基于模糊决策的快速星图识别
2022-05-07王华超程昊文彭喜衍
王华超, 刘 静, 程昊文, 彭喜衍
(1. 中国科学院国家天文台, 北京 100101; 2. 中国科学院大学天文与空间科学学院, 北京 100049)
0 引 言
空间碎片的危害已成为国际关注的热点问题。为了保障空间安全,需要对空间态势进行常态化监测。常用的监测手段主要有两种:基于雷达的无线电探测和基于望远镜的光学观测。光学观测在空间碎片探测中起着重要作用。光学观测后可以得到光学图像数据,经过处理可以得到空间碎片的高精度位置信息。由于空间态势感知的时效性要求很高,需要快速处理海量的图像数据,这对光学图像处理算法的速度和精度都提出了挑战。
光学图像处理普遍采用天文定位的方法来计算空间碎片的位置,我们将关注的空间碎片称为目标。天文定位是一种相对定位的方法,其利用电荷耦合器件(charge-coupled device, CCD)相机图像中目标星像与背景恒星的相对位置,依据恒星星表得到背景恒星的精确位置,构建映射关系(又称为底片模型),计算目标的位置坐标。将图像中的恒星和已知星表中恒星建立一一对应关系,这一过程称为星图识别(星表匹配),是天文定位过程的关键步骤。由于图像中往往有数百甚至上千颗恒星,成像过程伴随着多种误差的影响,这导致星图识别的复杂性大大增加,直接影响了天文定位处理的速度和精度。
星图识别可以视为一个模式识别问题,目前工程中常用的是三角形匹配法。三角形匹配法是以三角形为基元,将光学图像中的恒星组成的三角形和星表中的恒星组成的三角形在一定容差范围内进行匹配。三角形匹配成功后,即可为图像三角形包含的三颗恒星找到对应的星表恒星,从而星图识别成功。三角形匹配算法实现简单,但由于识别过程被简化,易出现伪匹配,且不易纠正。很多人在此基础上改进了匹配的速度、精度和鲁棒性。有人提出了金字塔算法,采用四颗星进行星表匹配。虽然提高了处理精度和稳定性,但对于视场内恒星较多的情况,算法的处理速度将大大降低。有人提出了快速三角形匹配算法,重新定义了三角形表示的参量,通过按参量排序,选择三角形密度稀疏的区域进行匹配识别,大大降低了匹配出错的几率。
我们实验分析发现,由于望远镜指向误差的存在,快速三角形匹配方法仍然无法避免误匹配问题。另外,实际应用中的图像会有一些噪点(假恒星),求解底片模型需要匹配上足够的三角形,即使指向误差较小,随着匹配三角形个数的增加,该算法也难以避免匹配出错。我们在此基础上进行了改进,增加了模糊投票法来提高星表匹配的准确性,从而提出一种基于模糊投票的新星图识别方法,在不显著提高计算复杂性的同时提高星图识别的准确性。
1 改进的快速三角形匹配方法
1.1 快速三角形匹配算法的误匹配问题
为了提高三角形匹配的速度,Tabur于2007年提出了快速三角形匹配算法。该算法重新定义了三角形,用(,)表示,定义如下:
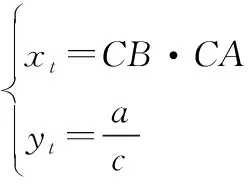
(1)
式中:、、为三角形的三个顶点,和为最长边,为中长边,为最短边。三角形的第一个分量是最长边和中长边的向量点积,第二个分量是最长边和最短边的边长比值。相较于Groth的三角形算法,该公式引入了图像的像素比例尺,需要从图像文件的头信息中读取。图像恒星可以由比例尺计算得到角度位置,从而和星表恒星的表示方式一致。引入比例尺后,数值的分布区间更大,降低了三角形的分布密度,也可以大大减少需要匹配的三角形个数。基于以上公式画出了三角形的分布情况,如图1所示。
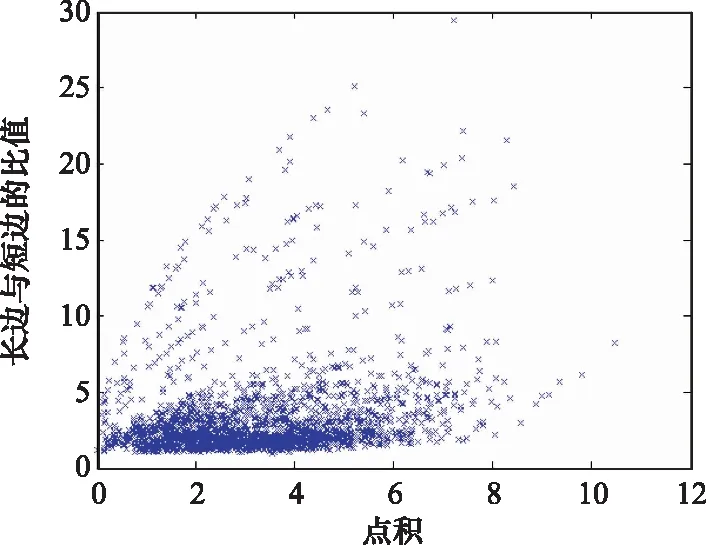
图1 快速三角形匹配算法的三角形分布Fig.1 Triangle distribution in fast triangle matching algorithm
从图1可以发现,在定义的三角形空间中,值越大,恒星密度越小,匹配出错概率越低。因此,作者提出了快速三角形匹配算法。该算法用来对三角形进行排序,优先选择值大的三角形进行匹配,匹配成功一定数量后即退出。值大的区域三角形密度比较低,需要匹配的数量很少,因此可以大大提高匹配的速度。为了提高搜索三角形的速度,该算法还采用了高效的二分法进行搜索匹配。
快速三角形匹配算法的介绍如下。
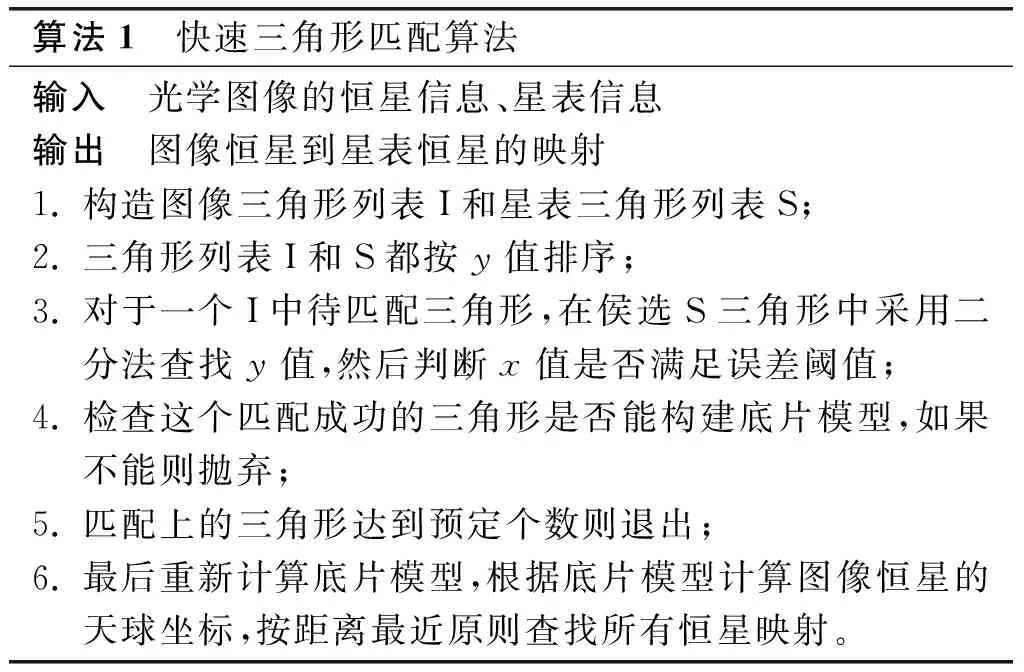
算法1 快速三角形匹配算法输入 光学图像的恒星信息、星表信息输出 图像恒星到星表恒星的映射1. 构造图像三角形列表I和星表三角形列表S;2. 三角形列表I和S都按y值排序;3. 对于一个I中待匹配三角形,在侯选S三角形中采用二分法查找y值,然后判断x值是否满足误差阈值;4. 检查这个匹配成功的三角形是否能构建底片模型,如果不能则抛弃;5. 匹配上的三角形达到预定个数则退出;6. 最后重新计算底片模型,根据底片模型计算图像恒星的天球坐标,按距离最近原则查找所有恒星映射。
该算法认为,三角形匹配是在三角形分布稀疏区域进行的,最后选择的三角形匹配都是正确的,因此识别的恒星集合直接用于底片模型计算。但在实验中发现:在望远镜的指向比较准确时,上述的快速三角形匹配算法确实能够达到很好的效果;而在实际应用中,我们并不能保证望远镜一直保持良好的机械精度,该算法在指向误差较大时效果并不理想。
指向误差越大,图像恒星和视场内星表恒星的交集越小,即同时存在于图像和星表子集的恒星越少。交集占的比例比较小时,图像三角形和星表三角形的分布区域的交叠部分也会发生变化。可能会出现这样一种情况,图像三角形分布稀疏的区域,对应的星表三角形分布却比较密集。这就会导致三角形匹配出错的概率增加。图2是指向误差02°时的分析结果,绿色菱形表示星表恒星三角形,红色方块表示图像恒星三角形,蓝色圆形圈出了匹配的三角形。从第11个三角形开始,就已经出现匹配出错的情况。匹配20个三角形以后,匹配错的三角形开始大量增加。指向误差如果继续增大,匹配出错的情况将更加严重,从第二、甚至第一个三角形就开始匹配出错。原因如前面所说,由于指向误差的影响,图像三角形分布稀疏的区域,未必是星表三角形分布稀疏的区域,三角形匹配出错无法避免。
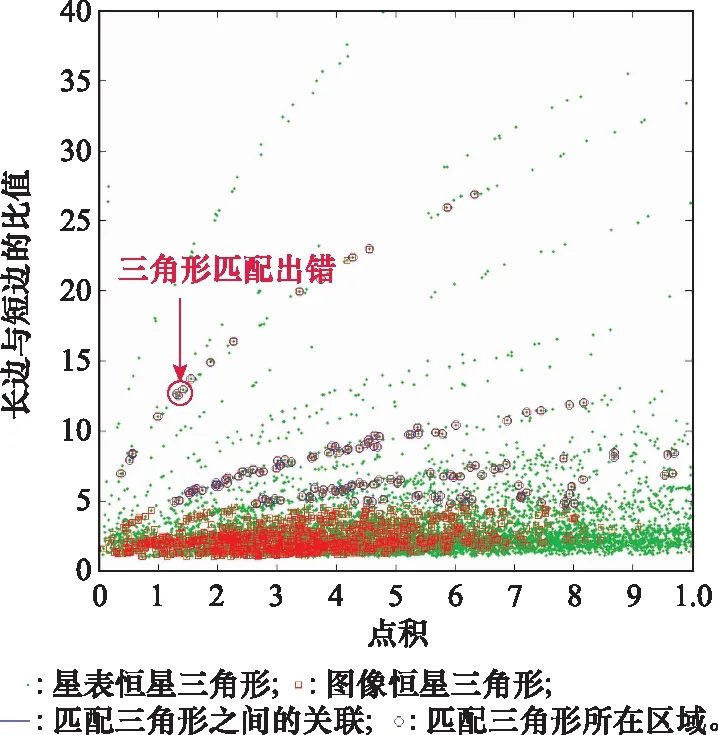
图2 指向误差对三角形分布的影响Fig.2 Influence of pointing offset on triangle distribution
另一方面,为了保证底片模型的精度,我们希望匹配上的恒星越多越好。根据经验,至少需要匹配成功6颗恒星(大约对应20个三角形)。这就要求交集内的恒星越多越好。由于交集区域无法提前预知,要增加交集内的恒星数,就不可避免地要扩大视场内的星表恒星集合(例如提取更暗的恒星),使用更多的恒星参与三角形匹配。随着使用恒星数的增加,三角形的分布密度逐渐增大,匹配出错的概率逐渐增加。图3展示了视场33°时的仿真结果。随着指向误差增大,匹配成功率逐渐降低。因此,在实际应用中,快速三角形匹配算法的匹配准确性是打折扣的。
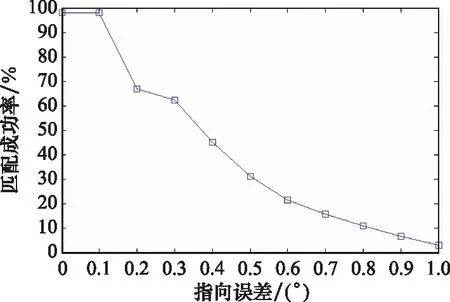
图3 指向误差对匹配成功的影响Fig.3 Influence of pointing offset on matching success
另外,三角形匹配都是基于误差阈值来判断是否成功的。当三角形的分布密度增大到一定程度,误差阈值的选取就变得比较困难。为了在实际应用中具有较高的容错性,我们经常会将阈值设置的相对宽松,以应对光学畸变、星象定心不准、亮度测量精度不高等因素的影响。实际图像中的恒星分布并不均匀,因此对应的三角形空间的分布密度会有很大变化。当阈值大于三角形分布密度时,凭借经验设定的阈值难以保证不出现错误匹配。
通过以上分析可以看出,由于指向误差的影响,原有的快速三角形匹配算法丧失了快速找出正确三角形匹配的优势。为了满足后续底片模型计算的需求,该算法需要大大增加迭代次数,从而找到足够的匹配三角形。然而,该算法对三角形匹配正确的核验是基于阈值的。这样会导致两种结果:① 阈值设定过松,匹配错误的恒星映射被当作正确结果参与后续底片模型计算,导致底片模型精度较差甚至模型计算不成功;② 阈值设定过紧,匹配正确的恒星映射无法通过核验,导致搜索次数大大增加,消耗过多时间。虽然我们尝试了修改阈值、增加匹配时间、扩大搜索视场、提高星表恒星使用星等(提取更暗恒星)等方法,编制程序运行数小时,但是均未在可接受时间内得到预期结果。
在上述信息不完备的情况下,为了尽可能提高匹配的准确性,去除错误匹配,我们在原快速三角形匹配算法基础上进行了改进,通过模糊投票法来提高匹配准确性。
1.2 模糊决策原理
模糊决策是基于模糊数学的推理方法,是指在模糊环境下进行决策的数学理论和方法。现实生活中,我们在做决策时所掌握的信息一般都是不完备的。严格来说,现实的决策大多是模糊决策。
模糊决策的目标是对论域中的对象进行排序,或依据限制条件选择出最优对象。我们可以选用模糊综合评价法,应用模糊关系合成的原理,从多个因素(指标)对事物进行评价,给出评分,以便后续进行排序或筛选。
模糊综合评价法的步骤如下:
确定评价对象的指标集合;
确定评价等级集合,例如{优,良,差}或者{正确,错误};
建立各指标对评价等级的模糊关系矩阵,其元素为中元素对中等级的隶属函数;
确定各评判因素(指标)的权重向量;
选择评价指标的合成算子;
计算综合评价得分=O。
1.3 模糊投票法
如第11节所述,在实际应用中,三角形匹配出错是无法完全避免的。如果三角形匹配出错,采用该匹配结果来计算图像恒星到星表恒星的映射关系,可能会得到矛盾甚至错误的恒星映射。假设三角形匹配结果1和三角形匹配结果2是错误的。如果三角形匹配结果1认为图像恒星A对应于星表恒星B,而三角形匹配结果3认为图像恒星A对应于星表恒星C,则会得到矛盾的恒星映射结果。如果三角形匹配结果1和匹配结果2认为图像恒星A对应于星表恒星B,而三角形匹配结果3认为图像恒星A对应于星表恒星C,则传统投票法得到的图像恒星A的映射结果可能是错误的。容易匹配出错的三角形之间的相似度比较高,我们应该用更精确的方法来衡量三角形匹配结果的可靠性,并将这种可靠性度量融入后续的恒星映射的投票中,以便得到更可靠的恒星映射结果。因此,尝试引入模糊决策方法。
选择三角形的特征匹配误差作为评价指标,通过模糊计算得到三角形匹配正确的确定性程度,后续据此进行投票,通过票数多少决定恒星映射。由于匹配正确和匹配错误是互补关系,只需计算每个指标对匹配正确的隶属度函数。用一个变量来表示某一指标导致的不确定性(即该指标的隶属度函数),然后采用模糊逻辑方法综合所有指标的不确定性,最后推理得到期望目标的确定性。
首先用一个模糊变量来表示两个三角形在某一特征上的匹配程度(或匹配的不确定程度,它和匹配程度之和为1)。假设三角形匹配时通过判断特征和的差异是否小于阈值来判断两个三角形是否匹配。图像恒星三角形用(,)表示,星表恒星三角形用(′,′)表示。|-′|和|-′|都小于指定阈值则三角形匹配成功。为了后续用于投票,匹配程度应该是一个值域大小固定的量。将特征的差值归一化到[0,1]区间,用来表示某一特征匹配成功的不确定度。可以简单定义公式如下:
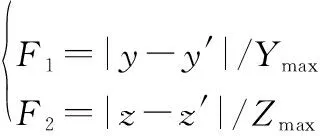
(2)
式中:是变量所在定义域中的最大值,是变量所在定义域中的最大值,实际应用中可以通过统计值和值得到。这里的归一化要考虑变量的特点,也可采用其他模糊数学的方法来定义。和的值域应该为[0,05),超过05则认为阈值设置不合理,应该调整相应阈值。然后,将两个变量的不确定度融合成三角形匹配的不确定度,可以从模糊算子中选择一种来计算。这里采用简单的欧氏距离方法进行初步尝试。假设三角形用个特征表示,′相当于维误差向量的模,然后再进行归一化得到融合后的不确定度(由于最大值为05,′的最大值为(×14)12),这样更易于理解,即
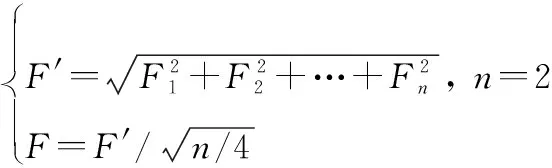
(3)
最后,求得三角形匹配的确定度=1-。的取值范围大概为(0,1]。采用投票法,累加三角形匹配的确定度形成投票矩阵(如表1所示),通过投票结果来决定图像恒星和哪个星表恒星是正确匹配。假设三角形匹配成功,匹配确定度为,则投票时对包含的恒星映射的票数加。最后选取投票数最高的恒星映射。表1中,如果图像恒星1的最高投票得分为15,则其对应于星表恒星3。
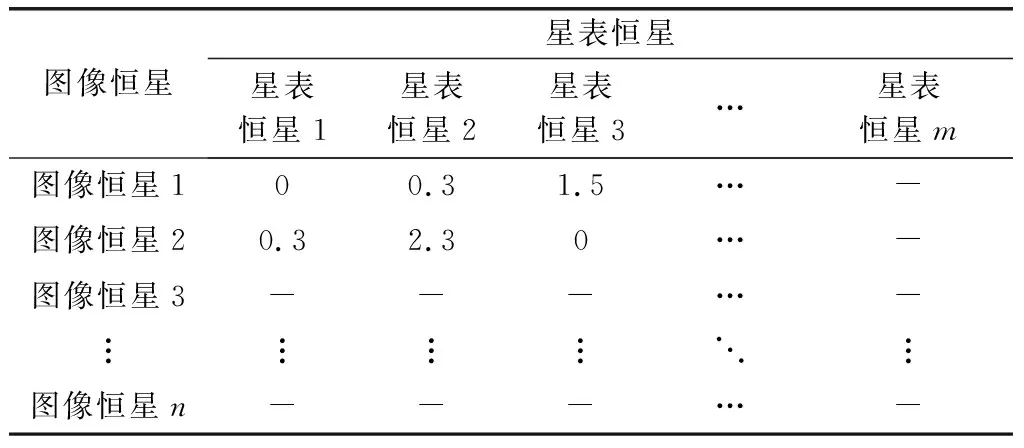
表1 投票矩阵
2 算法设计
快速三角形匹配算法中还有一个需要关注的参量,即需要匹配成功的三角形的个数,假设其大小为。当匹配成功个三角形后,就要退出循环,进入后续的底片模型计算阶段。的选取要综合考虑计算速度和计算精度:设置过大会导致耗时较长,丧失快速三角形匹配的优势;设置过小会导致底片模型计算所需的三角形个数不足,影响模型精度。下面通过实验分析一下如何设置大小。
由前述快速三角形匹配算法的介绍可以看出:最开始是在三角形分布稀疏区域进行匹配的,匹配准确的概率较高;随着三角形匹配个数的增加,匹配逐渐进入三角形分布密集区域,三角形匹配出错的概率逐渐增大,随之导致恒星匹配的正确率逐渐下降。分析恒星匹配的准确率(匹配正确恒星数匹配恒星总数)和匹配成功三角形个数的关系,如图4所示。
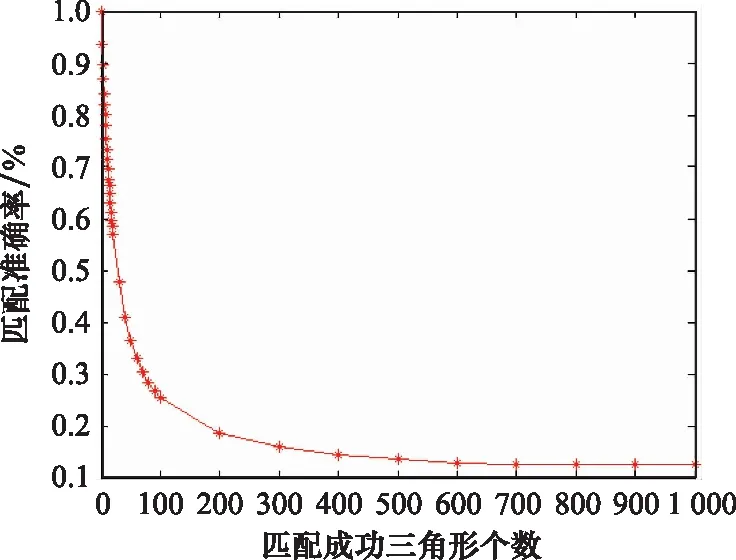
图4 匹配成功三角形个数对恒星匹配准确率的影响Fig.4 Influence of the number of successfully matched triangles on the accuracy of star matching
从图4可以看出,匹配准确率下降很快,即使要求匹配成功的三角形个数很少,也很难保证用于底片模型计算的恒星映射都是正确的。这就要求快速匹配算法有一定的容错性。对之前的快速匹配算法进行改进:一方面采用三角形的多个特征参与判别是否匹配,期望能提高准确率;另一方面放宽匹配条件,允许出现满足阈值的多个匹配,通过后续的模糊投票法来最终确定恒星映射。
下面首先介绍改进后的算法主流程,然后简单介绍算法中涉及的底片模型计算。
2.1 改进的星表匹配算法
重新定义三角形,除长中边点积和长短边比值外,还保留长中边比值、中短边比值、最长边的边长值,因此具有更多特征,匹配准确性更高。三角形用(,,,,)表示,定义如下:
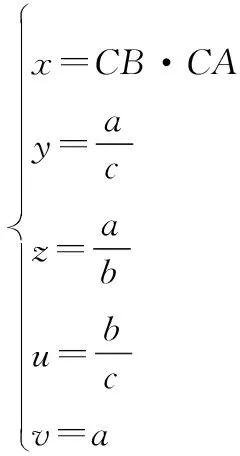
(4)
式中:为中长边。改进后的算法如下。算法中的取值根据实际需求设定,精度稳定、满足耗时要求即可。

算法2 改进的快速三角形匹配算法输入 图像恒星、星表恒星、阈值、搜索范围Δ输出 图像恒星到星表恒星的映射1. 构造图像和星表三角形列表,都按y值排序;2. 对于一个待匹配三角形,在侯选三角形中采用二分法查找最接近的y值;3. 在找到的y值附近[y-Δ,y+Δ]寻找满足匹配阈值的所有三角形;
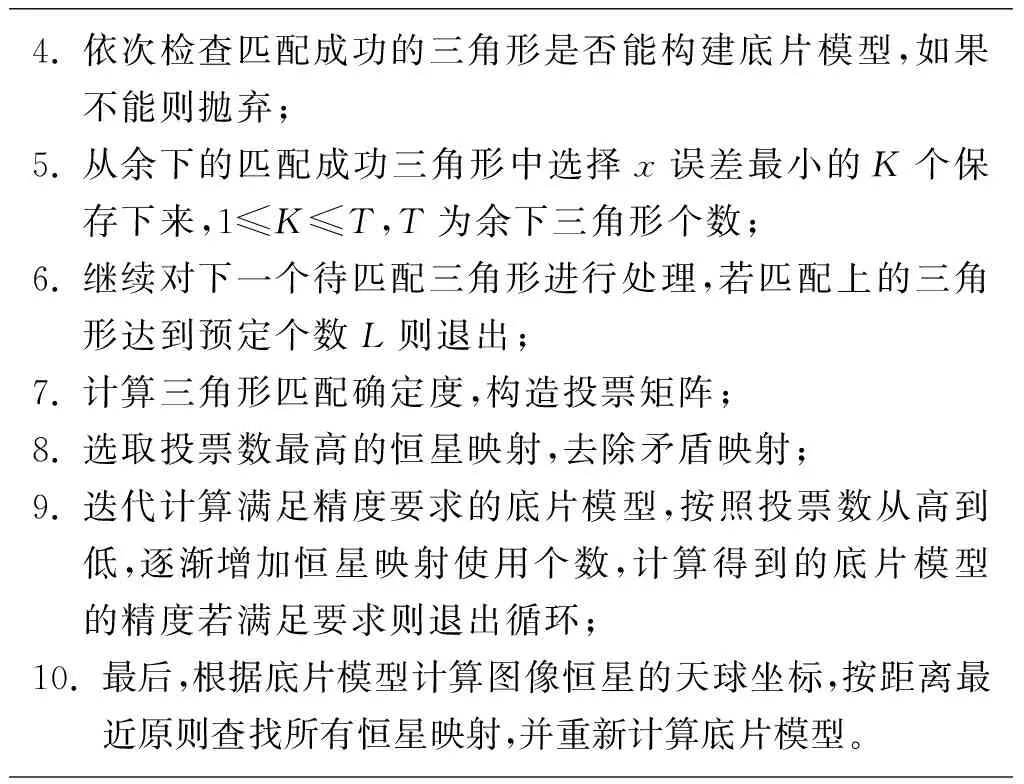
4. 依次检查匹配成功的三角形是否能构建底片模型,如果不能则抛弃;5. 从余下的匹配成功三角形中选择x误差最小的K个保存下来,1≤K≤T,T为余下三角形个数;6. 继续对下一个待匹配三角形进行处理,若匹配上的三角形达到预定个数L则退出;7. 计算三角形匹配确定度,构造投票矩阵;8. 选取投票数最高的恒星映射,去除矛盾映射;9. 迭代计算满足精度要求的底片模型,按照投票数从高到低,逐渐增加恒星映射使用个数,计算得到的底片模型的精度若满足要求则退出循环;10. 最后,根据底片模型计算图像恒星的天球坐标,按距离最近原则查找所有恒星映射,并重新计算底片模型。
基于模糊投票逐个选出正确的恒星映射,通过迭代计算底片模型去除了错误匹配,最后采用正确的底片模型、按照距离最近原则找到所有恒星的映射。通过这种方法,解决了参量、匹配阈值的设置问题,使算法具有自适应性,并能够容忍一定程度的指向误差。
2.2 底片模型简介
底片模型既是天文定位的输出,也是判断星表匹配是否成功的准则。底片模型是一个转换方程,原理如图5所示。

图5 投影模型Fig.5 Projection model
星表恒星天球坐标(,)可以通过公式(5)转换为理想平面坐标(例如平面中的一点),对应图像中某一测量坐标。若已知底片模型和光学图像中空间目标的测量坐标,即可计算得到空间目标的理想平面坐标,进而转换得到其天球坐标。式(5)中,为天球赤经,为天球赤纬,为望远镜光轴指向的天球赤经,为望远镜光轴指向的天球赤纬。(,)即为图像中心指向。
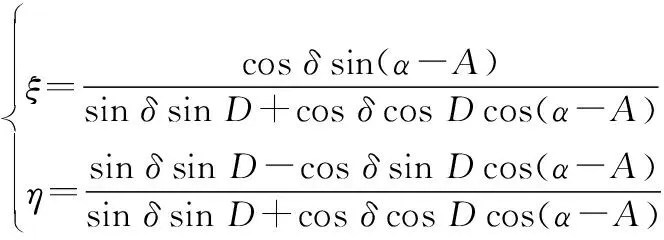
(5)
常用的底片模型的转换方程有6常数模型、12常数模型,以及20常数模型,表达式如下:
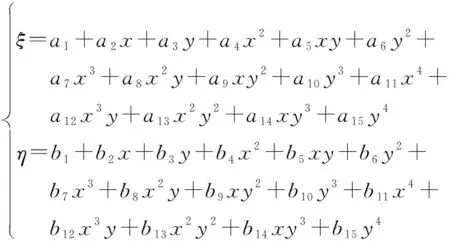
(6)
选择和的前3项即是6常数模型,选择前6项即是12常数模型,选择前10项即是20常数模型。其中,为恒星在图像中的像素横轴坐标,为恒星在图像中的像素纵轴坐标,为恒星在理想坐标系的横坐标,为恒星在理想坐标系的纵坐标。底片模型求解即是计算和的取值。
求解底片模型需要输入已经匹配上的恒星信息,包括恒星的图像测量坐标(,)和匹配得到的天球坐标转换得到的理想平面坐标(,)。为了尽快找到满足精度要求的底片模型,优先选择投票数多的恒星映射参与底片模型计算。求解底片模型参数,一般采用最小二乘法,可以通过解方程组的方式计算得到。
3 仿真校验
采用上述改进算法进行软件实现,有些算法参考了一些成熟的天文软件(涉及软件架构、星象提取、星表使用、底片模型和系统稳定性)。然后对处理性能进行了测试。软件运行的软硬件环境如表2所示。

表2 测试的硬件和软件环境
处理了新疆南山站一台25 cm望远镜的图像(视场3.3°×3.3°),选取了其中678幅图像的数据作为天文定位模块的测试输入。设定从图像中选取最亮的40颗恒星进行星表匹配。显然,匹配的恒星数越多,耗时越长,且耗时呈几何级增长。根据实际需求选取足够的图像恒星进行匹配即可。
该望远镜的指向误差大约为0.2°左右。由于指向误差较大,原有的快速三角形匹配算法难以在短时间内找到足够多且匹配正确的恒星映射,无法生成满足精度要求的底片模型。因此,无法给出原快速三角形匹配算法的处理结果,只能从文献[5]中摘出计算耗时进行参考:匹配40颗恒星,CPU 2.4 GHz的情况下耗时(24.43±1.36)ms。
采用改进后的算法对这678幅图像的数据进行处理,天文定位成功677幅,成功率约为99.9%。其中1幅图像匹配成功4颗星并计算得到底片模型,由于不满足5颗星的成功判别指标,被人为判别为失败。两种算法的性能对比如表3所示。

表3 测试结果对比
改进算法的测试结果显示,星表匹配平均耗时为30.310 ms,其中,底片模型计算及天球坐标转换模块平均耗时为2.718 ms。星表匹配平均匹配成功61.848颗恒星,底片模型拟合赤经标准差平均为2.795 arcsec,底片模型拟合赤纬标准差平均为0.694 arcsec。
后来对软件的内存使用进行了优化,计算耗时进一步降低。将两种算法的匹配耗时随使用恒星数的变化情况列表如表4所示。

表4 计算耗时对比
4 结 论
为了应对海量光学图像的快速处理任务,分析了三角形匹配算法在实际应用中的一些问题,提出了一种改进的快速处理算法。该算法在保持快速处理的情况下,通过模糊投票法提高了星表匹配的准确性,进而提高了天文定位的精度,并且增强了算法对指向误差的适应性,进而提高了软件的稳定性。最后给出了软件实现后的测试结果,证明了算法的有效性。
