汽车CAN 总线入侵检测算法性能模糊测试方法研究*
2022-05-06田韵嵩李中伟金显吉
田韵嵩 ,李中伟 ,谭 凯 ,洪 晟 ,刘 勇 ,金显吉
(1.哈尔滨工业大学 电气工程及自动化学院,黑龙江 哈尔滨150001;2.北京航空航天大学 网络空间安全学院,北京 100191)
0 引言
现代汽车智能化功能越来越丰富,汽车与外部的信息交互越来越频繁,汽车网络被入侵的风险越来越高[1]。而入侵检测算法被应用于汽车CAN 总线网络安全防御中,其检测恶意攻击的能力将对汽车CAN 总线网络的安全性产生影响。
入侵检测算法能够识别外部针对网络资源的恶意操作,也能够检测内部用户的违规或未授权的非法行为。 目前,入侵检测算法从检测技术的角度可分为以下3 类:(1)基于规则的入侵检测算法;(2)基于统计的入侵检测算法;(3)基于机器学习的入侵检测算法[2]。 其中基于机器学习的入侵检测算法能够利用庞大的已有数据进行学习,发现内在规律,实现网络攻击行为检测的智能化。 并且机器学习具备预测能力,对未知模式的攻击也具备一定的检测能力,是目前热门的入侵检测算法研究领域。
近年来,越来越多的研究人员开始对汽车CAN总线的入侵检测算法进行研究。 美国密歇根大学的Cho 等提出利用电子控制单元(Electronic Control Unit,ECU)指纹时钟,结合递归最小二乘法有效监测CAN总线异常[3]。 德国的 Kneib 等提出从 CAN 报文数据帧中提取指纹来识别 ECU[4]。Groza 等提出利用布隆过滤器监测报文标识符和部分数据字段的周期,检测潜在的重放和篡改攻击[5]。 曾润针对时间触发型和事件触发型的汽车CAN 报文,分别提出了基于发送时间间隔与C4.5 决策树的入侵检测算法[6]。吴贻淮提出了基于 PCA-BP 的 CAN 数据包发送频率检测算法及基于GA-RBF 神经网络的CAN 网络数据关联性检测算法[7]。 入侵检测算法的多样性为保障车载通信网络的安全提供了更多的选择,然而,如何对入侵检测算法的检测性能进行测试,确保应用于汽车通信安全防护的算法是可靠且有效的成为了一个新的亟待解决的问题。
目前,国内外针对入侵检测算法的检测性能主要采用相对传统的方法进行测试,即利用已有数据集对算法检测性能进行模糊测试,这种方法的缺点是所采用的测试数据集格式和内容固定,脱离入侵检测算法的实际应用情境,导致得到的测试结果可信度较低[8-9]。为解决这一问题,本文提出一种改进汽车CAN 总线入侵检测算法性能模糊测试方法[10-12]。该方法针对已知和未知CAN 总线协议规范的情况分别利用基于字段权重和基于WGAN-GP 的方法生成测试覆盖率较高的测试用例,通过将测试用例输入汽车CAN 总线入侵检测算法中,得到入侵检测算法对测试用例的检测率,完成对入侵检测算法的性能测试。
1 基于机器学习的入侵检测算法
入侵检测算法被广泛应用于汽车CAN 总线网络的安全防护中,而基于机器学习的入侵检测算法更是目前研究的热点[13]。 基于机器学习的入侵检测算法能够把异常行为识别转换为模式识别问题,根据传输数据特征和已有数据记录等来区分正常和异常的行为,在提升入侵检测效率的同时也降低了误报率和漏报率,应用前景广阔。 常用的基于机器学习的入侵检测算法主要包括神经网络、集成学习、K 近邻、贝叶斯网络、聚类算法等。
为验证本文提出的测试方法的有效性,本文选取了两种理论成熟、应用广泛且精度较高的基于机器学习的入侵检测算法——K 近邻算法和AdaBoost算法进行研究并实现,利用本文提出的方法对两种入侵检测算法进行性能测试。
1.1 基于 KNN 的汽车 CAN 总线入侵检测算法
K 近 邻 算 法(K-Nearest Neighbor,KNN)是 一 种 监督学习算法。 这种算法通过使用所有已知类型的数据样本作为参照,来判断未知数据样本的类别。 首先,计算待判断类型的未知数据样本到所有已知类型的数据样本之间的距离,然后按照与待判断类型的未知数据样本距离最近的原则选择k 个已知类型的数据样本,判断未知数据样本的类型与k 个已知类型的数据样本中占比较多的类型是否相一致。其中常见的计算样本间距离的函数有:马氏距离、巴氏距离、汉明距离、切比雪夫距离等。 KNN 算法的优点是理论简单、易于实现,并且使用新数据更新训练模型也较为容易。 缺点在于对样本容量较大的数据集应用该算法时计算量较大,且在每次分类时都会进行一次全局运算;另外k 值的选取也会对分类结果的准确性产生很大的影响。
基于KNN 的汽车 CAN 总线入侵检测算法基本流程如图 1 所示。

图1 KNN 算法流程图
本文以汉明距离作为所实现的KNN 算法的距离函数,计算已知与未知报文样本之间的距离,找出k 个距离待判断类型的未知报文样本最近的已知类型报文样本,并统计其中正常与异常报文的数量,以其中数量占比更多的报文类别作为未知报文样本的类别判定结果。
1.2 基于AdaBoost 的汽车CAN 总线入侵检测算法
自适应提升算法(Adaptive Boosting,AdaBoost)是一种提升学习算法。 AdaBoost 算法的优点是可有效利用弱分类器进行级联且模型训练方式充分考虑了每个弱分类器的权重,分类精度较高;缺点是AdaBoost 训练过程迭代次数的设定对分类结果影响较大,且模型整体的训练过程耗时较长。 AdaBoost算法的基本流程如下:
(1)构造训练集。 在汽车 CAN 总线上采集正常的CAN 报文并变异生成训练数据集, 赋予其中所有样本相同的初始权重值。
(2)训练弱分类器。 训练初始弱分类器,计算样本分类正误率,按照正误率确定弱分类器的权重,并对训练集样本权重进行更新:提高分类错误的样本权重,降低分类正确的样本权重。 之后训练下一个弱分类器。
(3)弱分类器组合构成强分类器。在强分类器中弱分类器的影响能力由训练时对训练样本检测的正误率决定。 弱分类器的检测正确率越高,在最终的分类函数中影响力越大。
(4)在得到 AdaBoost 算法的强分类器后,使用强分类器 H(x)检测报文。 AdaBoost 算法的训练过程如图 2 所示。

图2 AdaBoost 算法的训练过程
2 改进汽车CAN 总线入侵检测算法性能模糊测试方法
模糊测试通过向被测对象发送大量随机或半随机的数据来进行安全性测试。 目前,对入侵检测算法的性能测试多采用公开数据集或经随机变异得到的数据集作为测试用例,测试算法对于异常报文的检测率。 但公开数据集的内容形式相对固定,人工随机变异得到的数据集则存在随机性太强的缺点,所以传统模糊测试方法的测试用例覆盖率不高,易出现组合爆炸的问题,测试效率较差且得到的测试结果并不可靠。 而本文所提出的改进汽车CAN 总线入侵检测算法性能模糊测试方法重点针对生成模糊测试用例的方法进行研究,可以生成高覆盖率的测试用例,通过计算汽车CAN 总线入侵检测算法对测试用例的检测率,测试算法的性能,能够得到可信度较高的入侵检测算法性能测试结果。
本文所提出的汽车CAN 总线入侵检测算法性能测试方法的具体步骤如下:
(1)构建报文数据集。 采用以下两种方式构建数据集:①利用汽车内部的OBD 等接口,在汽车处于正常行驶的状态下收集CAN 报文,构造正常报文集,并通过人工变异的方式构建伪造异常报文集。②通过CANoe 等仿真软件模拟汽车正常行驶和出现异常的状况,生成正常和异常报文数据,构建报文数据集。
(2)预处理 CAN 报文,按照 ID 分类 CAN 报文。根据规定,CAN 总线报文数据场长度不超过 8 B,为了方便进行统一处理,当报文数据场的长度不足8 B 时,用 0 补齐至 8 B。 并将十六进制的报文数据转化为二进制形式进行表示。
(3)生成测试用例。 这部分是本文提出的汽车CAN 总线入侵检测算法性能测试方法的核心。 为生成覆盖率较高的测试用例集,本文针对是否已知CAN 总线协议规范的情况分别提出了两种生成测试用例的方法,分别是基于字段权重和基于WGAN-GP 的测试用例生成方法,在已知 CAN 总线协议规范的情况下可运用基于字段权重的测试用例生成方法,在未知CAN 总线协议规范的情况下,可以使用基于WGAN-GP 的测试用例生成方法。
(4)将测试用例输入到入侵检测分类器中,观察分类结果, 根据分类结果计算分类器的准确率,评价入侵检测算法的性能。
2.1 基于字段权重的测试用例生成方法
基于字段权重的测试用例生成方法需要在已知CAN 总线应用层报文数据场的字段格式基础上进行。 下面首先对报文数据场内第j 位的位翻转数进行定义:

式中,BFNj为报文数据场第 j 位的位翻转数,m 为汽车 CAN 总线系统中一段时间 t 内某 ID 相同报文的集合,n 为某ID 相同报文的集合中的报文数量。
则在该段时间内报文的第j 位翻转率为:

式中,BFAj为报文第 j 位的位翻转率,BFNj为报文数据场第 j 位的位翻转数,n 为某 ID 相同报文的集合中的报文数量。
计算出在一段时间t 内某ID 的报文的位翻转率BFAj后,定义该字段内的平均位翻转率为:

式中,BFDk为第 k 个字段的平均位翻转率,k1为该字段的起始位,k2为该字段的结束位。
当一个字段的平均位翻转率越高,说明在这段时间内该字段的变化越快,在生成测试用例时应作为重点考虑的变异对象。 所以对变化较快的字段赋予较高的权值。 本文采用了以下几种构造变异数据的方法:
(1)对CAN 报文数据场中的某一段数据进行随机变异,其余部分保持不变。
(2)设置一定的变异比例,按照比例选取CAN报文数据场中的部分二进制位,以“从 0 置 1,从 1置0”的形式对这部分二进制位进行变异。
(3)按照协议规范,将数据场中某一字段看作是一个整体,对整体的数据值进行加1 或减1 操作来进行变异。
(4)选取数据场中一定比例的二进制位进行置0 或 置 1 操 作 。
另外,当多个字段组合起来进行变异时也可能会被入侵检测算法检测到异常,因此为了提升生成的测试用例的质量,还需要考虑将同一ID 的报文所划分的不同报文字段进行多字段组合变异。 单一字段变异和组合字段变异两者结合生成最终模糊测试使用的所有测试用例。 具体的步骤如下:
(1)首先根据协议规范对字段格式的划分,确定对每个字段进行变异的权重指数。
(2)针对单一字段进行变异。采用合适的变异方法,利用之前确认的每个字段进行变异的权重指数,确定单一字段进行变异的次数,变异权重越高,则变异次数越多,相应生成的测试用例也越多。
(3)分析不同字段之间可能存在的关联性。利用人工分析或通过采取关联规则分析技术分析不同字段之间可能存在的关系,以此为基础进行组合字段的变异。
(4)计算组合字段的变异权重指数,进一步确认组合测试用例的数目并变异生成。
本文采用从正常运行的汽车上采集的数据变异生成模糊测试用例,为保护汽车协议的私密性,采用“X”来隐藏汽车的一部分报文 ID,采集 ID 为 0x1X4的报文格式为[0X1X2X31B 08 3Y 00 Z1Z2Z3Z4]。 在计算了字段的平均位翻转率及组合字段变异权重等参数后,能够生成报文 ID 为 0x1X4 的部分模糊测试用例如表1 所示。

表1 基于字段权重方法生成的部分 ID 0x1X4 报文
由表1 可以看出,生成的报文基本符合字段的格式。
2.2 基于WGAN-GP 的测试用例生成方法
生成对抗网络(Generative Adversarial Network,GAN)是一种深度学习算法,分别由生成模型和判别模型两部分组成。 模型整体的训练是一个博弈的过程,生成模型输入噪声,判别模型输入真实数据及生成模型生成的数据,按照判别模型对其输入数据的判别结果调整GAN 模型的参数,使生成数据与真实数据逐渐相似。 而本文的测试用例需要依据协议格式规范生成,采用生成对抗网络模型进行训练能够高效地对正常CAN 总线报文的格式规范进行学习,训练完成的模型最终能够生成多数满足使用需要的测试用例[14]。
Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network,WGAN)是为了解决 GAN 在使用时可能出现的梯度消失、梯度爆炸、模型不收敛等问题而提出的一种改进方法[15]。 使用 Wasserstein 距离来衡量真实数据与生成数据的差异性,该距离的定义如式(4)所示:

另外,其判别模型的目标函数如式(5)所示:

生成模型的目标函数如式(6)所示:

式(4)~式(6)中,Pdata是真实数据分布,PZ是生成数据分布,V(D,G)为生成对抗网络的目标函数,D 代表判别模型,D(x)表示 x 是真实数据的概率,G 代表生成模型,G(z)是样本数据 z 的概率分布。
Wasserstein 距离越小,则证明模型训练效果越好。
然而,WGAN 仍存在训练困难、模型收敛较慢等问题。 为解决上述问题,Ishaan 等人提出了引入梯度惩罚的改进Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network with Gradient Penalty,WGAN-GP),去除权重裁剪项并在判别模型的目标函数中加入梯度惩罚项,目标函数如式(7)所示[16]。 WGAN-GP 能够稳定地以更快的速度趋于收敛,因此本文将选用WGAN-GP 进行模型的训练,生成模糊测试用例。

本文的WGAN-GP 模型采用全连接神经网络结构,由输入层、隐藏层、输出层组成,隐藏层的激活函数选取ReLU 函数,能够有效避免在训练过程中可能会出现的梯度消失现象,减少模型训练和使用时的运算开销。 模型目标函数的优化运用随机梯度下降方式。
在经过充分训练后,可以得到成熟可用的生成对抗网络模型,该模型能够生成可用于入侵检测算法性能测试的模糊测试用例。 改进Wasserstein 生成对抗网络的整体结构如图3 所示。 而生成模型的输入采用均匀的噪声分布,判别模型利用通过汽车OBD 等接口采集的真实CAN 总线报文和生成模型生成的数据进行训练。 训练过程中,生成模型与判别模型相互博弈,调整参数,最终逐渐使生成模型生成的测试用例与正常汽车CAN 总线报文的格式一致。

图3 改进Wasserstein 生成对抗网络训练流程与结构图
基于WGAN-GP 的测试用例生成方法无需对CAN 总线协议格式进行具体分析,该方法可以在未知CAN 总线协议规范的基础上进行,可以直接利用采集到的CAN 总线报文进行模型训练,其适用性更强。 具体步骤如下:
(1)构造训练数据集。生成对抗网络模型的训练过程要用到大量的数据,因此,为保证模型训练的效果,在训练前需要合理地构造训练数据集。 本文使用 CAN 总线分析仪,从汽车的 OBD 等端口获取真实的CAN 总线报文数据,所采集的报文数据均为十六进制的形式,为便于模型的训练使用,对采集的报文数据进行了两步预处理操作:去除报文数据集中存在重复的数据,并将报文数据由十六进制的形式转换为十进制形式,形成用于训练模型的数据集。
(2)构建生成模型。 本文利用 WGAN-GP 技术构建测试用例生成模型。 所构建的模型将满足以下两点条件:①能够生成符合CAN 报文格式规范要求的测试用例,同时也要求不同测试用例的内容存有足够的差异性,保证测试用例的测试覆盖率足够高;②保证构建生成模型并将模型训练至成熟可用这一过程的时间成本要尽可能地低。
(3)输入测试。利用生成对抗网络模型生成测试用例,将生成的测试用例注入到入侵检测算法中,观察分类结果。
WGAN-GP 模型生成的 ID 0x1X4 的部分报文数据如表 2 所示。 通过WGAN-GP 模型同样也生成了符合协议格式的报文。

表2 基于WGAN-GP 方法生成的部分 ID 0x1X4 报文
3 试验验证
为了验证本文所提出的改进汽车CAN 总线入侵检测算法性能模糊测试方法的有效性,本文对基于KNN 和AdaBoost 的入侵检测算法进行了性能测试,选取了 10 个不同 ID 的 CAN 总线报文集训练入侵检测算法的分类器。 使用汽车正常运行时实际采集的20 000 条CAN 总线报文作为正常报文数据集,并通过人工随机变异的方式生成异常报文数据集。 对报文数据集按照报文 ID 进行分类。 在基于KNN 算法和AdaBoost 算法的分类器训练过程中,训练集中包括多个不同 ID 的 CAN 报文,每个ID 各有3 000 条报文,其中正常和异常的报文各占一半,训练过程采用MATLAB 软件中的工具箱进行,最终能够分别得到基于两种算法的检测分类器。
利用基于字段权重的方法和基于WGAN-GP 的方法生成测试用例。 两种测试用例生成方法使用的编程环境为 PyCharm,编译器为 Python3.5。 基于WGAN-GP 的测试用例生成方法采用了深度学习框架TensorFlow 搭建生成对抗网络。 使用生成的测试用例对基于KNN 和 AdaBoost 的入侵检测算法进行性能测试,分别计算两种入侵检测算法对测试用例的检测率,作为入侵检测算法的检测性能测试结果,具体如图4 和图 5 所示。 图中横坐标为不同报文的ID,纵坐标为入侵检测算法对ID 不同的测试用例的检测率。
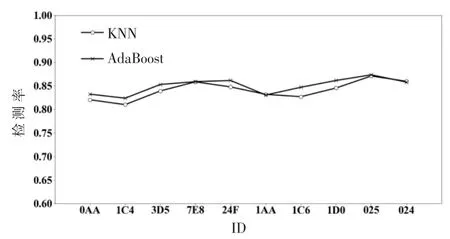
图4 基于字段权重生成的测试用例的检测率

图5 基于WGAN-GP 生成的测试用例的检测率
由图 4 和图 5 可以看出,KNN 算法对基于字段权重生成的测试用例的平均检测率为84.3%,对基于WGAN-GP 生成的测试用例的平均检测率为78.3%。 AdaBoost 算法对基于字段权重生成的测试用例的平均检测率为85.1%,对基于 WGAN-GP 生成的测试用例的平均检测率为79.8%。
由测试结果分析可知:(1)相对于传统的汽车CAN 总线入侵检测算法性能模糊测试方法,本文提出的改进模糊测试方法所生成的测试用例通过KNN 算法和AdaBoost 算法检测的成功率更高,证明了本文所提出的两种方法所生成的模糊测试用例相较于传统模糊测试方法所使用的测试用例的针对性更强,能够更好地适应入侵检测算法的实际应用场景。 (2)与基于字段权重方法生成的测试用例相比,利用改进Wasserstein 生成对抗网络方法生成的测试用例通过 KNN 和 AdaBoost 算法检测的概率相对较高,这表明该方法生成的测试用例在报文格式上与正常的CAN 总线报文更为相似,能够更好地避开入侵检测,可以更有效地挖掘汽车CAN 总线入侵检测算法检测能力存在的不足之处。 (3)从两种入侵检测算法对异常报文的平均检测率结果来看,AdaBoost 算法的检测水平要更优于 KNN 算法,因此若安全研究人员在选用汽车CAN 总线入侵检测算法时相较于其他因素更为注重检测性能,则可以优先考虑选用AdaBoost 算法,提高汽车CAN总线通信系统的安全防护水平。
4 结论
本文提出了基于字段权重和基于WGAN-GP生成对抗网络的模糊测试用例生成方法,解决了传统模糊测试方法的测试结果因测试用例覆盖率较低而导致可信度较差的问题;提出了一种改进汽车CAN 总线入侵检测算法性能模糊测试方法,以基于机器学习的入侵检测算法 KNN 和 AdaBoost 算法的分类器为对象进行方法的测试验证。 测试结果表明AdaBoost 算法对异常报文的平均检测率相对较高,本文提出的改进汽车CAN 总线入侵检测算法性能模糊测试方法能够生成针对性更强、冗余度更低的测试用例,可以被用于测试入侵检测算法的性能。
本文的下一步研究工作是对实际汽车CAN 总线网络中使用的入侵检测算法进行模糊测试,进一步检验本文所提出的改进汽车CAN 总线入侵检测算法性能模糊测试方法的性能。
