合的支持向量或者所有数据离分类平面最远;SVR回归不同于SVM的是使得集合内所有数据到平面的距离最近,具体为回归预测值f(x)与真实值y之间得偏离程度不大时,即可以认为预测正确,损失不用计算。
关于SVR的问题可以简化为
(4)
式中:C是正则化参数;ε为ε-的一个不敏感损失函数,
(5)
SVR能较好地解决局部最优问题,并且有较优的抗过拟合能力。使用该模型时,核函数的选取也是一个重要的影响因素,选择合适的核函数能更好地拟合数据,得到更好的回归预测值,有较低的模型损失。
4.2 Xgboost模型
Xgboost模型(eXtreme gradient boosting)是一种tree boosting的可拓展机器学习系统,旨在通过结合k个精度较低的回归树组成一个高精度的模型,使得树群的预测值尽量接近真实值,具有较高的准确率,并且有很强的泛化能力。其目标函数为传统的损失函数加上模型复杂度:
(6)

(7)

4.3 评价标准
对于辛烷值的预测,本文更关注辛烷值的预测值与原本的真实值之间的误差,所以采用均方误差(mean squared error,MSE)作为模型评价指标,
(8)

R2也可以作为另外一种参考的指标,
(9)
5 实验结果与分析
5.1 实验结果
将通过有效性处理后的数据输入本文所选取的2种算法,再分别对其进行10折交叉验证,利用模型评价指标对各模型效果进行评估,结果如图6所示。
由图中数据可得,在未进行参数调优之前,在R2指标上,SVR的值明显大于Xgboost的;而在均方误差上,SVR的值小于Xgboost的,模型的损失较小,SVR模型性能整体高于Xgboost,因此本文基于SVR构建辛烷值预测模型。
5.2 模型改进
SVR主要核函数有4种,分别为linear、poly、rbf、sigmoid,使用不同核函数得到的模型精度如图7所示。由图中数据可知,rbf核函数的R2值最大,平均误差最小,所以选取rbf核函数作为本文模型的核函数。
SVR模型的内置参数有2个,分别为C和γ。C,即为惩罚系数,表示对误差的宽容度,C值越大,表示对误差的容忍度越低,越不能容忍出现误差,过拟合的风险越大;反之,则表示容忍度越高,容易出现欠拟合,惩罚系数过大或者过小,模型的泛化能力都会变差。γ是选择rbf核函数之后函数自带的参数,隐含的表示了数据映射到新的特征空间的分布,γ越小,支持向量越多;反之,则支持向量越少。

图6 2种模型评估指标对比效果Fig.6 Comparison of evaluation indexes of two models

图7 不同核函数模型精度对比Fig.7 Comparison of accuracy of different kernel function models
使用学习曲线选取最优参数,模型学习曲线如图8所示。

由图8数据可知,当参数γ、C分别取0.08、17时,模型效果达到峰值。通过调整参数后,模型精度达到84.36%,平均误差降到0.169。结合表2可知,当采用随机森林结合孤立森林进行数据筛选后,通过改进模型得到的模型精度相对于普通数据处理方式使用未改进模型后的精度有较大的提升。

表2 模型精度对比Tab.2 Comparison of model accuracy
图9、10分别为调参前后模型预测效果图,三角号为真实值,星号为预测值,两者的覆盖率表示模型预测的准确度。相比于图9,图10中的预测值与真实值两者相交范围明显扩大,表明准确率有明显提升。相应的模型调优前,存在部分偏离正常范围的数值点,形成孤立现象;调优后,部分偏离的真实值与预测值之间产生交集或者两者之间距离缩短,表明误差减小,可以很好地预测数据。
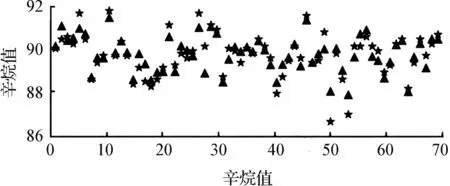
图9 调参前模型预测效果Fig.9 Rrediction effect of model before parameter adjustment

图10 调参后模型预测效果Fig.10 Rrediction effect of model after parameter adjustment
5.3 模型比较
以目前国内普遍的辛烷值预测方法红外光谱测量法以及拉曼光谱结合偏最小二乘法作为比较对象,红外光谱测量法即通过红外光谱分析技术,分析已知辛烷值的汽油产品的特征基团和表征结构的近红外光谱参数,使用多元线性回归的方法结合马达法、研究法以及主成分分析来预测辛烷值。比较结果见表3。

表3 模型预测误差比较Tab.3 Comparison of model prediction error
结合表3发现,在最小误差上,本文所建立的模型预测结果与马达法以及研究法相差不大,但在最大误差以及平均绝对误差上均小于其他2种方法;而在模型R2的比较上拉曼光谱结合偏最小二乘法略高于主成分分析法以及本文所建立模型,但本文所建立的辛烷值预测模型的平均绝对误差远小于另外两者方法,可见本文所建立的模型表现要优于其他4种方法。
6 结语
本文将特征工程应用到辛烷值预测模型特征处理与选取上,不同于一般的数据处理方式,采用随机森林与孤立森林结合的方法,对缺失值与异常值进行有效处理,使得样本数据更加精确合理。使用PCA降维的方式,分析特征对原始数据的解释能力,通过特征累积解释方差进行特征提取,使得所选取的数据特征契合不同算法,较好地提升了模型对数据的预测能力与泛化效果,对模型的预测精度有较大的提升。通过对Xgboost与SVR的模型评估指标对比与参数调优,进行弃劣留优操作选出效果最优模型,使得模型整体精度达到84.36%,平均误差降到0.169。通过本文所构建的预测模型可以对汽油辛烷值进行更好的预测,降低工业辛烷值提纯的损失,为后续工业辛烷值提纯设备需求数据的完备提供可能。
由于辛烷值样本数据量不够完备,因此预测模型在辛烷值预测性能中未能达到理想的效果。在以后将进一步对辛烷值预测模型进行深入研究,提升其预测精度。
